精彩专栏推荐订阅:在下方主页👇🏻👇🏻👇🏻👇🏻
💖🔥作者主页 :计算机毕设木哥🔥 💖
文章目录
- 一、项目介绍
- 二、选题背景意义
- 三、开发环境
- 四、系统展示
- 五、代码展示
- 六、项目文档展示
- 七、项目总结
- [<font color=#fe2c24 >大家可以帮忙点赞、收藏、关注、评论啦 👇🏻](#fe2c24 >大家可以帮忙点赞、收藏、关注、评论啦 👇🏻)
一、项目介绍
本系统《基于大数据的各省碳排放数据分析与可视化系统》是专为计算机专业毕业生设计的一套综合性数据分析平台。系统采用Python语言开发,深度融合了大数据处理技术,利用Spark分布式计算框架对海量历史碳排放数据进行清洗、转换与高效计算,克服了传统工具处理大规模数据时的性能瓶颈。在功能实现上,系统集成了时间维度的趋势演变分析、空间维度的区域格局对比以及排放结构维度的深度拆解,能够全方位、多角度地展示各省及重点区域的碳排放现状。前端界面采用可视化技术,将复杂的数据结果以直观的图表形式呈现,不仅解决了毕设项目中"数据展示不直观"的难题,更体现了从数据采集、处理到展示的全流程技术能力,是一个兼具技术深度与实用价值的高质量毕设项目。
二、选题背景意义
选题背景
随着全球气候变化问题日益严峻,减少温室气体排放已成为国际社会的共识。我国明确提出"双碳"目标,即碳达峰与碳中和,这对各地区的能源结构和产业发展模式提出了新的挑战。在这个过程中,准确掌握各省份的碳排放数据,摸清排放家底,对于制定科学的减排政策至关重要。传统的数据统计方式往往依赖于人工汇总,不仅效率低下,而且难以从宏观和微观两个层面发现数据背后的潜在规律。在大数据技术飞速发展的今天,利用计算机技术对海量的环境数据进行挖掘分析,已成为辅助政府决策和学术研究的重要手段。因此,开发一个能够高效处理并可视化展示碳排放数据的系统,顺应了国家绿色发展的战略需求,也符合当前信息化建设的实际趋势。
选题意义
开发这套系统的初衷主要是为了锻炼自己处理大规模数据的能力,同时也希望能给相关领域的数据分析提供一个便捷的工具。从实际应用角度来看,系统通过直观的图表展示,能帮助使用者快速理解不同省份、不同行业的碳排放差异,不用再对着枯燥的Excel表格发愁。对于像我们这样的学生来说,这不仅仅是一个毕业设计项目,更是一次将大数据理论应用于具体实践的尝试。虽然系统功能可能无法媲美商业级软件,但它在整合多维度数据、展示区域排放特征方面确实发挥了一定作用,能够为关注环保话题的人士提供一种清晰的数据视角。做这个项目最大的收获,就是学会了如何用技术手段去解决现实生活中的复杂问题,这种解决问题的思路比项目本身更有价值。
三、开发环境
- 大数据技术:Hadoop、Spark、Hive
- 开发技术:Python、Django框架、Vue、Echarts
- 软件工具:Pycharm、DataGrip、Anaconda
- 可视化 工具 Echarts
四、系统展示
页面模块展示:

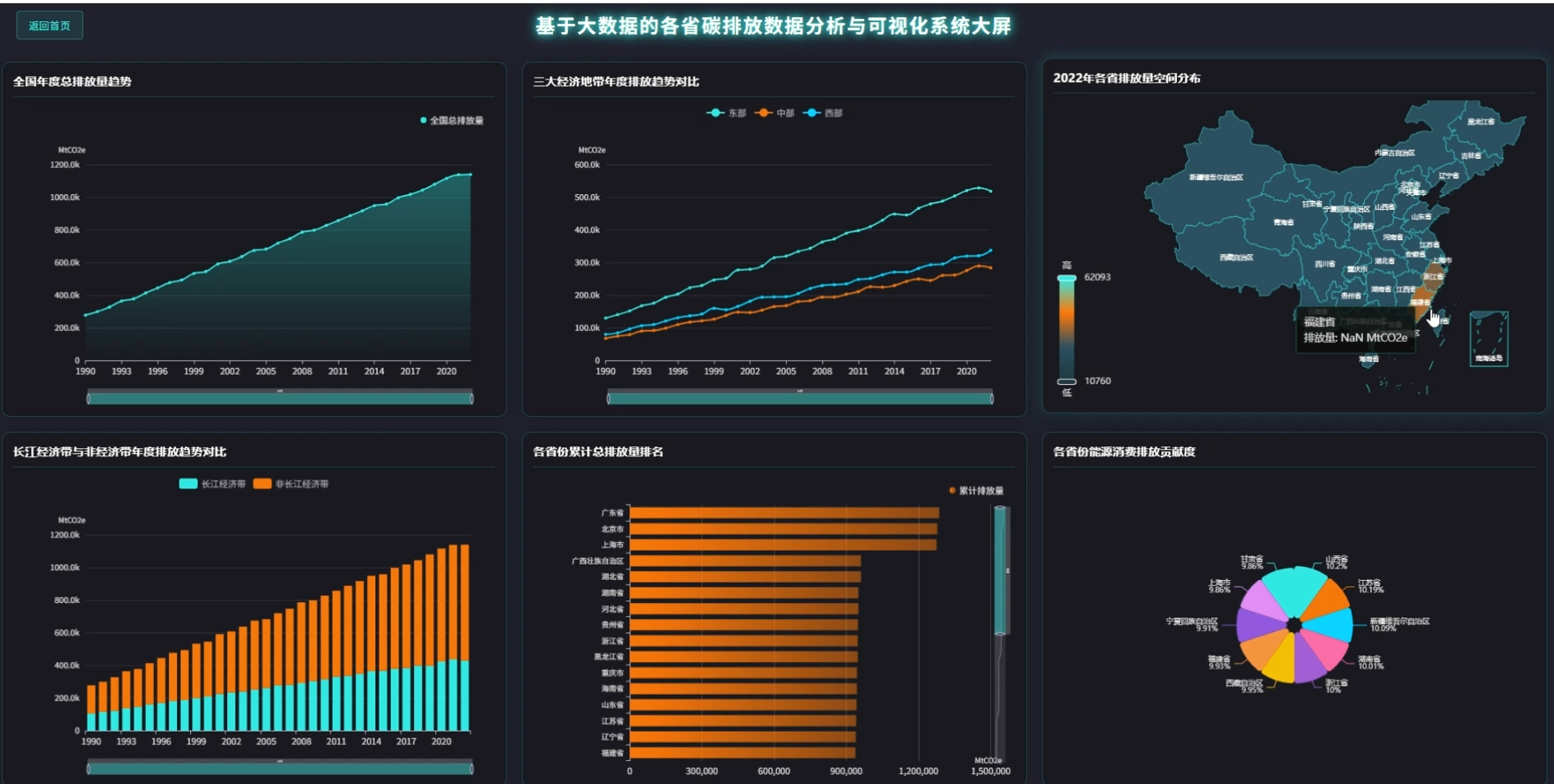
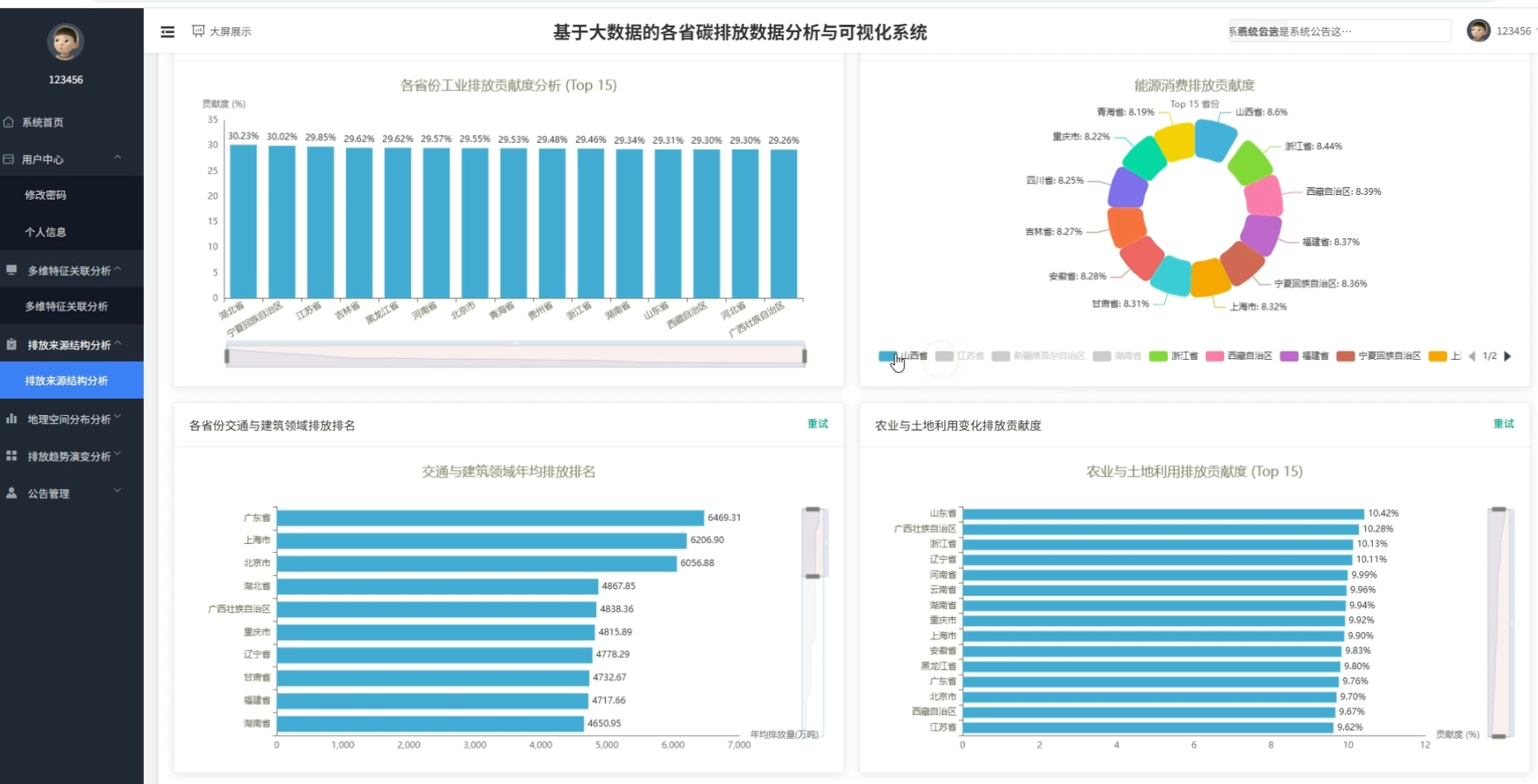
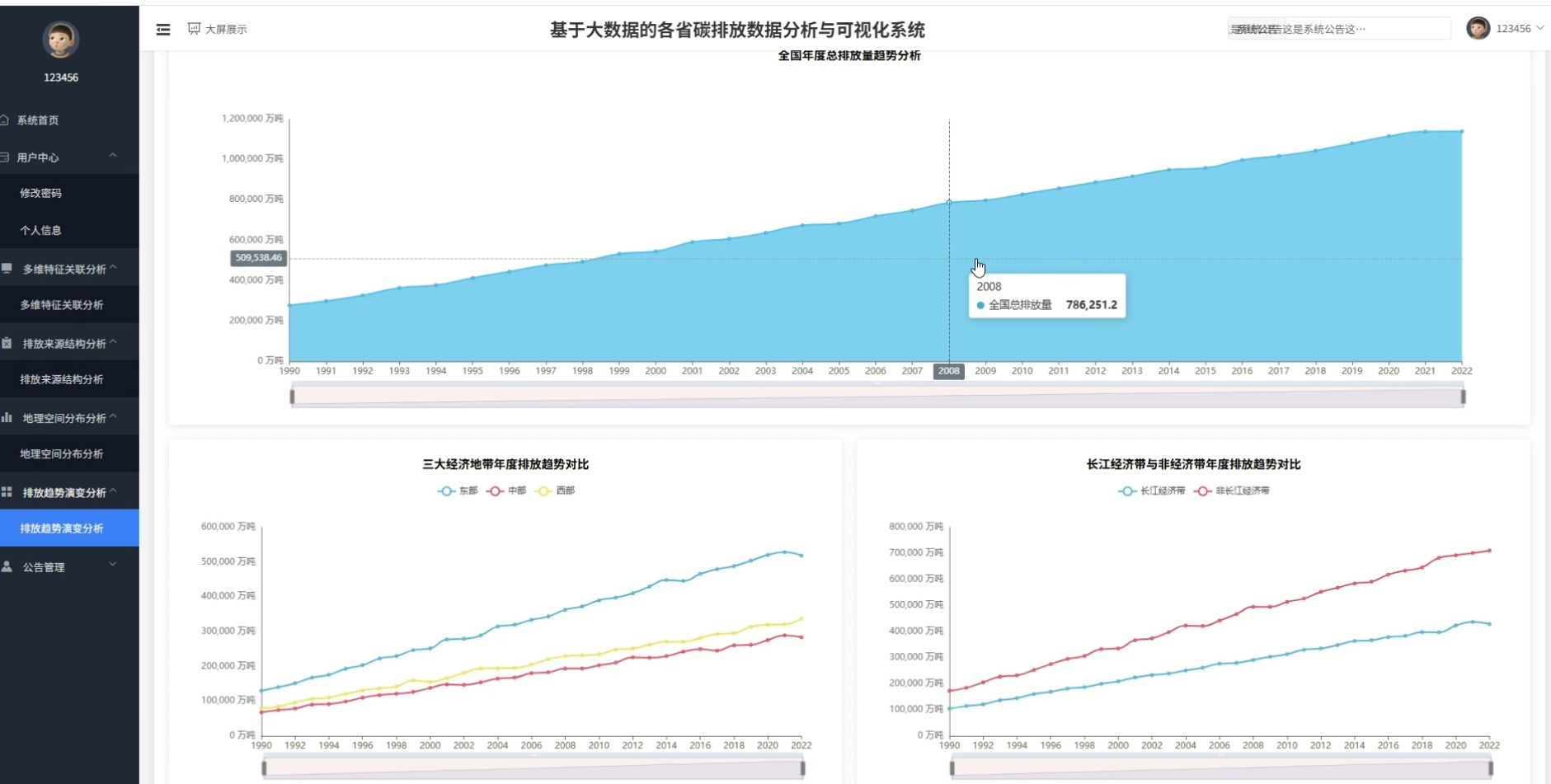
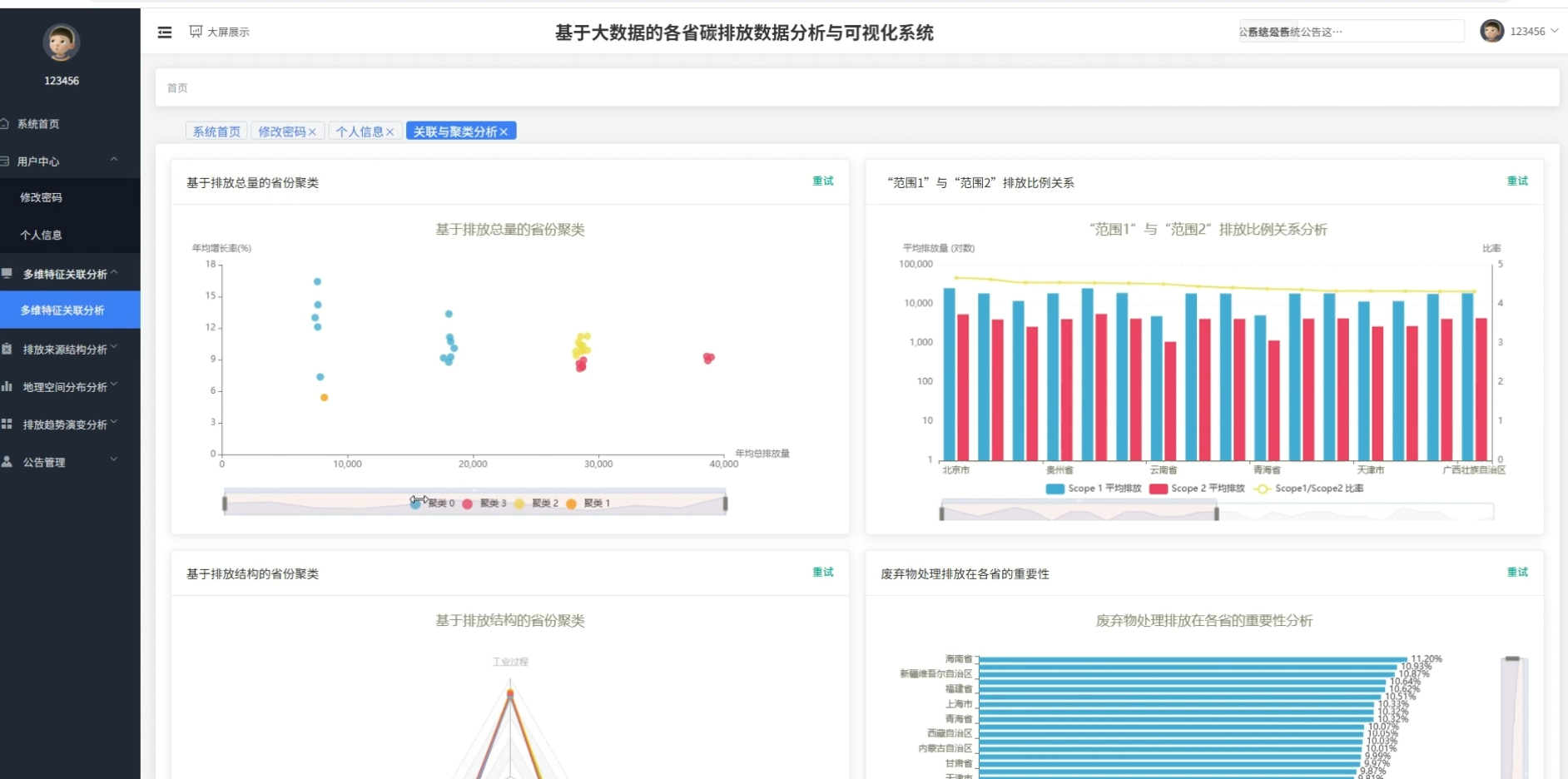

五、代码展示
bash
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, sum as _sum, avg, when, lit
spark = SparkSession.builder.appName("CarbonEmissionAnalysis").getOrCreate()
def analyze_annual_trend(df):
df.createOrReplaceTempView("emission_data")
result_df = spark.sql("SELECT year, SUM(total_emissions) as annual_total FROM emission_data GROUP BY year ORDER BY year")
return result_df
def analyze_regional_distribution(df):
df_grouped = df.groupBy("province").agg(_sum("total_emissions").alias("province_total")).orderBy(col("province_total").desc())
return df_grouped
def analyze_industrial_structure(df):
df_with_ratio = df.withColumn("industrial_ratio", when(col("total_emissions") != 0, col("industrial_process_emissions") / col("total_emissions")).otherwise(0))
avg_ratio_df = df_with_ratio.groupBy("province").agg(avg("industrial_ratio").alias("avg_industrial_ratio")).orderBy(col("avg_industrial_ratio").desc())
return avg_ratio_df
def classify_provinces_by_growth(df):
stats_df = df.groupBy("province").agg(_sum("total_emissions").alias("total"), avg("total_emissions").alias("avg_emission"))
classified_df = stats_df.withColumn("type", when((col("total") > 1000000) & (col("avg_emission") > 50000), "High_Emission_High_Growth").when((col("total") < 500000) & (col("avg_emission") < 20000), "Low_Emission_Stable").otherwise("Normal_Type"))
return classified_df六、项目文档展示

七、项目总结
本项目《基于大数据的各省碳排放数据分析与可视化系统》通过对Spark大数据计算框架的应用,成功实现了对多维度碳排放数据的高效处理与深度挖掘。系统不仅展示了从时间演变到空间分布的全貌,还通过聚类算法识别了不同省份的排放模式,体现了数据分析在环境领域的应用潜力。在整个开发过程中,重点解决了数据清洗、复杂指标计算以及可视化展示等关键技术问题,实现了预期的各项功能。虽然在数据广度和算法复杂度上还有提升空间,但系统整体架构清晰,交互友好,较好地完成了既定的设计任务,为毕业设计交上了一份满意的答卷。
大家可以帮忙点赞、收藏、关注、评论啦 👇🏻
💖🔥作者主页 :计算机毕设木哥🔥 💖