在之前的章节中,我们实现了🐼基于文件/数据库授权的 Flask API。这种模式在处理"毫秒级"任务(如简单的签名生成、数据查询)时表现良好。
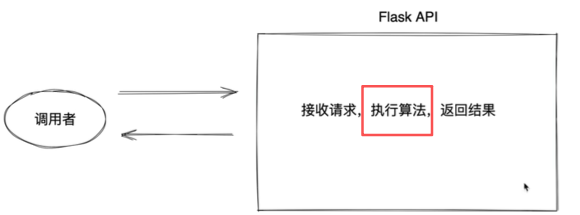
🐬然而在真实的生产环境中,可能面临:
a)长耗时任务: 如果核心算法涉及深度学习推理、大规模数据转换或第三方API调用,单次处理时间可能长达几十秒,在同步架构下,这意味着整个后端线程会被该请求死死占用;
b)高并发压力: 当请求量激增时,即使每个任务都耗时很短,有限的数据库连接和服务器线程也会瞬间填满,导致系统响应剧烈抖动甚至瘫痪。
异步任务队列架构
当 API 面临耗时较长的核心算法或极高的瞬时请求压力时,传统的"同步阻塞"模式会导致服务器资源迅速耗尽。为此,我们引入了如下图所示的异步解耦架构。
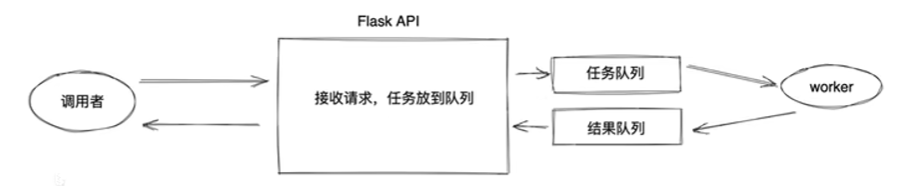
🙋**调用者:**携带参数发起请求
💻**API:**负责"接单"。
++①任务入队++ :将任务参数包装成一个消息,推送到任务队列(Redis或RabbitMQ)中;
++②响应凭证++ :迅速向调用者返回一个响应(通常包含一个 task_id),告知:"任务已受理,正在处理"。此时 API与调用者的连接立即断开,释放资源去接待下一个用户。
📁**任务队列:**作为消息的中转站,负责暂存所有待处理的任务。
📔**worker:**一个或多个独立的 worker进程:
① 持续监听任务队列。一旦空闲,就从任务队列中取出一个任务
② 处理完成后将结果写入结果队列(Result Backend),并标记任务状态"已完成"。
📝**结果获取:**调用者通过之前拿到的task_id 回来查询任务进度,或者由系统通过Webhook 等方式主动将结果推送给调用者。
1 API 实现
python
import json
import uuid
import redis
from flask import Flask, request, jsonify
# 创建按一个Flask实例对象
app = Flask(__name__)
@app.route("/task", methods=["POST"])
def task():
'''
请求的数据格式要求: {"ordered_string": "......"}
'''
ordered_string = request.json.get('ordered_string')
if not ordered_string:
return jsonify({"status":False, "error":"参数错误"})
# 创建任务 ID
tid = str(uuid.uuid4())
# 1.加入redis任务队列
task_dict = {'tid': tid, 'data': ordered_string}
REDIS_CONN_PARAMS = {
"host": "127.0.0.1",
"password": "123456",
"port": 6379,
"encoding": 'utf-8'
}
conn = redis.Redis(**REDIS_CONN_PARAMS)
conn.lpush('spider_task_list', json.dumps(task_dict))
# 2. 返回给调用者
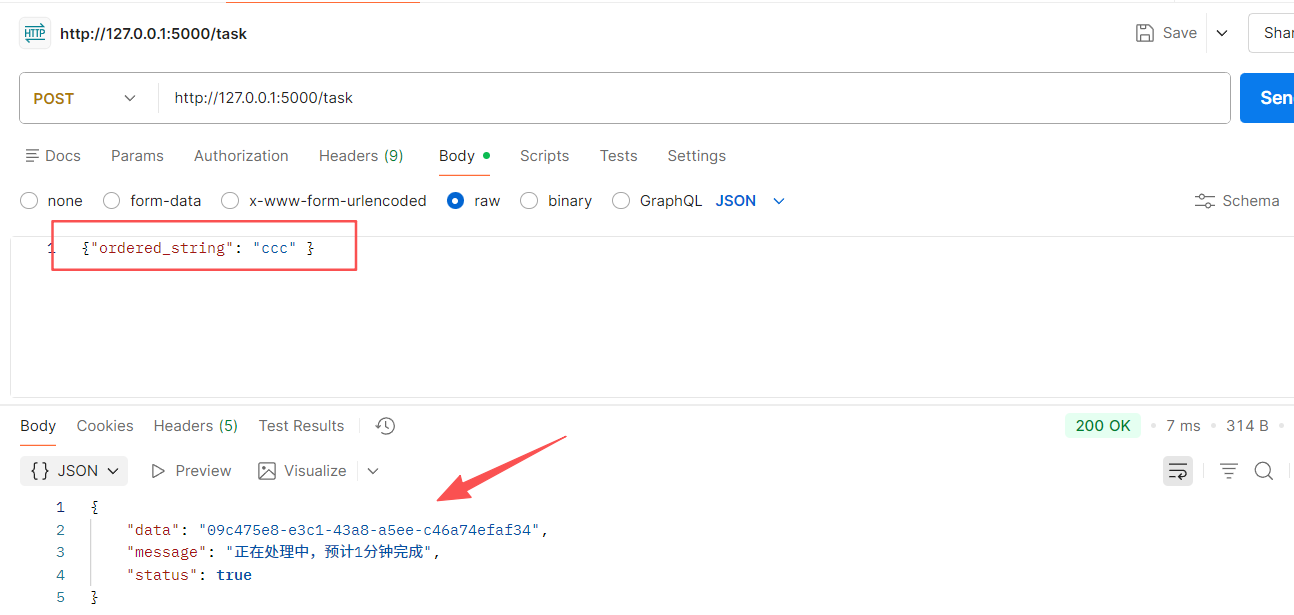
return jsonify({'status':True, 'data':tid, 'message':'正在处理中,预计1分钟完成'})
if __name__ == '__main__':
app.run()注意运行项目时要启动 Redis 服务:
python
redis-server.exe redis.windows.conf// 运行效果:
2 Worker 实现
角色职责:去队列中获取任务,执行并写入到结果队列。
python
import hashlib
import json
import redis
def get_task():
REDIS_CONN_PARAMS = {
"host": "127.0.0.1",
"password": "123456",
"port": 6379,
"encoding": "utf-8"
}
conn = redis.Redis(**REDIS_CONN_PARAMS)
data = conn.brpop("spider_task_list", timeout=10)
if not data:
return None
return json.loads(data[1].decode('utf-8'))
def set_result(tid, value):
# 建立连接
REDIS_CONN_PARAMS = {"host": "127.0.0.1", "password": "123456", "port": 6379, "encoding": "utf-8"}
conn = redis.Redis(**REDIS_CONN_PARAMS)
# 存入结果
conn.hset("spider_task_result", tid, value)
def run():
while True:
# 1.获取任务
task_dict = get_task()
print(task_dict)
if not task_dict:
continue
# 2. 执行任务处理
# {'tid':'...', 'data':'......'}
ordered_string = task_dict['data']
encrypt_string = ordered_string + "123456789"
obj = hashlib.md5(encrypt_string.encode('utf-8'))
sign = obj.hexdigest()
# 3.写入到结果队列(redis_result)
tid = task_dict['tid']
set_result(tid, sign)
if __name__ == '__main__':
run()// 运行效果:

3 调用者获取结果
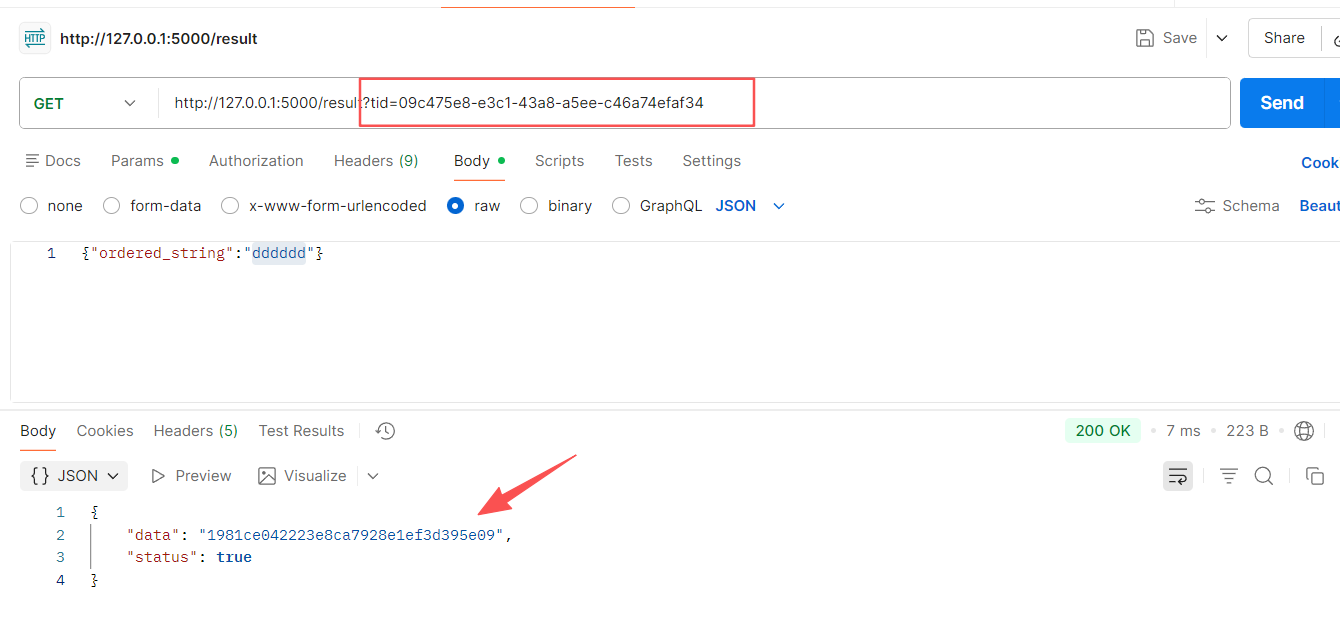
在app.py添加视图函数 result() 用于处理:用户拿着tid查询指定任务的处理结果。
获取参数 tid,链连接 redis-结果队列,从Hash中获取结果后,在原来字典中删除相应记录。
python
@app.route("/result", methods=["GET"])
def result():
'''
请求的url格式:/result?tid=......
'''
tid = request.args.get('tid')
if not tid:
return jsonify({'status': False, 'error': "参数错误"})
# 查询结果队列
conn = redis.Redis(host="127.0.0.1", password="123456", port=6379)
# 从 Hash 中获取结果
sign = conn.hget('spider_task_result', tid)
if not sign:
return jsonify({"status": True, 'data':"", "message":"未完成,请继续等待"})
sign_str = sign.decode('utf-8') # 获取的字节结果转化为字符串
conn.hdel('spider_task_result', tid) # 取出即焚
return jsonify({"status": True, "data": sign})// 运行效果:
优化
可以看redis的连接代码是有重复的,为了更加简洁与高效,我们考虑将redis的连接以及队列的名称 写成全局,另外redis的官方也提供了相关的连接池。
下面是**++使用redis连接池实现内置键值对数据库连接++**的优化代码:
Flask API部分代码如下:(Worker对应更改即可)
python
import json
import uuid
import redis
from flask import Flask, request, jsonify
app = Flask(__name__)
REDIS_POOL = redis.ConnectoinPool(host='127.0.0.1', port=6379, password='123456', encoding='utf-8')
TASK_QUEUE = "spider_task_list"
RESULT_QUEUE = "spider_result_dict"
@app.route("/task", methods=["POST"])
def task():
'''
请求的数据格式要求: {"ordered_string": "......"}
'''
ordered_string = request.json.get('ordered_string')
if not ordered_string:
return jsonify({"status":False, "error":"参数错误"})
# 创建任务 ID
tid = str(uuid.uuid4())
# 1.加入redis任务队列
task_dict = {'tid': tid, 'data': ordered_string}
conn = redis.Redis(connection_pool=REDIS_POOL)
conn.lpush(TASK_QUEUE, json.dumps(task_dict))
# 2. 返回给调用者
return jsonify({'status':True, 'data':tid, 'message':'正在处理中,预计1分钟完成'})
@app.route("/result", methods=["GET"])
def result():
'''
请求的url格式:/result?tid=......
'''
tid = request.args.get('tid')
if not tid:
return jsonify({'status': False, 'error': "参数错误"})
# 查询结果队列
conn = redis.Redis(connection_pool=REDIS_POOL)
# 从 Hash 中获取结果
sign = conn.hget(RESULT_QUEUE, tid)
if not sign:
return jsonify({"status": True, 'data':"", "message":"未完成,请继续等待"})
sign_str = sign.decode('utf-8') # 获取的字节结果转化为字符串
print(sign)
conn.hdel(RESULT_QUEUE, tid) # 取出即焚
return jsonify({"status": True, "data": sign_str})
if __name__ == '__main__':
app.run()笔记便利贴
🎤问题1:代码过程中混淆了 json.dump() 和 json.dumps()而导致报错,区分如下:
- json.dump(obj, fp):用于将对象序列化并写入文件,它需要第二个参数 fp(文件指针);
- json.dumps(obj) :用于将对象序列化为字符串(S代表String)
🎤问题2:Redis(Remote Dictionary Server)
Redis是一个开源的、高性能的内存键值对数据库。具有如下核心特征:
**全内存操作:**不同于传统数据库将数据存放在硬盘,Redis 将所有数据存储在RAM(内存)中,读写高效;
**键值对存储:**类似于Python的字典(dict),通过一个唯一的 Key 来存取对应的 Value;
**丰富的数据结构:**支持字符串、List、Set、Hash、ZSet等;
持久化机制: 虽然数据在内存,但Redis可以定期将数据快照保存到硬盘,防止断电导致数据丢失。
安装链接:Window下Redis的安装和部署详细图文教程(Redis的安装和可视化工具的使用)_redis安装-CSDN博客
📝注意事项:
① 队列的存放与取出要相对应,比如 hget()与hset(),lpush()-lpop()-rpush-rpop()等
② 若要清除 redis 中清除掉旧的错误类型的 Key:
pythonDEL spider_task_result # DEL Key的名字
总结
本文介绍了基于Redis实现的异步任务队列架构,用于解决Flask API在处理长耗时任务和高并发请求时的性能瓶颈。通过将任务拆分为API接收、Worker处理、API返回 三个模块,实现了请求的异步处理。
API接收请求后将任务参数存入Redis队列并立即返回任务ID,Worker进程持续监听队列并处理任务,最终将结果存入Redis。用户可通过任务ID查询处理结果。
文章详细展示了Flask API、Worker处理程序的具体实现代码,并提供了Redis连接池优化方案,同时指出了JSON序列化方法区别和Redis数据结构操作的注意事项。该架构有效解决了同步阻塞问题,提高了系统吞吐量和响应能力。