摘要:近年来,大语言模型(LLM)展现的跨领域泛化能力常被公众认知为"人工智能的突变式爆发"。本文从计算学习理论、网络架构机制、优化目标演进与系统工程约束四个维度,论证现代AI大模型并非技术代际的断裂,而是深度神经网络(Deep Neural Networks, DNN)在规模扩展律(Scaling Laws)与自监督学习范式驱动下的必然连续形态。所谓"智能跃迁",本质上是高维统计学习系统在数据量、参数量与计算量跨越临界规模阈值(Critical Threshold)后产生的相变现象(Phase Transition),而非架构本质的根本改变。
一、问题的起点:AI真的"突然变聪明"了吗?
过去十年,深度学习已经在各个领域取得成功:
- 图像识别(CNN)
- 语音识别(RNN/LSTM)
- 机器翻译(Seq2Seq)
- 自然语言理解(BERT)
然而这些模型大多给人一种印象:
很强,但只会干一件事。
而近年的大模型却表现出跨领域能力:
- 强大的语言理解
- 写文章
- 生成代码
- 做数学推理
- 执行复杂项目指令
许多能力仿佛末世影视片照进了现实,这让许多人产生一种错觉:AI仿佛突然从"工具"变成了"通用智能体"。
但从技术史视角审视,这一跃迁是连续累积量变引发的质变,而非技术路径的断裂。深度神经网络的核心数学框架、优化方法与计算图机制并未发生本质改变。

二、本质统一:大模型仍为深度神经网络的数学连续体
从函数逼近论的角度,大模型与传统DNN共享统一的数学形式:
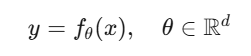
其中 f 为由可微分非线性变换构成的复合函数,通过反向传播(Back-Propagation)与梯度下降(Gradient Descent)进行参数优化。
无论是 CNN、RNN 还是 Transformer,本质都是由多层可微函数复合而成,通过反向传播进行梯度优化。
| 维度 | 传统DNN | 当代大模型 | 连续性分析 |
|---|---|---|---|
| 数学表征 | 多层非线性函数逼近 | 深度可微函数复合 | 完全一致 |
| 优化机制 | 随机梯度下降(SGD/Adam) | 分布式AdamW/Adafactor | 算法族系延续 |
| 参数空间 | 权重矩阵 W∈Rn×m\mathbf{W} \in \mathbb{R}^{n \times m}W∈Rn×m | 高维张量参数化 | 维度扩展,形式未变 |
| 表征学习 | 分层特征提取 | 上下文相关动态表征 | 深度与宽度的量变 |
因此,大模型并非"新物种",而是深度神经网络在表征容量(Model Capacity) 与训练目标(Learning Objective) 演进下的高阶形态。
三、关键转折一:从"任务拟合"到"世界建模"的认知升级

传统深度神经网络
传统深度学习的核心范式为判别式建模(Discriminative Modeling) ,主要解决的是任务驱动的监督学习问题 ,即学习条件概率 P(y∣x) :
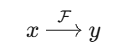
其中**(x,y)** 来自特定任务的标注数据集。这种范式下,模型习得的是任务边界内的决策边界,能力受限于监督信号的覆盖范围。
例如:
- 图像 → 类别(猫狗分类)
- 语音 → 文本(语音识别)
- 中文 → 英文(文字翻译)
模型学习的是一个特定任务的映射函数,其能力天然受任务定义边界限制。
AI大模型
大模型通过自回归语言建模(Autoregressive Language Modeling) 转向生成式建模(Generative Modeling) ,目标函数变为:
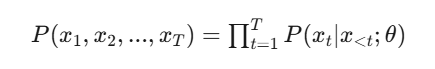
这一看似简单的"下一个Token预测"任务,迫使模型隐式学习:
- 语法结构:语言的组合性规则与层级依赖
- 事实知识:训练语料中压缩的世界状态信息
- 推理模式:多步逻辑与因果关系的统计规律
- 语义关联:跨领域概念空间的分布式表征
举个例子
假设句子是:"我要吃饭"
根据公式:
P("我要吃饭")=P("我")×P("要"∣"我")×P("吃饭"∣"我要")
拆解预测过程:
第1步 :P("我") :句子开头,预测第一个词是"我"的概率(可能还有"你"、"他"等候选)
第2步: P("要"∣"我") :看到"我"之后,预测下一个词是"要"的概率(可能是"要"、"想"、"在"...)
第3步: P("吃饭"∣"我要") :看到"我要"后,预测下一个词是"吃饭"的概率
而 θ 则是上述训练的权重,也就是模型学到的"知识"
大模型训练时,就是不断调整参数 θ ,让真实语料的这种概率乘积最大化(即让模型觉得"人话"的概率高,"胡话"的概率低)。
其最终训练结果是模型内部形成了一个高度压缩的世界知识统计表征空间,而非单一任务的决策边界。
这是从"函数拟合"向"知识建模"的关键转变。
四、关键转折二:架构演进与归纳偏置的弱化让"全局关系建模"成为可能

传统网络架构引入强归纳偏置(Inductive Bias)以提升样本效率,但限制了建模灵活性:
| 架构 | 归纳偏置 | 优势域 | 结构性局限 |
|---|---|---|---|
| CNN | 局部平移不变性(Local Translation Invariance) | 网格数据(图像) | 长距离依赖需通过深层堆叠间接建模 |
| RNN | 时间因果性(Temporal Causality) | 序列数据 | 梯度消失/爆炸,难以并行化 |
Transformer架构通过自注意力机制(Self-Attention) 实现了输入自适应的连接权重(Input-adaptive Connectivity):
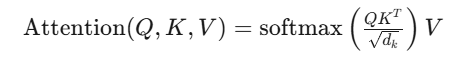
这使得任意位置的从"多层传播"缩短为"一步直连", 突破了CNN的局部性约束与RNN的时序依赖约束,,使模型具备大规模关系建模能力。
核心思想:Transformer并非引入"神秘机制",而是提供了一种可扩展的、弱归纳偏置的通神经网络连接方式,使模型能够通过增加参数规模而非人工特征工程来捕捉复杂模式。
五、关键转折三:规模跨越带来的能力相变
深度神经网络一直在变大,但在大模型阶段出现了不同以往的现象------涌现能力(Emergence)。
当模型规模、数据规模与计算量共同跨越某个阈值后,会出现:
- 上下文学习(In-Context Learning):无需梯度更新,仅通过提示(Prompt)即可适应新任务
- 思维链推理(Chain-of-Thought Reasoning):显式多步逻辑推导能力
- 指令泛化(Instruction Generalization):对未见过指令格式的零样本执行能力
这些能力并非显式编程所得,而是高维参数空间在预训练过程中形成的分布式统计结构的副产品。。
这种现象更像物理系统中的相变 ,即当系统控制参数(温度/规模)跨越临界阈值,宏观序参量(磁性/智能行为)发生非连续跳变 ,而不是线性性能的提升。

六、关键转折四:工程能力使规模扩展成为现实
大模型的实现不仅是算法创新,更是计算-存储-通信协同优化的系统工程成果:
| 技术维度 | 关键突破 | 解决的问题 |
|---|---|---|
| 分布式训练 | 张量并行(TP)、流水线并行(PP)、ZeRO优化器状态分片 | 单卡显存墙(Memory Wall) |
| 数值精度 | BF16/FP16混合精度、梯度缩放(Gradient Scaling) | 训练稳定性与吞吐效率 |
| 推理优化 | KV-Cache、PageAttention、量化(INT8/INT4) | 自回归生成的计算瓶颈 |
| 基础设施 | InfiniBand高速互联、NVLink/NVSwitch拓扑 | 节点间通信带宽约束 |
因此,大模型是算法创新、数据工程、硬件算力与分布式系统协同演化的产物,缺一不可。
七、重新理解"大模型的出现"
如果将时间线拉长,我们会发现大模型的技术发展路径是连续的:
感知机(1958) → 多层感知机(反向传播,1986)
→ 深度卷积网络(AlexNet, 2012)/ 序列建模(LSTM, 1997)
→ 注意力机制(Attention Is All You Need, 2017)
→ 自监督预训练(GPT/BERT, 2018-2019)
→ 规模临界跃迁(GPT-3/4, 2020+)
→ 通用基础模型(Foundation Model)因此:
AI并非突然爆发,而是深度神经网络在规模与目标函数演化下发生的一次能力"相变"。
八、结论:从"专用模型"到"基础模型"
| 阶段 | 模型定位 | 学习目标 | 知识形态 |
|---|---|---|---|
| 传统DNN时代 | 任务专用模型(Task-specific Model) | 判别式目标 P(y∣x)P(y|x)P(y∣x) | 局部决策边界 |
| 大模型时代 | 通用基础模型(Foundation Model) | 生成式目标 P(x)P(x)P(x) | 世界知识的统计先验 |
两者并非替代关系,而是层级包含关系:
Foundation Model⊂Deep Neural Network
基础模型学习的不再是单一任务的映射函数,而是支撑众多问题的知识结构本身,通过提示工程或微调即可特化为具体任务求解器。

九、对工业AI的启示:为什么"大模型时代"并不等于"传统DNN过时"
在讨论大模型带来的能力跃迁时,一个常见误区是:
既然大模型这么强,是不是所有AI系统都应该被替换为大模型?
在工业场景中,真实状况往往并不如此。
9.1 工业问题的本质:强约束、小样本、实时性
工业过程控制、预测性维护与质量检测具有以下特征:
| 特征维度 | 工业场景约束 |
|---|---|
| 数据形态 | 高维结构化传感器数据、时序信号、脉冲数据 |
| 样本规模 | 小样本(故障数据稀缺),但单样本信息密度高 |
| 任务目标 | 明确的物理量预测(水分、温度、应力)或状态分类 |
| 实时约束 | 毫秒级至秒级延迟要求(硬实时系统) |
| 部署环境 | 边缘计算单元、PLC、嵌入式ARM架构 |
这类问题本质为强物理约束下的函数逼近,正是传统DNN(CNN、RNN、MLP)的擅长领域。
9.2 分层智能的架构范式
大模型的优势在于开放域知识与复杂语义推理,但在工业控制中常常面临几个现实限制:
-
不需要"通识智能"
生产线上的模型不需要理解历史、文学或法律知识,只需要稳定地预测某个物理量。
-
数据分布高度专用
工业数据往往来自固定工艺流程,大模型预训练中学到的"世界知识"难以直接迁移。
-
计算与部署成本高
大模型推理资源需求远高于传统DNN,不适合边缘设备实时运行。
-
可解释性与稳定性要求更高
工业系统强调确定性和可验证性,而大模型的生成式特性可能引入不必要的不确定性。
因此,在大量工业AI问题中,轻量化、结构受控、任务专用的深度神经网络依然是最优工程解。这但并不意味着大模型与工业无关,而是角色不同。
未来更合理的形态是分层智能架构:
认知层(Cognitive Layer):大模型
↓ 语义抽象、知识推理、报告生成、决策支持
感知-控制层(Perception-Control Layer):传统DNN
↓ 实时信号处理、物理量预测、闭环控制
物理层(Physical Layer):传感器/执行器例如:
-
大模型用于:
- 生产知识问答
- 工艺文档解析
- 故障报告自动生成
- 操作员辅助决策
-
传统DNN用于:
- 在线属性检测
- 设备状态识别
- 质量实时判定
- 闭环控制预测模型
也就是说:
大模型更像"认知中枢",而传统DNN仍是"感知与控制神经"。
十、结语:所谓"AI爆发",只是长期技术积累的临界点
当人们惊叹于大模型带来的能力跃迁时,容易忽略一个事实:
技术的进步往往是连续积累的,而人类的感知却是离散跳变的。
深度神经网络的发展从未中断:
- 更深的网络
- 更大的数据
- 更强的算力
- 更通用的结构
这些因素在十余年间持续推进,只是在大模型阶段第一次同时跨越了关键规模阈值,使模型从"任务拟合工具"转变为"通用知识表征系统"。这种能力的出现更像是物理系统中的相变,而非技术路径的突然转折。
因此,大模型并不是对过去深度学习的否定,而是其自然延伸:
- 数学基础没有改变
- 训练机制没有改变
- 神经网络这一核心框架没有改变
真正改变的是:
模型开始学习的对象,从"标签函数"扩展为"世界知识的统计结构"。
从这个角度看,今天的AI并非"突然觉醒",而是深度神经网络在长期演化后,第一次具备了支撑通用智能行为的表征能力。
而在真实世界的工程系统中,这种能力并不会取代已有的专用模型,而是与其形成分层协作的关系------
高层负责认知与理解,底层负责感知与控制。
总结:
大模型不是AI技术史的断裂点,而是深度神经网络在规模、数据与目标函数共同演进下达到临界状态后的自然相变结果。所谓"爆发",只是人类终于触及了这条指数增长曲线的拐点。