1. 业务需求
技术人员常常是保守的,我们认为根本没必要用这种技术的,然而业务市场人员却高喊着要拥抱大模型技术,特别最近OpenClaw这只小龙虾在中国大火以来,是业务人员首先使用OpenClaw起来,听到深圳龙岗区有百万企业扶持基金,恨不得跑去开一个皮包公司,个别客户也提出要在企业内网里搞一个大模型,更让业务人员有理由必须要搞。
具体是什么业务需求必须要上大模型都没搞清楚,公司就买一块GPU过来要搞起来,希望一周后能上大模型系统给客户演示,多少年过去了,大跃进依然时不时刺激我们一下积极性。
就我本人来说,个人对deepseek是怀有深深敬意的,各家头部公司的大模型网页版,确实比以前的搜索功能强大好用,现在编程时基本不用某度搜索来查资料了。但是,企业业务系统要上大模型技术,解决客户问答、企业知识库、文档生成等,投入这么多软件硬件成本和开发成本,最后就搞出这些应用来,从投入产出比率来看值得不值得?
2. 软硬件环境
2.1 服务器1
我们从2014年开始就做人脸识别系统,对GPU一直是有用的,故公司有测试服务器,都是线上淘汰下来的,其中一台准备使用,配置情况如下:
~$ nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2021 NVIDIA Corporation
Built on Mon_May__3_19:15:13_PDT_2021
Cuda compilation tools, release 11.3, V11.3.109
Build cuda_11.3.r11.3/compiler.29920130_0
~$ nvidia-smiWed Mar 4 18:29:41 2026
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 465.19.01 Driver Version: 465.19.01 CUDA Version: 11.3 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA Tesla P4 On | 00000000:05:00.0 Off | 0 |
| N/A 38C P8 7W / 75W | 0MiB / 7611MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
首先安装了pytorch,自然是可以成功的:
pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu113
其次安装了Ollama,也是可以运行的,但是ollama pull下deepseek和qwen几个版本,运行起来总是无法使用到GPU,用CPU运行起来慢到无法使用了。
最后安装vLLM, vLLM官网:https://vllm.ai/,
源代码地址:https://github.com/vllm-project/vllm
分析它发布的各个版本支持的CUDA,最低都是11.8,CUDA11.3根本从来都没支持过。
而且vLLM还不支持CPU版本部署,从当前发布的包来安装,基本没法玩了,只能申请新购买一块。
2.2 服务器2
我们在豆包上调研了一下:
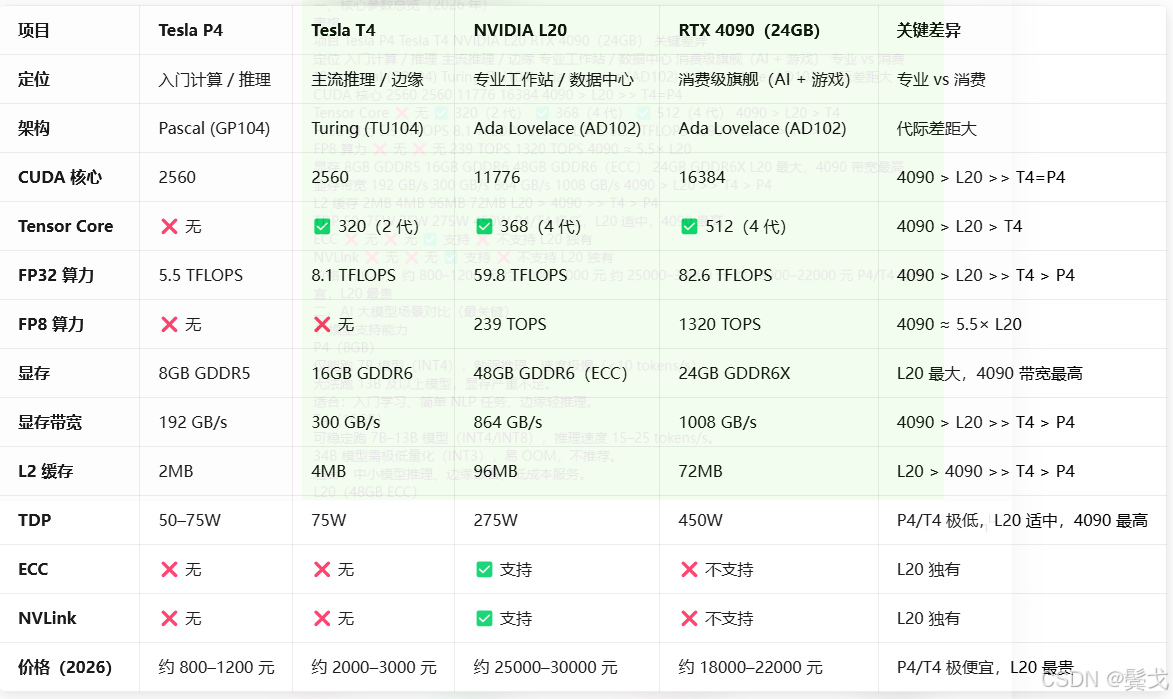
最终选定nvidia L20, 基于的理由是这款要稳定一些,显存也最大,48G,带宽速度对企业内部应用不是特别需要,在https://www.nvidia.cn/drivers/上搜索了一下:
软硬件安装完毕之后,具体配置情况如下:
~/llm$ cat /proc/version
Linux version 6.8.0-106-generic (buildd@lcy02-amd64-074) (x86_64-linux-gnu-gcc-13 (Ubuntu 13.3.0-6ubuntu2~24.04.1) 13.3.0, GNU ld (GNU Binutils for Ubuntu) 2.42) #106-Ubuntu SMP PREEMPT_DYNAMIC Fri Mar 6 07:58:08 UTC 2026
~/llm$ nvcc --versionnvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2023 NVIDIA Corporation
Built on Fri_Jan__6_16:45:21_PST_2023
Cuda compilation tools, release 12.0, V12.0.140
Build cuda_12.0.r12.0/compiler.32267302_0
~/llm$ nvidia-smiMon Mar 16 02:13:28 2026
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 590.48.01 Driver Version: 590.48.01 CUDA Version: 13.1 |
+-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA L20 Off | 00000000:84:00.0 Off | 0 |
| N/A 32C P8 26W / 350W | 0MiB / 46068MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+
3. 安装基础库
默认安装Python,版本如下:
~/llm$ python -V
Python 3.12.3
在虚拟环境里安装训练环境吧:
sudo apt install python3.12-venv
~/llm$ python -m venv qwen3
~/llm$ ls
qwen3
~/llm$ source qwen3/bin/activate
设置pip默认源为清华大学镜像源, 不然从默认源下载太慢:
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
开始在虚拟环境下进行安装PyTorch库:
pip install torch torchvision
pip install transformers datasets accelerate peft trl
pip install deepspeed
pip install bitsandbytes
pip install flash-attn
pip install vllm
以上安装都没有指定版本号,这就是用新硬件的好处,省事很多。
Torch 和 Torchvision 是 PyTorch 深度学习生态系统的两个核心组件,主要用于构建和训练神经网络,特别是在计算机视觉领域。
datasets 是数据集加载和处理库,提供对 Hugging Face Hub 上数万种数据集的便捷访问。
accelerate 是分布式训练和混合精度训练的简化工具,零代码改动实现单机多卡、多机多卡训练,自动处理混合精度训练(FP16/BF16)。
peft 是参数高效微调库,实现各种"只训练少量参数"的微调方法,大幅降低显存和计算需求。
trl 是基于 Transformer 的强化学习训练库,实现大语言模型的对齐训练(RLHF全流程)。
transformers 库是由 Hugging Face 开发的一个开源 Python 库,它是目前最流行的大语言模型(LLM)和深度学习模型工具之一。
flash-attn 是一个用于加速 Transformer 模型中注意力机制计算的 CUDA 优化库。它通过重新设计注意力计算方式,显著提升了大语言模型(LLM)的训练和推理效率。
DeepSpeed 是由微软开发的一个开源深度学习优化库,主要用于大规模分布式训练和推理。它针对 PyTorch 提供了大量优化技术,让研究人员和工程师能够更高效地训练超大模型。
bitsandbytes 是一个用于 8-bit 和 4-bit 量化 的 Python 库,主要用于 大型语言模型(LLM)的高效推理和微调。它由 Tim Dettmers 开发,是 Hugging Face 生态系统中非常重要的组件。
4. 安装LlamaFactory
LlamaFactory源代码地址:https://github.com/hiyouga/LlamaFactory,从源代码进行安装:
git clone --depth 1 https://github.com/hiyouga/LlamaFactory.git
cd LlamaFactory
pip install -e .
pip install -r requirements/metrics.txt
一切都安装成功之后,运行:
~/llm/LlamaFactory$ llamafactory-cli webui
有屏幕日志打印:
Visit http://ip:port for Web UI, e.g., http://127.0.0.1:7860
* Running on local URL: http://0.0.0.0:7860
* To create a public link, set `share=True` in `launch()`.
在浏览器中输入地址:http://192.168.0.24:7860/,打开:
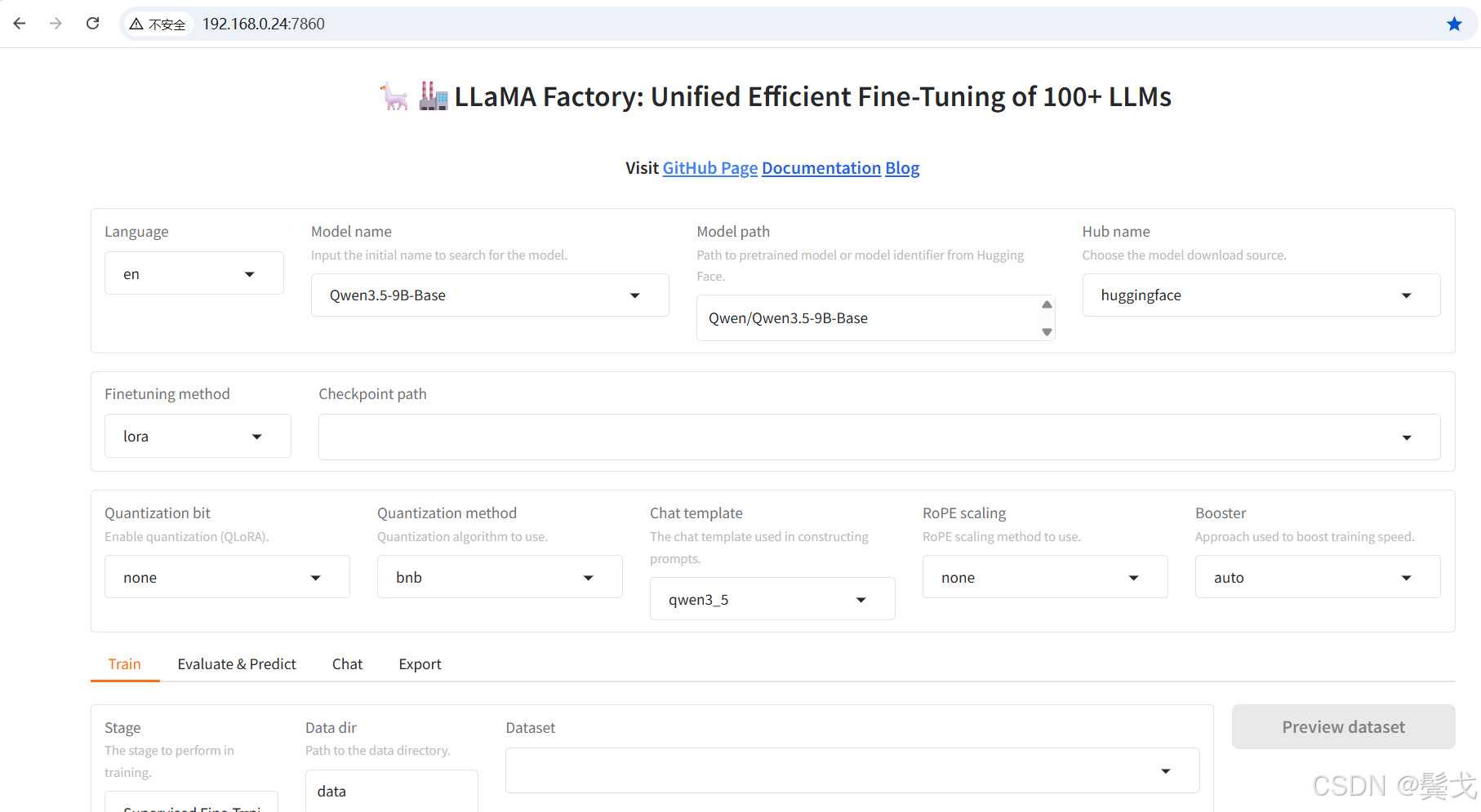
5. 准备训练数据集
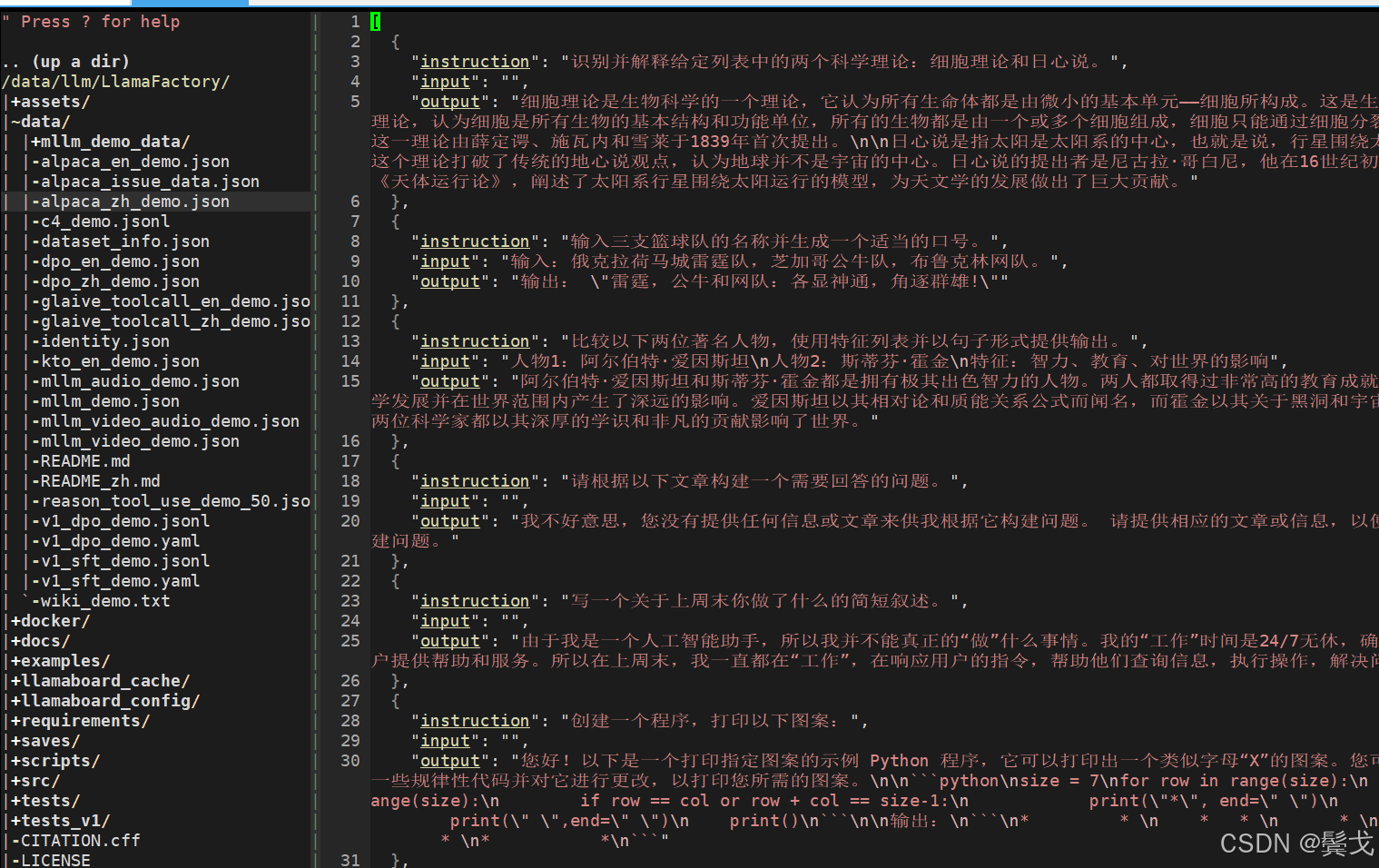
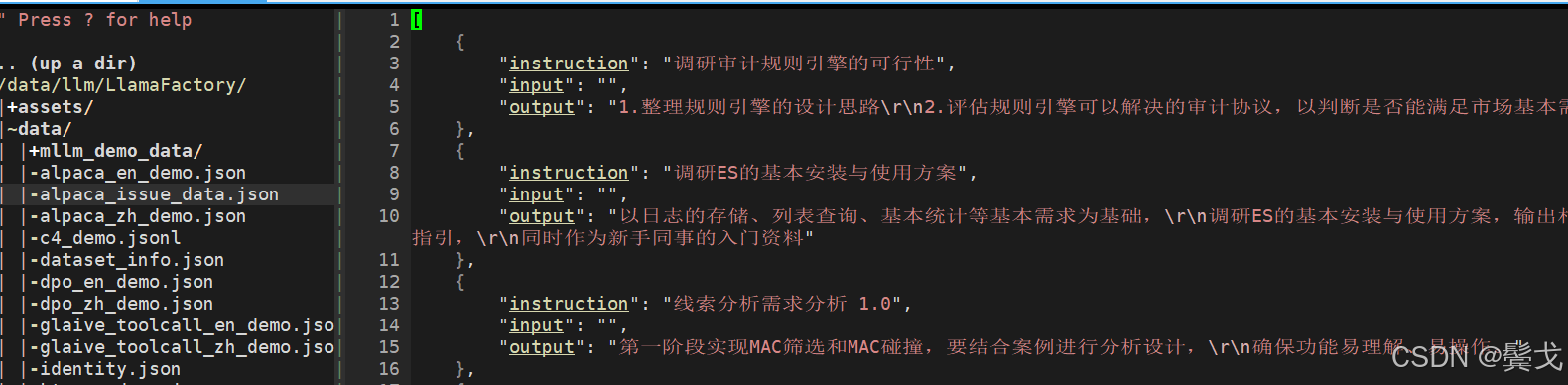
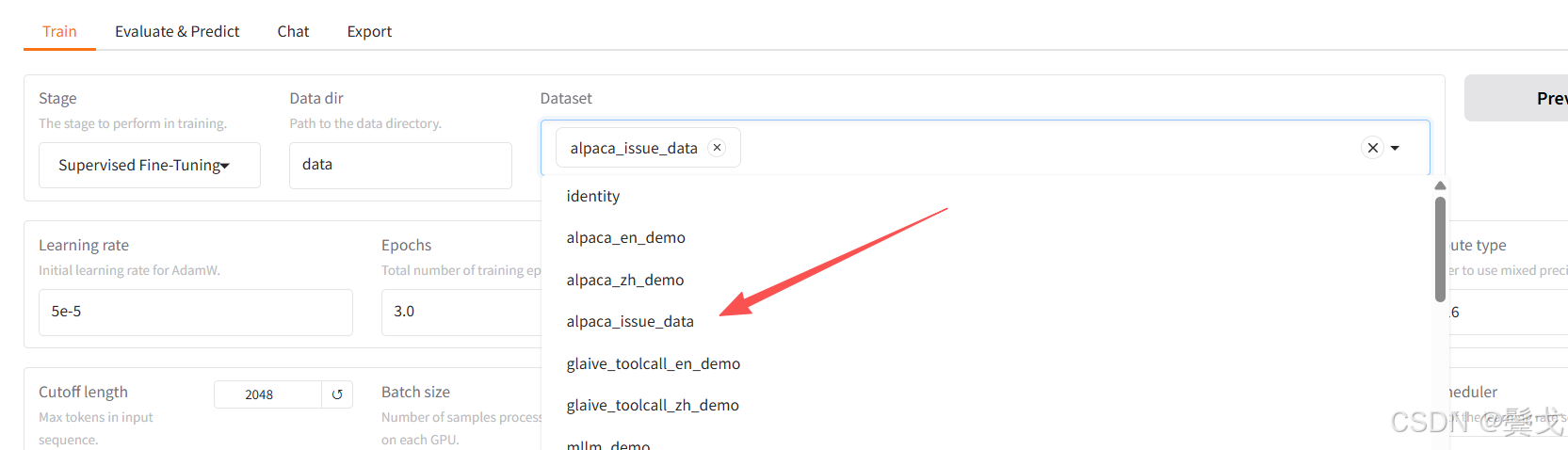
上图是LlamaFactory工程下data目录的情况,首次训练就用最简单的alpaca数据格式,把开发部门任务单系统中任务单导出来做成一个简单的小数据集alpaca_issue_data.json:
最后在dataset_info.json中添加一个配置项:
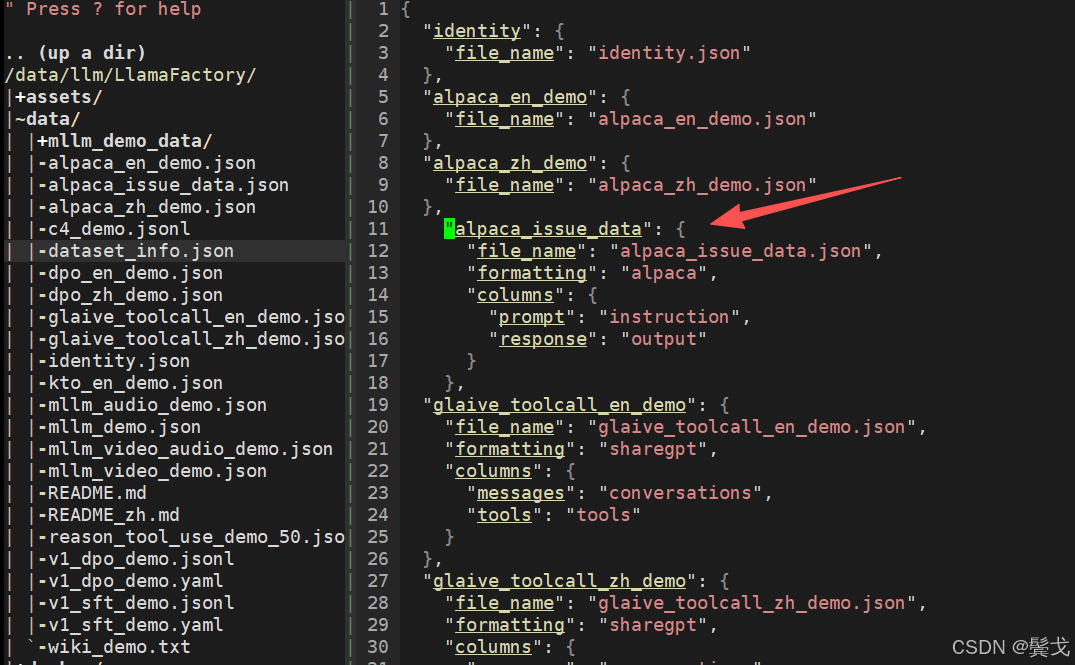
我们在webui界面上就可以看到新配置的数据集:
6. 微调训练初体验
第一次微调训练顾不得效果如何,能把训练跑完就OK, 太多参数选择,好在现在有这么多LLM网页版使用,同一个问题在好几家平台上发起咨询,问题基本都能解决,LLM取代传统的搜索引擎确实强大好用,下面简单记录一下碰到的小白问题:
File "/data/llm/LlamaFactory/src/llamafactory/hparams/parser.py", line 401, in get_train_args _verify_model_args(model_args, data_args, finetuning_args)
File "/data/llm/LlamaFactory/src/llamafactory/hparams/parser.py", line 177, in _verify_model_args raise ValueError("Please use scripts/pissa_init.py to initialize PiSSA for a quantized model.") ValueError: Please use scripts/pissa_init.py to initialize PiSSA for a quantized model.
-----》
同时开启了以下两个选项,但它们在当前版本的 LLaMA-Factory 中不能直接组合使用:
- 量化加载 (Quantization) :选择了
4-bit(QLoRA)。- PiSSA 初始化 :勾选了
Use PiSSA
解决:不勾选Use PiSSA.
File "/data/llm/qwen3/lib/python3.12/site-packages/multiprocess/pool.py", line 774, in get raise self._value ValueError: The number of videos does not match the number of <video> tokens in {'content': '视频控件改造方案的调研', 'role': 'user'}, {'content': 'h2. 方案A:使用Qt\\r\\n\\r\\n待解决的问题:\\r\\n# 静态编译Qt5 \[成功\r\n# 制作简单控件并能成功在IE中加载 完成\r\n# 支持XP 失败\r\n# 支持SSL 成功\r\n\r\nh2. 方案B:使用HTML5\r\n\r\n待解决的问题:\r\n# 确定HTML5的<video>标签是否支持实时流\r\n# 将实时音视频混合为fMP4格式\r\n\r\n\[HTML5媒体服务器设计思路]', 'role': 'assistant'}].
----》
- 训练数据中,有一条数据的文本内容里包含了
<video>这个字符串(在你的例子中,是 assistant 回复里提到了 HTML5 的<video>标签)。- LLaMA-Factory 的数据处理器(特别是针对多模态模型如 Qwen-VL)在预处理时,会扫描文本中的
<video>、<image>等标记,试图将它们替换为真正的视频/图像占位符。
解决:训练数据集中去掉<video>。
You can update Transformers with the command `pip install --upgrade transformers`. If this does not work, and the checkpoint is very new, then there may not be a release version that supports this model yet. In this case, you can get the most up-to-date code by installing Transformers from source with the command `pip install git+https://github.com/huggingface/transformers.git`
----》
这个错误是因为 Transformers 库版本(4.57.6)过低 ,无法识别 Qwen3.5 模型的新架构类型
qwen3_5。你需要将 Transformers 升级到支持 Qwen3.5 的版本(至少 4.58.0 以上)。
解决:pip install --upgrade transformers,直接升级到最高版本。
packages/transformers/utils/versions.py", line 43, in _compare_versions raise ImportError( ImportError: transformers>=4.51.0,<=5.2.0 is required for a normal functioning of this module, but found transformers==5.3.0. To fix: run `pip install transformers>=4.51.0,<=5.2.0` or set `DISABLE_VERSION_CHECK=1` to skip this check.
-----》
上面默认升级到5.3.0,太高了。
解决:pip install transformers==5.2.0 。
File "/data/llm/qwen3/lib/python3.12/site-packages/peft/peft_model.py", line 459, in from_pretrained config = PEFT_TYPE_TO_CONFIG_MAPPINGPeftConfig._get_peft_type(model_id, \*\*hf_kwargs).from_pretrained( ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/data/llm/qwen3/lib/python3.12/site-packages/peft/config.py", line 323, in _get_peft_type raise ValueError(f"Can't find '{CONFIG_NAME}' at '{model_id}'") ValueError: Can't find 'adapter_config.json' at 'saves/my_model/qlora_alpaca'
-----》
如果这是第一次训练 ,这个参数应该为空 或不设置
如果是继续训练 ,确保路径正确且包含
adapter_config.json文件
解决:Checkpoint path不要设置,为空即可。
File "/data/llm/LlamaFactory/src/llamafactory/model/adapter.py", line 360, in init_adapter model = _setup_lora_tuning( ^^^^^^^^^^^^^^^^^^^ File "/data/llm/LlamaFactory/src/llamafactory/model/adapter.py", line 240, in _setup_lora_tuning raise ValueError("DoRA is not compatible with PTQ-quantized models.") ValueError: DoRA is not compatible with PTQ-quantized models.
-----》
DoRA(Weight-Decomposed Low-Rank Adaptation)与量化模型不兼容。
在训练配置中同时启用了 DoRA 和模型量化(PTQ),但这两者不能一起使用。
解决:关闭 DoRA。
最终跑起来,webui界面上目前选择如下:
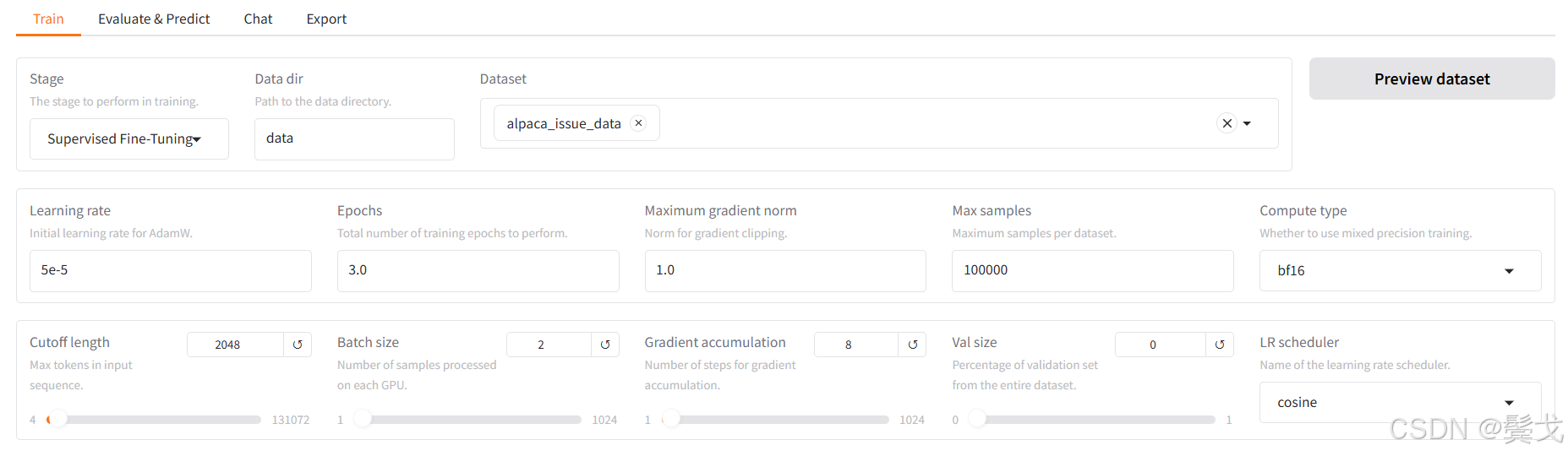
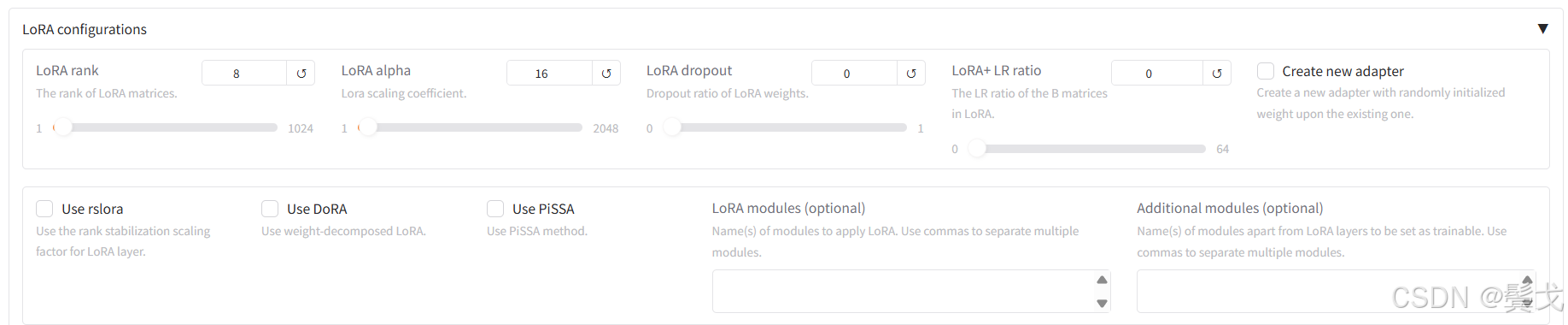
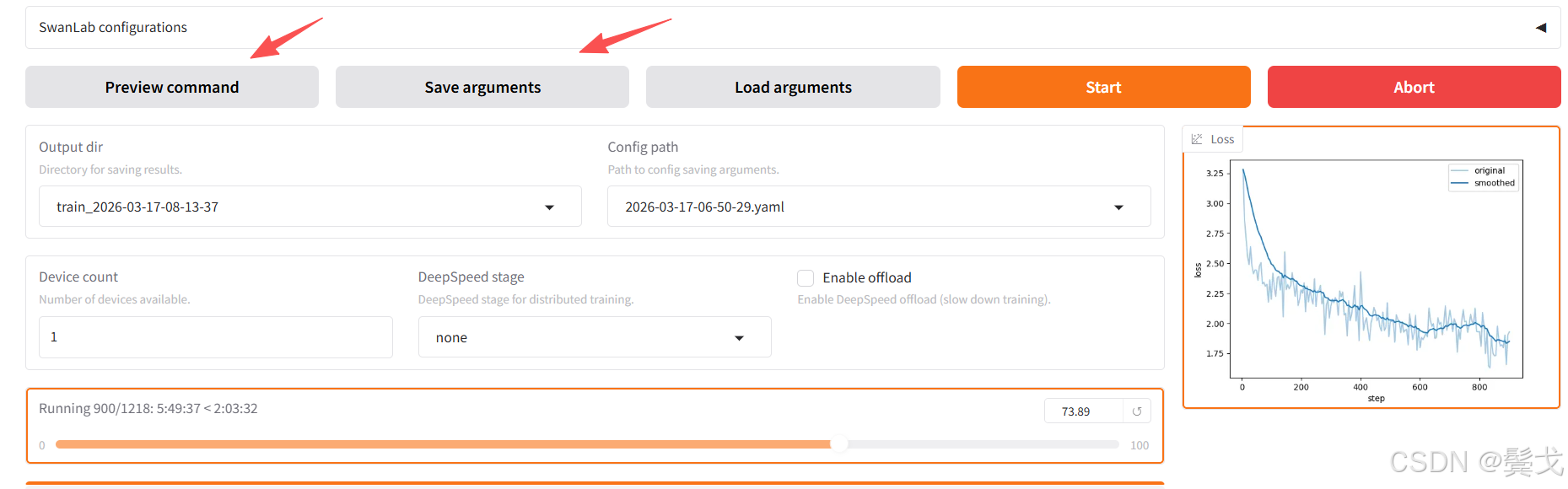
正常跑起来应该如上图,执行时间很长,需要几个小时,看看nvidia-smi:
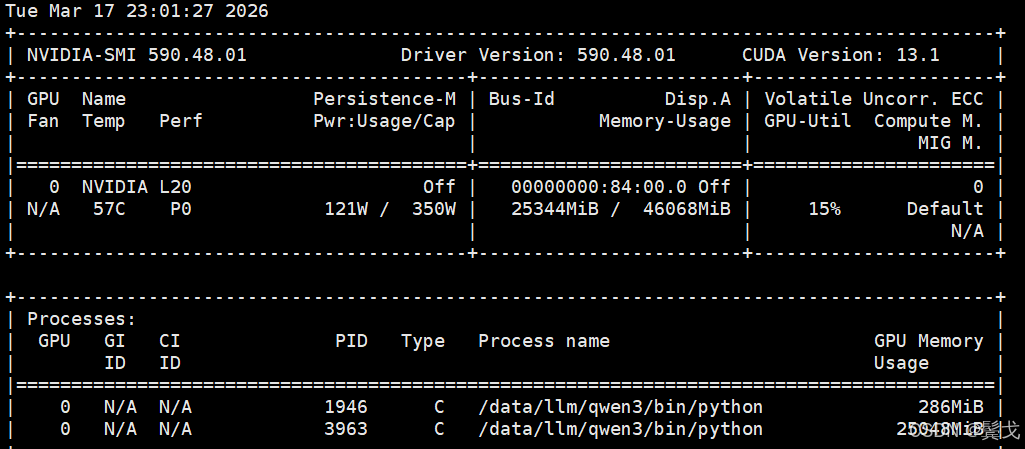

上面两张图可见,CPU和内存使用不高,主要是显存占到了25G, 最高时到了41G。
当我们在webui界面上点击:

界面会打印对应执行的训练命令:
bash
llamafactory-cli train \
--stage sft \
--do_train True \
--model_name_or_path Qwen/Qwen3.5-9B-Base \
--preprocessing_num_workers 16 \
--finetuning_type lora \
--template qwen3_5 \
--flash_attn auto \
--dataset_dir data \
--dataset alpaca_issue_data \
--cutoff_len 2048 \
--learning_rate 5e-05 \
--num_train_epochs 3.0 \
--max_samples 100000 \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 8 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 5 \
--save_steps 100 \
--warmup_steps 0 \
--packing False \
--enable_thinking True \
--report_to tensorboard \
--output_dir saves/Qwen3.5-9B-Base/lora/train_2026-03-17-08-13-37 \
--bf16 True \
--plot_loss True \
--trust_remote_code True \
--ddp_timeout 180000000 \
--include_num_input_tokens_seen True \
--optim adamw_torch \
--quantization_bit 4 \
--quantization_method bnb \
--double_quantization True \
--lora_rank 8 \
--lora_alpha 16 \
--lora_dropout 0 \
--lora_target all \
--freeze_vision_tower True \
--freeze_multi_modal_projector True \
--image_max_pixels 589824 \
--image_min_pixels 1024 \
--video_max_pixels 65536 \
--video_min_pixels 256上面各个参数的含义,将是接下来慢慢熟悉慢慢优化的地方,目前先不管细节。
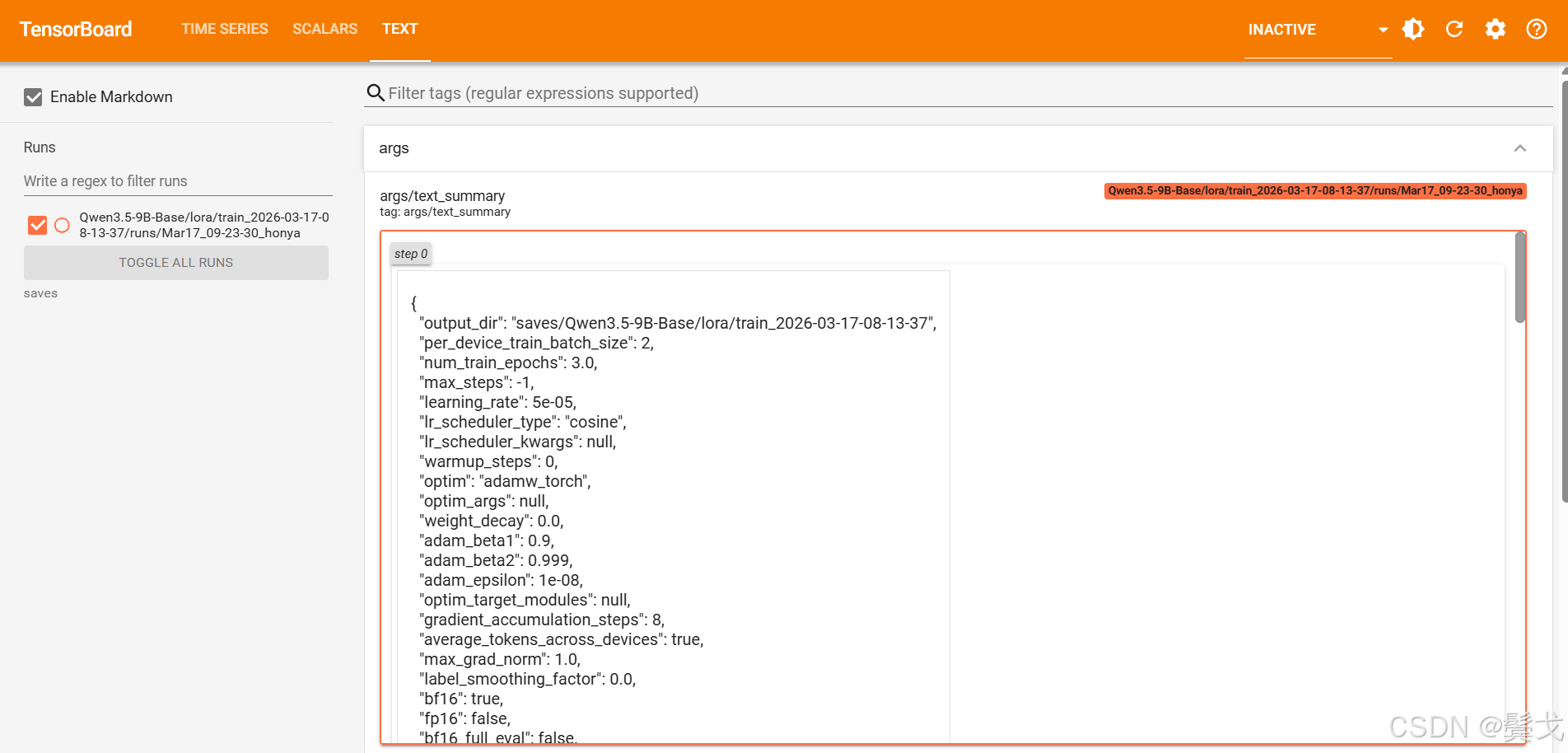
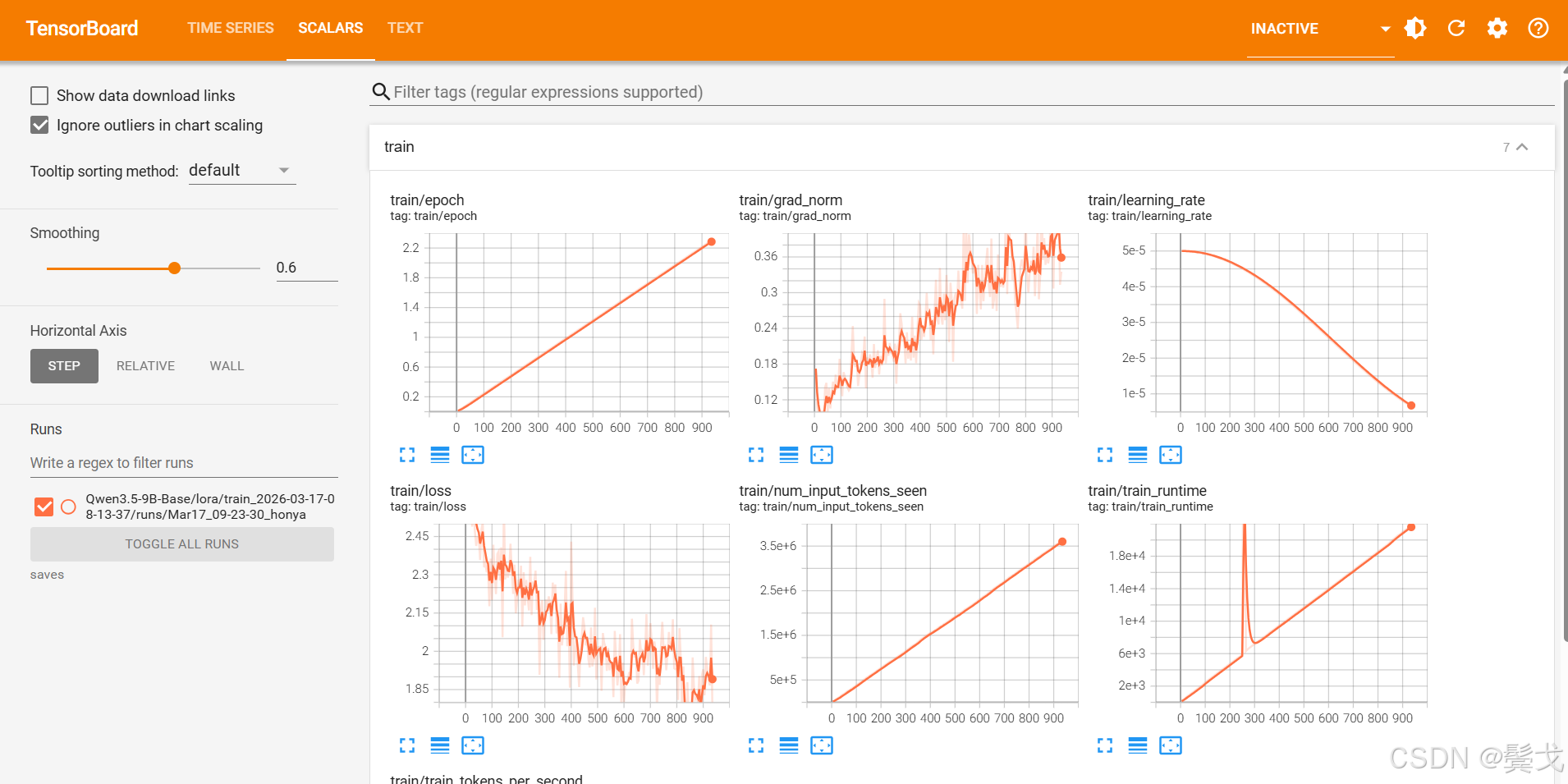
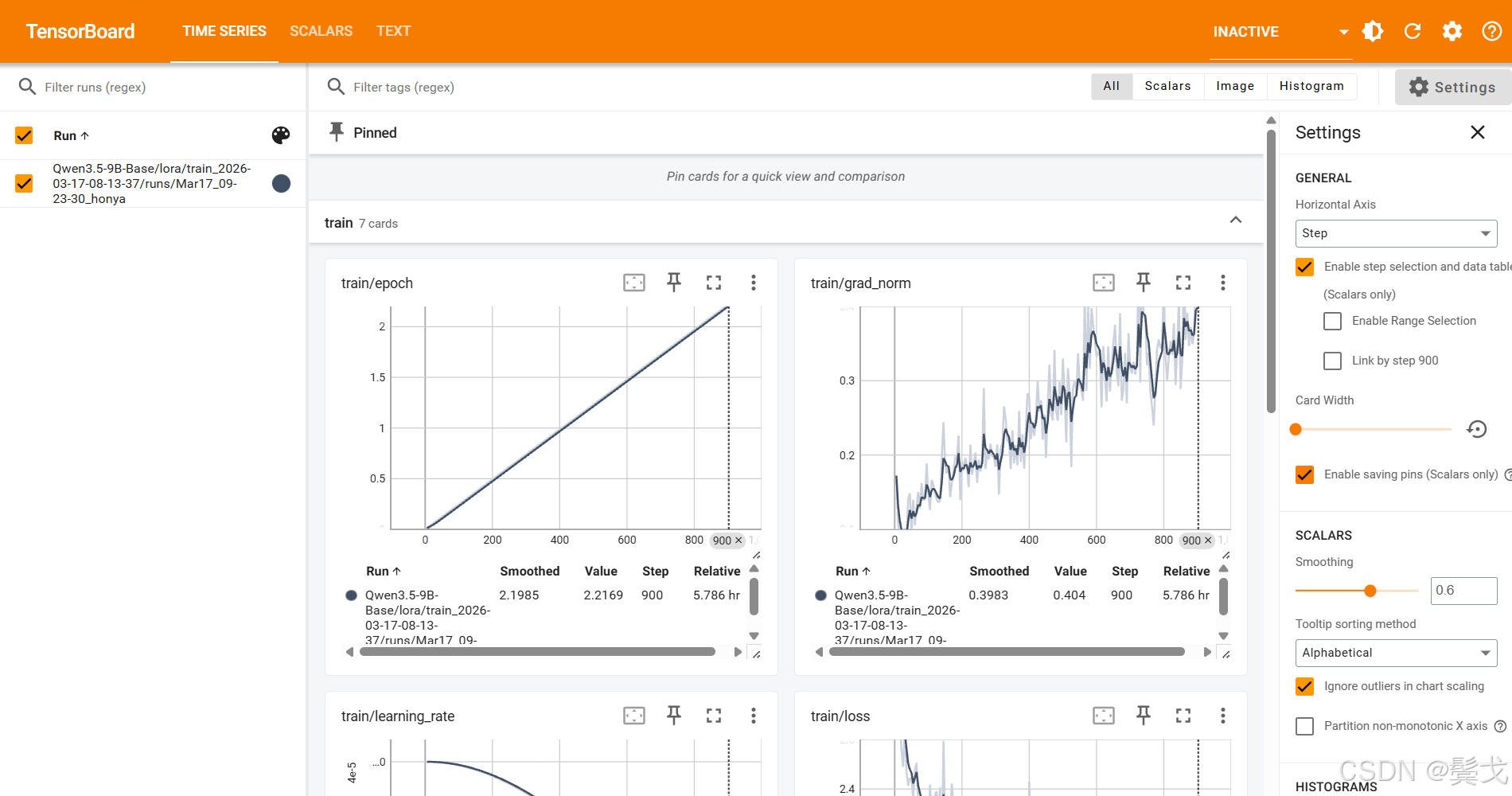
7. TensorBoard监控
需要手工安装:
pip install tensorboard
编写一个启动脚本:
(qwen3) honya@honya:~/llm/LlamaFactory$ cat run_tensorboard.sh
#!/bin/bash
nohup tensorboard --bind_all --logdir=saves >./nohup_tensorboard.out 2>&1 &

在浏览器打开:http://localhost:6006/
8. 结束语
主要是训练过程很慢,同步把工作记录一下,当做简单的工作笔记而已,没有什么价值。