
背景
在实际业务开发中,我们经常遇到这样的场景:某个字段包含复合信息(如 ORDER_12345_USER_6789),需要从中提取某个部分(如订单ID 12345)用于查询和统计。
这时候有两种常见方案:
- 方案A:在 View 层使用正则表达式动态提取
- 方案B:在表中直接存储提取后的ID,View 直接读取
下面通过一个 100 万数据量的实际测试,对比这两种方案的性能差异。
测试环境
- 数据库:PostgreSQL 12+
- 工具:DBeaver
- 数据量:100 万条记录
- 测试方式:同一个表,通过不同的 View 进行对比
方案设计
表结构
js
CREATE TABLE orders (
id SERIAL PRIMARY KEY,
order_info VARCHAR(255), -- 完整的订单信息字符串 (如:ORDER_12345_USER_6789)
order_id INTEGER, -- 预先提取的ID(方案B使用)
amount NUMERIC(10,2),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 为 order_id 创建索引
CREATE INDEX idx_order_id ON orders(order_id);方案A:View中使用正则表达式
js
CREATE OR REPLACE VIEW v_orders_with_regex AS
SELECT
id,
order_info,
(regexp_match(order_info, '[0-9]+'))[1]::INTEGER AS extracted_id, -- 运行时提取
amount,
created_at
FROM orders;特点:
- 不占用额外存储空间
- 每次查询时都需要执行正则表达式
- 无法使用索引优化
方案B:View中直接读取预存的ID
js
CREATE OR REPLACE VIEW v_orders_with_direct_id AS
SELECT
id,
order_info,
order_id AS extracted_id, -- 直接读取
amount,
created_at
FROM orders;特点:
- 需要额外的存储空间(一个 INTEGER 字段)
- 查询时直接读取,无需计算
- 可以使用索引进行优化
**运行结果比较 **

🚀 性能差异:方案B 比方案A 快 ~34 倍!
进行 10 轮不同范围的查询测试:
js
SELECT * FROM benchmark_comparison();运行结果比较

测试3:不同数据范围的详细分析
js
SELECT * FROM detailed_performance_analysis();测试结果
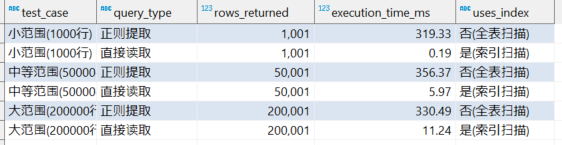
性能分析总结
为什么方案B会快
-
索引使用
- 方案A:正则表达式是运行时计算,无法建立索引,必须全表扫描
- 方案B:预存储的
order_id有索引,可以快速定位
-
计算成本
- 方案A:每次查询都要对每一行执行正则匹配和类型转换
- 方案B:直接读取已存储的值,无需任何计算
-
扫描方式
- 方案A:Seq Scan(顺序扫描)100万行
- 方案B:Index Scan(索引扫描)只访问需要的行
**完整测试代码 **
js
-- =============================================
-- 性能对比测试:View层正则 vs 表中直接存储ID(单表版本)
-- 数据库:PostgreSQL 12+
-- 工具:DBeaver
-- 说明:两种方案的数据在同一个表中,通过不同的View进行对比
-- =============================================
-- =============================================
-- 第一步:创建统一的数据表
-- =============================================
DROP TABLE IF EXISTS orders CASCADE;
CREATE TABLE orders (
id SERIAL PRIMARY KEY,
order_info VARCHAR(255), -- 完整的订单信息字符串
order_id INTEGER, -- 预先提取的ID(方案B使用)
amount NUMERIC(10,2),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 删除可能存在的旧索引
DROP INDEX IF EXISTS idx_order_id;
DROP INDEX IF EXISTS idx_order_info;
-- 为order_id创建索引(方案B会使用)
CREATE INDEX idx_order_id ON orders(order_id);
-- 为order_info创建索引
CREATE INDEX idx_order_info ON orders(order_info);
-- =============================================
-- 第二步:创建两个不同的View
-- =============================================
-- 方案A:View中使用正则表达式提取ID
CREATE OR REPLACE VIEW v_orders_with_regex AS
SELECT
id,
order_info,
(regexp_match(order_info, '[0-9]+'))[1]::INTEGER AS extracted_id, -- 运行时提取
amount,
created_at
FROM orders;
-- 方案B:View中直接读取预存的ID
CREATE OR REPLACE VIEW v_orders_with_direct_id AS
SELECT
id,
order_info,
order_id AS extracted_id, -- 直接读取
amount,
created_at
FROM orders;
-- =============================================
-- 第三步:插入100万条测试数据(需要等待1-2分钟)
-- =============================================
INSERT INTO orders (order_info, order_id, amount)
SELECT
'ORDER_' || i || '_USER_' || (i % 10000), -- 生成订单信息字符串
i, -- 同时存储提取后的ID
ROUND((RANDOM() * 1000)::NUMERIC, 2)
FROM generate_series(1, 1000000) AS i;
-- 验证数据插入
SELECT
'总记录数' AS info,
COUNT(*) AS count
FROM orders;
-- 查看样例数据
SELECT * FROM orders LIMIT 5;
-- =============================================
-- 第四步:更新统计信息
-- =============================================
ANALYZE orders;
-- =============================================
-- 第五步:创建性能测试函数
-- =============================================
-- 创建综合对比测试函数
CREATE OR REPLACE FUNCTION performance_comparison_test()
RETURNS TABLE(
method TEXT,
record_count BIGINT,
avg_amount NUMERIC,
sum_amount NUMERIC,
execution_time_ms NUMERIC
)
LANGUAGE plpgsql
AS $$
DECLARE
start_time TIMESTAMP;
end_time TIMESTAMP;
result_count BIGINT;
result_avg NUMERIC;
result_sum NUMERIC;
BEGIN
-- 测试方案A:使用正则表达式
start_time := clock_timestamp();
SELECT COUNT(*), AVG(amount), SUM(amount)
INTO result_count, result_avg, result_sum
FROM v_orders_with_regex
WHERE extracted_id BETWEEN 100000 AND 200000;
end_time := clock_timestamp();
RETURN QUERY
SELECT
'方案A:正则提取ID'::TEXT,
result_count,
ROUND(result_avg, 2),
ROUND(result_sum, 2),
ROUND(EXTRACT(EPOCH FROM (end_time - start_time)) * 1000, 2);
-- 测试方案B:直接读取ID
start_time := clock_timestamp();
SELECT COUNT(*), AVG(amount), SUM(amount)
INTO result_count, result_avg, result_sum
FROM v_orders_with_direct_id
WHERE extracted_id BETWEEN 100000 AND 200000;
end_time := clock_timestamp();
RETURN QUERY
SELECT
'方案B:直接读取ID'::TEXT,
result_count,
ROUND(result_avg, 2),
ROUND(result_sum, 2),
ROUND(EXTRACT(EPOCH FROM (end_time - start_time)) * 1000, 2);
END;
$$;
-- =============================================
-- 第六步:执行性能对比测试
-- =============================================
SELECT * FROM performance_comparison_test();
-- =============================================
-- 第七步:查看执行计划对比
-- =============================================
-- 方案A的执行计划(使用正则表达式,全表扫描)
EXPLAIN (ANALYZE, BUFFERS, TIMING, VERBOSE)
SELECT extracted_id, amount
FROM v_orders_with_regex
WHERE extracted_id BETWEEN 100000 AND 200000
LIMIT 100;
-- 方案B的执行计划(直接读取ID,使用索引)
EXPLAIN (ANALYZE, BUFFERS, TIMING, VERBOSE)
SELECT extracted_id, amount
FROM v_orders_with_direct_id
WHERE extracted_id BETWEEN 100000 AND 200000
LIMIT 100;
-- =============================================
-- 第八步:多轮压力测试(10轮测试)
-- =============================================
CREATE OR REPLACE FUNCTION benchmark_comparison()
RETURNS TABLE(
summary TEXT,
test_rounds INTEGER,
regex_total_ms NUMERIC,
direct_total_ms NUMERIC,
regex_avg_ms NUMERIC,
direct_avg_ms NUMERIC,
speed_improvement TEXT
)
LANGUAGE plpgsql
AS $$
DECLARE
i INTEGER;
rounds INTEGER := 10;
start_time TIMESTAMP;
end_time TIMESTAMP;
regex_time NUMERIC := 0;
direct_time NUMERIC := 0;
dummy_count BIGINT;
BEGIN
-- 测试正则方案
FOR i IN 1..rounds LOOP
start_time := clock_timestamp();
SELECT COUNT(*) INTO dummy_count
FROM v_orders_with_regex
WHERE extracted_id BETWEEN (i * 50000) AND (i * 50000 + 10000);
end_time := clock_timestamp();
regex_time := regex_time + EXTRACT(EPOCH FROM (end_time - start_time)) * 1000;
END LOOP;
-- 测试直接存储方案
FOR i IN 1..rounds LOOP
start_time := clock_timestamp();
SELECT COUNT(*) INTO dummy_count
FROM v_orders_with_direct_id
WHERE extracted_id BETWEEN (i * 50000) AND (i * 50000 + 10000);
end_time := clock_timestamp();
direct_time := direct_time + EXTRACT(EPOCH FROM (end_time - start_time)) * 1000;
END LOOP;
-- 返回对比结果
RETURN QUERY
SELECT
'━━━━━ 性能对比结果 ━━━━━'::TEXT,
rounds,
ROUND(regex_time, 2),
ROUND(direct_time, 2),
ROUND(regex_time / rounds, 2),
ROUND(direct_time / rounds, 2),
ROUND(regex_time / NULLIF(direct_time, 0), 1) || 'x 慢'::TEXT;
END;
$$;
-- 执行压力测试
SELECT * FROM benchmark_comparison();
-- =============================================
-- 第九步:详细的性能分析
-- =============================================
-- 创建详细分析函数
CREATE OR REPLACE FUNCTION detailed_performance_analysis()
RETURNS TABLE(
test_case TEXT,
query_type TEXT,
rows_returned BIGINT,
execution_time_ms NUMERIC,
uses_index TEXT
)
LANGUAGE plpgsql
AS $$
DECLARE
start_time TIMESTAMP;
end_time TIMESTAMP;
row_count BIGINT;
BEGIN
-- 测试1: 小范围查询 - 正则
start_time := clock_timestamp();
SELECT COUNT(*) INTO row_count FROM v_orders_with_regex
WHERE extracted_id BETWEEN 100000 AND 101000;
end_time := clock_timestamp();
RETURN QUERY SELECT
'小范围(1000行)'::TEXT, '正则提取'::TEXT, row_count,
ROUND(EXTRACT(EPOCH FROM (end_time - start_time)) * 1000, 2),
'否(全表扫描)'::TEXT;
-- 测试1: 小范围查询 - 直接
start_time := clock_timestamp();
SELECT COUNT(*) INTO row_count FROM v_orders_with_direct_id
WHERE extracted_id BETWEEN 100000 AND 101000;
end_time := clock_timestamp();
RETURN QUERY SELECT
'小范围(1000行)'::TEXT, '直接读取'::TEXT, row_count,
ROUND(EXTRACT(EPOCH FROM (end_time - start_time)) * 1000, 2),
'是(索引扫描)'::TEXT;
-- 测试2: 中等范围查询 - 正则
start_time := clock_timestamp();
SELECT COUNT(*) INTO row_count FROM v_orders_with_regex
WHERE extracted_id BETWEEN 100000 AND 150000;
end_time := clock_timestamp();
RETURN QUERY SELECT
'中等范围(50000行)'::TEXT, '正则提取'::TEXT, row_count,
ROUND(EXTRACT(EPOCH FROM (end_time - start_time)) * 1000, 2),
'否(全表扫描)'::TEXT;
-- 测试2: 中等范围查询 - 直接
start_time := clock_timestamp();
SELECT COUNT(*) INTO row_count FROM v_orders_with_direct_id
WHERE extracted_id BETWEEN 100000 AND 150000;
end_time := clock_timestamp();
RETURN QUERY SELECT
'中等范围(50000行)'::TEXT, '直接读取'::TEXT, row_count,
ROUND(EXTRACT(EPOCH FROM (end_time - start_time)) * 1000, 2),
'是(索引扫描)'::TEXT;
-- 测试3: 大范围查询 - 正则
start_time := clock_timestamp();
SELECT COUNT(*) INTO row_count FROM v_orders_with_regex
WHERE extracted_id BETWEEN 100000 AND 300000;
end_time := clock_timestamp();
RETURN QUERY SELECT
'大范围(200000行)'::TEXT, '正则提取'::TEXT, row_count,
ROUND(EXTRACT(EPOCH FROM (end_time - start_time)) * 1000, 2),
'否(全表扫描)'::TEXT;
-- 测试3: 大范围查询 - 直接
start_time := clock_timestamp();
SELECT COUNT(*) INTO row_count FROM v_orders_with_direct_id
WHERE extracted_id BETWEEN 100000 AND 300000;
end_time := clock_timestamp();
RETURN QUERY SELECT
'大范围(200000行)'::TEXT, '直接读取'::TEXT, row_count,
ROUND(EXTRACT(EPOCH FROM (end_time - start_time)) * 1000, 2),
'是(索引扫描)'::TEXT;
END;
$$;
-- 执行详细分析
SELECT * FROM detailed_performance_analysis();
-- =============================================
-- 第十步:查看表结构和索引信息
-- =============================================
-- 查看表结构
SELECT
column_name,
data_type,
character_maximum_length
FROM information_schema.columns
WHERE table_name = 'orders'
ORDER BY ordinal_position;
-- 查看索引信息
SELECT
indexname,
indexdef
FROM pg_indexes
WHERE tablename = 'orders';
-- =============================================
-- 第十一步:清理测试数据(可选)
-- =============================================
/*
DROP TABLE IF EXISTS orders CASCADE;
DROP FUNCTION IF EXISTS performance_comparison_test();
DROP FUNCTION IF EXISTS benchmark_comparison();
DROP FUNCTION IF EXISTS detailed_performance_analysis();
*/引用