一、逻辑回归基础:从线性回归到分类
1. 与线性回归的本质区别
线性回归的核心是在N维空间中寻找线性函数(如y=kx+b)拟合连续型标签数据,其输出是无限区间的连续值。
逻辑回归的巧妙之处在于:将线性回归的输出通过Sigmoid函数映射到0,1区间,从而将连续值转换为概率,实现分类任务。
2. 核心工具:Sigmoid函数
Sigmoid函数是逻辑回归的灵魂,其公式与特性如下: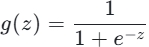
-
输出:hθ(x)=
θ^T x -
核心作用:将线性回归结果压缩为概率值,以0.5为默认阈值:
-
当
g(z) > 0.5时,预测为正类(y=1) -
当
g(z) < 0.5时,预测为负类(y=0)
-
3. 数学建模:从概率到目标函数
逻辑回归的核心是通过数据找到最优参数θ,步骤如下:
-
线性组合 :计算输入特征的线性回归结果
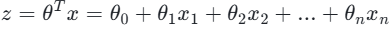
-
概率转换 :通过Sigmoid函数得到正类概率
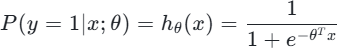 ,负类概率
,负类概率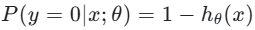
-
目标函数:为了找到θ,我们构建对数似然函数(即最小化损失函数):
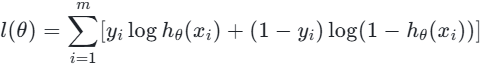
转换为损失函数(交叉熵损失):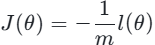
损失函数的意义:衡量预测概率与真实标签的偏差,J(θ)越小,模型拟合效果越好。
二、模型训练全流程:从数据预处理到参数优化
1. 数据预处理:为训练铺路
**数据标准化:**逻辑回归依赖梯度下降优化,特征差异会导致参数更新失衡,因此必须标准化:
- 0~1标准化(离差标准化):将特征映射到0,1区间,公式:
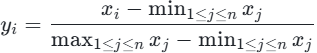
- Z标准化 (标准差标准化):基于均值和标准差转换,公式:
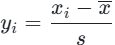
其中x̄是均值,s是标准差,适用于特征分布接近正态的场景。
2. 参数求解:梯度下降法
逻辑回归的目标是最小化损失函数J(θ),最常用的优化方法是梯度下降法,步骤如下:
-
计算偏导数 :对损失函数
J(θ)求偏导,得到参数更新的方向: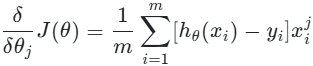
-
参数更新 :沿梯度负方向迭代更新
θ,直到收敛(损失函数变化小于阈值tol):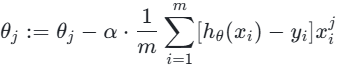
其中α是学习率(控制步长,过大易震荡,过小收敛慢)。
3. 正则化:防止过拟合
过拟合是模型训练的常见问题------训练集表现优异,测试集性能暴跌,原因是模型参数过于复杂。逻辑回归通过正则化约束参数,核心是在损失函数中加入惩罚项:
(1)正则化类型(penalty参数)
-
L2正则化 (默认):惩罚项为**
(1/2)θ²** -
L1正则化 :惩罚项为**
|θ|**
(2)正则化强度(C参数)
C是正则化系数λ的倒数,C越小,正则化越强(参数约束越严格),可通过交叉验证调整。
三、模型评价:不止于准确率
模型训练完成后,需通过科学的评价指标评估性能,避免单一指标误导。核心基于混淆矩阵,衍生出多个关键指标。
1. 混淆矩阵:评价的基础
混淆矩阵展示模型预测结果与真实标签的对应关系,以二分类为例(真实值1=患病,0=健康):
|-----------|-----------|-----------|
| | 预测值=1(患病) | 预测值=0(健康) |
| 真实值=1(患病) | TP(真阳性)=5 | FN(假阴性)=2 |
| 真实值=0(健康) | FP(假阳性)=4 | TN(真阴性)=4 |
-
TP:真实患病,预测正确;
-
FN:真实患病,预测错误(漏诊);
-
FP:真实健康,预测错误(误诊);
-
TN:真实健康,预测正确。
2. 核心评价指标
(1)准确率(Accuracy)
-
公式:
Accuracy = (TP + TN) / (TP + TN + FP + FN) -
意义:整体预测正确的比例,适用于样本平衡场景。
-
示例计算:
(5+4)/(5+2+4+4) = 9/15 = 60%。
(2)精确率(Precision)
-
公式:
Precision = TP / (TP + FP) -
意义:预测为正类的样本中,真实正类的比例(精准度),适用于重视"误诊成本"的场景(如垃圾邮件识别,避免正常邮件被误判)。
-
示例计算:
5/(5+4) ≈ 55.6%。
(3)召回率(Recall/Sensitivity)
-
公式:
Recall = TP / (TP + FN) -
意义:真实正类中,被正确预测的比例(覆盖率),适用于重视"漏诊成本"的场景(如疾病诊断,避免漏诊患者)。
-
示例计算:
5/(5+2) ≈ 71.4%。
(4)F1-score
-
公式:
F1 = 2 * (Precision * Recall) / (Precision + Recall) -
意义:精确率和召回率的调和平均,平衡两者矛盾,适用于样本不平衡场景。
-
示例计算:
2*(0.556*0.714)/(0.556+0.714) ≈ 62.5%。
3. 交叉验证:更可靠的性能评估
单一的训练集-测试集划分可能因数据分布不均导致评价偏差,K折交叉验证是解决方案:
-
将数据集分为K份(常用K=5或10);
-
每次用K-1份作为训练集,1份作为测试集;
-
重复K次,取K次评价指标的平均值作为最终性能。
- 优势:充分利用数据,避免过拟合对评价的影响,结果更稳健。
四、实战注意事项:参数调优与问题排查
1. 关键参数调优(sklearn)
|--------------|--------|----------------------------|
| 参数 | 作用 | 推荐取值 |
| penalty | 正则化类型 | 默认L2,高维数据用L1 |
| C | 正则化强度 | 0.01~100,通过交叉验证选择 |
| solver | 优化算法 | 小数据集liblinear,大数据集sag/saga |
| multi_class | 多分类方式 | 二分类用ovr,多分类用multinomial |
| class_weight | 类别权重 | 样本不平衡用balanced |
| max_iter | 最大迭代次数 | 数据复杂时增大(如500、1000) |
2. 常见问题与解决方案
-
欠拟合:模型训练不充分,训练集和测试集性能都差。
-
原因:特征过少、模型参数简单。
-
解决:增加有效特征、降低正则化强度(增大C)。
-
-
过拟合:训练集性能好,测试集性能差。
-
原因:参数复杂、特征冗余。
-
解决:增加正则化强度(减小C)、使用L1正则化筛选特征、增加训练数据。
-
-
模型不收敛:迭代次数用尽仍未达到收敛条件。
- 解决:增大max_iter、调整学习率α、数据标准化。