一、集合操作与排序
1.1、集合运算
|--------|---------------------|-----------------------------------------|
| 有时候需要过滤或将一组时间序列与另一组时间序列进行合并,Prometheus 提供了 3 个在瞬时向量之间操作的集合运算符。 |||
| 序号 | 集合运算符 | 说明 |
| 1 | 交集 (and) | 如对较高错误率触发报警,但是只有当对应的总错误率超过某个阈值的时候才会触发报警 |
| 2 | 并集 (or) | 对序列进行并集计算 |
| 3 | 除非 (unless) | 如要对磁盘空间不足进行告警,除非它是只读文件系统 |
| 与算术和过滤二元运算符类似,这些集合运算符会尝试根据相同的标签集在左侧和右侧之间查找来匹配序列,除非你提供 on() 或 ignoring() 修饰符来指定应该如何找到匹配。 |||
|  |||
|||
[prometheus支持的集合运算]
bash
#集合运算示例
#示例1-【or】列出所有低于 10 或者高于 50 的请求率
rate(prometheus_http_request_duration_seconds_count[5m])<10 or rate(prometheus_http_request_duration_seconds_count[5m])>50
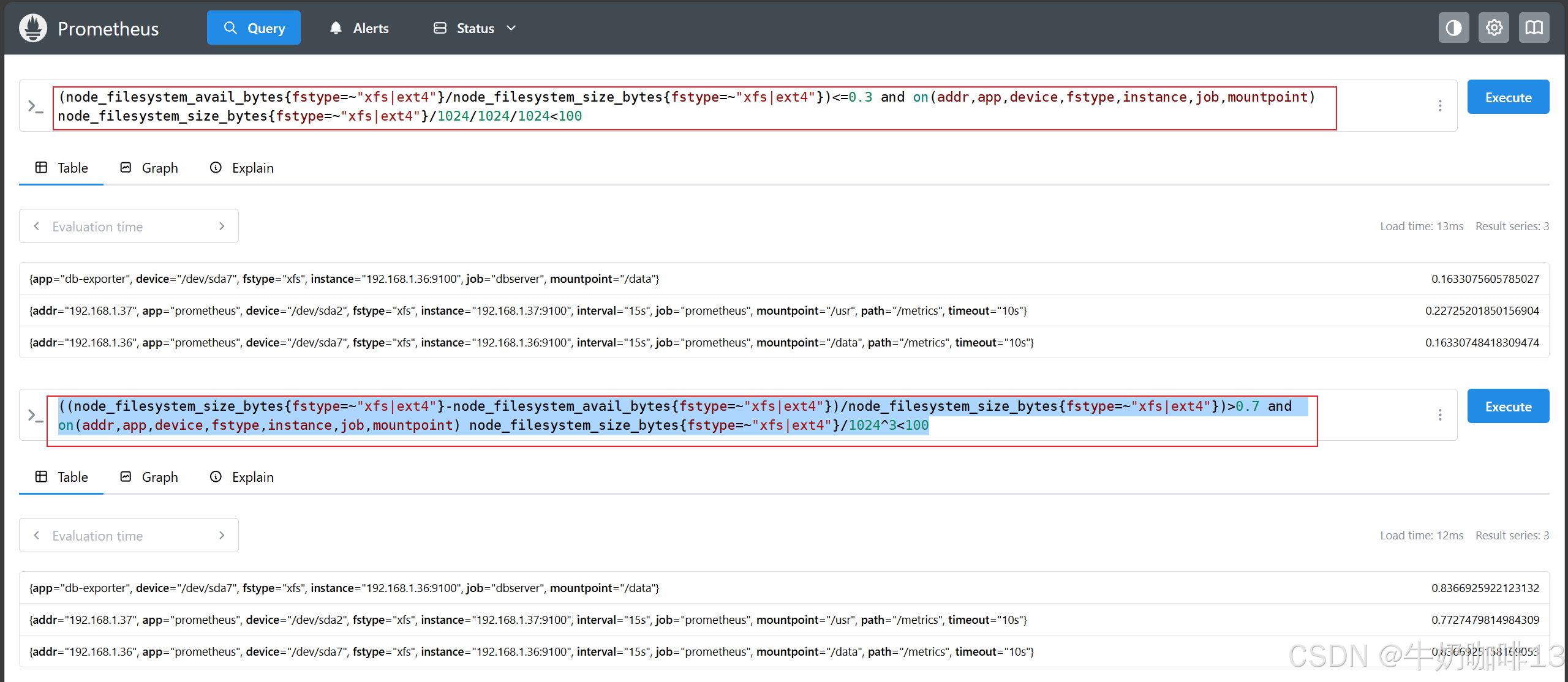
#示例2-【and】关于磁盘的使用率,有的磁盘分区很大,比如 10T,有的分区很小,比如 100G,像这种情况如果只是用磁盘的使用率做告警就不太合理,比如 disk_used_percent{job="dockerserver"} > 70 表示磁盘使用率大于 70% 就告警。对于小盘,这个策略是合理的,但对于大盘,70% 的使用率表示还有非常多的空间,就不太合理。这时我们希望给这个策略加一个限制,只有小于 200G 的硬盘在使用率超过 70% 的时候,才需要告警,这时我们就可以使用 and 运算符
((node_filesystem_size_bytes{fstype=~"xfs|ext4"}-node_filesystem_avail_bytes{fstype=~"xfs|ext4"})/node_filesystem_size_bytes{fstype=~"xfs|ext4"})>0.7 and on(addr,app,device,fstype,instance,job,mountpoint) node_filesystem_size_bytes{fstype=~"xfs|ext4"}/1024^3<100
(node_filesystem_avail_bytes{fstype=~"xfs|ext4"}/node_filesystem_size_bytes{fstype=~"xfs|ext4"})<=0.3 and on(addr,app,device,fstype,instance,job,mountpoint) node_filesystem_size_bytes{fstype=~"xfs|ext4"}/1024/1024/1024<100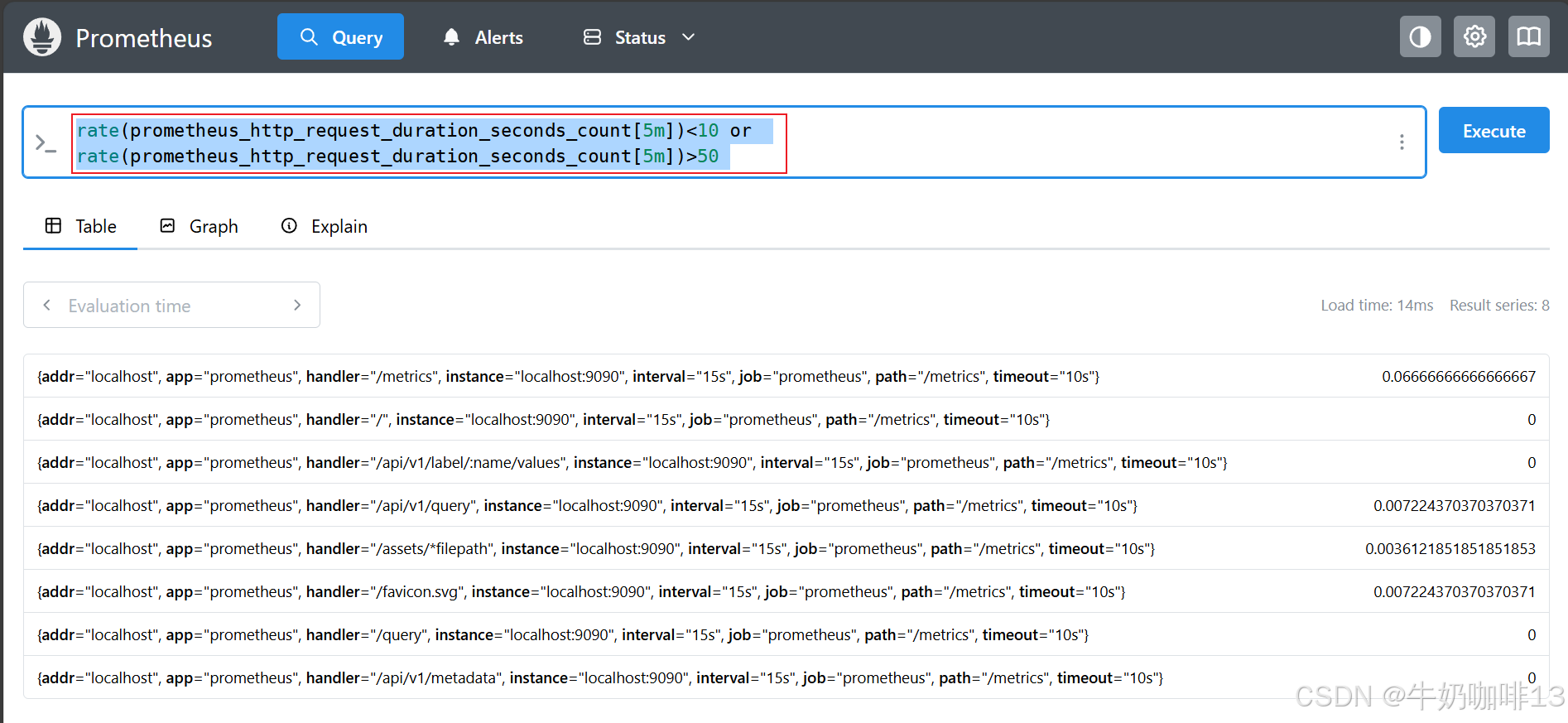
1.2、对查询结果进行排序
可以使用【sort() 升序】或者【sort_desc() 降序】函数来实现对输出结果进行排序。
有时候,只对最大或最小的几个序列感兴趣,可以使用【topk()】和【bottomk()】这两个运算符来操作,可以返回 K 个最大或最小的序列。
bash
#对查询结果进行排序示例
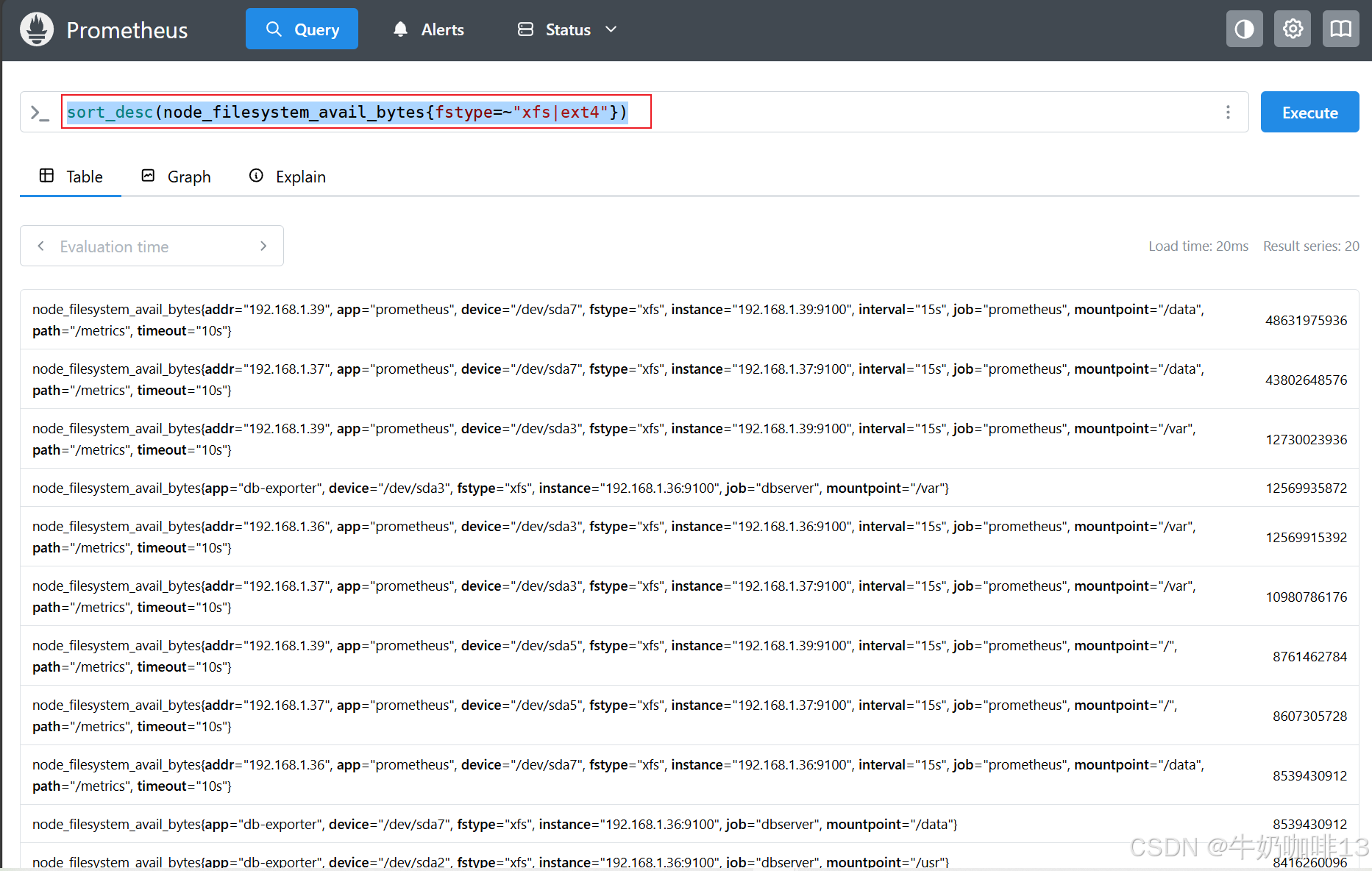
#1-示例1-按值对系统可用空间按照从大到小排序
sort_desc(node_filesystem_avail_bytes)
sort_desc(node_filesystem_avail_bytes{fstype=~"xfs|ext4"})
#2-示例2-按值显示最大的前三个内容
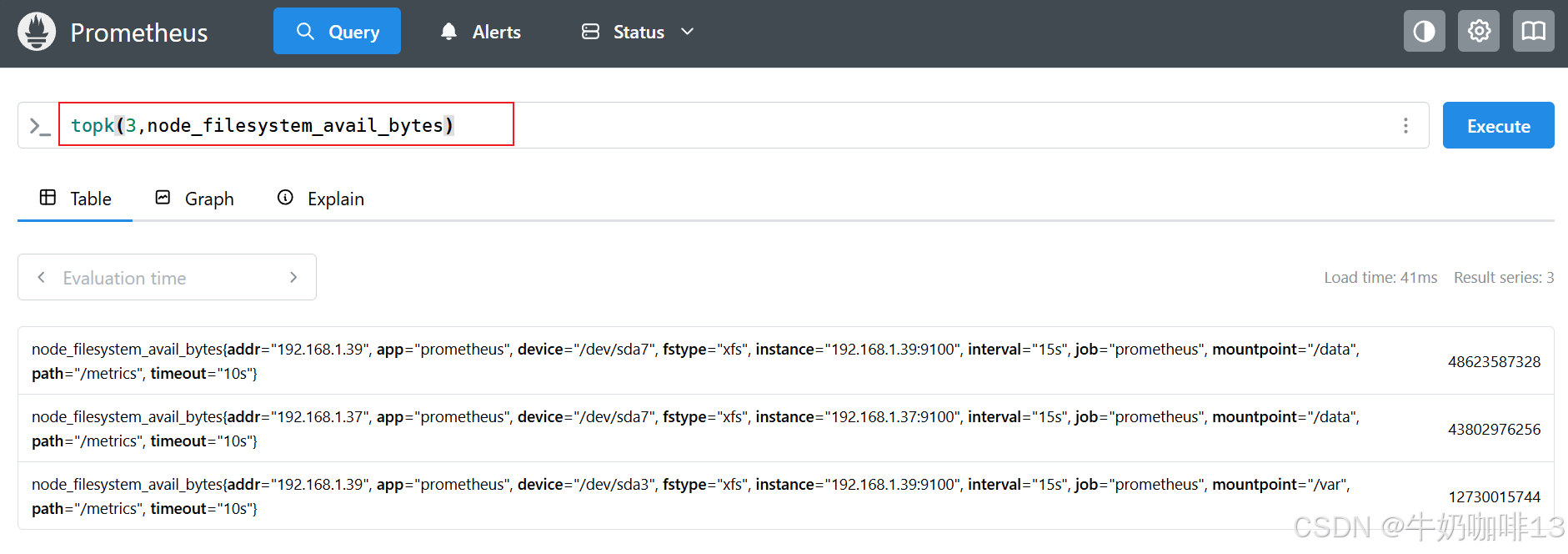
topk(3,node_filesystem_avail_bytes)
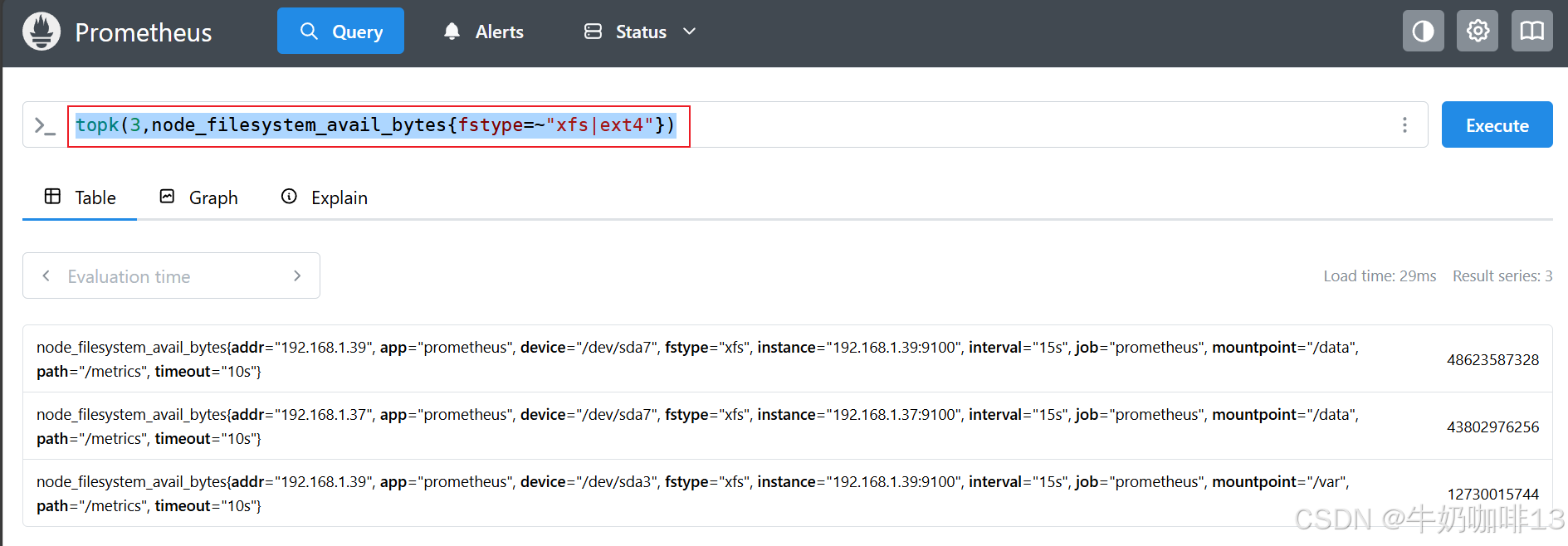
topk(3,node_filesystem_avail_bytes{fstype=~"xfs|ext4"})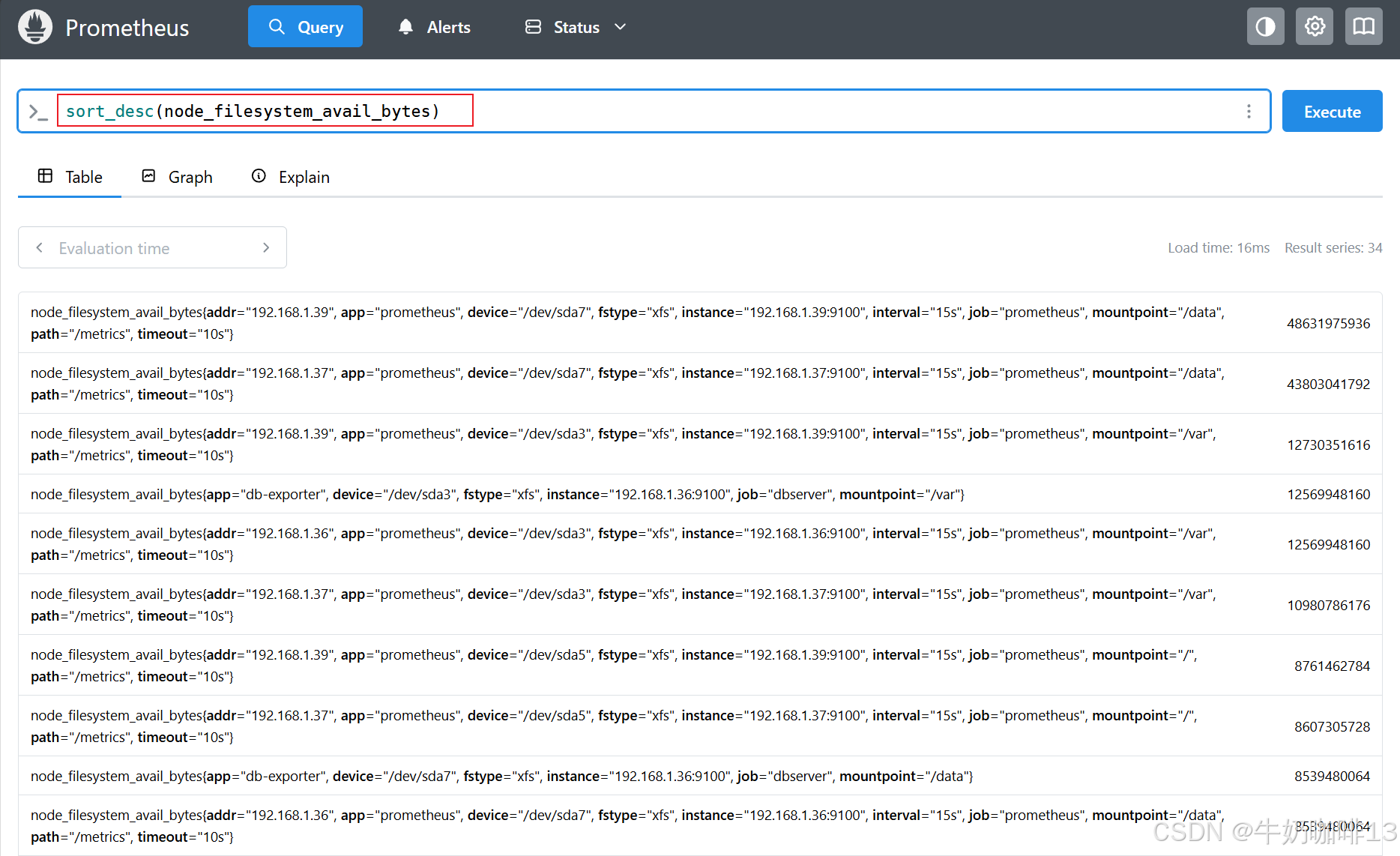
二、直方图
prometheus 中的直方图指标用来记录某个服务一系列数值的分布 。直方图通常用于跟踪请求的延迟或响应大小等指标值。直方图是如何记录数值分布的?
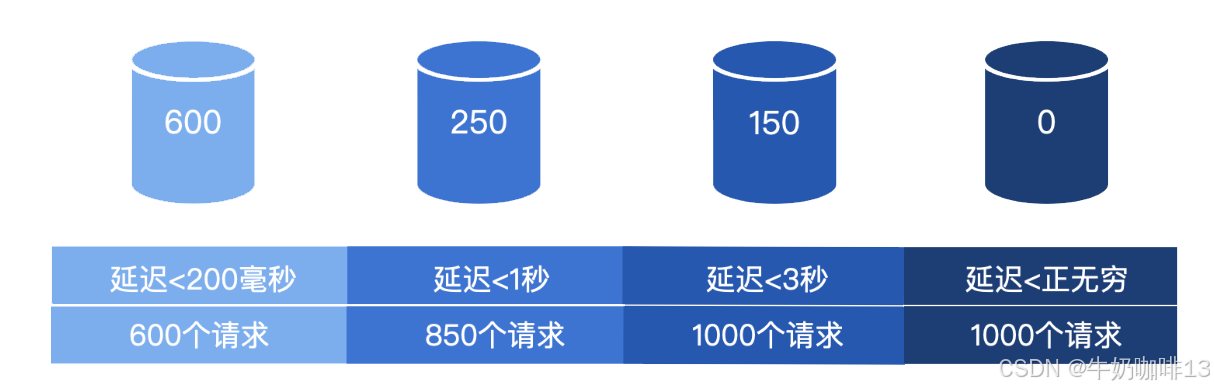
比如有个web api接口服务,监控到的样本的响应时间范围为 200ms~3s,大致的分布区间是,大部分接口延迟最小在一两百毫秒,最大的通常在 1 秒,如果超过 3 秒,就意味着系统不正常了。直方图的做法是根据数据的范围,规划多个桶(bucket),把样本数据点放入不同的桶来统计。根据web api接口服务的情况,可以规划 4 个桶,假设有 1000 个请求,来看下各个桶和对应的样本统计值情况如下:
《1》延迟小于 200 毫秒的,有 600 个请求落到了这个区间。
《2》延迟小于 1 秒的,有 850 个请求落到了这个区间,其中大于 200 毫秒的有 250 个请求。
《3》延迟小于 3 秒的,有 1000 个请求落到了这个区间,其中大于 1 秒的有 150 个请求。
《4》延迟小于正无穷的,也就是总量,有 1000 个请求落到了这个区间,说明没有大于 3 秒的请求。
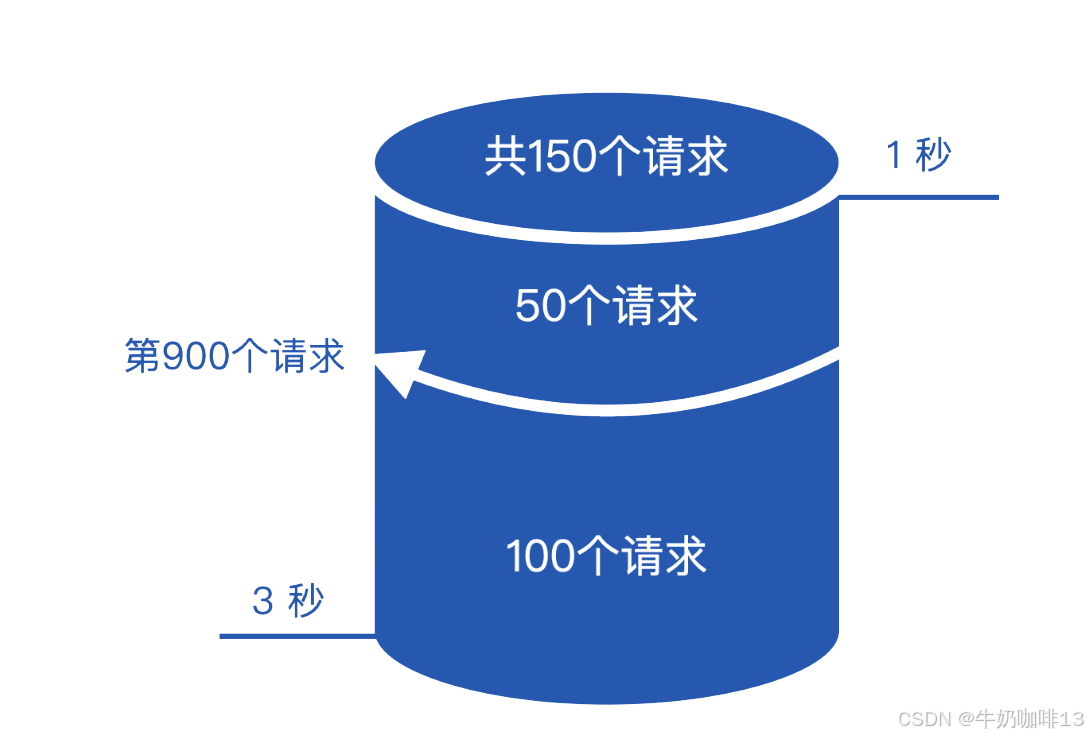
现在来计算 90 分位值,也就是第 900 个请求,说明这个值落到了第 3 个桶,延迟小于 3 秒的桶,于是我们可以得出结论,90 分位的延迟大小是 1~3 秒之间。
虽然知道了区间范围,但是还无法得出具体的值。为了计算出具体的值,prometheus 有个假设,它认为各个桶里的样本数据是均匀分布的,即第三个桶的这 150 个请求,延迟最小的请求恰好延迟了 1 秒,延迟最大的恰好延迟了 3 秒 ,总量的第 900 个请求,是这个桶里的第 50 个请求,最终 90 分位的延迟数据计算方法是:(3−1)×(50÷150)+1=1.67秒。 这就是 histogram_quantile函数的计算方法。【histogram_quantile 】是 Prometheus 的一个函数。用来计算分位数,而且是一个预估值,并不完全准确,因为这个函数是假定每个区间内的样本分布是线性分布来计算结果值的。预估的准确度取决于 bucket 区间划分的粒度,粒度越大,准确度越低。
在 prometheus 内部,直方图被实现为一组时间序列,每个序列代表指定桶的计数(例如10ms以下的请求数、25ms以下的请求数、50ms以下的请求数等)。 在 prometheus 中每个 bucket 桶的计数器是累加的,这意味着较大值的桶也包括所有低数值的桶的计数。在作为直方图一部分的每个时间序列上,相应的桶由特殊的 le 标签表示。le 代表的是小于或等于。
bash
prometheus_http_request_duration_seconds_bucket{handler="/metrics"}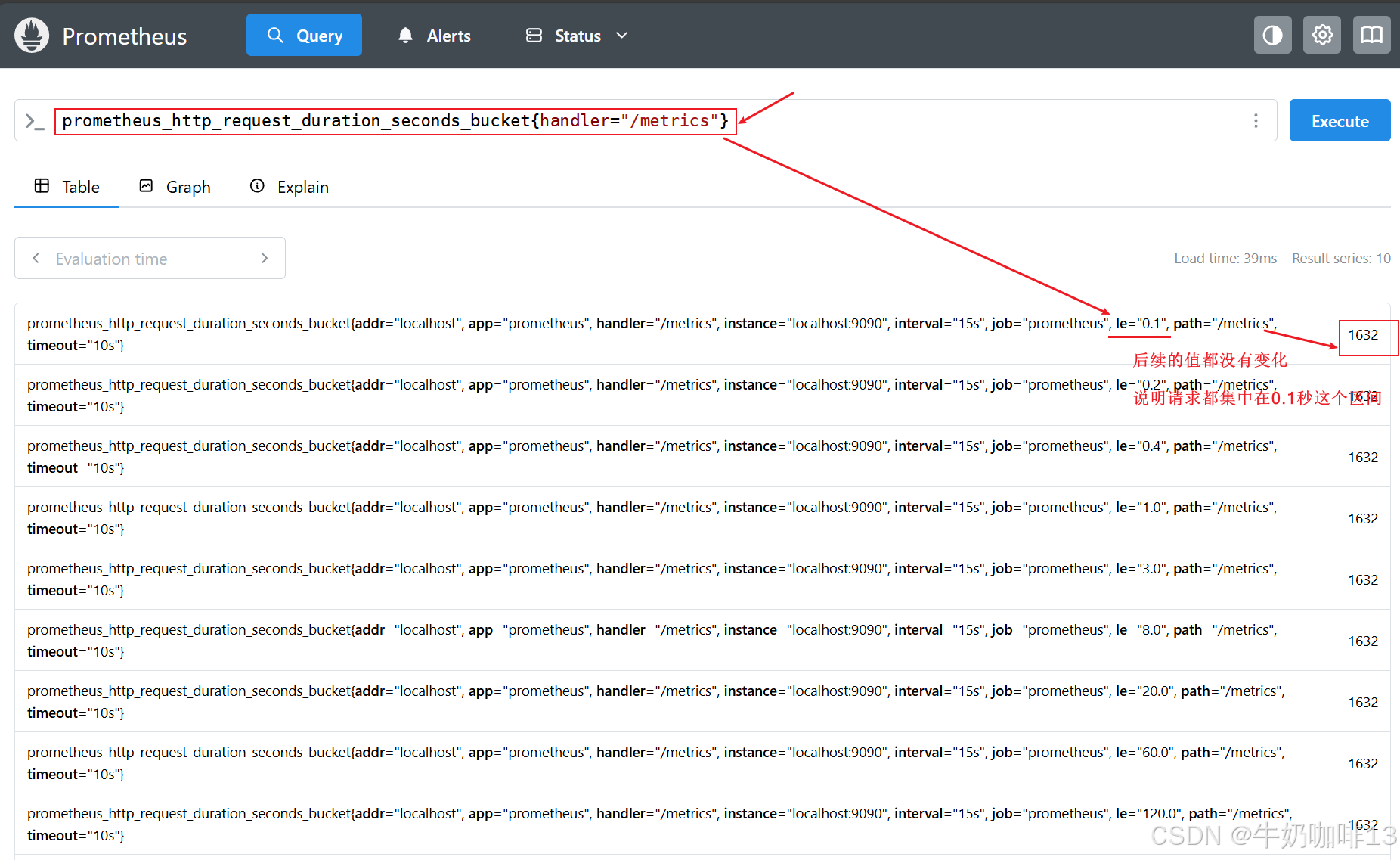
直方图可以帮助我们了解这样的问题(如:"我有多少个请求超过了100ms的时间?" (当然需要直方图中配置了一个以 100ms 为边界的桶),又比如"我99%的请求是在多少延迟下完成的?",这类数值被称为百分位数 或分位数)。在 prometheus 中这两个术语几乎是可以通用,只是百分位数指定在 0-100 范围内,而分位数表示在 0 和 1 之间,所以第 99 个百分位数相当于分位数 0.99。
bash
#直方图示例
#示例:计算过去5分钟内第90个百分位数的API延迟
histogram_quantile(0.9,rate(prometheus_http_request_duration_seconds_bucket{handler="/metrics"}[5m])) 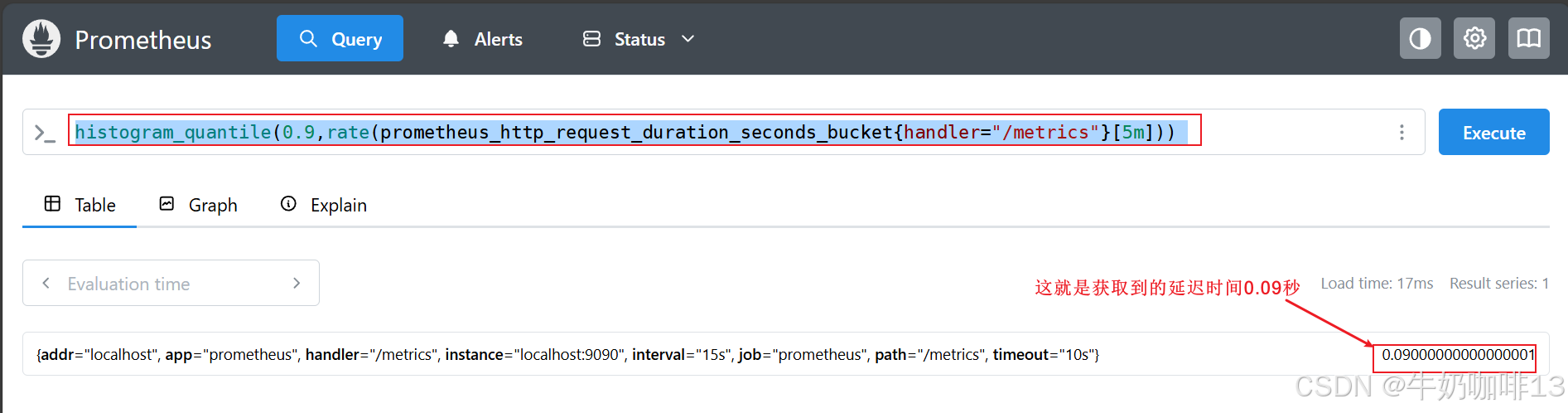
三、实例状态监测
3.1、检查实例抓取状态
每当 prometheus 抓取一个目标时,它都会存储一个合成的样本(其中包含指标名称 up 和被抓取实例的 job 和 instance 标签),如果抓取成功,则样本的值被设置为 1,如果抓取失败,则设置为 0,因此可以通过下面的查询来获取当前哪些实例处于正常或挂掉的状态:
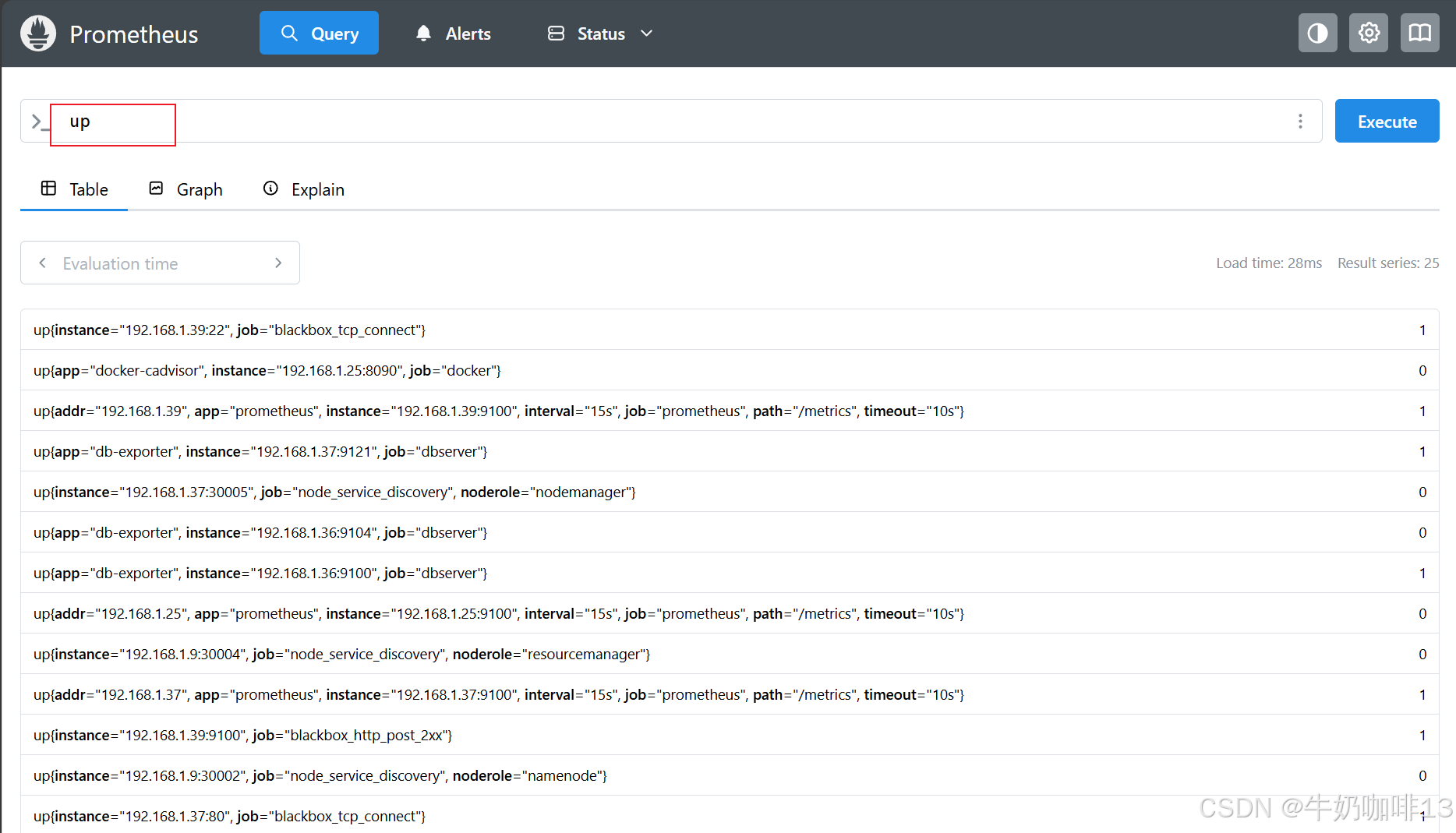
bash
#检查实例抓取状态示例
#1-示例1:获取所有掉线的实例
up==0
#2-示例2:获取挂掉实例的总数
sum by(instance)(up==0)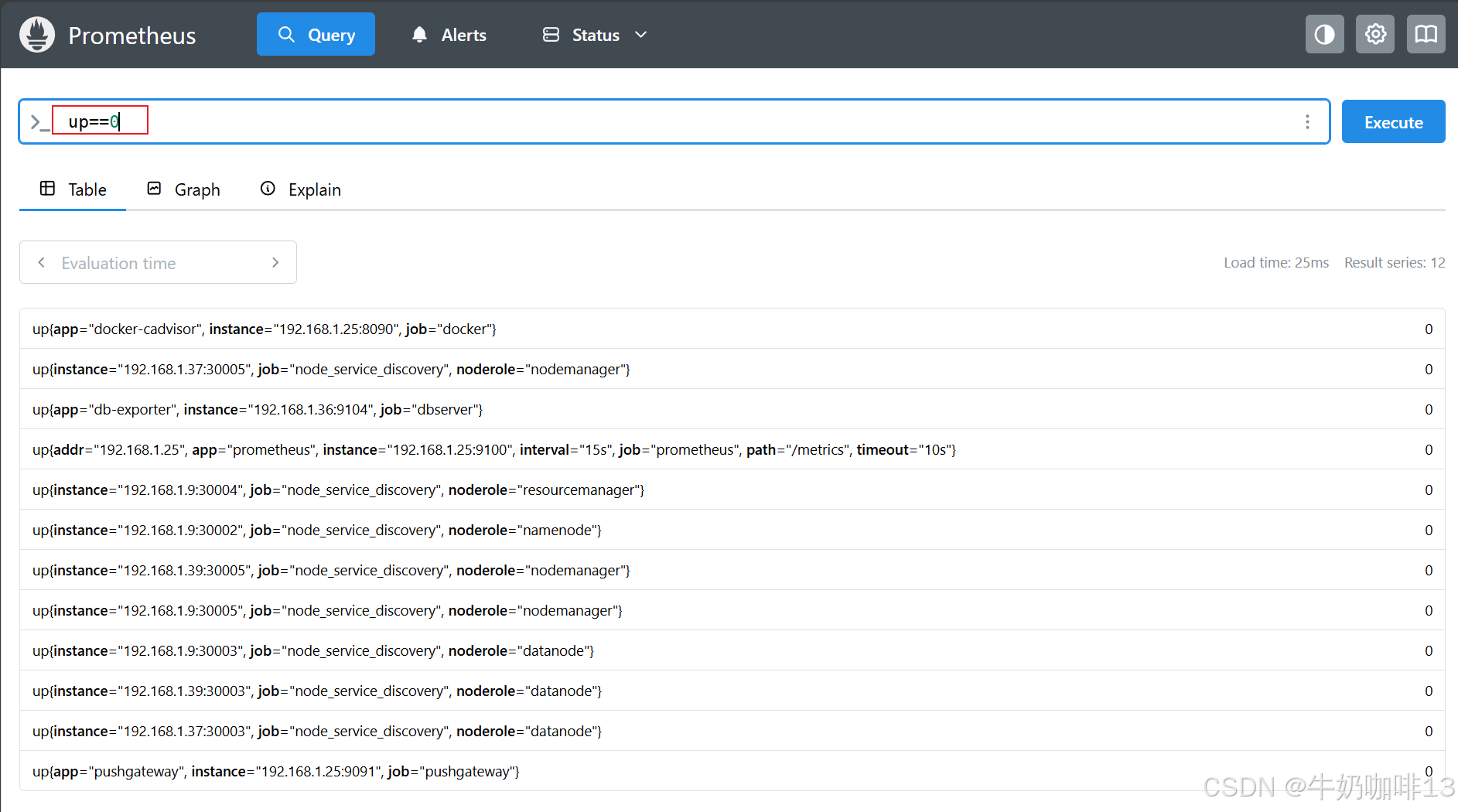
3.2、检查序列数据
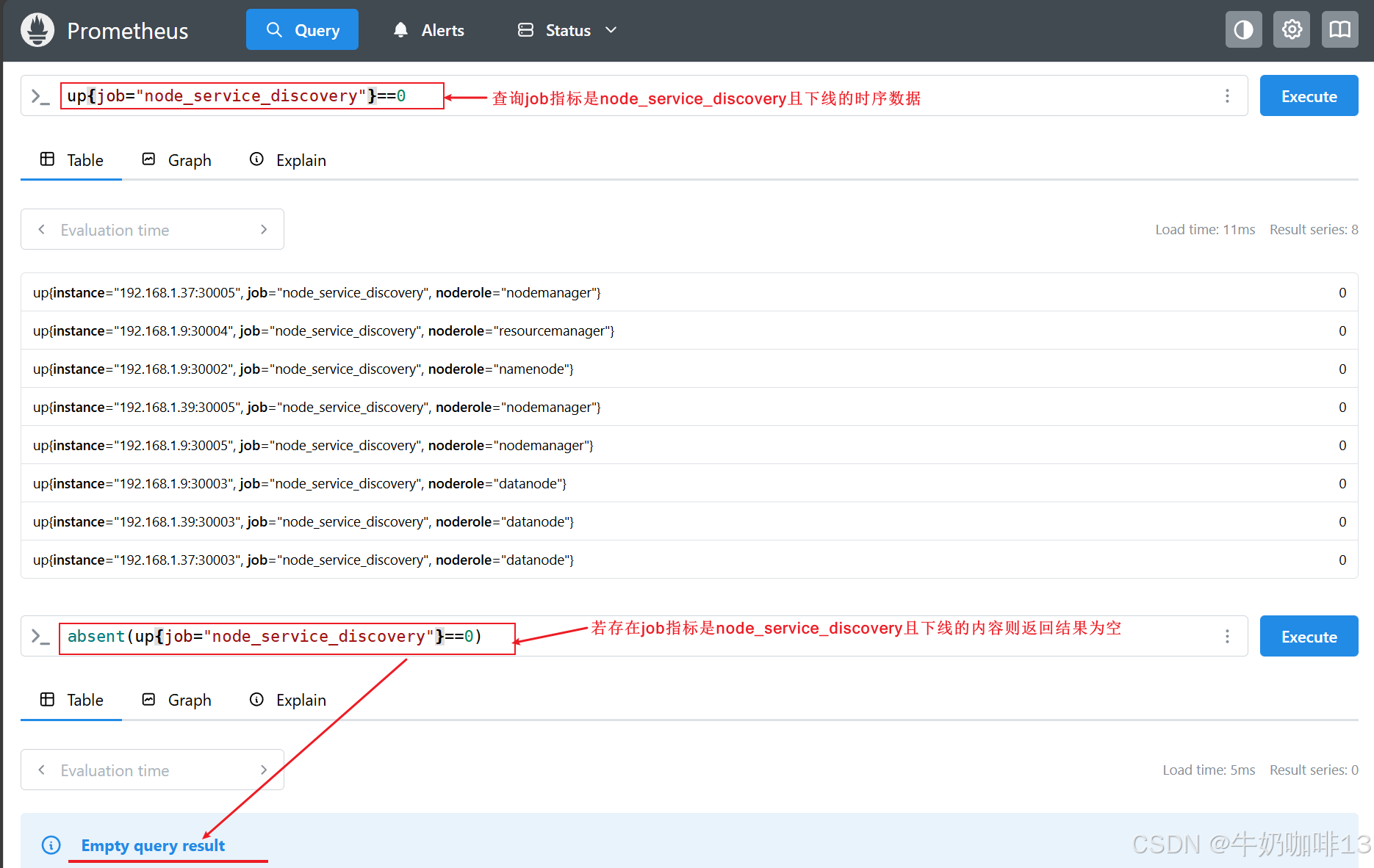
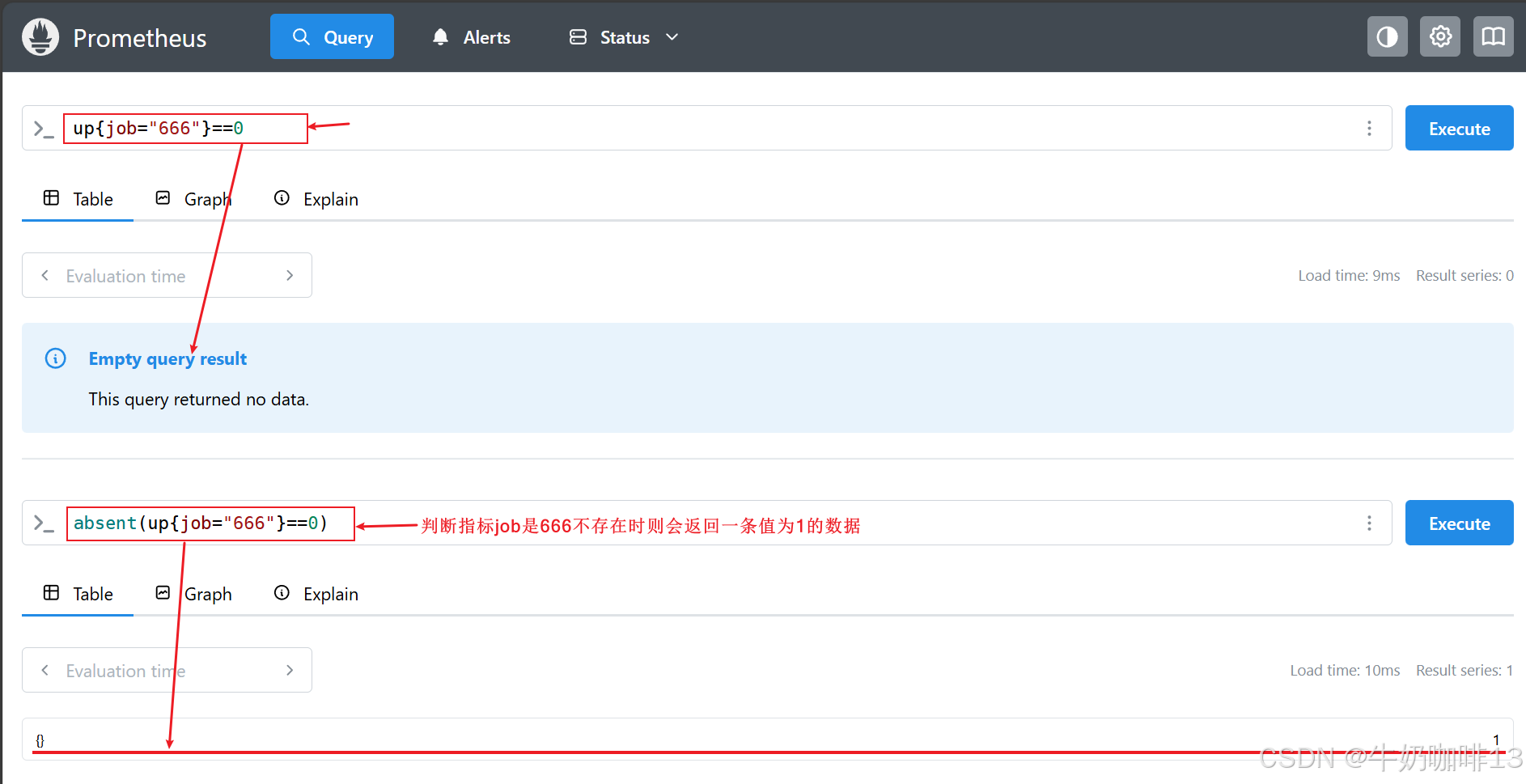
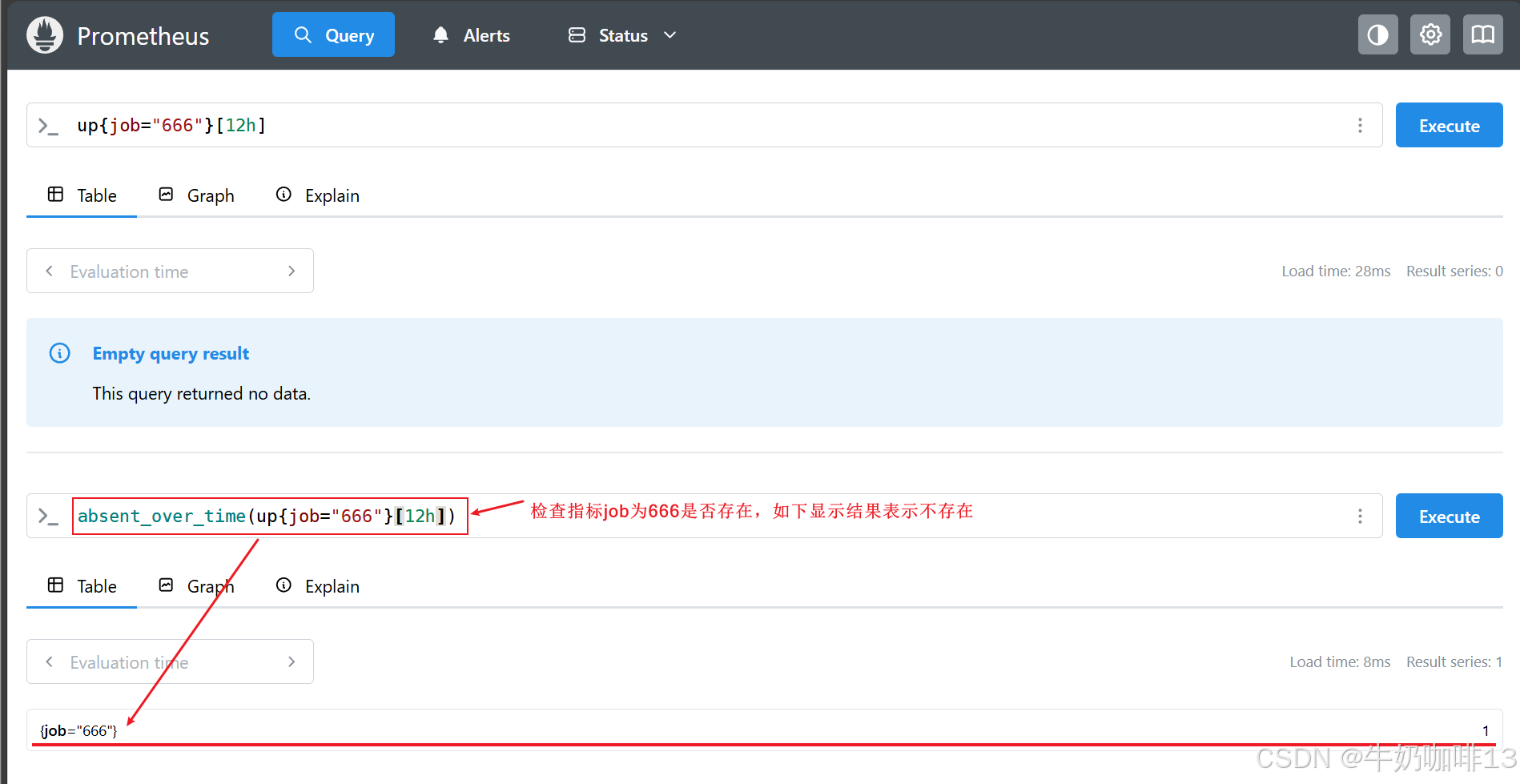
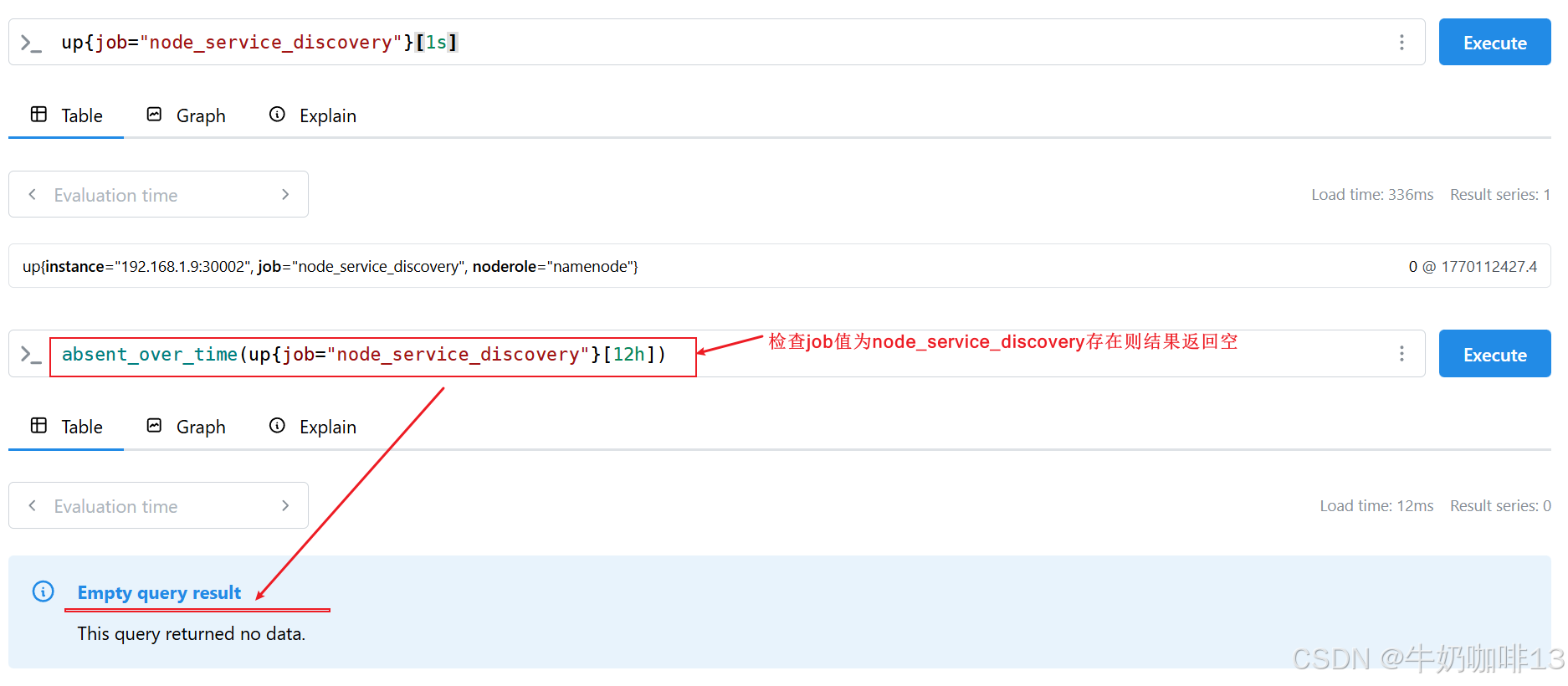
在某些情况下,只查看实例的状态是不够的,有时还需要检测是否存在某些序列,上面我们用【up == 0】语句来查询所有无法抓取的实例服务,但是只有已经被抓取过的目标才会被加上 up 指标,如果 Prometheus 都没有抓取到任何的实例服务目标,应该怎么办呢?【此时,absent() 函数就非常有用了,absent() 将一个瞬时向量作为其输入,当输入一个已存在的序列时,将返回一个空结果,不存在时,将返回单个输出序列,而且样本值为1 】。此外还有一个 函数【absent_over_time() 】,它接受一个区间向量,告诉我们,在该输入向量的指定时间范围内是否有样本(当输入一个已存在的序列时,将返回一个空结果,不存在时,将返回单个输出序列,而且样本值为1)。
bash
#检查序列数据示例
#示例1-检查指定指标存在且掉线
up{job="node_service_discovery"}==0
absent(up{job="node_service_discovery"}==0)
#示例2-检查指定指标不存在
up{job="666"}==0
absent(up{job="666"}==0)
#示例3-检查
up{job="666"}[12h]
absent_over_time(up{job="666"}[12h])