摘要
2024年3月,我参与了某科技公司"新一代L4级自动驾驶测试平台"的研发工作,在项目中担任系统架构师 ,负责整体技术架构设计与核心模块选型。该平台旨在解决复杂城市工况下的自动巡航、动态避障与路径规划难题。鉴于自动驾驶车辆(端侧)每日产生TB级海量数据,且对决策延迟有毫秒级的严苛要求,传统单一的云计算或边缘计算模式均无法满足系统在实时性、带宽成本及模型迭代效率上的综合指标。因此,我设计了一套基于KubeEdge的边云协同架构 。本文将结合项目实践,从资源协同、数据协同、智能协同及应用管理协同四个维度,详细论述该架构的设计与落地。实际运行表明,该架构将网络回传带宽节省了90%,长尾场景模型迭代周期缩短至3天,有效支撑了系统的稳定运行。
正文
一、 项目背景与问题分析
随着智能交通系统的飞速发展,L4级自动驾驶已成为行业竞争的制高点。我所参与的"新一代L4级自动驾驶测试平台"项目,总投资5000万元,旨在构建一套支持由激光雷达、毫米波雷达、高清摄像头组成的多源异构传感器融合感知的自动驾驶系统。系统需在复杂的城市道路环境中,实现车辆的厘米级定位、毫秒级决策以及对突发路况的自主应对。
作为系统架构师,在项目初期的需求分析与架构预研阶段,我发现该系统面临着极其尖锐的矛盾,也就是所谓的"云端算力无限但太远,车端响应即时但太弱"的问题,具体表现在:
第一,海量数据与有限带宽的矛盾。 单车搭载的64线激光雷达和4K摄像头每小时产生约2TB原始数据。若采用全量上云方案,不仅4G/5G流量成本是天文数字,且在基站切换或信号盲区(如隧道)时,网络抖动将直接导致数据链路中断。
第二,实时决策与网络延迟的矛盾。 车辆在60km/h高速行驶时,遇到行人横穿等紧急情况,留给系统的反应时间不足100ms。依赖云端计算的往返延迟(RTT)通常在50ms以上,且不可控,这对于生命攸关的自动驾驶系统是绝对不可接受的。
第三,模型泛化能力与端侧算力的矛盾。 车载计算单元(MDC)虽然算力在不断提升,但仍无法支撑大规模深度学习模型的训练任务。而云端虽然拥有海量GPU集群,却无法实时获取车辆在行驶中遇到的"长尾数据"(Corner Case),导致模型迭代滞后,无法应对未见过的复杂场景。
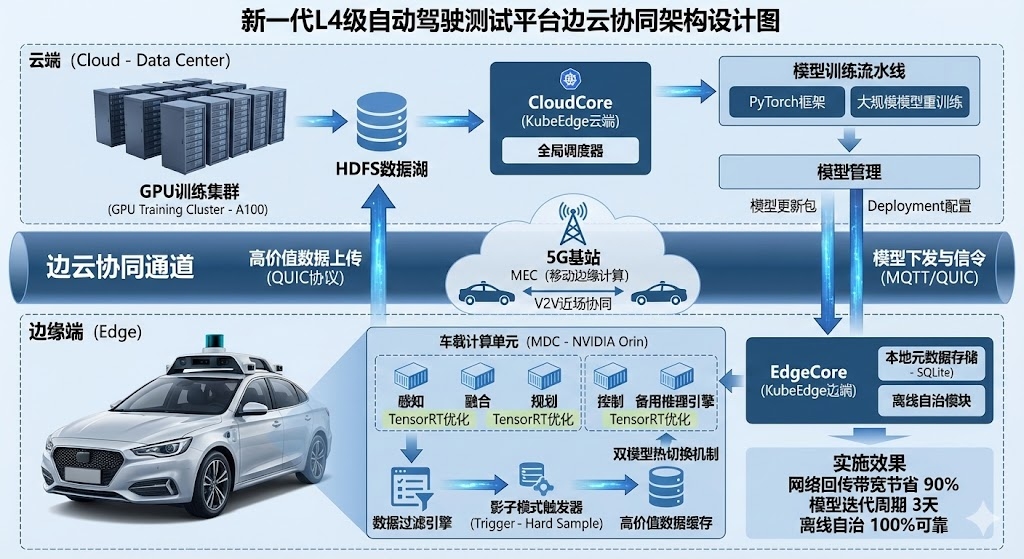
面对上述挑战,经过多轮技术评审,我决定摒弃传统的"车端独立智能"或"纯云端控制"方案,转而采用边云协同架构。将车载计算单元(MDC)定义为边缘节点,利用云计算擅长全局性、长周期大数据处理的优势,结合边缘计算局部性、短周期、低延迟的特点,构建"车路云一体化"的协同体系。
二、 边云协同架构的核心设计与实施
在确定总体架构后,我基于业界主流的边云协同方法论,结合 KubeEdge 开源框架,重点在资源、数据、智能、应用四个层面进行了深度设计与落地。
1. 资源协同:构建高可用与弹性的基础设施
资源协同的核心在于如何统一调度云端无限的算力与边缘端受限的算力。
在硬件层,车端采用了基于ARM架构的高性能计算平台(如NVIDIA Orin),云端则构建了基于A100的GPU训练集群。为了消除异构硬件的管理隔阂,我引入了 KubeEdge 作为边缘计算底座。
遇到的问题 :原生Kubernetes(K8s)的 kubelet 组件内存占用较高,且在车端断网时会触发Pod驱逐机制,导致车载服务重启,这严重威胁行车安全。
解决方案 :
我采用了KubeEdge的 CloudCore(云端) 与 EdgeCore(边端) 分离架构。EdgeCore是对kubelet的轻量化重构,内存占用仅为原来的1/5。更关键的是,我配置了EdgeCore的离线自治(Offline Autonomy)功能。
当车辆进入隧道导致网络中断时,EdgeCore会自动切换至本地元数据存储(SQLite),确保本地感知道路、规划控制等核心容器持续稳定运行,不依赖云端心跳。当网络恢复后,再自动与CloudCore进行状态同步。
此外,我还设计了闲时算力调度策略。当车辆夜间在车库充电休眠时,云端调度器会下发低优先级的离线任务(如日志压缩、数据格式化)到车端MDC执行,充分利用了边缘侧的闲置资源。
2. 数据协同:构建价值驱动的数据流水线
数据协同旨在解决"传什么、怎么传"的问题。
设计策略:边缘负责高频数据的采集、清洗与初筛,云端负责长周期数据的存储与价值挖掘。
具体实施 :
边缘侧(清洗与触发) :我在边缘端部署了一套基于规则的数据过滤引擎。
对于常规的直行、无障碍路况数据,系统在本地完成感知后,仅保留轻量级的结构化元数据(如经纬度、速度),原始点云和视频数据直接丢弃。
对于"高价值数据",我设计了"影子模式"触发器。当发生急刹车(加速度阈值超限)、人工接管(Disengagement)或感知置信度低于0.6时,系统会自动截取前后30秒的传感器原始数据,并标记为"Hard Sample"。
边云通道(可靠传输) :针对弱网环境,我放弃了传统的HTTP上传,改用基于 QUIC协议 的文件传输服务,利用其多路复用和0-RTT连接特性,提升上传成功率。对于控制信令,则采用 MQTT协议,确保指令的轻量级与低延迟。
云端(数据湖):云端接收到高价值数据后,存入HDFS数据湖,用于后续的事故复盘和模型训练集扩充。这种机制确保了在有限带宽下,云端能获取到最关键的训练样本。
3. 智能协同:云端训练,边缘推理的闭环
这是自动驾驶系统不断进化的引擎。我们严格遵循"边缘执行推理,云端开展模型训练"的协同模式。
云端(集中训练) :
云端通过数据协同收集到的"长尾数据",经过半自动标注后,进入训练流水线。我们使用PyTorch框架在GPU集群上进行大规模模型的重训练。例如,针对某次路测中识别失败的异形工程车样本,云端将其加入数据集,训练出泛化能力更强的新模型。
边缘侧(推理加速) :
为了让庞大的模型能在车端跑得动,我在模型下发前增加了一个模型优化环节。利用 TensorRT 工具对模型进行算子融合与FP16量化,在精度损失小于1%的前提下,将推理延迟从50ms降低至15ms。
遇到的问题 :模型更新时,如何确保车端服务不中断?
解决方案 :我设计了双模型热切换机制。EdgeCore在后台下载新版模型文件,校验签名通过后,加载到内存中的备用推理引擎。待备用引擎初始化完毕,流量网关瞬间切换指向,旧引擎随即卸载。整个过程对业务透明,实现了行车过程中的无感OTA。
4. 应用管理协同:全生命周期的容器化治理
为了解决车载软件版本碎片化、升级困难的问题,我实施了基于容器的应用管理协同。
具体实施 :
我们将感知、融合、规划、控制等核心模块全部微服务化,并封装为Docker容器。云端作为控制平面(,维护着所有测试车辆的"期望状态"。
当算法团队发布了"路径规划算法 v2.0"镜像后,运维人员只需在云端修改Deployment配置。云端CloudCore通过消息通道通知边缘EdgeCore。EdgeCore在车辆空闲时段(通过读取车辆CAN总线状态判断),自动拉取镜像、替换容器并重启服务。
此外,我还引入了灰度发布机制。新版本应用首先推送到5辆内部测试车,通过云端监控其运行指标(如CPU占用、崩溃率),确认稳定后,再全量推送到整个车队。这种协同机制将软件发布周期从周级缩短到了天级。
三、 实施效果与总结
该测试平台自2024年3月上线以来,已稳定运行超过6个月,累计支持了50辆自动驾驶汽车的城市开放道路测试,测试里程突破10万公里。通过引入边云协同架构,项目取得了显著成效:
-
降本增效:通过数据协同的端侧过滤机制,单车日均上传数据量从2TB下降至50GB左右,节省了95%的流量成本和云存储成本。
-
高可靠性:得益于资源协同中的离线自治能力,车辆在穿越长隧道和信号屏蔽区时,从未发生过因云端失联导致的功能失效,实现了100%的本地业务闭环。
-
快速迭代:智能协同机制打通了"数据回传-云端训练-模型下发"的自动化闭环,使得针对特定长尾场景的模型修复周期从原来的2周缩短至3天,极大地提升了算法团队的研发效率。
总结与展望 :
本项目的成功实践证明,边云协同是解决自动驾驶系统算力、带宽与实时性矛盾的最佳架构方案。目前,系统在多车协同(V2V)方面还存在局限,主要依赖云端转发,延迟较高。未来,我计划在架构中引入MEC(移动边缘计算)技术,利用5G基站侧的算力实现车与车之间的近场协同,进一步提升交通效率与安全性。
架构师论文写作要点(机考特供版)
1. 篇幅与排版:利用键盘优势
-
字数上浮 :机考打字速度远快于手写,建议将正文目标定在 2500~2800字(摘要300-330字)。更充实的内容意味着展示了更多的技术细节,是拿高分的关键。
-
视觉分段 :屏幕阅读容易疲劳,严禁长篇大论不分段。每个小标题下建议拆分为 2-3 个自然段。利用 (1) ... (2) ... 或 第一,... 第二,... 等序号强行分割视觉块,让阅卷老师一眼看到逻辑结构。
-
标点规范 :注意中英文标点的切换,英文单词前后建议留一个空格(如:使用 KubeEdge 框架),这样排版更美观、专业。
2. 术语准确性:警惕"提手忘音"
-
大小写规范:机考中,英文术语必须严格遵守官方写法。例如 KubeEdge(注意K和E大写)、TensorRT、Docker、MQTT。不要出现全小写(如 kubeedge)或全角字符,这显得非常不专业。
-
输入法陷阱:机考输入法(通常是微软拼音)没有手机智能。务必检查同音错别字!
-
❌ 错误示例:阀值、步署、回朔、按装。
-
✅ 正确写法:阈值、部署、回溯、安装。
-
-
高分词汇:文中提到的 CloudCore、EdgeCore、QUIC、离线自治、影子模式 等词汇,是体现你技术深度的关键,输入时要确保零失误。
3. 逻辑结构:"问题-解决"闭环
-
核心写法 :坚持采用 "设计思路 -> 遇到具体问题 -> 架构决策与解决" 的写法。
- 示例:不要只写"我们用了EdgeCore"。要写"原生kubelet内存占用高且断网会驱逐Pod(问题 ),因此我们引入了轻量级的EdgeCore,并配置了离线自治功能(解决)"。
-
非线性写作 :利用机考优势,先敲出一、二、三级标题的骨架,防止跑题。然后再往里面"填肉"。这样能确保你的"问题-解决"逻辑链条在整篇文章中是严密扣合的。
4. 真实感:细节决定成败
-
拒绝空谈 :文中提到的"夜间充电时调度"、"进入隧道断网"、"加速度阈值触发截取数据"等业务场景细节,是证明项目真实性的铁证。
-
数据支撑:在机考中,你可以更从容地补充量化数据。例如:"带宽节省了90%"、"延迟从50ms降至15ms"、"模型更新周期缩短至3天"。这些具体的数字比"效果很好"更有说服力。