Toward Cognitive Supersensing in Multimodal Large Language Model
Authors: Boyi Li, Yifan Shen, Yuanzhe Liu, Yifan Xu, Jiateng Liu, Xinzhuo Li, Zhengyuan Li, Jingyuan Zhu, Yunhan Zhong, Fangzhou Lan, Jianguo Cao, James M. Rehg, Heng Ji, Ismini Lourentzou, Xu Cao
Deep-Dive Summary:
迈向多模态大语言模型的认知超感知(Toward Cognitive Supersensing in Multimodal Large Language Model)
本文提出了一种名为**认知超感知(Cognitive Supersensing)**的新型训练范式,旨在增强多模态大语言模型(MLLMs)在复杂认知任务中的表现。尽管现有的 MLLM 在开放词汇感知任务中表现出色,但在处理需要视觉记忆和抽象细节的认知问题时仍面临挑战。
1 引言(Introduction)
目前的 MLLM 往往依赖于文本空间的链式思考(CoT)推理,但语言在表达几何变换、动态模拟或抽象规则时存在局限。为了填补感知与高层认知推理之间的鸿沟,作者受到人类"视空间写字板(Visuospatial Sketchpad)"和"视觉表象(Visual Imagery)"的启发,探索在潜空间(Latent Space)中进行内部视觉推理。
主要贡献包括:
- Cognitive Supersensing:一种结合监督微调(SFT)和强化学习(RL)的范式,使模型能够生成视觉潜表征推理链。
- CogSense-Bench:一个从五个认知维度(流体智力、晶体智力、视觉空间认知、心理模拟和视觉程序)评估视觉认知的综合基准。
- CogSense-8B:在 CogSense-Bench 上达到了 SoTA 性能,超越了 GPT-5.2 等模型,并具有出色的领域外泛化能力。
3 方法(Method)
CogSense 的训练分为三个阶段:
3.1 阶段 I:推理链生成
使用高性能 MLLM 作为教师模型,为图像输入生成高质量的 CoT 推理步骤(即 rationale Z Z Z),并过滤掉答案错误或包含幻觉的内容。
3.2 阶段 II:带潜视觉表象预测(LVIP)的 SFT
引入 潜视觉表象预测(Latent Visual Imagery Prediction, LVIP) 磁头 g ψ ( ⋅ ) g_{\psi}(\cdot) gψ(⋅),它是一个附加在 LLM 主干上的 MLP,用于预测正确答案选项图像的潜表征。
联合损失函数定义为:
L S F T = − ∑ t = 1 ∣ x ∣ log q θ ( x t ∣ X , x < t ) + β ⋅ M S E ( h ^ y , h y ) \mathcal{L}{\mathrm{SFT}} = -\sum{t = 1}^{|x|}\log q_{\theta}(x_{t}\mid X,x_{< t}) + \beta \cdot \mathrm{MSE}(\hat{h}{y},h{y}) LSFT=−t=1∑∣x∣logqθ(xt∣X,x<t)+β⋅MSE(h^y,hy)
其中 h ^ y \hat{h}_y h^y 是预测的潜表象, h y h_y hy 是由视觉编码器提取的真实图像嵌入。
3.3 阶段 III:带潜推理链的强化学习(RL)
使用生成流网络(GFlowNet)对推理路径 q θ ( Z ∣ X ) q_{\theta}(Z \mid X) qθ(Z∣X) 进行优化。奖励函数由答案正确性奖励 R a n s R_{\mathrm{ans}} Rans 和 LVIP 潜表征对齐奖励 R i v i p R_{\mathrm{ivip}} Rivip 组成:
R ( Z ; X , y ) = α R a n s ( Z ; X , y ) + γ R i v i p ( Z ; X , y ) R(Z;X,y) = \alpha R_{\mathrm{ans}}(Z;X,y) + \gamma R_{\mathrm{ivip}}(Z;X,y) R(Z;X,y)=αRans(Z;X,y)+γRivip(Z;X,y)
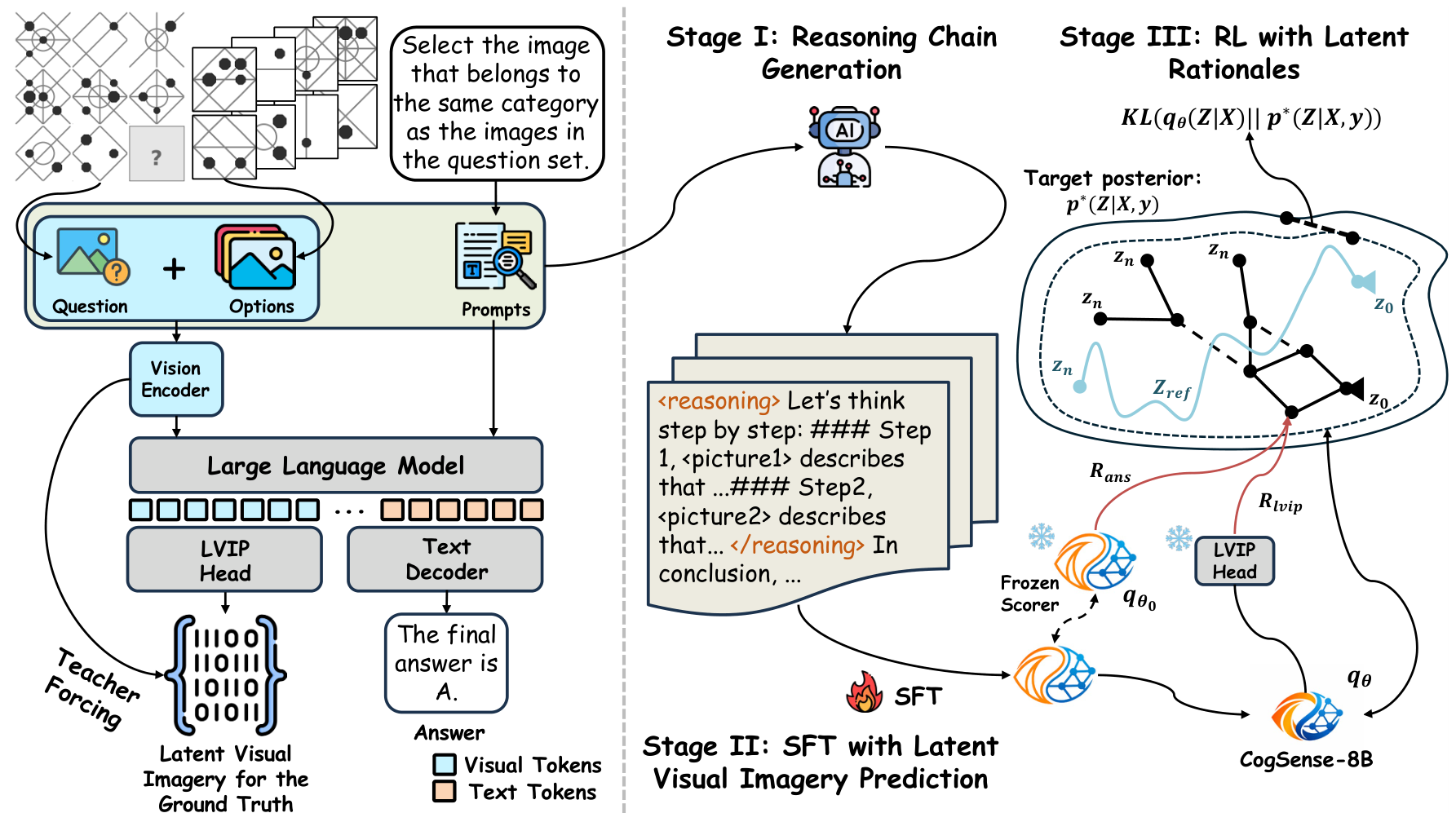
图 3:Cognitive Supersensing 框架。 左侧为模型架构,右侧为三阶段训练流程。
4 实验结果(Experiments)
4.1 认知能力评估
CogSense-8B 在所有认知任务上均取得了最佳性能,总平均准确率为 73.8%,大幅领先于 GPT-5.2(40.3%)和 Qwen3-VL-30B(37.4%)。
表 1:认知能力结果比较。
|--------------------|--------------|---------------------|-------------------|--------------|--------------|------|
| Model | Fluid Intel. | Crystallized Intel. | Visuospatial Cog. | Mental Simu. | Visual Rout. | Avg. |
| Human | 82.7 | 91.3 | 88.5 | 97.9 | 78.7 | 88.4 |
| GPT-5.2 | 29.4 | 35.9 | 57.5 | 60.0 | 37.6 | 40.3 |
| CogSense-8B (Ours) | 63.8 | 91.0 | 69.0 | 68.0 | 50.5 | 73.8 |
4.2 通用能力评估
CogSense-8B 在 HallusionBench、ScienceQA 等通用视觉问答基准上也表现稳定,证明了认知增强并未损害其基础感知能力。
表 2:通用能力结果。
|--------------------|----------------|------|------|-----------|-------------|---------|-------|--------|
| Model | HallusionBench | AI2D | GQA | ScienceQA | RealWorldQA | ChartQA | BLINK | MMStar |
| Qwen3-VL-8B(base) | 61.1 | 85.4 | 71.4 | 92.6 | 71.5 | 88.6 | 64.7 | 70.9 |
| CogSense-8B (Ours) | 60.5 | 85.1 | 71.8 | 92.6 | 71.9 | 84.7 | 65.3 | 66.8 |
4.3 消融实验
消融实验表明,LVIP 模块和专门设计的强化学习方法对性能提升至关重要。
表 3:消融实验结果。
|--------------------------|--------------|---------------------|-------------------|--------------|--------------|------|
| Variant | Fluid Intel. | Crystallized Intel. | Visuospatial Cog. | Mental Simu. | Visual Rout. | Avg. |
| Qwen3-VL-8B SFT w/o LVIP | 51.1 | 76.6 | 63.7 | 59.3 | 41.9 | 62.3 |
| Qwen3-VL-8B SFT w/ LVIP | 55.4 | 88.6 | 61.1 | 61.3 | 44.1 | 68.0 |
| CogSense-8B (Ours) | 63.8 | 91.0 | 69.0 | 68.0 | 50.5 | 73.8 |

图 4:视觉认知推理的定性示例。 展示了 CogSense-8B 如何通过连贯的多步逻辑链推断出正确的图案规则。
4.5 域外评估
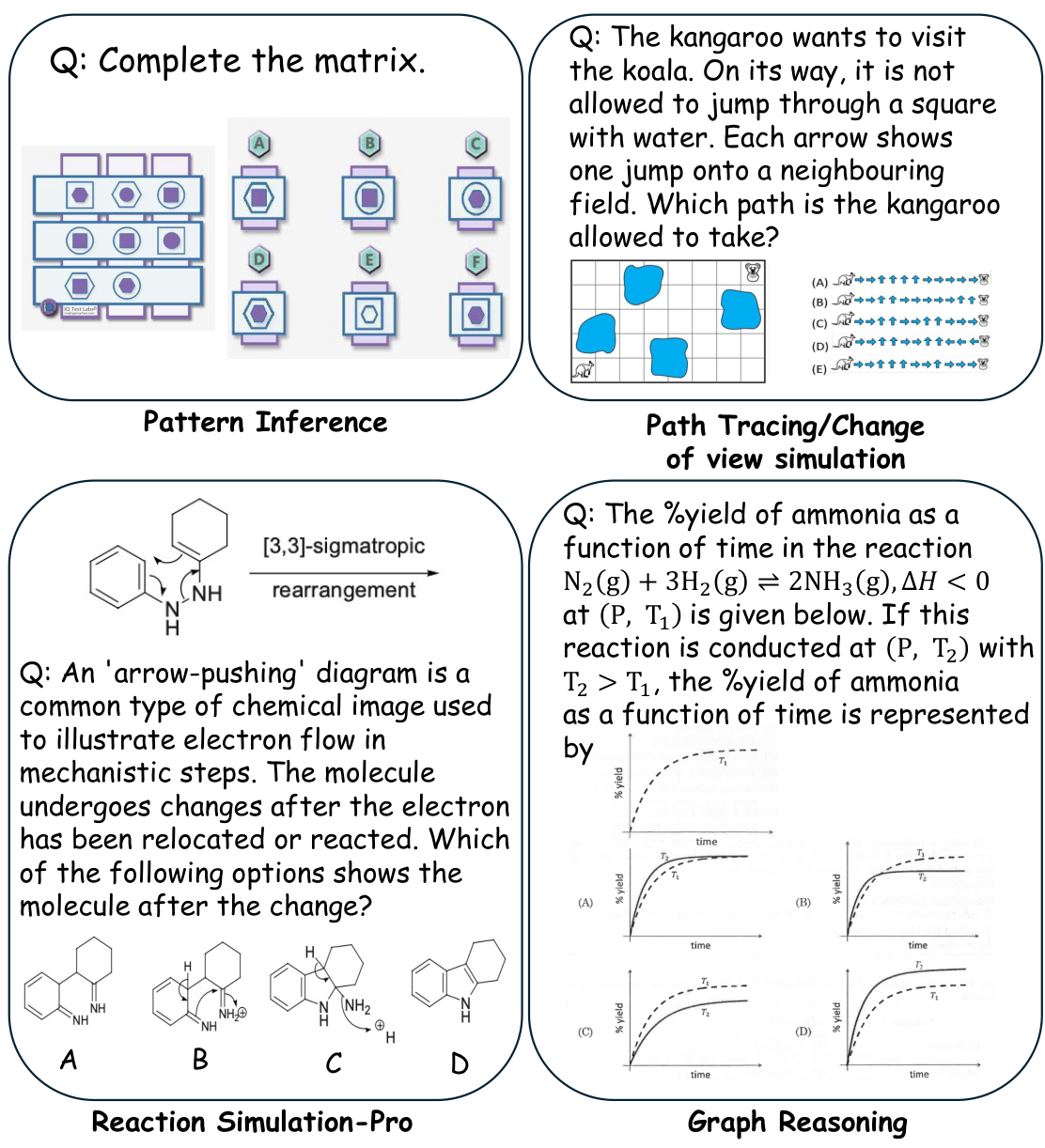
为了进一步验证 CogSense-8B 的泛化能力,研究团队将评估扩展到了域外(out-of-domain)场景,使用了 EMMA 基准测试(Hao et al., 2025)中的化学(Chemistry)和数学(Math)子集。这些测试的题目和选项均包含图像。如图 5 所示展示了 EMMA 数据的示例。如表 4 所示,CogSense-8B 在化学和数学子集上分别实现了 + 6.2 +6.2 +6.2 和 + 8.8 +8.8 +8.8 的显著性能提升。这证实了该方法学习到的是通用的视觉认知模式,而非对特定训练数据的过拟合。
5 相关工作
本工作与抽象推理、视觉认知、用于视觉推理的视觉语言模型(VLMs)以及潜层视觉推理密切相关。附录 E 中提供了更详尽的讨论。
6 结论
在这项工作中,我们提出了"认知超感知"(Cognitive Supersensing)范式,旨在弥合多模态大语言模型(MLLMs)中感知处理与复杂认知推理之间的鸿沟。通过集成潜层视觉图像预测(LVIP)头,并采用结合了监督微调(SFT)和带有潜层推理链(Latent Rationales)的强化学习(RL)训练策略,我们使 CogSense-8B 能够模拟出与语义推理链保持一致的内部视觉图像。
我们进一步引入了 CogSense-Bench,这是一个针对视觉认知五个维度的综合评估套件。实验结果表明,CogSense-8B 在这些认知任务上的表现优于现有的先进(SoTA)MLLM 基准模型。这些结果表明,建模视觉模拟与逻辑推演之间的交互是提升多模态系统推理能力的有效方向。
Original Abstract: Multimodal Large Language Models (MLLMs) have achieved remarkable success in open-vocabulary perceptual tasks, yet their ability to solve complex cognitive problems remains limited, especially when visual details are abstract and require visual memory. Current approaches primarily scale Chain-of-Thought (CoT) reasoning in the text space, even when language alone is insufficient for clear and structured reasoning, and largely neglect visual reasoning mechanisms analogous to the human visuospatial sketchpad and visual imagery. To mitigate this deficiency, we introduce Cognitive Supersensing, a novel training paradigm that endows MLLMs with human-like visual imagery capabilities by integrating a Latent Visual Imagery Prediction (LVIP) head that jointly learns sequences of visual cognitive latent embeddings and aligns them with the answer, thereby forming vision-based internal reasoning chains. We further introduce a reinforcement learning stage that optimizes text reasoning paths based on this grounded visual latent. To evaluate the cognitive capabilities of MLLMs, we present CogSense-Bench, a comprehensive visual question answering (VQA) benchmark assessing five cognitive dimensions. Extensive experiments demonstrate that MLLMs trained with Cognitive Supersensing significantly outperform state-of-the-art baselines on CogSense-Bench and exhibit superior generalization on out-of-domain mathematics and science VQA benchmarks, suggesting that internal visual imagery is potentially key to bridging the gap between perceptual recognition and cognitive understanding. We will open-source the CogSense-Bench and our model weights.
PDF Link: 2602.01541v1
部分平台可能图片显示异常,请以我的博客内容为准
