文章标题:《GridDehazeNet: Attention-Based Multi-Scale Network for Image Dehazing》
期刊及年份:ICCV 2019
作者:Xiaohong Liu
论文链接:https://arxiv.org/abs/1908.03245v1
一、摘要
本文提出了一种端到端的可训练的用于单图像去雾的CNN(卷积神经网络)模型,命名为GridDehazeNet。GridDehazeNet由三个模块组成:预处理(pre-processing) 、骨干网络(backbone) 和**后处理(post-processing)**模块。
与手工选择的预处理方法产生的输入相比,可训练的预处理模块可以产生学习的输入(能够具有更好的多样性和更相关的特征)。
骨干网络在网格网络中应用一种新型的基于注意力的多尺度估计,可以有效缓解常规多尺度方法中经常遇到的瓶颈问题。
后处理模块有助于减少最终输出中的伪像。
二、引言
根据大气散射模型(相关公式: 公式中 (  ) 是 模糊 (清晰) 图像中像素x的第i个颜色通道的强度,t(x)是传输矩阵,A是全局大气光的强度 ),论文中指出,在不知道A和t(x)的情况下,图像去雾通常是一个不确定的过程。
以下三个问题需要重点关注:
1.物理模型的作用:许多数据驱动的图像恢复的方法需要合成的数据集进行训练。为了产生这些数据集,有必要具有相关图像退化过程的物理模型 (例如,雾霾效应的大气散射模型)。一个自然的问题出现了,图像恢复算法的设计是否需要依赖于这个物理模型 。显然,由于模型不匹配,依赖于模型的算法可能会在现实的图像上遭受固有的性能损失。但是,通常认为这样的算法在使用相同物理模型创建的合成图像上具有优势。
2.预处理方法的选择:预处理可以用来生成给定图像的几个变体,提供形式的多样性,可以通过适当的融合加以利用。然而,预处理方法通常是基于试探法选择的,因此不一定最适合所考虑的问题。
3.多尺度估计的瓶颈:**图像恢复需要显式/隐式了解失真图像与原始清晰版本之间的统计关系。**捕获这种关系所需的统计模型通常需要大量的参数,可比甚至超过可用的训练数据。多尺度估计通过以下方式解决此问题:(1)用低维统计模型近似高维统计模型 (2)基于训练数据进行低维模型的参数估计 (3)参数化估计的低维模型的邻域,执行精细化估计,并在需要时重复此过程。由于多尺度估计通常以连续的方式进行,因此其性能通常受到某些瓶颈的限制。
GridDehazeNet主要有三个贡献:(1)该方法不依赖于大气散射模型;(2)预处理模型是可以训练的,相比于人工选择的方法更具有灵活性;(3)基于注意力机制的多尺度网络可以较好的估计模型中的参数,该网络可以高效的交换不同尺度的信息,从而有效缓解多尺度估计的瓶颈问题。
三、主要内容
3.1 GridDehazeNet
所提出的端到端可训练网络GridDehazeNet具有三个重要功能:
1.不依赖大气散射模型 :在下图中,我们提供了一种可能的解释,即为什么如果盲目地使用t(x)与颜色通道无关的事实 来缩小搜索空间 会有问题,以及为什么在搜索最佳t(x)时放松这种约束 可能是有利的。然而,通过这种放松,大气散射模型在估计过程中没有提供维数减少。更重要的是,众所周知,CNN的损失面通常表现良好,因为局部最小值通常几乎与全局最小值一样好。另一方面,通过将大气散射模型结合到CNN中,基本上引入了本质上与网络其余部分不同的非线性分量,这可能产生不期望的损耗表面。
下图(图1)中我们专注于单个像素的两种颜色通道,并通过t1和t2对各自的透射图进行降噪。图(a)绘制了作为t1和t2的函数的loss表面。可以看出,全局最小值达到了满足t1 = t2的点 (绿点),这与大气散射模型一致。黑点作为起始点,可以通过梯度下降找到全局最小点(见黄色路径)。然而,基于沿t1 = t2方向的大气散射模型的区域限制搜索 (见红色路径) 将在紫色点指示的点处卡住 (见图2(b))。该点是受限空间中的局部最小值 ,而不是原始空间中的局部最小值,并且仅由于采用了大气散射模型而成为障碍。
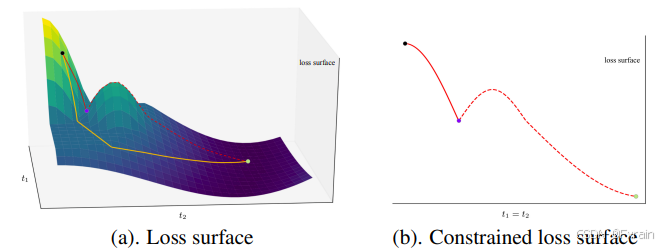 图1 关于使用大气散射模型进行图像去雾的潜在有害影响
图1 关于使用大气散射模型进行图像去雾的潜在有害影响
2.可训练的预处理模块 :预处理模块通过生成给定朦胧图像的多个变体,每个变体突出显示该图像的不同方面,并使相关特征信息更明显地暴露,从而有效地将单图像去雾问题转换为多图像去雾问题。
3.基于注意力的多尺度估计 :与编码器-解码器网络和广泛用于图像恢复的传统多尺度网络相比,网格网络具有明显的优势。特别是,编码器-解码器网络或传统多尺度网络中的信息流往往因分层架构而受到瓶颈效应的影响,而网格网络则通过使用上采样/下采样块在不同尺度之间建立密集连接,从而规避了这一问题。我们进一步为网络赋予了通道注意力机制,这使得信息交换和聚合更加灵活。注意力机制还使网络能够更好地利用预处理模块所创造的多样性。
3.2 网络架构
下图(图2)展示了GridDehazeNet整体架构:
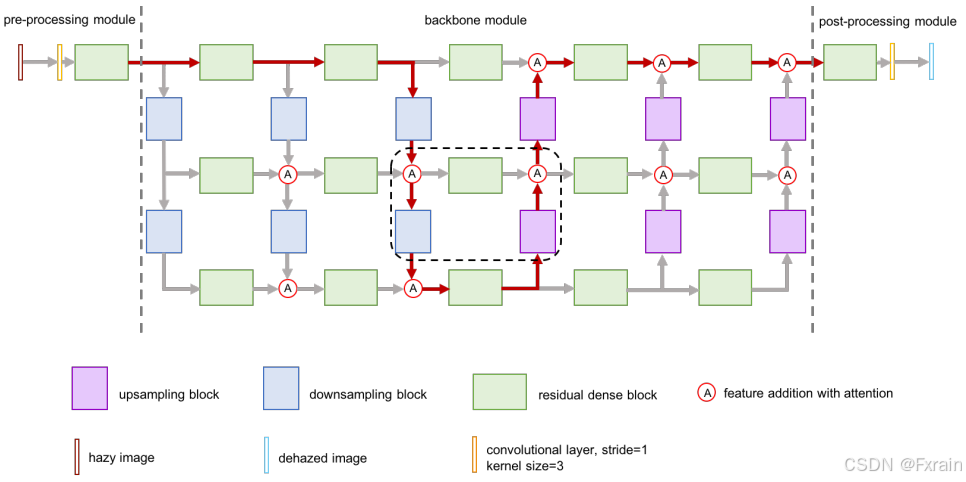 图2 GridDehazeNet的整体架构
图2 GridDehazeNet的整体架构
预处理模块 由卷积层 (w/o激活函数) 和**残差密集块 (residual dense block,RDB)**组成。它从给定的朦胧图像中生成16个特征图,这些特征图将作为学习的输入。
骨干模块是GridNet的增强版本,最初是为语义分割而提出的。它根据预处理模块生成的学习输入执行基于注意力的多尺度估计。这里我们选择具有三行六列的网格网络。每一行对应于不同的比例,并由保持特征映射数量不变的五个RDB块组成。每列可以被视为通过上采样/下采样块连接不同刻度的桥。在每个上采样 (下采样) 块中,特征映射的大小减少 (增加) 2倍,而特征映射的数量增加 (减少) 相同的因子。这里的上采样/下采样是使用卷积层而不是诸如双线性或双插值之类的传统方法来实现的。下面提供了关于RDB块,上采样块和下采样块的详细的插图(图3):
 图3 图2虚线块示意图
图3 图2虚线块示意图
每一个RDB块有五个卷积层组成,前四层用于增加特征图的数量,最后一层融合了这些特征图,然后通过通道方式将其输出与该RDB块的输入合并。RDB的增长率设置为16。上采样块和下采样块在结构上是相同的,除了使用不同的卷积层来调整特征图的大小。在所提出的GridDehazeNet中,除了预处理模块中的第一个卷积层和每个RDB块中的1×1卷积层外,所有卷积层均采用ReLU作为激活函数。为了在输出大小和计算复杂度之间取得平衡,我们将三个不同尺度的特征图数量分别设置为16、32和64。
直接从骨干模块的输出构建的去雾图像倾向于包含伪像。因此,通过后处理模块提高去雾图像的质量。后处理模块的结构与预处理模块的结构对称。
3.3 基于通道注意力的特征融合
来自不同尺度的特征映射可能并不具有相同的重要性,本文提出了一种逐通道注意机制,以生成用于特征融合的可训练权重。让 和
分别代表从行流(row stream)和列流(column stream)中的第i个特征通道,并让
和
表示它们的关联注意力权重。基于通道方向的注意力机制可以表示为以下公式:
表示在第i通道的融合特征。注意力机制使GridDehazeNet能够灵活调整特征融合中不同尺度的贡献。
值得注意的是,可以通过选择合适的注意力权重来修剪 (或停用) 提议的GridDehazeNet的部分,并作为特例恢复一些现有网络。例如,图3中的红色路径示出了可以通过修建GridDehazeNet获得的编码器-解码器网络。
3.4 损失函数(Loss Function)
为了训练所提出的网络,采用了平滑的L1损失和感知损失。
平滑的L1损失提供了去雾图像与ground truth之间差异的定量度量,由于L1范数可以防止潜在的梯度爆炸,因此对异常值的敏感性低于MSE损失。
L1损失可以表示为:
其中, 表示在去雾图像中像素x的第i个颜色通道强度,N代表整个像素的数量。
与每像素损失不同,感知损失利用从经过预训练的深度神经网络中提取的多尺度特征来量化估计图像与ground truth之间的视觉差异。我们使用在ImageNet上预先训练的VGG16作为损失网络,并从前三个阶段 (即Conv1-2,Conv2-2和Conv3-3) 的最后一层提取特征。
感知损失公式为:
代表与去雾图像
(真值J) 相关的上述三个VGG16特征图,
分别代表不同的维度。
最后总损失为:
λ是一个参数,用于调整两个损失分量上的相对权重。在本文中,λ被设置为0.04。