目录
[1. 网络结构](#1. 网络结构)
[1.1 卷积池化](#1.1 卷积池化)
[1.2 全连接层](#1.2 全连接层)
[1.3 Dropout与LRN](#1.3 Dropout与LRN)
[2. AlexNet实战](#2. AlexNet实战)
[2.1 model](#2.1 model)
[2.2 train](#2.2 train)
[2.2.1 准备数据部分](#2.2.1 准备数据部分)
[2.2.2 训练配置部分](#2.2.2 训练配置部分)
[2.2.3 训练循环](#2.2.3 训练循环)
[2.2.4 结果可视化](#2.2.4 结果可视化)
[2.3 test](#2.3 test)
[2.4 自定义数据集](#2.4 自定义数据集)
[2.5 模型推理](#2.5 模型推理)
2012 年,在ILSVRC视觉竞赛中,一种名为 AlexNet的模型夺得冠军。该比赛基于ImageNet 数据集,由李飞飞团队推动建立,被视为衡量计算机视觉算法水平的试金石。AlexNet首次在大规模视觉任务中系统引入深度卷积神经网络,使模型性能断层式提升。
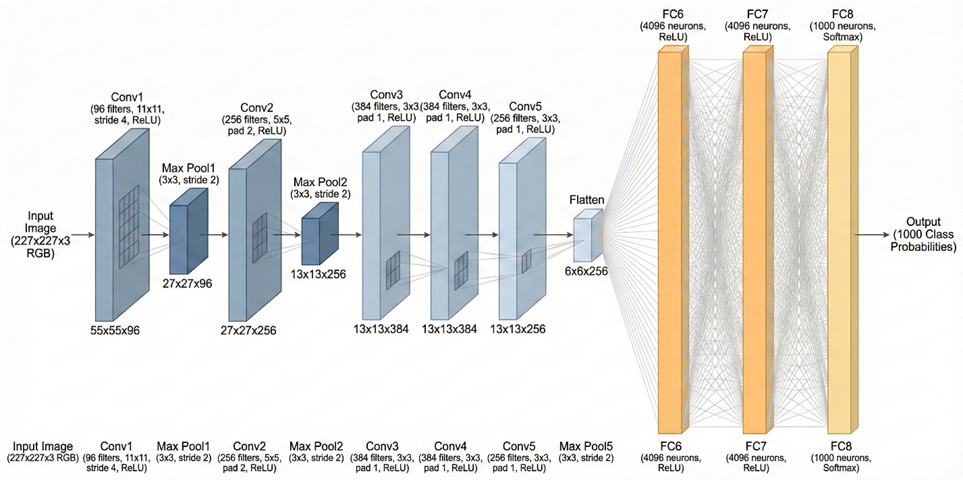
1. 网络结构
AlexNet包含5个卷积层,3 个全连接层,使用ReLU激活函数,第1、2、5个卷积层后面连接一个最大池化层,输入为RGB三通道的224 × 224 × 3大小的图像(可填充为227×227×3),最终输出层为softmax,用于预测图像的类别
计算流程可以表示为:
Conv1 → Pool → Conv2 → Pool → Conv3 → Conv4 → Conv5 → Pool → FC6 → FC7 → FC8
1.1 卷积池化
输入:227×227×3
卷积层C1:输入227×227×3,卷积核11×11×3×96,步长为4,输出特征图55×55×96
最大池化层P2:输入55×55×96,size为3×3,stride=2,输出27×27×96
卷积层C2:输入27×27×96,卷积核5×5×96×256,stride=1,padding=2,输出特征图27×27×256
最大池化层P2:输入27×27×256,size为3×3,stride=2,输出13×13×256
卷积层C3:输入13×13×256,卷积核3×3×256×384,stride=1,padding=1,输出特征图13×13×384
卷积层C4:输入13×13×384,卷积核3×3×384×384,stride=1,padding=1,输出特征图13×13×384
卷积层C5:输入13×13×384,卷积核3×3×384×256,stride=1,padding=1,输出特征图13×13×256
最大池化层P3:输入13×13×256,size为3×3,stride=2,输出6×6×256
其中,卷积运算后输出特征图的大小可由以下公式计算:
其中,𝑁表示输入特征图尺寸,𝐹为卷积核尺寸,𝑃为填充大小,𝑆为步幅。当计算结果出现小数时,通常向下取整。
1.2 全连接层
P3输出经展平操作,得到6×6×256=9216个数据与全连接层相连
全连接层F1:输入数据9216,神经元个数4096,输出4096经Dropout处理后作为下一层输入
全连接层F2:输入数据4096,神经元个数4096,输出4096同样经Dropout处理
全连接层F3:输入数据4096,神经元个数1000,softmax输出1000分类
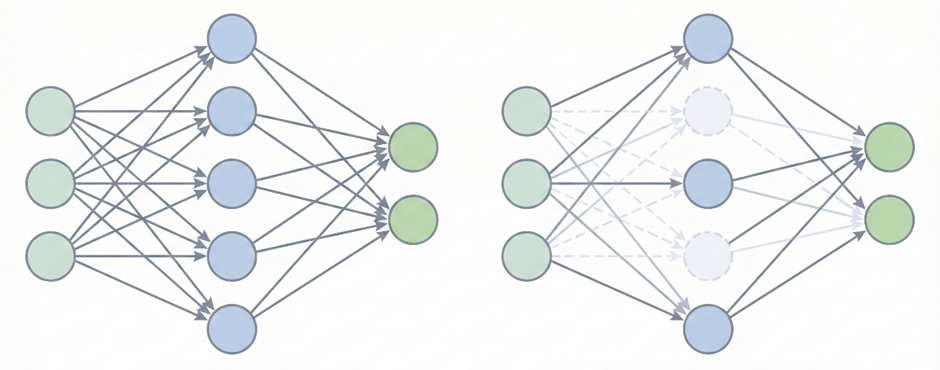
1.3 Dropout 与LRN
AlexNet 在前两层全连接层中引入了 Dropout 机制,缓解网络参数多带来的过拟合问题。Dropout 在每一轮训练过程中随机失活一定比例的神经元,它们不参与前向传播和反向更新。网络无法依赖某些固定的特征组合,泛化性更强
局部响应归一化(LRN)
LRN位于前两层卷积层的ReLu函数之后。在同一空间位置上,不同通道之间形成竞争关系,使响应较强的神经元抑制邻近通道的响应
除此之外,AlexNet通过旋转、翻转、裁剪等数据增强变换,增加训练数据的多样性,提高模型的泛化能力
2. AlexNet实战
项目主要包含三部分:模型、训练和测试。模型(model.py) 部分负责定义 AlexNet 的网络结构;训练(train.py) 部分实现数据读取、前向传播和参数更新,输出训练好的模型数据;**测试(test.py)**部分用于评估模型在测试集上的效果。由于使用成熟的数据集,故不涉及预处理部分
环境
Python3.8
Pytorch1.10.1
Cudatookit11.3.1
Cudnn8.2
Torchsummary1.5.1
Numpy1.23.2
Pandas1.3.4
Matplotlib3.5..0
Sklearn0.0HaoYuanxinn/AlexNet: 搭建AlexNet,使用FashionMNIST 数据集
2.1 model
这部分定义AlexNet的网络结构。思路为:首先在init里把所有层声明出来,定义各层结构;在forward() 里连接各个层;最后在main里实例化模型并用 summary 检查输入输出尺寸,确保结构正确
Nn是Pytorch提供的核心库,包含卷积层、池化层、Dropout等等组件。是 PyTorch 里所有网络的父类,我们定义的AlexNet也继承自它
class AlexNet(nn.Module):在init函数中声明各个层,nn已经提供了成熟的封装,我们不用自己写卷积是如何实现的,只需定义各层参数。如卷积层Conv1,使用Con2d函数Pycharm自动提示参数

由之前的理论推导,该层输入227×227×3,卷积核11×11×3×96,步长为4,输出特征图55×55×96。由于使用FashionMNIST数据集,黑白图片输入通道数为1,输出通道数96,填入对应参数
self.c1 = nn.Conv2d(in_channels=1, out_channels=96, kernel_size=11, stride=4)如此完成所有层的声明
def __init__(self):
super(AlexNet, self).__init__()
self.ReLU = nn.ReLU()
self.c1 = nn.Conv2d(in_channels=1, out_channels=96, kernel_size=11, stride=4,)
self.s2 = nn.MaxPool2d(kernel_size=3, stride=2)
self.c3 = nn.Conv2d(in_channels=96, out_channels=256, kernel_size=5, padding=2)
self.s4 = nn.MaxPool2d(kernel_size=3, stride=2)
self.c5 = nn.Conv2d(in_channels=256, out_channels=384, kernel_size=3, padding=1)
self.c6 = nn.Conv2d(in_channels=384, out_channels=384, kernel_size=3, padding=1)
self.c7 = nn.Conv2d(in_channels=384, out_channels=256, kernel_size=3, padding=1)
self.s8 = nn.MaxPool2d(kernel_size=3, stride=2)
self.flatten = nn.Flatten()
self.f1 = nn.Linear(6*6*256, 4096)
self.f2 = nn.Linear(4096, 4096)
self.f3 = nn.Linear(4096, 10)接下来在**forward()**前向传播函数里连接各个层。该函数输入实例self与输入数据x,第一步进入卷积层1,并通过ReLu函数
x = self.ReLU(self.c1(x))其余层按顺序串联即可
def forward(self, x):
x = self.ReLU(self.Conv1(x))
x = self.Pool1(x)
x = self.ReLU(self.Conv2(x))
x = self.Pool2(x)
x = self.ReLU(self.Conv3(x))
x = self.ReLU(self.Conv4(x))
x = self.ReLU(self.Conv5(x))
x = self.Pool3(x)
x = self.flatten(x)
x = self.ReLU(self.f1(x))
x = self.drop(x)
x = self.ReLU(self.f2(x))
x = self.drop(x)
x = self.f3(x)
return x最后在main中定义device,自动选择 CPU/GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")之后实例化模型,放在设备上
model = AlexNet().to(device)并打印每一层的输出shape
print(summary(model, (1, 227, 227)))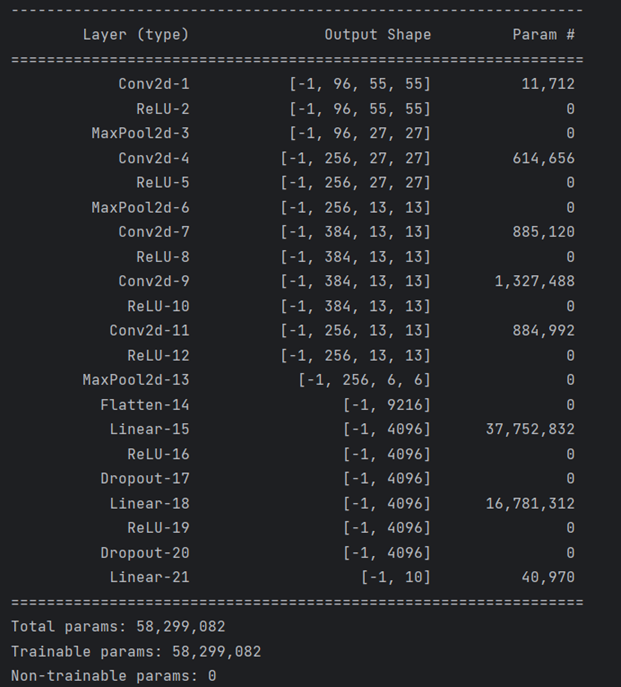
Model.py完整代码:
import torch
from torch import nn
from torchsummary import summary
import torch.nn.functional as F
class AlexNet(nn.Module):
def __init__(self):
super(AlexNet, self).__init__()
self.ReLU = nn.ReLU()
self.Conv1 = nn.Conv2d(in_channels=1, out_channels=96, kernel_size=11, stride=4,)
self.Pool1 = nn.MaxPool2d(kernel_size=3, stride=2)
self.Conv2 = nn.Conv2d(in_channels=96, out_channels=256, kernel_size=5, padding=2)
self.Pool2 = nn.MaxPool2d(kernel_size=3, stride=2)
self.Conv3 = nn.Conv2d(in_channels=256, out_channels=384, kernel_size=3, padding=1)
self.Conv4 = nn.Conv2d(in_channels=384, out_channels=384, kernel_size=3, padding=1)
self.Conv5 = nn.Conv2d(in_channels=384, out_channels=256, kernel_size=3, padding=1)
self.Pool3 = nn.MaxPool2d(kernel_size=3, stride=2)
self.flatten = nn.Flatten()
self.f1 = nn.Linear(6*6*256, 4096)
self.f2 = nn.Linear(4096, 4096)
self.f3 = nn.Linear(4096, 10)
self.drop = nn.Dropout(p=0.5)
def forward(self, x):
x = self.ReLU(self.Conv1(x))
x = self.Pool1(x)
x = self.ReLU(self.Conv2(x))
x = self.Pool2(x)
x = self.ReLU(self.Conv3(x))
x = self.ReLU(self.Conv4(x))
x = self.ReLU(self.Conv5(x))
x = self.Pool3(x)
x = self.flatten(x)
x = self.ReLU(self.f1(x))
x = self.drop(x)
x = self.ReLU(self.f2(x))
x = self.drop(x)
x = self.f3(x)
return x
if __name__ == "__main__":
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = AlexNet().to(device)
print(summary(model, (1, 227, 227)))这里并没有添加LRN,因为数据是单通道的,如果使用多通道数据训练,可以在__init__中声明两层LRN
self.lrn1 = nn.LocalResponseNorm(size=5, alpha=1e-4, beta=0.75, k=2.0)
self.lrn2 = nn.LocalResponseNorm(size=5, alpha=1e-4, beta=0.75, k=2.0)并在forward函数中第1、2层卷积层的ReLu与Pooling之间加入LRN
x = self.ReLU(self.Conv1(x))
x = self.lrn1(x)
x = self.Pool1(x)
x = self.ReLU(self.Conv2(x))
x = self.lrn2(x)
x = self.Pool2(x)2.2 train
这一部分的实现思路是:先对数据进行预处理并划分训练集和验证集;然后配置训练所需的设备、损失函数和优化器;核心训练部分,在每一轮训练中使用训练集更新模型参数、使用验证集评估模型性能,并在整个过程中记录指标、保存验证集表现最优的模型;最终通过可视化结果来分析模型的训练效果。
2.2.1 准备数据部分
下载FashionMNIST 数据集,并在加载时对图像进行统一的预处理,由于原始 FashionMNIST 图像尺寸为 28×28,而 AlexNet 的网络结构是227×227 输入,因此通过 Resize 操作将图像放大到227×227,再将图像转换为张量送入网络。
train_data = FashionMNIST(root='./data',
train=True,
transform=transforms.Compose([transforms.Resize(size=227), transforms.ToTensor()]),
download=True) # 下载 FashionMNIST 并resize 到 227按照 8:2 的比例随机划分为训练集和验证集
train_data, val_data = Data.random_split(train_data, [round(0.8*len(train_data)), round(0.2*len(train_data))])用DataLoader对训练集和验证集进行封装,以batch为单位加载数据。batch_size=32每次喂 32张图;shuffle=True打乱顺序;num_workers=2用2个子进程加载
train_dataloader = Data.DataLoader(train_data, batch_size=32, shuffle=True, num_workers=2)
val_dataloader = Data.DataLoader(val_data, batch_size=32, shuffle=True, num_workers=2)完整代码
def train_val_data_process():
train_data = FashionMNIST(root='./data',
train=True,
transform=transforms.Compose([transforms.Resize(size=227), transforms.ToTensor()]),
download=True) # 下载 FashionMNIST 并resize 到 227
# 80% 训练、20% 验证
train_data, val_data = Data.random_split(train_data, [round(0.8*len(train_data)), round(0.2*len(train_data))])
train_dataloader = Data.DataLoader(dataset=train_data, batch_size=32, shuffle=True, num_workers=2)
val_dataloader = Data.DataLoader(dataset=val_data, batch_size=32, shuffle=True, num_workers=2)
return train_dataloader, val_dataloader2.2.2 训练配置部分
配置设备、选择Adam优化器、使用交叉熵损失函数。Adam优化器用于参数更新,与其他优化器原理均基于梯度下降
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss()2.2.3 训练循环
训练要经过多次循环epoch,对每一循环,包含训练段 和验证段。
训练段参数会更新,以batch为单位,每个batch经历前向、计算损失、反向传播、更新参数几个步骤。
train_dataloader 每次迭代返回一批数据,这一批数据是一个二元组 (x, y)。b_x指batch_x,代表输入数据,b_y是这批数据对应的标签。将数据输入设备,并开启训练模式
for step, (b_x, b_y) in enumerate(train_dataloader):
b_x = b_x.to(device)
b_y = b_y.to(device)
model.train()接下来进入前向流程并计算损失
output = model(b_x)
pre_lab = torch.argmax(output, dim=1)
loss = criterion(output, b_y)model是nn.Module 的子类,而nn.Module 里面定义了一个__call__()
class Module:
def __call__(self, *args, **kwargs):
return self.forward(*args, **kwargs)当我们写model(b_x),实际执行的是model.forward(b_x)前向传播函数。
在分类任务里模型输出一般是:output.shape == (batch_size, num_classes),dim=1表示在类别维度上找最大值
输出分类,并将模型输出值与标签对比,计算损失函数
之后三步反向传播并更新参数
optimizer.zero_grad() # 清空上一轮梯度
loss.backward() # 反向传播计算
optimizer.step() # 更新网络的参数计算出的loss是当前batch 的平均loss,且格式为tensor,首先用item函数将其转换为数字,并乘上batch所包含的数据数量b_x.size(0)得到总loss
train_loss += loss.item() * b_x.size(0)累计判断正确pre_lab == b_y的个数并累加,同时记录累计样本数
train_corrects += torch.sum(pre_lab == b_y.data) # 累计预测正确数
train_num += b_x.size(0) # 累计样本数总代码
for step, (b_x, b_y) in enumerate(train_dataloader):
b_x = b_x.to(device)
b_y = b_y.to(device)
model.train() # 训练模式
output = model(b_x) # 前向传播
pre_lab = torch.argmax(output, dim=1)
loss = criterion(output, b_y) # 计算损失函数
optimizer.zero_grad() # 清空上一轮梯度
loss.backward() # 反向传播计算
optimizer.step() # 更新网络的参数
train_loss += loss.item() * b_x.size(0) # 累计loss
train_corrects += torch.sum(pre_lab == b_y.data) # 累计预测正确数
train_num += b_x.size(0) # 累计样本数验证段参数不更新,代码部分与训练段类似;最后对每一epoch,训练段和验证段结束后,统一计算指标并更新最优参数
# 计算并保存每一次迭代的loss值和准确率
train_loss_all.append(train_loss / train_num)
train_acc_all.append(train_corrects.double().item() / train_num)
val_loss_all.append(val_loss / val_num)
val_acc_all.append(val_corrects.double().item() / val_num)
print("{} train loss:{:.4f} train acc: {:.4f}".format(epoch, train_loss_all[-1], train_acc_all[-1]))
print("{} val loss:{:.4f} val acc: {:.4f}".format(epoch, val_loss_all[-1], val_acc_all[-1]))
if val_acc_all[-1] > best_acc:
best_acc = val_acc_all[-1] # 更新最优模型参数
best_model_wts = copy.deepcopy(model.state_dict())
# 计算训练和验证的耗时
time_use = time.time() - since
print("训练和验证耗费的时间{:.0f}m{:.0f}s".format(time_use//60, time_use%60))2.2.4 结果可视化
设定的训练轮次结束后,加载最优模型并保存权重。之后绘制 loss/acc 曲线
点击运行,模型开始训练,训练完成后记录最优参数并可视化
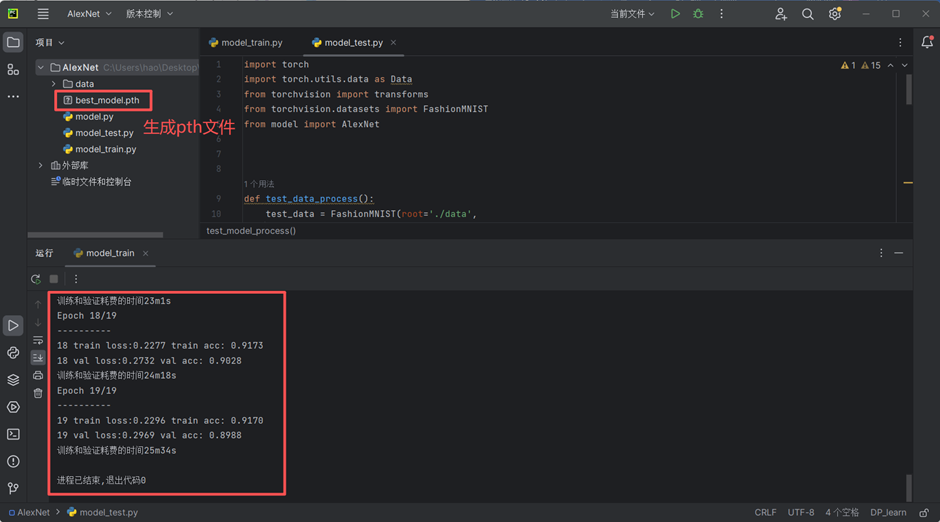
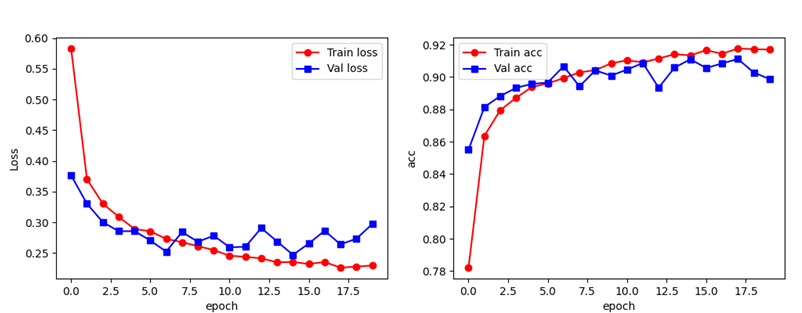
Train.py 完整代码:
import copy
import time
import torch
from torchvision.datasets import FashionMNIST
from torchvision import transforms
import torch.utils.data as Data
import numpy as np
import matplotlib.pyplot as plt
from model import AlexNet
import torch.nn as nn
import pandas as pd
def train_val_data_process():
train_data = FashionMNIST(root='./data',
train=True,
transform=transforms.Compose([transforms.Resize(size=227), transforms.ToTensor()]),
download=True) # 下载 FashionMNIST 并resize 到 227
# 80% 训练、20% 验证
train_data, val_data = Data.random_split(train_data, [round(0.8*len(train_data)), round(0.2*len(train_data))])
train_dataloader = Data.DataLoader(dataset=train_data, batch_size=32, shuffle=True, num_workers=2)
val_dataloader = Data.DataLoader(dataset=val_data, batch_size=32, shuffle=True, num_workers=2)
return train_dataloader, val_dataloader
def train_model_process(model, train_dataloader, val_dataloader, num_epochs):
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss()
model = model.to(device)
best_model_wts = copy.deepcopy(model.state_dict()) # 保存最优参数
# 初始化参数
best_acc = 0.0
train_loss_all = []
val_loss_all = []
train_acc_all = []
val_acc_all = []
since = time.time()
for epoch in range(num_epochs):
print("Epoch {}/{}".format(epoch, num_epochs-1))
print("-"*10)
# 初始化参数
train_loss = 0.0
train_corrects = 0
val_loss = 0.0
val_corrects = 0
train_num = 0
val_num = 0
for step, (b_x, b_y) in enumerate(train_dataloader):
b_x = b_x.to(device)
b_y = b_y.to(device)
model.train() # 训练模式
output = model(b_x) # 前向传播
pre_lab = torch.argmax(output, dim=1)
loss = criterion(output, b_y) # 计算损失函数
optimizer.zero_grad() # 清空上一轮梯度
loss.backward() # 反向传播计算
optimizer.step() # 更新网络的参数
train_loss += loss.item() * b_x.size(0) # 累计loss
train_corrects += torch.sum(pre_lab == b_y.data) # 累计预测正确数
train_num += b_x.size(0) # 累计样本数
for step, (b_x, b_y) in enumerate(val_dataloader):
b_x = b_x.to(device)
b_y = b_y.to(device)
model.eval()
output = model(b_x)
pre_lab = torch.argmax(output, dim=1)
loss = criterion(output, b_y)
val_loss += loss.item() * b_x.size(0)
val_corrects += torch.sum(pre_lab == b_y.data)
val_num += b_x.size(0)
# 计算并保存每一次迭代的loss值和准确率
train_loss_all.append(train_loss / train_num)
train_acc_all.append(train_corrects.double().item() / train_num)
val_loss_all.append(val_loss / val_num)
val_acc_all.append(val_corrects.double().item() / val_num)
print("{} train loss:{:.4f} train acc: {:.4f}".format(epoch, train_loss_all[-1], train_acc_all[-1]))
print("{} val loss:{:.4f} val acc: {:.4f}".format(epoch, val_loss_all[-1], val_acc_all[-1]))
if val_acc_all[-1] > best_acc:
best_acc = val_acc_all[-1] # 更新最优模型参数
best_model_wts = copy.deepcopy(model.state_dict())
# 计算训练和验证的耗时
time_use = time.time() - since
print("训练和验证耗费的时间{:.0f}m{:.0f}s".format(time_use//60, time_use%60))
# 选择最优参数,保存最优参数的模型
model.load_state_dict(best_model_wts)
torch.save(best_model_wts, "C:/Users/hao/Desktop/AlexNet/best_model.pth")
train_process = pd.DataFrame(data={"epoch":range(num_epochs),
"train_loss_all":train_loss_all,
"val_loss_all":val_loss_all,
"train_acc_all":train_acc_all,
"val_acc_all":val_acc_all})
return train_process
def matplot_acc_loss(train_process):
# 显示每一次迭代后的训练集和验证集的损失函数和准确率
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(train_process['epoch'], train_process.train_loss_all, "ro-", label="Train loss")
plt.plot(train_process['epoch'], train_process.val_loss_all, "bs-", label="Val loss")
plt.legend()
plt.xlabel("epoch")
plt.ylabel("Loss")
plt.subplot(1, 2, 2)
plt.plot(train_process['epoch'], train_process.train_acc_all, "ro-", label="Train acc")
plt.plot(train_process['epoch'], train_process.val_acc_all, "bs-", label="Val acc")
plt.xlabel("epoch")
plt.ylabel("acc")
plt.legend()
plt.show()
if __name__ == '__main__':
AlexNet = AlexNet()
train_data, val_data = train_val_data_process()
train_process = train_model_process(AlexNet, train_data, val_data, num_epochs=20)
matplot_acc_loss(train_process)2.3test
Test部分首先加载测试数据集,与训练阶段进行一致的预处理操作,并通过 DataLoader 读取测试数据。
测试阶段不涉及参数更新,因此在模型推理时使用 torch.no_grad() 关闭梯度计算,并将模型切换到评估模式model.eval(),以确保Dropout等训练相关操作被关闭。
前向传播、输出类别预测结果、统计预测正确的样本数量等操作与train中类似
Test.py完整代码:
import torch
import torch.utils.data as Data
from torchvision import transforms
from torchvision.datasets import FashionMNIST
from model import AlexNet
def test_data_process():
test_data = FashionMNIST(root='./data',
train=False,
transform=transforms.Compose([transforms.Resize(size=227), transforms.ToTensor()]),
download=True)
test_dataloader = Data.DataLoader(dataset=test_data,batch_size=1,shuffle=True,num_workers=0)
return test_dataloader
def test_model_process(model, test_dataloader):
device = "cuda" if torch.cuda.is_available() else 'cpu'
model = model.to(device)
# 初始化参数
test_corrects = 0.0
test_num = 0
# 只进行前向传播计算,不计算梯度,从而节省内存,加快运行速度
with torch.no_grad():
for test_data_x, test_data_y in test_dataloader:
test_data_x = test_data_x.to(device)
test_data_y = test_data_y.to(device)
model.eval()
output= model(test_data_x)
pre_lab = torch.argmax(output, dim=1)
test_corrects += torch.sum(pre_lab == test_data_y.data)
test_num += test_data_x.size(0)
# 计算测试准确率
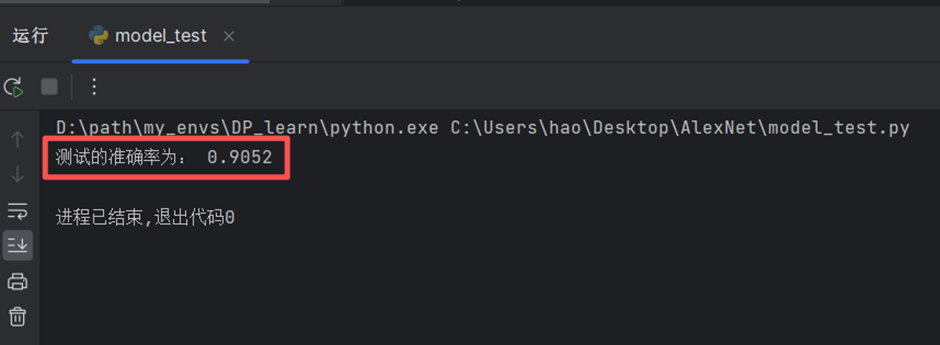
test_acc = test_corrects.double().item() / test_num
print("测试的准确率为:", test_acc)
if __name__ == "__main__":
model = AlexNet()
model.load_state_dict(torch.load('best_model.pth'))
test_dataloader = test_data_process()
test_model_process(model, test_dataloader)运行test文件,输出测试的模型准确率
2.4 自定义数据集
简单分类问题如使用自定义数据集,需要把FashionMNIST(...) 换成一个能返回 (图片, 标签)的 Dataset。
可以按文件夹给数据集分好类,类似
data/
train/
car/ xxx.jpg
person/ yyy.jpg
val/
car/ a.jpg
person/ b.jpg直接用 torchvision.datasets.ImageFolder即可,它默认一个文件夹是一个类别,文件夹名就是 类别名,而文件夹里的所有图片是该类别的样本。
train_data = datasets.ImageFolder(root="./mydata/train", transform=train_tf)同样需要对图像进行统一尺寸、转Tensor、归一化(Normalize)、数据增强等预处理
def train_val_data_process():
train_tf = transforms.Compose([
transforms.Resize(227), # resize大小
transforms.ToTensor(), # 转换为tensor
transforms.Normalize(mean=[...], std=[...]) # 归一化,对每个通道统计mean / std
])完整代码
from torchvision import datasets, transforms
import torch.utils.data as Data
def train_val_data_process():
train_tf = transforms.Compose([
transforms.Resize(227), # resize大小
transforms.ToTensor(), # 转换为tensor
transforms.Normalize(mean=[...], std=[...]) # 归一化
])
train_data = datasets.ImageFolder(root="./mydata/train", transform=train_tf)
train_data, val_data = Data.random_split(train_data, [round(0.8*len(train_data)), round(0.2*len(train_data))])
train_loader = Data.DataLoader(train_data, batch_size=32, shuffle=True, num_workers=2)
val_loader = Data.DataLoader(val_data, batch_size=32, shuffle=False, num_workers=2)
return train_loader, val_loader数据增强只用于训练集,不能用于验证集和测试集,可加在compose里,如
transforms.RandomHorizontalFlip(p=0.5)
transforms.RandomRotation(10)
transforms.RandomResizedCrop(224, scale=(0.8, 1.0)) # 随机裁剪后Resize
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1)另一种数据集格式是图片+标签表,需要实现一个Dataset类,读CSV并返回图片和标签
data/images/xxx.jpg
data/images/yyy.jpg
data/labels.csv # filename,label2.5 模型推理
在模型训练完成后,使用训练好的模型对新数据进行预测或生成。它与测试test基本一致,只是将测试集数据换为新数据
image = Image.open('xxx')
normalize = transforms.Normalize()
test_transform = transforms.Compose([transforms.Resize((224, 224)), transforms.ToTensor(), normalize])
image = test_transform(image)
image = image.unsqueeze(0) # 添加 batch 维度
with torch.no_grad():
model.eval()
image = image.to(device)
output = model(image)
pre_lab = torch.argmax(output, dim=1)
result = pre_lab.item()
print("预测值:", classes[result])