环境准备
|------------------------|-----------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 软件 | 版本 | 备注 |
| 操作系统 | centos7.9 | 一台 |
| seatunnel | 2.3.11 | https://seatunnel.apache.org/download/ |
| connector-cdc-mysql | 2.3.11 | https://mvnrepository.com/artifact/org.apache.seatunnel/connector-cdc-mysql |
| connector-cdc-postgres | 2.3.11 | https://mvnrepository.com/artifact/org.apache.seatunnel/connector-cdc-postgres |
| connector-starrocks | 2.3.11 | https://mvnrepository.com/artifact/org.apache.seatunnel/connector-starrocks |
| connector-jdbc | 2.3.11 | https://mvnrepository.com/artifact/org.apache.seatunnel/connector-jdbc |
| mysql jdbc驱动 | 8.0.28 | https://mvnrepository.com/artifact/mysql/mysql-connector-java/8.0.28 |
| postgresql jdbc驱动 | 42.6.0 | https://mvnrepository.com/artifact/org.postgresql/postgresql |
| mysql | 5+ | / |
| java | 1.8.0_421 | / |
| postgresql | 15+ | / |
1、安装包部署
1、mysql、pg自行安装(mysql -->pg)
安装完成后查看mysql是否开启binlog
sql
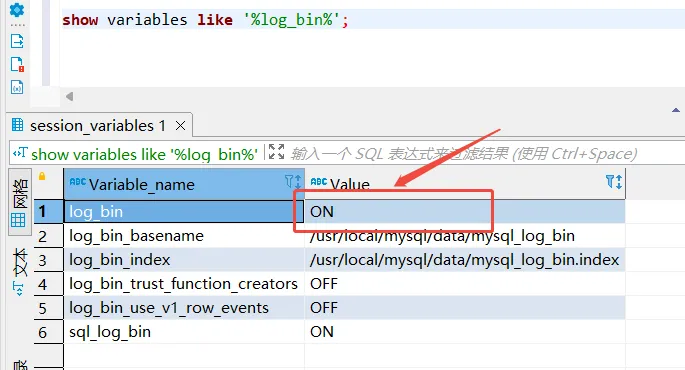
#查看mysql是否开启binlog
show variables like '%log_bin%';如图,如果为OFF,则需要编辑my.cnf配置文件(数据库连接工具自行准备,我这里用的dbeaver)
编辑my.cnf配置文件(可以输入whereis my.cnf查询文件位置)
bash
whereis my.cnf
vim /etc/my.cnf增加下面内容
bash
server_id = 1
binlog_format = ROW
log-bin = mysql_log_bin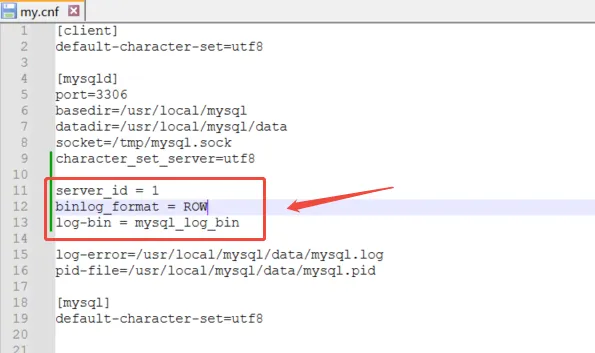
重启mysql,再次查看mysql是否开启 binlog
sql
service mysql restart创建mysql库和表,再库中添加几条数据
sql
create database wjx;
use wjx
CREATE TABLE players (
player_id INT NOT NULL AUTO_INCREMENT,
team_id INT,
player_name VARCHAR(255),
height FLOAT(53),
PRIMARY KEY (player_id)
);
insert into players (player_id,team_id,player_name,height) values
(1001,1001,'韦德','1.93'),
(1002,1002,'雷吉','1.91'),
(1003,1003,'安德烈','2.11'),
(1004,1004,'索恩','2.16'),
(1005,1005,'兰斯顿','1.88'),
(1006,1006,'格伦','1.98'),
(1007,1007,'伊斯梅尔','1.83'),
(1008,1008,'扎扎','2.11'),
(1009,1009,'乔恩','2.08');
select * from players;在pg库中创建一个数据库,不插入数据
sql
create database wjx;
\c wjx
CREATE TABLE players3 (
player_id INT NOT NULL,
team_id INT,
player_name VARCHAR(255),
height FLOAT(53),
PRIMARY KEY (player_id)
);2、seatunnel安装包部署
官网下载seatunnel安装包。(链接见上面环境准备)
下载对应连接器jar包、mysql、pg驱动包。(链接见上面环境准备)
上传到linux环境中并解压缩
bash
tar -zxvf apache-seatunnel-2.3.11-bin.tar.gz联网安装插件 :(如果没有网络请采用离线安装插件)
安装插件前需要进行Maven镜像地址更换与一些不用的插件不需要下载
插件目录
bash
cd /../apache-seatunnel-2.3.8/config/plugin_config安装插件
bash
cd /../apache-seatunnel-2.3.11/
sh bin/install-plugin.sh离线安装插件:
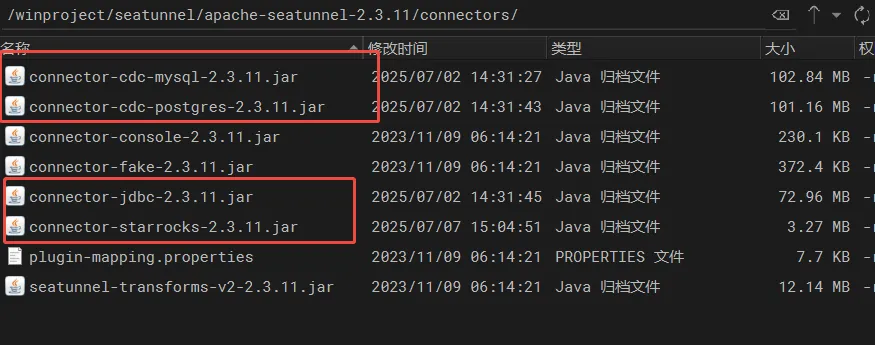
进入到connectors文件夹,将连接器jar包放入该文件夹
bash
cd /../apache-seatunnel-2.3.11/connectors/如图所示
将mysql、pg数据库jdbc驱动jar包放入lib文件夹
bash
cd /../apache-seatunnel-2.3.11/lib/如图所示
复制流式同步配置模板
bash
cp v2.streaming.conf.template test.config配置文件如下(mysql->pg)
java
env {
# You can set SeaTunnel environment configuration here
execution.parallelism = 2
job.mode = "STREAMING"
# 10秒检查一次,可以适当加大这个值
checkpoint.interval = 10000
#execution.checkpoint.interval = 10000
#execution.checkpoint.data-uri = "hdfs://localhost:9000/checkpoint"
}
# 配置数据源
source {
MySQL-CDC {
# 数据库账号
username = "root"
password = "root"
# 源表,格式:数据库名.表名
table-names = ["wjx.players"]
base-url = "jdbc:mysql://10.16.16.164:3306/wjx"
startup.mode = "INITIAL"
server-id = "250314002"
}
}
# 配置目标库
sink {
jdbc {
url = "jdbc:postgresql://10.16.16.164:1921/wjx"
driver = "org.postgresql.Driver"
user = "dbadmin"
password = "123456"
generate_sink_sql = true
# 目标数据库名
database = "wjx"
# 目标表名
table = "public.players2"
schema_save_mode = CREATE_SCHEMA_WHEN_NOT_EXIST
data_save_mode = APPEND_DATA
support_upsert_by_query_primary_key_exist = true
# 主键名称
primary_keys = ["player_id"]
}
}启动集群
bash
cd /../apache-seatunnel-2.3.11/
-- 创建日志文件夹
mkdir -p logs
-- 启动集群
nohup bin/seatunnel-cluster.sh 2>&1 &提交任务
java
nohup ./bin/seatunnel.sh --config ./config/test.config 2>&1 &jps查看如下

2、源码部署
1、下载源码
源码地址:
github地址:https://github.com/apache/seatunnel
官网地址:https://www.apache.org/dyn/closer.lua/seatunnel/2.3.11/apache-seatunnel-2.3.11-src.tar.gz
2、maven环境安装打包
- idea 内存不够:
点击菜单栏 ---> help ---> Change Memory Settings ---> 分配2048MB
windows环境:mvn clean install -DskipTests -Dskip.spotless=true
linux环境:sh ./mvnw clean install -DskipTests -Dskip.spotless=true
一个模块打包:
mvn clean package -pl seatunnel-connectors-v2/connector-jdbc -am -DskipTests -Dskip.spotless=true -T 1C
3、上传到linux环境
进入到seatunnel/seatunnel-dist/target/目录下,找到压缩包,移入到linux环境解压进行上述安装包中seatunnel部署步骤即可(源码打包,无需安装jar包,直接编辑配置文件即可)
apache-seatunnel-2.3.12-SNAPSHOT-bin.tar.gz
附:postgresql CDC同步postgresql相关配置及测试案例
编辑配置文件postgresql.conf 配置wal日志
sql
# 找到对应配置并进行修改
# 更改wal日志方式为logical(方式有:minimal、replica 、logical )
wal_level = logical
# 更改solts最大数量(默认值为10),flink-cdc默认一张表占用一个slots
max_replication_slots = 20
# 更改wal发送最大进程数(默认值为10),这个值和上面的solts设置一样
max_wal_senders = 20
# 中断那些停止活动超过指定毫秒数的复制连接,可以适当设置大一点(默认60s,0表示禁用)
wal_sender_timeout = 180s
sql
-- 查看pg是否开启wal日志
SHOW wal_level;
# 发布表
-- 设置发布为true
update pg_publication set puballtables=true where pubname is not null;
-- 把所有表进行发布
CREATE PUBLICATION dbz_publication FOR ALL TABLES;
-- 查询哪些表已经发布
select * from pg_publication_tables;
# 更改表的标识
-- 更改复制标识包含更新和删除之前值(目的是为了确保表 players2 在实时同步过程中能够正确地捕获并同步更新和删除的数据变化。如果不执行这两条语句,那么 players2 表的复制标识可能默认为 NOTHING,这可能导致实时同步时丢失更新和删除的数据行信息,从而影响同步的准确性)
ALTER TABLE players2 REPLICA IDENTITY FULL;
-- 查看复制标识(为f标识说明设置成功,f(表示 full),否则为 n(表示 nothing),即复制标识未设置)
select relreplident from pg_class where relname='players2';
# 附:创建players2的DDL
CREATE TABLE public.players2 (
player_id int4 NOT NULL,
team_id int4 NULL,
player_name varchar(255) NULL,
height float8 NULL,
PRIMARY KEY (player_id)
);复制流式同步配置模板
bash
cd /../apache-seatunnel-2.3.11/config/
cp v2.streaming.conf.template test2.config配置文件如下(pg->pg)
java
env {
# You can set SeaTunnel environment configuration here
execution.parallelism = 2
job.mode = "STREAMING"
# 10秒检查一次,可以适当加大这个值
checkpoint.interval = 10000
#execution.checkpoint.interval = 10000
#execution.checkpoint.data-uri = "hdfs://localhost:9000/checkpoint"
}
# 配置数据源
source {
Postgres-CDC {
# 数据库账号
username = "dbadmin"
password = "123456"
# 源表,格式:数据库名.表名
# table-names = ["wjx.players"]
database-names = ["wjx"]
schema-names = ["public"]
table-names = ["wjx.public.plyers2"]
base-url = "jdbc:postgresql://10.16.16.164:1921/wjx?loggerLevel=OFF"
startup.mode = "INITIAL"
# debezium 属性
# debezium={"interval.handling.mode":"string"}
server-id = "250314003"
}
}
# 配置目标库
sink {
jdbc {
url = "jdbc:postgresql://10.16.16.164:1922/wjx"
driver = "org.postgresql.Driver"
user = "dbadmin"
password = "123456"
generate_sink_sql = true
# 目标数据库名
database = "wjx"
# 目标表名
table = "public.plyers2"
schema_save_mode = CREATE_SCHEMA_WHEN_NOT_EXIST
data_save_mode = APPEND_DATA
support_upsert_by_query_primary_key_exist = true
# 主键名称
primary_keys = ["player_id"]
}
}启动集群
bash
cd /../apache-seatunnel-2.3.11/
-- 创建日志文件夹
mkdir -p logs
-- 启动集群
nohup bin/seatunnel-cluster.sh 2>&1 &提交任务
java
nohup ./bin/seatunnel.sh --config ./config/test2.config 2>&1 &debezium属性(了解一下怎么设置)
java
debezium = {
database.trustServerCertificate=true
}
debezium={"interval.handling.mode":"string"}