SparkSQL的运行环境是在社区版idea中,spark版本是3.0.0,需要有一个外部的hive,开启metastore服务,博主的hive版本是3.1.2,并且使用MySQL存储元数据。
在idea中,sparkSQL中使用外部hive数据源,操作步骤可以分为三步。
1、修改pom文件引入依赖包
2、把hive的配置文件,hive-site.xml放到resources目录下
3、创建sparkSQL环境SparkSession并测试,启动SparkSession需要启用Hive的支持。
- 首先配置依赖,pom文件如下
只需要spark-core、spark-sql、spark-hive以及mysql-connector即可
xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>sparkDailyLearning</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>pom</packaging>
<modules>
<module>spark-core</module>
</modules>
<repositories>
<repository>
<id>aliyunmaven</id>
<name>阿里云公共仓库</name>
<url>https://maven.aliyun.com/repository/public</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
</repositories>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.27</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>3.0.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<!-- 该插件用于将 Scala 代码编译成 class 文件 -->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
<executions>
<execution>
<!-- 声明绑定到 maven 的 compile 阶段 -->
<goals>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.1.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>-
把hive的配置文件,hive-site.xml放到resources目录下
博主的hive-site.xml比较简单,是搭建的一个开发环境。(后续会出一个Hadoop伪分布式集群搭建)
-
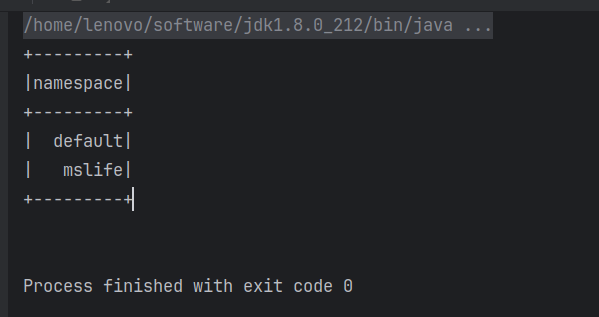
创建sparkSQL环境SparkSession并测试
java
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
object Spark05_SparkSQL_Hive {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local").setAppName("spark-hive")
// enableHiveSupport()就是启动对hive的支持
val spark = SparkSession.builder().config(sparkConf).enableHiveSupport().getOrCreate()
spark.sql("show databases").show
spark.stop()
}
}结果如下: