《智能的理论》全书转至目录****
不同AGI的研究路线对比简化版:《AGI(具身智能)路线对比》,欢迎各位参与讨论、批评或建议。
视觉工作记忆,也称为视觉空间画板。它是成分工作记忆模型的一部分,负责视觉信息的加工与暂存。按照信息类型的不同,视觉工作记忆至少又可以分为客体工作记忆和空间工作记忆。客体指现实中存在的各种物体, 如建筑物、几何图形、面孔等。它是由颜色、形状、纹理、方位等不同维度的视觉特征组合而成,客体工作记忆的作用就在于将这些视觉信息整合成一个客体;空间工作记忆能将空间信息进行暂时地保存,它除了能保存物体所在的空间位置,还能保存客体间的空间关系及客体的运动方向(Goodale和Milner,1992)。
一.客体工作记忆
工作记忆容量问题,一直都是研究工作记忆的主要关注点之一。从记忆容量的研究角度出发,不同学者分别提出了不同的视觉客体工作记忆的存储机制。
1.强客体存储假说
该理论认为客体工作记忆的基本存储单位是客体而非特征,将各种视觉特征整合为客体后再存储于工作记忆中。因此客体工作记忆的容量取决于客体的数目,而每个客体的特征如何并不会影响记忆容量,也不会占用其他认知加工资源(刘飞,2010)。
Luck和Vogel(1997)对客体工作记忆的强客体存储假说进行了研究,研究者认为视觉工作记忆的存储单位是客体,并证明了其存储容量约为3到4个。该实验采用了变化察觉的实验范式,设置如下:在学习阶段,被试需要先观看一张学习图片,图像上会展示数个(2、4或6个)正方形,每个正方形的颜色不同。其后会出现1秒的空屏。接着进入测试阶段,该阶段会出现另一张测试图像。测试图片可能与学习图片完全一样,即在个数、颜色和位置上均完全相同;也有可能在其中一个正方形的颜色上与学习图片不同,如图1。被试的任务是判断测试图片与学习图片是否一样。实验结果表明,当正方形的个数小于4时,被试基本能作出正确判断。但当正方形的个数大于这个数时,被试的正确率随着个数的增加而减少。因此研究者认为客体工作记忆的存储容量大约为4个客体。当少于该数时由于存储空间充足,因此不会发生错误。
由于上述实验使用的刺激是单色正方形,一个客体仅有一个区别特征,即颜色。因此上述实验的结果也有可能是:客体工作记忆存储的是特征,而非客体(基于特征的假说)。为了排除这种可能。研究者在上述实验(单色正方形客体)的基础上,使用了双色嵌套方块(一种颜色在外,另外一种颜色嵌套在内的方块)进行了相同的实验,即仅将上述实验中的单色正方形换成了双色嵌套方块。在实验过程中,测试图片与学习图片可能完全相同,也可能其中一个颜色不同(其中一个嵌套方块的内部或外部颜色不同)。如果被试记住的是客体而非特征,那么正方形与双色块这两种实验材料的成绩应该相同。相反,在同等客体数目下,双色块的成绩应该会低于正方形的成绩。这是因为双色块的特征数(颜色数)是正方形特征数的两倍。实验结果显示,被试对双色块的记忆成绩与正方形的成绩并无差异,均是四个,从而验证了客体工作记忆的存储单位是客体的想法。与这一结论相对应的是插槽模型。该模型认为客体工作记忆有3到4个插槽,每个插槽只能存储一个客体。
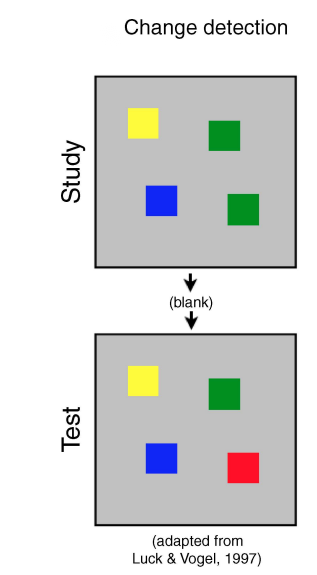
图1
2.基于特征的假说
基于特征的假说认为,视觉工作记忆存在多个特征子系统(颜色、形状、朝向...),每个特征子系统存储不同维度的特征(如颜色子系统仅存储颜色特征),各子系统可存储若干个同一维度的特征。客体不同维度的特征平行地存储在各自的特征子系统中,同时特征间通过捆绑,组成一个完整的客体(一般只能存储3到4个客体)。客体拥有几个构成特征,就要占用几个容量单位。该假说还认为,如果同一个客体在同一维度上存在多个特征,这些特征之间会发生干扰,如红、蓝、黄、绿构成的客体就会出现四种颜色之间的竞争;而同一客体在不同维度的特征上,互不干扰,如一个红色正方形的颜色特征和形状特征互不干扰(刘飞,2010;李广平,2004)。对于不同客体,只要不超过容量范围(3到4个客体),即使同一维度间的特征也互不干扰,如对于四个颜色的正方形,它们的颜色特征互不干扰。
在Xu等人(2002)的变化察觉实验中使用了蘑菇形状的客体作为刺激,蘑菇包括蘑菇帽和蘑菇茎,这两部分可以是不同的颜色。另外,蘑菇茎有其自身的方向。研究者进行了两组实验,第一组是对Luck 的双色变化察觉实验进行验证。他们既测量单色情况下的成绩,即被试只需记住蘑菇帽或蘑菇茎的颜色;也测试了双色情况下的成绩,既被试需同时记住蘑菇帽和蘑菇茎的颜色。结果表明双色情况下的成绩要低于单色的,这说明客体工作记忆的存储单位不是客体,否则两种情况的成绩应该相同。该组实验无法复现上述Luck的双色嵌套方块的实验结果。另外,这也说明了客体工作记忆的容量与特征相关。在第二组实验中,他们测量了被试记住蘑菇茎朝向的成绩,他们也测量了被试同时记住蘑菇帽颜色和蘑菇茎朝向的成绩,结果发现,两种成绩相同。这两组实验的不同之处在于,第一组实验的双特征使用的是同一维度的(都是颜色),第二组实验的双特征使用不同维度的(颜色和形状)。第一组的双特征成绩变差,说明同一维度的两个特征之间会产生干扰(尤其在同一客体中);第二组实验说明不同维度的特征之间不会产生干扰。这两组实验为基于特征的假说供证据。
3.弱客体存储假说
该假说认为,客体工作记忆容量不仅取决于客体的数量,同时还受到特征、特征之间的整合方式等的影响。在弱客体假说中,特征与客体共同占用一个存储系统,它们之间相互竞争记忆资源(刘飞,2010)。
在Olson和Jiang(2002)的研究中。研究者在实验1中进行了类似于上述Luck的双色嵌套方块研究实验。在学习阶段先呈现3到6个单色客体,或呈现3到6个双色客体。经过一段时间的延时后,在测试阶段仅呈现一个客体,该客体处于学习图片的其中一个客体上。要求被试判断两客体的颜色是否发生了变化。实验结果显示,被试在单色情况下的成绩要优于双色情况下的,因此说明客体工作记忆不是单纯的基于客体进行存储的。该组实验无法复现上述Luck的双色嵌套方块的实验结果。另外,研究者在实验3中使用线条作为刺激,该类刺激包括长度和朝向两种特征。他们首先测试了被试对单特征(朝向特征(长度固定朝向变化),或长度特征(朝向固定长度变化))的记忆成绩,刺激的个数分别为4个或8个(即4个或8个特征);然后测试双特征的记忆成绩(长度和朝向同时变化),刺激的个数分别为2个或4个(4个或8个特征)。如图2。研究发现,在同等特征数的情况下,双特征的成绩要好于单特征的。如包含两个朝向和两个长度特征(一共两个双特征的线条)的记忆情况要好于包含4个朝向特征(一共四个朝向不同长度相同的线条)的记忆情况。虽然都是4个特征,但实验1使用了4个客体,而实验3只使用了2个客体。由此说明了客体的数目也会对客体工作记忆产生影响,即客体也是客体工作记忆的存储单位。从而否认了基于特征的假说。
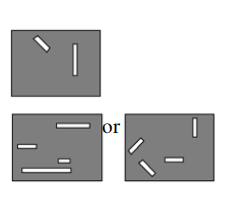
图2
4.信息有限假说
Brady等人(Brady,Konkle和Alvarez,2011)以一个USB存储照片的例子说明了信息有限假说的基本思想。视觉工作记忆的容量是有限的,能存储多少客体与存储客体的"分辨率"有关。当所存储客体的特征越精细、结构越复杂时,存储客体的分辨率越高,客体工作记忆能存储的客体越少;反正则越多。客体工作记忆的存储容量可比作一个USB的存储空间,客体的记忆表征好比USB存储的照片。USB的存储容量是固定的,能存储多少张照片,需要看每张照片的分辨率大小。当照片分辨率越高,信息量越大,USB能存储的照片越少;反之则越多。如一个500M容量的USB,如果每张照片的大小为5M,那么USB能存储100张照片;而如果每张照片的大小为20M,那么USB只能存储25张照片。客体工作记忆的存储机制可以与USB进行类比。下面通过三组实验进行论证。
Wilken和Ma(2004)使用了连续报告范式进行了实验研究。与上述Luck实验不同的是他们需要被试给出正方形的具体颜色,而非仅指出颜色是否变化。他们先对被试呈现包含数个正方形的学习图片,每个正方形不同颜色。在短暂的空屏后,呈现测试图片。测试图片会指定学习图片的某个正方形,要求被试调整连续色环,以示出指定正方形的准确颜色。如图3(a)。实验结果表明,被试报告的颜色精度会随着正方形个数的增加而减少。研究者认为,如果客体工作记忆是以客体为存储单位(强客体假说),那么被试应该能记住3到4个正方形的准确颜色;而如果工作记忆是以信息量为存储单位。当要求记住的颜色越精确,存储正方形所需的信息量就越大,能记住的正方形数量就越少。实验结果的表现与后者相符。
Alvarez和Cavanagh(2004)进行了上述Luck变化察觉实验的一个变种,变化的是他们将刺激从不同颜色的正方形改变为不同旋转角的正方体,如图3(b)。实验结果表明,当学习图片只呈现一个正方体时,被试能正确地检测出变化。但是当呈现的正方体数量为4时,被试不能正确地检测出变化。如果按照强客体假说,被试应该能记住3到4个正方体的旋转角,这显然与实验结果不符。而按照信息有限假说,与察觉颜色的变化相比,察觉正方体的旋转角所需的信息量更大,因此能被记住的数量更少。
Awh,Barton和Vogel(2007)进行的另外一个变化察觉实验中发现,即便是特征复杂的客体,当学习图片和测试图片之间变化很大时,只需要很少的信息量便能检测出来,从而能记住更多的客体。这个实验的学习图片包含一些文字和一些正方体,在测试图片中将其中一个正方体变化为一个文字,如图3(c)。实验结果表明,虽然客体有着复杂的特征,但是如果所变化的特征差异很大,那么被试只需记住客体的低分辨率特征就可将前后两个客体区分开来(比如不需要记住正方体的旋转角,只需记住它是一个几何体即可;同时也不需要记住具体文字,只需记住它是一个符号即可。利用几何体和符号的低分辨率特征就能将客体区分开来),所以能容纳的客体数就会变多。
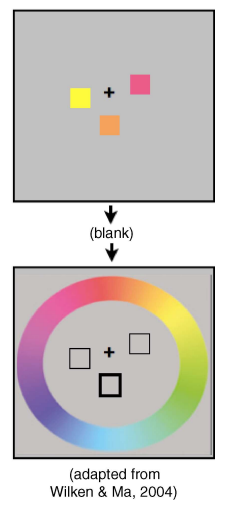
图3(a)
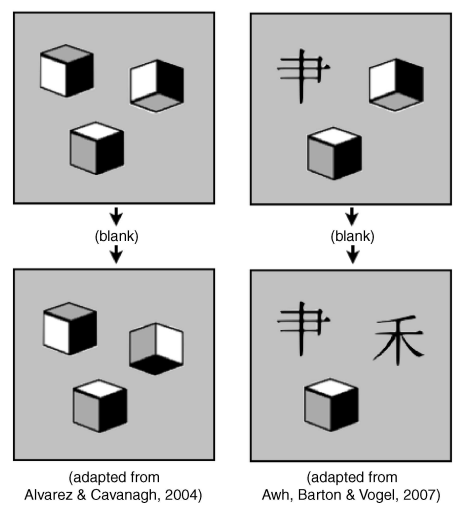
图3(b) 图3(c)
5.层次化结构理论
综合各种理论,Brady等人(Brady,Konkle和Alvarez,2011)提出了客体工作记忆的层次化结构理论。该理论认为,记忆单元的最高层是一个整合的物体表征;记忆单元的最底层是特征表征,这个层次结构与视觉系统的分层结构有相似的组织方式。该结构有两个特点:首先,特征之间存在一定的独立性,因此可以独立地调节某些特征的信息量(如"连续报告范式"的精确颜色),甚至可以独立地遗忘某些特征(如上述Luck的正方形形状特征)。其次,最初的编码过程是基于物体的,而编码一个新的分层特征可能会带来额外信息量的成本。即当仅编码整个物体时,这时所需的分辨率较低(如Awh,Barton和Vogel(2007)实验中的几何体和字符),需要的记忆容量较少;但需要对其特征进行编码时,即对特征层进行编码,其分辨率较高(如Alvarez和Cavanagh(2004)实验中正方体的旋转角和Wilken和Ma(2004)实验中的精确颜色),需要的记忆容量就更多。如图4(图(a)代表强客体假说,图(b)代表基于特征的假说,图(c)代表层次化结构理论,图展示了三种理论的区别)。
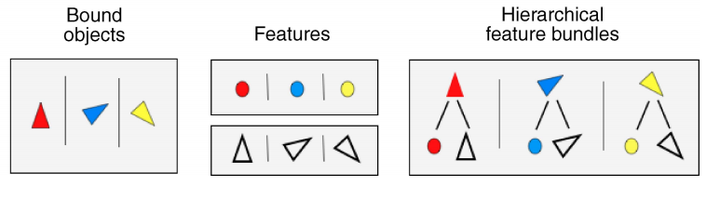
图4(a) 图4(b) 图4(c)
6.群体客体
(1)群体客体
Brady和Alvarez(2011)认为特征和客体处于工作记忆的不同层次,它们构成了客体工作记忆的层次化表征。更进一步的,他们认为,在一个多客体的视图中,客体与客体之间并不是互相独立的,而是会整合并构成更大的客体群组表征,它处于客体表征之上。客体工作记忆从特征表征到单个客体表征,再到群体表征,每个层次之间互相影响。客体群组可以由具有相似特征的客体聚类而成,即客体群组表征编码了关于其客体的一些统计特性,客体决定了客体群组的表征。另外,他们发现客体群组反过来也会影响客体。
他们的实验如下,在学习阶段,被试首先会观看一张包含三个红色圆圈、三个蓝色圆圈和三个绿色圆圈的学习图片(如图5所示),同时他们会被要求记住图中红色和蓝色的圆圈。每种颜色的圆圈半径大小由某一高斯分布随机生成,即相同颜色的圆圈有相似的大小。而不同颜色圆圈之间的大小可能会有一定差距。在测试阶段,会给被试呈现一张仅包含一个黑色圆圈的图片,黑色圆圈的位置处于学习图片中6个红蓝圆圈位置中的一个。被试要做的是,将黑色圆圈的大小调整到学习图片对应位置的圆圈的大小。结果表明,被试在调整的时候出现了均值偏向现象,即如果对应位置的圆圈是蓝色(红色),被试更倾向于将黑色圆圈的大小调整为篮色(红色)圆圈群组的均值。这说明客体群组的统计特性影响了单个客体的表征。

图5
(2)群体客体的信息有限假说
群体编码也服从信息有限假说。如图6所示(Brady,2011),实验使用变化察觉范式,图上方是学习图片,图下方分别展示了两种测试图片,在测试阶段让被试判断测试图片是否发生变化。被试对左下测试图片的判断成绩比对右下测试图片的成绩更高。这是因为,左下图对学习图片的变化更大,变化的客体与群体偏离严重,对群体编码所要求的信息量不高;相反,右下图的变化客体与群体相似,需要对该客体进行更加精细的编码才能进行区分,所要求的信息量更高。
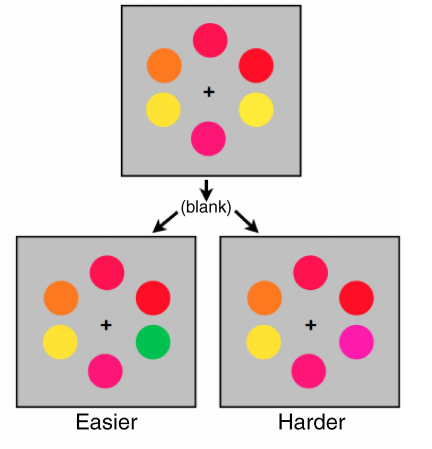
图6
(3)全局客体与局部客体
聂其阳(Nie,Müller和Conci,2016)等人发现了全局客体与局部客体相比(全局客体由若干个相同的局部客体组合而成)(如图7上,左边的大三角形为全局客体,它由许多个小正方形组成,而这些正方形即局部客体),全局客体具有全局优先性,即个体会优先对全局客体进行编码,全局客体获得更多的注意。同样使用变化察觉范式,他们先让被试观察学习图片,其包含数个全局客体(如图7上)。然后给被试呈现一张仅包含一个全局客体的测试图片,并让被试判断与学习图片对应的全局客体相比是否发生了变化。测试图片的全局客体有三种可能的情况,第一种是全局客体发生变化而局部客体没发生变化(如图7左下,全局客体由三角形转变为菱形,而局部客体仍然是正方形);第二种是局部客体发生变化,全局没变(如图7中下);第三种都是没发生变化(如图7右下)。结果发现,全局变化与局部变化相比,被试成功发现全局变化的概率更高。研究者认为,这是由于全局客体具有全局优先性的原因。而编码局部客体需要更多的信息量,因此更难被发现。
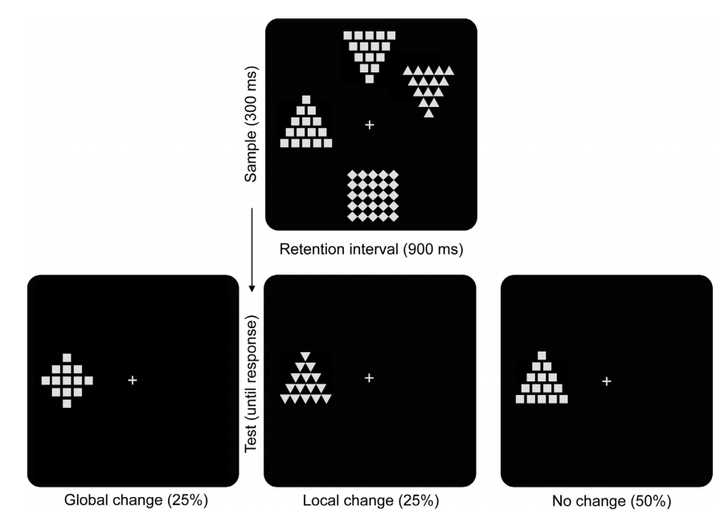
图7
二.空间工作记忆
1.客体-位置绑定
客体和位置的整合具有的理论和现实意义,因为个体对客体作出某种行为,必须将特征信息和位置信息整合,即客体-位置绑定。例如,我们进入超市购物,凭记忆挑选商品时,都是基于什么商品在什么个区域或者哪个个货架,即"什么样的客体在哪里"。
有研究表明(Jiang ,Olson和Chun,2000),当同时对客体特征及客体之间的位置关系进行编码时,既有利于对客体属性的回忆,也有利于对客体位置的回忆。研究者使用了两种不同的变化察觉范式进行对比。两种实验的学习阶段都使用了有8个颜色正方形的学习图片。在回忆阶段,一种实验的测试图片从学习图片中随机挑选一个正方形,然后用一个方框把该正方形框起来,以表明该方框是目标方框。该正方形可能保持其颜色也可能改变其颜色(只改变目标正方形的颜色,而位置不变;其余7个正方形的颜色和位置均不变)。被试需要做的是判断目标正方形的颜色是否与学习图片的相同。另一种实验的测试图片只保留一个正方形,保持或者改变其颜色。被试需要做的是判断目标正方形的颜色是否与学习图片的相同。如图8。实验结果表明,第一组的成绩要优于第二组的,表明了记忆正方形并不是孤立存储的,该正方形与其他正方形共同编码。当呈现它与其他正方形的关系时,有助于对它客体特征(颜色)的回忆。在他们的另外一项实验中对客体的位置记忆进行了验证,学习图片是8个绿色的正方形,测试图片分为三种情况,(a)从8块正方形随机选一个,保持或者改变其位置,其余7块不变;(b)只保留一块正方形,保持或改变其位置;(c)随机保留四块正方形,并从中取一块保持或者改变其位置。被试需要做的是,判断目标正方形的位置是否发生了改变。结果表明,(a)的成绩要优于(b),(b)要又优于(c)。之所以情况(c)的成绩最差,可能是因为新的客体布局影响了目标客体的表征。
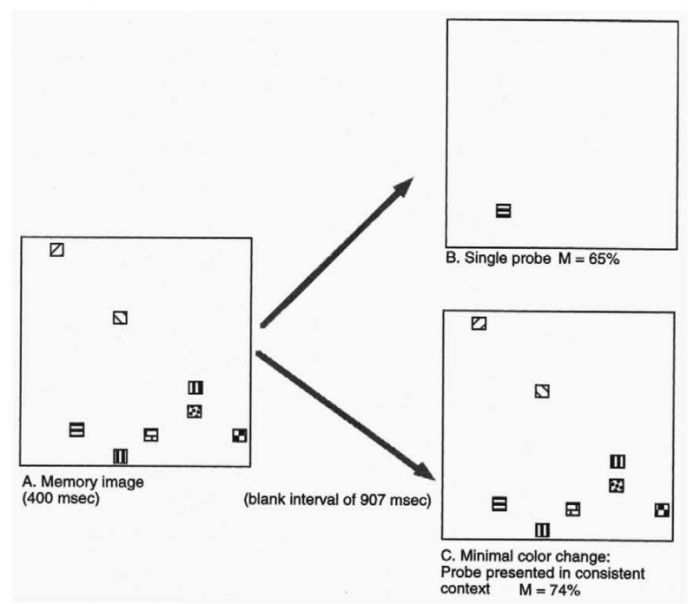
图8(不同纹理代表不同颜色)
为了进一步研究位置关系有何特点,研究者(Jiang ,Olson和Chun,2000)继续进行了如下实验。将学习图片分为4个象限,每个象限都有一个客体,被试需要记住客体的颜色或者形状(颜色组的被试需要记住颜色,形状组的被试需要记住一些简单形状(圆形、正方形等))。测试图片分为三种情况,第一种是四个客体的位置相同;第二种是对四个客体的距离进行缩放但确保它们在各自的象限中,保持相对位置关系不变;第三种是四个客体的位置在各自象限内随机变化,如图9。被试需要做的是判断每个象限的客体是否发生变化。实验发现,不论是颜色组还是形状组,第一种和第二种情况的分数一致,第三种情况分数最差。这说明了,空间工作记忆保存的是各个客体的相对位置关系,而非绝对位置关系。
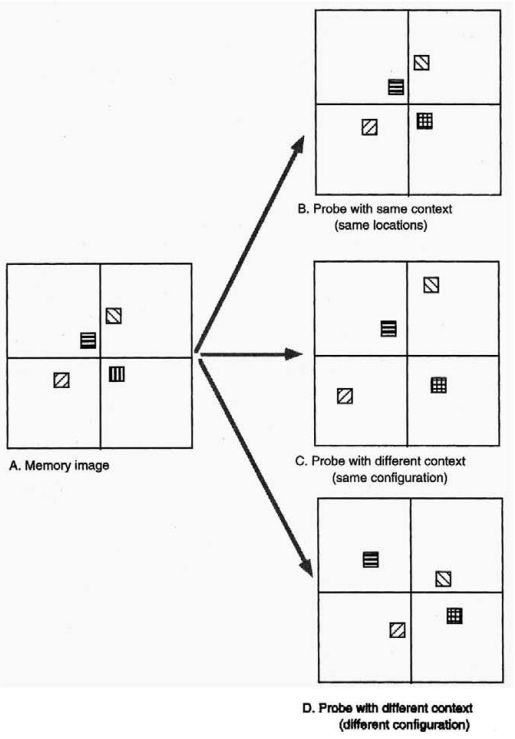
图9
Sapkota等人(Sapkota,Pardhan和van der Linde,2011)等人将"客体-位置绑定"理论推广到时间的维度上。研究者以序列的方式将客体先后显示在显示屏上(刺激的个数为1到5个),每个客体出现的位置不重叠,如图10所示。其中,刺激的序号表示它们的出现顺序。在测试阶段,测试图片会出现一个刺激,被试需要做的是判断该刺激是否在学习图片中出现过。研究者将实验分为三组,在第一组中测试图片的刺激的出现位置与学习图片的相同;在第二组中测试图片的刺激随机地在图片上出现;在第三组中刺激出现在图片的中心。结果显示,第一组的成绩要优于其他两组,第二组和第三组的成绩相仿。同时,成绩会随着学习刺激个数的增加而减少。这说明,被试能在序列中整合各个客体的位置信息,形成客体-位置绑定,从而提高被试的成绩(第一组)。需要说明的是,设置第三组的原因在于,排除第二组成绩变差的一种可能:"第三组并无吸引注意力,而第二组和第三组的成绩相仿,因此排除了第二组成绩变差是由于刺激突然出现在随机位置影响了注意力"。

图10
2.位置特征的层次
最后,Jiang 等人(Jiang ,Olson和Chun2000)还证实了颜色特征和位置特征之间的层次关系,即哪个特征更早被加工或更为基础。如果是位置特征更基础,那么改变颜色特征不会影响被试关于客体位置的成绩。这个实验采用了变化察觉的实验范式。在学习阶段对被试呈现一张包含8个正方形色块的学习图片,在测试阶段可能呈现一张完全相同的测试图片,也可能将8个正方形的颜色改变。然后随机选择一个正方形色块,被试需要做的是判断该正方形色块的位置是否与学习图片中对应的正方形色块的位置相同。实验结果是,不论是保持8个正方形的颜色,还是改变8个正方形的颜色,这两种情况下被试对目标正方形的位置判断成绩是一致的。这说明,颜色特征对位置特征的影响很小。往更深的方向说,位置特征可能比颜色特征更为原始,既视觉系统可能先加工客体的位置特征,然后再加工客体的颜色特征,因此改变客体颜色对其位置无影响。类似的,鲍旭辉和何国立(2014)证明了颜色对形状具有优先性,即颜色特征比形状特征更为原始。
3.场景中的位置记忆
Jiang 等人(Jiang ,Olson和Chun2000)使用的是较为简单的图案。而Hollingworth(2006)使用自然场景作为研究对象,研究了场景记忆对位置信息的作用。与简单图案相比,对自然场景的研究可能更能反映出人类空间工作记忆的加工机制。Hollingworth的实验程序如图11(a)所示,先后展示:一个自然场景,以此作为学习图片;一个"dot onset"场景,即在图中的一处突然出现一个亮点以吸引被试注意,保证被试不会注意场景中的其他客体(Hollingworth,2003a);点亮消失保持场景的显示(学习图片);雪花图片;测试图片1;空白图片;测试图片2。在其中一张测试图片中,场景中的其中一个客体会发生旋转,比如玩具货车旋转了90度(图(c)),又或者变化为另外一种同类客体,如将玩具货车换成玩具卡车(如图(d)),另外一种与学习图片一致(图(b))。被试需要做的是判断测试图片1还是测试图片2的目标客体与学习图片的目标客体相同。测试图片有两种形式,一种是使用背景,即图片的背景是原来的自然场景(如图的第二行,图的第一行);另外一种是不使用背景,即仅展示客体,而背景是空屏(如图的第三行,图的第二行)。结果显示了使用场景的成绩要优于不使用场景的。

图11(a)
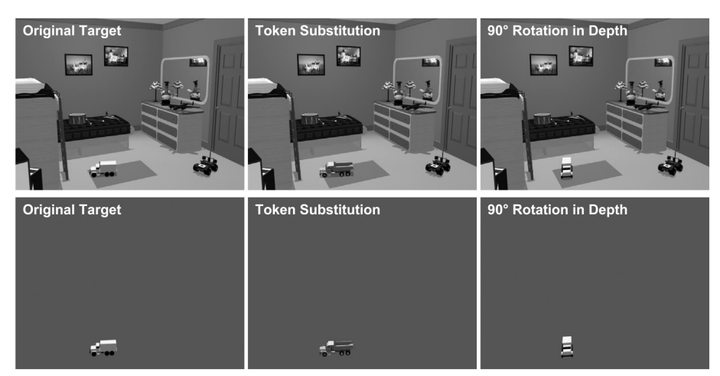
图11(b) 图11 (c) 图11 (d)
为了证明自然场景中的记忆受长时记忆影响,Hollingworth(2005a)使用多客体和延时测试的方式进行了研究。其中,多客体表示一个场景中包含超过4个的客体(超过短时记忆容量);延时测试表示对一个场景的测试,放在下一个场景的学习之后,如第N-1轮场景学习->第N-2轮测试->第N论场景学习->第N-1测试...(超过短时记忆的存储时间)。结果表明被试的测试成绩并不比在短时记忆中的成绩差,说明长时记忆中整合了场景信息(包括位置信息)与客体信息,并在任务过程中发挥作用。
场景信息如何影响客体的位置特征?Hollingworth(2006)提出了三种可能:(a)大尺度的几何结构(如房间的墙壁、地板和天花板);(b)场景中的其他客体;(c)目标客体的局部信息(如玩具卡车(目标客体)和地毯之间的局部关系)。而对于(c)的可能性,已被Hollingworth(2003b)排除。他设计了一个实验,该实验用一个空白圆盘将目标客体的局部信息屏蔽(如图12)。结果发现使用空白圆盘对被试的测试成绩并无造成多少影响。

图12
Hollingworth的这些实验共同证明了客体表征被整合在一个更大的场景中,并且这个场景信息存储于长时记忆中,并为视觉工作记忆的任务提供支持。具体的,可以用一个模型说明,当眼睛观察一个客体时,该客体及其空间表征存储于工作记忆中,随后该两表征被整合在长时记忆中的场景表征中。当眼睛扫视场景时,被注视的新客体会替换掉旧客体,并在工作记忆中形成新的表征。而长时记忆的场景表征则在保持的同时,从工作记忆中融合进新的客体表征和新的空间表征(Henderson,1994;Hollingworth,2005b)。
三.视觉工作记忆中的信息整合
1.低频信息和高频信息(卢剑刚,2010)
自然界中的视觉客体可以分解为高频信息和低频信息两部分,高频信息可表达刺激的细节特征低频信息可表达全局结构。生理研究发现,高、低频信息在视觉皮层分别由不同的神经细胞加工,低频信息主要通过大细胞通路传导,高频信息主要通过小细胞通路传导。
来自恒河猴的研究发现,视觉皮层对低频信息的提取先于高频信息约51ms,既低频信息的传导速度快于高频信息。另外结合大量现有的研究数据表面,在客体表征的构建过程中,不同的知觉信息可能并非都以"全有"(完整的视觉客体)或"全无"(没有任何信息)的形式进入工作记忆,而是有先后次序,精度较低整体性更强的低频信息优先进入工作记忆,形成初级表征;细节丰富的高频信息随后进入,构建高精度表征。遵循"粗糙到精细",以累积的形式构建视觉客体表征。
2.时间维度上的视觉信息整合
即便是在同一视角下(也可以在不同视角下),场景或客体也会随着时间而运动,这时历史视觉信息存储于视觉短时记忆中,而当前观察到的视觉感觉记忆如何被整合到视觉短时记忆中呢?
(1)研究范式与现象
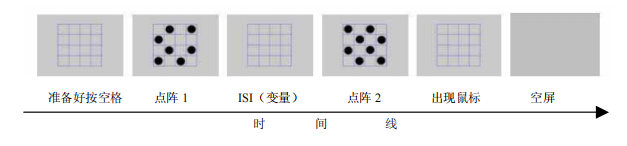
图13
Brockmole等人(Brockmole,Wang和Irwin,2002)采用了空白单元格定位实验,研究了视觉感觉信息与视觉短时记忆如何整合的问题。如图13,实验流程如下。首先呈现点阵1,即一个4*4的网格,共16个单元格,其中7个包含圆点。经过一定时间(ISI)的空屏后,呈现点阵2,点阵2包含8个圆点,并且该8个圆点所占的单元格与点阵1的不重叠。换句话说,两个点阵的圆点共占15个单元格(7+8=15),被试需要指出在网格中哪一个是剩余的单元格(点阵1和点阵2均没有占的单元格)(16-15=1)。实验的逻辑是,被试在观看点阵1后,需要将其存储于短时记忆中。并在观看点阵2时,被试只有成功地将点阵2的感觉信息与点阵1的短时记忆进行整合,才能顺利的完成测试。
在实验中,研究人员会调整两点阵之间的时间间隔(ISI),以测试短时记忆整合与ISI的关系。结果表明,被试的正确率呈"U型"曲线特点。具体的说,当ISI为0ms时,被试的成绩最好;当ISI从0ms上升到100ms时,被试成绩逐渐降低。这是因为当ISI极短时,点阵1的知觉记忆还未消退,两个点阵可以直接使用知觉记忆进行比较,而点阵1的知觉记忆随着时间逐渐消退,从而成绩变差;ISI在100ms后被试的成绩又开始上升,并约在1300ms时达到最好水平(比0ms的成绩低);在1300-5000ms范围内,被试成绩处于一个稳定的水平。这是由于关于点阵1的短时记忆需要一个构建过程,构建越完整被试的成绩越好(约在1300ms构建完成)。另外,研究人员分别研究了点阵1、点阵2与被试成绩的关系,即被试给出错误答案时,被试指出的剩余单元格,实际是被点阵1圆点占据,还是被点阵2圆点占据。结果显示,错误主要是发生在点阵1上(被试指出的点处于点阵1的圆点中),因此被试的成绩更依赖于对点阵1的短时记忆(由于忘记了点阵1的圆点,因此把剩余点定位在点阵1中)。
Brockmole等人(Brockmole和Irwin,2005;Brockmole和Wang,2003)还研究了第二帧在第一帧的基础上进行平移、缩放和旋转的成绩,分别如图14(a)、图14(b)和图14(c)。三种情况的实验程序类似,以平移为例:先呈现第一部分,即点阵1;呈现第二部分,即平移前的无圆点的4*4网格;呈现第三部分,即空屏;呈现第四部分,即平移后的网格;呈现第五部分,即平移后的点阵2。其中,第三部分的空屏时间为ISI,位移前两部分(第一和第二部分)的网格位置相同,位移后两部分(第四和第五部分)的网格位置相同。实验分为两种实验条件,分别为平移前成分条件,即保持第四部分的呈现时间,调整第二部分的呈现时间并判断其与被试成绩的关系;平移后成分条件,即保持第二部分的呈现时间,调整第四部分的呈现时间并判断其与被试成绩的关系。在平移前成分条件下,被试成绩随呈现时间的增加而增加,并到达一定值时保持稳定。这表明从感觉记忆到短时记忆之间存在一个构建过程。在平移后成分条件下,被试成绩同样随呈现时间的增加而增加,并到达到一定值时保持稳定。这表明被试对短时记忆进行了一个平移的操作。缩放和旋转也有类似的实验结论。

图14(a)
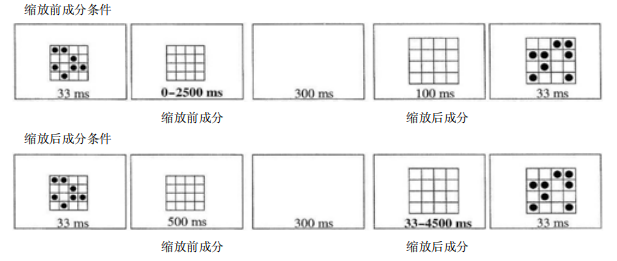
图14(b)
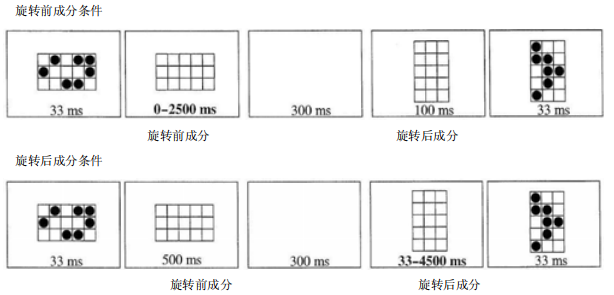
图14(c)
(2)整合模型
有两种模型对短时记忆的知觉整合机制进行了解释,并且这两种假说完全对立(任衍具,禤宇明和傅小兰,2007)。图像-知觉整合假说(Brockmole,Irwin和Wang,2003)认为被试先记住点阵1的圆点位置,然后和点阵 2 中的圆点位置进行整合,在两点阵整合后再确定空白单元格的位置。而转换-比较假说(或称有限整合假说)(Jiang,Kumar和Vickery,2005)则认为,被试先记住点阵1中没有被圆点占据的空白格位置,称为点阵1的负图像,然后将负图像和点阵2中的圆点位置进行比较。负图像的空格与点阵2的点重合,且多出一个空格,即目标空白单元格。
为了验证哪种模型才是正确的,Jiang等人(Jiang,Kumar和Vickery,2005)的实验采用了两种任务混合的模式。即每个被试会在实验中进行一系列的试次,其中一些试次进行一个任务,而另外一些试次进行另外一个任务。两个任务包括:空白单元格定位,如前所述,出现两帧16格网格点阵,前一帧7个圆点,后一帧8个,两帧圆点的位置不重叠,并要求被试找出空白单元格;变化检测任务,出现两帧16格网格的点阵,前一帧为7个圆点,后一帧出现8个,但是两帧中有7个圆点重叠,即第二帧的第8个点是在第一帧7个点的基础上多出来的,而被试需要指出哪个圆点是从第一帧中多出来的。研究者控制了两个任务在实验中的比例。在每个试次中,不会对被试提示该试次属于哪个任务,但被试可以通过两帧的重叠情况直接判断该试次的所属任务(当无重叠时进行空白格定位,当存在7个圆点重叠时进行变化检测)。当然,这需要在第二帧出现时才能确定该试次是哪种任务。另外,研究者也会事先告知被试哪类任务占多数。
该实验的实验逻辑是,对于变化检测任务,因为记住第一帧的圆点位置(图像-知觉整合假说)时,第二帧多出的圆点能直接"弹出来",因此检测效率更高。而记住第一帧的剩空白位置(转换-比较假说),则没有这种效果。这说明在进行这类任务时应该更偏向于记住圆点位置。因此,如果图像-知觉整合假说是正确的(即在空白格检测任务,被试是先记住第一帧圆点的位置),被试在一个实验的所有试次只需记住第一帧的圆点位置即可,不管任务比例如何均不会影响两个任务的结果。而如果转换-比较假说是正确的,那被试可能会在两种"惯性"中切换。即在空白格检测任务中偏向记住第一帧剩余空白格,在变化检测任务中偏向记住第一帧圆点。且在这种假说情况下,如果是变化检测任务的试次数量占优,那么记住第一帧圆点的惯性会更大,这会对空白格检测任务的成绩造成损害;反之,如果是空白格检测任务的数量占优,则记住第一帧剩余空白格的惯性更大,这会对变化检测任务的成绩造成损害。实验结果表明,当空白单元格定位任务在实验中占多数时,该任务的正确率随着ISI的增加而增加。而当变化检测任务占多数时,空白单元格定位的正确率并不随ISI而变化。实验支持了转换-比较假说的正确性。
任衍具等人(任衍具,禤宇明和傅小兰,2007)发现,当点阵1圆点数在短时记忆容量范围之内时,被试采用图像-知觉整合策略;反之则采用转换-比较策略。
3.眼跳过程中的视觉信息整合
观察者在一个时刻所能观察到的信息是有限的,其信息量远远少于场景所包含的。而通过眼球和头部运动,我们能够观察到场景的不同位置,从而增加关于场景的信息量。这涉及到一个问题,即如何在视角变化的过程中整合不同视角的信息,使我们体验到一个统一的、稳定的和连续的视觉表征。
Irwin(1991)在实验中对眼跳的信息整合进行了研究。实验包括三种实验条件。第一种是眼动条件,其实验设置如图15(a)所示,实验分为5个阶段。阶段1为视觉校准,显示器会先后呈现5个"+"号,呈现时间为1.5秒,当"+"号呈现时被试需要对其注视;阶段2,会在第二个(或第四个)位置处呈现"+"号,被试需要对它进行注视;阶段3,在第四个(或第二个)位置上方会出现一个4*4大小的方阵(共4*4=16个位置),方阵包含8个点并随机放置在方阵的16个位置中。这时被试需要从第二个位置向右眼跳到第四个位置(或需要从第四个位置向左眼跳到第二个位置),并对方阵的"+"号注视;阶段4,被试眼跳开始时(第三阶段)方阵消失,空屏幕时间为40-5000ms("+"号还在),但仍然要求被试保持对第四个位置(第二个位置)的"+"号进行注视;阶段5,8个点的方阵再次呈现,方阵可能与第一次呈现的完全相同,也可能其中一个点会被移动。被试的任务是,判断阶段5的方阵与阶段3的是否相同。在该实验条件下,在阶段3和阶段5期间,方阵的位置始终重合(都处于第四个(第二个)"+"号上方的位置),但方阵刺激在视网膜的位置发生了变化(阶段3的方阵在视网膜的右边(左边),眼跳后即阶段5,方阵在视网膜的中央)。
另外两个实验条件,其流程与眼跳条件类似,该两条件要求眼睛始终保持固定。第二个实验条件是"位置-视网膜"重合条件,阶段3和阶段5的方阵刺激始终出现在同一位置。因此这两个阶段方阵的视网膜位置和空间位置都是相同的。第四个实验条件是不重合条件,阶段3的方阵在注视"+"号上方3英尺的地方,阶段5的方阵与"+"号的位置关系正常。因此,该条件下,在两阶段的视网膜位置和空间位置均不重合。
研究人员对阶段4的空屏时间进行了控制,并观察不同空屏时间下被试的成绩。实验结果如图15(b)所示。与其他实验条件相比,"位置-视网膜"重合条件的成绩最好。因为方阵的视网膜位置和空间位置没有发生变化,所以被试能同时利用阶段3方阵的感觉记忆和短时记忆判断阶段5方阵。另外,被试成绩随着空屏时间的增加而减少,研究者认为,这符合感觉记忆和短时记忆的特点,即感觉记忆和短时记忆会随着时间的增加而衰退。在无重合条件下,当控制阶段4的空屏幕时间从40ms增加到300ms时,被试成绩先增加,然后在300ms后被试成绩逐渐减少。研究者认为,在该条件下,由于方阵在空间位置和视网膜位置均无重合,因此这两个阶段的感觉记忆是不同的(阶段3的感觉记忆在视觉外周,阶段5的在中央凹),因此被试无法使用阶段3的感觉记忆判断阶段5的,而只能使用短时记忆。构建短时记忆需要消耗一定的时间,因此被试成绩一开始较低,然后在构建的过程中逐步提高,直到短时记忆被构建完成(约300ms)。构建完成后,短时记忆开始消退,因此此阶段被试成绩随着开屏时间的增加而减少。无重合条件还有一个特点,被试成绩明显低于"位置-视网膜"重合条件的成绩。研究者认为这是因为"位置-视网膜"重合条件的两个方阵均处于中央凹处,该处分辨率最高;相反,在无重合条件下,阶段3方阵处于外周视觉,该处分辨率较低,阶段5方阵处于中央凹。在眼动条件下,由于空间位置重合而视网膜不重合,因此无法使用感觉记忆。被试成绩显著低于其他两种条件,这表明没有视网膜重合的空间重合对被试成绩几乎没有什么好处。最后,被试在眼动条件条件下的成绩显著高于随机条件(>50),因此证明了被试能在眼动过程整合了视觉信息。
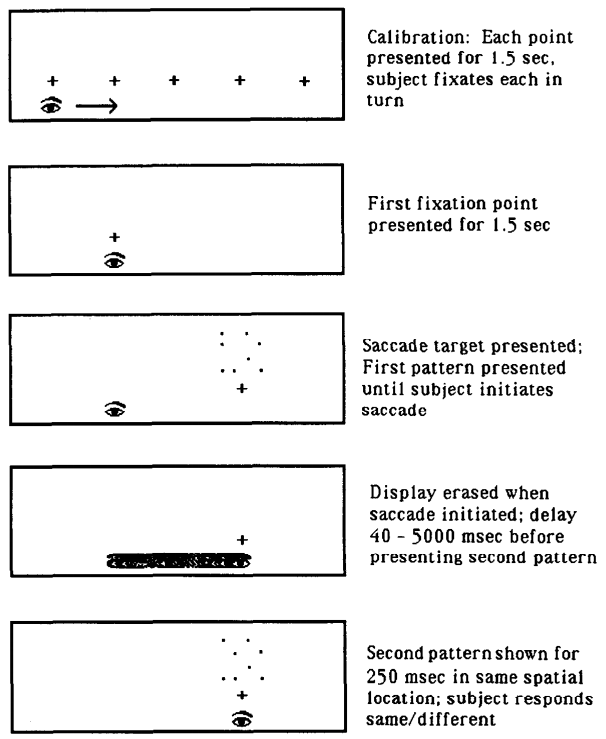
图15(a)
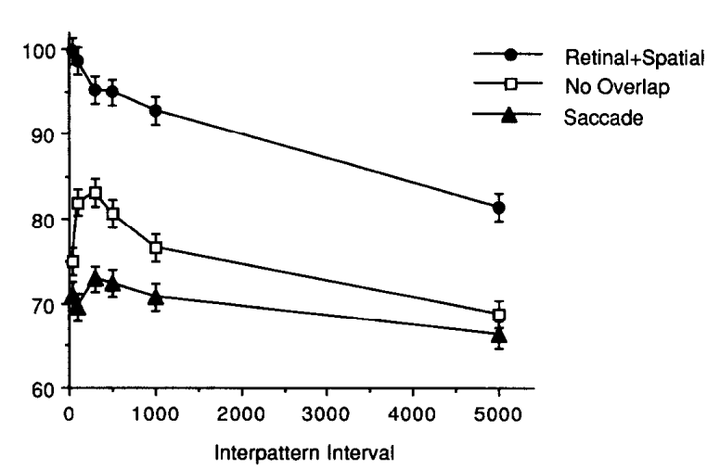
图15(b)
四.基于格式塔线索的动态整合
在日常生活中,知觉信息往往是离散地进入工作记忆。工作记忆能否发现离散信息中存在的格式塔线索,进而利用这些线索对离散信息进行动态整合,是体现视觉工作记忆动态加工能力的重要方面。Gao等人(2016)采用变化察觉范式的一种变式(如图16),记性项分两部分呈现,先呈现记忆项1,然后呈现记忆项1的掩码以防止视觉后效,再呈现记忆项2,然后呈现其掩码。最后给被试呈现测试项,需要被试判断测试项是否记忆项1和记忆项2的组合。记忆项的组合有三种条件,一种是记忆项1和记忆项2可以通过格式塔原则(如闭合性)组合,第二种是组合刺激只有一半符合格式塔原则,第三种是记忆项1和记忆项2无组合规则。结果显示当组合刺激越符合格式塔原则时,被试的成绩越好。
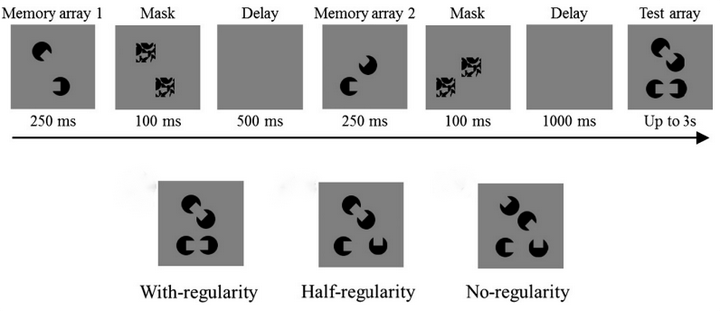
图16