目录
[题目1:Transformer 核心架构的原理和工作流程](#题目1:Transformer 核心架构的原理和工作流程)
[题目 2:多头注意力机制的设计动机](#题目 2:多头注意力机制的设计动机)
[题目 3:位置编码的必要性和实现方式](#题目 3:位置编码的必要性和实现方式)
[题目 4:LayerNorm 与 BatchNorm 的区别及选择原因](#题目 4:LayerNorm 与 BatchNorm 的区别及选择原因)
[题目 5:Transformer 的训练稳定性问题](#题目 5:Transformer 的训练稳定性问题)
题目7:详细描述智能体Agent的组成模块和运行机制,举例说明;
题目8:根据智能体对话状态机制流程图,给出具体部件描述和举例说明
[题目 9:主流智能体协作的框架和原理是什么?](#题目 9:主流智能体协作的框架和原理是什么?)
[题目 10:多智能体系统的协作模式](#题目 10:多智能体系统的协作模式)
[题目 11:任务分配机制](#题目 11:任务分配机制)
[题目 12:通信协议与信息交换](#题目 12:通信协议与信息交换)
[题目 13:冲突消解机制](#题目 13:冲突消解机制)
[题目 14:Saas方式调用大模型服务,先解释API遵循Restful格式,再举例调用Qwen3](#题目 14:Saas方式调用大模型服务,先解释API遵循Restful格式,再举例调用Qwen3)
[题目15:说明本地部署 Qwen3 模型的完整流程,涵盖前置准备、核心部署、优化扩展三大模块,逻辑清晰且符合技术文档规范。](#题目15:说明本地部署 Qwen3 模型的完整流程,涵盖前置准备、核心部署、优化扩展三大模块,逻辑清晰且符合技术文档规范。)
[题目16:大模型的函数调用,请对比Function Call和MCP?](#题目16:大模型的函数调用,请对比Function Call和MCP?)
[题目17:LoRA 注入机制优势是什么?举例实现](#题目17:LoRA 注入机制优势是什么?举例实现)
[题目18:LangChain 和 LangGraph 区别?](#题目18:LangChain 和 LangGraph 区别?)
[题目19:基于 LangChain 的 Chains 机制,实现一个「天气查询 + 行程推荐 + 邮件发送」的有序链路](#题目19:基于 LangChain 的 Chains 机制,实现一个「天气查询 + 行程推荐 + 邮件发送」的有序链路)
[题目 1:Qwen3-VL 的技术创新为多模态 AI 的发展开辟了新的道路,合理的架构设计和技术融合,如何保持高效计算的同时实现强大的多模态理解能力?](#题目 1:Qwen3-VL 的技术创新为多模态 AI 的发展开辟了新的道路,合理的架构设计和技术融合,如何保持高效计算的同时实现强大的多模态理解能力?)
[题目 2:LoRA 微调技术?举例说明](#题目 2:LoRA 微调技术?举例说明)
[题目 3:AgentScope(字节跳动开源)核心架构、原理通俗讲解是什么,并给出实例?](#题目 3:AgentScope(字节跳动开源)核心架构、原理通俗讲解是什么,并给出实例?)
[题目 4: Agent Skill(智能体技能)的核心原理、架构,再对比 MCP 协议的区别?](#题目 4: Agent Skill(智能体技能)的核心原理、架构,再对比 MCP 协议的区别?)
[题目 5:多智能体系统的学习与进化机制](#题目 5:多智能体系统的学习与进化机制)
****一、中级算法工程师知识(原理题)
题目1:Transformer 核心架构的原理和工作流程
请通俗解释一下Transformer 核心架构及工作原理,并说明优势和缺陷?
考察点:
自注意力机制的基本原理理解;工作流程;核心概念
标准答案:
Transformer 核心架构是 "编码器 + 解码器",全程靠注意力机制实现语义理解与生成,无循环或卷积依赖。
**整体流程:**先将文字转为向量(词嵌入),注入位置信息(位置编码)解决无序问题;编码器堆叠 N 层,通过多头自注意力捕捉全词关联,结合残差连接和 LayerNorm 稳定训练,输出全文语义记忆;解码器同样堆叠 N 层,新增掩码自注意力屏蔽未来词,靠交叉注意力对齐编码器语义,逐词生成目标序列,最后经线性层 + Softmax 输出词概率。
**优势显著:**一是并行计算效率高,不像 RNN 顺序处理,所有词的注意力可同时计算,训练速度大幅提升;二是长依赖捕捉能力强,任意词间直接关联,无梯度衰减问题,适合长文本;三是适配性广,多视角注意力能学习语法、语义等多元关系,可用于翻译、生成、分类等多任务;四是训练稳定,残差连接 + LayerNorm 组合避免梯度消失和数值震荡。
**缺陷同样突出:**一是长序列成本高,注意力复杂度随长度呈平方级增长,显存占用和计算量剧增;二是缺乏归纳偏置,无局部性、时序性先验,需更多数据和算力训练;三是推理效率低,自回归解码需逐词生成,无法并行;四是外推性差,传统位置编码在推理长序列时,超出训练长度的位置信息失效;五是小数据场景表现一般,依赖大规模数据支撑才能发挥优势,数据不足时易过拟合。
核心模块的作用总结
|---------------|-----------------|-----------------------------|
| 模块名称 | 简称 | 核心作用(一句话总结) |
| 词嵌入 | Emb | 文字转数字向量,让模型可计算 |
| 位置编码 | PE | 注入顺序信息,解决 Transformer 无序问题 |
| 多头自注意力 | MHA | 全词关联,多视角学习词间语义关系 |
| 掩码自注意力 | Masked MHA | 生成时屏蔽未来词,保证顺序合法 |
| 交叉注意力 | Cross Attn | 解码回看编码,让生成内容对齐输入原文 |
| 残差连接 | Residual | 梯度直达,防止深层模型梯度消失 |
| LayerNorm | LN | 稳定特征数值,让训练不震荡、好收敛 |
| 前馈网络 | FFN | 单词特征非线性提纯,提升模型表达能力 |
| 线性 + Softmax | Linear+Softmax | 特征转词概率,输出最终预测词 |
题目 2:多头注意力机制的设计动机
为什么要使用多头注意力而不是单头注意力?多头注意力的优势体现在哪些方面?
考察点:多头注意力的设计动机;不同头的分工机制;特征子空间的理解
标准答案:
多头注意力的核心动机: 是让模型能够从不同的特征子空间捕捉输入序列的多元语义关系。单头注意力可能只能捕捉一种类型的依赖关系,而多头机制相当于为模型配备了多组 "认知透镜",不同头可以同时关注语法依赖、语义关联、位置交互等不同类型的关系(8)。这种设计使模型能够更全面、更细粒度地理解序列,提升整体性能。
**多头注意力的核心作用:**是给模型装多组 "不同的认知镜头"------ 单头只能用一套视角看句子,多头能同时从语法、语义、指代等多个维度理解词间关系,让特征更全面、更精准。
单头注意力的致命短板很明显:它只有一套 Q、K、V 映射,只能学习一种类型的依赖关系。比如处理 "小猫爬上树,它很高" 这句话,单头要么重点关注 "爬上" 和 "树" 的语法搭配,要么侧重 "它" 和 "树" 的指代关系,没法同时兼顾。就像一个人同时要当语法分析师、语义理解师、逻辑推理师,顾此失彼,不同类型的信息会互相干扰,最终学到的关联模式既肤浅又混乱。
**多头注意力的解决思路:**把特征维度拆分成多个独立 "子空间",每个子空间对应一个 "头",各自独立计算注意力。比如 8 个头就相当于 8 个专业分工的 "分析师":有的专门盯局部语法("爬上" 与 "树"),有的专注长距离语义("小猫" 与 "高"),有的负责指代关系("它" 与 "树"),还有的捕捉主题关联(全句围绕 "树" 展开)。每个头专注自己的分工,不会被其他类型的关系干扰,能学出更纯粹、更精细的关联模式。
最后,模型会把所有头的分析结果拼接起来,融合成一个 "多维度综合报告"。这个融合后的特征,既包含局部语法结构,又有长距离语义关联,还有逻辑指代关系,比单头的 "单一视角" 丰富得多。
**举例:**简单说,单头是 "一个人干所有活",能力有限还互相干扰;多头是 "专业团队分工协作",各司其职又汇总成果。这也是为什么多头注意力能让模型理解更复杂的句子:它能同时捕捉多元语义关系,避免单头的表达瓶颈,让特征更有层次、更全面,最终提升模型的理解和生成能力。
题目 3:位置编码的必要性和实现方式
为什么 Transformer 需要位置编码?原生 Transformer 使用的正弦位置编码和可学习位置编码各有什么优缺点?
考察点:位置编码的必要性;不同位置编码方式的特点;外推能力的理解
标准答案:
原理
**为什么需要位置编码?**自注意力是 "无位置感知" 的 ------ 就像把一句话的单词打乱,模型还能算出单词间关联,但分不清 "我吃苹果" 和 "苹果吃我" 的区别。位置编码就是给每个 Token 贴 "位置标签",注入顺序 / 空间信息,让模型知道谁在前、谁在后,这对语言(时序)和图像(空间)任务都至关重要(比如 Qwen3-VL 需要知道图像块的空间位置)。
正弦位置编码 vs 可学习位置编码
正弦编码:固定公式生成(用正余弦函数),优点是不占训练参数、支持长序列外推(比如训练时学 200 字,推理时能处理 1000 字);缺点是自适应差,复杂位置关系捕捉弱。
可学习编码:随机初始化后跟着数据训练,优点是能适配任务学习专属位置特征,捕捉复杂依赖;缺点是依赖训练数据,长序列外推差(没学过的长度容易出错)、多占参数。
举例
用正弦编码:训练一个翻译模型,输入 "我爱中国"(4 个词),推理时遇到 "我在美丽的中国旅游"(8 个词),模型能通过固定公式生成新位置编码,不会因长度超纲失效。
用可学习编码:训练一个短视频字幕生成模型,它能学到 "视频开头 3 秒的画面" 对应 "开头字幕" 的位置关联,但如果推理时遇到 10 分钟长视频(远超训练时的 1 分钟长度),位置编码就会 "没见过",导致字幕时序错乱。
Qwen3-VL 用的 Interleaved-MRoPE,就是在正弦编码基础上优化,兼顾外推性和自适应,既支持超长视频,又能精准对齐时空位置。
题目 4:LayerNorm 与 BatchNorm 的区别及选择原因
为什么 Transformer 选择 LayerNorm 而不是 BatchNorm?两者的核心区别是什么?
考察点:
LayerNorm 和 BatchNorm 的原理差异;Transformer 选择 LayerNorm 的原因;序列数据的特殊性理解
标准答案:
LayerNorm 和 BatchNorm 的核心区别在于归一化的维度不同。
**思路:**① 维度:LayerNorm 按 "样本维度" 归一化(同一序列内),BatchNorm 按 "批次维度" 归一化;② 优势:LayerNorm 不依赖批次大小(适配 Transformer 变长序列)、训练稳定(缓解梯度消失),Qwen3-VL 视觉编码器也沿用这一思路。
BatchNorm 像 "全班统一评分标准"------ 按整个班级(批次)的成绩统计均值、方差来归一化,依赖班级人数(批次大小),人少就不准,还不适合变长的句子 / 图像块。
举例:
LayerNorm 像 "个人专属评分标准"------ 按单个学生的各科成绩(同一序列的所有 Token)统计归一化,不管班级大小,哪怕是长短不一的句子、图像块都能适配。
Transformer 用 LayerNorm,核心是适配 "变长序列"(比如一句话 10 个字、另一句 100 字),且不依赖批次大小,训练更稳定;还能缓解梯度消失,让深层网络学进去。
Qwen3-VL 视觉编码器要处理不同分辨率的图像(切块后序列长度不一样),沿用 LayerNorm 刚好适配这种灵活场景,保证不管图像大小,每个图像块的特征都能稳定归一化,不影响后续融合效果。
题目 5:Transformer 的训练稳定性问题
为什么深层 Transformer 在训练时容易出现不稳定的问题?Pre-LN 和 Post-LN 架构有什么区别,为什么现代大模型倾向于使用 Pre-LN?
考察点:
Transformer 训练不稳定的原因;Pre-LN 和 Post-LN 的差异;梯度传播路径的理解
标准答案:
原理讲解
深层 Transformer 训练不稳定的原因:深层 Transformer(比如 24 层以上)就像 "多层放大器"------ 每一层的激活值(特征数据)会被反复放大,若没有有效约束,数值会越来越大(梯度爆炸)或越来越小(梯度消失)。加上自注意力的全局依赖会让 "误差传播" 更明显,深层网络的参数更新容易 "跑偏",导致训练崩溃(比如 loss 突然飙升、模型输出乱码)。
Pre-LN 和 Post-LN 的核心区别:两者的关键是 "归一化(LN)放在哪":
Post-LN(传统架构):先做注意力 + 前馈网络(放大数值),再归一化。好比 "先把声音放大,再调音量",容易出现 "放大过度" 导致数值溢出,深层更不稳定;
Pre-LN(现代架构):先归一化(把数值拉回合理范围),再做注意力 + 前馈网络。好比 "先调音量到合适水平,再放大",从源头约束数值波动,深层训练更稳。
现代大模型选 Pre-LN 的原因:一是训练稳定性拉满,能支撑 100 层以上的深层架构(比如 GPT-4、Qwen3-VL 的深层编码器);二是梯度传播更顺畅,缓解深层梯度消失;三是对学习率更鲁棒,不用反复调参,训练效率更高。
实例说明
比如训练一个 32 层的 Transformer 大模型(类似 Qwen3-VL 的 32B 版本):
用 Post-LN:训练到 10 层左右,激活值就可能涨到几千,导致梯度爆炸,loss 直接变成无穷大,训练被迫停止;
用 Pre-LN:每层先通过 LN 把激活值压缩到均值 0、方差 1 的范围,再进行特征变换,32 层训练全程 loss 平稳下降,最终模型收敛到更高精度。
再比如 Qwen3-VL 的视觉编码器(基于 VIT 深层架构):图像特征经过多层 Transformer 时,Pre-LN 能保证不同分辨率、不同场景的图像特征数值稳定,避免某类图像(比如高对比度、低亮度图)的特征 "淹没" 其他特征,让后续跨层融合(DeepStack)更可靠。
题目6:上下文驱动行为规划是什么?设计方法有哪些?举例说明
定义
基于上下文的行为规划,是指智能体在接收到输入后,不是直接生成结果,而是先综合历史对话、系统状态、已完成子任务与当前目标,构建一个状态丰富的上下文结构,并以此为基础规划下一步行动,包括是否调用外部工具、如何分解子任务、是否中断或回溯流程等操作。
上下文不仅包含语言内容,还应包括变量值、函数调用历史、模型响应状态、用户行为偏好等任务元信息,是智能体感知-认知-执行能力贯通的关键载体。
方法总结
结构化 Prompt 嵌套把历史任务状态、中间变量、环境参数、已执行工具及结果等上下文信息封装进 Prompt,以摘要、嵌入等形式整合,引导模型依托上下文完成链式推理与行为判断。
状态标签与条件提示在上下文内加入任务阶段、工具执行结果、用户意图等显式状态标签,让模型精准定位任务节点,匹配对应执行行为,提升规划准确性。
系统动态规划模板将完整任务拆解为多类状态节点,为每个节点定义可执行操作与目标状态,依托上下文引导模型判断流程走向,选择继续、分支、合并、终止或回溯。
多轮上下文拼接策略采用滑动窗口、关键信息摘要融合的方式,在模型 Token 长度限制内保留长期任务与对话核心信息,保障模型决策的连续性与长期关联性。
举例说明
适用:法律审查、合同审核、投资合规、敏感信息识别、内容安全。需要模型识别风险等级、敏感字段、缺失条款,并按风险等级执行不同动作。
标签设计
合规状态:合规 / 轻微风险 / 重大风险
审查阶段:条文抽取 / 风险比对 / 条款补全 / 报告生成
缺失条款:投资主体 / 资金用途 / 风控措施(枚举)
当前状态 合规状态: 重大风险 审查阶段: 风险比对 缺失条款: 风险处置措施
条件行为规则
合规状态=重大风险,必须高亮标注风险点,禁止给出"通过"结论
缺失条款非空时,优先提示补充条款,不进入最终报告
仅当合规状态=合规 且 无缺失条款,才可输出审查通过意见
题目7:详细描述智能体Agent的组成模块和运行机制,举例说明;
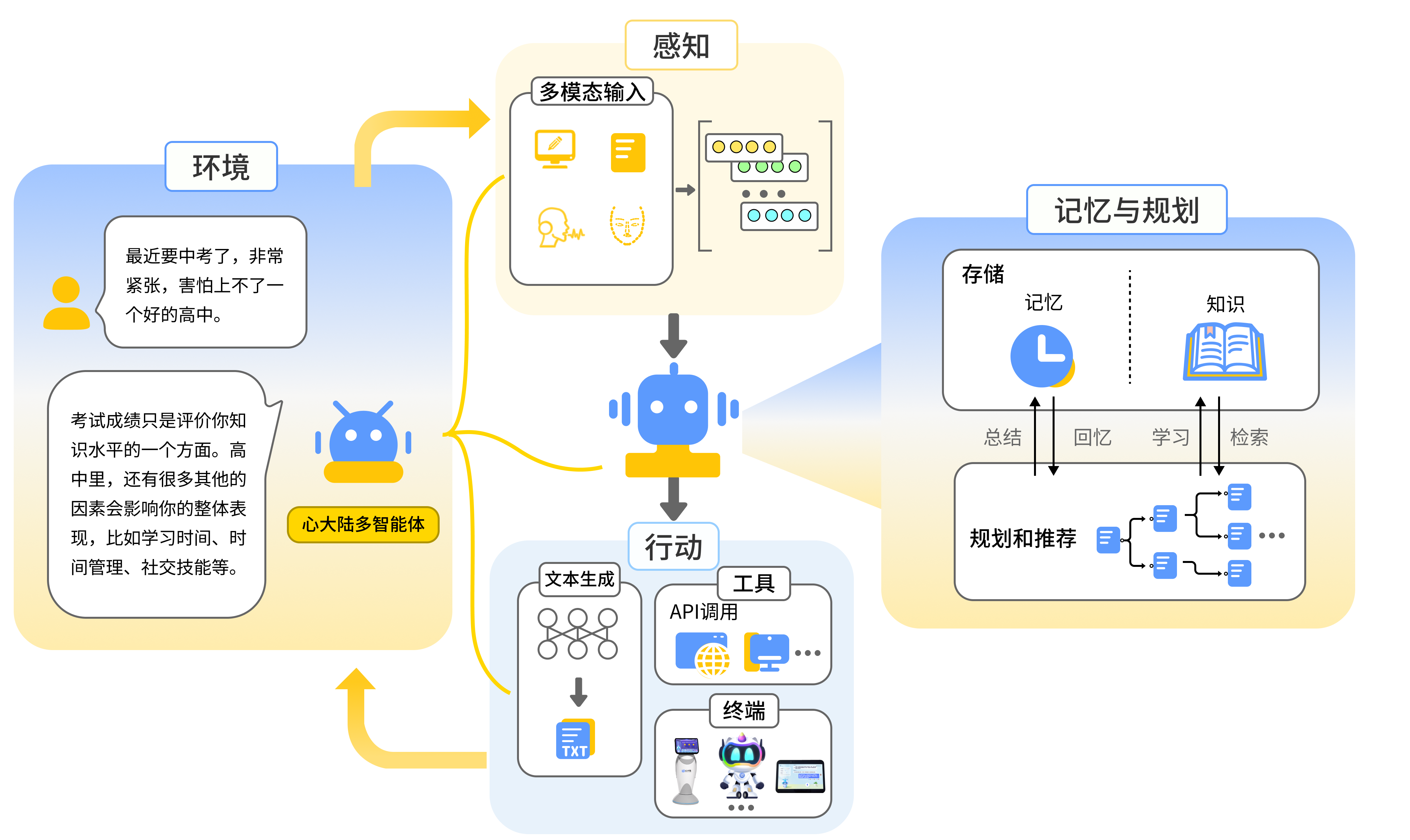
Agent 四大构成模块详解(功能 + 机制 + 实例)
- 感知模块
- 核心功能:Agent 的 "五官"------ 接收并解析外部信息(文本、图像、语音、系统数据等),转化为内部可处理的格式。
- 内部机制:多模态识别(如 OCR、语音转文字)→ 数据清洗(去噪、格式标准化)→ 信息提取(关键实体、意图识别)。
- 实例:售后 Agent 的感知模块接收用户 "故障照片 + 语音'无法开机'",先识别图像中的产品型号,语音转文字提取故障关键词,输出 "产品 A + 开机故障" 的结构化信息。
- 决策模块
- 核心功能:Agent 的 "大脑"------ 基于感知信息和记忆,规划任务步骤、选择行动策略(如调用工具、协同其他 Agent)。
- 内部机制:意图匹配(关联历史记忆)→ 任务拆解(复杂任务拆分子步骤)→ 策略选择(基于规则 / 强化学习选最优方案)。
- 实例:科研 Agent 的决策模块收到 "撰写论文" 需求,拆解为 "文献检索→数据整理→框架搭建→撰写",选择调用 "学术数据库工具" 和 "分析 Agent" 协同。
- 行动模块
- 核心功能:Agent 的 "手脚"------ 执行决策指令,包括工具调用、系统操作、信息输出等,实现与外部环境的交互。
- 内部机制:指令解析→ 工具适配(匹配对应技能 / API)→ 执行反馈(接收结果并回传决策模块)。
- 实例:财务 Agent 的行动模块接收 "生成发票" 指令,调用 ERP 系统 API 创建发货单,再调用财务工具生成发票,将 "发票编号" 反馈给决策模块。
- 记忆模块
- 核心功能:Agent 的 "知识库"------ 存储短期任务状态、长期经验 / 规则,支持记忆检索与更新。
- 内部机制:短期记忆(缓存当前任务数据)→ 长期记忆(存储行业规则、历史交互)→ 记忆优化(删除冗余、强化关键信息)。
- 实例:客服 Agent 的记忆模块短期缓存用户当前订单信息,长期存储 "退款规则",用户二次咨询时,快速召回历史对话和订单数据,无需重复询问。
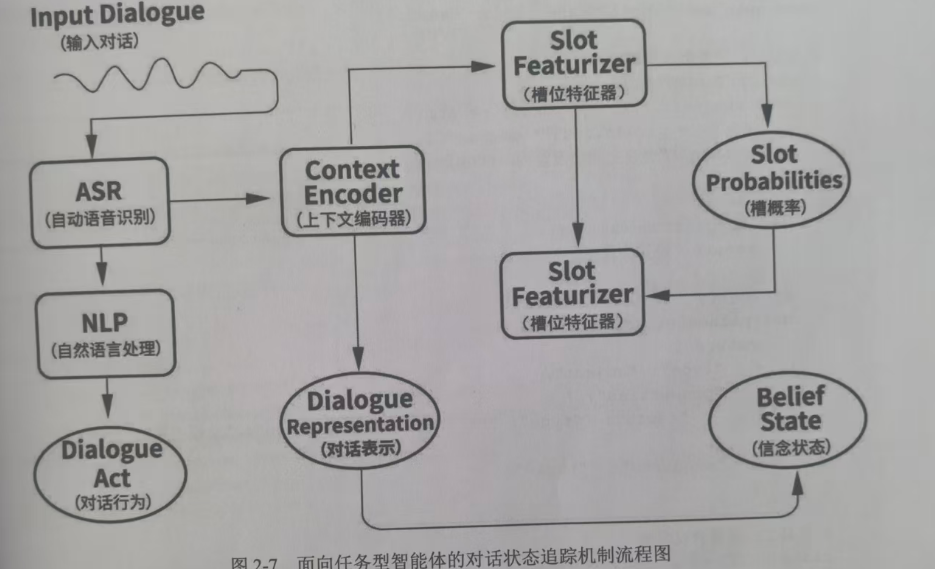
题目8:根据智能体对话状态机制流程图,给出具体部件描述和举例说明
一、总体描述
这个流程图描述的是一个能记住你之前说过什么、一步步理解你需求的智能对话系统。它的核心是:把你说的话转成机器能懂的信息,然后结合你之前的对话内容,持续更新它对你真实需求的判断,最后为下一步的响应做准备。
简单来说,它就像一个医院导诊员:
先听清你说的话(ASR)
理解你想干什么(NLP)
回忆你之前提过的要求(Context Encoder)
分析你这次说的话里关键信息的可能性(Slot Featurizer)
最后形成对你需求的完整判断(Belief State),然后给你准确的指引。
二、每个部件的作用
|---------------------------------|--------------------------------------------------------------------------------|
| 部件 | 通俗作用 |
| Input Dialogue(输入对话) | 你对着智能体说的原话,比如 "我想明天去医院挂个内科的号"。 |
| ASR(自动语音识别) | 把你说的声音转成文字,就像手机的语音转文字功能。 |
| NLP(自然语言处理) | 读懂文字的意思,识别出你的对话行为(Dialogue Act):比如是 "查询" 还是 "预约"。 |
| Context Encoder(上下文编码器) | 记忆大师,把你这次说的话和之前所有对话内容融合成一个 "对话表示",让智能体不会 "失忆"。 |
| Slot Featurizer(槽位特征器) | 专门抠细节的侦探,从对话里找出关键信息(槽位),比如 "时间(明天)"、"科室(内科)",并计算这些信息的概率。 |
| Slot Probabilities(槽概率) | 对抠出来的细节进行可信度打分,比如你说 "明儿",它判断 "明天" 这个时间的概率是 95%。 |
| Belief State(信念状态) | 智能体最终对你需求的完整理解,是它的 "内部结论",比如:用户想明天 (时间)去内科 (科室)挂号(行为)。 |
题目 9:主流智能体协作的框架和原理是什么?
考察点:
多智能体系统的基本概念;协作的价值和优势;系统复杂性理解
标准答案:
调研:
**谷歌:LangGraph(LangChain 生态)**原理:基于图结构(节点 + 边)实现流程驱动协作,强状态管理支持持久化与回溯,适配复杂决策链。举例:企业风控审批,将 "资料审核→风险评估→审批决策" 拆分为节点,状态流转中保存中间结果,支持驳回回溯重新评估。
独立框架(大厂生态适配):CrewAI原理:角色化团队协作,强制定义 "角色 - 任务 - 工具",模拟真实团队分工,轻量化快速搭建。举例:产品市场调研,配置 "行业研究员(查数据)+ 竞品分析师(对比优势)+ 文案策划(写报告)",各角色绑定专属工具,协同完成调研文档。
**阿里:Qwen-Agent(多模态适配)**原理:依托 Qwen3-VL 多模态能力,支持图文 / 视频输入的智能体协作,结合 DeepStack 跨层融合与超长上下文,适配复杂多模态任务。举例:长视频内容分析,"视觉识别智能体(提取画面特征)+ 时序分析智能体(梳理事件顺序)+ 文案生成智能体(写总结)" 协同,输出带时间戳的视频摘要。
题目 10:多智能体系统的协作模式
多智能体系统有哪些主要的协作模式?各有什么特点?
考察点:
不同协作模式的理解;架构设计选择;适用场景分析
标准答案:
多智能体系统主要有两种协作模式:
垂直架构(中央集权式):
有一个核心大脑 ------ 主 Agent(Manager)
负责接收任务、拆解目标、调度下属、整合结果
优点:架构清晰、可控性强、便于调试监控
缺点:高度依赖主 Agent,存在单点故障风险
水平架构(去中心化式):
所有 Agent 是平等的,无中央权威
通过协商、辩论或投票机制共同决策
优点:灵活性高、单个 Agent 失效不影响整体
缺点:通信与共识成本高、决策过程复杂
题目 11:任务分配机制
多智能体系统中任务分配的基本原则是什么?常用的任务分配算法有哪些?
考察点:
任务分配的基本原理;常用算法理解;分配策略设计
标准答案:
一、多智能体任务分配基本原则(核心是 "把活分给对的人")
效率优先:让任务完成总耗时 / 总成本最低(比如让跑得快的快递员送远单);
能力匹配:智能体能力要适配任务需求(比如让图像识别智能体处理图片,而非文本智能体);
负载均衡:不让单个智能体累垮、 others 闲置(比如不让一个快递员扛所有急单);
鲁棒性:某智能体故障时,能快速重新分配(比如快递员车坏了,急单转派给其他人);
全局最优:不纠结单个任务最优,追求整个系统整体效益最高(比如牺牲一个快递员的短距离高效,换全网无超时单)。
二、常用任务分配算法(通俗类比 + 举例)
贪心算法:"先到先得,就近分配"------ 每次给当前任务找最优匹配的智能体,不考虑后续。举例:外卖平台派单,新订单直接分给距离最近、当前无单的骑手,简单快,但可能导致远处骑手闲置。
匈牙利算法:"全局最优匹配"------ 适合任务和智能体数量相近的场景,找到总成本最低的分配方案。举例:3 个翻译智能体(擅长英 / 日 / 德)处理 3 个对应语言的文档翻译任务,算法精准匹配,避免 "日语智能体处理英语文档" 的资源浪费。
拍卖算法:"智能体竞价抢任务"------ 任务发布后,智能体根据自身能力报价(比如耗时、能耗),价低者得。举例:多机器人协同搬运,大箱子任务发布后,承重强、能耗低的机器人报价最低,成功接单。
强化学习算法:"边做边学,动态优化"------ 智能体根据历史分配效果调整策略,适配复杂动态场景。举例:多智能体巡检电网,算法通过学习 "某区域智能体处理故障更快",后续优先分配该区域任务,越用越高效。
市场机制算法:"用'虚拟货币'调节分配"------ 智能体完成任务获 "货币",兑换资源,激励能力强的多接单。举例:云端多模型推理任务分配,Qwen3-VL(擅长多模态)完成复杂图文任务获更多 "货币",可优先占用算力资源,提升整体处理质量。
题目 12:通信协议与信息交换
智能体之间如何进行通信?常用的通信协议有哪些?
考察点:
通信机制的理解;协议设计原理;信息交换方式
标准答案:
智能体之间的通信方式主要有:
自然语言通信:基于 LLM 的 Prompt 交互
结构化通信:使用 JSON 或 XML 格式明确定义任务与反馈内容
API 调用通信:通过函数签名交换数据
常用的通信协议包括:
合同网协议(CNP):主 Agent 发布任务,子 Agent 竞标,系统选择最优方案
黑板系统:所有 Agent 可读写同一共享知识库,实现历史任务记忆、数据缓存复用、上下文共享
题目 13:冲突消解机制
当多个智能体在目标、资源或结果上产生冲突时,系统如何解决?
考察点:
冲突类型的理解;消解机制设计;策略选择能力
标准答案:
**多智能体冲突解决核心:**是 "找平衡、定规则",常用 3 类思路:
- 规则优先:提前定优先级(比如 "紧急任务> 普通任务""高权限智能体优先");
- 协商妥协:智能体通过 "沟通" 调整目标,各让一步;
- 全局优化:系统总控重新分配资源 / 任务,追求整体最优。
举例:
- 规则优先:快递多智能体抢同一小区急单,系统按 "距离最近 + 当前负载最低" 规则分配,避免争抢;
- 协商妥协:两机器人同时需用充电仓,协商后 "低电量机器人先充,高电量机器人先执行短任务,后续轮换";
- 全局优化:Qwen3-VL 多模态协作中,视觉识别智能体和文本生成智能体同时需算力,系统优先分配给 "长视频分析" 核心任务,文本生成智能体暂用备用算力,保证整体效率。
题目 14:Saas方式调用大模型服务,先解释API遵循Restful格式,再举例调用Qwen3
RESTful 设计风格
- 基础概念
REST(Representational State Transfer,表述性状态转移) 是 Roy Fielding 在 2000 年博士论文中提出的软件架构风格 ,并非强制标准或协议,主要用于指导分布式系统、Web API、前后端分离接口的设计,目标是实现接口的简洁、通用、可扩展、无状态、易维护。
满足 REST 约束条件的 API,称为RESTful API,是当前 SaaS 服务后端接口、开放平台接口最主流的设计规范。
- REST 核心架构约束
这是判断接口是否为 RESTful 的关键标准,而非仅使用 HTTP 动词就叫 RESTful:
客户端 - 服务器分离:前端(客户端)专注用户交互与展示,后端(服务器)专注数据处理、业务逻辑、存储,前后端通过接口解耦,可独立迭代升级,适配 SaaS 多终端访问的特性。
无状态(Stateless) :服务器不存储任何客户端会话状态,每一次请求都是独立的,所有必要信息(身份凭证、参数、上下文)全部包含在本次请求中,服务器仅凭请求报文即可完成处理,便于集群扩容、负载均衡,契合 SaaS 高并发、弹性扩展需求。
可缓存:充分利用 HTTP 原生缓存机制(Cache-Control、ETag、Last-Modified 等),对静态资源、频繁访问的只读数据做缓存,减少服务器压力,提升 SaaS 服务响应速度。
统一接口:接口设计遵循一致的规则,包括资源标识、操作方式、返回格式、状态码,降低开发者学习与对接成本。
分层系统:系统可分层设计(网关层、应用层、数据层、缓存层等),客户端无需感知底层架构,网关可做限流、鉴权、路由,适配 SaaS 多租户、高安全要求。
按需代码(可选):服务器可向客户端返回可执行代码(如 JS 脚本)扩展功能,非强制约束。
- RESTful 核心设计规范
(1)资源为核心,用名词定义 URL
RESTful 以资源 为核心(资源即数据实体,如用户、订单、商品、文档),URL 只用于标识资源,禁止使用动词,统一用名词复数形式提升可读性。
错误示例(含动词):
/getUserList、/deleteOrder、/addProduct正确示例(纯名词):
/users、/orders、/products、/documents(2)用 HTTP 请求动词对应资源操作
依托 HTTP 原生请求方法,精准对应资源的增删改查(CRUD) 操作,避免在 URL 中体现操作行为:
HTTP 方法 标准含义 对应资源操作 SaaS 场景示例 GET 获取、查询 查询单个 / 多个资源 GET /users(查询所有用户)、GET /users/123(查询 ID=123 的用户)POST 创建、提交 新增单个资源 POST /users(新建一个用户)PUT 全量更新 替换整个资源的全部字段 PUT /users/123(全量更新 ID=123 的用户信息)PATCH 局部更新 仅修改资源部分字段 PATCH /users/123(仅修改用户手机号 / 昵称)DELETE 删除 删除指定资源 DELETE /users/123(删除 ID=123 的用户)(3)URL 层级与参数规范
- 层级关系:关联资源用斜杠
/体现层级,如用户的订单:/users/123/orders(用户 123 的所有订单)、/users/123/orders/456(用户 123 的 ID=456 的订单)核心需求
用户单次提问,模型一次性返回完整回答,无对话上下文,适用于简单问答、单次生成场景。
RESTful 调用示例
- 请求信息
HTTP 方法:POST
请求 URL :
https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation请求头:
plaintext
Content-Type: application/json Authorization: Bearer sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx(替换为你的API-Key)
- 请求体(JSON)
json
{ "model": "qwen3-8b-instruct", "input": { "messages": [ { "role": "user", "content": "请解释什么是RESTful设计风格,用3句话概括" } ] }, "parameters": { "temperature": 0.7, // 中等随机性,兼顾准确与灵活 "max_tokens": 512, // 限制最大生成长度 "stream": false // 非流式,一次性返回结果 } }
- 响应结果(200 OK,JSON 格式)
HTTP 状态码返回200 OK (符合 RESTful 成功响应规范),响应体包含请求 ID、模型输出、使用量等信息,核心回答在
output.choices[0].message.content中:json
题目15:说明本地部署 Qwen3 模型的完整流程,涵盖前置准备、核心部署、优化扩展三大模块,逻辑清晰且符合技术文档规范。
硬件环境校验
核心要求:Nvidia 显卡(显存≥10GB,推荐 RTX 3060 及以上;14B 模型需≥20GB,72B 模型需≥48GB 或多卡集群)
辅助配置:CPU≥8 核、内存≥16GB、存储空间≥50GB(8B 模型)/100GB(14B 模型)/300GB(72B 模型)
无 Nvidia 显卡可使用 CPU 部署(仅支持轻量测试,推理速度极慢)
软件环境配置
操作系统:Windows 10+/Linux(Ubuntu 20.04+/CentOS 7+)/macOS 12+
基础依赖:
Python 3.8-3.11(推荐 3.10 版本)
Nvidia CUDA 11.7+(仅 N 卡需要,含对应显卡驱动)
PyTorch 2.0+(需匹配 CUDA 版本,CPU 版无需 CUDA)
二、核心部署阶段
模型文件获取
渠道:通过 ModelScope、Hugging Face 官方仓库下载对应版本(qwen3-8b-instruct/qwen3-14b-instruct/qwen3-72b-instruct)
内容:确保下载完整包(含权重文件 (.bin/.safetensors)、配置文件 (.json)、词表文件等)
存储:解压至指定路径(建议英文路径,无特殊字符)
依赖库安装
打开终端 / 命令行,执行统一依赖安装命令:
|-----------------------------------------------------------------------------|
| pip install torch transformers accelerate sentencepiece protobuf tokenizers |可选依赖(量化 / UI 所需):bitsandbytes(量化)、gradio/streamlit(网页 UI)、auto-gptq(GPTQ 量化)
模型加载与运行
编写 / 修改运行脚本(核心逻辑):
导入依赖库(transformers、torch 等)
配置模型路径(本地解压后的文件夹路径)
加载模型与 Tokenizer(指定 device_map="auto" 自动分配显卡 / CPU 资源)
定义对话输入与生成参数(temperature、max_tokens 等)
执行脚本:python run_qwen3.py(脚本名可自定义)
验证:脚本执行后输入提问,模型返回本地推理结果即部署成功
三、优化与扩展阶段
量化优化(显存不足时)
4bit/8bit 量化:通过 bitsandbytes 库在加载模型时启用,显存占用可降低 50%-75%
命令示例:model = AutoModelForCausalLM.from_pretrained(model_path, load_in_4bit=True)
界面部署(可选)
轻量网页 UI:使用 Gradio/Streamlit 快速搭建可视化聊天界面
成熟方案:部署 Open WebUI、ChatTUI 等开源项目,支持多轮对话、历史记录管理
性能调优(可选)
启用 FP16/FP8 精度:torch_dtype=torch.float16(需显卡支持)
关闭梯度计算:torch.no_grad()减少内存占用
调整 batch_size:根据显存大小合理设置,避免溢出
四、关键注意事项
模型路径需准确,避免中文或特殊字符导致加载失败
依赖库版本需匹配,避免因版本冲突引发报错
首次运行加载模型耗时较长(需读取大文件),后续推理速度显著提升
量化会牺牲少量精度,优先保证显存充足再考虑量化
运行中若出现显存溢出,可降低模型版本、启用量化或减少 max_tokens 参数
题目16:大模型的函数调用,请对比Function Call和MCP?
一、Function Call(函数调用)
Function Call 是大模型原生的工具调用能力 ,可通俗理解为专业助理查固定接口。模型不直接计算、查询实时数据,而是识别用户需求后,按预设格式输出调用指令,对接外部函数、API、数据库,拿到结果后整理成自然语言回复。
核心特点
轻量精准:依赖开发者预先定义函数规范(名称、参数、用途),模型只做匹配和参数填充,不自主创造工具,调用逻辑可控,误差低。
解决模型固有缺陷:弥补大模型实时数据滞后、精确计算易出错、无法操作外部系统的问题,专注信息整合。
单向执行:单次需求对应一次或串行多次调用,完成即终止,无长期状态留存。
通俗举例
用户问 "北京明天天气 + 12.34×56.78 精确结果",模型不会瞎编:先判断需调用天气 API 和数学计算函数,输出规范指令,系统执行后返回数据,模型再组织成通顺回答。还可用于查快递、查股价、创建日程,都是固定工具的标准化调用。
二、MCP(多角色协作 / 多智能体协同)
MCP 是多智能体协同架构 ,不是单一调用工具,而是多个专用大模型 / 智能体分工配合,类比项目组跨岗位协作完成复杂任务,每个智能体有专属技能,通过通信交互、迭代优化,共同解决单模型难以完成的复杂流程化任务。
核心特点
分工协作:拆分复杂任务,如规划师定流程、分析师查数据、程序员写代码、评审员验错,各司其职。
有状态、可迭代:保留对话上下文和任务进度,多轮沟通修正,支持循环优化,可处理长流程、多步骤任务。
能力泛化:不局限于预设函数,可自主拆解任务、分配工作,处理模糊、开放的复杂需求,灵活性远高于 Function Call。
复杂度更高:需要调度机制、通信协议、冲突解决逻辑,资源消耗和部署成本高于单一函数调用。
通俗举例
用户要求 "写一份电商活动营销方案并做数据预估"。MCP 架构下:规划智能体拆解任务,数据智能体调用接口调取行业数据,文案智能体撰写方案,测算智能体做投入产出计算,质检智能体核查逻辑漏洞,最终汇总成完整方案,全程多角色接力,远超单模型函数调用的能力边界。
三、核心差异总结
Function Call 是单点工具调用 ,解决 "模型做不到的精准 / 实时小事",轻量可控,适合查询、计算、标准化操作;MCP 是系统级协同,解决 "单模型搞不定的复杂大事",灵活可迭代,适合方案撰写、项目执行、复杂分析。
两者并非替代关系,而是层级互补:MCP 的智能体执行具体步骤时,往往会内嵌 Function Call 调用工具,共同构建大模型的外部能力延伸体系。
题目17:LoRA 注入机制优势是什么?举例实现
LoRA 注入机制(Low-Rank Adaptation)
轻量微调方案 ,核心是冻结预训练模型所有参数 ,仅在 Transformer 注意力层(Attention)的线性层(如 Q/K/V 投影层)插入低秩矩阵对(A 和 B) 实现参数高效微调。
低秩分解:将高维权重更新 ΔW 分解为低秩矩阵 A(d×r)和 B(r×k),r 为低秩维度(远小于原矩阵维度),参数量仅为全量微调的 0.1%~1%;
前向计算:输出 = 原模型输出 + BA× 输入(LoRA 分支仅做残差补充);
训练仅更新 A、B 矩阵,显存 / 算力需求骤降,可在消费级显卡运行;
推理时可将 BA 融合进原线性层权重,无额外推理开销,与原模型使用一致。✅ 核心优势:轻量、高效、低显存、易部署、多任务可插拔(不同任务 LoRA 权重单独保存)。
二、极简代码实现(PyTorch,适配 Transformer 注意力层)
核心实现 LoRA 注入、前向计算、权重融合,无复杂框架依赖,贴合底层逻辑,总代码约 50 行:
python
运行
import torch import torch.nn as nn import torch.nn.functional as F # 1. LoRA核心层:注入低秩矩阵对,适配任意线性层 class LoRALayer(nn.Module): def __init__(self, in_dim, out_dim, rank=8, alpha=16): super().__init__() # 低秩矩阵:A随机初始化,B全零初始化(训练起点更稳定) self.A = nn.Linear(in_dim, rank, bias=False) # d×r self.B = nn.Linear(rank, out_dim, bias=False) # r×k nn.init.normal_(self.A.weight, std=1/rank) nn.init.zeros_(self.B.weight) # 缩放因子:alpha/r,平衡LoRA分支贡献 self.scaling = alpha / rank def forward(self, x): # LoRA前向:x→A→B→缩放,输出残差 return self.B(F.linear(x, self.A.weight)) * self.scaling # 2. 带LoRA注入的注意力层(核心:冻结原层,仅训练LoRA) class LoRAAttention(nn.Module): def __init__(self, dim, rank=8): super().__init__() # 原注意力线性层(冻结,不参与训练) self.q_proj = nn.Linear(dim, dim) self.v_proj = nn.Linear(dim, dim) for param in [self.q_proj, self.v_proj]: param.requires_grad = False # 冻结核心参数 # 注入LoRA层(仅这部分参与训练) self.lora_q = LoRALayer(dim, dim, rank) self.lora_v = LoRALayer(dim, dim, rank) def forward(self, x): # 原输出 + LoRA残差(核心融合逻辑) q = self.q_proj(x) + self.lora_q(x) v = self.v_proj(x) + self.lora_v(x) return q, v # 输出给注意力计算 # 3. 训练+推理演示 if __name__ == "__main__": batch_size, seq_len, dim = 2, 10, 128 x = torch.randn(batch_size, seq_len, dim) # 模拟输入 model = LoRAAttention(dim=128, rank=8) # 初始化带LoRA的模型 # 训练阶段:仅优化LoRA参数(查看可训练参数量,极少量) optimizer = torch.optim.AdamW( [p for p in model.parameters() if p.requires_grad], lr=1e-4 ) q, v = model(x) loss = q.sum() + v.sum() loss.backward() optimizer.step() # 推理阶段:融合LoRA权重到原层,无额外开销 with torch.no_grad(): model.q_proj.weight += model.lora_q.B.weight @ model.lora_q.A.weight * model.lora_q.scaling model.v_proj.weight += model.lora_v.B.weight @ model.lora_v.A.weight * model.lora_v.scaling # 融合后可删除LoRA层,直接用原层推理,与原生模型一致 del model.lora_q, model.lora_v三、核心要点总结
全量微调是 "整体更新",LoRA 是 "局部注入 + 残差补充",仅训练低秩矩阵,算力需求降低 99% 以上;
LoRA 核心在注意力层注入(模型语义拟合的关键层),其他层无需注入,兼顾效果与效率;
代码中通过
requires_grad=False冻结原模型,保证预训练知识不被破坏,LoRA 仅学习任务专属特征;推理权重融合后,模型结构与原生模型完全一致,无额外延迟,适合工业部署。
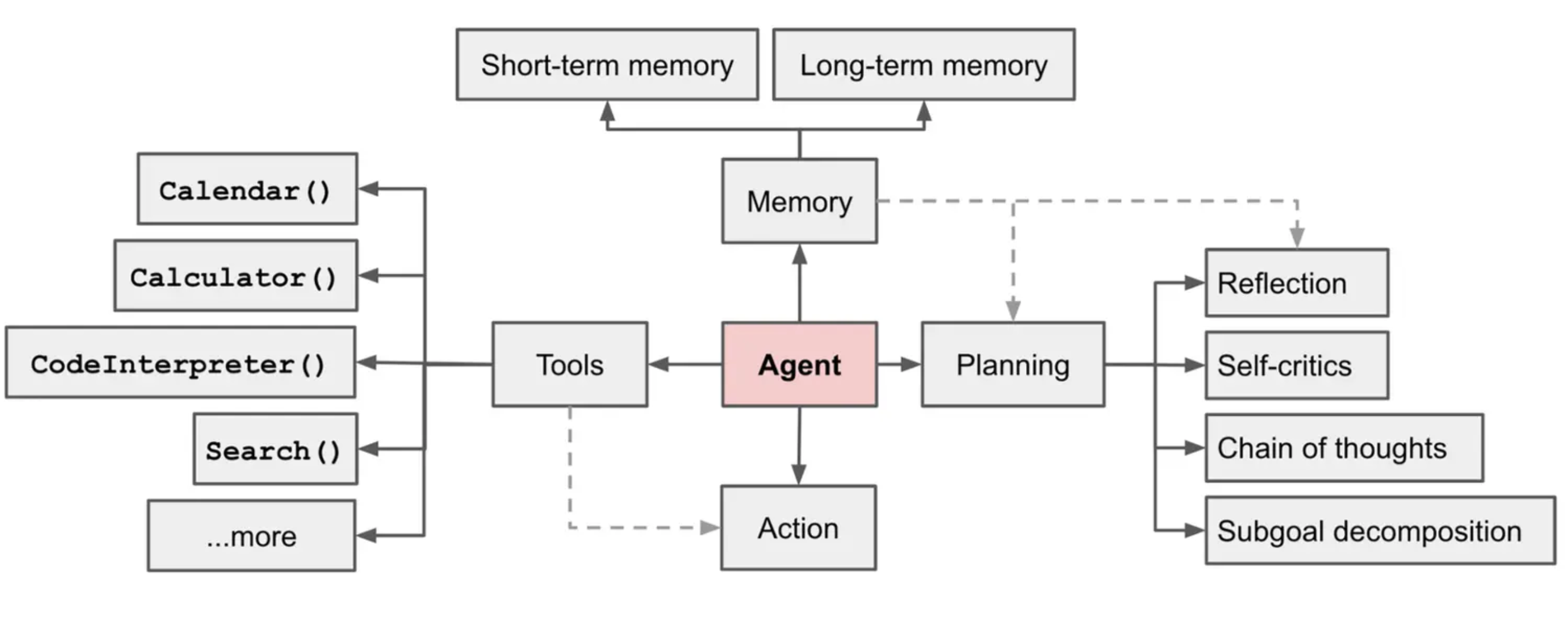
题目18:LangChain 和 LangGraph 区别?
1. LangChain
- 定位:大模型应用开发的通用基础框架,是连接大模型与外部资源、能力的「万能桥梁」;
- 初衷:解决纯大模型「无记忆、不会用工具、无私有数据」的基础痛点,将大模型应用开发的通用能力(模型调用、记忆、工具、RAG、简单链流程)抽象为可复用组件,让开发者快速搭建常规 LLM 应用(如知识库问答、单轮工具调用、简单对话助手);
- 核心逻辑:组件化组合,通过拼接模型、提示词、记忆、工具等基础组件,实现标准化的简单流程。
2. LangGraph
- 定位:基于 LangChain 组件的有状态、多步推理 / 多智能体协同专用框架,是 LangChain 生态中针对「复杂任务」的进阶解决方案;
- 初衷:解决 LangChain 原生在复杂流程编排、多智能体协作、状态持久化、灵活迭代修正上的不足,专门为「需要大模型自主思考、多步决策、多角色分工、循环迭代」的复杂场景设计;
- 核心逻辑:图结构编排,将复杂任务抽象为「节点(Node,执行单元)+ 边(Edge,流程走向)+ 状态(State,任务数据)」的有向图,精准控制任务流程的走向、迭代与协作。
二、核心能力与关键特征对比
|---------|---------------------------------------------------------|-----------------------------------------------------------|
| 对比维度 | LangChain(通用框架) | LangGraph(专用架构) |
| 核心形态 | 组件化体系 + 线性 / 简单链式流程 | 有向图(Graph)结构 + 节点 / 边 / 状态管理 |
| 状态管理 | 基础会话记忆(如 ConversationBufferMemory),无全局任务状态管理,仅记录简单上下文 | 原生全局有状态管理,支持任务全流程数据持久化、共享、更新,是核心能力之一 |
| 流程控制 | 以「链(Chain)」为核心,多为线性 / 串行流程,分支 / 循环需手动复杂开发,灵活性低 | 以「图」为核心,原生支持分支、循环、条件判断、并行执行,流程编排灵活,可精准定义「下一步该做什么」 |
| 多智能体协作 | 支持基础 Agents,但协作逻辑简单,多为单智能体选工具,多智能体分工 / 通信 / 迭代需大量自定义代码 | 专为多智能体协同设计,原生支持多智能体节点定义、角色分工、信息交互、任务调度,无需复杂自定义 |
| 迭代修正能力 | 弱,仅能通过简单逻辑实现单次校验,无原生的「失败重跑、循环优化」机制 | 强,原生支持「条件判断节点」,可基于任务结果动态触发「重新执行、分支切换、迭代优化」,贴合复杂任务的试错逻辑 |
| 依赖关系 | 独立框架,是 LangGraph 的基础底座 | 完全依赖 LangChain,可直接调用 LangChain 的所有组件(模型、工具、RAG、记忆),无重复开发 |三、总结
若开发常规、简单、单步的大模型应用,直接用 LangChain,组件化开发,快速高效;
若开发复杂、多步、多智能体协作的大模型应用,用 LangGraph,基于 LangChain 封装基础能力,通过图结构编排复杂流程,大幅降低自定义开发成本;
二者核心关系:LangChain 是大模型应用开发的「基础通用底座」,LangGraph 是 LangChain 生态中针对「复杂任务」的「专属进阶架构」。
题目19:基于 LangChain 的 Chains 机制,实现一个「天气查询 + 行程推荐 + 邮件发送」的有序链路
用户需求:查询目标城市次日天气 → 根据天气推荐户外 / 室内行程 → 自动生成行程邮件并输出(模拟发送),全程通过 Chains 串联 3 个工具模块,有序执行且传递中间结果。
Chains 机制的核心价值
- 流程标准化:将多步任务拆分为 "模块 + 链路",避免代码混乱,逻辑清晰;
- 复用性强:单个LLMChain可在不同链路中复用(如天气查询模块可用于其他行程推荐场景);
- 易于调试:verbose=True可查看每个模块的输入输出,快速定位问题;
- 无状态线性执行:适合 "一步接一步" 的有序任务,开发成本低,上手快。
from langchain_openai import ChatOpenAI
from langchain.chains import SequentialChain, LLMChain
from langchain.prompts import PromptTemplate
import os
1. 环境配置(替换为自己的OpenAI API密钥,或切换为智谱/文心等模型)
os.environ"OPENAI_API_KEY" = "your-api-key"
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0.3)
2. 定义3个核心模块(工具/逻辑),通过PromptTemplate标准化输入输出
模块1:天气查询(模拟工具调用,实际可替换为真实天气API的Function Call)
weather_prompt = PromptTemplate(
input_variables="city",
template="""你是天气查询助手,返回{city}次日的天气情况(温度、是否下雨、风力),格式简洁:
示例:北京 次日:25-32℃,晴,微风
输出:"""
)
weather_chain = LLMChain(llm=llm, prompt=weather_prompt, output_key="weather_info")
模块2:行程推荐(基于天气结果,推荐适配的1日行程)
itinerary_prompt = PromptTemplate(
input_variables="city", "weather_info",
template="""根据{city}的天气{weather_info},推荐1个适合年轻人的1日行程(含3个景点/活动),要求:
天气下雨则推荐室内活动(博物馆、商场、咖啡馆);
天气晴朗则推荐户外景点(公园、登山、网红打卡地);
行程需包含时间安排和简短亮点说明,格式清晰。
输出:"""
)
itinerary_chain = LLMChain(llm=llm, prompt=itinerary_prompt, output_key="itinerary")
模块3:邮件生成(将行程和天气整合为邮件正文)
email_prompt = PromptTemplate(
input_variables="weather_info", "itinerary",
template="""将以下天气和行程整理为一封友好的行程推荐邮件,收件人是朋友,格式如下:
主题:明日行程推荐
正文:
Hi~ 给你推荐明日的行程呀!
天气情况:{weather_info}
推荐行程:
{itinerary}
祝玩得开心!
输出完整邮件(含主题和正文):"""
)
email_chain = LLMChain(llm=llm, prompt=email_prompt, output_key="final_email")
3. 用SequentialChain串联3个模块,形成有序链路
核心逻辑:city输入 → 模块1(天气)→ 模块2(行程)→ 模块3(邮件)→ 输出最终结果
overall_chain = SequentialChain(
chains=weather_chain, itinerary_chain, email_chain,
input_variables="city", # 最终用户输入的变量
output_variables="weather_info", "itinerary", "final_email", # 可选:输出中间结果
verbose=True # 打印执行过程,方便调试
)
4. 执行链路(用户仅需输入目标城市)
result = overall_chain.run(city="成都")
5. 输出最终结果
print("\n" + "="*50 + " 最终邮件结果 " + "="*50)
print(result)
题目20:ReACT的工作原理是什么?
ReACT Agent 即 "推理与行动(Reasoning and Acting)智能体" ,核心在于将推理(Reasoning)和行动(Action)相结合,让模型以更智能、合理的方式完成复杂任务。其工作机制基于 "思考(Thought)- 行动(Action)- 观察(Observation)" 循环,具体如下:
思考阶段:当接收到用户任务指令,如 "制定一份本季度电子产品销售推广方案",ReACT Agent 首先利用内部大语言模型(LLM)对任务进行深入分析与推理。它会将复杂任务拆解为一系列更易处理的子任务,思考执行任务所需的信息和步骤。在该例子中,它可能会思考需要了解当前市场上电子产品的热门趋势、竞争对手的推广策略、本季度目标客户群体的偏好等信息。这种思考过程类似人类在解决问题前的思维梳理,通过语言模型生成推理步骤,清晰展示其 "思考" 轨迹,从而引导后续行动。
行动阶段:基于思考得出的结果,Agent 决定采取相应行动,调用外部工具或执行特定操作以获取所需信息或推进任务。这些工具涵盖搜索引擎、数据库、各类 API 接口等。若要获取市场趋势信息,Agent 可能执行 "Action: SearchEngine ('本季度电子产品市场热门趋势')",即调用搜索引擎工具,并将 "本季度电子产品市场热门趋势" 作为输入参数。通过这种方式,Agent 能够突破自身知识局限,从广泛的外部资源中获取最新、最准确的数据。
观察阶段:执行行动后,Agent 会获取工具返回的结果,即观察(Observation)。假设搜索引擎返回一系列关于电子产品市场趋势的新闻报道、研究报告等信息,这些信息便成为 Agent 的观察内容。Agent 对观察结果进行分析理解,判断是否已获取足够信息解决任务,或是否需要进一步行动。若发现获取的市场趋势信息中提及某类新兴电子产品备受关注,但缺乏竞争对手针对该产品的推广策略信息,Agent 会再次进入思考阶段,规划下一步行动。
循环迭代:Agent 不断重复 "思考 - 行动 - 观察" 循环,直至完成任务得出最终答案。如在制定销售推广方案时,可能需多次搜索不同信息、调用数据分析工具处理数据、参考企业内部销售数据库等,通过多轮循环逐步完善方案内容,最终生成完整且符合要求的本季度电子产品销售推广方案。这种迭代机制使 Agent 能应对复杂多变任务,根据每一步新信息动态调整策略,极大提升任务处理的灵活性与准确性。
**用户需求:**输入工作项目名称→获取项目数据(模拟接口)→ 生成结构化工作报告(含工作成果、进度、问题、下周计划)→ 输出 Markdown 格式,Agent 自主决策工具调用。from langchain_openai import ChatOpenAI
from langchain.agents import create_react_agent, AgentExecutor
from langchain_core.tools import Tool
from langchain_core.prompts import PromptTemplate
import os
from dotenv import load_dotenv
环境配置(干练化:仅保留必要依赖)
load_dotenv()
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0.1)
1. 工具1:获取项目数据(模拟数据库查询/API调用)
def get_project_data(project_name: str) -> str:
"""获取指定项目的核心数据(成果、进度、问题),生成报告的前置必要工具"""
模拟真实数据返回,实际可替换为数据库查询/API调用
mock_data = {
"电商APP迭代项目": "成果:完成支付模块优化,转化率提升15%;进度:80%(剩余UI适配);问题:部分安卓机型兼容异常;",
"客户管理系统开发": "成果:完成客户标签功能开发,支持3类标签配置;进度:60%(待测试);问题:数据同步延迟;"
}
return mock_data.get(project_name, "未查询到项目数据,请确认项目名称")
2. 工具2:生成结构化报告
def generate_report(data: str) -> str:
"""基于项目数据,生成结构化工作报告(含成果、进度、问题、下周计划)"""
prompt = f"""基于以下数据生成简洁工作报告:
{data}
格式要求:
标题:项目名称周工作报告
分4点:工作成果、项目进度、现存问题、下周计划
每点不超过3行,语言精炼"""
return llm.invoke(prompt).content
3. 工具3:Markdown格式标准化
def format_markdown(content: str) -> str:
"""将工作报告转为标准Markdown格式(标题加粗、列表格式化)"""
return f"### {content.replace('1.', '-').replace('2.', '-').replace('3.', '-').replace('4.', '-')}"
工具封装(description简洁,让Agent快速识别用途)
tools = [
Tool(name="GetProjectData", func=get_project_data,
description="获取项目核心数据,生成报告必须先调用此工具"),
Tool(name="GenerateReport", func=generate_report,
description="基于项目数据生成结构化报告,需在GetProjectData后调用"),
Tool(name="FormatMarkdown", func=format_markdown,
description="格式化报告为Markdown,需在GenerateReport后调用")
]
ReAct Prompt(干练化:去除冗余规则,聚焦核心逻辑)
react_prompt = PromptTemplate(
input_variables="input", "agent_scratchpad", "tools", "tool_names",
template="""你是工作报告助手,按以下规则工作:
推理:缺数据→调用GetProjectData,有数据→生成报告,报告生成→格式化;
调用格式:工具名称(参数),例如GetProjectData("电商APP迭代项目");
输出:最终Markdown格式报告或下一步行动。
用户需求:{input}
工具:{tools}
思考记录:{agent_scratchpad}
输出:"""
)
创建Agent并执行(干练化:合并初始化步骤)
agent = create_react_agent(llm=llm, tools=tools, prompt=react_prompt, verbose=False)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True, handle_parsing_errors="请按格式调用工具")
运行(用户仅需输入项目名称)
if name == "main":
user_input = "生成「电商APP迭代项目」的周工作报告"
result = agent_executor.run({"input": user_input})
print("\n" + "="*50 + " 最终工作报告 " + "="*50)
print(result)
题目21:LangChain vs LangGraph 核心对比表
LangChain 与 LangGraph 核心维度的对比表格,聚焦设计定位、架构思想、执行模式、状态管理、适用场景、开发方式等关键差异,严格对应两者官方定位与实际使用特点
LangChain vs LangGraph 核心对比表
|----------|-----------------------------------------------------------------------------------|--------------------------------------------------------------------------|
| 对比维度 | LangChain | LangGraph |
| 核心定位 | 大模型应用开发工具链 / 脚手架,提供可复用组件(LLM、Prompt、Memory、Tool、Retrieval、Chain),快速搭建单智能体 / 简单流程 | 基于状态图、有向循环图的智能体工作流编排框架,专注复杂、多步、可循环、可中断、可回溯的 Agent 执行控制 |
| 设计思想 | 面向链式调用(Linear Chain),以 "链" 为核心,流程多为单向、顺序执行 | 面向图结构执行(Graph/StateGraph),以 "节点 + 边 + 状态" 为核心,支持循环、分支、跳转、多轮迭代 |
| 执行模式 | 静态 / 半静态:预先定义好调用顺序,多为 A→B→C→D 单向流水线,循环能力弱、动态调整难 | 动态图执行:基于状态驱动,节点可根据运行结果动态跳转、循环、重试、中断、恢复,支持开放式任务 |
| 状态管理 | 以 Chain 为单位管理上下文,状态分散在 Memory、Callback、各组件内部,全局统一状态管理弱 | 内置中心化全局状态(State),所有节点共享、读写同一状态,状态可追踪、可持久化、可观测 |
| 循环与迭代 | 原生支持弱,需手动封装 while/for 或自定义循环链,难以实现稳定多轮工具调用、反思、自修正 | 原生强支持循环,通过图边条件实现工具重试、反思(Reflection)、自修正、多轮对话,是原生设计能力 |
| 流程控制能力 | 基础分支(RouterChain、SimpleSequentialChain),仅支持简单条件判断,复杂逻辑需大量自定义 | 完备的条件分支、循环、并行、中止、回退、暂停恢复,可表达任意复杂工作流,类似可编程状态机 |
| 可观测性与调试 | 依赖 LangSmith/Callback,流程执行链路可见,但内部状态流转、循环细节追踪能力一般 | 深度可观测,每一步节点执行、状态变化、边跳转都可追踪、打断、单步调试,适合复杂 Agent 排障 |
| 多智能体协作 | 基础协作能力,通过多 Chain 组合、消息传递实现,无统一调度与状态同步层 | 原生支持多智能体(Multi-Agent)图编排,可定义不同 Agent 为节点,统一状态、统一调度、结构化协同 |
| 典型适用场景 | 简单问答、RAG 检索问答、单轮工具调用、固定流程小应用、快速 POC | 复杂任务型智能体、多轮工具调用、代码生成 & 执行、研究型 Agent、反思式 Agent、工作流自动化、多 Agent 协作 |
| 代码抽象层级 | 高抽象,开箱即用,组件封装度高,少量代码即可跑通基础应用 | 中低抽象,更偏 "编程式编排",需要显式定义节点、边、状态结构,灵活度极高 |
| 与对方关系 | 可独立使用,也可作为节点组件被 LangGraph 调用 | 并非替代 LangChain,而是上层编排层,内部可无缝集成 LangChain 的 LLM/Tool/Prompt/Retrieval 组件 |
| 优势 | 开发速度极快、组件生态全、上手门槛低、文档完善、适合快速搭建原型 | 流程表达能力极强、状态可控、支持循环与自修正、生产级稳定性、适合复杂智能体系统 |
| 劣势 | 复杂动态流程(循环、多轮反思、条件跳转)表达困难,扩展性与可控性不足 | 上手比基础 LangChain 略高,需要理解图与状态概念,简单场景没必要用 |langChain 是大模型应用组件库与基础流水线框架,擅长快速搭建单向、固定流程的 RAG、简单 Agent 与小应用,核心是 "链"。
- LangGraph 是基于状态图的专业智能体工作流框架,擅长表达循环、分支、重试、自修正、多 Agent 协作等复杂行为,核心是 "图 + 全局状态"。
- 实际工程中通常是组合使用:用 LangChain 提供底层能力(LLM、工具、检索、记忆),用 LangGraph 做顶层流程编排与状态控制,构建生产级复杂智能体。
题目22:复杂任务的图式化编排大致可以将开发流程总结为以下几个步骤;举例说明
以医疗诊疗为例,患者就诊的检查,每一个检查就是一个独立子任务,检查结果存储在数据库,如果医生需要查询结果,到PACS数据库看影像报告,到LIS数据库看检查结果,如果结果需要复查重新迭代。具体如下:
具体步骤如下:
01任务拆解:将整体目标分解为若干可独立执行的子任务,明确每个子任务的输入与输出;
02节点定义:为每个子任务建立节点,封装任务逻辑,确保功能边界清晰;
03 依赖建模:通过有向边明确任务之间的顺序、条件与依赖关系,支持分支、循环与并行;
04 状态管理:为节点执行过程引入状态存储机制,保证上下文在不同环节之间传递与追踪;
05 异常处理:设计回溯与替换路径,确保任务失败时可以局部恢复而非重启整体流程;
06 集成外部工具:将数据库、检索模块或计算服务作为节点融入流程,提升系统能力;
07 执行与监控:通过任务图运行整体流程,记录节点输入、输出及状态,便于溯源与优化;
08 迭代优化:根据运行反馈调整任务划分与依赖关系,持续提升复杂任务执行的稳定性与08效率;
二、高级算法工程师知识(实战题)
****题目 1:****Qwen3-VL 的技术创新为多模态 AI 的发展开辟了新的道路,合理的架构设计和技术融合,如何保持高效计算的同时实现强大的多模态理解能力?
考察点:
原理理解
标准答案:
Vision Transformer(VIT)和 Swin Transformer 在图像领域的核心技术原理,并深入探讨了 Qwen3-VL 模型如何创新性地融合这两种架构的优势。研究表明,VIT 通过将图像划分为固定大小的 Patch 并应用全局自注意力机制,实现了对图像全局信息的高效建模,在 ImageNet 等基准测试中取得了优异成绩,但其 O (N²) 的计算复杂度限制了在高分辨率图像和实时应用中的使用。
Swin Transformer
通过引入分层架构和 Shifted Window Attention 机制,成功将计算复杂度降至线性水平,同时保持了优异的性能表现,在图像分类、目标检测、语义分割等任务上都达到了 SOTA 水平。其分层设计和高效的注意力机制为后续的视觉 Transformer 发展奠定了重要基础。
Qwen3-VL 作为新一代多模态大模型,通过创新性的技术融合实现了多项突破。
首先,通过DeepStack 跨层融合机制,Qwen3-VL 成功将多级 ViT 特征注入到 LLM 的多个中间层,既保留了底层的视觉细节又强化了高层的语义理解,实现了视觉 - 语言信息的深度融合。其次,Interleaved-MRoPE 位置编码解决了传统 MRoPE 的频谱不平衡问题,显著提升了长视频理解能力。第三,文本时间戳对齐机制提供了更精确的时间定位,使模型能够实现语言描述与视频帧的毫秒级同步。
在性能表现方面
Qwen3-VL 展现出了全面的技术领先性。在 MMMU 基准测试中,Qwen3-VL-235B-A22B 达到 78.7 分,超越了 GPT-4o 和 Claude Sonnet 3.7,而 8B 版本以仅为 GPT-4o 1/50 的参数量达到其 90% 以上的能力水平。在视觉感知、多模态推理、长视频理解等各个维度,Qwen3-VL 都展现出了与闭源先进模型相媲美的性能,同时作为开源模型提供了更高的可定制性和部署灵活性。
展望未来,Qwen3-VL 的技术创新为多模态 AI 的发展开辟了新的道路。其成功证明了通过合理的架构设计和技术融合,能够在保持高效计算的同时实现强大的多模态理解能力。随着硬件技术的进步和算法的不断优化,我们有理由相信,以 Qwen3-VL 为代表的新一代多模态模型将在更多领域发挥重要作用,推动人工智能技术向更高水平发展。
|--------------------------|-----------------------------------------|-----------------------------------------|
| 核心技术 | 一句话特点总结 | 核心价值 |
| VIT(Vision Transformer) | 图像切块转序列,全局自注意力建模,打破 CNN 局部局限 | 高效捕获图像全局信息,为 Qwen3-VL 视觉编码器奠定基础 |
| Swin Transformer | 窗口注意力 + 分层架构,线性算力 + 多尺度特征,解决 VIT 算力浪费问题 | 适配高分辨率图像 / 密集预测任务,启发 Qwen3-VL 分层特征融合思路 |
| 三模块架构(视觉编码器 + 融合器 + LLM) | 分工明确的 "视觉 - 语言协作体系",兼顾感知与理解 | 原生支持文本、图像、视频混合输入,适配多模态场景 |
| DeepStack 跨层融合 | 视觉特征(VIT 多层)跨层注入 LLM,细节与语义 "双在线" | 复杂图像 / 视频理解准确率提升,比如精准识别模糊物体、复杂场景 |
| Interleaved-MRoPE | 时间、空间、高度编码均匀分布,频谱平衡无偏向 | 长视频理解能力升级,同时不牺牲图像空间定位精度(继承 VIT/Swin 优势) |
| 文本时间戳对齐 | 显式文本标记视频时间,替代复杂编码,简单直接 | 视频与语言描述毫秒级同步,长视频事件定位准确率达 99.5% |
| 256K 超长上下文(可扩 1M) | 超大容量记忆,支持长文档 / 长视频全流程理解 | 处理数百页书籍、数小时视频,无信息丢失 |
| Dense/MoE 双架构选择 | 小模型高效、大模型强能,按需匹配场景 | 边缘设备(2B/4B)到云端旗舰(235B)全覆盖,性价比拉满 |
| 自适应稀疏采样(视频) | 智能筛选关键视频帧,不丢重点且省资源 | 长视频处理效率提升,兼顾速度与召回率 |
| 平方根归一化 Token 损失 | 平衡文本与多模态数据训练权重,避免 "偏科" | 多任务性能均衡,视觉推理、语言生成两不误 |
题目 2:LoRA 微调技术?举例说明
考察点:
LoRA大模型微调技术
标准答案:
- 核心原理:给 Agent "加装专属技能插件"
核心原理:Agent 的 "轻量技能植入术"------ 不重训大模型全部参数,仅在 Transformer 注意力层插入低秩矩阵(ΔW=B・A),通过训练这少量参数(仅全量微调的 1%-10%),让 Agent 快速学会专属技能,且不丢失原有通用能力,训练成本大幅降低。
技术:① QLoRA(量化版):4 位精度量化基座模型,24GB 显卡即可微调 130 亿参数模型,显存占用减 75%;② LoRA+:为低秩矩阵 A/B 设差异化学习率,训练收敛快 30%;③ AdaLoRA:动态为不同层分配秩,相同参数量下性能显著提升;④ DoRA:分解权重为大小和方向分量,效果更贴近全量微调。
实例:用 QLoRA 在单张 RTX 4090 上,8 小时即可让通用 Agent 学会 "医疗病历解析" 技能,仅需训练 500 万参数,部署时仅需分发几 MB 的适配器文件,不占用额外存储空间,且可随时叠加 "用药推荐" 新技能插件。
LoRA(Low-Rank Adaptation)是大模型微调的 "轻量神器"------ 不用给整个大模型(比如 Qwen、GPT)重训所有参数,只需在模型关键层(如 Transformer 的注意力层)插入一个 "小插件"(低秩矩阵),仅训练这个插件的少量参数,就能让模型快速学会专属技能,同时不丢原有能力。
通俗说:大模型像一部智能手机,原有功能(通用能力)已经很全,LoRA 就像装一个 "专属 APP"(比如 "电商售后插件"),不用换手机(重训模型),只需装 APP(训练插件),就能让手机新增专属功能,还不占太多内存(参数量仅为全量微调的 1%-10%)。
- Agent 场景实例:给通用 Agent 快速定制 "电商售后技能"
背景:通用 Agent 已经懂自然对话,但不会处理电商售后的具体流程(查订单、算退款、开工单),全量微调要训几十亿参数,耗时又耗力;
LoRA 微调操作:
从通用 Agent(如基于 Qwen-7B)中,挑选注意力层插入 LoRA 插件(仅新增约 500 万参数);
用电商售后数据集(订单查询记录、退款案例、工单模板)训练这个插件,不用动原模型的几十亿参数;
训练完成后,插件和原模型结合,通用 Agent 就变成了 "电商售后专属 Agent";
效果:
训练成本:仅需 1 块 GPU,8 小时完成(全量微调要 8 块 GPU、3 天);
技能表现:能精准识别 "查订单 123""退订单 456" 等需求,调用售后工具完成操作,原有对话能力不受影响;
灵活切换:想让 Agent 新增 "物流查询" 技能,只需再训一个 LoRA 插件,按需加载,不冲突。
核心优势:让 Agent 快速 "上岗" 特定岗位,低成本、高效率,还能灵活叠加多个技能,特别适合中小企业定制行业 Agent。
题目 3:AgentScope(字节跳动开源)核心架构、原理通俗讲解是什么,并给出实例?
考察点:
原理和架构
标准答案:
一、核心架构(五层 "乐高积木" 设计)
AgentScope 像企业级 "智能体协作工厂",五层架构层层递进、可自由组合:
智能体层:核心执行者,有聊天、工具调用等现成模板,可自定义角色(如售后、数据分析),自带记忆和决策能力;
能力抽象层:智能体的 "技能库",统一管理工具(API、数据库),支持线性 / 分支式任务编排;
数据存储层:"记忆大脑",短期存临时任务状态,长期对接知识库,支持记忆召回;
工程化支撑层:"保障网",负责监控、日志、故障重试,确保系统稳定;
应用层:业务场景入口,低代码配置即可落地(如客服、运维)。
二、核心原理
显式通信:智能体通过 "中枢" 传递消息,而非直接对话,像 "公司 OA 沟通",信息可追溯;
模型无关:同一协作流程能无缝切换 GPT、通义千问等模型,不用改代码;
实时干预:任务执行中可随时暂停调整,比如智能体出错时,人工修正后继续;
故障隔离:单智能体故障不影响整体,沙箱环境避免工具调用风险。
三、实例说明
智能客服场景:配置 "接待智能体"(聊需求)、"知识库智能体"(查答案)、"工单智能体"(派售后),用户咨询后,接待智能体转派任务,全程可监控,答案有误可实时修正;
物流优化场景:华东区路径规划、实时路况预测、成本优化三个智能体并行协作,通过分布式调度快速给出最优路线,效率提升 3 倍;
工业运维场景:设备端边缘智能体采集数据,传给云端诊断智能体,分析后触发工单智能体创建维修单,分布式架构确保单设备离线不影响整体。
题目 4: Agent Skill(智能体技能)的核心原理、架构,再对比 MCP 协议的区别?
考察点:
原理理解
标准答案:
**1. 核心原理:**智能体的 "专属技能包"
Agent Skill 是 Agent 能完成特定任务的 "本事",核心是 **"标准化封装 + 可插拔调用"**------ 把工具(API、数据库、脚本)、执行逻辑(比如 "先查数据再计算")、输入输出规则打包成 "技能模块",智能体像用 APP 一样一键调用,不用重复写底层代码。
底层遵循 ReAct 范式:先 "思考"(判断该用哪个技能),再 "行动"(调用技能执行),最后 "反馈"(接收技能结果并决策下一步),循环迭代完成任务。
2. 架构组成(三层 "技能底座")
- 技能定义层:明确技能的 "功能说明书"------ 比如 "查询天气" 技能,定义输入(城市名)、输出(温度 / 降雨概率)、调用权限(所有智能体可调用);
- 技能封装层:将原始工具标准化 ------ 比如把第三方天气 API 封装成 Agent 能识别的格式,处理参数校验(避免输错城市名)和结果解析(把 API 返回的 JSON 转成自然语言);
- 技能调度层:对接智能体决策逻辑 ------ 智能体通过钩子(Hook)机制触发技能,支持同步 / 异步调用,还能监控技能执行状态(成功 / 失败 / 超时)。
二、Agent Skill 与 MCP 协议的核心区别
|-------|-----------------------------|--------------------------------|
| 对比维度 | Agent Skill(智能体技能) | MCP 协议(通信协议) |
| 核心定位 | 智能体的 "能力模块"(比如 "查数据""写报告") | 智能体 / 工具间的 "通信语言"(比如 "数据已就绪") |
| 作用范围 | 单个智能体的 "内功",解决 "能做什么" | 多个组件的 "外功",解决 "怎么沟通" |
| 核心功能 | 封装工具逻辑,提供可调用的具体能力 | 定义消息格式,确保交互兼容、数据传输顺畅 |
| 通俗类比 | 厨师的 "炒菜技能"(会炒川菜、粤菜) | 厨师间的 "沟通话术"("食材切好了""可以下锅了") |
三、实例说明
- Agent Skill 的应用:电商售后智能体
- 给售后智能体配置 3 个核心技能:
① "订单查询技能"(封装订单系统 API,输入订单号→输出订单状态);
② "退款计算技能"(封装退款规则脚本,输入订单金额 / 退货原因→输出退款金额);
③ "工单创建技能"(封装售后工单工具,输入问题描述→自动生成维修工单);
- 执行流程:用户咨询 "订单 123 为何没退款",智能体先调用 "订单查询技能" 确认状态,再用 "退款计算技能" 核算金额,最后通过 "工单创建技能" 发起退款申请,全程无需人工写代码调用工具。
题目 5:多智能体系统的学习与进化机制
如何设计智能体的学习机制,使系统能够通过交互和经验不断改进协作策略?
考察点:
学习机制设计原理
协作策略优化方法
系统进化能力
标准答案:
设计智能体的学习与进化机制需要考虑以下几个方面:
1. 个体学习机制:
强化学习:智能体通过与环境交互获得奖励,学习最优策略
状态:智能体的局部观测和内部状态
动作:可执行的协作动作(如任务请求、资源共享)
奖励:协作成功的收益或失败的惩罚
算法选择:Q-Learning、SARSA、深度 Q 网络(DQN)等
模仿学习:智能体观察其他成功智能体的行为,学习其策略
行为克隆:直接学习成功智能体的动作分布
逆强化学习:从示范中推断奖励函数
贝叶斯学习:智能体维护对环境和其他智能体的信念分布
先验知识:系统初始配置和领域知识
观测更新:根据交互经验更新信念
决策制定:基于后验信念做出最优决策
2. 群体学习机制:
社会学习:智能体通过观察群体行为学习最佳实践
从众效应:跟随大多数智能体的选择
专家学习:向表现优秀的智能体学习
网络传播:通过社交网络传播成功经验
演化博弈论:模拟生物进化过程,适者生存
策略变异:随机改变策略的某些参数
策略交叉:结合多个成功策略的优点
选择压力:表现差的策略逐渐被淘汰
分布式学习:多个智能体协同学习,共享知识
参数服务器:集中存储和更新模型参数
联邦学习:在不共享数据的情况下协同训练模型
知识图谱:构建共享的领域知识表示
3. 协作策略的表示与优化:
策略表示方法:
规则集:使用 if-then 规则表示协作策略
神经网络:使用深度学习模型表示复杂策略
图结构:使用贝叶斯网络或马尔可夫网络表示依赖关系
状态机:使用有限状态机表示状态转移
优化目标设计:
全局优化:最大化系统整体性能
帕累托优化:在不损害其他智能体的情况下优化个体性能
公平性约束:确保所有智能体获得合理收益
稳定性要求:策略变化不能过于剧烈
4. 学习环境的设计:
模拟环境:使用仿真平台测试和优化策略
环境建模:准确模拟真实环境的动态特性
场景生成:生成多样化的测试场景
性能评估:提供全面的评估指标
在线学习:在真实环境中进行学习
探索与利用平衡:在学习新策略和利用已知策略间平衡
安全约束:确保学习过程不会损害系统正常运行
渐进式改进:逐步优化策略,避免剧烈变化
5. 知识共享与迁移:
经验回放:智能体将成功的协作经验存储在回放缓冲区中
知识迁移:将一个任务中学到的策略应用到相似任务
元学习:学习如何快速适应新任务的元策略
社会知识图谱:构建和维护智能体间的共享知识
通过以上机制的综合设计,多智能体系统能够实现:
从经验中学习和改进协作策略
适应环境变化和新的任务类型
发现更优的协作模式和分工方式
提高整体系统的性能和效率
实现可持续的进化和发展