PyTorch 的即时执行模式在原型开发阶段很方便,但在推理性能上存在明显短板。每个张量操作独立启动 kernel、独立访问显存,导致内存带宽成为瓶颈GPU 算力无法充分利用。
torch.compile 通过提前构建计算图来解决这个问题。它的核心策略是操作融合和缓冲区复用:第一次调用需要编译而之后的推理会快很多。在 PyTorch 官方的基准测试中,各种模型平均获得了 20%-36% 的加速。
即时执行意味着每个操作独立运行。一个 32 层、每层 100 个操作的模型,前向传播一次就要触发 3200 次 kernel 启动,这些开销全部叠加到推理延迟里。
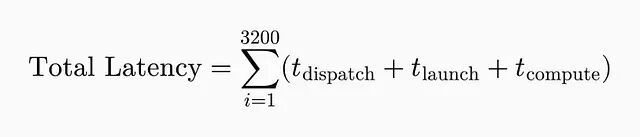
延迟飙升的根本原因是什么?内存才是即时执行成为瓶颈。Nvidia H100 能跑到 300+ TFLOPs但内存带宽只有约 3 TB/s。所以内存搬运的代价太高了,即时执行模式在规模化场景下根本撑不住。每个操作至少要做三次内存访问:从 VRAM 读输入张量、把中间结果写回 VRAM、再从 VRAM 读权重。
比如说这个简单的表达式
x = torch.relu(torch.matmul(a, b) + c),即时执行模式下至少要六次内存传输:分别读 a、b、c,写矩阵乘法结果,读这个结果,写最终输出。内存带宽很快就被打满了,GPU 核心反而闲着。
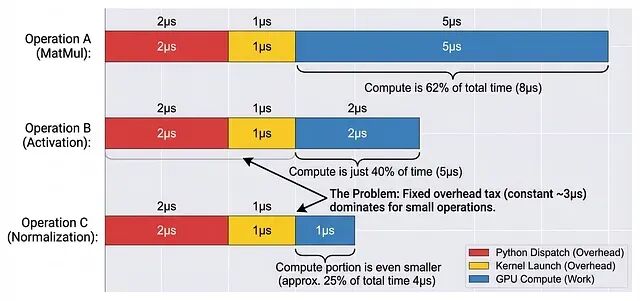
所以问题的本质在于:独立的操作没法融合内存传输,造成大量冗余的 VRAM 访问。
生产环境下情况更糟。CPU 要处理成千上万的并发请求,花在 PyTorch 调度器上的时间可能比真正计算还多,吞吐量被严重拖累。
计算图
torch.compile 要解决的就是这种逐操作的开销。它会提前捕获整个计算图,核心靠两个组件:TorchDynamo 是一个 Python JIT 编译器,负责拦截字节码执行;TorchInductor 是后端,为 GPU 生成优化过的 Triton kernel,为 CPU 生成 C++ 代码。
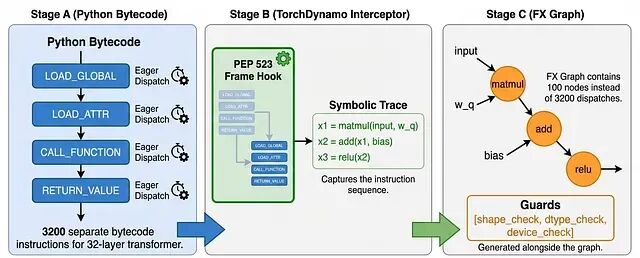
PyTorch 里这个计算图叫 FX Graph,把操作表示成有向无环图(DAG)的节点。调用 torch.compile 时,TorchDynamo 分析 Python 字节码,生成 FX 图:节点是张量操作,边是数据依赖。
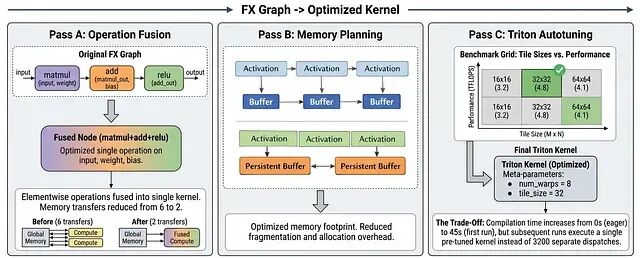
TorchInductor 拿到 FX 图后会做三件事:操作融合、内存规划、Triton 自动调优。
操作融合
还是前面那个例子
x = torch.relu(torch.matmul(a, b) + c)。即时执行要六次 VRAM 传输,TorchInductor 把它们融合成一个 Triton kernel:先把 a、b、c 的分块加载到片上 SRAM(共享内存),在寄存器里算矩阵乘法,加法和 ReLU 也在寄存器里做完,最后只把结果写回 VRAM。
内存传输从 6 次降到 2 次,减少了 3 倍。
内存规划
TorchInductor 不会给每个中间结果都分配新内存,而是让生命周期不重叠的缓冲区共用同一块空间------和编译器复用寄存器是一个思路。这相当于在整个计算图上做全局缓冲区复用,对激活模式不规则的 Transformer 模型特别有效。另一个好处是压低峰值内存占用,能跑更大的 batch。
Triton 自动调优
Triton 自动调优会针对具体硬件和输入 shape,自动搜索最优的 kernel 配置:tile 大小、线程块维度、流水线深度这些参数都不用手动调。
结果
第一次调用时,大模型的编译可能要几分钟。但后续调用只需要几毫秒加载预编译好的 kernel。初始开销会在后续推理中摊销掉,特别适合生产场景下模型持续运行的情况。冷启动慢一点,后面每个请求都快很多。
PyTorch 官方在 165 种模型(Transformer、CNN、扩散模型都有)上做了基准测试,torch.compile 在 float32 精度下平均加速 20%,开启自动混合精度(AMP)后加速 36%。
用起来也很简单:
import torch
# For a model
model = YourModel()
compiled_model = torch.compile(model)
# Or for a function, also enables Triton autotuning
@torch.compile(backend="inductor")
def forward_pass(x, weights):
return torch.relu(torch.matmul(x, weights))
output = compiled_model(input_tensor)这就是 torch.compile 的大致原理:不再为每个操作单独启动 kernel、单独搬运数据,而是用一个 kernel 处理多个操作,共享内存缓冲区。内存瓶颈的影响被大幅削减,GPU 算力利用率上去了。
总结
这种加速具有普适性,不只对大语言模型有效,CNN、扩散模型等架构同样适用。torch.compile 的价值在于:它把原本需要手写 CUDA 或 Triton 才能实现的优化,封装成了一行代码的事情。对于生产环境下的推理服务,这是目前性价比最高的优化手段之一。
https://avoid.overfit.cn/post/271bbf42f4a946c3a92b8a9745e223db
作者:Aryan Keluskar