🌟🌟 欢迎来到我的技术小筑,一个专为技术探索者打造的交流空间。在这里,我们不仅分享代码的智慧,还探讨技术的深度与广度。无论您是资深开发者还是技术新手,这里都有一片属于您的天空。让我们在知识的海洋中一起航行,共同成长,探索技术的无限可能。
🚀 探索专栏:学步_技术的首页 ------ 持续学习,不断进步,让学习成为我们共同的习惯,让总结成为我们前进的动力。
🔍 技术导航:
- 人工智能:深入探讨人工智能领域核心技术。
- 自动驾驶:分享自动驾驶领域核心技术和实战经验。
- 环境配置:分享Linux环境下相关技术领域环境配置所遇到的问题解决经验。
- 图像生成:分享图像生成领域核心技术和实战经验。
- 虚拟现实技术:分享虚拟现实技术领域核心技术和实战经验。
🌈 非常期待在这个数字世界里与您相遇,一起学习、探讨、成长。不要忘了订阅本专栏,让我们的技术之旅不再孤单!
💖💖💖 ✨✨ 欢迎关注和订阅,一起开启技术探索之旅! ✨✨
文章目录
- [1. 背景介绍](#1. 背景介绍)
- [1 引言](#1 引言)
-
- [Audio-Visual 模态组合](#Audio-Visual 模态组合)
- [Text-Visual 模态组合](#Text-Visual 模态组合)
- [Touch-Visual 模态组合](#Touch-Visual 模态组合)
- [Depth-Visual 模态组合](#Depth-Visual 模态组合)
- 多模态发展趋势分析
- [2 视听多模态(Audio-Visual)](#2 视听多模态(Audio-Visual))
-
- [2.1 声音定位(Sound Localization)](#2.1 声音定位(Sound Localization))
- [2.2 声音分离(Sound Separation)](#2.2 声音分离(Sound Separation))
- [2.3 声音空间化(Sound Spatialization)](#2.3 声音空间化(Sound Spatialization))
- [2.4 视听识别(Audio-Visual Recognition)](#2.4 视听识别(Audio-Visual Recognition))
- [2.5 视听生成(Audio-Visual Generation)](#2.5 视听生成(Audio-Visual Generation))
- [2.6 视频摘要与精彩片段检测(Video Summarization and Highlight Detection)](#2.6 视频摘要与精彩片段检测(Video Summarization and Highlight Detection))
- [3 文本-视觉(Text-Visual)](#3 文本-视觉(Text-Visual))
-
- [3.1 视觉描述生成(Visual Description Generation)](#3.1 视觉描述生成(Visual Description Generation))
- [3.2 文本到视觉生成(Text to Visual Generation)](#3.2 文本到视觉生成(Text to Visual Generation))
- [3.3 文本-视觉检索(Text-Visual Retrieval)](#3.3 文本-视觉检索(Text-Visual Retrieval))
- [3.4 视觉问答(Visual Question Answering)](#3.4 视觉问答(Visual Question Answering))
- [3.5 视频摘要与精彩片段检测(Video Summarization and Highlight Detection)](#3.5 视频摘要与精彩片段检测(Video Summarization and Highlight Detection))
- [4 触觉-视觉(Touch-Visual)](#4 触觉-视觉(Touch-Visual))
-
- [4.1 状态估计(State Estimation)](#4.1 状态估计(State Estimation))
- [4.2 几何形状感知(Geometric Shape Perception)](#4.2 几何形状感知(Geometric Shape Perception))
- [4.3 物体识别(Object Recognition)](#4.3 物体识别(Object Recognition))
- [4.4 触觉-视觉生成(Touch-Visual Generation)](#4.4 触觉-视觉生成(Touch-Visual Generation))
- [5 深度-视觉(Depth-Visual)](#5 深度-视觉(Depth-Visual))
-
- [5.1 物体检测与识别(Object Detection and Recognition)](#5.1 物体检测与识别(Object Detection and Recognition))
- [5.2 场景识别(Scene Recognition)](#5.2 场景识别(Scene Recognition))
- [5.3 三维重建(3D Reconstruction)](#5.3 三维重建(3D Reconstruction))
- [5.4 活动识别(Activity Recognition)](#5.4 活动识别(Activity Recognition))
- [5.5 手势识别(Gesture Recognition)](#5.5 手势识别(Gesture Recognition))
- [5.6 显著性检测(Saliency Detection)](#5.6 显著性检测(Saliency Detection))
- [6 超越双模态学习(Beyond Bimodal Learning)](#6 超越双模态学习(Beyond Bimodal Learning))
-
- [6.1 多模态对比预训练模型(Multimodal Contrastive Pre-Trained Models)](#6.1 多模态对比预训练模型(Multimodal Contrastive Pre-Trained Models))
- [6.2 大语言模型(Large Language Models)](#6.2 大语言模型(Large Language Models))
- [7 其他模态(Other Modalities)](#7 其他模态(Other Modalities))
- [8 展望未来(Look into the Future)](#8 展望未来(Look into the Future))
- [9 结论(Conclusion)](#9 结论(Conclusion))
1. 背景介绍
Amugongo L M, Kriebitz A, Boch A, et al. Mobile computer vision-based applications for food recognition and volume and calorific estimation: A systematic reviewC//Healthcare. MDPI, 2022, 11(1): 59.
🚀以上学术论文翻译由ChatGPT辅助。
多模态信息处理是类人感知能力的重要基础,其灵感来源于人类五种基本感官(视觉、听觉、嗅觉、味觉与触觉)之间的协同作用,这种多感知通道的交互使人类具备更优越的环境感知与学习能力。受此启发,多模态机器学习(Multimodal Machine Learning)试图引入多种输入模态(如图像、音频、文本等),通过联合建模挖掘不同模态间的内在关联。作为人工智能未来发展的关键方向之一,总结多模态机器学习的研究进展具有重要意义。
本文从模态组合的基本形式出发,对当前快速发展的多模态机器学习领域进行了系统性综述,覆盖了代表性的研究方法、最新技术进展及其典型应用场景。特别地,本文深入分析了不同模态之间的关系,从多种实际应用背景中梳理出当前多模态研究面临的关键问题;同时,全面回顾了多模态学习领域中主流的模型方法和常用的数据集,并对其适用范围与性能特点进行了比较分析。
在此基础上,本文进一步指出了多模态学习领域当前存在的重大挑战,并提出了未来可能的发展方向。例如,如何有效对齐异质模态、如何在数据不平衡或模态缺失条件下实现鲁棒融合、以及如何提升模型的可解释性与泛化能力,都是当前亟需解决的问题。鉴于本综述内容的系统性与全面性,无论是关注单一模态建模的研究者,还是致力于多模态联合任务的工程实践者,都能从本文中获得有益启发,进而推动多模态智能研究的深入发展。
1 引言
人类通过多种信息组合感知世界,例如:看到路上的一辆车、听到发动机启动的声音,即可判断这是一辆即将启程的汽车;又如我们可以通过食物的外观、香气、触感、咬合声音和咀嚼味道来辨别其种类。通常,这些不同形式的信息被视为不同的模态(modality)。在多模态机器学习中,各种信息的不同表现形式也被归为模态。近年来,大多数研究者倾向于使用两种模态进行多模态研究。他们期望利用模态间的共性或互补性,达成单模态研究中难以实现的目标,或解决新问题。
然而,不同研究者采用的模态类型往往不同,所面临的问题与解决方式也各异,这使得虽然都归属"多模态研究"范畴,但不同研究之间的关联性却在减弱。我们认为,不同模态领域的研究者应具备对整个多模态研究领域的整体认知,才能把握其发展全貌。本文旨在梳理不同模态间的研究进展,帮助多模态学习研究者系统了解各方向的研究现状,进而推动该领域的发展。因此,无论是关注特定模态的研究者,还是聚焦具体任务的工程实践者,均可从本综述中获得启发。
本文选取了五种常见模态:视觉(visual)、音频(audio)、文本(text)、触觉(touch)与深度(depth)(见 Figure 1),并从这些模态的不同组合出发,如 Audio-Visual、Text-Visual、Touch-Visual、Depth-Visual,系统梳理了多模态学习的主要研究方法与最新进展,帮助研究者全面理解各细分领域的研究现状。最后,本文还分析了当前多模态研究所面临的挑战,并对未来发展趋势进行了展望。此外,我们还在附录中整理了约 120 个多模态数据集,包含类别、规模、描述等详细信息,并提供了可访问与下载的链接。
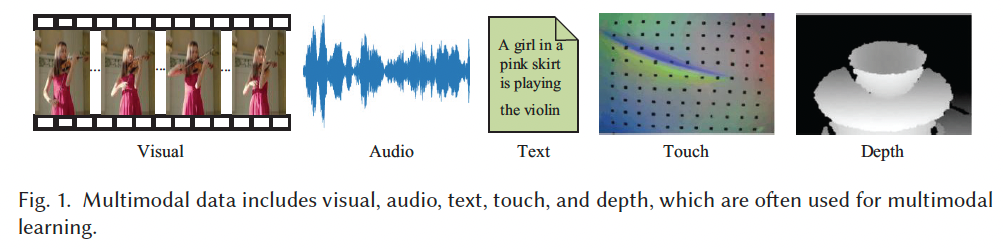
Audio-Visual 模态组合
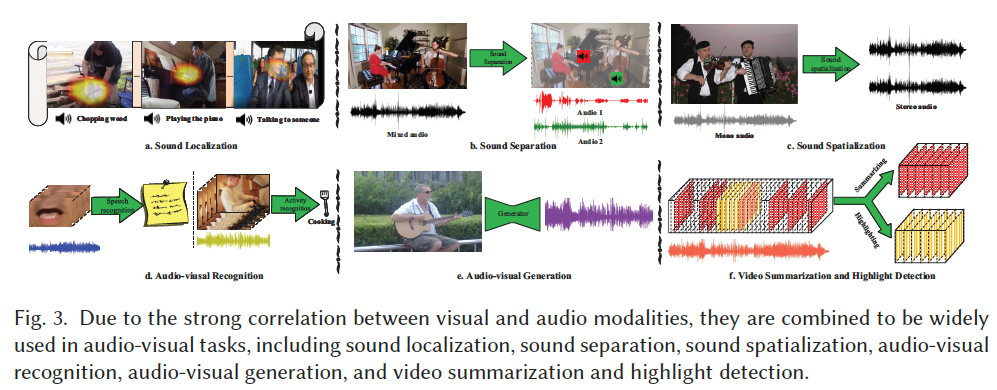
在多模态学习中,视频是最具代表性的信息载体,其同时包含丰富的视觉与音频模态。视频中的这两种模态天然对齐,构成了具有关联性的整体事件描述。音频在数据结构上是连续变化的模拟信号,而视觉信息是二维或三维像素组成的密集矩阵。如 Figure 3 所示,Audio-Visual 学习旨在建模视觉与音频模态之间的关联关系,从而推动相关任务的发展。
Text-Visual 模态组合
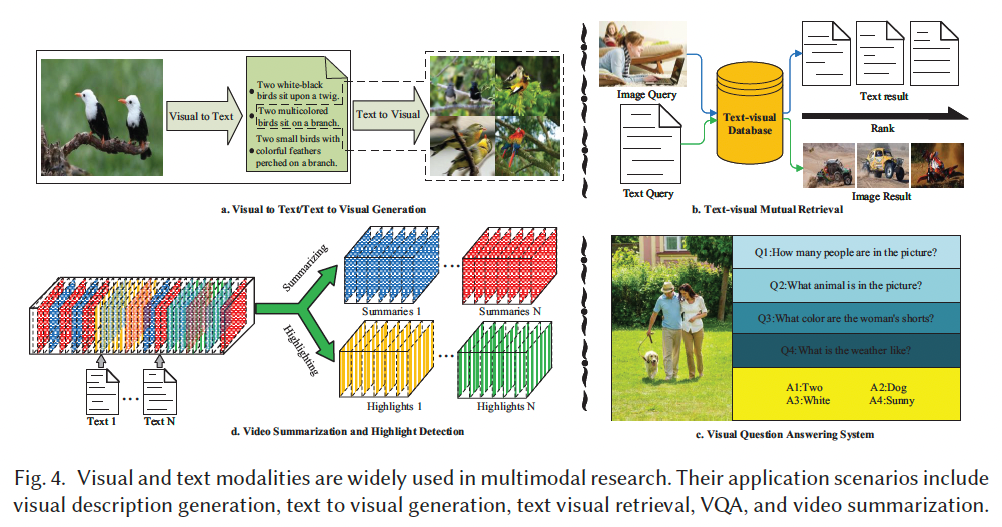
文本与视觉是多模态学习中最常用的两种模态。如 Figure 4 所示,二者之间的关键差异在于抽象程度。视觉模态以图像或视频形式呈现,通常包含特定主体、物体、场景、事件或活动,而文本是由字符串构成。尽管词语可描述某个对象或行为,但仅提供高度抽象的语义概念。
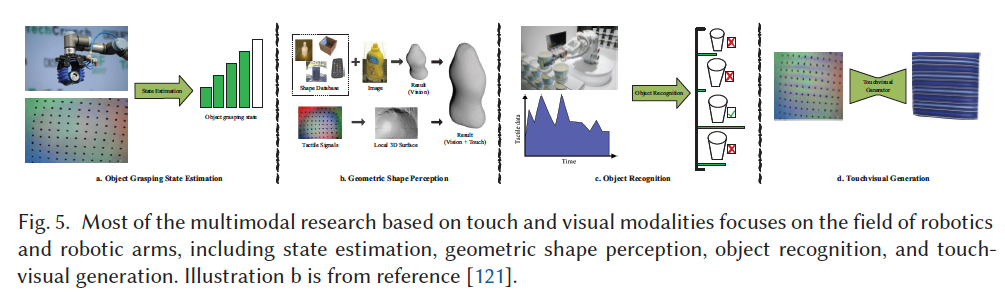
Touch-Visual 模态组合
如 Figure 5 所示,触觉可与视觉模态结合使用。视觉信息具有全局性,而触觉则能提供物体的物理属性和精细特征。在现实中,我们闭上眼睛、仅靠指尖就能感知物体的纹理与几何形状。受此启发,研究者期望视觉与触觉可以实现互生成。早在 1960 年代,关于将视觉信息编码为触觉信息的研究就已开始。
Depth-Visual 模态组合
深度图是一种图像形式,表示传感器与物体表面之间的距离,可视作灰度图,其像素值表示与目标物体的距离。如 Figure 6 所示,RGB 图像与深度图常被配准(registration),即两者在空间上存在一一对应关系,结合后可提供丰富的空间结构信息。

多模态发展趋势分析
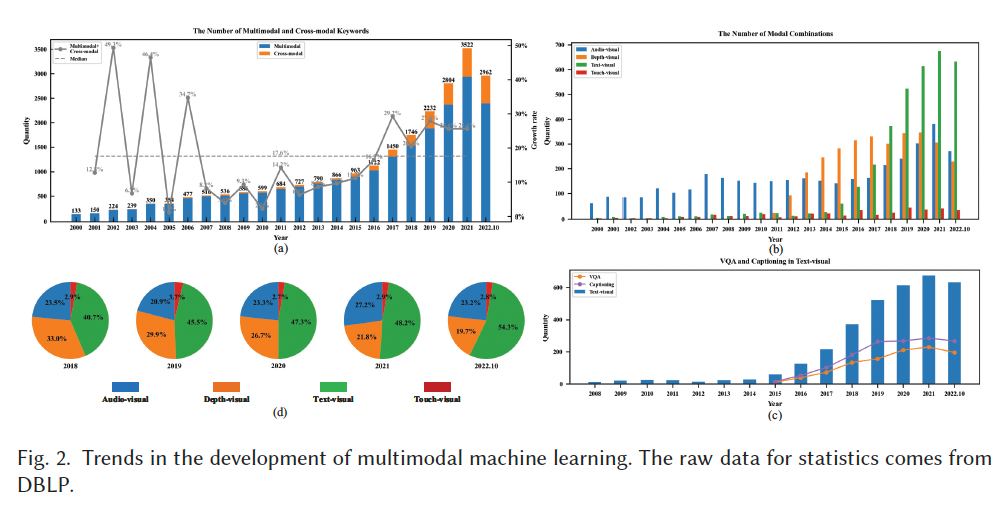
为了直观理解多模态学习的演进与模态组合的发展趋势,本文基于 DBLP 数据库中 2000--2022 年的统计数据(截至 2022 年 10 月)进行分析。通过对文献年份、类型与关键词的筛选,Figure 2 展示了多模态学习的 23 年发展趋势。
Figure 2(a) 显示了包含 "multimodal" 与 "cross-modal" 关键词的文章数量及年度增长率。可以看到,多模态研究远多于跨模态研究,因其能够更直接地利用模态间的共性与互补性。在 21 世纪初期,多模态学习发展迅速,2002 年增长率高达 49 % 49\% 49%。2007--2016 年间,该增长率趋于平稳(平均 17.6 % 17.6\% 17.6%),但自 2017 年起再次上升,保持在 20 % 20\% 20% 以上。
Figure 2(b) 展示了不同模态组合的发展趋势。从中可看出,Audio-Visual 一直是研究热点,而 Depth-Visual 模态的关注度则始于 2011 年。这与 Kinect 相机的发布密切相关,其于 2010 年 11 月 4 日面世,但直到 2012 年 2 月 1 日微软发布 Kinect SDK 才激发研究热潮,导致 Depth-Visual 相关论文数量激增。
相比之下,Text-Visual 的研究在 2014 年前增长缓慢,直到 2015 年基于深度学习的图像描述(Image Captioning)方法【115】与视觉问答(VQA)任务【3】的提出,才推动该方向迅速发展。Figure 2© 分析了这两个任务自 2015 年以来的发展轨迹,显示其在前 3 年发展迅速,近两年增长趋缓。其中 Image Captioning 的研究更为广泛。
Touch-Visual 是相对冷门的方向,受限于硬件与应用场景,其研究数量仍较少,但近年来呈缓慢增长态势,未来随着新型硬件、算法与任务的发展,有望迎来快速增长期。
Figure 2(d) 展示了各模态组合在近 5 年中的占比变化。Text-Visual 始终占据最大比例,并呈持续扩展趋势;而 Depth-Visual 的比例则逐年下降。2021 年,Audio-Visual 的研究比例首次超过 Depth-Visual,成为新的热点方向。
2 视听多模态(Audio-Visual)
同时使用视觉与音频模态进行的多模态机器学习被称为视听学习(audio-visual learning) 。视频是视听学习中最广泛使用的多模态数据形式,它同时包含视觉模态及其对应的音频模态。视频中的视觉与声音在语义、时间与空间 三个层面上天然对应。例如,在一段吉他独奏视频中,画面与声音在语义层面上都可以指向"吉他";同时,画面与声音在时间维度上是对齐的;如果声音为立体声,空间维度上也能够体现这种对应关系。研究者正是利用这种天然对应关系,来提升以往单模态任务的性能,或解决更具挑战性的全新问题。
视听学习的应用场景主要包括:声音定位、声音分离、声音空间化、视听识别、视听生成、视频摘要与精彩片段检测等。
2.1 声音定位(Sound Localization)
声音定位是指在视觉场景中定位发声物体的位置。研究者通常结合视觉与音频模态,并通过关系建模将发声物体的视觉特征与声音特征关联起来,从而实现声音定位。一些研究 5, 82, 139 通过设计视听预训练任务(pretext task),利用音频与视觉模态之间的天然对应关系来建立二者之间的特定联系。
为了建立视频中视觉与音频之间的语义关系 ,Arandjelovic 等人 5 随机替换视频所对应的音频,并采用自监督学习判断视觉内容是否与音频匹配,进而学习到的视听特征被用于声音定位任务。类似地,为了建立视觉与音频之间的时间关系,Owens 等人 82 在时间维度上随机偏移视频对应的音频,并通过自监督学习判断音频是否发生偏移,所学习到的视听特征同样可用于声源定位。
Yang 等人 139 将视听学习中的预训练任务从时间域扩展到空间域,通过无监督方式训练模型判断左右声道是否被翻转,从而迫使模型学习视觉与音频之间的空间对齐关系。实验结果表明,所学习到的视听空间对应关系能够提升模型在声音定位、声音空间化以及声音分离等任务上的性能。
上述方法 5, 82, 139 均通过预训练任务来建模视觉与音频模态之间的关系,并通过建立显著的视听关联来提升下游任务的性能。然而,这类方法使得下游任务的表现高度依赖于预训练任务建模的质量。此外,这种基于对比学习的预训练任务在大规模训练时容易受到**伪正样本(false positive)**的影响,从而损害表示学习效果。
为缓解伪负样本(false negative)带来的误导,Sun 等人 109 提出了伪负样本感知的对比学习策略 ,通过利用模态内相似性来识别潜在的伪负样本,并引入伪负样本抑制机制以降低其影响。然而,该方法仅建立了视觉与音频模态之间的单一表示关系,导致跨模态建模能力不足。Li 等人 69 从语义一致性、时间同步性和空间对应性三个方面系统探索了视听模态之间的关系,并表明对多维表示关系的全面理解能够显著提升声音定位性能。
Senocak 等人 101 提出了带有注意力机制的双流网络结构来解决视觉场景中的声音定位问题,并发布了一个新的(带标注的)声音定位数据集。该网络可以通过无监督方式训练;为减少无监督方法在部分场景下引入的误差,作者进一步通过增加监督损失,将该双流网络扩展至有监督与半监督设置。
目前尚未形成统一的声音定位性能评估标准。多数研究 5, 82 给出了声音定位可视化的定性结果,并通过比较类别激活映射(Class Activation Mapping, CAM)的响应来评估模型性能(见图 3(a))。Rachavarapu 等人 93 使用 F F F-measure 和平均绝对误差(MAE)对声音定位性能进行定量评估,而 Senocak 等人 101 则主张使用一致性交并比(consensus Intersection over Union, cIoU)指标进行评估。基于 cIoU 的评估方法需要人工标注图像中发声区域的边界框,因而具有较强的主观性。
2.2 声音分离(Sound Separation)
声音分离是指从混合声音中分离出两个或多个声源。在不依赖视觉模态的情况下,仅使用音频模态进行声音分离的研究已取得了良好效果 18。鉴于物体的声音与视觉之间存在强相关性,进一步引入视觉模态可以引导模型对混合声音进行分离,其性能往往优于仅使用音频模态的方法。
Afouras 等人 1 采用自监督学习训练了一种将音频与视频中说话对象关联起来的模型。该模型采用双流结构,输入为图像及其对应音频,输出为与说话人相关的视听对象(潜在声源的轨迹)及其嵌入表示。最终得到的嵌入可用于多说话人声音分离、声音定位与跟踪、音视频错位校正以及说话人检测等下游任务。
Zhao 等人 158 提出了 PixelPlayer 系统,利用大量无标注视频学习定位图像中产生声音的区域,并将输入声音分解为一组表示每个像素声音成分的分量。实验结果表明,该混合与分离框架在声音分离任务上优于多种基线方法。随后,Zhao 等人 157 指出可以通过物体的视觉运动来跟踪声源,并提出了一种端到端的**深度密集轨迹(Deep Dense Trajectory, DDT)**模型,结合课程学习策略来捕捉物体运动信息。与依赖外观线索的模型 1, 82, 158 相比,该方法利用运动线索在乐器声音分离任务上表现更为有效。
Zhu 等人 169 提出了一个两阶段的声源分离框架,同时利用视觉与运动信息来分离混合声音,并可扩展应用于声音定位与活动识别任务。然而,上述方法在扩展到新乐器时需要对整个视听网络进行微调,训练成本较高。为此,Chen 等人 17 提出了基于查询的声音分离框架,通过插入额外查询作为音频提示,从而适配新乐器。
尽管取得了诸多进展,声音分离仍面临两大挑战:声源数量与声源多样性 。现有方法在少量混合的异质声源场景中表现良好,但在同质声源或超过三个声源混合的情况下效果有限。因此,对任意数量与类型声音的分离仍可视为该领域尚未解决的难题。
2.3 声音空间化(Sound Spatialization)
声音空间化是指将单声道音频转换为双声道或多声道音频。该技术能够显著提升听觉体验,尤其适用于 VR/AR 场景。与单声道音频相比,立体声音频还有助于提升声音定位、话语聚类和语音分离等任务的模型性能。
Gao 等人 38 使用专业设备采集了首个包含室内双耳音频的视频数据集,并结合视觉信息与编码器--解码器模型,成功实现了单声道到双声道音频的转换。Zhou 等人 163 注意到声音分离与立体声生成在目标上具有相似性,因而将二者统一到一个框架中,在实现声源分离的同时提升了立体声生成性能。Li 等人 65 采用多任务学习策略,在立体声生成基础上增加了左右声道是否翻转的子任务,通过加权损失联合训练模型。
与 38, 163 直接在通道维度拼接视听特征的方法不同,Zhang 等人 153 提出了多注意力融合网络(MAFNet),以更有效地融合视听特征,并通过迭代结构持续优化立体声生成。进一步地,Garg 等人 41 主张在视觉模态中解耦几何线索,提出了一种多任务方法,利用环境几何特征和视听时空表示将单声道音频转换为双耳音频。
为增强声音空间化中空间音频与视觉模态的相关性,Liu 等人 74 基于视听空间化网络提出了一种视听匹配损失。不同于上述基于声谱图的方法,Li 等人 70 首次尝试在波形域 生成空间音频,提出了一种物体感知扩散模型,利用局部发声物体进行细粒度视觉引导以生成空间音频。
由于空间音频的各个声道来自同一场景或物体,不同声道之间既存在共性也存在差异。例如,一架靠近左耳的钢琴,左右耳都会听到钢琴声,但声压级不同。因此,探索不同声道之间的共性与差异是立体声生成面临的重要问题,而该问题尚未得到充分研究。人类可以直观感受到立体声的空间感,但如何在研究中定量评估立体声音频的空间感知仍是一个悬而未决的问题。
2.4 视听识别(Audio-Visual Recognition)
视听识别是指同时利用视觉与音频信息进行识别的任务,主要包括语音识别 与活动识别。语音识别系统旨在利用机器处理语音信号并将其转换为相应文本,其研究可追溯至 1952 年。随着技术发展,语音识别系统已较为成熟,应用范围不断扩大。在理想环境下,仅依靠音频即可达到接近人类水平的识别精度;但在嘈杂环境中,基于音频的语音识别准确率往往显著下降。为解决这一问题,一些研究在音频基础上引入了唇动等视觉模态信息。
在深度学习出现之前,已有研究将人工设计的视觉特征引入语音识别系统,其性能优于纯音频方法。随着深度学习的发展,研究者开始利用深度模型进行视听语音识别,并逐步超越以往先进方法。Burchi 等人 13 使用视觉编码器与音频编码器分别提取唇部视觉特征与音频特征,再通过视听融合模块进行特征聚合以完成语音识别。大量研究表明,在语音识别中引入视觉信息能够有效降低词错误率(Word Error Rate, WER%),尤其在噪声环境下效果显著。
活动识别是指对视频中事件与活动的识别。基于视觉模态的单模态活动识别已被广泛研究,但当视觉受遮挡时往往产生错误预测。多模态活动识别通过融合多种模态信息为活动识别提供互补信息,可显著提升识别性能。视听模态是活动识别中常用的两种模态,已有大量研究开展相关探索。例如,Subedar 等人 105 提出了用于活动识别的不确定性感知多模态贝叶斯融合框架。
针对视听事件识别与定位问题,Wu 等人 129 指出在特征融合过程中,短时视觉与音频片段易受到轻微时间错位的影响,因此提出了双重注意力匹配(Dual Attention Matching, DAM)模块:使用较长时间片段进行事件建模,使用较短时间片段进行事件定位。Kazakos 等人 54 将听觉信息引入第一人称活动识别中,为视觉提供补充信息。不同于以往假设视听事件严格同步的工作,作者在 时间绑定窗口(Temporal Binding Window, TBW)内对输入进行融合,使模型能够利用来自不同模态的异步输入进行训练。其主要贡献在于提出了时间绑定网络(Temporal Binding Network, TBN),并首次将视听融合应用于第一人称活动识别,在 EPIC-Kitchens 27 的可见与不可见测试集上均取得了最先进的性能。
Assefa 等人 8 在半监督动作识别中引入了视听对比与一致性学习,通过深度嵌入聚类获得高质量伪标签,从而降低确认偏差(confirmation bias)。
2.5 视听生成(Audio-Visual Generation)
视听生成是一个令人印象深刻的研究方向,其生成结果的质量甚至可以欺骗人类受试者。单模态的图像生成与音频生成已经取得了令人惊讶的进展,能够从噪声或原始数据中生成逼真的内容。在视听跨模态生成领域,一些研究 19, 20, 47, 83, 166 探索了视觉与声音模态之间的关系,实现"由视觉生成声音"以及"由声音生成视觉"。
Owens 等人 83 从人们使用鼓槌敲击或刮擦物体的无声视频中生成声音,合成的声音逼真到足以欺骗实验参与者。Zhou 等人 166 提出了一种模型,能够直接从输入视频中预测声音的波形 。该模型面向的是自然场景(in-the-wild)视频中的声音生成,而非 83 中的受控实验室环境。然而,在自然场景视频中,不可避免地会存在与视觉内容无关的声音,这使得生成模型可能被迫学习视觉与无关声音之间的不准确映射。为此,Chen 等人 20 提出了 REGNET 框架,并设计了一种音频前向正则项(audio forwarding regularizer),通过直接将真实声音作为输入并输出瓶颈特征,从而抑制无关声音的影响。
反过来,也可以由声音生成视觉内容。例如,文献 19, 47 使用对抗生成网络,从音频模态生成对应的视觉模态。Chen 等人 19 采用条件生成对抗网络,实现了音乐表演的跨模态视听生成,该模型既可以由音频生成视觉,也可以由视觉生成音频。为了提升感官替代设备中的跨模态转换质量并避免繁琐的人工评估,Hu 等人 47 提出使用机器模型来评估转换质量,并针对先天失明与后天失明两种情况分别提出了跨模态感知模型,目标是从转换后的声音中生成特定的视觉内容。
相较于以往的单模态生成,Kurmi 等人 58 探索了多模态联合生成。该方法分别使用 MoCoGAN 和 WaveGAN 从噪声中生成视频与音频,随后通过一个联合判别器对音视频对进行判别,从而实现对音频与视频联合生成的初步探索。然而,该方法仅简单组合了音频与视频生成模型,并未充分考虑二者生成过程之间的内在关联。
利用已有预训练模型的表示与生成能力,可以进一步提升视听生成性能。Xing 等人 132 利用预训练模型 ImageBind 42 中的共享语义空间,将音频与视频生成模型连接起来,从而实现音视频联合生成、视觉到音频生成以及音频到视觉生成。Yariv 等人 141 则利用文本条件视频生成模型的强大生成能力来提升生成质量与多样性,其方法将输入音频映射为一组伪 token 序列,并将其输入到文本条件生成模型中以生成视频。
由于视觉与音频模态之间存在显著异质性,例如数据维度不同、信息不对称等,跨模态生成的结果质量仍不理想,高质量的视听生成仍是该领域长期面临的挑战。随着图像、音频与视频采集设备的不断升级,真实数据质量持续提升,而相比之下,视听生成模型所生成的模态内容往往质量偏低。此外,现有视听生成模型通常建立在数据丰富性不足且模态依赖性较强的数据之上,导致生成结果的泛化性与多样性受限;同时,生成内容的时长通常只有数秒,语义较为单一。目前,多数研究仍将视觉与音频模态的生成视为相互独立的过程。尽管已有少量工作开始关注视听模态的联合生成,但尚未充分建模不同模态之间的共性与互补信息。
2.6 视频摘要与精彩片段检测(Video Summarization and Highlight Detection)
视频摘要是指从一段较长的原始视频中提取具有代表性的片段,在尽可能保持原始视频信息完整性的前提下,形成一个简短而信息丰富的摘要。随着互联网视频数量的爆炸式增长,该技术使人们能够用更少的时间获取原本需要长时间观看才能获得的信息,并有助于高效分析与理解视频内容。
已有研究提出了多种仅基于视觉模态的视频摘要方法,包括基于聚类的方法、基于内容的方法、基于注意力的方法、基于神经网络的方法以及基于 Transformer 的方法 21,并取得了良好效果。关于神经网络方法在视频摘要中的系统综述,可参考文献 4。此外,一些研究 55, 60, 155, 156 指出,音频作为与视觉内容高度相关的模态,可以与视觉模态结合以进一步推动视频摘要研究。
例如,在体育赛事中,解说员的声音是观众关注的重要信息;当关键事件发生时,音频能量通常会突然升高并在短时间内保持较高水平。因此,音频是体育视频摘要中的重要模态。Kiani 等人 55 提出了基于内容感知视听特征的足球视频摘要方法,在精度上取得了令人满意的结果,同时处理速度接近实时的两倍。Zhao 等人 155 提出了一种视听循环网络,利用双流 LSTM 分别编码视觉与音频特征,再通过另一 LSTM 对两种模态进行融合,实验结果表明,该方法优于仅使用视觉模态的摘要方法。
由于 LSTM 需要顺序处理视频帧,其性能依赖于历史隐藏状态。相比之下,Transformer 可以整体处理视频帧,获取全局信息,从而减轻长时依赖带来的性能退化问题。Zhao 等人 156 提出了层次化 Transformer,用于捕获帧级与镜头级之间的依赖关系,并基于该结构设计了视听融合机制。针对现有方法难以处理长视频的问题,Lee 等人 60 提出了一种能够同时利用视觉与音频特征、并捕获短期与长期时间依赖的模型。为进一步提升视频摘要性能,Xie 等人 131 从大规模知识库中引入了额外的隐式知识,并将其融入视觉与音频模态中。
与视频摘要"既包含重要片段又能完整表达视频内容"的目标不同,视频精彩片段检测的目的是从视频中找出最具吸引力的瞬间。相较于通常使用的视觉模态,Islam 等人 50 仅使用音频模态生成体育视频精彩集锦,表明音频可为精彩片段检测提供有效补充信息。Vahedi 等人 114 提出了 TechTube 系统,能够通过自然语言查询视频中的精彩片段;在生成阶段,该系统利用音频振幅信息辅助检测视频中的停顿,从而实现视频分割。然而,该方法仅使用了音频的简单表示,忽略了视听模态之间的交互关系。
Badamdorj 等人 9 提出了一种联合建模音频与视觉模态的方法,通过双模态注意力机制 捕获模态间交互,从而提升精彩片段检测性能,并采用加权求和的线性融合方式融合视听信息。但该方法可能难以充分建模两种模态之间的复杂相关性。Ye 等人 142 提出了低秩视听张量融合方案,在减少训练参数数量的同时,实现了高效的模态交互建模。Mundnich 等人 80 进一步验证了非结构化视频中有趣事件本质上是视听事件,并在视频摘要与精彩片段检测任务中开展实验。结果表明,在视频摘要任务中,视听模态优于仅使用视觉模态;而在精彩片段检测任务中,视频摘要中学到的知识可以迁移使用。
需要注意的是,精彩片段中并不总是包含高质量音频,这在一定程度上限制了多模态方法的应用。针对这一问题,Li 等人 66 首次提出了一种跨模态预训练模型来学习音频与视觉模态的语义表示,并在精彩片段检测中仅给定视觉模态的情况下生成视听联合表示。
视频摘要数据集的标注结果在很大程度上受主观因素影响,使得视频摘要成为一个高度主观的任务。视频摘要通常需要帧级的重要性评分,标注成本极高;同时,由于视频内容本身存在冗余,标注信息也存在重复性。我们认为,一种可行的方式是对大量用户在观看视频时的行为进行分析,例如暂停、回放、加速与跳过等操作,以缓解标注的主观性与成本问题。
视听视频摘要方法要求音频与视觉模态之间具有良好的协同关系。然而,在真实场景视频中,音频与视觉可能存在不一致现象,例如旁白、背景音乐以及时间错位等,尤其是在自然场景视频中更为常见。这些因素可能导致音频模态不仅无法提升摘要性能,反而对视频摘要过程产生负面影响。
3 文本-视觉(Text-Visual)
文本与视觉模态在多模态研究中被广泛使用,其中图文匹配(image-text matching)起着关键作用。图文匹配是指衡量图像与文本之间相似度的任务。常见的度量方法是将图像与文本联合嵌入到一个共享的低维潜在空间中,然后直接在该空间内比较两种模态的向量表示。由于该空间维度较低,这种方式在跨模态任务中具有很高的便利性。
例如,在跨模态检索任务中,给定一段查询文本,需要根据图像与文本在该共享空间中的相似度检索语义相近的图像;在图像描述生成任务中,给定一幅图像,需要基于图像内容检索相似文本,并将其作为(或进一步生成)图像的文本描述;在图像问答任务中,需要根据给定的文本问题,在图像中找到对应的答案内容,同时还需要从视觉内容中检索与预测答案相匹配的文本语义。
在早期研究中,典型相关分析(Canonical Correlation Analysis, CCA)被广泛用于挖掘数据之间的相关关系,并应用于图文匹配任务。CCA 通过寻找一种线性投影,使得两种视图在投影空间中的相关性最大化。然而,CCA 难以扩展到大规模数据场景。近年来,基于深度学习的图文匹配方法取得了显著进展。相较于线性投影方法,深度学习模型所具备的非线性映射能力能够提供更强的表示能力。
3.1 视觉描述生成(Visual Description Generation)
视觉描述生成,也称为视觉字幕生成(visual captioning)或视觉到文本生成(visual-to-text generation) ,是指针对给定的视觉内容生成与之匹配的文本描述,包括图像描述生成 和视频描述生成。早期已有一些开创性的视觉描述生成工作被提出 33,但这些基于模板的方法通常预先设定了句式模板与生成规则,导致生成描述的多样性不足。
近年来,基于神经网络的方法 52, 103, 164, 165 被广泛应用于图像描述生成任务。为了直接从训练数据中学习图像与语言之间的对应关系,Karpathy 等人 52 提出了一种神经网络模型,用于推断句子片段与其所描述图像区域之间的潜在对齐关系,其生成的句子质量显著优于基于检索的基线方法。
**指代对齐准确率(grounding accuracy)**描述了模型在生成词语时能否关注到正确视觉对象的能力。在视觉描述生成任务中,模型往往依赖一定的先验知识,从而可能生成视觉中并未出现的内容,导致指代对齐准确率下降。为此,Zhou 等人 165 提出了 POS-SCAN 模型,在保证图像描述质量的同时提升了指代对齐准确率。针对视频描述生成,Zhou 等人 164 在视频的某一帧中为句子中的每个名词短语标注对应的边界框,从而将文本描述与视频内容进行显式关联。
当图像或视频中包含多个具有不同行为的对象时,仅用一句话往往难以完整描述复杂的视觉内容。为解决这一问题,研究者提出了**密集视觉描述(dense visual captioning)**任务,其目标是使用多句文本对图像或视频内容进行描述。Shen 等人 103 提出了一种新的密集视频描述方法,实验表明,即便仅利用弱监督信号训练,模型也能够生成信息丰富且多样化的视频描述。
将视觉模型与**大语言模型(Large Language Models, LLMs)**结合,可以充分发挥 LLM 强大的语言生成能力。Zhu 等人 167 通过投影层将冻结的视觉编码器与冻结的 LLM(Vicuna)对齐,使 GPT-4 展现出包括图像描述生成在内的多种高级多模态能力。在视频描述任务中,Yang 等人 135 通过引入特殊的时间 token 来增强大语言模型,使其能够预测视频中的文本描述以及事件边界。
视觉描述生成系统的性能依赖于模型对视觉内容的提取能力与文本描述的生成表达能力。在视觉信息提取阶段,模型需要正确识别显著目标、目标属性以及目标之间的关系;在文本生成阶段,模型需要基于视觉信息生成复杂的自然语言,并确保生成句子的完整性、流畅性与正确性 。有监督的视觉描述生成模型通常需要大量完整标注的图像-文本对,为保证泛化能力,一张图像往往需要配置多条描述语句;部分方法还对视觉内容进行额外标注以获取更有效的视觉信息,这无疑进一步增加了数据采集与标注成本。
3.2 文本到视觉生成(Text to Visual Generation)
文本到视觉(Text-to-Visual, T2V)生成的目标是:根据文本描述生成在视觉真实性与语义一致性上均符合要求的视觉内容。该方向是自然语言处理与计算机视觉领域中的研究热点。随着生成对抗网络(GAN)的发展,越来越多基于 GAN 的方法 92, 96, 150 被提出。视觉生成是 GAN 最为广泛研究的应用之一,充分展示了 GAN 在该领域的巨大潜力。
与传统视觉生成直接以图像为输入不同,T2V 以文本描述作为输入或条件。Reed 等人 96 首次将文本描述作为条件引入 GAN 中,实现了从文本生成图像,但生成结果分辨率较低,且缺乏真实细节。为解决这些问题,Zhang 等人 150 提出了 StackGAN,通过两个独立阶段进行生成:第一阶段根据文本描述生成低分辨率图像,第二阶段将该低分辨率图像与文本描述共同作为输入,从而生成具有高分辨率与照片级真实感的图像。
尽管 GAN 在高分辨率与真实感图像生成方面取得了显著进展,但如何保持文本描述与图像内容之间的语义一致性 仍然是一个重要挑战。为此,Qiao 等人 92 提出了文本-图像-文本框架 MirrorGAN,通过"再描述生成"的思想,对生成图像进行文本重描述,以保持生成文本与原始文本之间的语义对齐。
Ramesh 等人 95 提出了基于 Transformer 的方法 DALL·E ,将文本 token 与图像 token 作为统一的数据流进行自回归建模,在 MS-COCO 数据集上实现了无需训练标签的零样本高质量图像生成。随后,**扩散概率模型(Diffusion Probabilistic Models, DPMs)**作为强大的文本到图像生成工具出现,展现出显著的视觉质量提升潜力。Ramesh 等人 94 提出了 DALL·E 2,将 DPMs 与 CLIP 的多模态能力相结合,大幅提升了生成图像的质量与多样性。然而,DPMs 的反向扩散过程在训练与推理阶段均具有较高的计算开销。为此,Rombach 等人 98 将 DPMs 从像素空间扩展至预训练的潜在空间,在保证生成质量的同时显著提升了生成效率。
2024 年,OpenAI 发布了文本到视频生成模型 Sora ,该模型结合了扩散模型与 Transformer 架构 75,在大规模文本-视频对数据集上进行训练,展现出令人印象深刻的泛化能力与真实感生成效果。Sora 的成功得益于先进的模型架构、模型规模以及训练数据规模,但其仍受限于对真实世界因果关系与组合推理能力的理解不足 23。与此同时,Pika Labs 推出了视频生成模型 Pika,不仅支持文本生成视频,还支持基于图像生成视频,并提供多种风格与局部元素修改能力 90。
Koh 等人 56 将大语言模型引入图像生成任务,通过建立大语言模型与预训练图像编码器之间的映射关系,其性能优于非 LLM 方法。除直接参与视觉生成外,大语言模型还可生成可控的辅助信息 以指导视觉生成。例如,Feng 等人 35 提出了 LayoutGPT ,可根据文本提示生成布局信息,再将其作为视觉先验与生成模型协同工作,用于生成二维图像与三维视觉场景。此外,大语言模型还可作为 T2V 生成的评估器 76,以提升生成结果与人类主观评价之间的相关性。
文本到视觉生成与视觉描述生成在任务目标上具有对偶关系,因此,T2V 中的文本特征表示提取与视觉描述生成中的视觉内容提取同等重要。此外,如何根据文本描述生成信息丰富的视觉场景仍是该领域的难点,这依赖于视觉生成系统建模能力的持续提升。同时,提高生成视觉内容的分辨率也对模型的细节控制能力提出了更高要求。
3.3 文本-视觉检索(Text-Visual Retrieval)
在视觉-文本跨模态检索任务中,给定一段查询文本,需要根据文本与视觉之间的相似度检索内容相近的图像。随着视觉数据与文本数据的快速增长及其广泛应用,二者之间的检索研究受到了广泛关注。文本-视觉检索的核心在于计算两种模态之间的相似性 ,常见做法是在文本嵌入与视觉嵌入之间引入距离度量,例如余弦相似度。
在深度学习算法出现之前,研究者主要通过人工设计特征 并结合哈希编码方法进行图文检索。Zhen 等人 160 提出了一种基于哈希的快速多媒体检索方法,对图像与文本模态的相关矩阵进行谱分析,并进一步学习数据分布中的有效参数以生成二进制编码。
随着深度学习的发展,研究者开始利用深度模型进行图文检索。Sarafianos 等人 99 针对文本中词汇差异大、复杂度高的问题,提出了一种对抗式图文匹配方法 ,通过对抗学习与跨模态匹配机制来学习不同模态的特征表示。Zhen 等人 159 提出了跨模态检索方法 DSCMR,通过更好地学习模态不变性特征,在不同模态之间构建统一的表示空间。
此外,一些研究将深度学习与哈希编码相结合用于图文检索。Yang 等人 136 提出了一种深度哈希跨模态检索方法,通过深度网络生成紧凑的哈希码,有效捕获图像与文本之间的内在关系。Nam 等人 116 在传统图文检索的基础上进一步提出图像编辑式检索任务,其输入为一张图像及若干期望修改该图像的文本描述,输出为满足这些文本期望的相似图像。
为在保持检索速度的同时提升准确率,Miech 等人 79 通过两种互补机制,将双编码器结构 与交叉注意力相结合,并将精确但速度较慢的模型知识蒸馏到快速双编码器中,使推理速度提升了数个数量级。
跨模态检索利用一种模态的数据作为查询,在另一种模态中进行检索,由于模态之间存在显著的异构差异,这是一项极具挑战性的任务。近年来,显著提升文本-视觉检索性能的一种有效方式是使用语言-图像预训练模型(如 CLIP 57、BLIP 64、EVA-CLIP 107)的特征来初始化检索模型。然而,高性能的语言-图像预训练模型通常依赖于耗时巨大的训练过程。为此,研究者提出通过最新的表示学习、优化策略与增强方法来提升训练效率与性能 107。
需要注意的是,预训练模型的特征往往具有通用性与大规模性 ,对于特定的文本-视觉检索任务而言,其中可能包含大量冗余信息。因此,如何从预训练模型中蒸馏与任务高度相关的知识 成为文本-视觉研究中的关键问题。此外,预训练模型的嵌入特征通常来自粗粒度对比学习 ,通过引入细粒度对比学习,有望获得更加精细且判别性更强的表示。
3.4 视觉问答(Visual Question Answering)
视觉问答(VQA)系统以视觉内容与关于该内容的自然语言问题作为输入,并以自然语言形式输出答案。与视觉描述生成相比,VQA 对文本与视觉模态的细粒度语义理解与逻辑推理能力 提出了更高要求。简言之,VQA 需要"看、理解并回答"。
为了正确回答问题,一个优秀的 VQA 系统应具备目标感知、目标定位、计数、场景理解与场景推理等能力。Antol 等人 3 首次提出了视觉问答任务并进行了初步研究。近年来,注意力机制 在 VQA 中被广泛采用,其能够根据问题自适应地学习图像关键区域的权重,从而预测正确答案。Yu 等人 146 提出了**协同注意力(co-attention)模块,用于将问题中的关键词与图像中的关键区域进行关联,并通过 自注意力(Self-Attention, SA)与引导注意力(Guided-Attention, GA)**分别建模模态内与模态间的密集关系。
尽管 VQA 系统已取得诸多令人鼓舞的成果,但仍存在一定局限性。其原因在于模型往往倾向于学习问题与答案之间的浅层统计关联 ,而未能真正理解视觉内容;同时,VQA 数据集本身的不合理性也加剧了这一问题。这容易导致 VQA 系统在回答复杂、抽象推理问题时表现良好,却在相关的简单视觉感知问题上失败,形成一致性问题。
为解决上述问题,Selvaraju 等人 100 将相关的视觉感知子问题引入推理过程,提出了一种通用建模方法以帮助模型生成更一致的答案。Wang 等人 123 提出了更为复杂的 VQA 性能评估方法,以增强 VQA 系统的泛化能力。近年来,研究者开始利用**大语言模型(LLMs)**来提升 VQA 的零样本能力与评估质量。Guo 等人 43 提出了一种即插即用模块,将图像映射为问答对,并借助 LLM 实现零样本 VQA;Shao 等人 102 探索了 GPT-3 在 VQA 中的潜力,通过生成答案启发式信息来帮助模型更好地理解任务并提升性能。
大语言模型不仅能够提升 VQA 性能,还可用于自动化评测。相关工作 78 将 VQA 评估设计为答案评分任务,由 LLM 根据参考答案对候选回答的准确性进行打分。
3.5 视频摘要与精彩片段检测(Video Summarization and Highlight Detection)
传统的单模态视频摘要方法通常生成固定的视频摘要,而不考虑用户兴趣,从而限制了内容的个性化程度。文本模态 能够为视频摘要与精彩片段检测提供明确的语义指导,使模型能够根据文本描述对视频进行定向或定制化的摘要与高亮生成。
Plummer 等人 91 将文本与视觉模态相结合,通过将视觉特征投影到学习到的文本-视觉空间中,生成更加多样且具有代表性的摘要。Li 等人 46 认为视频与文本之间的自监督学习有助于视频摘要,并提出了一种多模态自监督方法,通过挖掘文本与视觉模态之间的语义一致性来学习多模态编码器,并将其应用于视频摘要任务。Huang 等人 48 提出了查询可控的视频摘要方法,能够根据输入文本对摘要结果进行控制。随后,Narasimhan 等人 81 提出了 CLIP-It,将查询导向与通用视频摘要统一到文本引导框架中;其中,通用模式下的文本描述并非人工提供,而是通过密集视频描述自动生成。
在视频精彩片段检测中,文本模态被认为是降低主观性的重要手段之一。Guo 等人 45 提出了基于图的模型,用于电商场景中的视频精彩片段检测,通过图聚合机制融合多源自然语言信息。然而,文本中部分词语对于精彩片段检测而言可能是冗余的。Chen 等人 16 将精彩片段检测视为定位问题,提出了一种协同进化网络 ,在协同过程中实现文本与视觉模态的相互强化,同时在学习高亮片段的过程中过滤冗余词语。Ren 等人 97 提出了时间敏感的多模态大语言模型,用于长视频理解,并在零样本精彩片段检测任务中取得了先进性能。
多数视频摘要与精彩片段检测方法依赖于时间与语义对齐 的文本与视觉模态。然而,在真实视频中,文本与视觉往往并非严格对齐,甚至可能缺失文本信息,这在一定程度上限制了相关方法的实际应用。此外,文本模态表达丰富,通常包含噪声或无关词语,对模型的语言理解能力提出了更高要求。目前,高质量的视频-文本数据集仍主要依赖人工标注。尽管视频描述方法在一定程度上缓解了文本标注成本问题,但其描述准确性仍有限。进一步地,利用 LLMs 生成伪真值摘要可以便捷地构建大规模视频摘要数据集 6,因为 LLMs 能够从视频中提取最关键、最具信息量的时刻。
4 触觉-视觉(Touch-Visual)
触觉是人类在与环境交互时的重要感知来源之一。触觉信息能够帮助人类评估物体的多种属性,例如尺寸、形状、纹理、温度 等。研究表明,人类的触觉在处理物体的物理特性和精细几何形状方面,往往优于其他感官。类似地,机器人中的触觉传感器也能够提供物体的这些属性信息。
触觉-视觉组合的多模态机器学习研究主要集中在**机器人(尤其是机械臂)**领域,而当前该领域的大多数研究仍主要依赖于视觉观测。
尽管视觉信息十分有用,但其本身也存在固有局限,例如视觉遮挡、光照变化以及由二维到三维感知带来的模糊性 ,这些问题在单目相机条件下尤为突出。因此,一些研究者希望在机器人上安装触觉传感器以获取触觉反馈。通过触觉与视觉之间的多模态学习与跨模态建模,可以进一步提升机器人在物体抓取、物体识别以及触觉-视觉生成 等任务中的性能。
目前,触觉与视觉建模面临的主要挑战在于两种模态在尺度与精度上的显著差异:视觉模态能够感知大范围、粗粒度的场景,而触觉模态只能感知局部、但精度极高的区域。
4.1 状态估计(State Estimation)
在物体抓取或操作任务中,判断某一次抓取行为的质量或状态是任务成功的关键,这有助于机器人重新制定抓取策略。视觉模态能够为抓取状态估计提供直观的位置信息,而相比之下,触觉模态能够提供更为细致的接触信息,因此在该任务中同样发挥重要作用。一些研究尝试让机器人像人类一样结合视觉与触觉进行状态判断,实验结果表明,在视觉基础上引入触觉模态能够显著提升机器人抓取状态估计的性能。
Calandra 等人 15 提出了一种端到端的动作条件模型,可直接从原始的触觉-视觉数据中学习抓取策略。与仅使用视觉数据的方法相比,该模型在抓取新物体时表现更为有效。Yu 等人 145 提出了基于**增量平滑与建图(iSAM)**的状态估计框架,将触觉与视觉模态进行融合,实现对物体状态的实时估计。Lambert 等人 59 将几何约束与物理约束同触觉-视觉多模态信息相结合,对系统中的运动学状态进行联合估计,即使在存在视觉遮挡和触觉噪声的情况下,该方法仍能保持较好的状态估计效果。
为更好地融合触觉与视觉信息以实现物体抓取,Cui 等人 24 提出了一种基于自注意力机制 的触觉-视觉融合方法,其鲁棒性优于传统方法。针对可变形物体的抓取问题,Cui 等人 25 将抓取状态划分为滑动、合适与过度 三类,并提出了一种基于三维卷积的视觉-触觉融合神经网络进行分类,其分类准确率高达 99.97%。Zhang 等人 148 提出了一种带有触觉-视觉代价学习的迭代模型预测控制器,其中触觉模态用于防止布料下滑,视觉模态用于控制运动终止,实验结果表明基于触觉-视觉模型的控制预测优于单模态方法。Liang 等人 71 提出了一种基于触觉与视觉反馈的物体操作规划框架,两种模态被联合用于预测并指示物体的可操作性:视觉模态用于判断物体外观,触觉模态用于区分物体的内在属性。
4.2 几何形状感知(Geometric Shape Perception)
几何形状感知,也称为三维形状感知(3D shape perception) ,是指对物体三维几何形状的估计。在抓取或操作未知物体时,提前估计其几何结构有助于机器人更有效地完成抓取与操作任务。仅依赖触觉传感器进行几何形状估计时,由于传感器一次只能感知物体表面的一小部分区域,因此需要多次接触才能形成完整的几何模型,而多次局部形状的对齐过程既复杂又耗时。
另一方面,基于视觉模态的几何估计方法也会受到视觉遮挡与光照变化的影响。
通过结合视觉与触觉模态,可以在几何形状估计中同时获得全局但粗糙的信息 (视觉提供)和局部但高精度的信息 (触觉提供)。触觉-视觉融合具有两方面优势:其一,引入视觉模态可以减少触觉探索次数,从而缩短形状估计时间;其二,引入触觉模态可以缓解视觉遮挡与光照变化问题,提升几何估计质量。
常见的触觉-视觉几何形状估计方法通常先利用视觉模态获得物体的近似几何形状,再逐步引入触觉信息对形状进行更新,最终得到精确的三维模型。
Björkman 等人 10 提出了一种基于触觉-视觉模态的概率方法,利用高斯过程回归对物体形状进行估计:先通过视觉模态构建初始形状,再逐步加入触觉信息进行精细化。Wang 等人 121 将触觉信息引入三维物体形状感知任务,首先将视觉数据输入在形状库上预训练的神经网络中以预测物体的近似形状,然后利用触觉数据持续优化物体的三维结构。该方法仅需一张彩色图像和少量触觉探索即可有效构建常见物体的三维形状,并帮助机器人更好地完成抓取与操作任务。Xu 等人 134 提出了一种融合触觉与视觉模态的手-物体重建模型,能够支持对刚性与可变形物体的重建。
4.3 物体识别(Object Recognition)
物体识别是计算机视觉领域中的一个重要研究方向,基于视觉模态的物体识别已经形成了大量经典算法与数据集。在机器人感知领域,触觉常用于感知物体的硬度、材质、纹理与黏性等物理属性,从而辅助实现物体识别。触觉也可以在不显式建模物理属性的情况下直接用于物体识别。
在多模态物体识别中,触觉能够提供视觉模态无法获得的物理属性信息,将其与视觉信息相结合,可以更准确地识别物体,或解决仅依赖视觉信息难以处理的问题。Liu 等人 73 使用多变量时间序列模型表示触觉信号,并采用协方差描述子表示单张图像,进而提出一种基于核稀疏编码的触觉-视觉融合方法用于家庭物品分类,该方法不要求触觉与视觉模态之间的严格匹配。Yuan 等人 147 通过视觉与触觉的联合建模预测编织物的物理属性,并设计了多种跨模态训练的神经网络结构,实验表明联合使用视觉与触觉数据训练的模型优于仅使用视觉数据的模型。
Zheng 等人 161 提出了一种结合终身学习 与深度对抗学习 的跨视觉-触觉学习方法,使机器人能够通过跨模态检索自主地利用触觉传感器探索物体,并返回描述物体材料属性的图像集合。在终身学习设置下,该模型不仅能够保留先前任务中学到的知识,还能够利用累积知识帮助新任务学习或提升已有任务的性能。Lin 等人 72 提出通过匹配物体的触觉感知与视觉观测来进行实例级物体识别,具体而言,模型被训练用于判断给定的视觉观测是否与机器人当前的触觉读数来自同一物体。
一项有趣的触觉-视觉物体识别研究来自文献 32,作者通过迁移学习,将模型在视觉模态中学到的物体分类知识迁移到触觉模态中,从而利用视觉先验与触觉信息实现物体分类。需要分类的物体仅在视觉上被观察过,而从未被触摸。Li 等人 62 提出了一种基于 Transformer 的触觉-视觉融合机制,通过缓解视觉与触觉信息差异显著提升了物体识别精度。Wang 等人 117 提出了一种基于**孪生网络(Siamese Network)**的触觉-视觉融合模型,通过引入对比结构并测量子网络之间的距离来实现物体识别。
4.4 触觉-视觉生成(Touch-Visual Generation)
请设想这样一个场景:仅通过触摸杯子,我们便能在脑海中形成其大致外观;或者通过观察杯子,我们也能推断其触感。这种一种感官刺激引发另一种感官体验 的现象在心理学中被称为联觉(synesthesia)。那么,机器是否也能像人类一样产生联觉反应?
近年来,一些研究表明触觉与视觉之间可以实现相互生成。Li 等人 68 研究了视觉与触觉模态之间的关系,采集了成对的视觉与触觉数据,并提出了一种新的条件生成对抗网络模型。实验结果表明,该模型能够从触觉数据生成真实的视觉图像,反之亦然。Takahashi 等人 110 提出了一种深度触觉-视觉学习模型,能够利用视觉模态估计物体的触觉属性(如粗糙度)。该模型采用编码-解码结构,并通过无监督学习将触觉与视觉嵌入到连续潜在空间中,可在已知触觉属性的基础上扩展到对未知材料触觉属性的估计。
Lee 等人 61 提出了一种基于条件生成对抗网络的跨触觉-视觉生成模型,能够根据不同织物的视觉图像生成对应的触觉图像,反之亦然。评估结果表明,生成模态数据与原始模态数据在结构相似性上具有较高一致性。Yang 等人 138 将潜在扩散模型(latent diffusion model)应用于触觉到图像(以及反向)的生成任务,在触觉驱动的风格化问题上优于以往方法。不同于上述双向生成方法,Gao 等人 39 提出了一种条件生成模型,能够在给定草图、前景掩码以及像素位置编码的情况下,同时生成视觉与触觉图像。
5 深度-视觉(Depth-Visual)
随着深度传感器成本的不断降低,人们开始将深度传感器与普通相机相结合,构建各种 RGB-D 相机 ,从而能够同时获取高质量的视觉(RGB)图像与深度图。将二者联合建模,可以显著提升在物体识别、物体检测、三维重建、活动识别以及显著性检测 等任务中的性能。尽管深度-视觉数据为物体描述提供了丰富的多模态信息,但如何合理表示各个模态并有效融合两种模态 仍是一个尚未完全解决的挑战。目前,基于深度-视觉的多模态机器学习已从传统的手工特征方法 发展到基于深度学习的先进方法。
5.1 物体检测与识别(Object Detection and Recognition)
基于 RGB 的物体识别方法已经取得了良好效果,并发展成为较为成熟的研究领域。然而,由于 RGB 图像本质上是三维世界到二维空间的投影,仅依赖 RGB 模态不可避免地会造成信息丢失。同时,随着视角、光照和遮挡条件的变化,物体外观也会发生显著变化。为弥补这些不足,引入深度图像作为补充信息是一种有效手段。深度信息不受光照与颜色变化的影响,能够更好地区分前景与背景,并提供纯粹的几何与形状线索。因此,在特定场景下,结合 RGB 与深度模态能够显著提升物体识别性能。
基于手工特征的方法通常需要对特定领域具备深入理解,并且当数据类型发生变化时需要不断更新特征设计。Paulk 等人 85 从深度模态中提取几何与体积特征,从 RGB 模态中提取颜色特征,并将所有特征直接拼接后输入 AdaBoost、SVM 和 ANN 进行对比实验。Browatzki 等人 12 从 RGB 图像中提取 SURF、方向梯度直方图金字塔、自相似特征以及 CIELAB 颜色直方图四类特征;同时从深度图像中选取形状指数直方图、形状分布、深度缓冲区以及 3DSC 四类深度特征,最终融合所有多模态特征并使用 SVM 进行分类。
为减少对手工特征的依赖,研究者提出了一系列基于特征学习的方法,能够直接从原始数据中学习 RGB-D 特征。Bo 等人 11 采用两层分层匹配追踪(Hierarchical Matching Pursuit, HMP),分别从灰度、深度、RGB 以及表面法线通道中学习特征,并将其拼接后输入 LinSVM 进行训练与分类。主成分分析(PCA)及其变体也被广泛应用于 RGB-D 物体识别中。Sun 等人 108 将 PCA 与典型相关分析(CCA)相结合,构建了一个两级滤波层,其中一层通过 PCA 学习特征,另一层通过 CCA 最大化模态间相关性。
随着卷积神经网络(CNN)强大表征能力的展现,其已逐渐取代传统特征学习方法,成为 RGB-D 多模态机器学习的主流方案。Asif 等人 7 指出,RGB-D 数据在实际应用中面临类别间相似度高、类别内差异大、视角变化、光照变化、遮挡以及背景杂乱等挑战。为此,作者提出了一种具有空间不变性和 Fisher 编码正则化的多模态可判别空间不变 CNN(MDSI-CNN),用于在图像级与像素级学习多模态特征。为寻找更优的多模态分类网络结构,Vielzeuf 等人 87 提出了一个覆盖大量融合架构的通用搜索空间,并设计了一种高效的序列模型搜索方法,可针对不同数据集自动定制网络结构,验证了多模态融合在神经网络结构搜索中的有效性。
为在模态之间建立长程注意力关系 ,Xiao 等人 130 提出了 MCTNet,该网络由 MFP 与 CMTrans 模块组成,用于跨模态特征融合与长程依赖建模。不同于上述二维目标检测方法,Piekenbrinck 等人 89 提出了一种 RGB-D 三维物体检测模型,用于在室内场景中检测三维目标。
5.2 场景识别(Scene Recognition)
场景识别是指对图像或视频中出现的场景进行识别与分类。基于 RGB 的场景识别方法已经取得了令人瞩目的性能。由于深度信息能够提供有价值的物体边界与空间布局信息,研究者开始将深度模态作为 RGB 的补充用于场景识别。因此,与单模态 RGB 场景识别方法相比,基于 RGB-D 的场景识别方法通常具有更优性能。
由于 RGB 与深度图像在编码形式上的相似性,以及深度数据集规模相对较小,常见的 RGB-D 场景识别方法是:将在 RGB 数据集上预训练的网络微调到深度数据集上以获取深度特征,然后与 RGB 特征融合进行场景识别。然而,通过这种方式获得的深度特征是否真正具有强判别能力,仍是一个有待讨论的问题。Song 等人 104 采用两阶段训练策略,并证明弱监督预训练阶段相比直接微调与迁移方法,能够帮助网络学习到更有效的深度特征。
Du 等人 30 将跨模态翻译与场景识别任务统一到一个框架中,使翻译网络与识别网络共享编码器,并利用成对的 RGB-D 图像训练翻译网络,从而提升共享编码器的表示能力。编码器跨模态表征能力的增强,能够进一步提升 RGB 或深度单模态网络的场景识别性能。Xiong 等人 133 发现,RGB 与深度模态中局部物体之间的相关性强于背景区域,因此利用这种相关性分布有助于网络提取更优的局部语义特征,从而实现具有更大空间变化的室内场景分类。Guo 等人 44 将跨模态匹配与识别任务相结合,提出了一种"匹配到识别(matching-to-recognition)"方法,通过跨模态匹配网络引入分层语义损失,从而增强识别网络的表示能力。
目前,相当一部分 RGB 场景数据集直接来源于互联网;而由于深度相机具有较强的专业性(更偏向特定任务或专业设备),在互联网中获取匹配的 RGB-深度数据较为困难,这导致 RGB-D 数据集规模远小于 RGB 数据集。例如,2017 年发布的 RGB 场景识别数据集 Places 162 已达到 1000 万级别 ,而现有较大的 RGB-D 场景识别数据集规模通常仅为数十万级别。因此,构建更大规模的 RGB-D 场景数据集仍是该领域的迫切需求。
5.3 三维重建(3D Reconstruction)
三维重建任务需要满足两个基本要求:正确的物体几何结构 以及高保真的纹理质量。有监督的三维重建方法依赖于大量训练数据,而对重建精度的高要求又使得对数据准确性的要求极为严格。然而,消费级深度相机采集的深度数据通常包含大量噪声,加之扫描视角受限导致的缺失区域,使得重建结果往往存在几何不完整和表面细节模糊的问题。
一些研究利用大规模合成数据集进行三维重建,并取得了令人印象深刻的结果 127,但在真实场景中的泛化性能仍存在不足。为解决三维表面扫描与重建过程中由于遮挡和缺失带来的问题,Dai 等人 26 结合自监督方法与稀疏生成神经网络,实现了高质量的完整三维场景重建,其性能优于最先进的有监督方法。
部分 RGB-D 重建方法仅将 RGB 像素值直接映射到对应的深度几何上,往往导致重建物体的纹理模糊,并忽略了几何误差与相机位姿漂移问题。为提升 RGB-D 三维重建中的纹理一致性,Fu 等人 37 提出了三向相似性纹理合成方法,在 RGB 模态之外引入颜色图像的纹理细节层作为额外上下文信息,从而增强方法的有效性与鲁棒性。
Kawana 等人 53 进一步研究了一个更具挑战性的任务------日常可关节物体的形状重建 。由于此类物体由多个部件组成且结构多样,其形状变化范围极大。不同于直接基于实例学习的方法,作者提出了一种"先检测、再分组(detect-then-group)"的策略,以处理具有不同部件结构和数量的实例。
5.4 活动识别(Activity Recognition)
在第 2 节中,我们讨论了利用音频与视觉模态 进行活动识别的方法。本节将重点介绍RGB 与深度模态 在活动识别中的应用。在基于 RGB-D 的活动识别中,深度模态能够提供关键的三维结构信息 ,而 RGB 模态则提供丰富的纹理与颜色信息。两种模态之间的互补性可以显著提升活动识别性能。
早期的大多数 RGB-D 活动识别方法通常将深度模态与 RGB 模态视为独立通道 ,采用双流网络结构 分别提取各自特征,并在后续阶段进行融合以实现活动识别。Wang 等人 120 提出了一个协同训练的单一卷积神经网络(c-ConvNet),通过联合优化同构模态与异构模态的损失函数,增强特征的判别能力并减弱不同模态之间的差异。
此外,也有研究者从 RGB-D 数据中提取场景流(scene stream)用于活动识别。与分别处理并融合各模态的方法相比,场景流能够提取物体真实的三维运动信息,同时保留 RGB 与深度模态中的空间结构信息。Jia 等人 51 提出了一种半监督迁移学习方法,可将完整 RGB-D 数据集中的有用知识迁移到不完整的目标数据集中,从而解决某一模态缺失时的活动识别问题;通过在目标域中恢复缺失模态信息,模型的活动识别性能得到进一步提升。
为缓解时空建模的复杂性,Ma 等人 77 提出了多阶段时空分解架构。该方法由一个三维中心差分卷积(3D central difference convolution)主干模块以及多个因式分解的时空阶段组成,能够实现细粒度时间感知与层次化时空表示。
5.5 手势识别(Gesture Recognition)
手势识别是指对人体手部动作进行识别,其识别结果在一定程度上可以替代传统的物理输入设备,如鼠标和键盘等。近年来,随着机器在手势识别任务上的识别精度不断提升,手势识别已成功应用于人机交互、手语识别、游戏以及虚拟现实控制等领域。
基于 RGB 的手势识别方法易受到光照变化与背景干扰的影响,导致性能受限。随着大量 RGB-D 相机的出现以及 RGB-D 数据采集成本的逐步降低,利用 RGB-D 多模态数据进行手势识别已成为该领域的研究热点。2014 年,Escalera 等人 31 发起了多模态手势识别挑战赛(Multimodal Gesture Recognition Challenge),并发布了包含 RGB 图像、深度图像、骨架模型以及音频信息的数据集。
Zhu 等人 168 提出了一种基于 3D CNN 与卷积 LSTM 的双流网络 ,其中 3D CNN 用于提取短期时空特征,卷积 LSTM 用于提取长期时空特征。为更充分挖掘 RGB 与深度信息,Tian 等人 112 提出了一种多模态、多层级特征提取方法,显著提升了手势识别准确率。
上述方法多聚焦于孤立手势识别 ,而在实际应用中,手势变化往往是连续的。为更好地识别连续手势,Wang 等人 119 将连续手势识别任务分解为两个模块:分割模块首先将连续手势划分为手势帧与过渡帧 ,随后识别模块仅对手势帧进行识别。以往方法通常忽略了无关线索的干扰,从而影响识别性能。Li 等人 67 提出了一种不受手势无关因素影响的特征表示框架,通过信息损失函数提取更充分且紧凑的表示,从而缓解无关信息的影响。
Garg 等人 40 提出了一种基于 Transformer 的手势识别模型 ,结合多尺度池化与小波变换以增强模型对手势长期依赖的理解能力。值得注意的是,RGB 与深度模态同样可用于手势分割。Wang 等人 126 提出了带有终身学习机制的 CatNet 模型,使模型在记住旧手势样本的同时,能够更高效地学习新的手势样本。
尽管基于 RGB-D 的手势识别方法在准确率上普遍优于仅基于 RGB 的方法,但在实际应用中,由于引入了额外模态信息,多模态手势识别方法往往需要更多的存储空间、处理模型以及计算时间。因此,在保证实时性的前提下,多模态手势识别方法对设备性能提出了更高要求。
5.6 显著性检测(Saliency Detection)
视觉显著性检测旨在从视觉场景中将最显著(最吸引注意力)的对象 从背景中分离出来,从而在一定程度上减少背景干扰,并为后续视觉任务提供有效的目标信息。基于 RGB 图像的显著性检测方法已经取得了良好效果,但由于真实世界场景复杂多变(如显著目标与背景对比度较低),其应用仍受到限制。因此,基于 RGB-D 的显著性检测引起了研究者的广泛关注,并涌现出大量相关工作 88, 124, 152。
Zhang 等人 152 采用双流网络分别提取 RGB 与深度模态特征,并设计了一个可进行跨模态互补探索的交互模块 ,能够有效融合跨模态特性,并通过补充丰富的边界信息来增强各模态表现。此外,作者引入了补偿感知损失(compensation perception loss),进一步挖掘多模态特征中的结构信息,从而在具有挑战性的场景中保持显著性检测的高稳定性。
然而,双流网络结构 152 会带来额外的计算开销与内存消耗,同时深度数据的获取也增加了硬件成本,可能限制其实际应用。为此,Piao 等人 88 提出了 深度蒸馏器(deep distiller),能够将深度模态中学到的知识迁移到视觉模态中,并在测试阶段仅使用 RGB 数据完成显著性检测,在大幅减小模型规模的同时取得了最先进性能。
此外,大多数双流网络仅在最深层对 RGB 与深度特征进行融合,忽略了自顶向下的多模态特征交互 。针对这一问题,Feng 等人 34 提出了一种深度交织模型 ,在模型整体结构中实现自顶向下的跨模态融合与交互,从而提升检测性能。不同于上述确定性建模方法,Zhang 等人 151 指出人类对视觉显著目标的感知具有一定的主观性或不确定性,现有方法难以刻画这种随机特性,因此提出了基于条件变分自编码器的 UC-Net 模型,能够刻画不确定性并生成不同的显著性预测结果。
为缓解模型对大规模 RGB-D 数据集的依赖,Wang 等人 124 提出利用无标注 RGB 图像增强 RGB-D 显著性检测,并提出了 DS-Net,在半监督设置下验证了模型潜力。不同于直接融合 RGB 与深度模态的方法,Yao 等人 140 通过将深度图直接注入编码器来增强 RGB 模态的语义信息,该方法具有较高的计算效率。
RGB 与深度模态的互补性显著提升了显著性检测性能,但当某一模态缺失或质量较低时,原本表现良好的方法往往会失效。这种问题在多模态研究中普遍存在,并不仅限于 RGB-D 场景。对于多模态显著性检测而言,一个直观的解决思路是为缺失模态寻找替代模态 。例如,视听显著性检测 已被广泛研究 118。因此,一种理想的方案是利用音频模态来替代缺失或受限的模态,从而在保证多模态联合模型性能的同时,进一步提升其稳定性。
6 超越双模态学习(Beyond Bimodal Learning)
多模态机器学习长期以来主要聚焦于双模态(bimodal)研究。近年来,随着大规模预训练模型 (如 CLIP 57、ImageBind 42、EVA-CLIP 107)以及大语言模型 (如 LLaMA 113、Flamingo 2、ChatGPT)的快速发展,将它们与多模态任务相结合受到了广泛关注,研究范式逐渐超越了传统的双模态组合学习。
大规模预训练模型为多模态任务带来了强大的表示能力与零样本(zero-shot)能力,而大语言模型则被视为"大脑 ",用于执行各类多模态任务,并展现出令人惊叹的理解与推理能力。相比于传统的直接注入新模态的方法 63,本节主要介绍基于多模态对比预训练模型 与大语言模型的方法,这类方法在性能上已达到当前最先进水平。
6.1 多模态对比预训练模型(Multimodal Contrastive Pre-Trained Models)
多模态对比预训练模型通过大规模多模态对比学习 来学习不同模态数据之间的联合表示。利用对比预训练模型将系统扩展到更多新模态,是一种行之有效的途径。Wu 等人 128 提出了一种从大规模预训练模型 CLIP 中提取音频表示的方法,将音频投影到与图像和文本共享的嵌入空间中,从而实现了音频任务的扩展。Huang 等人 49 提出了一种图像-深度对比学习预训练方法,将 CLIP 的知识从二维域迁移到三维域,在零样本、少样本以及全监督点云分类任务中均取得了最先进的结果。类似地,Deng 等人 28 将多模态预训练模型的知识迁移到点云模态,通过将点云表示与预训练的视觉-语言模型对齐,实现了先进的动作识别性能。
Fu 等人 36 利用对比预训练模型,通过触觉-视觉 与触觉-语言 的成对对齐来实现三种模态的联合表示学习。所学习到的触觉编码器显著提升了分类准确率以及多模态理解能力。
相较于仅扩展单一新模态的方法 36,Girdhar 等人 42 提出了 ImageBind ,一种能够学习六种不同模态的联合表示学习方法。该方法利用大规模视觉-语言模型,通过不同模态与图像之间的自然配对,将零样本能力扩展到新模态。ImageBind 构建的多模态共享表示空间,使得其他方法能够更加便捷地集成更多新模态。Yang 等人 137 进一步将触觉与视觉、语言和声音统一起来,通过将触觉嵌入与 ImageBind 中预训练的视觉嵌入进行对齐,使模型能够在零样本条件下完成多种触觉感知任务。
6.2 大语言模型(Large Language Models)
将大语言模型(LLMs)引入多模态学习已成为一种日益流行的趋势。大语言模型被用作执行多种多模态任务的"大脑 ",并展现出极强的响应能力与推理能力 144。Zhang 等人 149 提出了 Video-LLaMA1 框架,该框架利用冻结的音频与视觉预训练编码器,并通过与大语言模型的跨模态训练,实现了对视听内容的联合理解。Ye 等人 143 提出了一种音视语言模型,通过在音频 VQA 任务中聚合动态视听场景中的问题线索,丰富了大语言模型的知识表示。
Sun 等人 106 提出了一种细粒度视听表示联合学习框架 ,基于大语言模型实现多模态理解与推理,可应用于声音定位和视觉问答等任务。为提升模型的空间理解能力,Cai 等人 14 将 RGB 与深度模态投影为 token,并输入到大语言模型中,在视觉识别、空间理解以及机器人操作等任务上表现出色。Cheng 等人 22 提出了深度-语言连接器(depth-language connector),将深度信息映射到视觉大语言模型的语言空间中,从而增强模型对复杂空间的感知与推理能力。
通常而言,超越双模态的研究 依赖于更多模态之间的数据对齐,但这类数据集的规模往往远小于双模态数据集。多模态对比预训练模型与多模态大语言模型的出现,在一定程度上缓解了数据对齐的难题。例如,在语言-图像预训练模型中,图像可被视为连接其他新模态的中介 ,因为与图像配对的其他模态数据通常更容易获得。因此,只要新模态能够与图像对齐,便可间接与文本模态交互,而无需显式依赖文本数据。此外,多模态大语言模型的出现使得文本模态更加易于获取,利用大语言模型生成缺失的文本模态也成为一种可行方案。
7 其他模态(Other Modalities)
本文围绕五种常见模态,系统梳理了多模态机器学习在模态组合方式 与应用场景 方面的研究进展。在本节中,我们进一步补充三类同样重要但相对独立的模态,分别是热红外模态(thermal modality) 、点云模态(point cloud modality)以及事件流模态(event modality)。
(1)热红外模态(Thermal Modality)
在具有相似纹理或暗背景的场景中,RGB 图像往往难以为模型提供具有判别力的信息。与深度模态类似,热红外模态能够为 RGB 图像提供关键的补充信息,尤其在夜间或光照不足的环境 中具有不可替代的重要性。热红外信息反映的是物体的温度分布,与可见光成像机制本质不同。由于热红外模态通常以灰度图像 的形式存在,因此可以直接复用现有的视觉模型进行处理。
RGB-T(RGB + Thermal)多模态学习已被广泛应用于目标跟踪、视觉显著性检测、语义分割以及人群计数等任务中 111,并在复杂光照条件下展现出显著优势。
(2)点云模态(Point Cloud Modality)
在受光照条件限制的环境中,点云模态同样可以为 RGB 图像提供重要的补充信息。与 RGB 相机和热红外相机相比,LiDAR 设备的成本与维护费用较高 ;同时,其数据结构也与图像存在本质差异,表现为稀疏的三维点集 而非规则的二维像素网格。
尽管如此,LiDAR 能够提供高精度的三维空间分辨能力 ,在探测距离与测量精度方面具有显著优势。因此,RGB-点云多模态方法在视觉显著性检测 与三维目标检测等任务中表现出良好的应用潜力 84。
(3)事件流模态(Event Stream Modality)
事件流模态是一种由事件相机(event camera)记录的异步数据流,用于反映像素亮度随时间的变化。与传统视觉模态相比,事件流模态具有高动态范围、高时间分辨率以及无运动模糊等优势,特别适用于高速运动或强光变化的动态环境。同时,事件流模态仅保留前景运动信息,避免了大量冗余的视觉数据。
然而,事件流模态在时间和空间上通常是异步且稀疏的 ,这也为其建模带来了新的挑战。尽管如此,事件流模态已在目标分类、活动识别、手势识别以及步态识别 等任务中取得了成功应用 125。其与其他视觉模态的结合也进一步验证了该模态的独特优势。因此,事件流模态在多模态场景中仍具有广阔的应用前景,例如视频摘要、视频超分辨率、视频生成、声音分离、声音空间化以及手语识别等方向。
8 展望未来(Look into the Future)
多模态机器学习仍处于发展初期阶段 。各类传感器的不断涌现以及互联网数据的爆炸式增长,使得多模态数据的获取变得更加便捷且成本更低;与此同时,硬件计算能力的提升、深度学习技术的成熟以及大语言模型(LLMs)的快速演进,极大推动了多模态学习的发展。由于多模态机器学习更接近人类的多感官协同活动,它被认为是最具前景的人工智能方向之一。然而,多模态机器学习仍面临诸多挑战,这些挑战主要来源于模态间的内在差异、主流深度学习方法的黑箱特性,以及多模态大语言模型所带来的巨大规模与高昂成本。
(1)从模态本身来看 ,不同模态在数据获取方式与表达形式上的差异,决定了它们之间存在显著的异构鸿沟。具有相似表示形式的模态更容易进行交互,而表示差异较大的模态则更难协同建模。因此,为不同模态构建在结构或语义上更相似的表示形式,是提升多模态学习性能的关键问题之一。
(2)从实际应用角度来看 ,多模态数据仍面临诸多现实问题,例如模态对齐(modal alignment) 、模态退化(modal degradation) 、**模态缺失(modal missing)以及模态不匹配(modal matching)**等。这些问题都会直接影响多模态系统的准确性与鲁棒性。
(3)从模态组合角度来看 ,当前大多数多模态研究仍聚焦于双模态 ,且通常以视觉模态为核心。未来,多模态研究很可能不再局限于双模态场景。因此,视觉模态有望成为多模态机器学习的核心骨架,并作为连接其他模态的桥梁,在多模态系统中发挥关键作用。
(4)从模型发展趋势来看 ,大语言模型与大规模对比预训练模型的出现,显著拓展了多模态学习的边界。多模态学习与大语言模型的结合,使人们看到了通用人工智能(AGI)的曙光。学术界与工业界已投入大量资源,加速多模态大语言模型的研发与落地应用。然而,这也带来了新的问题,例如巨大的能耗与碳排放压力 ,对环境构成潜在挑战;此外,幻觉(hallucination)问题作为大语言模型的共性缺陷,仍持续困扰多模态大语言模型的发展。
当前,多模态学习中显式建模不同模态之间关系 仍是一个尚未解决的问题。现阶段,深度学习方法仍是多模态研究的主流技术路线,但其黑箱特性使得我们难以从建模过程中直接解析模态之间的关系。现有方法多依赖大规模跨模态对比学习来建立模态关联,但这种关系往往是隐式的、缺乏可解释性 的;同时,它们仅基于已有大规模数据进行学习,仍然缺乏足够的全面性与灵活性。为此,研究者不断构建规模更大、结构更复杂的数据集,以期提升模型的泛化能力,但这种做法在一定程度上属于治标不治本。
多模态机器学习需要庞大的多模态与跨模态知识体系 ,仅依赖模态间的自学习机制可能仍然不足。我们认为,一种可行的发展路径是构建可持续演化的多模态知识库,并通过不断扩展知识库来提升多模态机器学习系统的整体性能。
随着大型多模态语言模型的发展,具身智能(Embodied Intelligence)正在迅速兴起。具身智能强调机器具备感知、理解并模仿人类行为的能力 ,其核心不在于单纯的计算或推理能力,而在于机器是否能够像人类一样感知世界并与环境交互。目前,一些科研机构和高校已开始将具身智能的研究成果应用于实践。例如,Google 提出的具身多模态大语言模型 PaLM-E,能够处理来自不同模态的多种具身推理任务,并在多项任务上表现优异 29。
当前,多模态大语言模型通常部署在云端。然而,随着云端计算成本的上升以及时延问题的凸显,在移动设备等本地端部署高效的多模态大语言模型 的需求日益迫切。因此,多模态大语言模型的轻量化与可移植性,将成为未来实现具身智能的关键问题之一。
最后需要指出的是,尽管大量研究报告了通过联合使用多模态数据所带来的性能提升,但也有研究发现,深度学习在多模态场景中的表现并不总是理想 122。具体而言:
(1)在某些情况下,使用多模态数据训练的神经网络性能反而不如单模态模型 ;
(2)即便多模态神经网络整体性能较好,仍可能存在模态层面学习不足 的问题。其根本原因在于,神经网络往往无法均衡利用各个模态,甚至会忽略某些模态,从而导致过拟合并降低泛化能力 86。
因此,一种常见的解决思路是为多模态神经网络设计专门的优化策略,以控制不同模态的学习速度并平衡其相互关系。**模态平衡学习(modal balance learning)**作为多模态研究中的一个核心问题,必将长期受到关注。
9 结论(Conclusion)
多模态机器学习是一门高度动态的交叉学科领域 ,其目标是构建能够处理并关联多种模态信息的模型。作为人工智能的重要发展趋势之一,本文对多模态机器学习进行了系统而全面的综述。
具体而言,本文围绕多模态研究中的5 种常见模态 、4 类模态组合方式 、20 余种应用场景 以及约 120 个多模态数据集 展开了系统梳理;同时,我们还补充讨论了 3 种重要模态------热红外模态、点云模态与事件流模态。最后,本文总结了多模态机器学习面临的关键挑战,并展望了其未来发展趋势。
我们希望本文能够为特定模态研究者 与特定任务研究者 提供有价值的参考与启发,并为相关领域未来的研究工作指明方向、提供思路。
🌟 在这篇博文的旅程中,感谢您的陪伴与阅读。如果内容对您有所启发或帮助,请不要吝啬您的点赞 👍🏻,这是对我最大的鼓励和支持。
📚 本人虽致力于提供准确且深入的技术分享,但学识有限,难免会有疏漏之处。如有不足或错误,恳请各位业界同仁在评论区留下宝贵意见,您的批评指正是我不断进步的动力!😄😄😄
💖💖💖 如果您发现这篇博文对您的研究或工作有所裨益,请不吝点赞、收藏,或分享给更多需要的朋友,让知识的力量传播得更远。
🔥🔥🔥 "Stay Hungry, Stay Foolish" ------ 求知的道路永无止境,让我们保持渴望与初心,面对挑战,勇往直前。无论前路多么漫长,只要我们坚持不懈,终将抵达目的地。🌙🌙🌙
👋🏻 在此,我也邀请您加入我的技术交流社区,共同探讨、学习和成长。让我们携手并进,共创辉煌!
