一、前馈神经网络 FNN
FNN:feedforward Neural Network:最基础最经典的人工神经网络------传统神经网络
传统神经网络:FNN、FCNs、MLP
//工作原理:
1.单向流动,数据没有循环和反馈;
2.全连接形式;
3.每个连接都有可以学习的权重,通过激活函数实现线性转化到非线性转化
//
//与现代圣经网络的区别
现代:1.通过共享参数减少参数
2.适用的数据:图像、序列数据
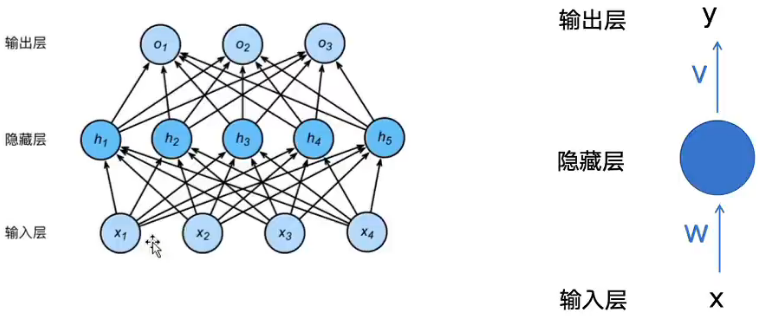
结构:由一个并行的固定长度向量在输入层输入,单向传播,每一层接受前一层的神经元信号,经过加权求和 + 激活函数传递给下一层,所以也叫做(多层感知器)MLP
优点:单向数据流动,没有循环;用于简答的分类和回归预测任务
缺点:
1.缺乏记忆功能,对处理序列数据能力 有限
2.由于多层传递:导致梯度消失或者梯度爆炸
梯度爆炸:反向传播过程中,梯度值传递时参数更细幅度过大,导致指数级增长
梯度消失: 反向传播过程中,靠近输入层的参数没办法更新
以FNN为基础,衍生出很多其他 CNN RNN transformer
二、循环神经网络 RNN
RNN:Recurrent Neural Network 循环神经网络,专门涉及用于序列数据的神经网络模型
引入RNN就是引入能够记住之前模型的信息,从而考虑历史上下文
与传统神经网络的区别是什么:每一个输入为独立处理,忽略了序列中输出元素的时间/顺序关系
于是体现了RNN的优点 :
1、能够处理可变长度的序列数据(NLP)
2、参数共享、减少模型参数数量
3、能够捕捉序列的时间关系
常见应用模式:
一对多:图像描述
多对一:情感分析(正向/负向,好评差评)、文本分类(NLP)
多对多:机器翻译(序列长度不同,需要使用编码器和解码器)
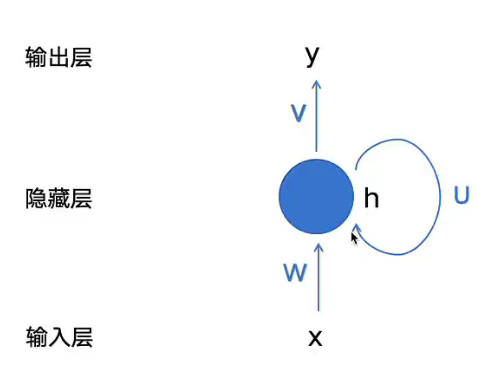
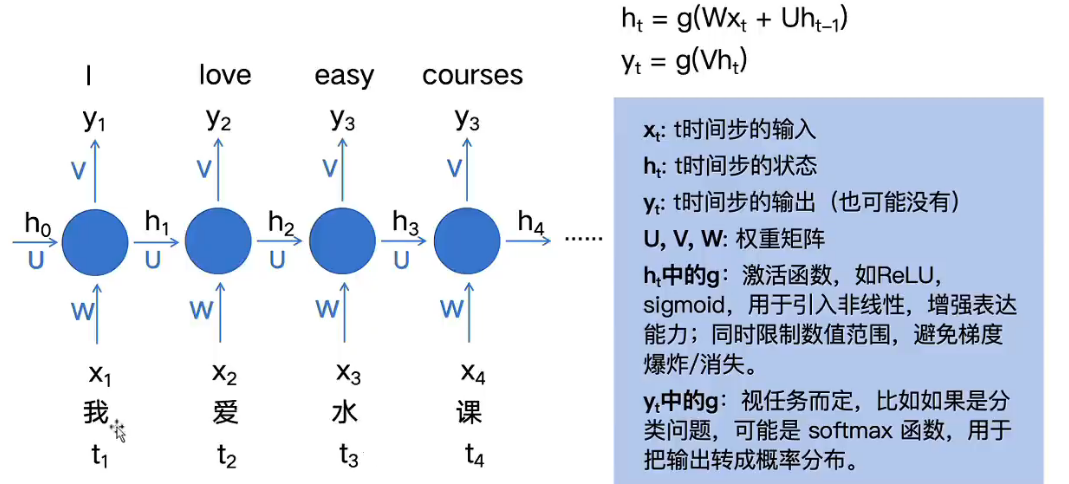
处理时序序列输入的时候可以一个个输入,而不需要一次性输入完所有的句子如上图所示,
RNN 的缺点
1、仍然会进行梯度回传 出现梯度消失/爆炸问题
2、慢,串行加法器,不能并行
3、长距离依赖:你懂的,很多修饰干扰就找不到主语
CNN
CNN的核心用于图像识别,通过卷积层提取空间特征。
输入图像、感受野、池化层、填充padding、步长、特征图、激活函数
卷积循环神经网络
局部空间结构,时间序列依赖
视频动作识别:卷积提取人物动作,循环层分析连续帧的动作变化
三、encoder/decoder 编码器和解码器结构
将输入内容与输出内容拆分成两部分
Encoder主要时对整个序列的语义进行编码,涵盖整个输入文本的语义信息
Encoder - > 最后输出的C有两种方式传入到Decoder
Encoder输出到Decoder的两种方式
第一种:单上下文向量传递:
h4直接作为C进行输出,即 C = h 4 h_4 h4 = S 0 S_0 S0
问题:
长距离,到最后一个输入的时候很难有将重要信息都编码到这个定长向量中。
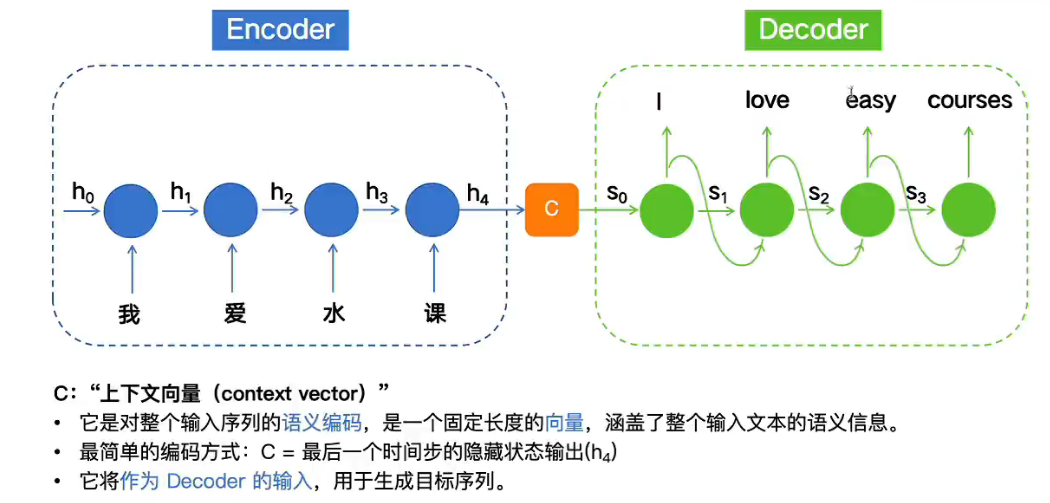
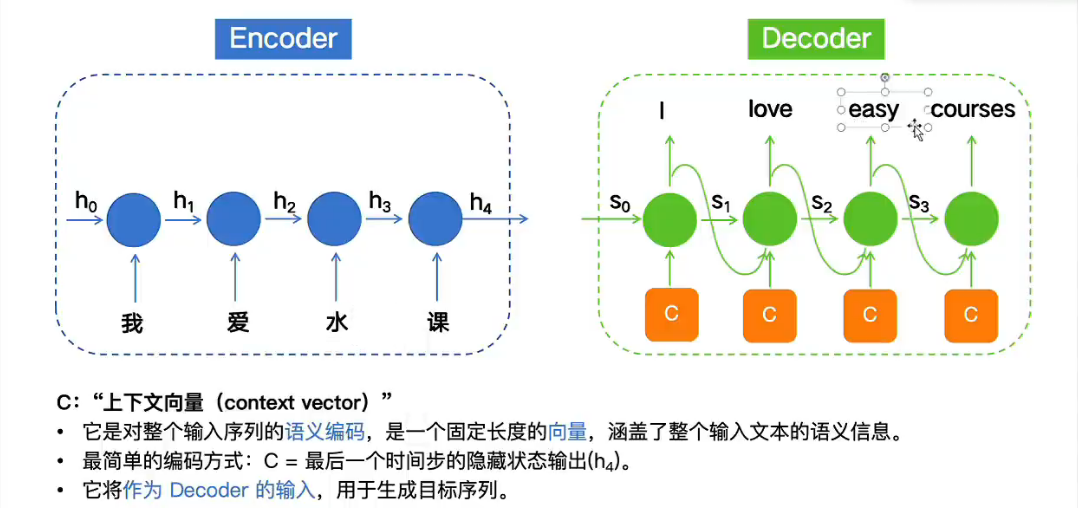
第二种:全隐藏状态序列 + 注意力机制
encoder:保留所有时间步隐藏状态 h 1 、 h 2 、 h 3 . . . . h_1、h_2、h_3 .... h1、h2、h3....
decoder:每生成一个词都会动态计算上下文讲 C t C_t Ct加入
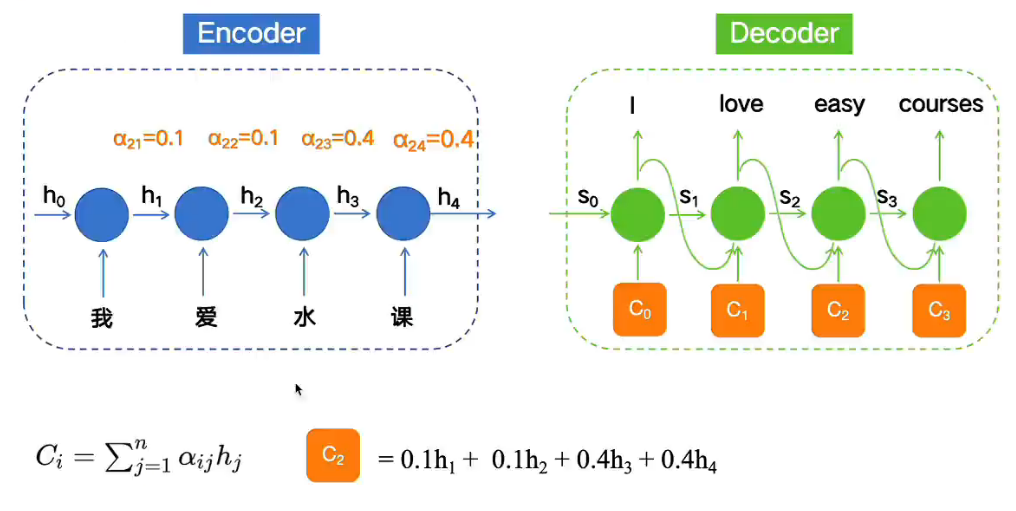
上图运用到了自注意力机制:也就是分配了权重,其中水课的权重分配最多,因此后续翻译也会重视这两个字组成的词的翻译,而不是翻译成water course
Attention Mechanism 注意力机制
解决模型处理长序列以往问题
解决不同时间输入有各自的重要性,不会被同等对待
核心思想:让模型在生成每个输出时,能够直接回头看整个序列,并根据相关性给不同位置的输入分配不同的权重。
四、LSTM
long short-term mechanism 长短期记忆网络
是一种特殊的循环神经网络,解决传统的RNN在处理长问题上。
LSTM:可以贯穿整个序列的信息传送带
该传送带有三大门控逻辑:遗忘门、输入门、输出门
遗忘门:Forget Gate 读取当前时刻的输入和上一时刻的隐藏状态
输入门:Input Gate 筛选值存入长期记忆的信信息
输出门:output Gate 决定当前时刻应该输出什么信息
LSTM的变体:双向LSTM、GRU
五、Transfomer
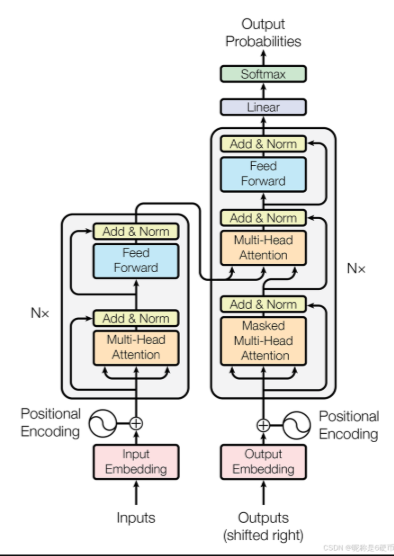
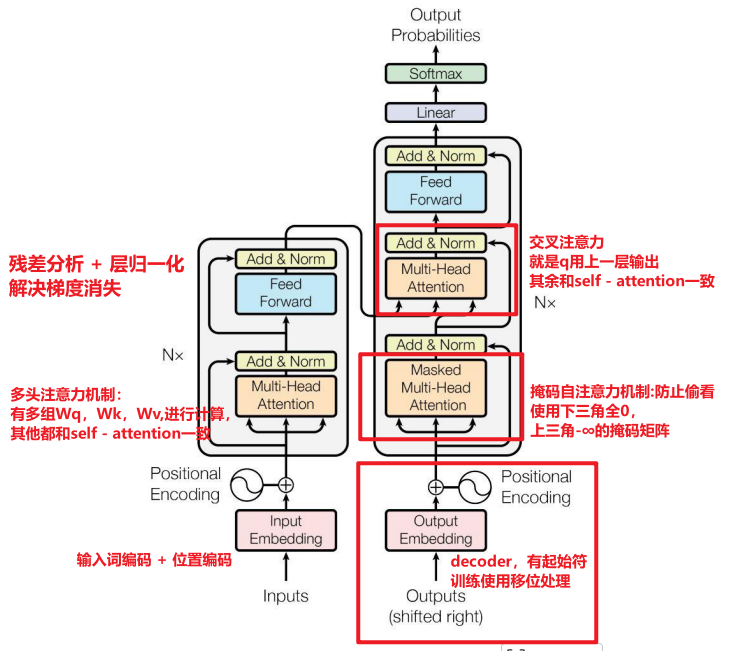
1、输入处理(词编码 / 位置编码)
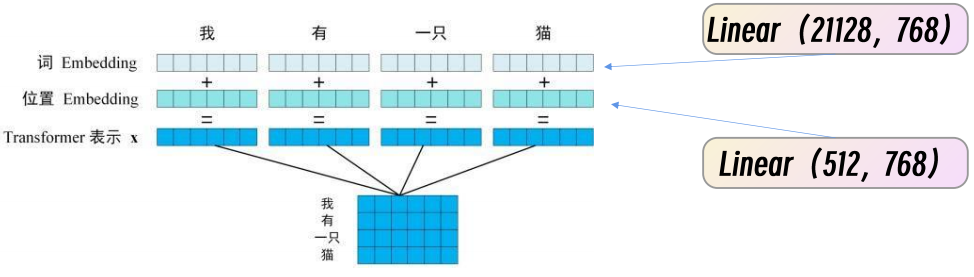
词编码 :one - hot 编码词共21168,经过liner(21128,768)完成输入
位置编码 :one - hot 编码,共512,经过liner(512,768)完成输入
我爱你 与 你爱我词都是相同的,但是表达的含义不同,是因为句子之间位置关系,所以必须是使用位置编码才能提升模型的能力
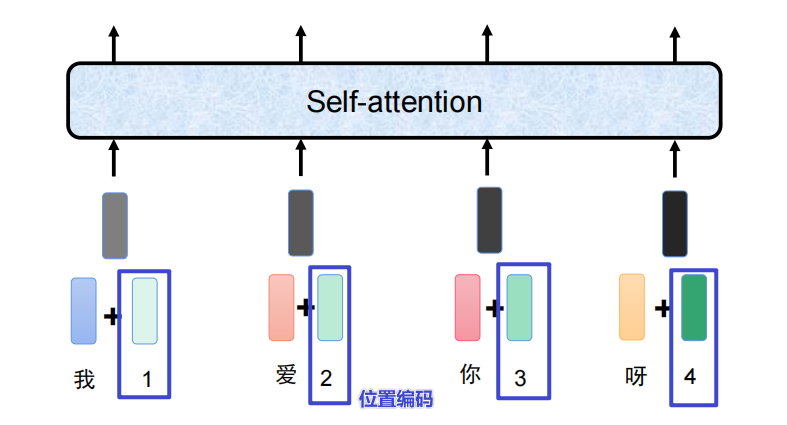
词编码 + 位置编码 = token(字)
2、self - attention
一个句子可以和序列中其他位置建立直接的练习,就是句子中的词语能将注意力分配给其他每个词上,根据语义相关性给他们分配不同的权重
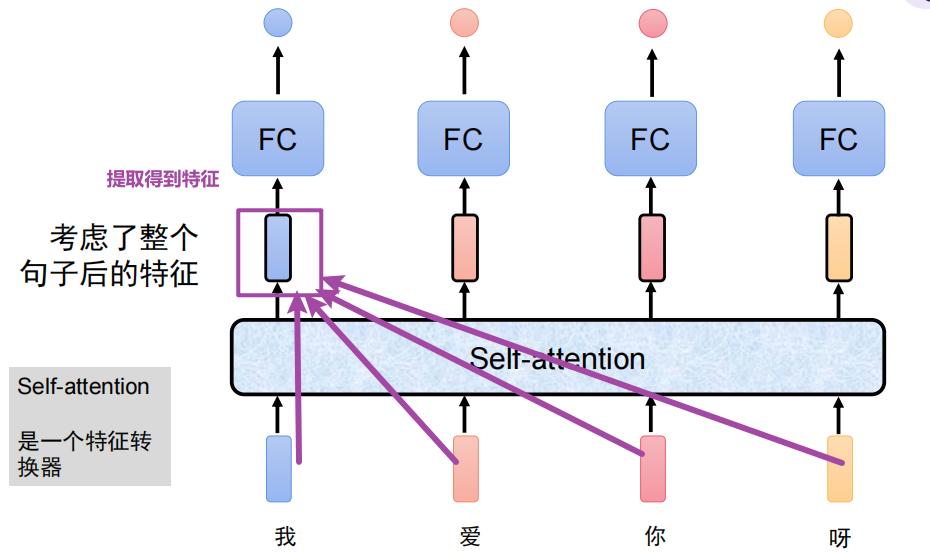
将这个词在其他词上的特征都考虑到后提取到的特征
b 1 = a 1 , 1 + a 1 , 2 + a 1 , 3 + a 1 , 4 b_1 = a_{1,1} + a_{1,2} + a_{1,3}+a_{1,4} b1=a1,1+a1,2+a1,3+a1,4
为这个句子的每个词分配注意力(类似于权重),
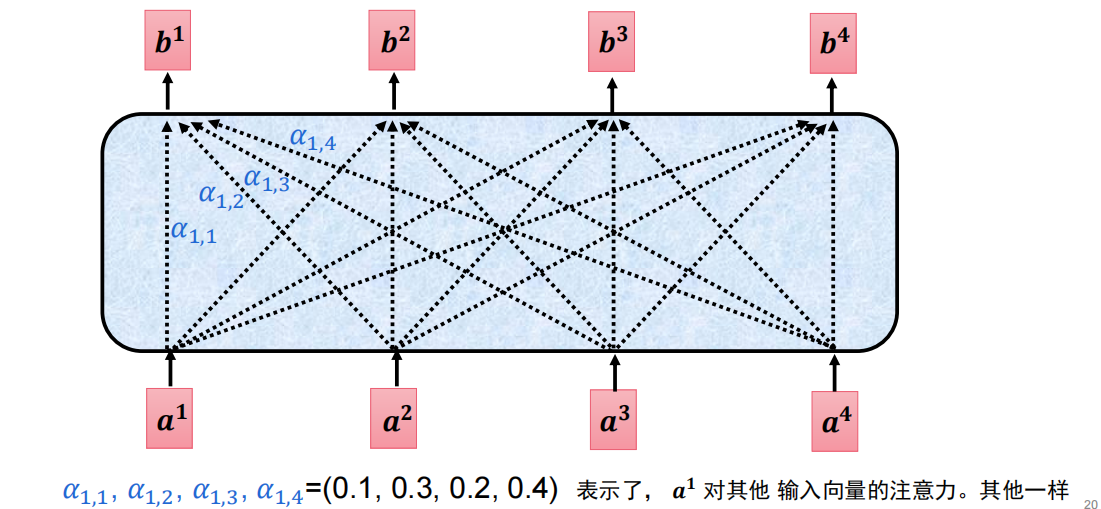
但是这个注意力机制太固定了,我们需要灵活的分配,于是需要重新计算各个注意力
(1)如何计算注意力(权重):使用点乘
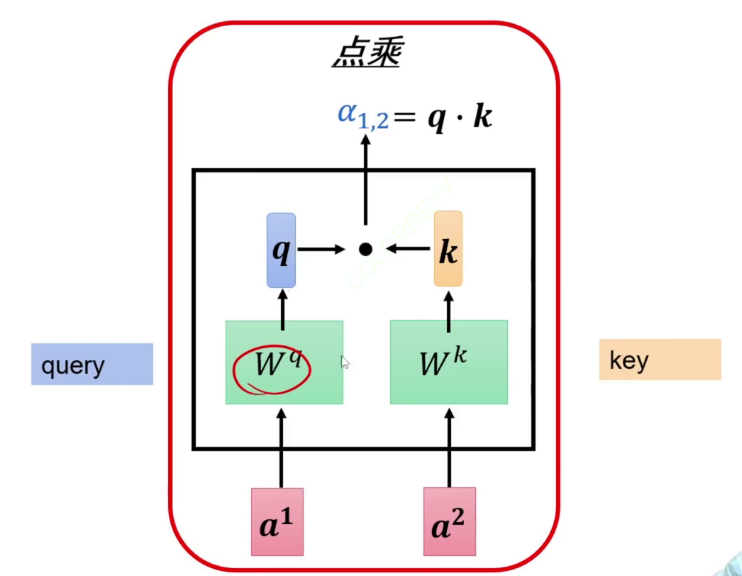
下面举例计算 a 1 , 2 a_{1,2} a1,2 即a1对a2应该分配多少注意力
模型中有矩阵 W q , W k , W v W^q, W^k, W^v Wq,Wk,Wv (只有这3个参数需要学习)让他们分别于a相乘得到对应的 q 1 , k 2 q^1, k^2 q1,k2
于是就可以计算得 a 1 , 2 = q 1 ⋅ k 2 a_{1,2} = q^1 · k^2 a1,2=q1⋅k2
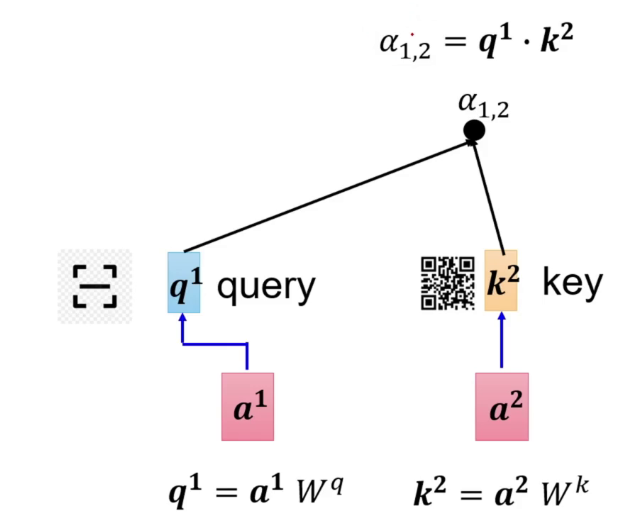
计算其他词的注意力如下
a 1 , 1 = q 1 ⋅ k 1 、 a 1 , 2 = q 1 ⋅ k 2 、 a 1 , 3 = q 1 ⋅ k 1 、 a 1 , 4 = q 1 ⋅ k 4 a_{1,1} = q_1 · k_1 、a_{1,2} = q_1 · k_2 、 a_{1,3} = q_1 · k_1 、 a_{1,4} = q_1 · k_4 a1,1=q1⋅k1、a1,2=q1⋅k2、a1,3=q1⋅k1、a1,4=q1⋅k4
使用softmax,保证合起来的注意力和为1
a ' 1 , 1 = s o f t m a x ( a 1 , 1 ) 、 a ' 1 , 2 = s o f t m a x ( a 1 , 2 ) 、 a ' 1 , 3 = s o f t m a x ( a 1 , 3 ) 、 a ' 1 , 4 = s o f t m a x ( a 1 , 2 = 4 ) a`{1,1} =softmax(a{1,1})、 a`{1,2} = softmax(a{1,2})、a`{1,3} =softmax(a{1,3})、a`{1,4} =softmax(a{1,2=4}) a'1,1=softmax(a1,1)、a'1,2=softmax(a1,2)、a'1,3=softmax(a1,3)、a'1,4=softmax(a1,2=4)

最后再加入v,则就得到看过了一句话后第一个字的特征 b 1 b_1 b1

V 1 = a 1 W v 、 V 2 = a 2 W v 、 V 3 = a 3 W v 、 V 4 = a 4 W v V^1 = a^{1}W^{v}、V^2 = a^{2}W^{v}、V^3 = a^{3}W^{v}、V^4 = a^{4}W^{v} V1=a1Wv、V2=a2Wv、V3=a3Wv、V4=a4Wv
b 1 = a 1 , 1 ′ V 1 + a 1 , 2 ′ V 2 + a 1 , 3 ′ V 3 + a 1 , 4 ′ V 4 b_1 = a'{1,1}V^1 + a'{1,2}V^2 + a'{1,3}V^3 + a'{1,4}V^4 b1=a1,1′V1+a1,2′V2+a1,3′V3+a1,4′V4
同理可以生成 b 2 、 b 3 、 b 4 b_2 、 b_3、 b_4 b2、b3、b4
生成 b 2 、 b 3 、 b 4 b_2 、 b_3、 b_4 b2、b3、b4过程可以全部同时进行
全部过程计如下:
1、先分别使用三个参数对字进行输入,最后得到该字对其他的字的qkv
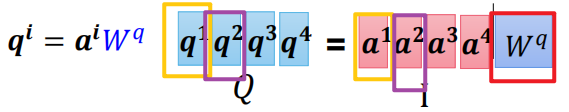
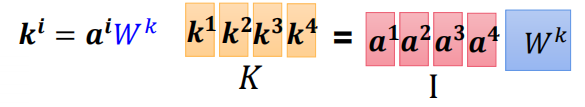
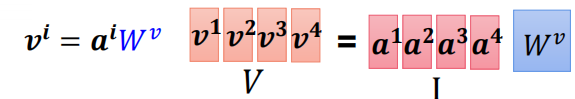
2.计算注意力:a,并且softmax

3.计算特征值b

总:参数变化
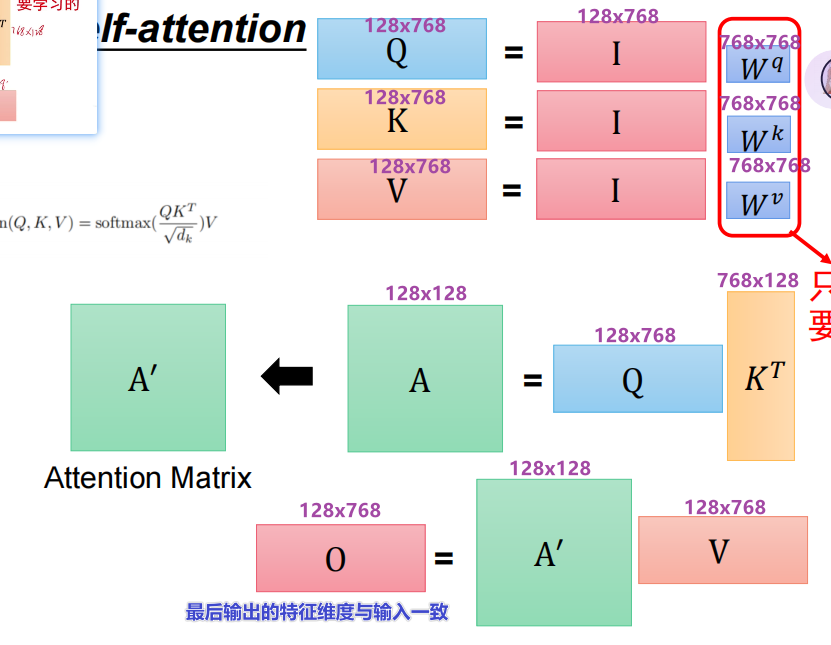
最后的输出特征维度与输入一致
由于输入输出维度都不会改变,所有可以多用几层self-attention
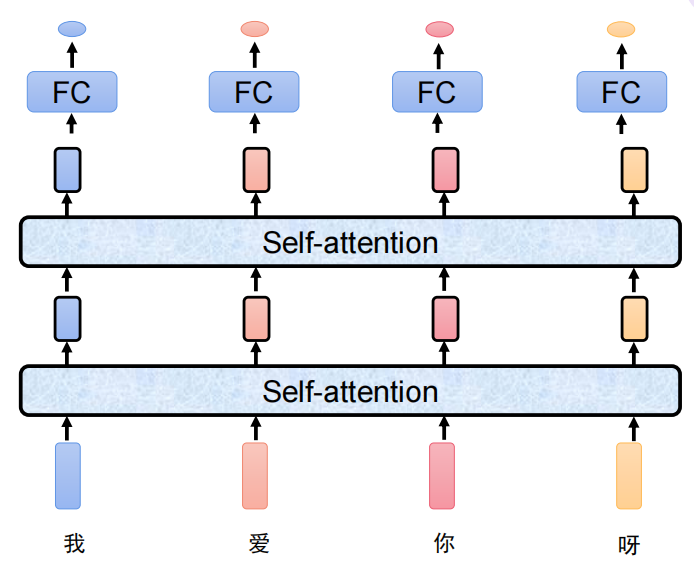
3、残差连接
o u t = f ( x ) + x out = f(x) + x out=f(x)+x
4、Transfomer的编码器------提取特征
将输入的序列转化成计算机能够处理的连续数值向量,捕捉上下文中的语义信息,针对不同的含义生成不同的向量
将N = 6 个相同的层堆叠在一起,每层都有两个子层:多头子注意力机制、全连接神经网络。每个子层都会采用残差连接、进行归一化,以便稳定训练过程并加速收敛。
5、Transfomer的解码器
解码器:同样由 N = 6个相同层堆叠而成。
每层分别是:带掩码的自注意力层、encoder-decoder注意力层、前馈网络层。
1.带掩码子注意力层,通过掩码机制只能看前面 i - 1 个未知信息,防止作弊,模拟人类逐字生成文本的过程。使用下三角矩阵可以实现掩码机制
2.encoder-decoder注意力层(交叉注意力机制),提供q值,而kv来自编码器的输出,否则q和k相乘的结果相同,就是下面这张图的区别。


3.前馈神经网络层:专注对每个位置的表示进行非线性变换和特征提取。一般有两层:第一层低 - 高纬度,通过激活函数Relu 引入非线性,第二层将维度压缩至原来的标准维度。
FFN ( x ) = m a x ( 0 , x W 1 + b 1 ) W 2 + b 2 \text{FFN}(x) = max ( 0,xW_1 + b_1 ) W_2 + b_2 FFN(x)=max(0,xW1+b1)W2+b2
6、总Transfomer的encoder - decoder
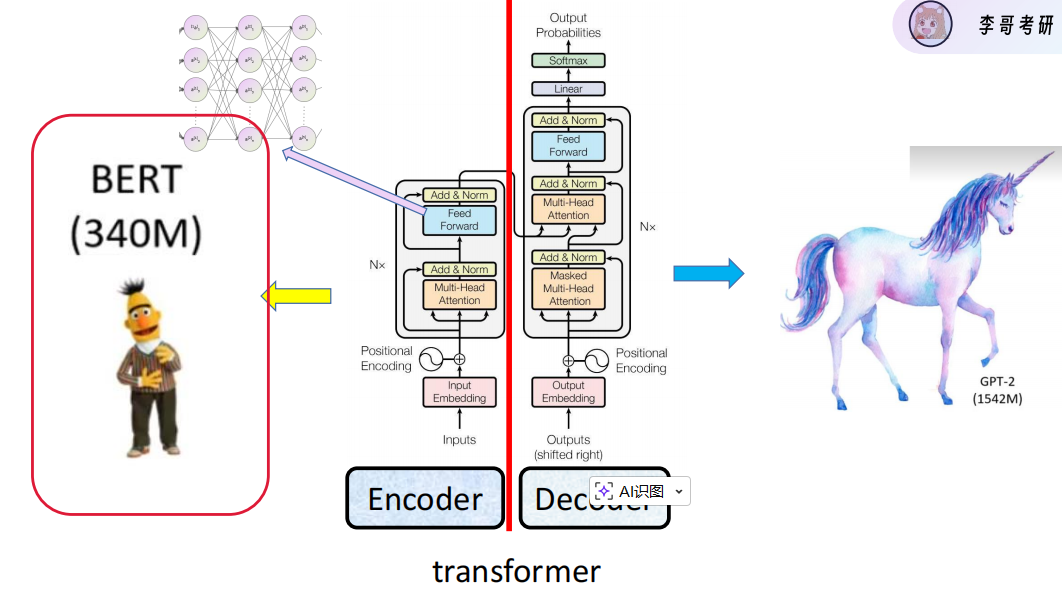
encoder == bert , decoder == GPT
Q: query - 代表我们想要寻找的信息特征
K ; Key:键向量代表每个筛选信息的索引特征
V : value :代表包含了实际信息的内容
Transfomer的公式: Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text{Attention}(Q,K,V) = \text{softmax}\left( \frac{QK^T}{\sqrt{d_k}} \right)V Attention(Q,K,V)=softmax(dk QKT)V
其中 d k \sqrt{d_k} dk 是:缩放点积注意力机制中的缩放因子,除以这个,可以将点积方差范围缩小至合理的空间 (有点像归一化),让softmax的输出更加平滑,从而保证训练的稳定性。
Q K T QK^T QKT 表示计算查询与所有键之间的相似度矩阵
乘以V:实现加权求和的过程,
注意力机制 vs 多头注意力机制
- 注意力机制:一人分多个角色,要关注语义、语法、位置,每个地方都懂一点但不精通,得到的关系类型是平均的,往往会产生妥协的结果。
- 多头注意力机制:职能划分很细致,团队专家协作,捕捉多种不同类型,语法专家、语义专家、位置专家,最后将所有的头拼接起来,通过一个线性变化得到最终的结果。(避免了单一视角的误判),每个专家都对自己负责的领域有更加清晰的描述,不会被其他信息干扰。
六、生成任务
训练阶段:decoder 输入时会移位 + 原始文本序列
例:输入start I love you -> 输出 i love you end
可以一次性计算所有位置的损失
训练的loss来decoder输出后再与真实目标序列进行计算
测试/推理阶段 :自回归生成:decoder输入起始符+上一步生成的词,有点像是RNN,
只能一个一个词的生成,就是大模型一个一个词生成。
七、总结图transformer