Transformer实战(35)------跨语言相似性任务
0. 前言
跨语言模型能够以统一的形式表示文本,即使句子来自不同的语言,只要它们的意义相近,就会被映射到向量空间中的相似向量,XLM-R (XLM-Robust)是流行跨语言模型之一。接下来,我们使用 XLM-R 模型进行实际应用,应用跨语言模型来衡量不同语言之间的相似性。
1. 使用 XLM-R 模型进行跨语言文本相似性
在本节中,我们将学习如何使用在跨语言自然语言推理 (Cross-Lingual Natural Language Inference, XNLI) 数据集上预训练的跨语言模型,来查找不同语言中的相似文本,我们可以将其应用于抄袭检测系统。我们将使用阿塞拜疆语的句子,看看 XLM-R 是否能找到与之相似的英语句子。
(1) 首先,需要加载一个适用于此任务的模型:
python
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer("stsb-xlm-r-multilingual") (2) 接下来,准备两个独立的句子列表,分别包含阿塞拜疆语句子和英语句子:
python
azeri_sentences = ['Pişik çöldə oturur',
'Bir adam gitara çalır',
'Mən makaron sevirəm',
'Yeni film möhtəşəmdir',
'Pişik bağda oynayır',
'Bir qadın televizora baxır',
'Yeni film çox möhtəşəmdir',
'Pizzanı sevirsən?']
english_sentences = ['The cat sits outside',
'A man is playing guitar',
'I love pasta',
'The new movie is awesome',
'The cat plays in the garden',
'A woman watches TV',
'The new movie is so great',
'Do you like pizza?'](3) 使用 XLM-R 模型的 encode 函数将这些句子表示为向量:
python
azeri_representation = model.encode(azeri_sentences)
english_representation = model.encode(english_sentences) (4) 最后,搜索第一个语言中与第二个语言含义相似的句子:
python
results = []
for azeri_sentence, query in zip(azeri_sentences, azeri_representation):
id_, score = util.semantic_search(
query,english_representation)[0][0].values()
results.append({
"azeri": azeri_sentence,
"english": english_sentences[id_],
"score": round(score, 4)
})(5) 使用 pandas DataFrame 查看结果:
python
import pandas as pd
pd.DataFrame(results)可以在输出中看到句子间的匹配得分情况:

如果我们将得分最高的句子作为同义句或翻译结果,模型在第 4 行出现了错误,因为即使所有的句子都不相关,也总有得分最高的句子,为了解决这一问题,我们可以设定一个阈值并接受高于该值的匹配结果。
2. 使用 LaBSE 模型进行跨语言文本相似性
除了 XLM-R 外,也可以使用其他双编码器模型。这类方法对两个句子进行成对编码,并对结果进行分类以训练模型,语言无关的 BERT 句子嵌入 (language-agnostic bert sentence embedding, LaBSE) 是典型的双编码器模型,可以通过 sentence-transformers 库和 TensorFlow Hub 加载使用。LaBSE 是一个基于 Transformer 的双编码器模型,类似于 Sentence-BERT,其中两个具有相同参数的编码器通过基于两个句子双重相似性的损失函数进行结合。
(1) 继续使用以上句子,将模型切换为 LaBSE,查看运行结果:
python
model = SentenceTransformer("LaBSE")
azeri_representation = model.encode(azeri_sentences)
english_representation = model.encode(english_sentences)
results = []
for azeri_sentence, query in zip(azeri_sentences, azeri_representation):
id_, score = util.semantic_search(
query,english_representation)[0][0].values()
results.append({
"azeri": azeri_sentence,
"english": english_sentences[id_],
"score": round(score, 4)
})
import pandas as pd
pd.DataFrame(results)结果如下所示:

可以看到,LaBSE 在这种情况下表现更好,第 4 行的结果这次是正确的。LaBSE 在查找句子的翻译方面表现非常出色,但在查找不完全相同的句子时效果稍逊。因此,可以将其用于查找通过翻译进行抄袭的行为。但同时,还有许多其他因素会影响结果,例如,每种语言的预训练模型的资源大小以及语言对的性质。为了进行合理的比较,我们需要全面考虑多种因素。
3. 可视化跨语言文本相似性
接下来,我们将测量并可视化两个句子之间的文本相似性,其中一个句子是另一个的翻译。Tatoeba 是一个免费收录此类句子及其翻译的集合,它是 XTREME 基准测试的一部分。该社区旨在通过许多参与者的支持,获得高质量的句子翻译。
(1) 首先,使用 pip 命令安装所需库:
python
pip install umap-learn(2) 从 Tatoeba 集合中提取俄语和英语的句子:
python
from datasets import load_dataset
import pandas as pd
data=load_dataset("xtreme","tatoeba.rus", split="validation")
pd.DataFrame(data)[["source_sentence","target_sentence"]]输出句子示例如下所示:
(3) 首先,取前 K=30 个句子对进行可视化,之后会对对整个集合进行可视化。使用 sentence-transformers 对这些句子进行编码:
python
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("stsb-xlm-r-multilingual")
K=30
emb=model.encode(data["source_sentence"][:K] + data["target_sentence"][:K])
len(emb), len(emb[0])(4) 得到 60 个长度为 768 的向量。使用 UMAP 将维度降到 2。将互为翻译的句子对用相同的颜色和代码标记,并在它们之间绘制虚线以更明显地显示它们的关联:
python
import matplotlib.pyplot as plt
import numpy as np
import umap
import pylab
X= umap.UMAP(n_components=2, random_state=42).fit_transform(emb)
idx= np.arange(len(emb))
fig, ax = plt.subplots(figsize=(12, 12))
ax.set_facecolor('whitesmoke')
cm = pylab.get_cmap("prism")
colors = list(cm(1.0*i/K) for i in range(K))
for i in idx:
if i<K:
ax.annotate("RUS-"+str(i), (X[i,0], X[i,1]), c=colors[i])
ax.plot((X[i,0], X[i+K,0]), (X[i,1], X[i+K,1]), "k:" )
else:
ax.annotate("EN-"+str(i%K), (X[i,0], X[i,1]), c=colors[i%K])输出结果如下所示,可以直观的看到跨语言文本相似性的分布情况:
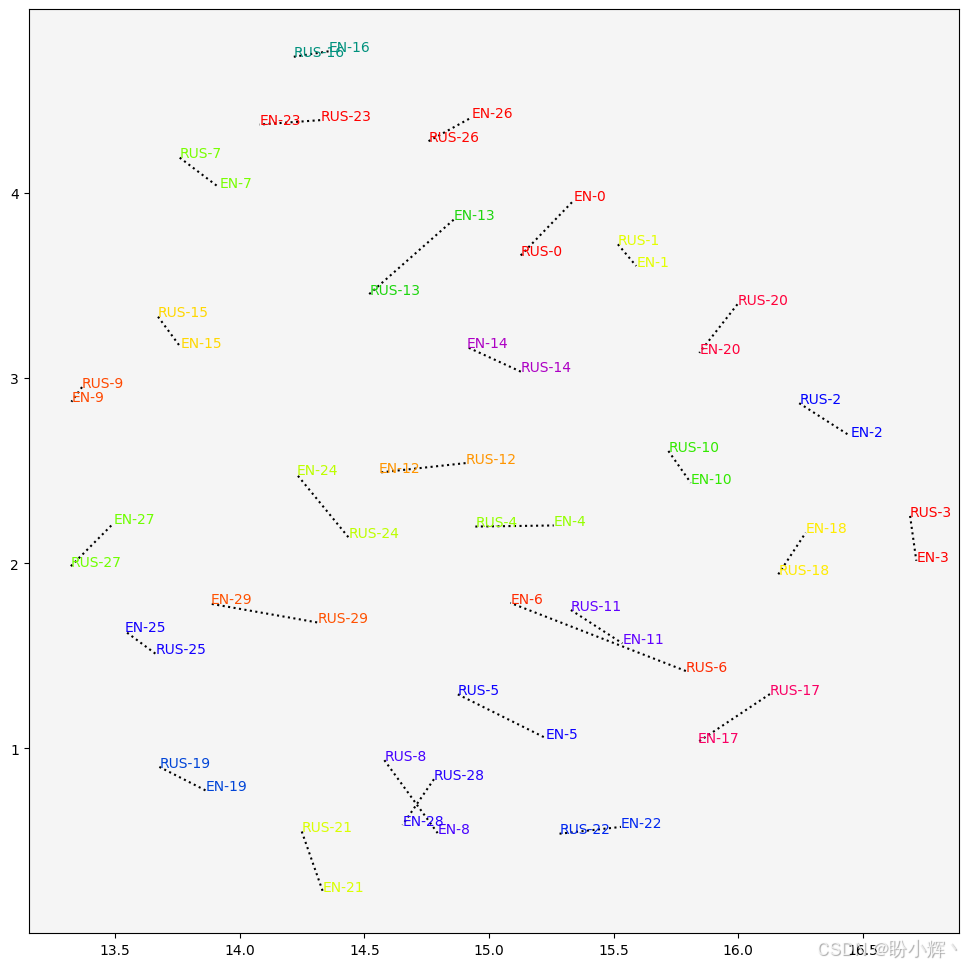
正如我们预期的,大多数句子对在向量空间中彼此靠近。但不可避免地,也存在某些句子对(例如编号为 ID 6 的句子对)相距较远的情况。
(5) 为了进行全面分析,接下来我们将对整个数据集进行测量。将对所有源句子和目标句子(共 1000 对)进行编码:
python
source_emb=model.encode(data["source_sentence"])
target_emb=model.encode(data["target_sentence"])(6) 计算所有句子对之间的余弦相似度,并将结果保存在 sims 变量中,然后绘制直方图:
python
from scipy import spatial
from matplotlib import pyplot
sims=[ 1 - spatial.distance.cosine(s,t) for s,t in zip(source_emb, target_emb)]
pyplot.hist(sims, bins=100, range=(0.8,1))
pyplot.show()输出结果如下所示:
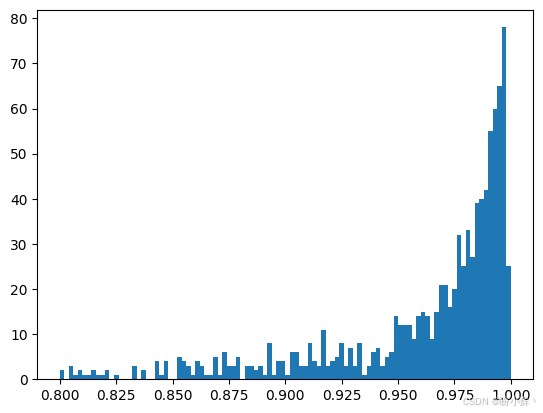
可以看到,相似度得分非常接近 1,这正是我们对一个优秀的跨语言模型的期望结果。查看所有相似度测量的均值和标准差,也可以看到跨语言模型的优异性能:
python
np.mean(sims), np.std(sims)
# (0.9464540109783411, 0.0825926376695912)可以运行相同的代码来测试其他语言,比如法语 (fra)、泰米尔语 (tam) 等。运行结果如下表所示,可以看到模型在多数语言中表现良好,但在某些语言中(如南非荷兰语或泰米尔语)则表现不佳:
| 语言 | 均值 | 标准差 |
|---|---|---|
| French (fra) | 0.94 | 0.087 |
| Afrikaans (afr) | 0.79 | 0.18 |
| Arabic (ara) | 0.94 | 0.08 |
| Korean (kor) | 0.92 | 0.11 |
| Tamil (tam) | 0.77 | 0.19 |
小结
跨语言模型能有效衡量不同语言文本的相似性,但性能受语言资源丰富度影响。实际应用中需结合任务需求选择模型,并通过阈值设定或后处理优化结果。本文介绍了跨语言模型在文本相似性计算中的应用,重点探讨了 XLM-R 和 LaBSE 两种模型的实际表现,并通过可视化分析验证了跨语言文本嵌入的有效性。
系列链接
Transformer实战(1)------词嵌入技术详解
Transformer实战(2)------循环神经网络详解
Transformer实战(3)------从词袋模型到Transformer:NLP技术演进
Transformer实战(4)------从零开始构建Transformer
Transformer实战(5)------Hugging Face环境配置与应用详解
Transformer实战(6)------Transformer模型性能评估
Transformer实战(7)------datasets库核心功能解析
Transformer实战(8)------BERT模型详解与实现
Transformer实战(9)------Transformer分词算法详解
Transformer实战(10)------生成式语言模型 (Generative Language Model, GLM)
Transformer实战(11)------从零开始构建GPT模型
Transformer实战(12)------基于Transformer的文本到文本模型
Transformer实战(13)------从零开始训练GPT-2语言模型
Transformer实战(14)------微调Transformer语言模型用于文本分类
Transformer实战(15)------使用PyTorch微调Transformer语言模型
Transformer实战(16)------微调Transformer语言模型用于多类别文本分类
Transformer实战(17)------微调Transformer语言模型进行多标签文本分类
Transformer实战(18)------微调Transformer语言模型进行回归分析
Transformer实战(19)------微调Transformer语言模型进行词元分类
Transformer实战(20)------微调Transformer语言模型进行问答任务
Transformer实战(21)------文本表示(Text Representation)
Transformer实战(22)------使用FLAIR进行语义相似性评估
Transformer实战(23)------使用SBERT进行文本聚类与语义搜索
Transformer实战(24)------通过数据增强提升Transformer模型性能
Transformer实战(25)------自动超参数优化提升Transformer模型性能
Transformer实战(26)------通过领域适应提升Transformer模型性能
Transformer实战(27)------参数高效微调(Parameter Efficient Fine-Tuning,PEFT)
Transformer实战(28)------使用 LoRA 高效微调 FLAN-T5
Transformer实战(29)------大语言模型(Large Language Model,LLM)
Transformer实战(30)------Transformer注意力机制可视化
Transformer实战(31)------解释Transformer模型决策
Transformer实战(32)------Transformer模型压缩
Transformer实战(33)------高效自注意力机制
Transformer实战(34)------多语言和跨语言Transformer模型