1. Elasticsearch 架构总览
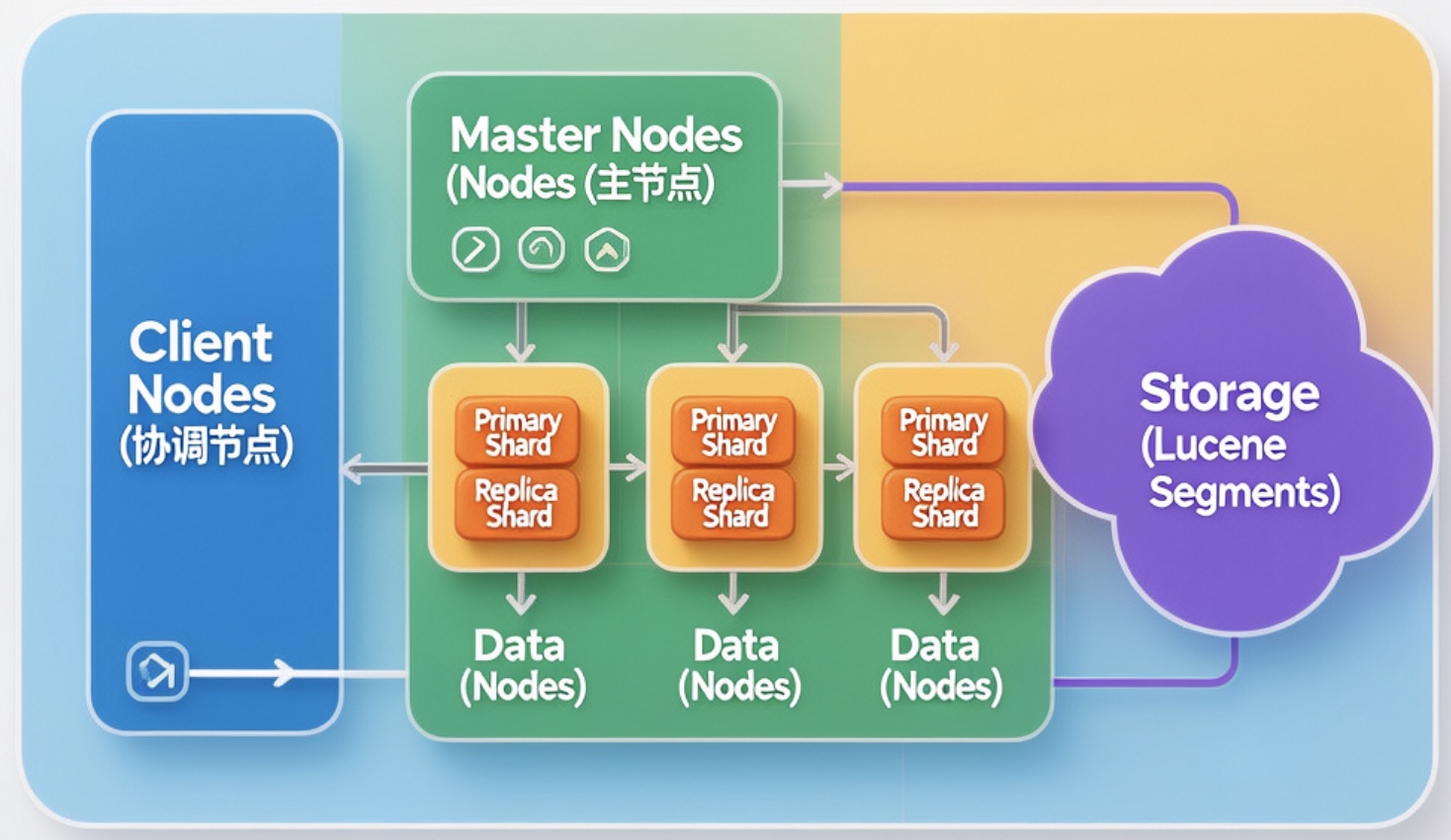
Elasticsearch的设计核心是水平扩展、高可用与近实时搜索。其架构是一个层次化的分布式系统,是分布式搜索的基石,我们可以通过下图理解其全貌:
解读:
- 去中心化的外部视图:对客户端而言,与集群中任何节点通信等价于与整个集群通信。协调节点(任何节点都可承担)负责接收请求、路由到正确数据节点并聚合结果。
- 中心化的内部管理 :集群内部有明确的主节点(由具备
master角色的节点选举产生),负责索引创建、分片分配、节点发现等集群级操作,但其不参与具体的数据读写,避免成为性能瓶颈。 - 数据分片与副本 :这是实现水平扩展 和高可用的核心。一个索引(Index)被划分为多个主分片(Primary Shard),每个分片都是一个完整的、独立的Lucene索引。分片可分布在不同数据节点上,实现存储与计算能力的并行扩展。每个主分片可配置一个或多个副本分片(Replica Shard),提供数据冗余和读请求的负载均衡。
2. 核心实现原理
2.1 倒排索引
ES高性能搜索的基石是倒排索引,这是一种从词项(Term)到文档的映射,与传统数据库的正排索引(从文档到内容)相反。
正排索引 vs. 倒排索引:
正排索引 (低效扫描):
文档1 -> "我喜欢吃苹果"
文档2 -> "苹果和橙子是我的最爱"
查询"苹果": 需逐行扫描所有文档内容。
倒排索引 (高效查询):
"苹果" -> [文档1, 文档2]
"橙子" -> [文档2, 文档3]
查询"苹果": 直接定位词项,获取文档ID列表。- 构建过程 :文档写入时,ES会对文本字段进行分词,生成词项,并记录每个词项出现在哪些文档中及其位置信息。
- 数据结构优化 :词典(Term Dictionary)使用FST(Finite State Transducer) 等压缩数据结构存储;文档ID列表(Posting List)使用增量编码和位图压缩,极大节省存储空间并提升缓存效率。
2.2 近实时搜索
ES并非"实时"系统,而是"近实时"(NRT)。数据写入后约1秒可被搜索,这得益于其精巧的写入路径设计。
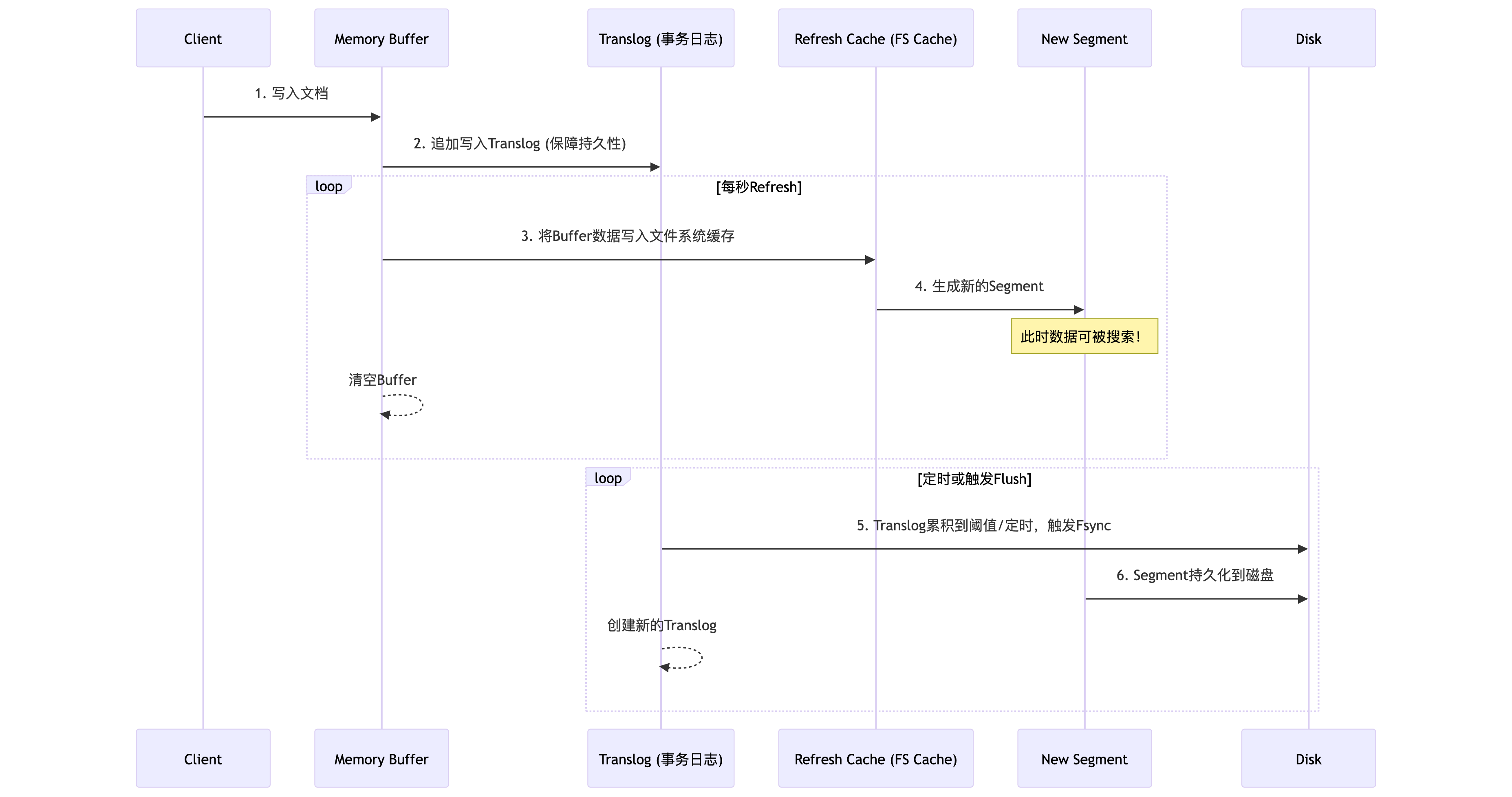
- Refresh :默认每秒一次,将内存缓冲区(Memory Buffer)的数据生成一个新的Segment (Lucene的最小索引单元)并打开,使其可被搜索。Segment一旦生成便不可变,这保证了缓存的高效性。
- Translog:类似于数据库的预写日志(WAL),保证在Refresh间隔内和Segment持久化前发生故障时,数据不丢失。
- Flush:当Translog大小或时间达到阈值,触发Flush,将文件系统缓存中的Segment持久化到磁盘,并清空旧的Translog。
2.3 分布式读写流程
2.3.1 写入流程
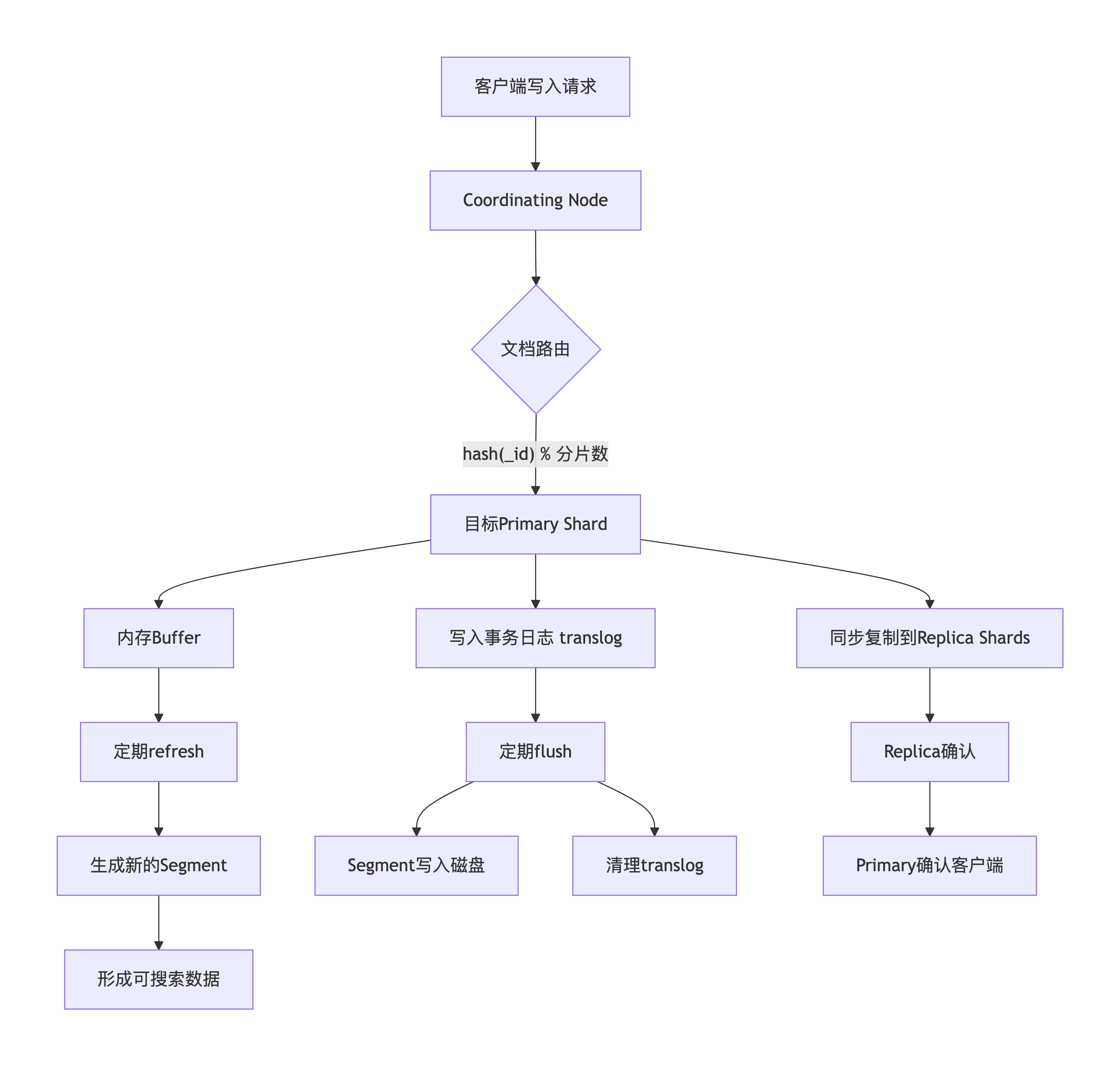
- 客户端向任一节点(协调节点)发送写入请求。
- 协调节点通过路由公式
shard = hash(routing) % number_of_primary_shards确定文档所属主分片。 - 请求被转发到该主分片所在的数据节点执行。
- 主分片写入成功后,并行将数据同步到所有副本分片。
- 待所有副本分片确认后,主分片向协调节点报告成功,协调节点再返回给客户端。
2.3.2 搜索流程(两阶段查询)
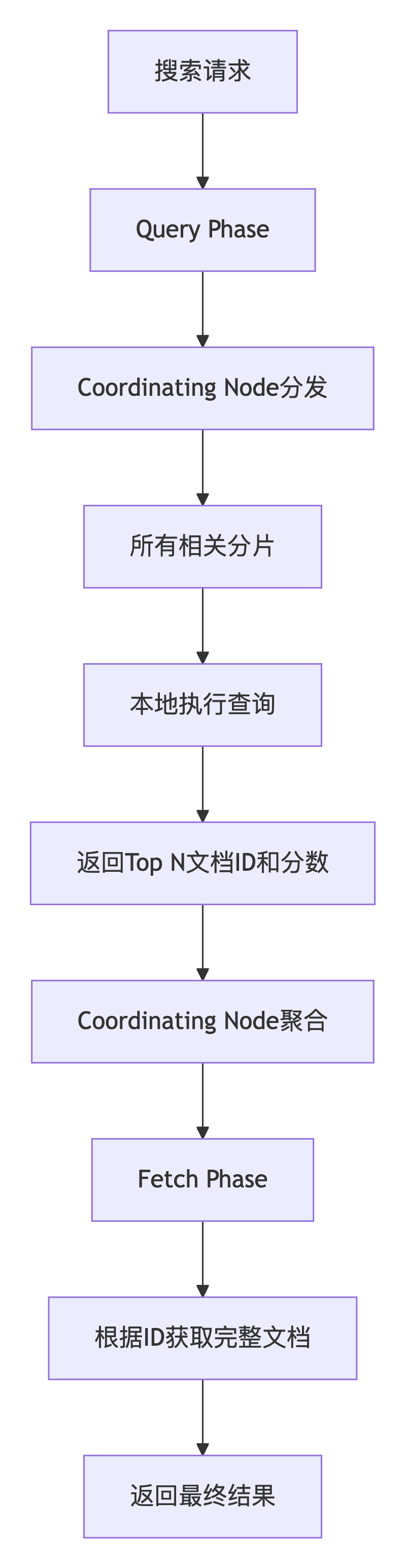
- Query Phase(查询阶段):协调节点将查询广播到所有相关分片(主分片或副本)。每个分片在本地执行搜索,构建一个包含文档ID和相关性分数的优先级队列,返回给协调节点。
- Fetch Phase(取回阶段):协调节点合并所有分片的结果,进行全局排序,然后向持有相关文档的分片发起第二次请求,获取完整的文档内容,最终组装返回给客户端。
3. 典型使用场景与解决的痛点
3.1 全文检索与复杂查询
- 痛点 :关系型数据库的
LIKE查询性能极差,无法支持多条件、模糊、权重评分等复杂搜索需求。 - 解决方案 :利用ES强大的倒排索引 和查询DSL,实现毫秒级的海量文本搜索。适用于电商商品搜索、内容平台文章检索、应用内搜索等。
3.2 日志集中管理与分析(ELK Stack)
- 痛点:分布式系统日志分散,排查问题如大海捞针;需要实时监控和历史回溯。
- 解决方案 :使用Filebeat/Logstash采集日志,写入ES建立集中索引。结合Kibana进行可视化查询、仪表盘构建和告警。ES的近实时特性 和强大的聚合能力完美契合此场景。
3.3 实时指标监控与业务分析
- 痛点:传统数据仓库分析延迟高,无法支持实时业务决策。
- 解决方案 :将应用指标、交易数据流式写入ES。利用其聚合框架 (如
terms、date_histogram、percentiles)实时计算PV/UV、交易额分布、响应时间分位数等。
3.4 地理位置查询
- 痛点:传统数据库对地理空间查询支持弱,性能差。
- 解决方案 :ES支持
geo_point和geo_shape字段类型,内置高效的地理空间索引和查询,轻松实现"附近的人"、"范围内的门店"等功能。
4. 生产环境常见问题与架构级解决方案
4.1 集群稳定性:脑裂问题
- 问题描述:网络分区或主节点负载过高导致集群中出现多个主节点,数据不一致,服务异常。
- 根因分析:部分节点与主节点失联后,自行发起选举产生新主。
- 解决方案 :
- 角色分离 :部署专用的主节点(
node.roles: [master]),避免与数据节点混布,防止资源竞争。 - 最小主节点数配置 :设置
discovery.zen.minimum_master_nodes(对于旧版本)或依赖新版本的内部仲裁机制。该值应设为(master_eligible_nodes / 2) + 1,确保只有获得多数票的节点才能成为主,从根本上防止脑裂。 - 优化网络与硬件:保证节点间网络稳定;为主节点配置稳定的CPU和内存。
- 角色分离 :部署专用的主节点(
4.2 写入性能瓶颈
- 问题描述:写入吞吐量低,写入延迟高。
- 根因分析与解决 :
- Refresh间隔过短 :默认1秒的Refresh会产生大量小Segment,增加合并压力。对于日志等可接受更高延迟的场景,可适当调大
refresh_interval(如30秒)以提升写入吞吐。 - 副本数影响 :写入需等待所有副本分片确认。在批量导入数据初期,可暂时将
number_of_replicas设置为0,导入完成后再调整回来,提升写入速度。 - Translog刷盘策略 :默认每次请求后都刷盘(
fsync)保证最强持久性,但影响性能。对于可容忍少量数据丢失的场景,可设置为异步(index.translog.durability: async)。
- Refresh间隔过短 :默认1秒的Refresh会产生大量小Segment,增加合并压力。对于日志等可接受更高延迟的场景,可适当调大
4.3 查询性能问题
- 问题描述:查询响应慢,聚合操作导致节点内存溢出(OOM)。
- 根因分析与解决 :
- 分片设计不当:单个分片过大(>50GB)导致数据迁移和恢复慢;分片过多则元数据开销大,查询合并成本高。建议单个分片大小控制在20-50GB,并提前做好容量规划。
- 深度分页 :
from+size方式查询靠后的页面时,协调节点需要合并和排序所有分片的前from+size条结果,开销巨大。应使用search_after或滚动查询(scroll)替代。 - 大聚合导致OOM :对高基数字段(如
user_id)进行terms聚合或进行深度嵌套聚合会消耗大量内存。需限制返回桶的数量(size),或使用cardinality聚合进行近似去重统计。
4.4 数据存储与运维
- 问题描述:磁盘空间增长过快,节点扩容与数据迁移复杂。
- 解决方案 :
- 使用索引生命周期管理(ILM):对时序数据(如日志)自动执行"热-温-冷-删除"策略,滚动创建新索引,自动迁移旧索引,控制存储成本。
- 索引模板与别名 :使用索引模板 统一新索引的配置;使用索引别名指向实际索引,实现底层索引的零停机切换与重建。
- 冷热数据分离架构:配置"热"节点(SSD,高性能)存储近期高频访问的数据,"温/冷"节点(HDD,大容量)存储历史数据,优化成本与性能。