VEQ: Modality-Adaptive Quantization for MoE Vision-Language Models
Authors: Guangshuo Qin, Zhiteng Li, Zheng Chen, Weihang Zhang, Linghe Kong, Yulun Zhang
Deep-Dive Summary:
VEQ:面向混合专家(MoE)视觉语言模型的模态自适应量化
摘要
混合专家(MoE)视觉语言模型(VLMs)表现卓越,但面临极高的内存和计算成本。训练后量化(PTQ)是解决该问题的有效技术。然而,现有的量化范式忽视了两种关键的异质性:视觉和语言 Token 之间的固有差异,以及不同专家贡献的不平衡。为此,本文提出了视觉专家量化(VEQ),这是一个双重感知的量化框架,旨在同时兼顾跨模态差异和专家间的异质性。VEQ 包含两个核心组件:
- 模态-专家感知量化(VEQ-ME):利用专家激活频率,为关键专家分配更高的误差最小化优先级。
- 模态-亲和力感知量化(VEQ-MA):通过整合 Token 与专家的亲和力以及模态信息来构建增强的 Hessian 矩阵,从而引导校准过程。
实验表明,在 W3A16 配置下,VEQ 在 KimiVL 和 Qwen3-VL 上相较于之前的 SOTA 方法分别实现了 2.04 % 2.04\% 2.04% 和 3.09 % 3.09\% 3.09% 的平均准确率提升。
1. 引言
随着对鲁棒多模态理解需求的增长,MoE 架构被广泛应用于领先的 VLM(如 DeepSeek-VL2、Kimi-VL、Qwen3-VL 等)。尽管 MoE 具有推理效率优势,但其巨大的参数量仍带来了内存压力。
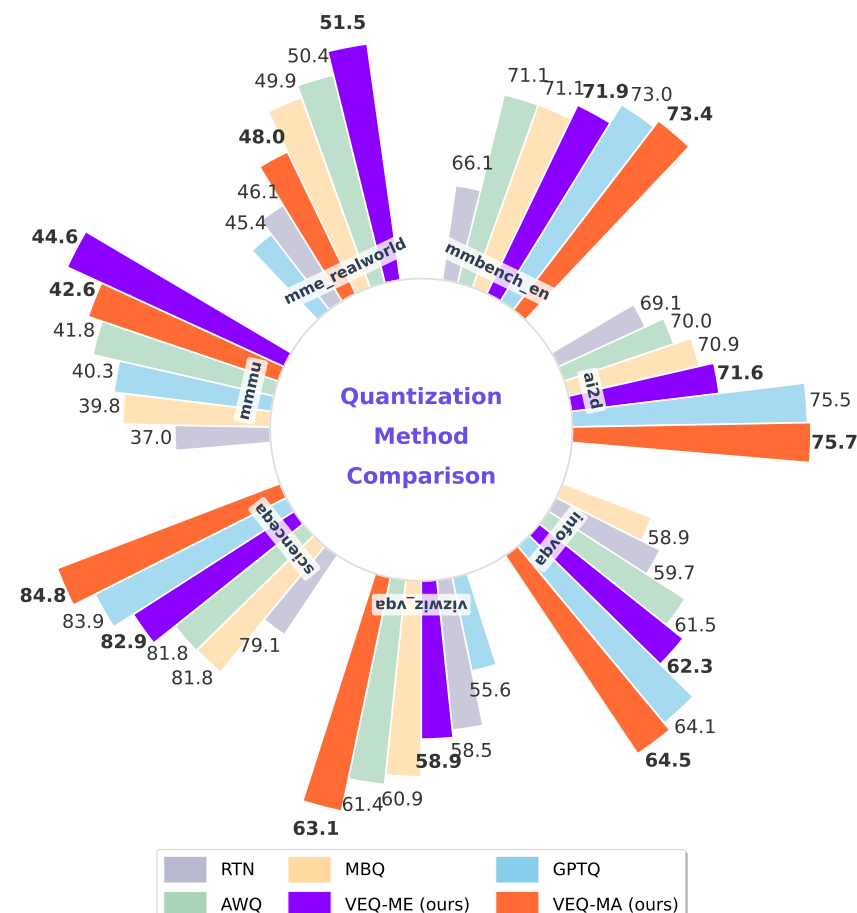
图 1. Kimi-VL-Instruct 在 3-bit 权重下(W3A16)的零样本性能。VEQ 在各基准测试中均优于现有基准。
传统量化方法(如 AWQ、GPTQ、MBQ)将模型视为单一的密集结构,忽视了 MoE 的结构稀疏性。如图 2 所示,少部分"热专家"被频繁访问并主导输出。此外,视觉 Token(空间冗余、连续)和文本 Token(语义密集、离散)在统计分布和量化敏感度上存在显著差异。
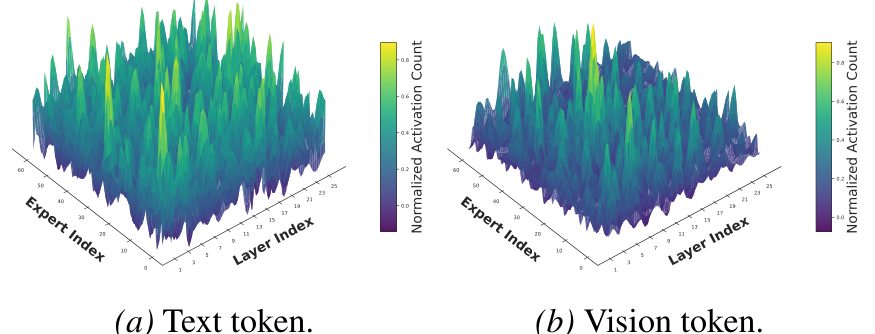
图 2. 不同模态激活特性的对比分析。峰值代表高激活频率。
VEQ 框架通过在多个挑战性基准(MMMU、MME-RealWorld 等)上的评估,证明了其在低比特设置下的优越鲁棒性。
2. 相关工作
2.1. VLM 量化
现有的 VLM 量化研究(如 VLMQ、Q-VLM、MBQ、MQuant 等)主要致力于解决视觉和文本模态间的分布异质性或识别 Token 的重要性,但在处理 MoE 架构独特的专家稀疏性方面仍有不足。
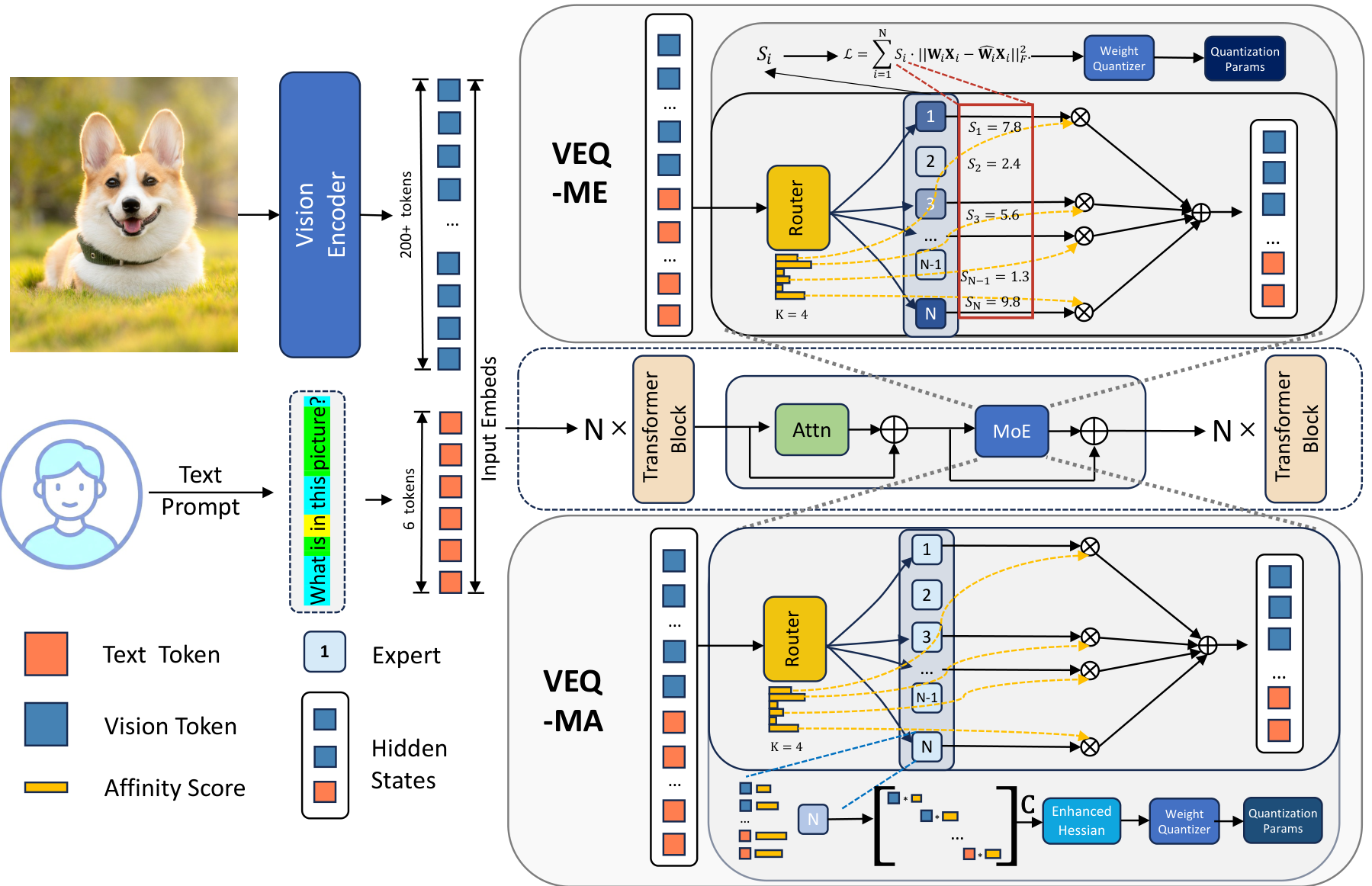
图 3. VEQ 框架概述。包含:(1) VEQ-ME:根据激活频率动态分配专家重要性评分 S i S_i Si;(2) VEQ-MA:整合 Token-专家亲和力和模态敏感度构建增强 Hessian 矩阵。
2.2. MoE LLM 量化
针对 MoE 架构的量化研究(如 MoEQuant、MoQE、MxMoE 等)侧重于解决专家负载不平衡和 Token 与专家间的亲和力问题。然而,这些方法通常未充分考虑多模态环境下的特殊需求。
3. 方法
3.1. MoE VLM 量化中的异质性分析
3.1.1. 模态异质性
通过 SFT 损失的梯度分析发现,文本 Token 的梯度幅值远高于视觉 Token(平均比值达 22.4 倍,见图 4)。这表明文本 Token 虽然数量较少,但在推理中起主导作用。
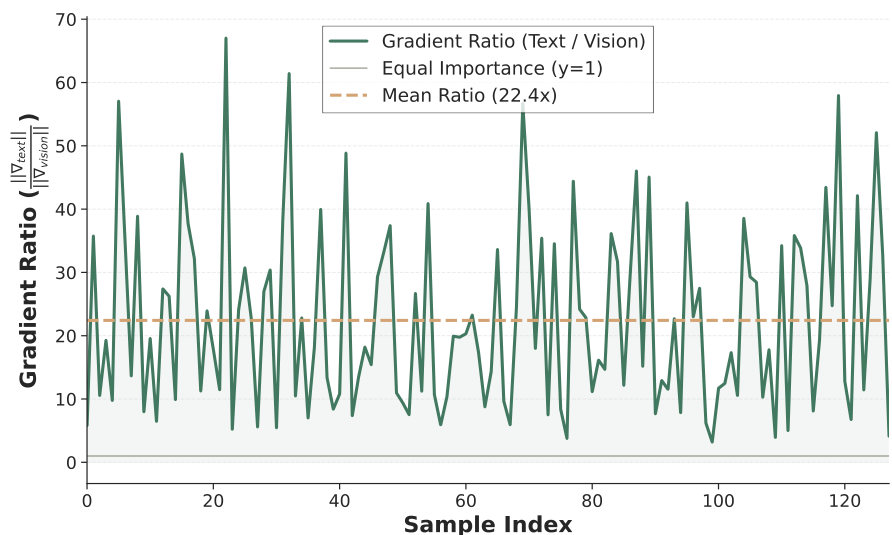
图 4. COCO 数据集上的梯度幅值分析。文本 Token 的梯度范数显著高于视觉 Token。
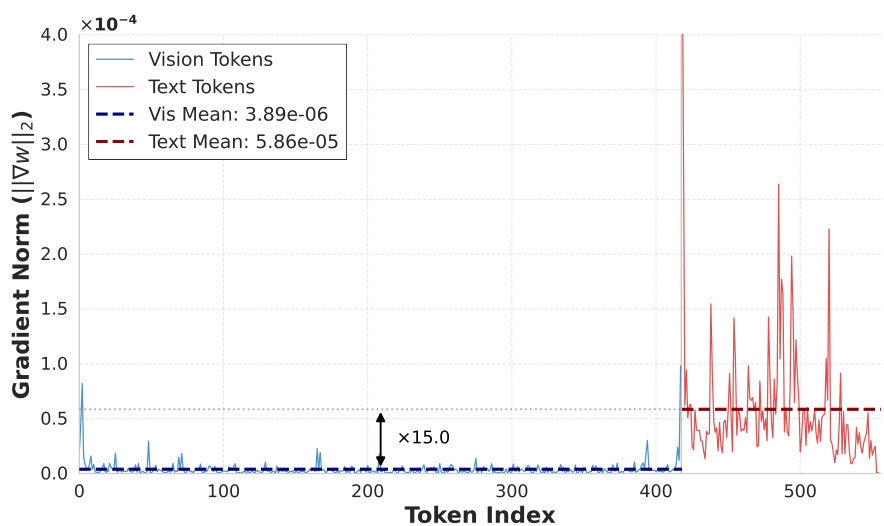
图 5. 样本 88 的详细梯度分析。文本与视觉的梯度比约为 15,证实了文本信息在推理中的主导地位。
3.1.2. 专家异质性
- 固有稀疏性与负载失衡:部分专家几乎不被激活,应用统一的量化指标是次优的。
- Token 分布异质性:存在通用型专家和模态专用型专家(见图 6e)。
- 路由偏置与决定性专家:Router 通常以极高置信度指向少数专家,这些专家的精度对模型性能至关重要。
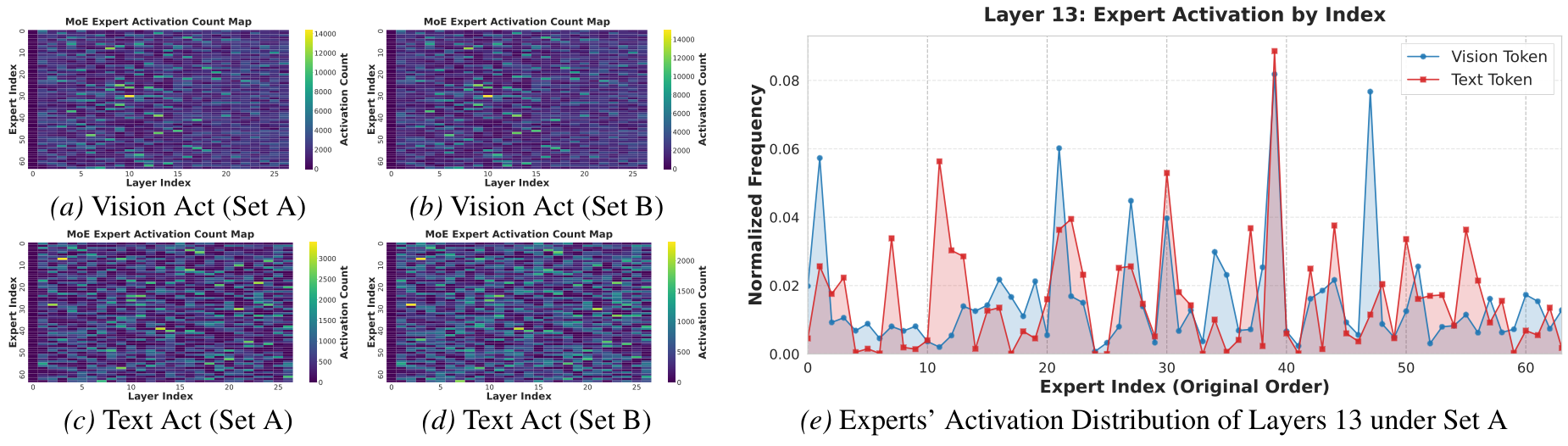
图 6. 专家亲和力模式可视化。展示了专家激活的稀疏性、负载不平衡以及模态特定的聚类特性。
3.2. 模态-专家感知量化 (VEQ-ME)
为了在量化过程中优先保护重要专家,我们定义了专家重要性评分 S i S_i Si:
S i = γ ⋅ N i t e x t + β ⋅ N i v i s , ( 1 ) S_{i} = \gamma \cdot N_{i}^{\mathrm{text}} + \beta \cdot N_{i}^{\mathrm{vis}}, \quad (1) Si=γ⋅Nitext+β⋅Nivis,(1)
其中 N i N_i Ni 为路由到该专家的 Token 数, β \beta β 是数量归一化因子, γ \gamma γ 是质量敏感因子(梯度比值)。
标准量化目标函数为:
L S t a n d a r d = ∑ i = 1 M ∥ W i X i − W ^ i X i ∥ F 2 , ( 2 ) \mathcal{L}{\mathrm{Standard}} = \sum{i = 1}^{M}\| \mathbf{W}_i\mathbf{X}_i - \hat{\mathbf{W}}_i\mathbf{X}_i\| _F^2, \quad (2) LStandard=i=1∑M∥WiXi−W^iXi∥F2,(2)
VEQ 将其重定义为加权目标函数:
L W e i g h t e d = ∑ i = 1 M S i ⋅ ∥ W i X i − W ^ i X i ∥ F 2 . ( 3 ) \mathcal{L}{\mathrm{Weighted}} = \sum{i = 1}^{M}S_{i}\cdot \| \mathbf{W}{i}\mathbf{X}{i} - \hat{\mathbf{W}}{i}\mathbf{X}{i}\|_{F}^{2}. \quad (3) LWeighted=i=1∑MSi⋅∥WiXi−W^iXi∥F2.(3)
3.3. 模态-亲和力感知量化 (VEQ-MA)
传统的 GPTQ 类方法使用 H = 2 X X ⊤ H = 2XX^{\top} H=2XX⊤ 计算 Hessian 矩阵。VEQ 提出构建增强 Hessian 矩阵 H ˉ \bar{H} Hˉ:
H ˉ = X C X ⊤ , ( 4 ) \bar{H} = XCX^{\top}, \quad (4) Hˉ=XCX⊤,(4)
其中 C \mathbf{C} C 是对角矩阵,其元素 c j c_j cj 定义为:
c j = p j ⋅ α j , 其中 α j = { γ x j 是文本 Token, 1 x j 是视觉 Token. ( 5 ) c_{j} = p_{j}\cdot \alpha_{j}, \quad \text{其中} \alpha_{j} = \left\{ \begin{array}{ll} \gamma & x_{j} \text{ 是文本 Token,} \\ 1 & x_{j} \text{ 是视觉 Token.} \end{array} \right. \quad (5) cj=pj⋅αj,其中αj={γ1xj 是文本 Token,xj 是视觉 Token.(5)
这里 p j p_j pj 是 Token 与专家的亲和力概率。该方法确保了高亲和力、高敏感度的 Token 在量化优化中具有更大的影响力。
4. 实验
4.1. 实验设置
- 模型:Kimi-VL-Instruct, Qwen3-VL-30B-A3B-Instruct。
- 基准测试:MMMU, MMBench, AI2D, InfoVQA, TextVQA, MME-RealWorld 等。
- 基准方法:BF16 (原模型), RTN, GPTQ, AWQ, MBQ。
- 实现:基于 lmms-eval 框架,推理后端使用 SGLang。
4.2. 主要结果
我们在 Kimi-VL-Instruct 和 Qwen3-VL-30B-A3B-Instruct 模型上,将本文提出的方法与最先进的基准方法进行了全面评估。为了分析清晰,我们将基于 AWQ 实现的"模态专家感知量化"简称为 VEQ-ME ,而将基于 GPTQ 实现的"模态亲和力感知量化"简称为 VEQ-MA。为了充分评估量化的鲁棒性,我们在 4-bit (W4) 和 3-bit (W3) 仅权重(weight-only)量化设置下进行了实验。表 1 展示了在七个多模态基准测试中的详细对比结果。
W4 设置下的性能:如表 1 上部所示,大多数方法在 4-bit 量化设置下都能保持稳健的性能。具体而言,对于 Kimi-VL-Instruct 模型,现有的基准方法(如 AWQ、MBQ、GPTQ)以及我们提出的 VEQ 均能恢复近 98% 的 BF16 平均精度。不同量化策略之间相对较小的性能差距表明,4-bit 精度提供了足够的容量来表示 MoE 权重,而不会产生灾难性的信息损失。
Table 1. Main comparison results of Kimi-VL-Instruct and Qwen3-VL-30B-A3B-Instruct under 3-bit (W3) and 4-bit (W4) weight only quantization. We report the zero-shot accuracy ( % ) (\%) (%) for all tasks. The best results for each bit-width are highlighted in bold. The improvement of VEQ-MA over the best baseline method is marked in parentheses. Abbreviations: InfoV: InfoVQA, TextV: TextVQA, RWQA: RealWorldQA, SciQA: ScienceQA, Viz: VizWiz, MMB: MMBench, MME-R: MME-RealWorld.
|---------------------------|-----|---------------|-------|-------|-------|-------|-------|-------|-------|-------|-------|---------------|---------------|
| Model | Bit | Method | Benchmarks ||||||||| Avg. |
| Model | Bit | Method | MMMU | AI2D | InfoV | TextV | RWQA | SciQA | Viz | MMB | MME-R | Avg. |
| Kimi-VL-Instruct | W3 | BF16 | - | 51.11 | 83.65 | 83.38 | 85.93 | 66.41 | 92.10 | 69.00 | 82.73 | 58.22 | 74.73 |
| Kimi-VL-Instruct | W3 | RTN | | 37.00 | 69.14 | 59.68 | 74.58 | 56.47 | 79.06 | 58.51 | 66.06 | 46.13 | 60.74 |
| Kimi-VL-Instruct | W3 | AWQ | | 41.78 | 70.05 | 61.49 | 74.04 | 58.17 | 81.84 | 61.37 | 71.13 | 50.44 | 63.37 |
| Kimi-VL-Instruct | W3 | MBQ | | 39.76 | 70.89 | 58.86 | 74.35 | 58.74 | 81.82 | 60.87 | 71.13 | 49.91 | 62.93 |
| Kimi-VL-Instruct | W3 | GPTQ | | 40.33 | 75.49 | 64.14 | 64.30 | 58.82 | 83.87 | 55.61 | 73.02 | 45.41 | 62.33 |
| Kimi-VL-Instruct | W3 | VEQ-ME (ours) | | 44.56 | 71.57 | 62.33 | 73.36 | 58.95 | 82.93 | 58.90 | 71.91 | 51.46 | 64.00 |
| Kimi-VL-Instruct | W3 | VEQ-MA (ours) | | 42.56 | 75.65 | 64.48 | 78.30 | 58.30 | 84.85 | 63.10 | 73.42 | 48.03 | 65.41 (+2.04) |
| Kimi-VL-Instruct | W4 | RTN | | 48.44 | 82.38 | 80.16 | 84.60 | 66.80 | 90.83 | 69.17 | 80.67 | 52.48 | 72.84 |
| Kimi-VL-Instruct | W4 | AWQ | | 49.00 | 81.74 | 79.01 | 83.37 | 66.27 | 90.92 | 69.07 | 80.58 | 53.70 | 72.63 |
| Kimi-VL-Instruct | W4 | MBQ | | 48.89 | 81.70 | 78.49 | 83.18 | 64.58 | 90.29 | 69.03 | 80.93 | 55.08 | 72.46 |
| GPTQ | W4 | | 50.00 | 82.32 | 80.04 | 84.63 | 64.84 | 91.39 | 68.86 | 81.44 | 53.14 | 72.96 |
| VEQ-ME (ours) | W4 | | 49.22 | 81.41 | 79.75 | 83.69 | 66.36 | 91.06 | 69.17 | 80.84 | 54.20 | 72.86 |
| Qwen3-VL-30B-A3B-Instruct | W3 | BF16 | - | 73.67 | 86.27 | 81.43 | 81.31 | 65.49 | 93.52 | 83.27 | 85.91 | 59.92 | 78.98 |
| Qwen3-VL-30B-A3B-Instruct | W3 | RTN | | 57.33 | 77.10 | 44.96 | 68.64 | 43.01 | 89.08 | 64.07 | 78.60 | 45.73 | 63.17 |
| Qwen3-VL-30B-A3B-Instruct | W3 | AWQ | | 58.89 | 73.61 | 44.62 | 67.93 | 45.36 | 88.40 | 61.75 | 77.06 | 42.38 | 62.22 |
| Qwen3-VL-30B-A3B-Instruct | W3 | MBQ | | 50.56 | 71.44 | 40.15 | 64.23 | 53.82 | 87.31 | 59.48 | 76.46 | 45.27 | 60.97 |
| Qwen3-VL-30B-A3B-Instruct | W3 | GPTQ | | 64.89 | 74.11 | 47.27 | 71.82 | 54.25 | 88.23 | 63.39 | 69.39 | 44.08 | 64.16 |
| Qwen3-VL-30B-A3B-Instruct | W3 | VEQ-ME (ours) | | 60.56 | 73.38 | 44.95 | 69.91 | 53.73 | 88.40 | 62.47 | 77.75 | 44.24 | 63.93 |
| Qwen3-VL-30B-A3B-Instruct | W3 | VEQ-MA (ours) | | 65.89 | 79.15 | 47.14 | 72.74 | 54.77 | 89.55 | 69.46 | 82.30 | 43.25 | 67.14 (+3.09) |
| Qwen3-VL-30B-A3B-Instruct | W4 | RTN | | 63.11 | 83.33 | 62.62 | 79.77 | 45.23 | 91.51 | 71.08 | 85.13 | 57.31 | 70.89 |
| Qwen3-VL-30B-A3B-Instruct | W4 | AWQ | | 65.20 | 81.22 | 58.32 | 77.40 | 63.14 | 91.06 | 69.73 | 85.22 | 57.31 | 72.07 |
| Qwen3-VL-30B-A3B-Instruct | W4 | MBQ | | 69.67 | 81.41 | 59.36 | 78.99 | 64.31 | 91.51 | 70.78 | 83.68 | 56.10 | 72.87 |
| GPTQ | W4 | | 72.67 | 82.93 | 62.54 | 80.18 | 53.46 | 93.23 | 71.32 | 84.53 | 57.96 | 73.20 |
| VEQ-ME (ours) | W4 | | 68.78 | 82.47 | 59.53 | 78.57 | 65.32 | 91.61 | 70.97 | 83.56 | 56.79 | 73.07 |
| | | VEQ-MA (ours) | 71.56 | 82.95 | 62.86 | 81.10 | 61.70 | 92.64 | 72.42 | 85.88 | 58.12 | 74.36 (+1.16) |
W3 设置下的性能 :在更具挑战性的 3-bit 设置下,各方法之间的差异变得显著。如表 1 下部所示,RTN 和 AWQ 等传统基准方法的性能严重下降,特别是在 MMMU 等推理密集型任务和 InfoVQA 等细粒度视觉任务上。这表明当比特宽度极度受限时,统一量化的假设将失效,且忽略模态异质性会导致严重的压缩误差。相比之下,VEQ 表现出了卓越的鲁棒性。通过显式建模专家重要性和模态亲和力,VEQ 显著优于基准方法。例如,在 Kimi-VL-Instruct 模型的 TextVQA 任务上,VEQ 比原始量化方法提升了 21.4 % 21.4\% 21.4%。这些结果证实,在低比特量化中,保护关键专家和区分模态敏感性至关重要。
4.3. 消融研究
为了验证所提方法的有效性和鲁棒性,我们进行了两个层面的消融研究:首先,评估各组件对下游任务性能的贡献;其次,在随机提取的验证集上进行超参数敏感性分析。所有实验均在相同的配置下进行以确保公平。
组件对下游任务的有效性:我们关注两个核心公式:VEQ-ME 中的专家重要性评分和 VEQ-MA 中的模态亲和力感知 Hessian 矩阵。
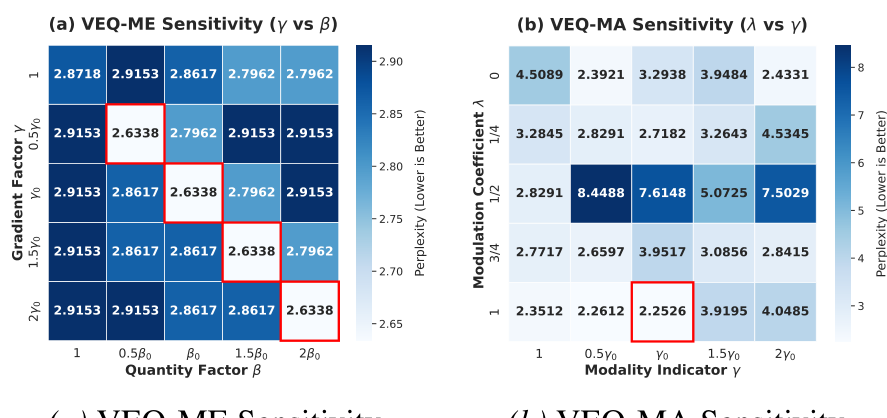
Figure 7. Visual analysis of parameter sensitivity regarding validation PPL. (a) VEQ-ME: It confirms the scale invariance of our method, where maintaining the relative ratio ensures consistent minimization of quantization error. (b) VEQ-MA: The results shows reducing λ \lambda λ generally results in an increase in PPL, validating that the router confidence is important for accurate quantization.
Table 2. Ablation study of Modality-Expert Importance (VEQME) on downstream tasks. γ \gamma γ : Gradient factor; β \beta β : Quantity factor.
|---------------|-------|---------|-----------|-------|
| Config | MMMU | InfoVQA | ScienceQA | Avg. |
| w/o γ(γ = 1) | 43.44 | 60.39 | 82.24 | 62.02 |
| w/o β(β = 1) | 43.89 | 60.34 | 82.67 | 62.30 |
| VEQ-ME (Full) | 44.56 | 62.33 | 82.93 | 63.27 |
- 模态专家重要性 (VEQ-ME) 的影响 :重要性评分公式为 S i = γ N i t e x t + β N i v i s i o n S_{i} = \gamma N_{i}^{text} + \beta N_{i}^{vision} Si=γNitext+βNivision。我们研究了梯度缩放因子 γ \gamma γ 和数量归一化因子 β \beta β 的必要性:
- 无 γ \gamma γ ( γ = 1 \gamma = 1 γ=1):仅根据 Token 数量处理重要性。如表 2 所示,这导致重文本推理任务性能明显下降,证实文本 Token 需要更高的敏感度权重。
- 无 β \beta β ( β = 1 \beta = 1 β=1):忽略数量差异会导致海量的视觉 Token 主导评分。结果显示这会降低性能,因为路由会偏向空间冗余的视觉特征。
- 模态亲和力感知 (VEQ-MA) 的影响 :Token 权重定义为 c j = p j ⋅ α j c_{j} = p_{j} \cdot \alpha_{j} cj=pj⋅αj。我们检查了亲和力 p j p_{j} pj 和模态指示器 α j \alpha_{j} αj 的作用:
- 无 p p p ( p = 1 p = 1 p=1):将所有路由到某专家的 Token 视为同等重要。表 3 显示这会导致次优结果,证明路由置信度更高的 Token 更有代表性。
- 无 α \alpha α ( α = 1 \alpha = 1 α=1):移除模态重加权会导致性能下降,证实区分信息密集型文本 Token 和冗余视觉 Token 对减少误差至关重要。
Table 3. Ablation study of Affinity-Aware Hessian (VEQ-MA) on downstream tasks. p p p : Router confidence; α \alpha α : Modality indicator.
|---------------|-------|---------|-----------|-------|
| Config | MMMU | InfoVQA | ScienceQA | Avg. |
| w/o p (p = 1) | 42.33 | 64.30 | 83.35 | 63.63 |
| w/o α (α = 1) | 41.33 | 63.72 | 82.34 | 62.46 |
| VEQ-MA (Full) | 42.56 | 64.48 | 84.85 | 63.96 |
参数敏感性分析:我们在从 MMMU 验证集中随机提取的 64 个样本上分析了平均困惑度 (PPL)。
- VEQ-ME 的敏感性 ( γ \gamma γ vs. β \beta β) :如图 7 所示,我们观察到成比例地缩放 γ \gamma γ 和 β \beta β 会产生一致的 PPL 值。这说明量化参数的搜索取决于专家重要性的相对比例(尺度不变性)。
- VEQ-MA 的敏感性 ( λ \lambda λ vs. γ \gamma γ) :我们通过调制系数 λ \lambda λ(控制路由置信度的强度)来分析 Hessian 加权。如图 7 所示,模型在全配置 ( λ = 1 , γ = γ 0 \lambda = 1, \gamma = \gamma_{0} λ=1,γ=γ0) 下达到最佳稳定性(最低 PPL 为 2.2526)。
5. 结论
在这项工作中,我们提出了视觉专家量化 (VEQ),这是一种专门为压缩混合专家视觉语言模型 (MoE VLMs) 设计的后训练量化框架。VEQ 突破了将 MoE FFNs 视为单一密集结构的局限性,有效地解决了专家激活的固有稀疏性以及视觉与文本模态之间的统计异质性。在多个多模态基准测试中,VEQ 一致优于现有基准方法。通过使量化策略与 MoE VLMs 的结构和模态特性相匹配,VEQ 树立了新的最先进标准,为在资源受限环境中高效部署大规模多模态智能体铺平了道路。
Original Abstract: Mixture-of-Experts(MoE) Vision-Language Models (VLMs) offer remarkable performance but incur prohibitive memory and computational costs, making compression essential. Post-Training Quantization (PTQ) is an effective training-free technique to address the massive memory and computation overhead. Existing quantization paradigms fall short as they are oblivious to two critical forms of heterogeneity: the inherent discrepancy between vision and language tokens, and the non-uniform contribution of different experts. To bridge this gap, we propose Visual Expert Quantization (VEQ), a dual-aware quantization framework designed to simultaneously accommodate cross-modal differences and heterogeneity between experts. Specifically, VEQ incorporates 1)Modality-expert-aware Quantization, which utilizes expert activation frequency to prioritize error minimization for pivotal experts, and 2)Modality-affinity-aware Quantization, which constructs an enhanced Hessian matrix by integrating token-expert affinity with modality information to guide the calibration process. Extensive experiments across diverse benchmarks verify that VEQ consistently outperforms state-of-the-art baselines. Specifically, under the W3A16 configuration, our method achieves significant average accuracy gains of 2.04% on Kimi-VL and 3.09% on Qwen3-VL compared to the previous SOTA quantization methods, demonstrating superior robustness across various multimodal tasks. Our code will be available at https://github.com/guangshuoqin/VEQ.
PDF Link: 2602.01037v1
部分平台可能图片显示异常,请以我的博客内容为准
