前言
大家好,今天程序员阿亮在整理简历的知识点的时候回忆了一下数据库更新时缓存保持一致性的策略!
在实践过程中,数据库与缓存之间的一致性问题是一个讨论了很久的课题,比较常见的做法,有先更数据库再删缓存、延迟双删、大厂常用的基于binlog监听的更新策略。
现在来给大家整理一波!

在分布式高并发系统中,引入 Redis 缓存是为了解决数据库(如 MySQL)的性能瓶颈。然而,"能力越大,责任越大",缓存的引入也带来了棘手的 数据一致性(Data Consistency) 问题。
当我们需要修改数据时,是先改数据库还是先删缓存?如何保证两者的一致性?
一、为什么要讨论"删除"而不是"更新"缓存?
在开始之前,我们需要达成一个共识:当数据变更时,我们通常选择"删除缓存",而不是"更新缓存"。
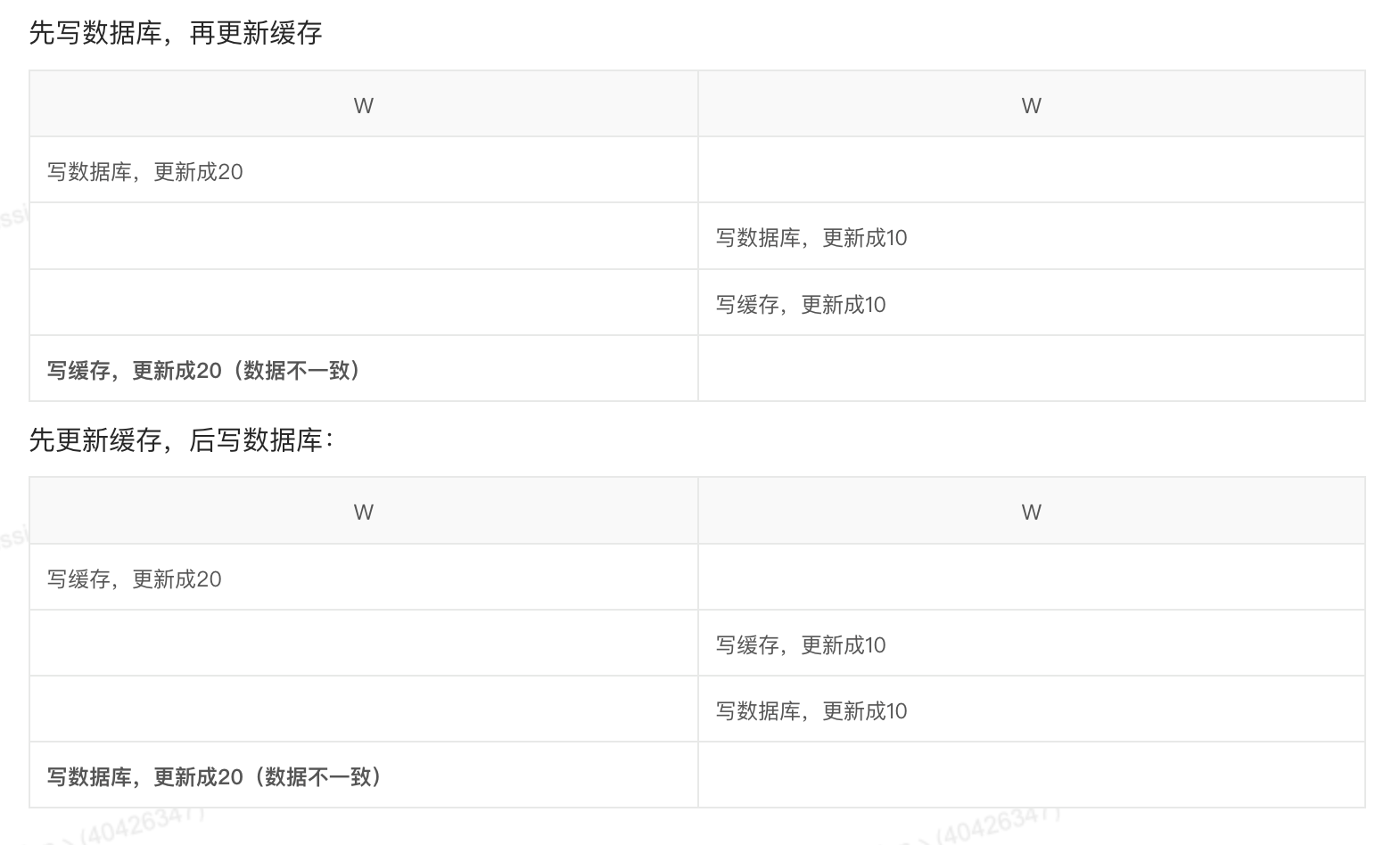
性能浪费: 如果你频繁更新数据库(写多读少),每次都去更新缓存,但这些缓存数据可能还没被读到就又被更新了,这是计算资源的浪费。
计算复杂: 有些缓存的值是经过复杂计算(如多表关联)得出的。直接更新缓存需要重复计算逻辑,而删除缓存是一种"懒加载"策略------等到下次读取时再计算并回填。
比如说,我们往Redis存一个对象,那么这个对象拿出来,需要解析成对象,又要修改,再转字符串,再存进去,那么,这样不仅费性能,又复杂。
所以业界一般都用删除缓存来代替,这样会有cachemiss问题嘛,但是也可以通过加锁解决。
还有就是我们的更新缓存在写写并发的情况下也会造成脏数据,如下图
因此,我们的讨论主要围绕 "删缓存" 和 "改数据库" 的顺序展开。
二、策略一:先删缓存,再更新数据库(危险!)
这是一个看似逻辑通顺,实则在 高并发场景下极其危险 的方案。
1. 流程
-
线程 A 删除 Redis 缓存。
-
线程 A 更新 MySQL 数据库。
2. 致命缺陷:高并发下的竞态条件
如果在这两步之间,有一个读请求进来,就会发生严重的 脏数据 问题。
场景复现:
-
线程 A(写):删除了缓存。
-
线程 B(读):此时进来查询,发现缓存缺失(Cache Miss)。
-
线程 B(读) :去读取 MySQL,注意!此时线程 A 还没来得及更新 MySQL,所以线程 B 读到的是"旧值"。
-
线程 B(读):将读到的"旧值"写入 Redis 缓存。
-
线程 A(写):终于完成了 MySQL 的更新(写入"新值")。
结果: MySQL 中是新值,Redis 中却是旧值。这个脏数据会一直存在,直到缓存自然过期。
所以结论就是很不建议使用先删缓存再更新数据库的策略,容易导致长时间的数据不一致问题!
三、 策略二:先更新数据库,再删除缓存 (Cache Aside Pattern)
这是业界最常用的标准方案,Facebook 等大厂均采用此策略。但它并非完美无缺。
1. 流程
-
线程 A 更新 MySQL 数据库。
-
线程 A 删除 Redis 缓存。
2. 问题一:原子性失败
如果第一步数据库更新成功了,但第二步 删除缓存失败(比如 Redis 抖动、网络超时),那么缓存里依然是旧数据。
- 后果: 用户读到脏数据。
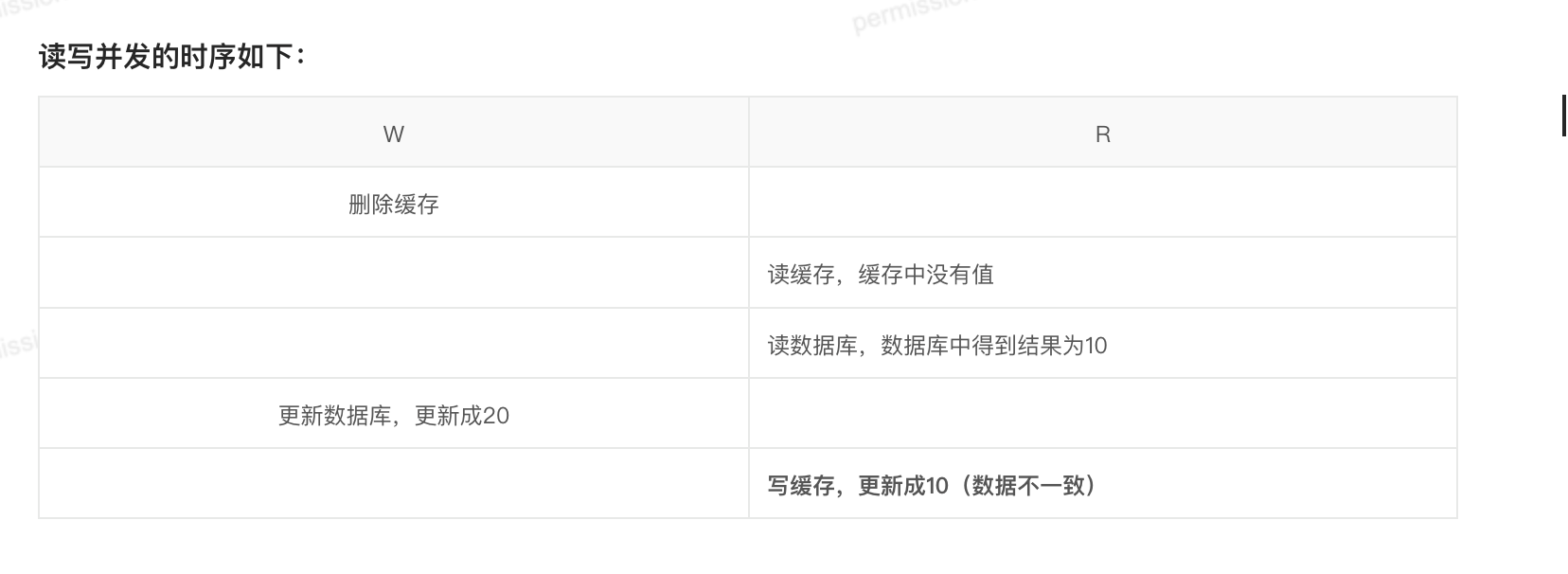
3. 问题二:高并发下的竞态条件(理论存在,实际罕见)
虽然这个概率极低,但在特定条件下依然会发生不一致。
场景复现: 前提:缓存刚好失效(Empty),且有一个读线程和一个写线程并发。
-
线程 A(读) :发现缓存没了,去读 MySQL,读到了 旧值。
-
线程 B(写) :在线程 A 写入缓存之前,抢先执行了 更新 MySQL 和 删除缓存(此时缓存本就是空的)。
-
线程 A(读) :拿着刚才读到的 旧值,写入了 Redis。
为什么说概率低? 这要求 "读数据库 + 写缓存" 的耗时 竟然比 "写数据库 + 删缓存" 的耗时还要长。在实际系统中,写数据库通常涉及锁和磁盘 IO,比读操作慢得多。因此,线程 A 通常在线程 B 更新完数据库之前就已经把缓存写好了,不会出现上述覆盖情况。
结论: 这是一个 99% 场景下可用的方案。为了解决剩下的 1%,我们需要引入更复杂的机制。
四、 进阶方案 A:延时双删 (Delayed Double Delete)
这是为了解决 "先删缓存,再更新数据库" 造成的脏数据问题,或者是为了给"先改库后删缓存"加一道保险。
1、大致思路就是:
java
public void update(String key, Object data) {
// 1. 先删除缓存
redis.del(key);
// 2. 更新数据库
db.update(data);
// 3. 休眠一段时间 (关键!)
Thread.sleep(N);
// 4. 再次删除缓存
redis.del(key);
}2. 为什么要删两次?
-
第一次删除: 是为了快速清除旧数据,让后续进来的请求去读库(虽然可能读到旧的,但目的是尽快让系统感知变化)。
-
第二次删除: 这是一个"兜底"操作。目的是清除在"步骤 2(更新数据库)"执行期间,被其他并发读请求错误写入缓存的 旧值。
3. 为什么要 Sleep(延迟)?延迟多久?
这是整个方案的灵魂所在。
-
意义: 你必须确保 第二次删除 发生在 并发的读请求完成其"写入缓存"操作 之后。
-
如果我不 Sleep 直接删:
-
线程 A(写):改库 -> 删缓存 -> 再次删缓存(太快了)。
-
线程 B(读):读旧库 -> (网络卡顿) -> 写入缓存(此时 A 已经删完两次了)。
-
结果:缓存里还是旧值。
-
-
时长设定: 需要大于"主从同步延迟" + "读请求处理逻辑耗时"。通常建议 500ms 左右,具体需根据业务监控调整。
4. 缺点
-
性能损耗: 线程需要 Sleep,导致吞吐量降低。
-
复杂度: 无法精确把控 Sleep 的时间。
五、 进阶方案 B:订阅 Binlog 异步删除 (最终一致性)
这是目前互联网大厂(如阿里、美团)最推崇的方案,彻底将应用逻辑与缓存一致性逻辑解耦。
1. 架构原理
应用程序只负责更新数据库,不再去管删除缓存的事。 通过一个中间件(如阿里的 Canal )伪装成 MySQL 的 Slave 节点,监听 MySQL 的 Binlog(二进制日志)。
2. 详细流程
-
应用层: 用户更新 MySQL,事务提交,写入 Binlog。
-
中间件(Canal): 实时订阅并解析 Binlog,检测到数据变更。
-
消息队列(Kafka/RabbitMQ): Canal 将变更消息推送到 MQ(保证消息的可靠性和顺序性)。
-
消费者: 专门的消费者程序从 MQ 获取消息,解析出 Key,执行
redis.del(key)。
3. 为什么这是最优解?
-
解耦: 业务代码不需要关心缓存,只管写库。
-
可靠性(重试机制): 如果删除缓存失败(Redis 挂了),消息队列会不断重试,或者记录死信队列后续处理,保证了 "最终一致性"。
-
无竞态条件: 所有的数据库变更都按顺序流转到 MQ 中,串行执行删除,避免了并发覆盖问题。
六、 总结
| 方案 | 流程 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 先删缓存后改库 | 删 -> 改 | 无 | 极大概率出现脏数据 | 不推荐 |
| 先改库后删缓存 | 改 -> 删 | 实现简单,大厂标准 | 极端情况下有脏数据;删除失败需兜底 | 中小型项目、非强一致性业务 |
| 延时双删 | 删 -> 改 -> 停 -> 删 | 极大降低脏数据概率 | 吞吐量降低,Sleep 时间难把控 | 并发较高,但不想引入复杂架构 |
| 订阅 Binlog | 改库 -> 异步删 | 解耦、高可靠、最终一致 | 架构复杂,引入中间件维护成本 | 大型系统、核心业务、数据一致性要求高 |
