在自然语言处理(NLP)入门阶段,如何把文本变成"模型能理解的数字",往往是第一个真正的门槛。
本文将通过一个完整的实战案例,带你从原始文本出发,使用 Word2Vec 构建词向量表示,并结合逻辑回归(Logistic Regression),完成 IMDB 电影评论的情感分类任务。
整个流程覆盖了从数据预处理到模型评估的完整闭环,适合作为 NLP 特征工程与传统机器学习结合的经典示例。
一、项目背景与任务定义
1.1 任务目标
基于 IMDB 电影评论数据集,判断一条评论的情感倾向:
-
1:正面(positive) -
0:负面(negative)这是一个标准的 二分类文本情感分析问题。
1.2 技术方案选择
本文采用的整体技术路线如下:
- 使用 NLTK 进行文本分词与停用词过滤
- 使用 Gensim 训练 Word2Vec 模型,将词映射为稠密向量
- 通过词向量平均的方式,将句子转换为固定长度向量
- 使用 逻辑回归 完成情感二分类
- 为什么选择这个组合?下面做一个简单对比:
| 方法 | 优点 | 缺点 |
|---|---|---|
| TF-IDF + 逻辑回归 | 实现简单、可解释性强 | 无法建模词语语义相似性 |
| Word2Vec + 逻辑回归 | 能捕捉语义关系,泛化能力好 | 平均操作会丢失词序信息 |
| BERT + 微调 | 效果最好 | 计算资源消耗大,工程复杂 |
Word2Vec + 逻辑回归 在效果与成本之间取得了不错的平衡,是非常经典、也非常适合入门理解的 NLP 实战方案。
二、环境准备
2.1 依赖安装
python
pip install numpy pandas tqdm nltk gensim scikit-learn2.2 NLTK 数据下载
首次运行需要下载分词器与停用词表:
import nltk
nltk.download("punkt")
nltk.download("stopwords")三、数据集说明
本项目使用 Stanford 提供的 IMDB Movie Review Dataset ( IMDB 电影评论数据集),共包含 50,000 条影评,正负样本各占一半。
- 数据格式(CSV):
| 字段 | 说明 |
|---|---|
text |
评论文本 |
label |
情感标签(1=正面,0=负面) |
-
数据划分:
data/
└── imdb/
├── imdb_train.csv # 25,000 条训练样本
└── imdb_test.csv # 25,000 条测试样本
四、项目结构
bash
Word2Vec/
├── data/
│ └── imdb/
│ ├── imdb_train.csv
│ └── imdb_test.csv
├── models/ # 训练好的模型
├── src/
│ └── imdb_word2vec.py # 主程序
└── docs/
└── IMDB 情感分类实战.md 这种结构便于 数据、代码和文档解耦,也更符合真实工程实践。
五、核心代码解析
5.1 数据加载
python
def load_data(train_path: str, test_path: str):
"""加载训练集与测试集"""
train_df = pd.read_csv(train_path)
test_df = pd.read_csv(test_path)
return train_df, test_df 逻辑非常直接:分别读取训练集和测试集,返回 DataFrame 供后续处理。
5.2 文本预处理(分词 + 去停用词)
文本预处理是 NLP 的第一步,其目标是降低噪声、统一输入形式。
python
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
stop_words = set(stopwords.words("english"))
def tokenize_text(text_series):
return text_series.progress_apply(
lambda x: [
word for word in word_tokenize(x.lower())
if word not in stop_words
]
)-
示例:
输入: "This movie is great! I really enjoyed it."
输出: ['movie', 'great', '!', 'really', 'enjoyed', '.'] -
说明:
- 全部转为小写,减少词表规模
- 去除停用词(the / is / a 等)以降低无信息噪声
5.3 训练 Word2Vec 模型
python
def train_word2vec_model(
tokens,
vector_size=100,
window=5,
min_count=5,
sg=1,
workers=4,
epochs=5
):
model = Word2Vec(
sentences=tokens,
vector_size=vector_size,
window=window,
min_count=min_count,
sg=sg,
workers=workers,
epochs=epochs
)
return model- 本实验中使用的关键参数如下:
| 参数 | 值 | 说明 |
|---|---|---|
vector_size |
300 | 较高维度,捕捉更多语义信息 |
window |
5 | 标准窗口大小 |
min_count |
40 | 过滤低频词,IMDB 语料较大,阈值可设高一些 |
sg |
1 | 使用 Skip-gram 算法 |
epochs |
5 | 训练轮数 |
5.4 句子向量化方法
Word2Vec 只能生成词向量 ,但分类器需要的是句子级特征。
最简单、也最常用的方法是 词向量平均 :
s ⃗ = 1 n ∑ i = 1 n w i ⃗ \vec{s} = \frac{1}{n} \sum_{i=1}^{n} \vec{w_i} s =n1i=1∑nwi
python
def sentence_to_vec(tokens, model, vector_size=100):
"""将句子转换为词向量的平均值"""
vecs = [model.wv[word] for word in tokens if word in model.wv]
if len(vecs) == 0:
return np.zeros(vector_size) # 处理全部 OOV 的情况
return np.mean(vecs, axis=0)-
其中,
w2v_model.wv返回的是一个KeyedVectors对象,它只负责"词 → 向量"的查询与相似度计算,不包含训练相关内容。 -
注意:
- 该方法会丢失词序信息,因此表达能力有限,但胜在简单、稳定、易解释。
- "我喜欢你"和"你喜欢我"的向量相同。
- 更好的方法包括 TF-IDF 加权平均、Doc2Vec、或使用 RNN/Transformer。
5.5 embedding映射:构建特征矩阵
这一步是连接 Word2Vec 和分类器的关键桥梁---将所有文本转换为统一格式的特征矩阵,供机器学习模型使用。
(1) 整体流程
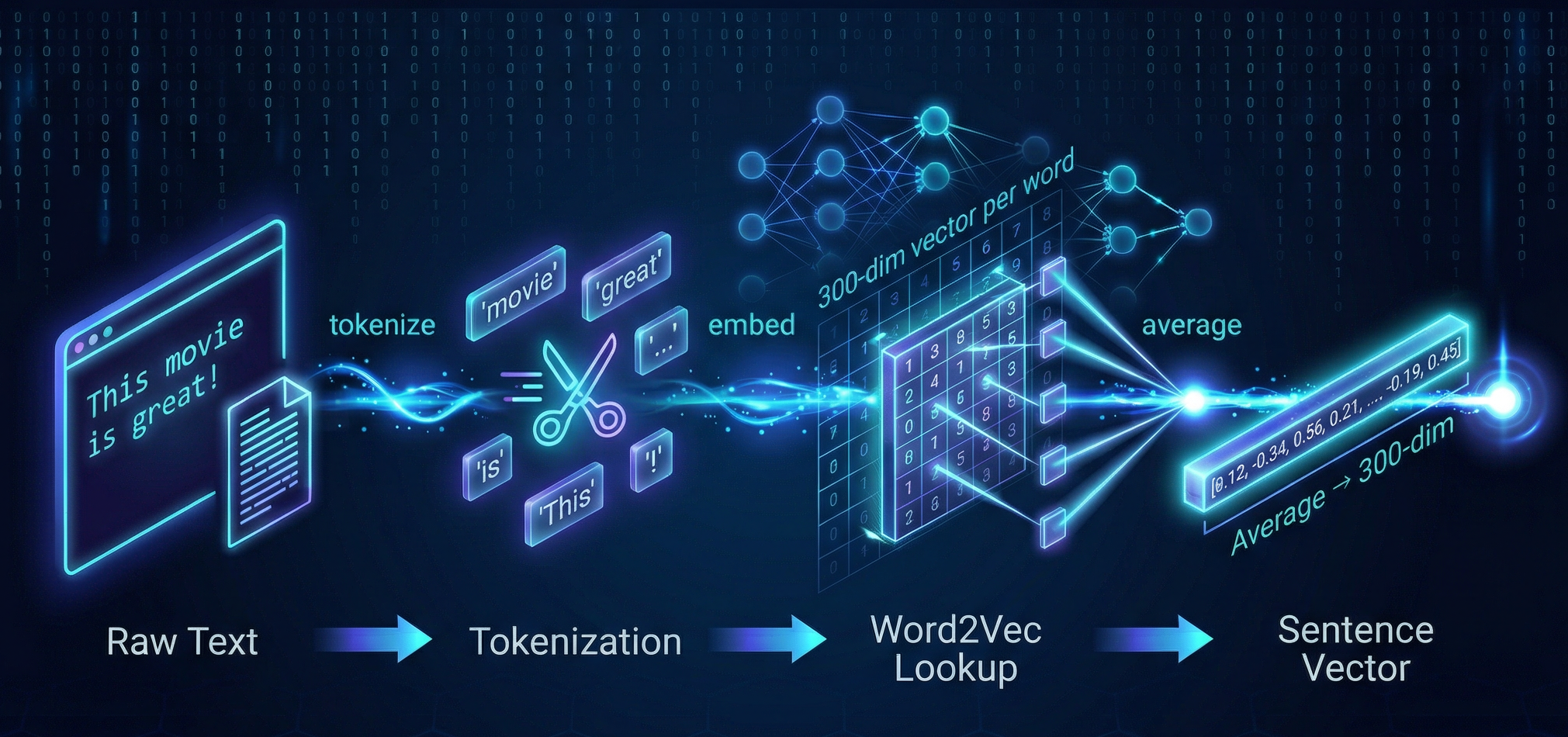
(2) 数据维度变化
| 阶段 | 数据形式 | 维度 |
|---|---|---|
| 原始数据 | 文本字符串 | 25,000 条评论 |
| 分词后 | 词语列表 | 每条评论 N N N个词 |
| Word2Vec 映射 | 词向量矩阵 | 每个词 → 300 维向量 |
| 句子向量化 | 句子向量 | 每条评论 → 300 维向量 |
| 最终输入 | 特征矩阵 X \mathbf{X} X | (25000, 300) |
(3) 代码实现
python
# 将所有句子转换为向量,堆叠成特征矩阵
X_train = np.vstack([sentence_to_vec(t, w2v_model, vector_size) for t in train_df["tokens"]])
X_test = np.vstack([sentence_to_vec(t, w2v_model, vector_size) for t in test_df["tokens"]])
print(X_train.shape) # (25000, 300)
print(X_test.shape) # (25000, 300)
# 标签
y_train = train_df["label"] # (25000,)
y_test = test_df["label"] # (25000,)(4) 映射示例
python
# 单条评论的映射过程
text = "This movie is great!"
tokens = ['movie', 'great', '!'] # 分词后(已去停用词)
# 查询每个词的向量
movie_vec = w2v_model.wv['movie'] # shape: (300,)
great_vec = w2v_model.wv['great'] # shape: (300,)
# '!' 不在词汇表中,跳过
# 取平均得到句子向量
sentence_vec = np.mean([movie_vec, great_vec], axis=0) # shape: (300,)-
经过这一步,我们得到了:
- X_train: (25000, 300) 的特征矩阵,每行是一条评论的向量表示
- y_train: (25000,) 的标签数组,0 或 1
-
这正是 scikit-learn 等机器学习库所需要的标准输入格式。
5.6 逻辑回归分类器
有了特征矩阵 X \mathbf{X} X和标签 y \mathbf{y} y,就可以使用任意分类器进行训练。这里选择逻辑回归作为分类器:
(1) 为什么选择逻辑回归?
| 优点 | 说明 |
|---|---|
| 简单高效 | 训练速度快,适合作为 baseline |
| 可解释性 | 可以分析特征权重 |
| 适合稠密特征 | 300 维的句子向量正好适用 |
(2) 代码实现
python
from sklearn.linear_model import LogisticRegression
def train_model(X_train, y_train):
"""训练逻辑回归分类器"""
clf = LogisticRegression(max_iter=1000)
clf.fit(X_train, y_train)
return clf-
核心思想:
- Word2Vec 负责「特征提取」------将文本转换为捕捉语义信息的向量;
- 逻辑回归负责「分类决策」------根据这些向量判断情感极性。
两者各司其职,组成完整的文本分类 pipeline。
5.7 模型评估
python
from sklearn.metrics import accuracy_score, classification_report
def evaluate_model(clf, X_test, y_test):
"""评估模型性能"""
y_pred = clf.predict(X_test)
acc = accuracy_score(y_test, y_pred)
report = classification_report(y_test, y_pred)
return acc, report六、运行流程
完整的执行流程如下:
1. 加载数据
├── 读取 imdb_train.csv(25,000 条)
└── 读取 imdb_test.csv(25,000 条)
2. 文本预处理
├── 分词(word_tokenize)
└── 去除停用词
3. 训练 Word2Vec
├── 输入:分词后的训练集
├── 输出:词向量模型
└── 保存模型到 models/ 目录
4. 句子向量化
├── 训练集 → X_train (25000, 300)
└── 测试集 → X_test (25000, 300)
5. 训练逻辑回归
└── 输入 X_train, y_train
6. 评估模型
└── 在测试集上计算准确率和分类报告 运行命令:
bash
python src/imdb_word2vec.py七、总结
本文以 IMDB 电影评论情感分类为例,完整演示了 Word2Vec + 逻辑回归 在文本分类任务中的实际应用流程。从原始文本出发,经过分词、去停用词、词向量训练、句子向量构建,最终完成情感预测,形成了一条清晰、可复现的 NLP 处理链路。
在该方案中,Word2Vec 负责将文本映射到语义向量空间,逻辑回归负责基于这些向量进行分类决策。两者分工明确,使得整个模型结构简单、训练高效,也非常适合作为文本分类任务的 baseline。
需要注意的是,词向量平均的方法会丢失词序和词重要性信息,因此模型性能存在一定上限。实际应用中,可以通过 TF-IDF 加权平均、Doc2Vec 或引入更复杂的深度模型来进一步提升效果。
总体而言,这一实战的核心价值在于帮助理解:文本是如何一步步转化为模型可学习的数值特征的。掌握这一过程,对后续学习更复杂的 NLP 模型具有重要意义。