
引言:
在Redis中,哈希结构还有一层更深的意义,跟我们习以为常的key-value的哈希结构有所不同的是,还有一层更深的意义,我们由此来引入filed这个概念~
Redis 自身已经是键值对结构了
Redis 自身的键值对就是通过 哈希 的方式来组织的.
把 key 这一层组织完成之后, 到了 value 这一层~~ value 的其中一种类型还可以再是哈希!
形如 key="key",value={{field1, value1},..., {fieldN,valueN }},Redis 键值对和哈希类型二者的关系可以用下图表示。
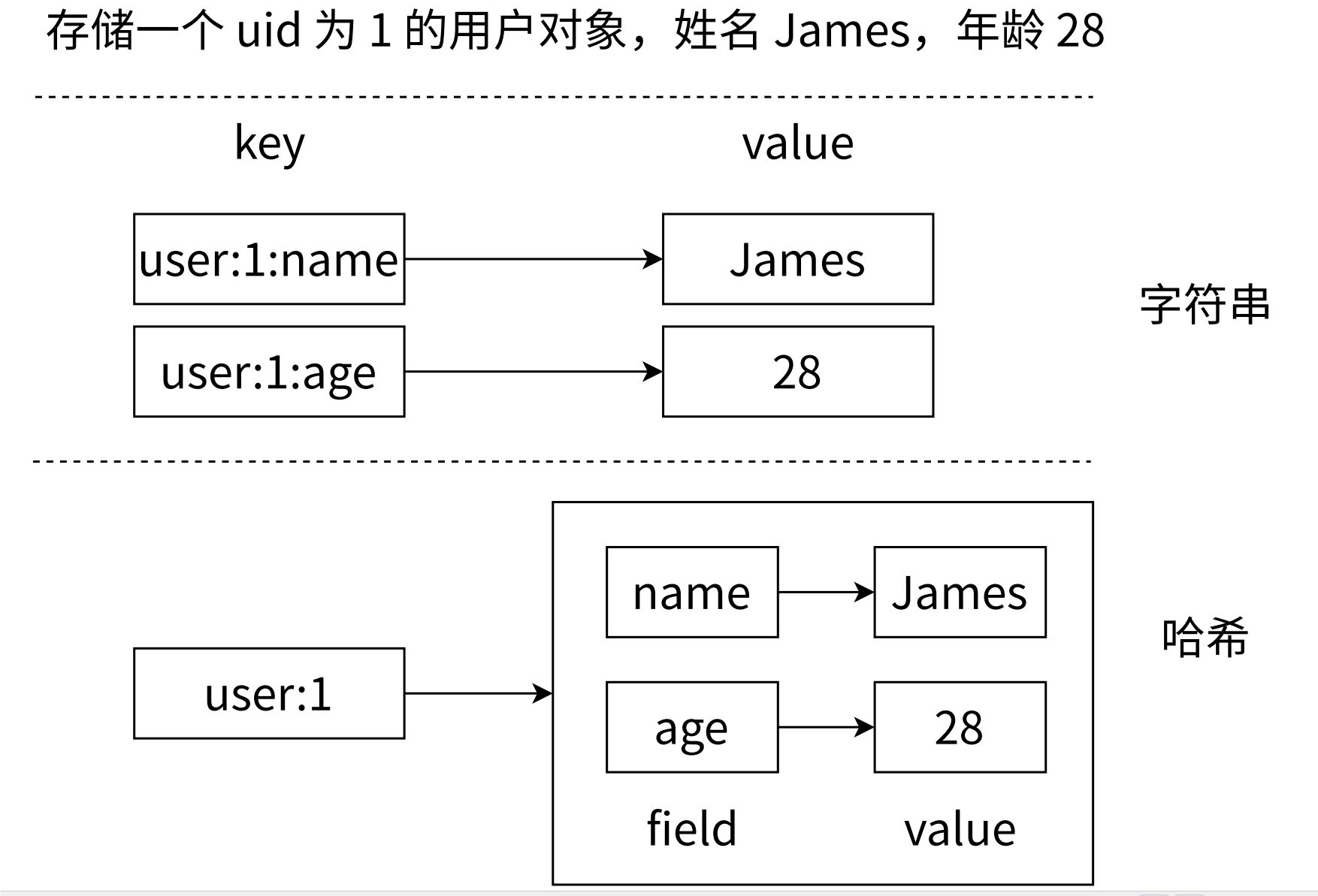
field-value和key-value的深层次解析:
在Redis中,field-value和key-value是层级嵌套关系 ,其中key是全局唯一标识符,指向一个哈希(Hash)结构;而field是该哈希内部的字段名,与对应的value组成键值对,存储在哈希中。以下是具体分析:
1. 层级关系:全局Key → 哈希结构 → 多个Field-Value
- 全局Key :Redis中的每个数据对象(如字符串、列表、哈希等)都通过唯一的
key标识。例如,user:1001可能是一个全局Key,指向某个用户的数据。 - 哈希结构 :当全局Key对应的数据类型是哈希(Hash)时,其值是一个字段-值对的集合。例如,
user:1001可能存储为一个哈希,包含用户的多个属性。 - Field-Value :哈希内部的每个属性由
field(字段名)和value(字段值)组成。例如,name: "Alice"、age: 30等。
2. Field的定义与作用
- Field的本质:Field是哈希内部的键(局部键),用于区分哈希中的不同属性。它类似于编程语言中的对象属性名或数据库表中的列名。
- 为什么需要Field :
- 结构化存储 :Field允许将多个相关属性组织在一个哈希中,避免为每个属性创建单独的全局Key(如
user:1001:name、user:1001:age),从而减少Key数量,提升管理效率。 - 原子性操作 :Redis支持对哈希的单个Field进行原子操作(如
HINCRBY递增数值),无需锁定整个哈希或全局Key,适合高并发场景。 - 内存优化:哈希在存储多个小字段时比单独的字符串更节省内存,尤其是当字段数量较多时。
- 结构化存储 :Field允许将多个相关属性组织在一个哈希中,避免为每个属性创建单独的全局Key(如
3. 示例说明
假设需要存储用户信息:
-
无Field的设计 :
`Key: user:1001:name, Value: "Alice" Key: user:1001:age, Value: 30 `- 缺点:Key数量多,管理复杂;修改年龄需操作独立Key,无法保证原子性。
-
有Field的设计(使用哈希) :
`Key: user:1001 Field: name, Value: "Alice" Field: age, Value: 30 `- 优点:Key数量少;可通过
HSET user:1001 age 31原子性更新年龄;内存占用更低。
- 优点:Key数量少;可通过
4. 核心区别总结
| 特性 | Key-Value(全局) | Field-Value(哈希内部) |
|---|---|---|
| 作用域 | 整个Redis数据库 | 单个哈希结构内部 |
| 唯一性 | 全局唯一 | 在哈希内唯一 |
| 典型操作 | GET key、SET key value |
HGET key field、HSET key field value |
| 设计目的 | 标识数据对象 | 描述对象属性 |
5. 适用场景
- 使用Field-Value(哈希) :
- 存储对象(如用户、商品、订单)。
- 需要原子性更新部分属性。
- 字段数量较多且需节省内存。
- 使用Key-Value(字符串) :
- 存储简单数据(如配置项、计数器)。
- 需要独立生命周期或全局唯一标识的场景。
为什么filed-value是原子性的,而key-value不是原子性的
在Redis中,field-value(哈希内部的字段值)的原子性操作是相对于哈希结构而言的 ,而key-value(全局键值对)的原子性操作是针对整个键的。两者的原子性范围不同,导致它们的特性有所差异。以下是具体分析:
1. 原子性的定义
- 原子性 :指一个操作要么完全执行,要么完全不执行,中间不会因其他操作或故障而中断。在Redis中,原子性通常由单命令保证(如
SET、HSET、INCR等)。
2. 为什么 field-value 是原子性的?
(1)哈希结构的原子性操作
Redis为哈希(Hash)提供了针对单个字段的原子操作命令,例如:
HSET key field value:设置字段值。HGET key field:获取字段值。HINCRBY key field increment:原子性递增字段的数值。HDEL key field:删除字段。
这些命令直接操作哈希中的某个字段,Redis保证它们的执行是原子的。例如:
bash
`HINCRBY user:1001 age 1 # 原子性将age字段的值+1
`即使多个客户端同时执行此命令,Redis也会通过内部锁机制确保最终结果正确(如age从30变为31,不会出现中间状态)。
(2)原子性范围
- 哈希的原子性仅限于单个字段 :如果需要同时修改多个字段(如
name和age),必须使用HMSET或事务(MULTI/EXEC),此时原子性扩展到整个命令或事务。 - 哈希本身不是全局原子性的 :如果其他客户端修改了哈希的其他字段(如
email),不会影响当前字段的操作。
3. 为什么 key-value(字符串)的原子性表现不同?
(1)字符串的原子性操作
Redis对字符串(String)也提供原子操作,例如:
SET key value:设置键值。GET key:获取键值。INCR key:原子性递增数值。DECR key:原子性递减数值。
这些命令直接操作整个键,原子性范围是全局的。例如:
bash
`INCR counter # 原子性将counter的值+1
`(2)关键区别:操作范围
- 字符串的原子性是全局的 :操作
counter时,其他客户端无法同时修改它,直到当前操作完成。 - 哈希的原子性是局部的 :操作
user:1001:age时,其他客户端可以同时修改user:1001:name,两者互不干扰。
(3)误解澄清:key-value 本身也是原子性的
- 字符串的
SET/GET等操作本身就是原子性的 ,但问题可能源于以下场景:- 复合操作非原子性 :如果需要先
GET再SET(如value = GET key; SET key value+1),这不是原子性的 ,需改用INCR。 - 与哈希的对比:哈希的原子性是针对字段的,而字符串的原子性是针对键的。如果比较的是"修改哈希的多个字段" vs "修改字符串的单个键",前者需要事务,后者天然原子。
- 复合操作非原子性 :如果需要先
命令篇
注意H系列的命令必须要保证key对应的value是哈希类型的!!!
HSET:
设置hash中指定的字段(field)的值(value)。
HSET key field value field value ...
时间复杂度:插入一组field为O(1),插入N组field为O(N)
返回值:添加的字段的个数。
示例:
bash
redis> HSET myhash field1 "Hello"
(integer) 1
redis> HGET myhash field1
"Hello"HGET
获取hash中指定字段的值
HGET key field
时间复杂度O(1)
返回值:字段对应的值或者nil
示例:
bash
redis> HSET myhash field1 "foo"
(integer) 1
redis> HGET myhash field1
"foo"
redis> HGET myhash field2
(nil)HEXIST
判断hash中是否有指定的字段hash
HEXISTS key field
时间复杂度:0(1)
返回值:1表示存在,0表示不存在。
示例:
bash
redis> HSET myhash field1 "foo"
(integer) 1
redis> HEXISTS myhash field1
(integer) 1
redis> HEXISTS myhash field2
(integer) 0HDEL
删除哈希中指定的字段
HDEL key field field ...
时间复杂度:删除一个元素为 O(1).删除 N 个元素为 O(N).
返回值:本次操作删除的字段个数。
示例:
bash
redis> HSET myhash field1 "foo"
(integer) 1
redis> HDEL myhash field1
(integer) 1
redis> HDEL myhash field2
(integer) 0HKEYS
获取hash中所有的字段
HKEYS key
时间复杂度:O(N),N为field 的个数
返回值:字段列表。
示例:
bash
redis> HSET myhash field1 "Hello"
(integer) 1
redis> HSET myhash field2 "World"
(integer) 1
redis> HKEYS myhash
1) "field1"
2) "field2"注意!!!这个操作也是存在一定的风险的!!!类似于之前介绍过的 keys
主要是咱们也不知道某个 hash 中是否会存在大量的field~
HVALS
获取hash中的所有的值
语法:
HVALS key
时间复杂度:O(N),N为field 的个数
返回值:所有的值。
示例:
bash
redis> HSET myhash field1 "Hello"
(integer) 1
redis> HSET myhash field2 "World"
(integer) 1
redis> HVALS myhash
1) "Hello"
2) "World"注意如果哈希非常大,这个操作就可能导致redis服务器被阻塞。
HGETALL
获取hash中所有字段以及对应的值
HGETALL key
时间复杂度:O(N),N为field 的个数
返回值:字段和对应的值。
示例:
bash
redis> HSET myhash field1 "Hello"
(integer) 1
redis> HSET myhash field2 "World"
(integer) 1
redis> HGETALL myhash
1) "field1"
2) "Hello"
3) "field2"
4) "World"HMGET
一次获取hash中多个字段的值
bash
HMGET key field [field ...]时间复杂度:只查询一个元素为 0(1),查询多个元素为 O(N),N 为查询元素个数.
返回值:字段对应的值或者 nil。
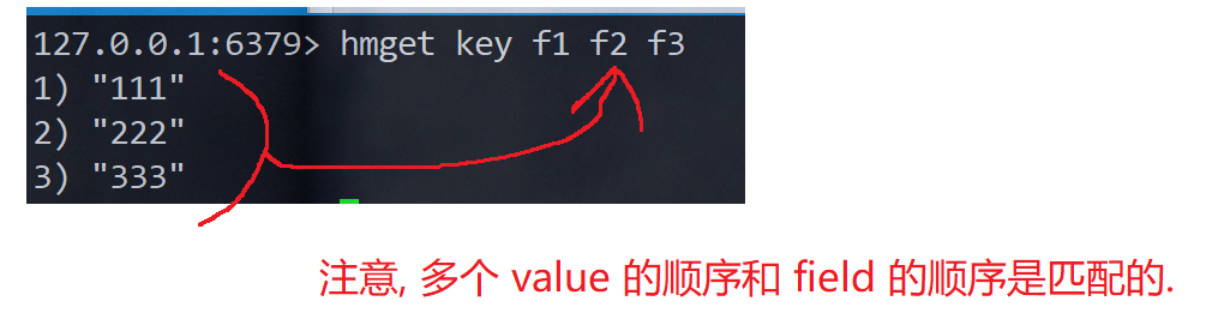
bash
redis> HSET myhash field1 "Hello"(integer) 1
redis> HSET myhash field2 "World"
(integer) 1
redis> HMGET myhash field1 field2 nofield
1) "Hello"
2) "World"
3) (nil)小总结:
上述hkeys、hvals、hgetall都是存在一定风险的(一条命令,就能完成所有的遍历操作)。hash的元素个数太多,执行的耗时会比较长,从而阻塞Redis
在使用 HGETALL时,如果哈希元素个数比较多,会存在阻塞 Redis 的可能。如果开发人员只需要获取部分 field,可以使用 HMGET,如果一定要获取全部 field,可以尝试使用 HSCAN命令,该命令采用渐进式遍历哈希类型~
HSCAN的思想:
敲一次命令,遍历一小部分,
再敲一次,再遍历一小部分
化整为零
连续执行多次,就可以完成整个的遍历过程了
哈希内部编码
在Redis中,哈希(Hash)类型的内部编码主要有 ziplist(压缩列表) 和 hashtable(哈希表) 两种,在Redis 7.0及以后版本中,ziplist被listpack(紧凑列表)替代,但核心设计思想类似。以下是具体说明:
1. ziplist(压缩列表)
-
适用场景:当哈希的元素数量较少且单个元素较小时,Redis会使用ziplist作为内部编码。
-
触发条件 :
- 元素数量小于
hash-max-ziplist-entries(默认512个)。 - 所有元素的值大小均小于
hash-max-ziplist-value(默认64字节)。
- 元素数量小于
-
特点 :
- 内存紧凑:ziplist通过连续内存存储多个字段和值,减少指针开销,节省内存。
- 顺序存储:字段和值按插入顺序连续存储,适合小规模数据。
- 性能权衡:当元素数量或大小超过阈值时,读写效率会下降(需扩容或遍历)。
-
示例 :
bash`127.0.0.1:6379> HMSET user:1 name "Alice" age 30 OK 127.0.0.1:6379> OBJECT ENCODING user:1 "ziplist" `
2. hashtable(哈希表)
-
适用场景:当哈希的元素数量较多或单个元素较大时,Redis会切换到hashtable作为内部编码。
-
触发条件 :
- 元素数量超过
hash-max-ziplist-entries。 - 任意元素的值大小超过
hash-max-ziplist-value。
- 元素数量超过
-
特点 :
- O(1)时间复杂度:哈希表通过哈希函数直接定位字段,读写效率高。
- 内存开销较大:需维护哈希表结构(如数组、链表或红黑树),指针开销较高。
- 动态扩容:当负载因子超过阈值时,哈希表会自动扩容(rehash)。
-
示例 :
bash`127.0.0.1:6379> HSET user:2 info "This is a long string that exceeds 64 bytes..." OK 127.0.0.1:6379> OBJECT ENCODING user:2 "hashtable" `
3. listpack(紧凑列表,Redis 7.0+)
- 背景:ziplist在极端情况下(如连续更新大元素)可能引发"连锁更新"问题,导致性能抖动。Redis 7.0引入listpack替代ziplist,优化内存布局和更新效率。
- 特点 :
- 内存更高效:通过改进节点编码(如前驱节点长度存储优化),减少内存碎片。
- 避免连锁更新:节点长度变更时,仅影响相邻节点,而非整个列表。
- 兼容性:与ziplist的API兼容,无需修改上层命令。
内部编码转换规则
- 单向性:编码转换仅从小内存编码(如ziplist/listpack)向大内存编码(如hashtable)进行,不可逆。
- 动态调整:Redis根据配置参数和实际数据量自动选择编码,无需手动干预。
配置参数优化
可通过修改Redis配置文件(redis.conf)或运行时使用CONFIG SET命令调整哈希的内部编码行为:
bash
`# 调整ziplist/listpack的最大元素数量(默认512)
hash-max-ziplist-entries 1024
# 调整ziplist/listpack中单个元素的最大值大小(默认64字节)
hash-max-ziplist-value 128
`应用场景建议
- 使用ziplist/listpack:存储字段数量少、值较小的哈希(如用户基本信息、配置项)。
- 使用hashtable:存储字段数量多或值较大的哈希(如商品详情、日志数据)。
缓存方式对比:
原生字符串类型------使用字符串类型,每个属性一个键。
bash
set user:1:name James
set user:1:age 23
set user:1:city Beijing优点:实现简单,针对个别属性变更也很灵活。
缺点:占用过多的键,内存占用量较大,同时用户信息在 Redis 中比较分散,缺少内聚性,所以这种方案基本没有实用性。
序列化字符串类型,例如 JSON 格式
bash
set user:1 经过序列化后的⽤⼾对象字符串优点:针对总是以整体作为操作的信息比较合适,编程也简单。同时,如果序列化方案选择合适,内存的使用效率很高。
缺点:本身序列化和反序列需要一定开销,同时如果总是操作个别属性则非常不灵活。
哈希类型:
优点:简单、直观、灵活。尤其是针对信息的局部变更或者获取操作。
缺点:需要控制哈希在 ziplist 和 hashtable 两种内部编码的转换,可能会造成内存的较大消耗。
哈希的两种编码为什么需要自动转换?
Redis 根据哈希的 字段数量 和 字段值大小 动态选择内部编码,目的是:
(1)避免极端情况下的性能或内存问题
- 如果始终用 ziplist :
当哈希字段数量或值过大时,ziplist 的插入/删除操作会变得非常低效(需频繁移动内存),甚至可能引发内存碎片或 OOM(内存不足)。 - 如果始终用 hashtable :
对小数据使用 hashtable 会浪费内存(指针开销占比高),且哈希表的初始化成本高于 ziplist。
(2)适应不同业务场景的需求
- 读多写少的小数据 :
ziplist 的内存优势更明显,适合配置类、缓存类数据。 - 高并发写或大数据 :
hashtable 的 O(1) 操作效率更关键,适合热点数据或频繁更新的场景。