精彩专栏推荐订阅:在下方主页👇🏻👇🏻👇🏻👇🏻
💖🔥作者主页 :计算机毕设木哥🔥 💖
文章目录
- 一、项目介绍
- 二、选题背景意义
- 三、开发环境
- 四、系统展示
- 五、代码展示
- 六、项目文档展示
- 七、项目总结
- [<font color=#fe2c24 >大家可以帮忙点赞、收藏、关注、评论啦 👇🏻](#fe2c24 >大家可以帮忙点赞、收藏、关注、评论啦 👇🏻)
一、项目介绍
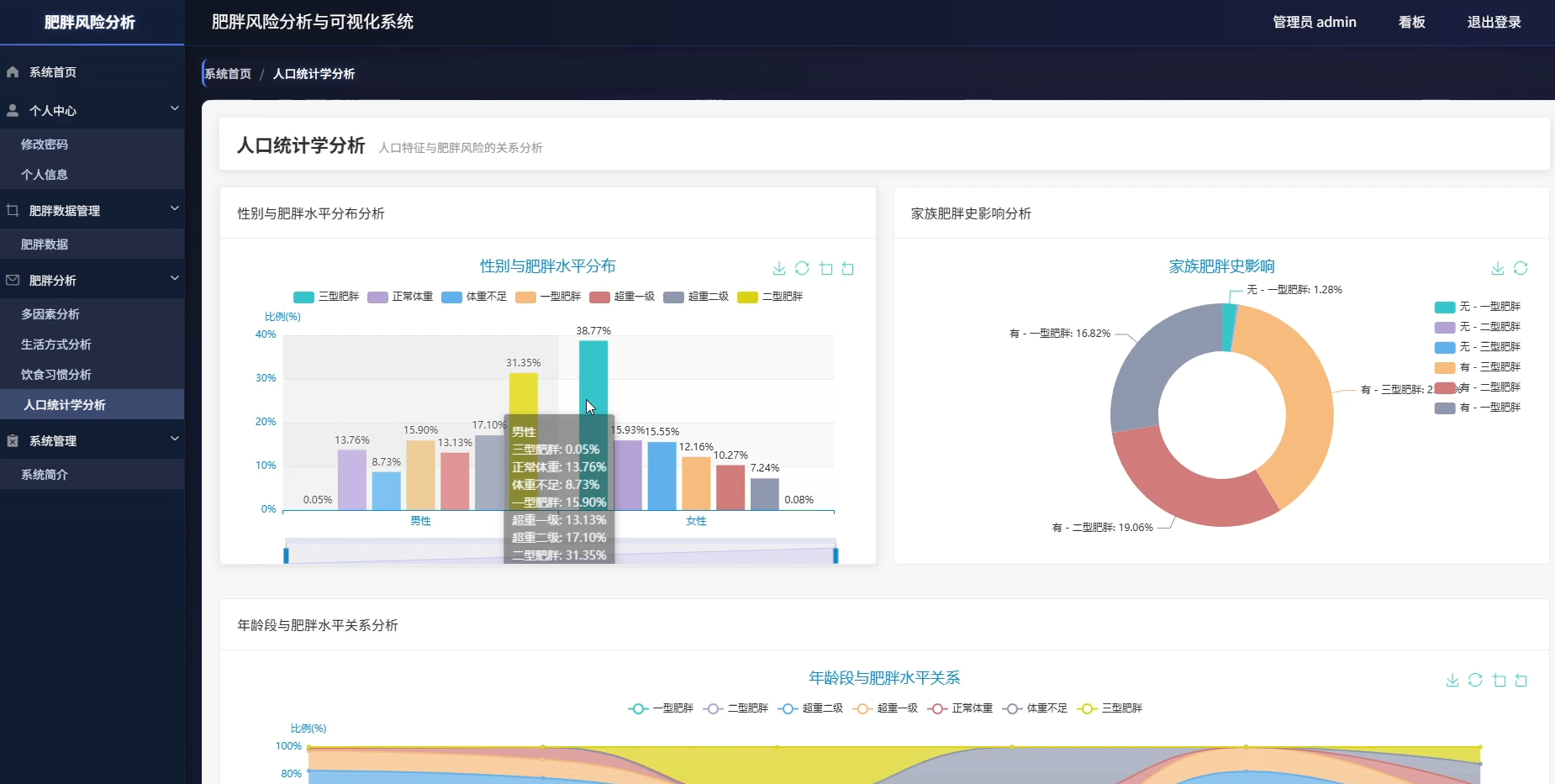
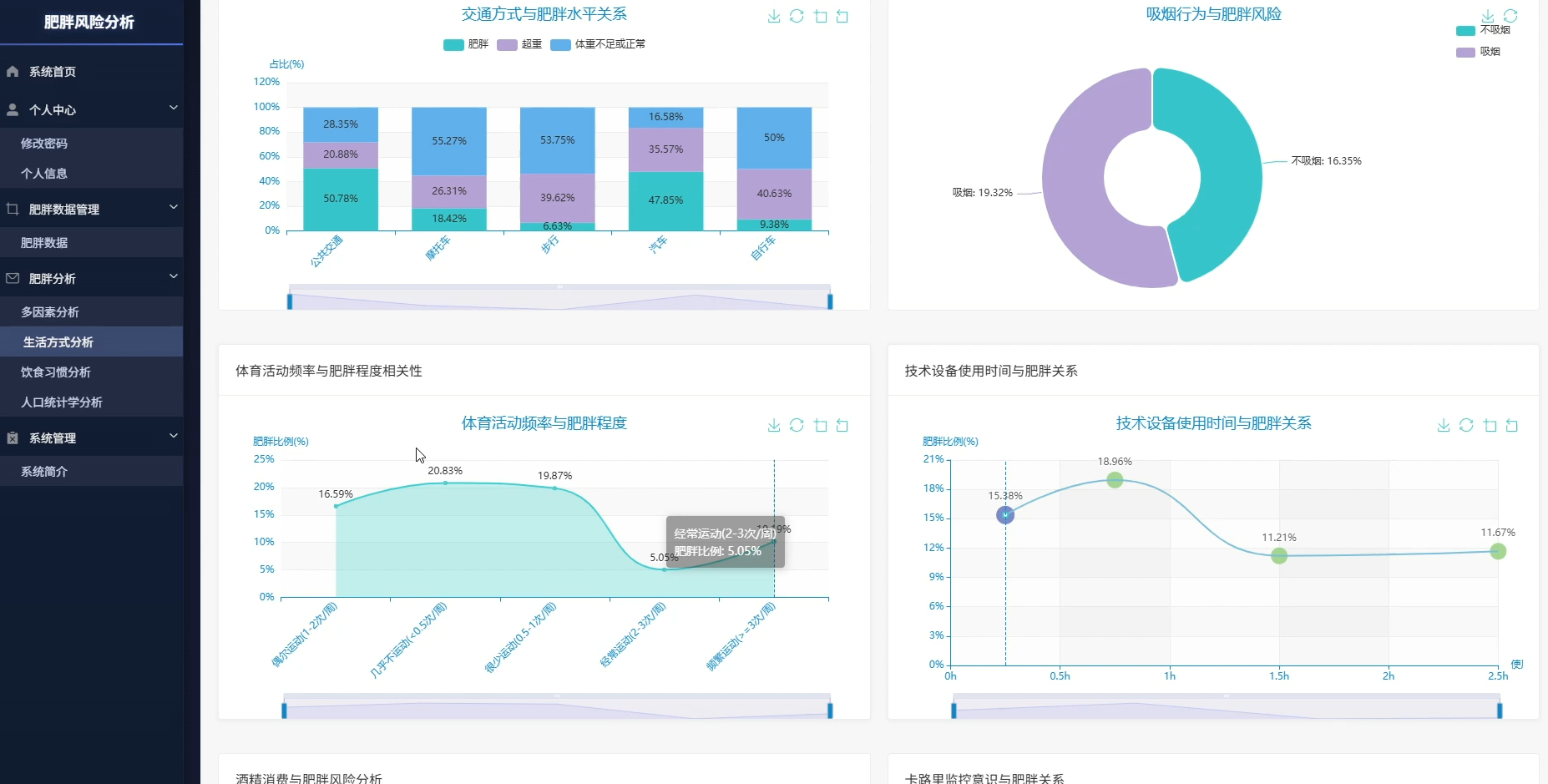
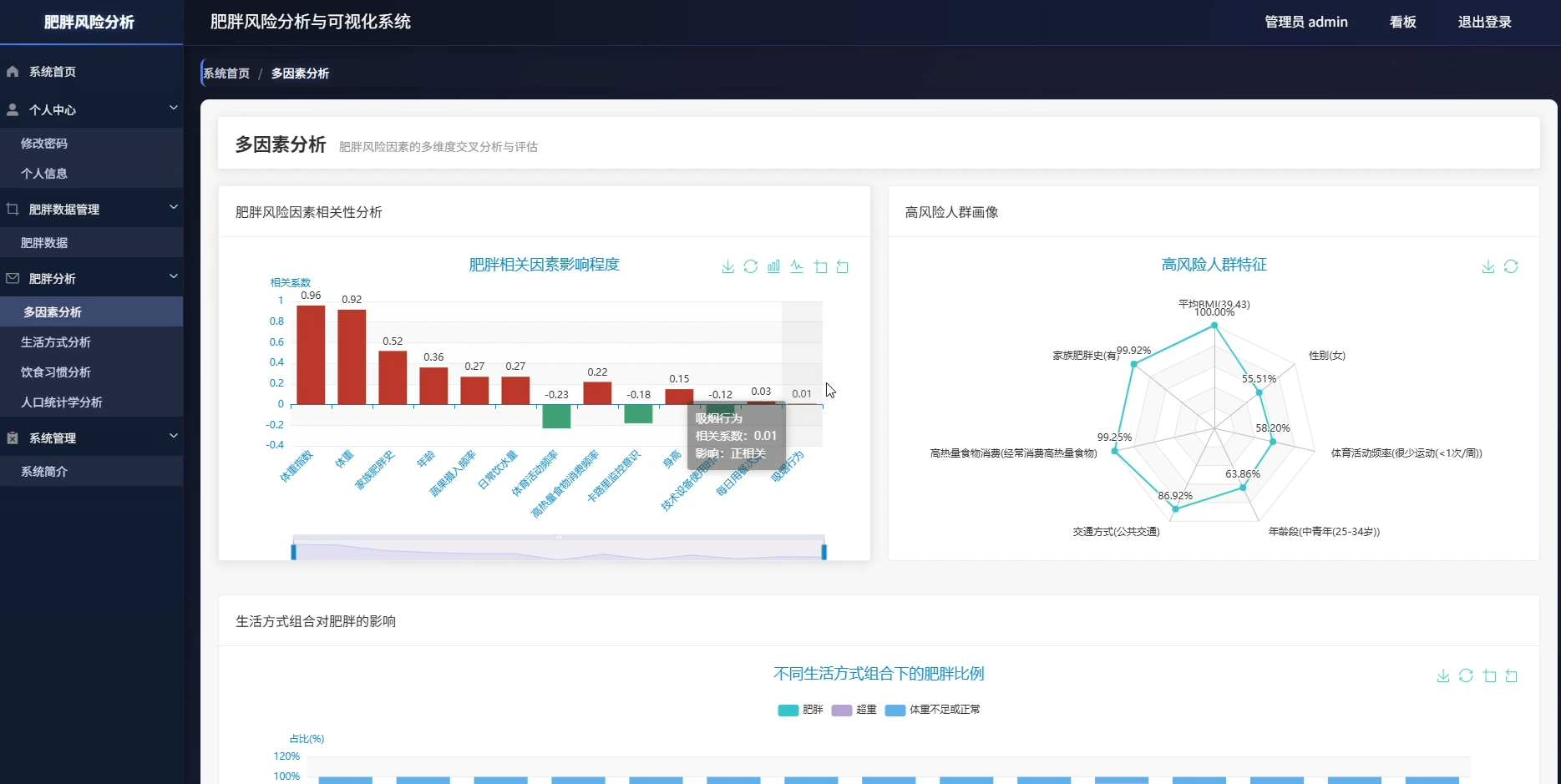
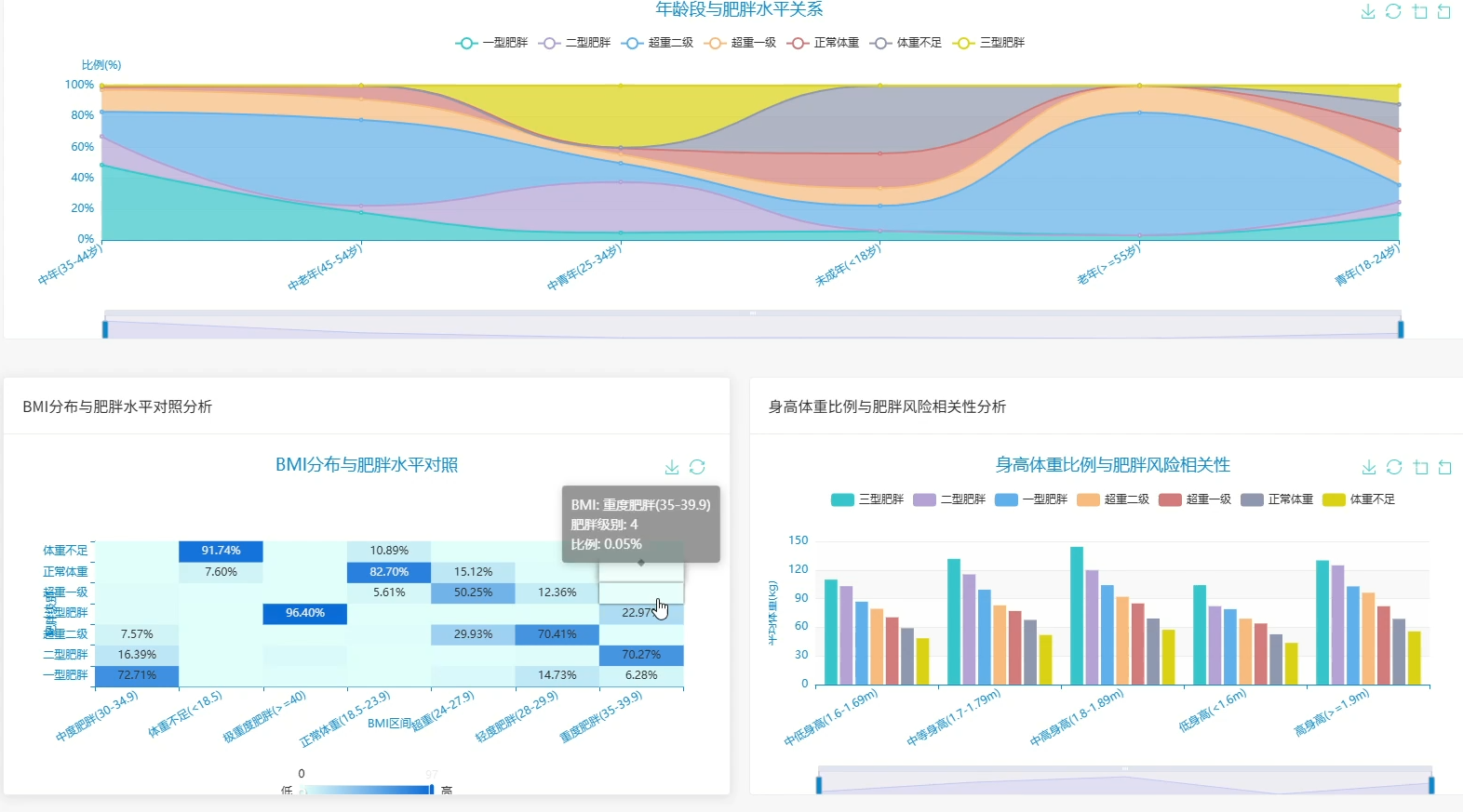
本系统是一套专注于肥胖风险识别与数据洞察的分析平台,围绕人口统计学特征、饮食习惯、生活方式三大维度展开数据挖掘与可视化呈现。系统内置性别与肥胖水平分布、年龄段风险识别、BMI对照验证、家族遗传影响评估等人口学分析模块,同时覆盖高热量食物消费、蔬果摄入频率、每日用餐次数、加餐行为、饮水量等饮食维度,以及交通方式、吸烟行为、体育活动频率、电子设备使用时间、酒精消费、卡路里监控意识等生活方式维度。在多因素综合分析层面,系统通过相关性计算确定风险因素权重,构建高风险人群特征画像,分析生活习惯组合与肥胖的关联关系,并探索遗传因素与环境因素的交互作用,最终按年龄性别分层识别差异化风险因素,为精准干预提供数据依据。所有分析结果通过可视化图表直观展示,帮助用户理解肥胖形成的复杂机制。
二、选题背景意义
肥胖问题在现代生活中越来越常见,已经不只是个人体型管理的事,而是关乎整体健康的重要议题。身边不少人都在为体重发愁,但很多人其实不太清楚自己到底是怎么胖起来的,是吃得不健康、动得太少,还是有家族遗传的因素在里头。现在市面上虽然有不少健康类应用,但大多只是记录体重或者算个BMI,能把饮食习惯、生活方式这些细节和肥胖风险结合起来分析的并不多。再加上很多大学生做毕设时想找既贴近生活又有技术含量的题目,健康大数据分析就是个不错的切入点。这个方向数据好找、分析维度多,既能练手大数据处理,又能做出点实际有用的东西,比那些纯理论或者完全脱离现实的题目要实在得多。
做这个系统的实际价值主要体现在几个方面。对学生自己来说,能把课堂上学的大数据技术真正用起来,从数据清洗到分析建模再到可视化展示,走完一个完整的项目流程,这比光看书本知识要强不少。做出来的东西还能给身边有减肥需求的朋友参考,让他们更清楚自己的生活习惯哪里有问题。对学校的教学来说,这种结合健康主题的项目也算是个案例,以后可以给学弟学妹展示怎么把技术和实际问题结合起来。虽然这只是个毕业设计,做得肯定不如商业产品那么完善,但至少能把数据分析的思路呈现出来,证明用大数据方法研究健康问题这条路是走得通的,也算为这方面的探索添了块小砖头。
三、开发环境
- 大数据技术:Hadoop、Spark、Hive
- 开发技术:Python、Django框架、Vue、Echarts
- 软件工具:Pycharm、DataGrip、Anaconda
- 可视化 工具 Echarts
四、系统展示
页面模块展示:

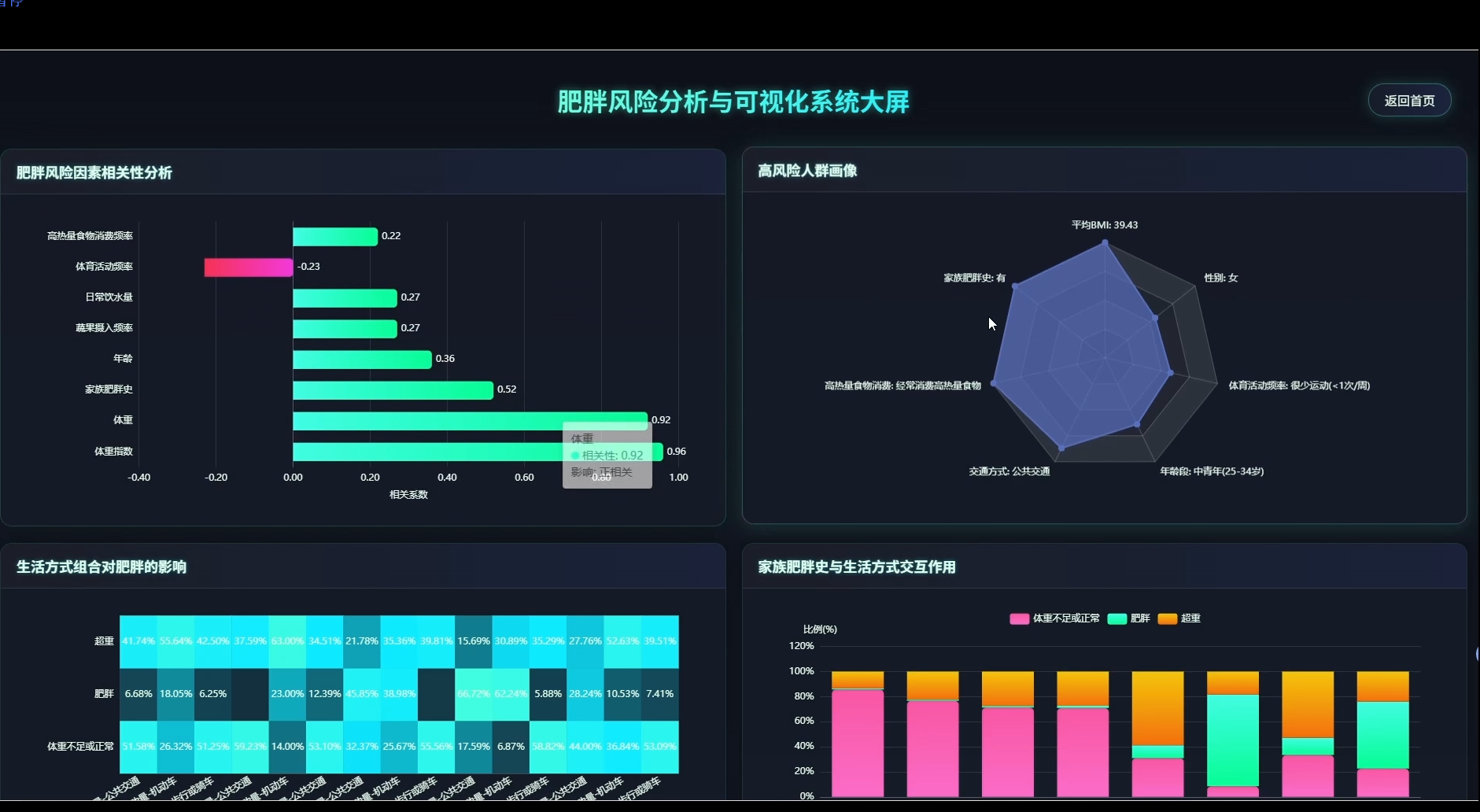
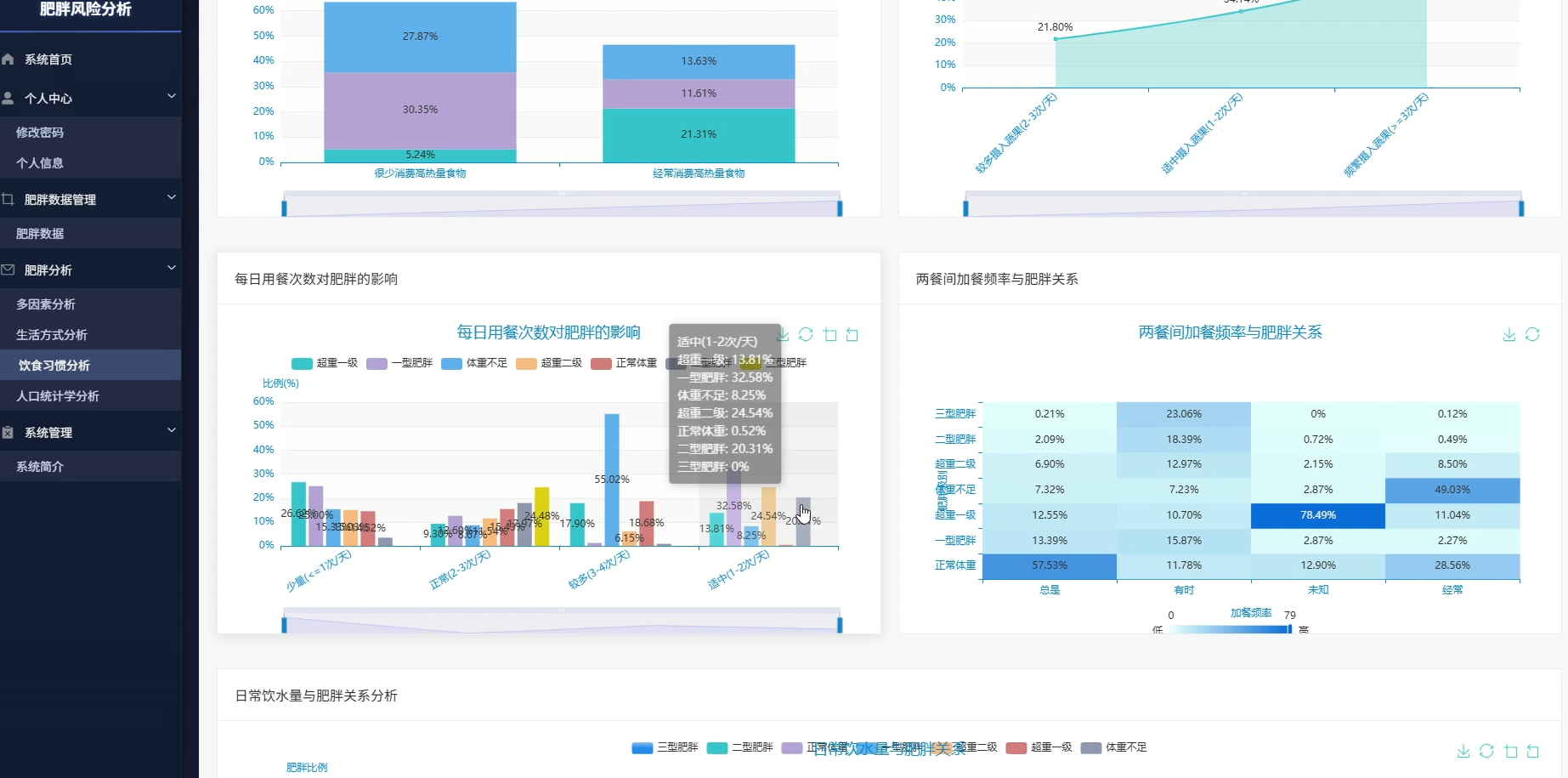
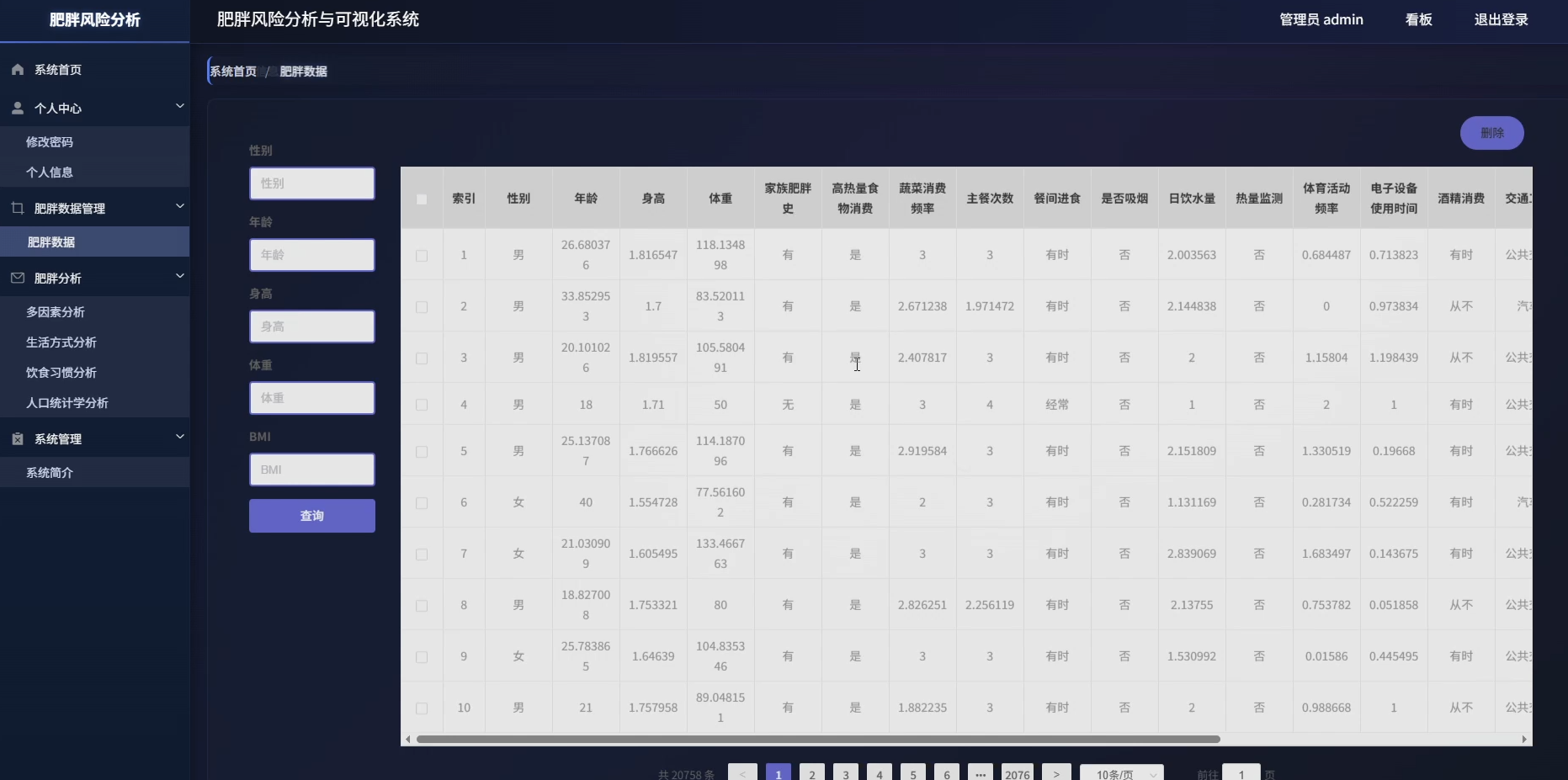
五、代码展示
bash
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, when, count, avg, stddev, corr, round as spark_round
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.stat import Correlation
import pandas as pd
import json
spark = SparkSession.builder.appName("ObesityRiskAnalysis").config("spark.sql.adaptive.enabled", "true").config("spark.sql.adaptive.coalescePartitions.enabled", "true").getOrCreate()
def analyze_gender_obesity_distribution(data_path):
df = spark.read.csv(data_path, header=True, inferSchema=True)
gender_obesity = df.groupBy("Gender", "ObesityLevel").agg(count("*").alias("count")).orderBy("Gender", "ObesityLevel")
total_by_gender = df.groupBy("Gender").agg(count("*").alias("total"))
result = gender_obesity.join(total_by_gender, "Gender").withColumn("percentage", spark_round(col("count") / col("total") * 100, 2))
pandas_df = result.toPandas()
distribution_dict = {}
for gender in pandas_df["Gender"].unique():
gender_data = pandas_df[pandas_df["Gender"] == gender]
distribution_dict[gender] = {row["ObesityLevel"]: {"count": int(row["count"]), "percentage": float(row["percentage"])} for _, row in gender_data.iterrows()}
return json.dumps(distribution_dict, ensure_ascii=False)
def calculate_bmi_obesity_correlation(data_path):
df = spark.read.csv(data_path, header=True, inferSchema=True)
df_with_bmi = df.withColumn("BMI", spark_round(col("Weight") / (col("Height") / 100) ** 2, 2))
obesity_mapping = {"Insufficient_Weight": 1, "Normal_Weight": 2, "Overweight_Level_I": 3, "Overweight_Level_II": 4, "Obesity_Type_I": 5, "Obesity_Type_II": 6, "Obesity_Type_III": 7}
mapping_expr = when(col("ObesityLevel") == "Insufficient_Weight", 1).when(col("ObesityLevel") == "Normal_Weight", 2).when(col("ObesityLevel") == "Overweight_Level_I", 3).when(col("ObesityLevel") == "Overweight_Level_II", 4).when(col("ObesityLevel") == "Obesity_Type_I", 5).when(col("ObesityLevel") == "Obesity_Type_II", 6).when(col("ObesityLevel") == "Obesity_Type_III", 7)
df_mapped = df_with_bmi.withColumn("ObesityNumeric", mapping_expr)
correlation_value = df_mapped.stat.corr("BMI", "ObesityNumeric")
bmi_stats = df_with_bmi.groupBy("ObesityLevel").agg(spark_round(avg("BMI"), 2).alias("avg_bmi"), spark_round(stddev("BMI"), 2).alias("std_bmi"), count("*").alias("count")).orderBy("ObesityLevel")
stats_list = [{"obesity_level": row["ObesityLevel"], "avg_bmi": row["avg_bmi"], "std_bmi": row["std_bmi"], "count": row["count"]} for row in bmi_stats.collect()]
return json.dumps({"correlation": round(correlation_value, 4), "bmi_statistics": stats_list}, ensure_ascii=False)
def analyze_diet_obesity_relationship(data_path):
df = spark.read.csv(data_path, header=True, inferSchema=True)
favc_analysis = df.groupBy("FAVC", "ObesityLevel").agg(count("*").alias("count")).withColumn("FAVC_Label", when(col("FAVC") == "yes", "经常吃高热量食物").otherwise("不常吃高热量食物"))
fcvc_analysis = df.withColumn("FCVC_Category", when(col("FCVC") >= 3, "高频摄入").when(col("FCVC") >= 2, "中频摄入").otherwise("低频摄入")).groupBy("FCVC_Category", "ObesityLevel").agg(count("*").alias("count"))
caec_analysis = df.groupBy("CAEC", "ObesityLevel").agg(count("*").alias("count")).withColumn("CAEC_Label", when(col("CAEC") == "no", "不加餐").when(col("CAEC") == "Sometimes", "偶尔加餐").when(col("CAEC") == "Frequently", "经常加餐").otherwise("总是加餐"))
favc_list = [{"diet_habit": row["FAVC_Label"], "obesity_level": row["ObesityLevel"], "count": row["count"]} for row in favc_analysis.collect()]
fcvc_list = [{"vegetable_freq": row["FCVC_Category"], "obesity_level": row["ObesityLevel"], "count": row["count"]} for row in fcvc_analysis.collect()]
caec_list = [{"snack_habit": row["CAEC_Label"], "obesity_level": row["ObesityLevel"], "count": row["count"]} for row in caec_analysis.collect()]
return json.dumps({"high_calorie_food": favc_list, "vegetable_intake": fcvc_list, "snacking_behavior": caec_list}, ensure_ascii=False)六、项目文档展示

七、项目总结
这套基于大数据的肥胖风险分析与可视化系统,本质上是用数据科学的思路去拆解一个和生活息息相关的健康问题。整个项目从数据层面把肥胖这件事拆成了人口特征、吃什么、怎么活三个大方向,每个方向下面又细分了好几个观察角度,比如性别年龄这些基本情况、吃饭喝水睡觉这些日常习惯,最后还把各种因素串起来看它们是怎么互相影响的。技术实现上主要用了Spark做大数据处理,支撑起数据读取、清洗、分组聚合、相关性计算这些操作,三个核心功能分别对应性别分布分析、BMI验证计算、饮食习惯关联这三个最基础也最实用的分析场景。整套系统下来,既练了大数据工具的使用,又把健康数据分析的完整流程走了一遍,从数据导入到结果输出都是通的。当然作为毕业设计,它离真正投入使用还有距离,分析模型比较简单,数据维度也有限,但核心框架是完整的,展示效果也是直观的,对于想入门健康大数据分析的同学来说,算是一个可以参考的样例,也为后续更深入的研究搭了个基础台阶。
大家可以帮忙点赞、收藏、关注、评论啦 👇🏻
💖🔥作者主页 :计算机毕设木哥🔥 💖