
🔥承渊政道: 个人主页
❄️个人专栏: 《C语言基础语法知识》 《数据结构与算法》
✨逆境不吐心中苦,顺境不忘来时路! 🎬 博主简介:

引言:在开源生态与后端开发、嵌入式开发、服务器运维等计算机核心领域,Linux 凭借其高稳定性、可定制性和开源特性,成为全球开发者的核心操作平台.不同于可视化集成开发环境(IDE)的一站式体验,Linux 的开发能力构建在一系列轻量、高效、可灵活组合的基础开发工具之上 ------ 这些工具是 Linux 开发体系的基石,也是开发者深入理解 Linux 设计思想、实现高效开发的必备核心能力.本文将围绕 Linux 开发全流程,系统讲解核心基础开发工具的使用方法、实用技巧与应用场景,帮助开发者摆脱对可视化工具的依赖,真正掌握 Linux 下的开发思维,为后续的复杂项目开发、系统运维与开源贡献筑牢基础.那么Liunx系统又有哪些方面的知识是需要学习和掌握的呢?废话不多说,带着这些疑问,下面跟着小编的节奏🎵一起学习吧!
目录
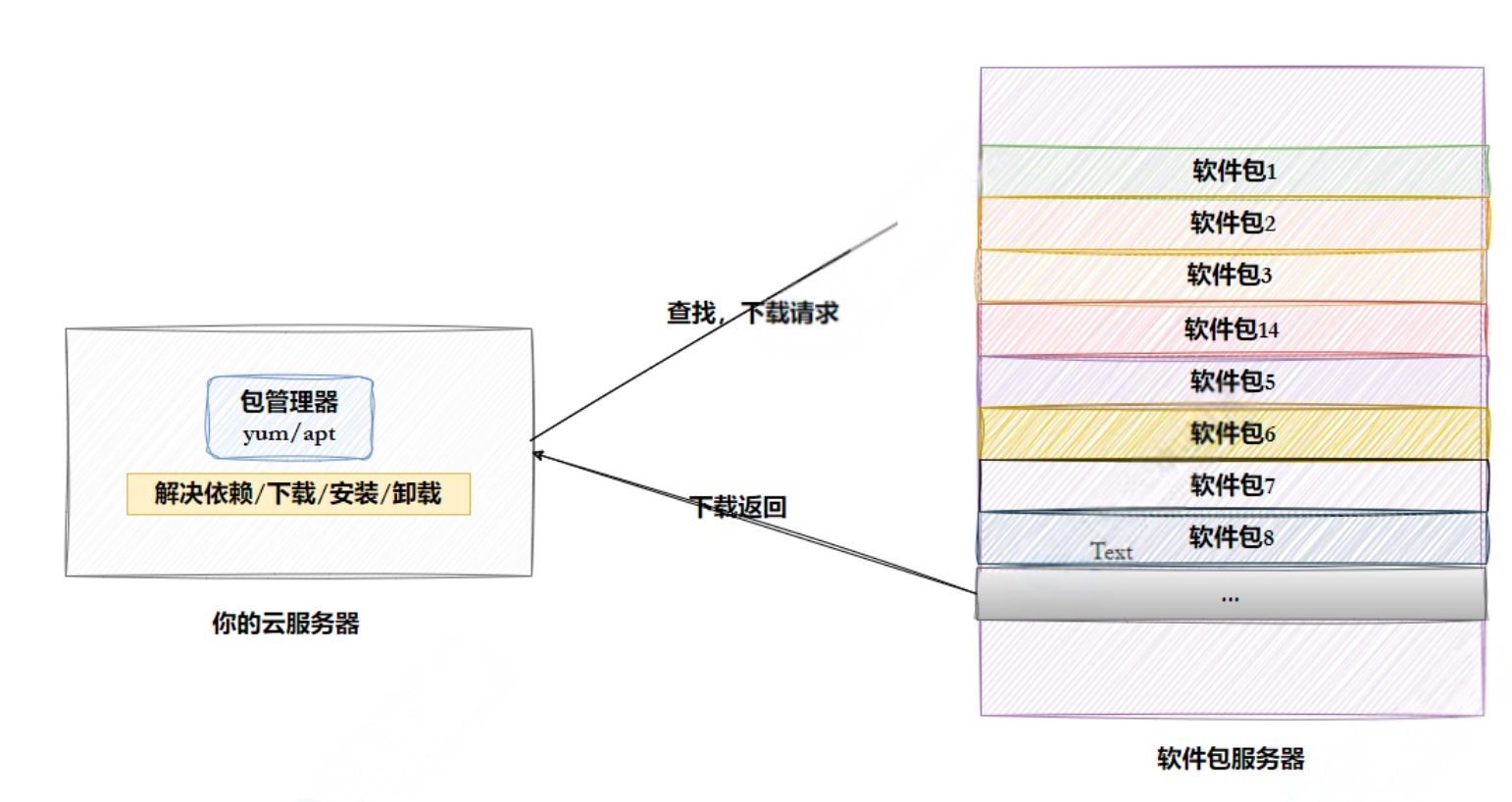
1.软件包管理器
在 Linux系统的开发、运维与日常使用中,软件包管理器是核心基础工具之一,它解决了 Linux 下软件安装、卸载、更新、依赖管理的核心痛点 ------ 如果手动下载软件源码编译或二进制文件安装,不仅要逐个处理依赖库、版本兼容问题,还会导致软件文件散落在系统各处,难以维护和清理.而软件包管理器通过标准化的软件包格式和统一的软件仓库,将软件的获取、安装、配置、升级、卸载全流程自动化,同时实现了依赖的自动检测与解决,是 Linux 系统管理软件的 "管家",也是开发者搭建开发环境、部署应用的必备工具.
1.1什么是软件包?
①在Linux下安装软件,⼀个通常的办法是下载到程序的源代码,并进⾏编译,得到可执⾏程序.
②但是这样太⿇烦了,于是有些⼈把⼀些常⽤的软件提前编译好,做成软件包(可以理解成windows上的安装程序)放在⼀个服务器上,通过包管理器可以很⽅便的获取到这个编译好的软件包,直接进⾏安装.
③软件包和软件包管理器,就好⽐ "App" 和 "应⽤商店" 这样的关系.
④yum(Yellow dog Updater, Modified)是Linux下⾮常常⽤的⼀种包管理器. 主要应⽤在Fedora,RedHat,Centos等发⾏版上.
⑤Ubuntu:主要使⽤apt(Advanced Package Tool)作为其包管理器.apt同样提供了⾃动解决依赖关系、下载和安装软件包的功能.
⑥软件包:将软件的可执行文件、配置文件、依赖库、说明文档等按固定格式封装的压缩文件,Linux 下主要有二进制包(已编译,可直接运行,如.deb、.rpm)和源码包(需手动编译,如.src.rpm),开发中常用二进制包提升效率.
⑦Linux 发行版主要分为Debian 系和RedHat 系,两大体系拥有各自独立的包格式和包管理器,底层为基础包管理工具(仅处理单个包,不解决依赖),上层为高级包管理工具(解决依赖,支持网络从仓库下载),开发中主要使用上层工具.
⑧Debian 系(.deb 包格式)
代表发行版:Ubuntu、Debian、Deepin、Kali Linux(开发/渗透常用)
底层工具:dpkg(直接操作.deb 包,无网络依赖管理能力,如dpkg -i 包名.deb)
上层核心工具:apt /apt-get(apt 是 apt-get 的升级版本,命令更简洁,输出更友好)
⑨RedHat 系(.rpm 包格式)
代表发行版:CentOS、RHEL、Fedora、Rocky Linux(服务器运维常用)
底层工具:rpm(直接操作.rpm 包,不解决依赖,如rpm -ivh 包名.rpm)
上层核心工具:yum /dnf(dnf 是yum 的升级版本,CentOS 8+、Fedora 默认使用 dnf,向下兼容 yum 命令).
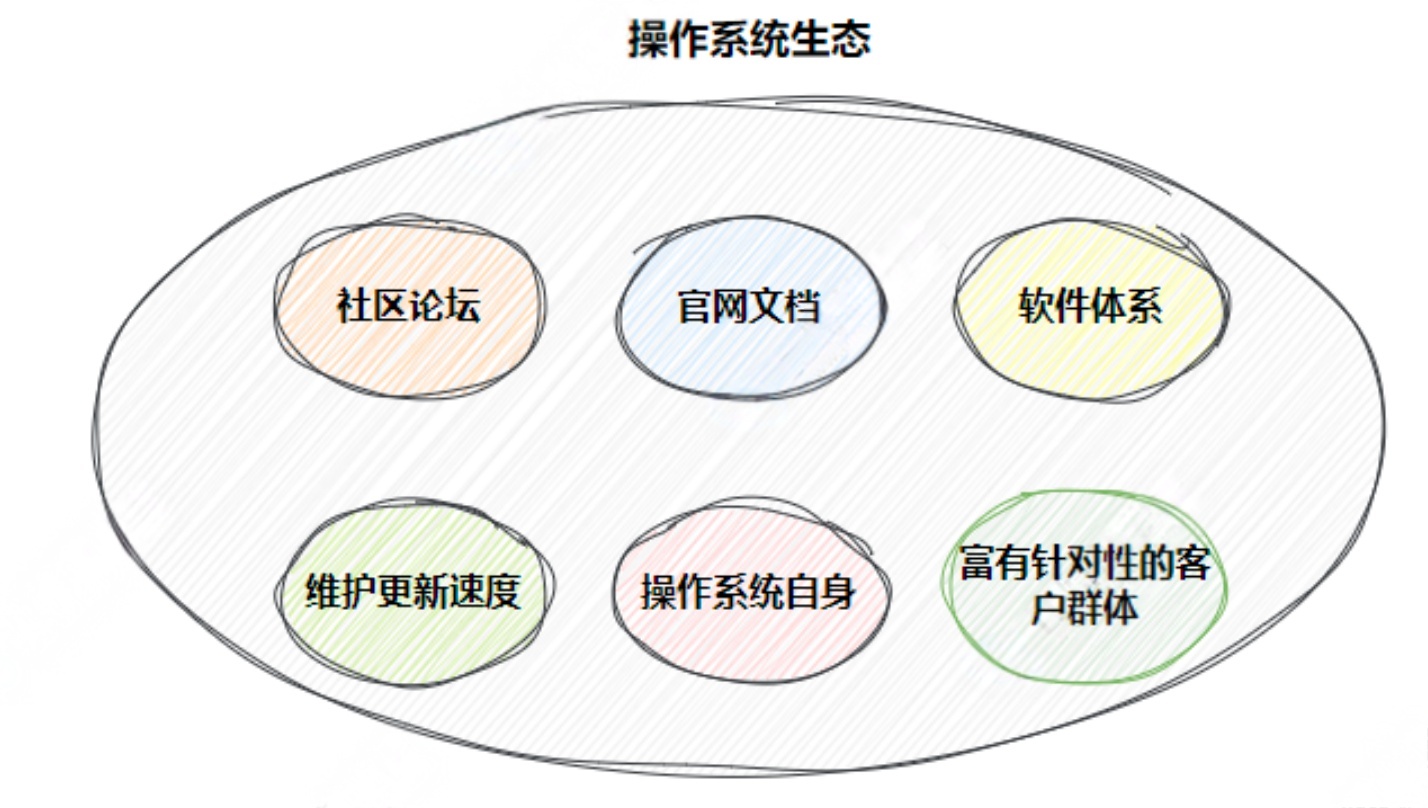
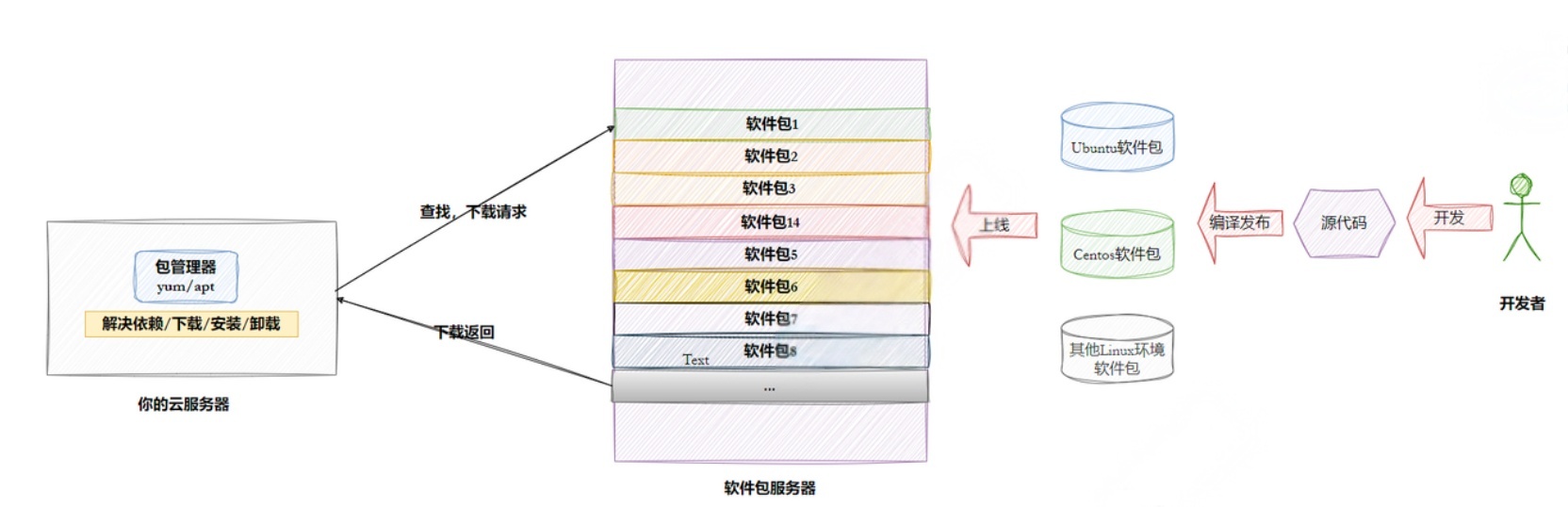
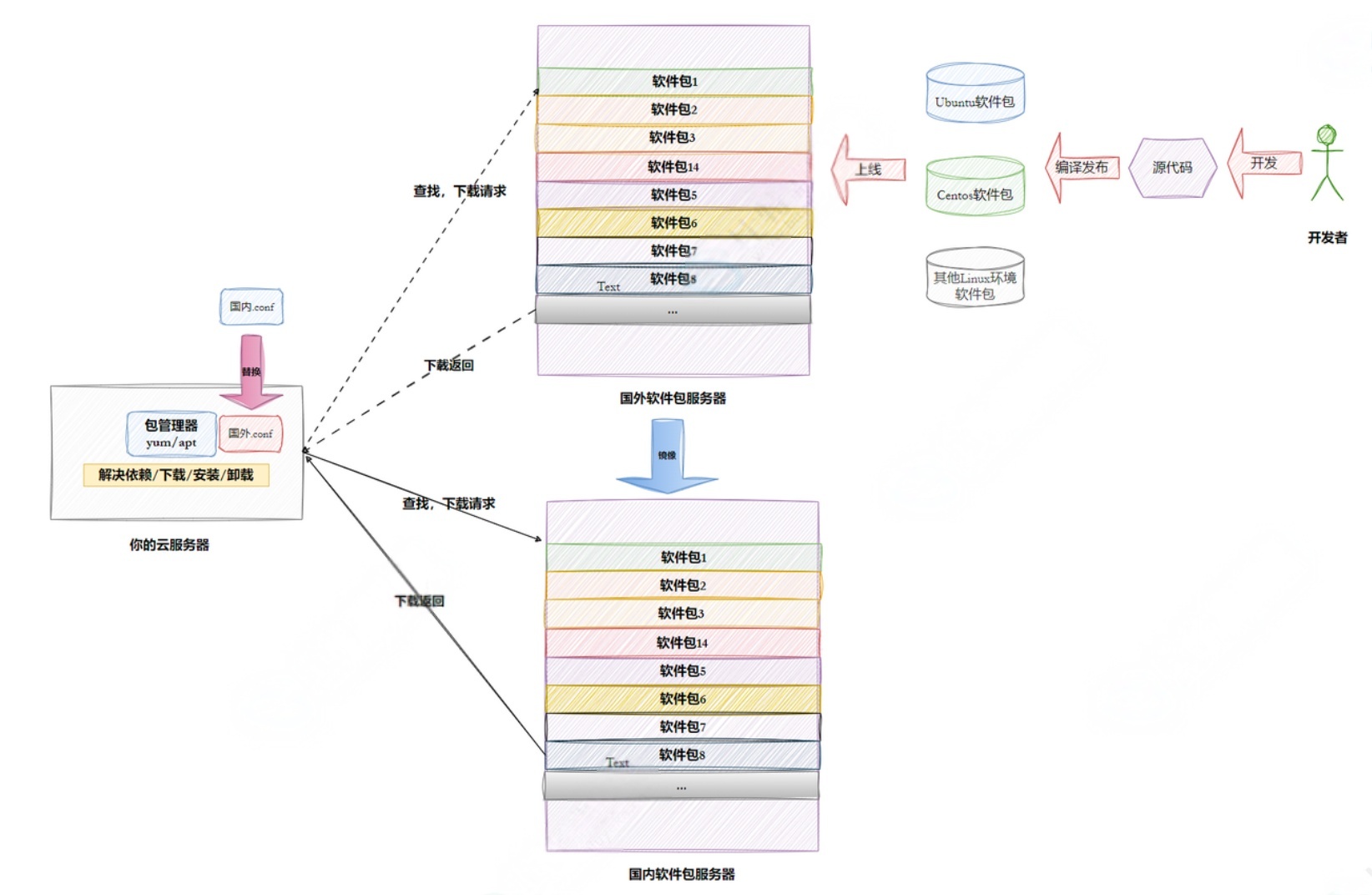
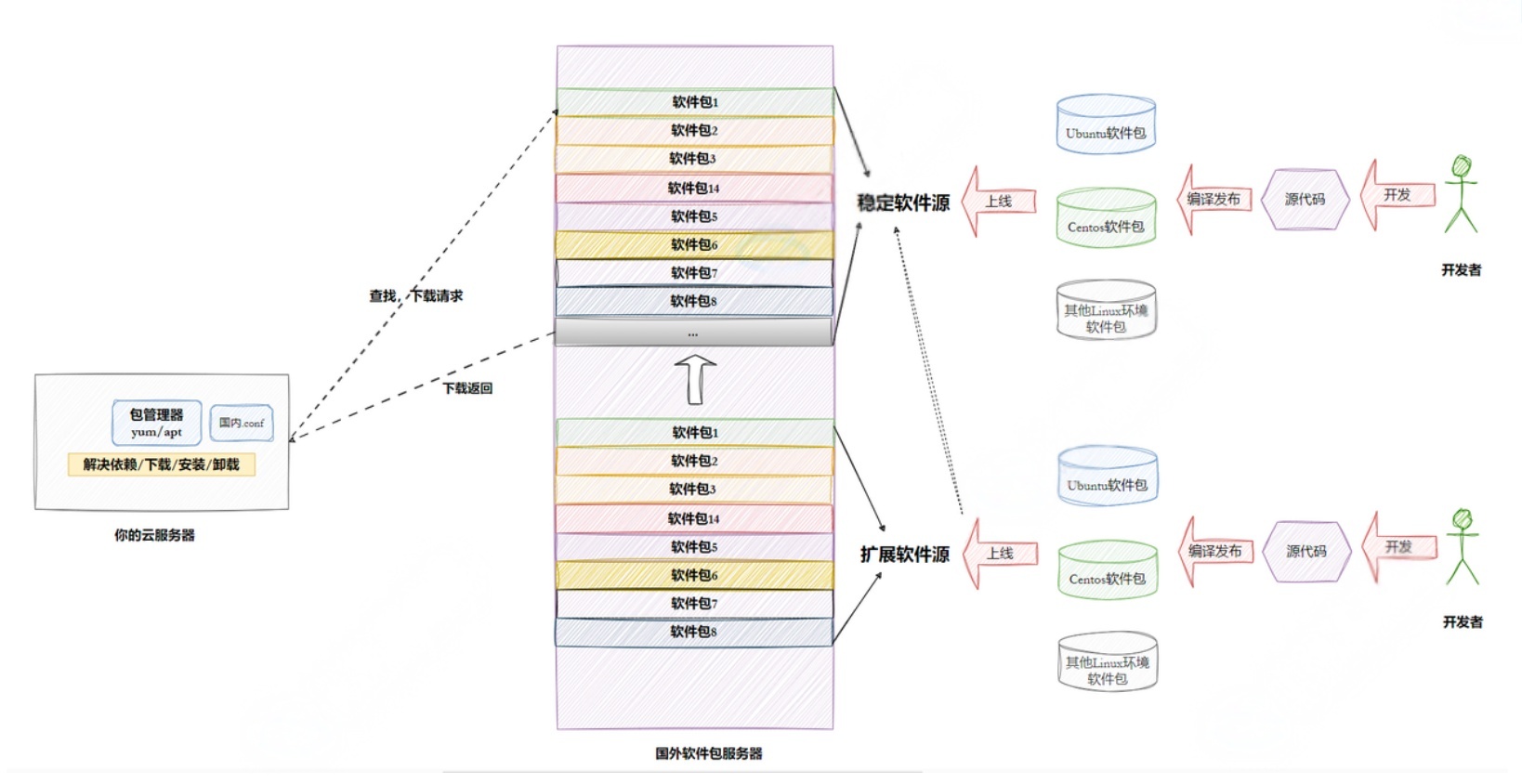
1.2Linux系统软件⽣态
Linux下载软件的过程(Ubuntu、Centos、other)
操作系统的好坏评估--- ⽣态问题
为什么会有⼈免费特定社区提供软件,还发布?还提供云服务器让你下载?
软件包依赖的问题
国内镜像源
💡以下是⼀些国内Linux软件安装源的官⽅链接:
1️⃣阿⾥云官⽅镜像站官⽅链接:阿里云官方镜像站
阿⾥云提供了丰富的Linux发⾏版镜像,包括CentOS、Ubuntu、Debian等,⽤⼾可以通过该镜像站快速下载和更新软件包.
2️⃣清华⼤学开源软件镜像站
官⽅链接:清华⼤学开源软件镜像站
清华⼤学镜像站提供了多种Linux发⾏版的镜像,以及Python、Perl、Ruby等编程语⾔的扩展包.该镜像站还提供了丰富的⽂档和教程,帮助⽤⼾更好地使⽤这些软件包.
3️⃣中国科学技术⼤学开源镜像站
官⽅链接:中国科学技术⼤学开源镜像站
中科⼤镜像站提供了多种Linux发⾏版的镜像,以及常⽤的编程语⾔和开发⼯具.⽤⼾可以通过该镜像站⽅便地获取所需的软件包和⼯具.
4️⃣中国科学院软件研究所镜像站(ISCAS)
官⽅链接:中国科学院软件研究所镜像站
ISCAS镜像站提供了多种Linux发⾏版、编程语⾔和开发⼯具的镜像.⽤⼾可以通过该镜像站快速获取所需的软件包和更新.
5️⃣上海交通⼤学开源镜像站
官⽅链接:上海交通⼤学开源镜像站
上海交⼤镜像站提供了丰富的Linux软件资源,包括多种发⾏版的镜像和软件仓库.⽤⼾可以通过该镜像站⽅便地下载和安装所需的软件包.
1.3yum具体操作
yum(Yellowdog Updater Modified)是 RedHat 系 Linux 专属的高级包管理器(底层基于 rpm),核心优势是自动解决软件依赖、支持从远程仓库网络安装,是 CentOS 7、RHEL 7 等发行版的默认包管理工具(CentOS 8+、RHEL 8+ 主推 DNF,完全兼容 YUM 命令,操作一致).
以下所有操作均需要 sudo 超级用户权限(系统级软件操作要求),示例均选用开发/运维高频软件(如 gcc、htop、nginx),兼顾基础使用和开发/运维实用场景,命令可直接复制执行.
1.3.1查看软件包
通过yum list 命令可以罗列出当前⼀共有哪些软件包.由于包的数⽬可能⾮常之多,这⾥我们需要使⽤grep命令只筛选出我们关注的包.例如:
bash
# Centos
$ yum list | grep lrzsz
#由于小编的是ubuntu系统,centos系统可以输入上面的指令进行查看,下面是小编查看出来的信息
root@VM-0-3-ubuntu:~# apt search lrzsz
Sorting... Done
Full Text Search... Done
cutecom/jammy 0.30.3-1build1 amd64
Graphical serial terminal, like minicom
lrzsz/jammy,now 0.12.21-10 amd64 [installed]
Tools for zmodem/xmodem/ymodem file transfer
root@VM-0-3-ubuntu:~# apt show lrzsz
Package: lrzsz
Version: 0.12.21-10
Priority: optional
Section: universe/comm
Origin: Ubuntu
Maintainer: Ubuntu Developers <ubuntu-devel-discuss@lists.ubuntu.com>
Original-Maintainer: Martin A. Godisch <godisch@debian.org>
Bugs: https://bugs.launchpad.net/ubuntu/+filebug
Installed-Size: 531 kB
Depends: libc6 (>= 2.15)
Suggests: minicom
Homepage: https://ohse.de/uwe/software/lrzsz.html
Download-Size: 74.8 kB
APT-Manual-Installed: yes
APT-Sources: http://mirrors.tencentyun.com/ubuntu jammy/universe amd64 Packages
Description: Tools for zmodem/xmodem/ymodem file transfer
Lrzsz is a cosmetically modified zmodem/ymodem/xmodem package built
from the public-domain version of Chuck Forsberg's rzsz package.
.
These programs use error correcting protocols ({z,x,y}modem) to send
(sz, sx, sb) and receive (rz, rx, rb) files over a dial-in serial port
from a variety of programs running under various operating systems.1️⃣
apt search lrzsz这是
apt的搜索命令,用于在软件仓库中查找包含关键词lrzsz的软件包.
输出解析 :
cutecom/jammy 0.30.3-1build1 amd64:一个图形化串口终端工具,是搜索结果的附带项.
lrzsz/jammy,now 0.12.21-10 amd64 [installed]:目标软件包,[installed]标记说明它已经安装在当前系统中 .
Tools for zmodem/xmodem/ymodem file transfer:对lrzsz的核心描述------它是基于zmodem/xmodem/ymodem协议的文件传输工具.2️⃣
apt show lrzsz这是
apt的详情命令,用于查看lrzsz包的完整信息,输出里的关键字段解释:
| 字段 | 含义 |
|---|---|
Package: lrzsz |
软件包名称 |
Version: 0.12.21-10 |
当前安装的版本号 |
Installed-Size: 531 kB |
安装后占用的磁盘空间 |
Depends: libc6 (>= 2.15) |
运行依赖(仅依赖系统基础库 libc6,兼容性好) |
Description |
详细说明:lrzsz 是一个修改版的文件传输工具,支持 z/x/y modem 错误纠正协议,通过串口传输文件。它包含两个核心命令: - rz:接收文件 (从本地向服务器上传文件) - sz:发送文件(从服务器向本地下载文件) |
1.3.2安装软件
通过 yum,我们可以通过很简单的⼀条命令完成 gcc 的安装.
bash
# Centos
$ sudo yum install -y lrzsz
# Ubuntu
root@VM-0-3-ubuntu:~# sudo apt install -y lrzsz
Reading package lists... Done
Building dependency tree... Done
Reading state information... Done
lrzsz is already the newest version (0.12.21-10).
0 upgraded, 0 newly installed, 0 to remove and 190 not upgraded.注意事项:
①yum/apt 会⾃动找到都有哪些软件包需要下载,这时候敲 "y" 确认安装.
②出现 "complete" 字样或者中间未出现报错,说明安装完成.(由于小编已经提前装过了,所以会显示以及是最新版的)
③安装软件时由于需要向系统⽬录中写⼊内容,⼀般需要 sudo 或者切到 root 账⼾下才能完成.
④yum/apt安装软件只能⼀个装完了再装另⼀个.正在yum/apt安装⼀个软件的过程中,如果再尝试⽤.
⑤yum/apt安装另外⼀个软件,yum/apt会报错.
⑥如果 yum/apt报错,请⾃⾏百度.
1.3.3卸载软件
bash
# Centos
sudo yum remove [-y] lrzsz
# Ubuntu
sudo apt remove [-y] lrzsz1.3.4注意事项
bash
#关于yum/apt的所有操作必须保证主机(虚拟机)⽹络畅通!!! 可以通过ping指令验证
ping www.baidu.com
#当天yum/apt也能离线安装,但是和我们当前⽆关,暂不关⼼.1.4安装源
📌CentOS(RedHat 系,yum/dnf 包管理器)
核心源配置目录
所有源配置文件目录:/etc/yum.repos.d/
系统的所有仓库配置文件都存放在这里,每个源对应一个.repo 格式的文件,常见核心源文件包括:
CentOS-Base.repo:系统默认的基础软件仓库
epel.repo:EPEL 扩展源(安装 epel-release 后自动生成)
📌Ubuntu(Debian 系,apt 包管理器)
核心源配置文件
主配置文件路径:/etc/apt/sources.list
这是系统默认的主源配置文件,定义了官方或第三方软件仓库的地址,所有 apt 操作都会优先读取这个文件.
额外源配置目录:/etc/apt/sources.list.d/
用于存放第三方仓库的配置文件(如 PPA 源、Docker 源、Node.js 源等),每个源对应一个.list 格式的文件,避免主配置文件过于臃肿.
bash
# centos安装扩展源
$ ll /etc/yum.repos.d/
total 16
-rw-r--r-- 1 root root 676 Oct 8 20:47 CentOS-Base.repo # 标准源
-rw-r--r-- 1 root root 230 Aug 27 10:31 epel.repo # 扩展源
# ubuntu安装扩展源
$ cat /etc/apt/sources.list # 标准源
$ ll /etc/apt/sources.list.d/ # 扩展源
#更新安装源,现场说明原理即可.云服务器不⽤考虑,因为软件源都是国内的了.2.编辑器Vim
Vim是Linux 系统默认自带的终端文本编辑器,是经典编辑器 Vi 的增强版(Vi Improved),凭借无图形化依赖、操作高效、定制性强的特点,成为 Linux 服务器开发、嵌入式开发、运维的核心工具 ------ 在无图形界面的远程服务器上,Vim 是编写 / 修改代码、配置文件的唯一选择.
2.1Linux编辑器-vim使⽤
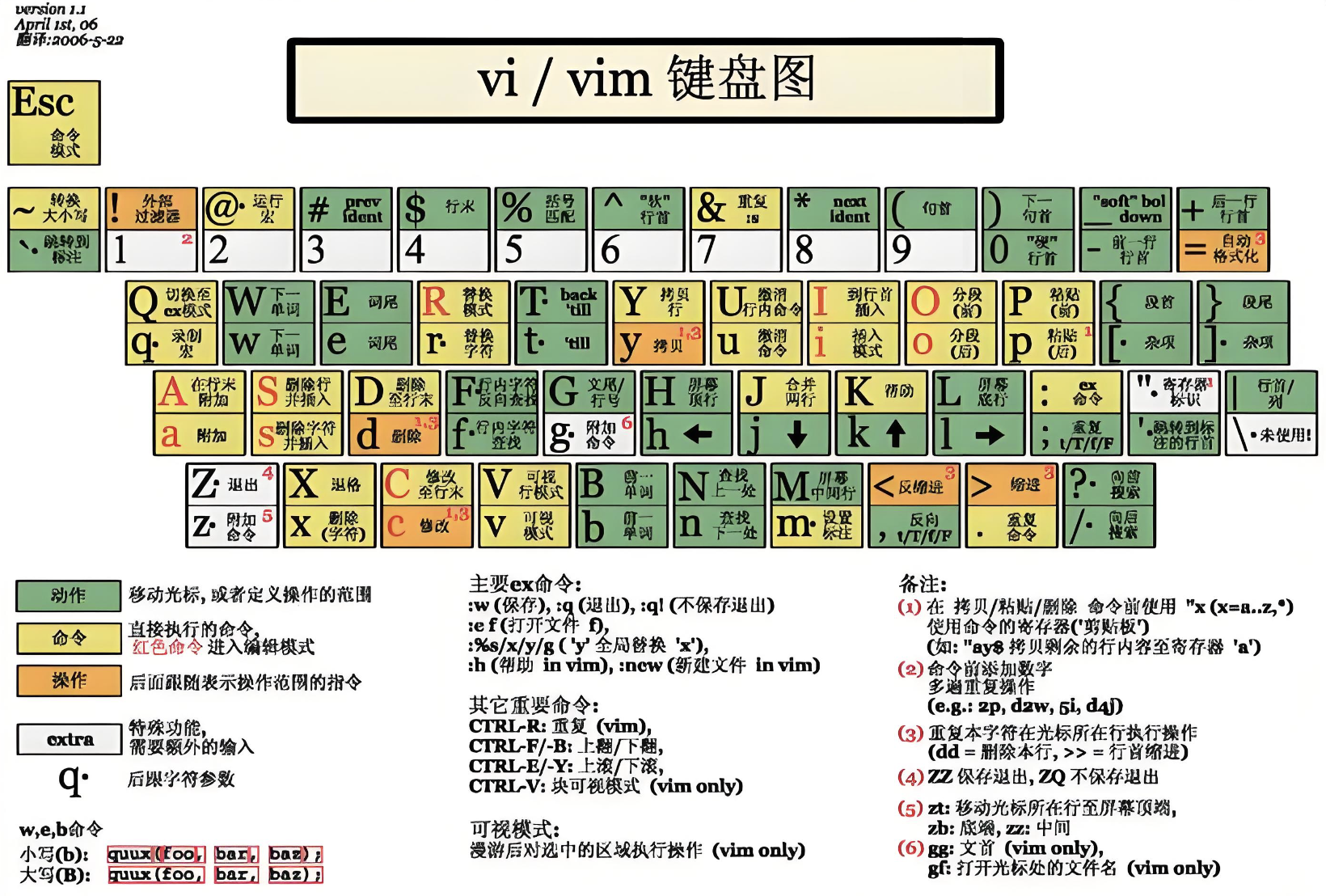
vi/vim的区别简单点来说,它们都是多模式编辑器,不同的是vim是vi的升级版本,它不仅兼容vi的所有指令,⽽且还有⼀些新的特性在⾥⾯.例如语法加亮,可视化操作不仅可以在终端运⾏,也可以运⾏于x window、 mac os、 windows,我们统⼀按照vim来进⾏介绍.
下面这个是过去的键盘布局,我们能够发现上下左右的移动对应键盘的k/j/h/l键,正是因为这个独特的地方,我们需要深入学习vim的使用,才能更好的适应Linux系统的学习.

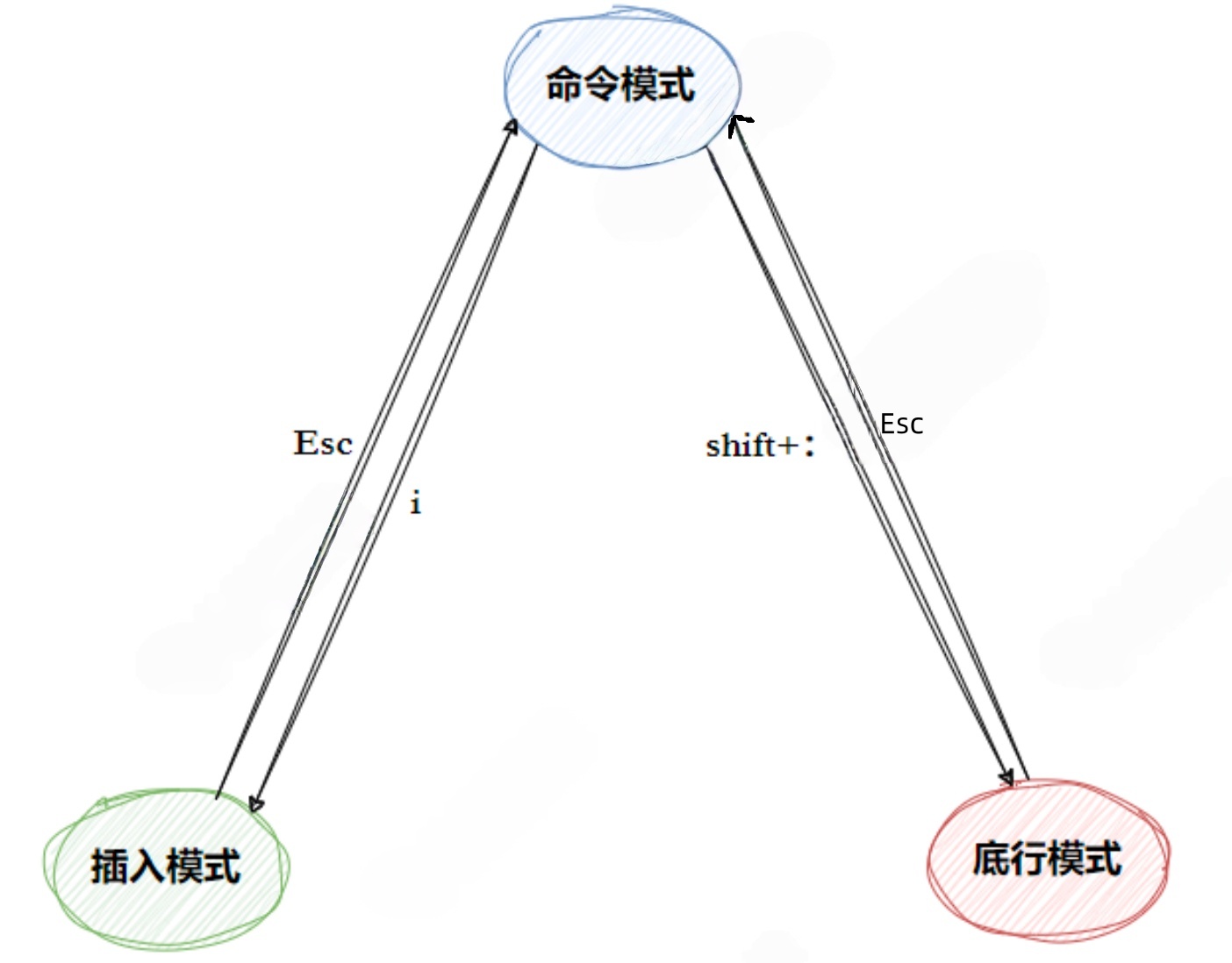
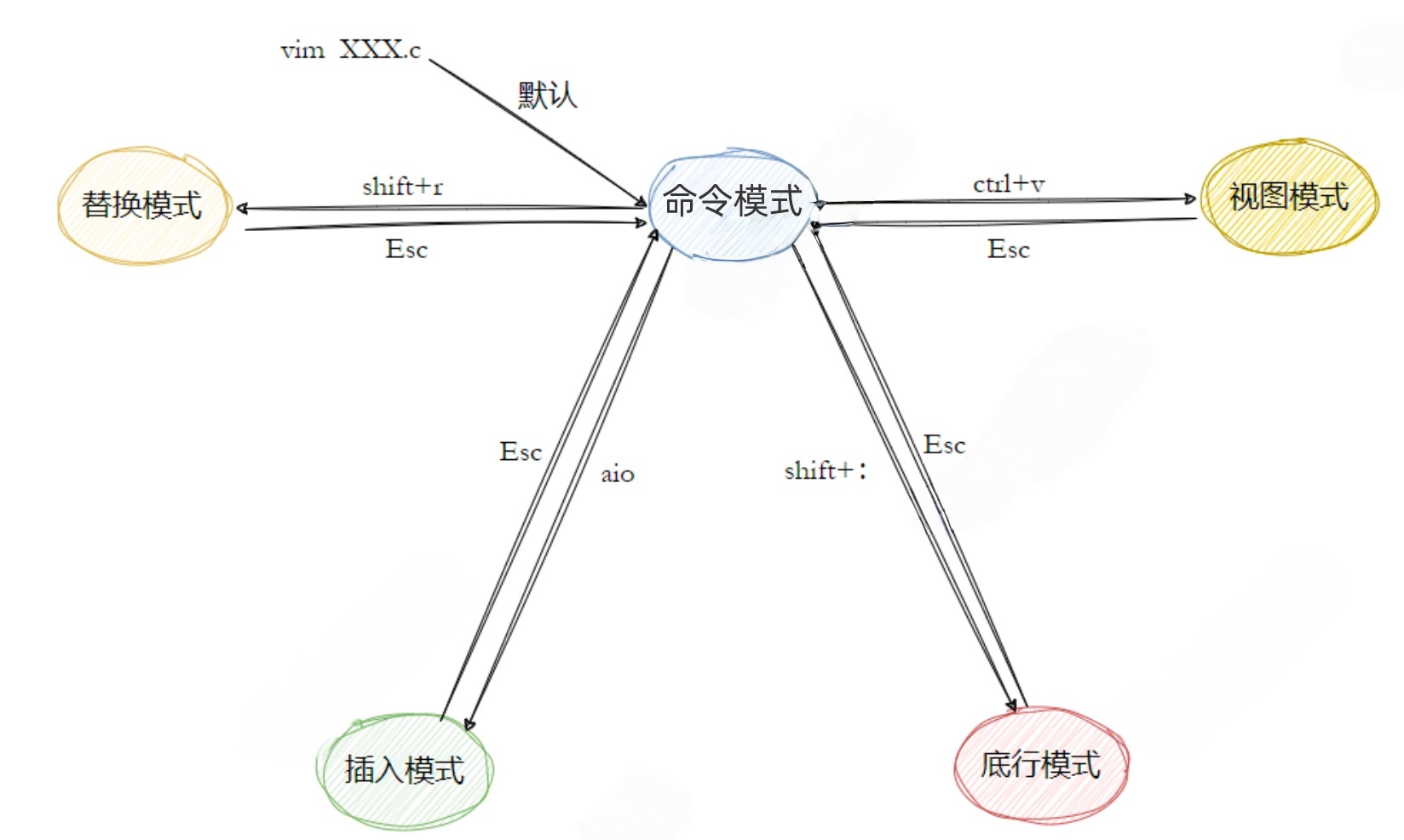
2.2vim的基本概念
这里我们介绍vim的三种模式(其实有好多模式,⽬前掌握这3种即可),分别是命令模式(command
mode)、插⼊模式(Insert mode)和底⾏模式(last line mode),各模式的功能区分如下:
1️⃣正常/普通/命令模式(Normal mode)
控制屏幕光标的移动,字符、字或⾏的删除,移动复制某区段及进⼊Insert mode下,或者到 last line mode
2️⃣插⼊模式(Insert mode)
只有在Insert mode下,才可以做⽂字输⼊,按ESC键可回到命令⾏模式.该模式是我们后⾯⽤的最频繁的编辑模式.
3️⃣末⾏模式(last line mode)
⽂件保存或退出,也可以进⾏⽂件替换,找字符串,列出⾏号等操作. 在命令模式下,shift+: 即可进⼊该模式.要查看你的所有模式:打开 vim,底⾏模式直接输⼊:help vim-modes 这⾥⼀共有12种模式:six BASIC modes和six ADDITIONAL modes.
2.3vim的基本操作
1️⃣进⼊vim,在系统提示符号输⼊vim及⽂件名称后,进⼊vim全屏幕编辑画⾯:vim test.c(你自己创建文件名称)
不过有⼀点要特别注意,就是你进⼊vim之后,是处于正常模式,你要切换到插⼊模式才能够输⼊⽂字.
2️⃣正常模式切换⾄插⼊模式
输⼊a
输⼊i
输⼊o
3️⃣插⼊模式切换⾄正常模式
⽬前处于插⼊模式,就只能⼀直输⼊⽂字,如果发现输错了字,想⽤光标键往回移动,将该字删除,可以先按⼀下ESC键转到正常模式再删除⽂字.当然,也可以直接删除.
4️⃣正常模式切换⾄末⾏模式
shift + ;,其实就是输⼊:
5️⃣退出vim及保存⽂件,在正常模式下,按⼀下:冒号键进⼊Last line mode,例如:
: w(保存当前⽂件)
: wq(输⼊wq,存盘并退出vim)
: q!(输⼊q!,不存盘强制退出vim)
2.4vim正常模式命令集
1️⃣插⼊模式
按i切换进⼊插⼊模式insert mode,按"i"进⼊插⼊模式后是从光标当前位置开始输⼊⽂件;
按a进⼊插⼊模式后,是从⽬前光标所在位置的下⼀个位置开始输⼊⽂字;
按o进⼊插⼊模式后,是插⼊新的⼀⾏,从⾏⾸开始输⼊⽂字.
2️⃣从插⼊模式切换为命令模式
按ESC键.
3️⃣移动光标
vim可以直接⽤键盘上的光标来上下左右移动,但正规的vim是⽤⼩写英⽂字⺟h、j、k、l,分别控制光标左、下、上、右移⼀格.
按G:移动到⽂章的最后
按$:移动到光标所在⾏的"⾏尾"
按^:移动到光标所在⾏的"⾏⾸"
按w:光标跳到下个字的开头
按e:光标跳到下个字的字尾
按b:光标回到上个字的开头
按#l:光标移到该⾏的第#个位置,如:5l,56l
按gg:进⼊到⽂本开始
按shift+g:进⼊⽂本末端
按ctrl+b:屏幕往"后"移动⼀⻚
按ctrl+f:屏幕往"前"移动⼀⻚
按ctrl+u:屏幕往"后"移动半⻚
按ctrl+d:屏幕往"前"移动半⻚
4️⃣删除⽂字
x:每按⼀次,删除光标所在位置的⼀个字符
#x:例如,6x表⽰删除光标所在位置的"后⾯(包含⾃⼰在内)"6个字符
X:⼤写的X,每按⼀次,删除光标所在位置的"前⾯"⼀个字符
#X:例如,20X,表示删除光标所在位置的"前⾯"20个字符
dd:删除光标所在⾏
#dd:从光标所在⾏开始删除#⾏
5️⃣复制
yw:将光标所在之处到字尾的字符复制到缓冲区中.
#yw:复制#个字到缓冲区
yy:复制光标所在⾏到缓冲区.
#yy:例如,6yy表示拷⻉从光标所在的该⾏"往下数"6⾏⽂字.
p:将缓冲区内的字符贴到光标所在位置.注意:所有与"y"有关的复制命令都必须与"p"配合才能完成复制与粘贴功能.
6️⃣替换
r:替换光标所在处的字符.
R:替换光标所到之处的字符,直到按下ESC键为⽌.
7️⃣撤销上⼀次操作
u:如果您误执⾏⼀个命令,可以⻢上按下u,回到上⼀个操作.按多次"u"可以执⾏多次回复.
ctrl + r:撤销的恢复
8️⃣更改
cw:更改光标所在处的字到字尾处
c#w:例如,c3w表示更改3个字
9️⃣跳⾄指定的⾏
ctrl+g列出光标所在⾏的⾏号.
#G:例如,15G,表示移动光标⾄⽂章的第15⾏⾸.
2.5vim末⾏模式命令集
在使⽤末⾏模式之前,请记住先按ESC键确定您已经处于正常模式,再按:冒号即可进⼊末⾏模式.
1️⃣列出⾏号
set nu:输⼊set nu后,会在⽂件中的每⼀⾏前⾯列出⾏号.
跳到⽂件中的某⼀⾏
#:#号表示⼀个数字,在冒号后输⼊⼀个数字,再按回⻋键就会跳到该⾏了,如输⼊数字15,再回⻋,就会跳到⽂章的第15⾏.
2️⃣查找字符
/关键字:先按/键,再输⼊您想寻找的字符,如果第⼀次找的关键字不是您想要的,可以⼀直按n会往后寻找到您要的关键字为⽌.
?关键字:先按?键,再输⼊您想寻找的字符,如果第⼀次找的关键字不是您想要的,可以⼀直按n会往前寻找到您要的关键字为⽌.
问题:∕ 和 ?查找有和区别?操作实验⼀下
/关键词 # 从光标处向下查找,示例:/main 查找所有main关键字.
?关键词 # 从光标处向上查找.
3️⃣保存⽂件
w:在冒号输⼊字⺟w就可以将⽂件保存起来
离开vim
q:按q就是退出,如果⽆法离开vim,可以在q后跟⼀个!强制离开vim.
wq:⼀般建议离开时,搭配w⼀起使⽤,这样在退出的时候还可以保存⽂件.
2.6vim操作总结
1️⃣Vim 核心:三种基础模式Vim 与其他编辑器(如记事本、VS Code)的最大区别是多模式 ,初学者最易踩坑的点就是模式切换错误 (比如在默认模式直接输入,导致终端无反应/乱码).
所有操作的前提是明确当前模式 ,核心只需掌握3种基础模式,模式间通过简单按键快速切换,无需记忆复杂命令.
| 模式名称 | 进入方式 | 核心作用 | 退出/切换方式 |
|---|---|---|---|
| 普通模式 | 启动 Vim 后默认进入; 任何模式按 Esc 键 |
光标快速移动、复制、粘贴、删除、撤销、行操作(Vim 高效的核心),不可直接输入文字 | 按 i/a/o 等进入插入模式; 按 : 进入末行模式 |
| 插入模式 | 普通模式下按 i/a/o/I/A/O 之一 |
纯文本编辑,和普通编辑器一致,可输入/修改代码、文字 | 按 Esc 键返回普通模式(最常用) |
| 末行模式 | 普通模式下按 :(冒号) |
保存文件、退出 Vim、查找替换、行号显示、配置临时生效等功能性操作 | 按 Esc 键返回普通模式; 执行命令后自动返回 |
2️⃣初学者必记:模式切换核心键
Esc:万能返回键 ,无论在插入/末行模式,按Esc均可回到普通模式(不确定当前模式时,多按几次Esc即可);
普通模式 → 插入模式 :记i或a即可(开发最常用);
普通模式 → 末行模式 :唯一入口是按:(冒号),光标会自动跳到终端底部,等待输入命令.核心退出命令(末行模式执行)
所有退出命令都需先按Esc回到普通模式,再按:进入末行模式,输入命令后按回车执行.
| 退出命令 | 适用场景 |
|---|---|
:q |
退出 Vim,仅适用于文件未修改的情况(文件修改后执行会报错,防止误退出) |
:q! |
强制退出 Vim,放弃所有文件修改(新手改错内容时,直接强制退出即可) |
:wq |
保存文件并退出 Vim(开发最常用,修改后正常保存退出) |
:x |
等价于 :wq,保存并退出,更简洁 |
3️⃣普通模式:高效操作核心(纯键盘操作,摆脱鼠标)
普通模式是 Vim 的精髓,所有光标移动、复制、粘贴、删除、撤销 均在此模式完成,命令多为单个按键/组合键 ,执行速度极快.
①光标快速移动无需按方向键,用键盘核心区域按键即可移动,适配盲打,提升效率.
| 操作 | 命令 | 适用场景 |
|---|---|---|
| 上下左右移动 | k/j/h/l |
替代方向键,盲打必备(上k下j左h右l) |
| 跳到行首 | 0(数字0) |
快速定位当前行开头 |
| 跳到行尾 | $ |
快速定位当前行结尾(开发常用) |
| 跳到文件首行 | gg |
直接跳到整个文件的第一行 |
| 跳到文件末行 | G |
直接跳到整个文件的最后一行 |
| 跳到指定行 | 行号 + G |
示例:50G 跳到50行(调试代码必备) |
| 按单词移动 | w |
跳到下一个单词的开头(写代码跳变量/函数) |
②复制 & 粘贴Vim 中复制称为拉(yank),粘贴称为放(put),命令简洁,支持单行/多行/选中复制,记核心即可.
| 操作 | 命令 | 示例/说明 |
|---|---|---|
| 复制当前行 | yy |
最常用,复制光标所在的整行 |
| 复制指定多行 | 数字 + yy |
示例:3yy 复制光标开始的3行 |
| 粘贴到光标下一行 | p |
最常用,复制后按p直接粘贴 |
| 粘贴到光标上一行 | P |
大写P,向上粘贴 |
③删除 & 撤销Vim 中删除兼具剪切功能------删除的内容会自动缓存,按
p可粘贴,无需单独记剪切命令.
| 操作 | 命令 | 示例/说明 |
|---|---|---|
| 删除当前行 | dd |
最常用,删除光标所在整行(可粘贴) |
| 删除指定多行 | 数字 + dd |
示例:5dd 删除光标开始的5行 |
| 删除光标后单个字符 | x |
替代删除键(Backspace),删除光标所在字符 |
| 撤销上一步操作 | u |
最常用,改错内容时撤销(无限撤销) |
| 恢复撤销操作 | Ctrl + r |
撤销多了,恢复上一步(反撤销) |
④行操作
| 操作 | 命令 | 说明 |
|---|---|---|
| 整行缩进 | >> |
光标所在行向右缩进(代码格式化) |
| 整行反缩进 | << |
光标所在行向左缩进 |
| 多行缩进 | 数字 + >> |
示例:4>> 缩进4行 |
4️⃣插入模式:纯编辑(记6个进入方式,适配不同场景)
普通模式下按以下按键进入插入模式,无需记全,记
i和a即可满足90%场景,其余为进阶适配.
| 命令 | 进入位置 | 适用场景 |
|---|---|---|
i |
光标前方 | 最常用,直接在光标处开始输入 |
a |
光标后方 | 光标在字符末尾时,快速向后输入 |
o |
光标下一行新建空白行 | 最实用的换行,无需按回车,直接新建行并进入编辑 |
O |
光标上一行新建空白行 | 向上插入空白行,编辑上方内容 |
I |
光标所在行行首 | 快速跳到行首开始输入(如加注释) |
A |
光标所在行行尾 | 快速跳到行尾开始输入(如加分号、括号) |
5️⃣末行模式:功能性操作(高频10个命令,记核心)
普通模式按
:进入,光标跳至终端底部,输入命令后按回车执行,以下为开发/运维最常用的命令,覆盖保存、查找、替换、配置等核心需求.
①基础文件操作
bash
:w # 保存文件(不退出,开发中随时保存,防止断网/死机丢失内容)
:wq # 保存并退出(最常用)
:q! # 强制退出,放弃修改
:w 新文件名 # 另存为新文件(示例::w test_bak.c,将当前内容保存为test_bak.c)
②查找与替换
bash
# 1. 查找关键词(普通模式也可执行,无需进末行模式)
/关键词 # 从光标处向下查找,示例:/main 查找所有main关键字
?关键词 # 从光标处向上查找
n # 查找下一个匹配项(按回车后,按n继续找)
N # 查找上一个匹配项
# 2. 全局替换(开发最常用,批量修改内容)
:%s/旧内容/新内容/g # 核心命令:%表示整个文件,s表示替换,g表示全局(所有匹配项)
# 示例1:将文件中所有的hello替换为world
:%s/hello/world/g
# 示例2:替换时逐行确认(防止误替换,重要文件修改用),加c(confirm)
:%s/old/new/gc
# 示例3:指定行范围替换(如1-50行,替换test为TEST)
:1,50s/test/TEST/g
③显示/隐藏行号
bash
:set nu # 显示行号(临时生效,Vim重启后失效)
:set nonu # 隐藏行号
④其他高频操作
bash
:set hlsearch # 高亮显示查找的关键词(默认开启,查完后可关闭)
:set nohlsearch # 关闭关键词高亮
:e! # 放弃所有修改,恢复文件原始状态(比:q!更灵活,不退出Vim)2.7简单vim配置(了解)
vim
#新建/编辑配置文件
vim ~/.vimrc # 不存在则新建,存在则打开
#在⽬录/etc/下⾯,有个名为vimrc的⽂件,这是系统中公共的vim配置⽂件,对所有⽤⼾都有效.
#⽽在每个⽤⼾的主⽬录下,都可以⾃⼰建⽴私有的配置⽂件,命名为:".vimrc"。例如,/root
#⽬录下,通常已经存在⼀个.vimrc⽂件,如果不存在,则创建之。
#切换⽤⼾成为⾃⼰执⾏su,进⼊⾃⼰的主⼯作⽬录,执⾏cd~
#打开⾃⼰⽬录下的.vimrc⽂件,执⾏ vim .vimrc
vim
" 基础配置 - 新手必备
set nu " 永久显示行号
set encoding=utf-8 " 设置编码为UTF-8,解决中文乱码
set hlsearch " 高亮显示查找关键词
set incsearch " 实时查找(输入关键词时立即高亮,无需按回车)
set autoindent " 自动缩进(新行和上一行保持相同缩进,写代码必备)
set smartindent " 智能缩进(针对C/C++等语言,自动识别大括号缩进)
set tabstop=4 " Tab键对应4个空格(开发规范,避免Tab/空格混用)
set shiftwidth=4 " 缩进时的空格数为4
set expandtab " 将Tab键自动转换为空格(推荐,统一缩进格式)
set cursorline " 高亮显示光标所在行(方便定位)
set showcmd " 显示正在输入的命令(新手友好)3.编译器gcc/g++
gcc/g++是GNU编译器集合(GNU Compiler Collection)的核心组件,是 Linux 系统下原生、默认的 C/C++ 编译器,也是后端开发、嵌入式开发、服务器开发的核心基础工具------ 它能将人类易读的 C/C++ 源代码编译为计算机可直接执行的机器码,同时支持代码优化、调试信息生成、跨平台编译、链接第三方库等核心功能.不同于 Windows 下的可视化编译工具(如 VS),Linux 下的 C/C++ 开发完全基于GCC/G++ 命令行编译,是后续学习 Makefile、CMake 自动化构建、GDB 调试的基础.对于 Linux 开发学习者,掌握gcc/g++的核心编译命令和选项,是实现 C/C++ 程序从源码到可执行文件的关键.
gcc/g++开始对程序进行翻译时会进行以下操作
1️⃣预处理(进⾏宏替换/去注释/条件编译/头⽂件展开等)
2️⃣编译(⽣成汇编)
3️⃣汇编(⽣成机器可识别代码)
4️⃣链接(⽣成可执⾏⽂件或库⽂件)
3.1预处理(进⾏宏替换)
预处理功能主要包括宏定义,⽂件包含,条件编译,去注释等.
预处理指令是以#号开头的代码⾏.
实例: gcc --E hello.c --o hello.i
选项"-E",该选项的作⽤是让 gcc 在预处理结束后停⽌编译过程.
选项"-o"是指⽬标⽂件,".i"⽂件为已经过预处理的C原始程序.
步骤一:预处理 - 选项 -E
核心作用:处理源代码中的预处理指令,生成纯语法的源码文件,不做语法检查.
处理内容:头文件包含(#include)、宏定义替换(#define)、条件编译(#if/#endif)、删除注释等;
生成文件:后缀 .i(C 语言)/.ii(C++ 语言);
实操命令:
bash
# 对test.c预处理,生成预处理文件test.i(-o 指定输出文件,核心选项)
gcc -E test.c -o test.i3.2编译(⽣成汇编)
在这个阶段中,gcc ⾸先要检查代码的规范性、是否有语法错误等,以确定代码的实际要做的⼯作,在检查⽆误后,gcc 把代码翻译成汇编语⾔.
⽤⼾可以使⽤"-S"选项来进⾏查看,该选项只进⾏编译⽽不进⾏汇编,⽣成汇编代码.
实例: gcc --S hello.i --o hello.s
步骤二:编译 - 选项 -S
核心作用:对预处理后的源码进行语法检查,将其翻译为汇编语言,是编译过程中最核心的步骤.
关键特性:若源码有语法错误(如少分号、变量未定义),此步骤会直接报错并终止编译,是排查代码语法问题的关键阶段;
生成文件:后缀 .s 的汇编语言文件;
实操命令:
bash
# 对预处理文件test.i编译,生成汇编文件test.s
gcc -S test.i -o test.s
# 也可直接对源码执行,自动跳过预处理(编译器会先执行-E再执行-S)
gcc -S test.c -o test.s3.3汇编(⽣成机器可识别代码)
汇编阶段是把编译阶段⽣成的".s"⽂件转成⽬标⽂件
读者在此可使⽤选项"-c"就可看到汇编代码已转化为".o"的⼆进制⽬标代码了
实例:gcc --c hello.s --o hello.o
步骤三:汇编 - 选项 -c
核心作用:将汇编语言翻译为机器码,生成目标文件,机器码为二进制格式,但无法直接执行(缺少库链接和入口地址).
生成文件:后缀 .o 的目标文件(Object File),Linux 下的二进制重定位文件;
实操命令:
bash
# 对汇编文件test.s汇编,生成目标文件test.o
gcc -c test.s -o test.o
# 直接对源码执行,自动完成预处理+编译+汇编
gcc -c test.c -o test.o3.4链接(⽣成可执⾏⽂件或库⽂件)
在成功编译之后,就进⼊了链接阶段.
实例: gcc hello.o --o hello
步骤四:链接 - 无专属选项
核心作用:将目标文件(.o)与系统库(如 C 标准库 libc.so、C++ 标准库 libstdc++.so)、其他依赖的目标文件链接,生成可直接执行的二进制文件.
关键特性:链接阶段不做语法检查,若缺少库依赖、函数未定义,会在此阶段报未定义引用错误;
生成文件:默认名为 a.out 的可执行文件(可通过 -o 自定义名称);
实操命令:
bash
# 将目标文件test.o链接,生成默认可执行文件a.out
gcc test.o
# 链接并自定义可执行文件名为test(开发最常用)
gcc test.o -o test
# 直接对源码执行,自动完成四步,生成可执行文件test(一键编译,最常用)
gcc test.c -o test3.5静态链接和动态链接
在我们的实际开发中,不可能将所有代码放在⼀个源⽂件中,所以会出现多个源⽂件,⽽且多个源⽂件之间不是独⽴的,⽽会存在多种依赖关系,如⼀个源⽂件可能要调⽤另⼀个源⽂件中定义的函数,但是每个源⽂件都是独⽴编译的,即每个.c⽂件会形成⼀个.o⽂件,为了满⾜前⾯说的依赖关系,则需要将这些源⽂件产⽣的⽬标⽂件进⾏链接,从⽽形成⼀个可以执⾏的程序.这个链接的过程就是
静态链接.
静态链接的缺点很明显:
①浪费空间:因为每个可执⾏程序中对所有需要的⽬标⽂件都要有⼀份副本,所以如果多个程序对同⼀个⽬标⽂件都有依赖,如多个程序中都调⽤了printf()函数,则这多个程序中都含有printf.o,所以同⼀个⽬标⽂件都在内存存在多个副本.
②更新⽐较困难:因为每当库函数的代码修改了,这个时候就需要重新进⾏编译链接形成可执⾏程序.但是静态链接的优点就是,在可执⾏程序中已经具备了所有执⾏程序所需要的任何东西,在执⾏的时候运⾏速度快.
动态链接的出现解决了静态链接中提到问题.动态链接的基本思想是把程序按照模块拆分成各个相对
独⽴部分,在程序运⾏时才将它们链接在⼀起形成⼀个完整的程序,⽽不是像静态链接⼀样把所有程序模块都链接成⼀个单独的可执⾏⽂件.动态链接其实远⽐静态链接要常⽤得多.
3.5.1静态链接
1️⃣核心定义
编译链接阶段 ,编译器会将程序中用到的静态库代码(.a) 直接完整复制、嵌入 到最终的可执行文件中.
✅ 通俗比喻:写论文时,直接把引用的文献内容完整抄到自己论文里 ,论文完成后可独立阅读,无需再查原文献.
2️⃣静态链接的编译命令(GCC/G++)
GCC/G++ 中通过**-static** 选项指定强制静态链接 ,结合之前的编译选项即可,需注意:系统需提前安装静态库文件 (默认仅装动态库,需手动安装).
前提:安装静态库依赖(CentOS/Ubuntu 不同)
bash
# Ubuntu/Debian 系:安装C/C++静态标准库(基础必备)
sudo apt install -y libc6-dev-static libstdc++-dev-static
# CentOS/RHEL 系:安装C/C++静态标准库
sudo yum install -y glibc-static libstdc++-static
# 若需其他静态库(如数学库、openssl),安装对应-static包,例:
sudo apt install -y libssl-static # Ubuntu 静态openssl库
sudo yum install -y openssl-static # CentOS 静态openssl库示例(以调用数学库的test.c为例)
c
// test.c 代码(调用数学库sqrt,之前的示例)
#include <stdio.h>
#include <math.h>
int main() {
printf("sqrt(16) = %lf\n", sqrt(16.0));
return 0;
}
bash
# 静态链接编译(C语言,加-static,链接数学库-lm)
gcc test.c -o test_static -Wall -lm -static
# C++ 静态链接(同理,用g++,加-static)
g++ test.cpp -o test_cpp_static -Wall -static3️⃣静态链接的核心特点(优缺点)
优点
①可执行文件独立运行,无外部依赖 :可执行文件包含所有需要的库代码,拷贝到同架构的任意Linux系统 (即使无对应库)都能直接运行,移植性极强 ;
②运行速度略快 :无需运行时加载库,减少了库文件的打开、映射开销;
③运行时环境稳定 :不受系统库版本更新、删除的影响(比如系统升级libc.so,不会影响已静态链接的程序).
缺点
①可执行文件体积极大 :因为嵌入了库代码,体积通常是动态链接的数倍甚至数十倍 ;
示例:上述test_static体积约 800KB+ ,而动态链接版本仅 10KB+ ;
②编译速度较慢 :需要复制库代码,链接阶段耗时更长;
③内存占用高 :若多个程序同时运行且都静态链接了同一个库,每个程序都会在内存中加载一份库代码,造成内存冗余 ;
④程序更新繁琐:若库代码有bug修复/功能更新(如C标准库修复漏洞),必须重新编译链接整个程序,才能使用新的库代码.
3.5.2动态链接
1️⃣核心定义
编译链接阶段 ,编译器不会复制库代码 到可执行文件中,仅在可执行文件中记录需要调用的库函数名称、对应的动态库路径 ;程序运行时 ,系统的动态链接器(ld-linux.so) 会自动找到并加载对应的动态库(.so),程序才能正常运行.
✅ 通俗比喻:写论文时,不抄文献内容,只写文献引用标注 (如"参考《XX书》P100"),别人阅读时需要找到对应的原文献才能看懂.
2️⃣动态链接的编译命令(GCC/G++)
GCC/G++ 默认就是动态链接 ,无需加额外选项,直接编译即可,这也是开发中最常用的方式.
实操示例(同一份test.c)
bash
# 动态链接编译(默认,无需额外选项,链接数学库-lm)
gcc test.c -o test_dynamic -Wall -lm
# C++ 动态链接(默认,g++自动链接C++标准库libstdc++.so)
g++ test.cpp -o test_cpp_dynamic -Wall3️⃣动态链接的核心特点(优缺点)
优点
①可执行文件体积极小 :仅记录库的引用信息,不复制库代码,节省磁盘空间;
②内存占用低,实现库共享 :系统中同一个动态库仅加载一份到内存,所有使用该库的程序共享这一份内存 ,大幅节省内存(服务器多程序运行时核心优势);
③库更新便捷 :若动态库修复bug/升级功能,只需替换系统中的.so文件,所有使用该库的程序无需重新编译 ,运行时自动加载新库;
④编译链接速度快 :无需复制库代码,仅记录引用,链接阶段耗时短.
缺点
①运行时依赖系统动态库 :程序必须在安装了对应版本动态库 的Linux系统中才能运行,若系统缺少库文件,会报**"找不到共享库"** 错误,移植性差;
②存在库版本兼容问题 :若系统动态库版本与程序编译时的库版本差异过大,可能出现**"符号未定义""版本不匹配"** 错误(如编译时用libc.so.6,系统只有libc.so.5);
③运行速度略慢:程序启动时,动态链接器需要查找、加载、映射动态库,有轻微的启动开销(日常使用几乎感知不到).
3.5.3静态链接vs动态链接核心对比
| 对比维度 | 静态链接 | 动态链接 |
|---|---|---|
| 链接时机 | 编译链接阶段 | 程序运行时(由动态链接器完成) |
| 库代码处理 | 完整复制嵌入可执行文件 | 不复制,仅记录库引用信息 |
| 可执行文件体积 | 极大(数倍于动态) | 极小 |
| 运行依赖 | 无外部依赖,独立运行 | 依赖系统对应动态库(.so) |
| 内存占用 | 高(无共享,多程序重复加载) | 低(库共享,仅加载一份) |
| 程序更新 | 库更新需重新编译整个程序 | 库更新仅替换.so文件,无需重新编译 |
| 移植性 | 极强(同架构任意Linux可运行) | 差(需匹配库版本) |
| 编译/链接速度 | 慢 | 快 |
| 运行速度 | 略快(无启动加载开销) | 略慢(轻微启动加载开销) |
| GCC/G++ 编译选项 | 需加 -static,且安装静态库 |
默认方式,无需额外选项 |
3.6静态库和动态库
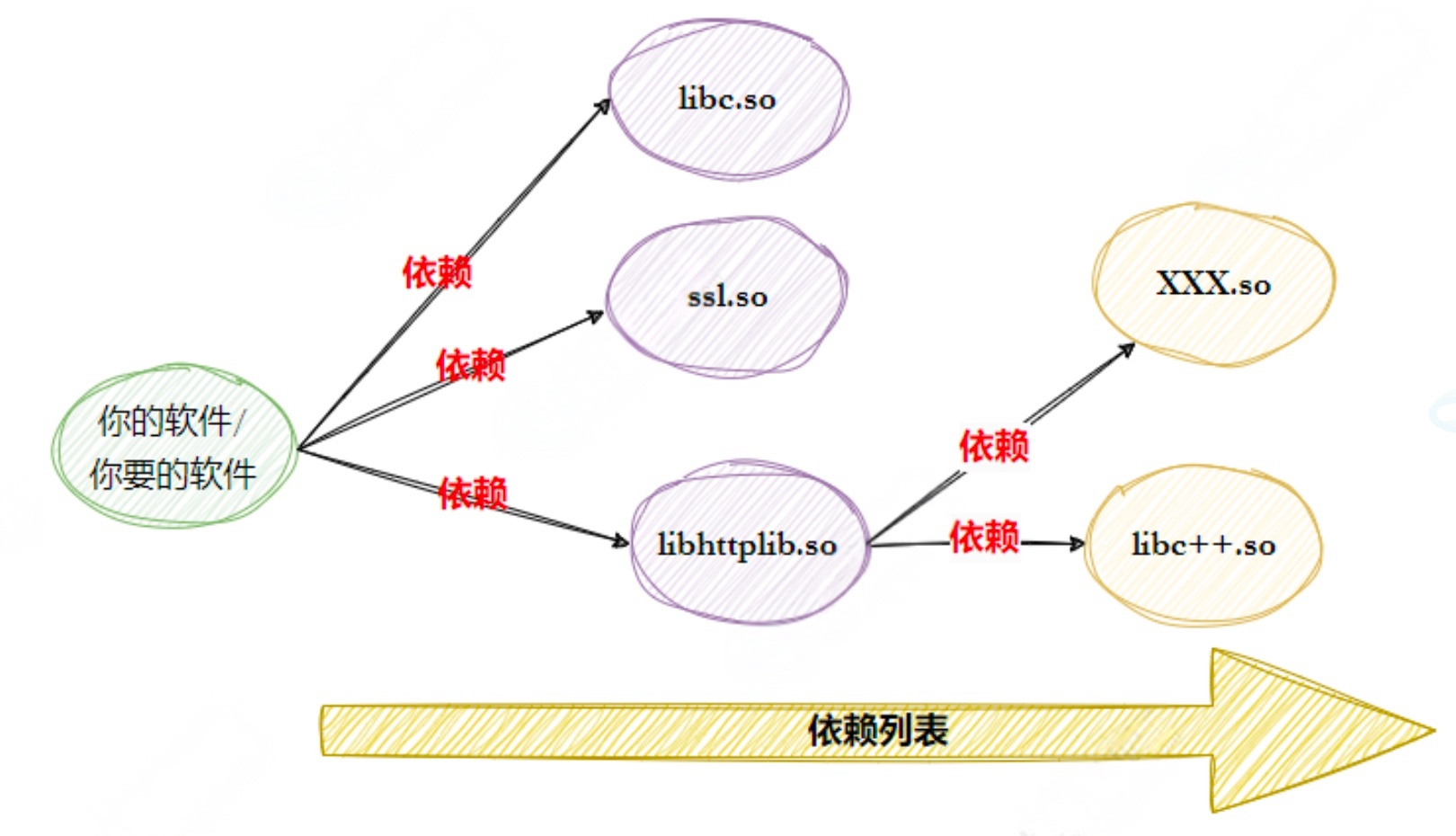
前面的介绍中涉及到⼀个重要的概念: 库.
我们的C程序中,并没有定义"printf"的函数实现,且在预编译中包含的"stdio.h"中也只有该函数的声明,⽽没有定义函数的实现,那么,是在哪⾥实"printf"函数的呢?
最后的答案是:系统把这些函数实现都被做到名为 libc.so.6 的库⽂件中去了,在没有特别指定时,gcc 会到系统默认的搜索路径"/usr/lib"下进⾏查找,也就是链接到 libc.so.6 库函数中去,这样就能实现函数"printf"了,⽽这也就是链接的作⽤.
1️⃣静态库是指编译链接时,把库⽂件的代码全部加⼊到可执⾏⽂件中,因此⽣成的⽂件⽐较⼤,但在运⾏时也就不再需要库⽂件了.其后缀名⼀般为".a"
2️⃣动态库与之相反,在编译链接时并没有把库⽂件的代码加⼊到可执⾏⽂件中,⽽是在程序执⾏时由运⾏时链接⽂件加载库,这样可以节省系统的开销.动态库⼀般后缀名为".so",如前⾯所述的libc.so.6 就是动态库.gcc 在编译时默认使⽤动态库.完成了链接之后,gcc 就可以⽣成可执⾏⽂件,如下所示.gcc hello.o --o hello
3️⃣gcc默认⽣成的⼆进制程序,是动态链接的,这点可以通过file命令验证.
📌注意1:
Linux下,动态库XXX.so,静态库XXX.a.
Windows下,动态库XXX.dll,静态库XXX.lib.
📌 注意2:
⼀般我们的云服务器,C/C++的静态库并没有安装,可以采⽤如下⽅法安装
centos系统:
yum install glibc-static libstdc+±static -y
ubuntu系统:
sudo apt install build-essential libc6-dev libstdc+±11-dev
3.6.1静态库
静态库(.a):制作 + 使用
静态库的制作流程非常简单 ,核心两步:编译生成目标文件(.o) → 打包归档为静态库(.a) ,无需额外编译选项.
步骤1:编译生成目标文件(.o)
进入lib_demo目录,用gcc -c编译库的源码文件(add.c、sub.c),生成对应的.o文件(仅编译汇编,不链接):
bash
# 编译add.c → add.o,sub.c → sub.o(-c 是核心,生成目标文件)
gcc -c add.c sub.c -Wall
# 执行后查看文件,会生成 add.o 和 sub.o
ls -l # 输出:add.c add.o calc.h main.c sub.c sub.o
步骤2:用ar命令打包为静态库(.a)
Linux 下用ar工具(Archive)将多个.o文件打包成静态库,核心命令ar rcs,格式:ar rcs 静态库名 目标文件1 目标文件2 ...
bash
# 打包add.o、sub.o为libcalc.a(遵守命名规则:lib+calc+.a)
ar rcs libcalc.a add.o sub.o
# 执行后查看,生成静态库文件 libcalc.a
ls -l # 输出:... libcalc.a ...关键参数解释(
ar rcs):
r:替换库中已存在的目标文件,若库不存在则创建;
c:静态创建库,不输出创建信息;
s:为库生成索引表,加快链接速度(必须加,否则链接可能报错).
步骤3:使用静态库编译测试程序(main.c)
调用静态库的核心是用 GCC/G++ 的-I(头文件路径)、-L(库文件路径)、-l(库名) 选项,格式:
bash
gcc 测试源码.c -o 可执行文件 -I<头文件路径> -L<库文件路径> -l<库名> -Wall本示例中,头文件(calc.h)、库文件(libcalc.a)都在当前目录,因此命令为:
bash
# -I. :指定头文件搜索路径为当前目录(. 表示当前)
# -L. :指定库文件搜索路径为当前目录
# -lcalc:链接libcalc.a(省略lib和.a)
gcc main.c -o test_static -I. -L. -lcalc -Wall
步骤4:运行测试,验证静态库可用
bash
# 给可执行文件加执行权限(若需要)
chmod +x test_static
# 运行
./test_static
#正确输出
#10 + 5 = 15
#10 - 5 = 5补充:静态链接的强制指定
若当前目录同时存在同名静态库和动态库(如 libcalc.a 和 libcalc.so),GCC/G++ 默认优先链接动态库 ,若要强制链接静态库,加-static选项即可:
bash
gcc main.c -o test_static_only -I. -L. -lcalc -Wall -static3.6.2动态库
动态库(.so):制作 + 使用(核心需加-fPIC)
动态库的制作比静态库多一个关键编译选项,核心两步:编译生成位置无关目标文件(.o) → 编译生成动态库(.so) ,其中**-fPIC是动态库的核心要求**,缺一不可.
关键前置:什么是-fPIC?
-fPIC是 Position Independent Code (位置无关代码)的缩写,动态库需要被多个程序共享加载 到内存的不同地址,因此库的代码不能包含绝对内存地址 ,必须是位置无关的-------fPIC就是告诉 GCC 编译出不依赖绝对地址的代码,这是动态库的硬性要求,不加会直接编译报错.
步骤1:编译生成位置无关的目标文件(.o)
在lib_demo目录执行,加-fPIC选项编译 add.c、sub.c:
bash
# -c 生成目标文件,-fPIC 生成位置无关代码,核心组合
gcc -c add.c sub.c -fPIC -Wall
# 生成 add.o 和 sub.o(若之前制作静态库时已生成,会被覆盖,不影响)
ls -l
步骤2:编译生成动态库(.so)
用 GCC 直接编译生成动态库,核心选项gcc -shared -o,格式:gcc -shared -o 动态库名 目标文件1 目标文件2 ...
bash
# -shared :表示生成动态库,-o 指定输出库名(遵守lib+calc+.so)
gcc -shared -o libcalc.so add.o sub.o
# 执行后查看,生成动态库文件 libcalc.so
ls -l # 输出:... libcalc.so ...
步骤3:使用动态库编译测试程序(main.c)
动态库的链接命令和静态库完全一致 ,同样用-I/-L/-l选项,GCC/G++ 默认优先链接动态库:
bash
# 命令和静态库完全相同,默认链接动态库 libcalc.so
gcc main.c -o test_dynamic -I. -L. -lcalc -Wall
步骤4:运行测试,解决动态库找不到问题
直接运行刚编译的程序,大概率会报找不到共享库错误,这是动态库的核心特点(运行时需系统能找到库文件),先执行看错误:
bash
# 加执行权限
chmod +x test_dynamic
# 直接运行,报错
./test_dynamic典型错误提示:
./test_dynamic: error while loading shared libraries: libcalc.so: cannot open shared object file: No such file or directory核心原因
Linux 动态链接器(ld-linux.so)会按固定顺序 查找动态库,当前目录并不是系统默认的库搜索路径 ,因此系统找不到我们在当前目录制作的libcalc.so.
解决方法
解决思路:让 Linux 动态链接器能找到libcalc.so.
方法:临时指定库路径(LD_LIBRARY_PATH,测试/应急首选)
通过环境变量LD_LIBRARY_PATH临时添加动态库搜索路径 ,优先级高于系统默认路径,仅当前终端有效,关闭终端后失效.
bash
# 把当前目录(.)添加到动态库搜索路径(核心命令)
export LD_LIBRARY_PATH=./:$LD_LIBRARY_PATH
# 再次运行,成功执行
./test_dynamic
#正确输出
#10 + 5 = 15
#10 - 5 = 53.6.3静态库vs动态库核心对比
| 对比维度 | 静态库(.a) | 动态库(.so) |
|---|---|---|
| 核心文件性质 | 多个.o文件的打包归档文件,无特殊编译要求 | 单独的位置无关二进制文件,必须加-fPIC编译 |
| 制作复杂度 | 简单(gcc -c + ar rcs) | 稍复杂(gcc -c -fPIC + gcc -shared) |
| 链接时的处理 | 完整拷贝库代码到可执行文件 | 仅记录库引用信息,不拷贝代码 |
| 可执行文件体积 | 大(包含库代码) | 小(仅记录引用) |
| 运行时依赖 | 无依赖,可执行文件独立运行 | 依赖系统能找到对应的.so文件 |
| 库更新维护 | 库代码修改后,所有使用该库的程序都要重新编译链接 | 库代码修改后,仅替换.so文件即可,所有使用程序无需重新编译 |
| 内存占用 | 高(多程序使用则重复加载库代码到内存) | 低(系统仅加载一份库代码,所有程序共享) |
| 链接优先级 | GCC/G++ 默认低,需-static强制链接 | GCC/G++ 默认高,优先链接 |
| 移植性 | 极强(同架构任意Linux系统可直接运行) | 一般(需携带.so文件或确保目标系统有该库) |
4.⾃动化构建---make/Makefile
4.1背景介绍
会不会写makefile,从⼀个侧⾯说明了⼀个⼈是否具备完成⼤型⼯程的能⼒!
1️⃣⼀个⼯程中的源⽂件不计数,其按类型、功能、模块分别放在若⼲个⽬录中,makefile定义了⼀系列的规则来指定,哪些⽂件需要先编译,哪些⽂件需要后编译,哪些⽂件需要重新编译,甚⾄于进⾏更复杂的功能操作.
2️⃣makefile带来的好处就是⸺"⾃动化编译",⼀旦写好,只需要⼀个make命令,整个⼯程完全⾃动编译,极⼤的提⾼了软件开发的效率.
3️⃣make是⼀个命令⼯具,是⼀个解释makefile中指令的命令⼯具,⼀般来说,⼤多数的IDE都有这个命令,⽐如:Delphi的make,Visual C++的nmake,Linux下GNU的make.可⻅,makefile都成为了⼀种在⼯程⽅⾯的编译⽅法.
4️⃣make是⼀条命令,makefile是⼀个⽂件,两个搭配使⽤,完成项⽬⾃动化构建.
4.2详细介绍---make/Makefile的使用
之前已经介绍了 GCC/G++ 编译、静态库/动态库的制作与使用,而实际开发中如果手动敲
gcc命令编译多文件项目,会出现命令繁琐、易出错、修改单个文件需重新编译所有代码 的问题,效率极低.
make/Makefile正是解决这个痛点的Linux 原生自动化构建工具 ------Makefile是定义编译规则的文本文件,make是执行这些规则的命令行工具.它的核心能力是按规则自动化执行编译命令,且仅重新编译修改过的文件 (增量编译),让多文件 C/C++ 项目的编译仅需一条make命令,大幅提升开发效率.
1️⃣Makefile 核心灵魂:基本规则(必掌握)
Makefile 的最小执行单元是规则 ,所有自动化编译逻辑都由一条或多条规则组成,这是 Makefile 最核心的语法,必须死记格式.
①规则的固定格式
makefile
# 规则格式:目标 冒号 依赖文件列表(空格分隔)
目标(target) : 依赖(dependency1) 依赖(dependency2) ...
# 命令(command):必须以【Tab键】开头,可写多条,每条占一行
命令1
命令2
...
②规则三要素解析
make_demo/
├── calc.h (函数声明头文件)
├── add.c (加法实现)
├── sub.c (减法实现)
└── main.c (测试主程序)
| 要素 | 作用 | 示例(calc 项目) |
|---|---|---|
| 目标 | 要生成的文件/执行的动作(如可执行文件、目标文件、静态库),是规则的核心 | test(可执行文件)、add.o(目标文件) |
| 依赖 | 生成「目标」所需要的文件(如 .c 文件、.h 文件、其他 .o 文件) | main.o add.o sub.o(生成test需要的3个.o) |
| 命令 | 从「依赖」生成「目标」的Shell命令(如 gcc 编译命令),必须Tab开头 | gcc main.o add.o sub.o -o test |
⚠️致命:Tab 键必须用
命令行前必须是 Tab 键,不能用空格代替 (哪怕4个/8个空格),否则执行make会报missing separator. Stop.错误,这是初学者最常犯的错误!
③第一个极简 Makefile(入门示例)
在make_demo目录下新建文件,命名为 Makefile (首字母大写,无后缀),写入以下内容(对应手动编译命令gcc main.c add.c sub.c -o test -Wall -g):
makefile
# 极简 Makefile:生成可执行文件test
# 目标:test 依赖:所有.c文件+头文件(.h可选,建议加,修改头文件会重新编译)
test : main.c add.c sub.c calc.h
gcc main.c add.c sub.c -o test -Wall -g # 必须Tab开头
④执行 make 命令,自动化编译
在make_demo目录下直接执行make命令,无需敲冗长的 gcc 命令:
bash
# 直接执行make,自动读取当前目录的Makefile
make
# 执行后会输出:gcc main.c add.c sub.c -o test -Wall -g
# 生成可执行文件test
ls -l # 可见 test 文件
# 运行测试,正常输出
./test
⑤增量编译:make 的核心优势
手动编译时,哪怕只修改了add.c一行代码,也需要重新敲命令编译所有文件;而make会自动比较目标和依赖的修改时间(时间戳) ,仅当依赖文件比目标文件新(或目标文件不存在)时,才执行命令重新编译.
实操验证增量编译:
⓵先执行make生成 test,此时 test 的时间戳是最新的;
⓶用touch命令修改add.c(模拟修改代码):touch add.c;
⓷再次执行make,会重新编译生成 test (因为 add.c 被修改,时间戳更新);
⓸再次执行make,会输出make: 'test' is up to date.(无文件修改,无需编译).
✅ 这就是增量编译,文件越多的项目,效率提升越明显!
2️⃣Makefile 进阶语法(实际开发必用)
上面的极简 Makefile 适合小项目,但如果有10个/20个 .c 文件,会出现代码冗余、修改麻烦 的问题.Makefile 提供了变量、模式匹配、伪目标、清理规则 等进阶语法,让配置更简洁、可维护性更高,这是实际开发中真正使用的写法.
①变量:代替重复内容,修改一处全生效
Makefile 中的变量类似 C 语言的宏,用于代替重复出现的内容(如编译器、编译选项、目标文件列表),定义后用 $(变量名) 引用 .
⑴变量的定义与引用格式
makefile
# 定义变量:变量名=值(等号前后无空格,值可空格分隔)
变量名 = 变量值
# 引用变量:$(变量名)
$(变量名)⑵常用预定义变量(无需自己定义,直接引用)
Makefile 内置了很多与编译相关的预定义变量,贴合 GCC/G++ 开发习惯,常用的有:
| 预定义变量 | 含义 | 示例 |
|---|---|---|
CC |
默认C编译器,默认值 cc |
重定义为 gcc |
CXX |
默认C++编译器,默认值 g++ |
直接引用即可 |
CFLAGS |
C编译器的编译选项 | -Wall -g |
CXXFLAGS |
C++编译器的编译选项 | -Wall -g -std=c++11 |
LDFLAGS |
链接选项(如 -L -l) | -L. -lcalc |
⑶自定义变量:代替目标/文件列表
适合代替可执行文件名、目标文件(.o)列表等自定义内容.
②模式匹配:%.o : %.c(自动生成 .o 文件规则)
实际开发中,会先将所有 .c 文件编译为 .o 目标文件,再链接为可执行文件(分离编译和链接,增量编译更精细).Makefile 用通配符 % 实现模式匹配,核心规则:
makefile
# 模式匹配规则:将 任意.c 文件 编译为 同名.o 文件
# % 是通配符,匹配任意字符串;$< 表示「当前依赖文件」(即 %.c);$@ 表示「当前目标文件」(即 %.o)
%.o : %.c
$(CC) -c $< -o $@ $(CFLAGS) # -c 生成.o,仅编译不链接自动变量:简化命令(配合模式匹配使用)
Makefile 提供了自动变量,用于代替规则中的目标和依赖,避免重复书写,常用的3个:
| 自动变量 | 含义 | 示例(%.o:%.c) |
|---|---|---|
$@ |
表示当前规则的目标文件 | 匹配 add.c 时,$@ = add.o |
$< |
表示当前规则的第一个依赖文件 | 匹配 add.c 时,$< = add.c |
$^ |
表示当前规则的所有依赖文件(去重) | 生成test时,$^ = main.o add.o sub.o |
③伪目标:.PHONY(解决目标与文件重名问题)
伪目标不是要生成的文件,而是要执行的动作 (如清理编译产物、编译所有目标).如果项目中存在与伪目标同名的文件(如clean文件),会导致make 伪目标无法执行,用.PHONY: 伪目标名可强制执行动作,不受文件影响.
常用伪目标:
all:指定默认编译的多个目标(如同时生成可执行文件、静态库、动态库);
clean:清理所有编译产物(.o、可执行文件、库文件),开发中必加;
static:单独制作静态库;
shared:单独制作动态库.
④清理规则:make clean(必加)
编译过程中会生成 .o、可执行文件、库文件等产物,需要一键清理,这就是clean伪目标的作用,核心命令是rm -rf(强制删除,无提示).
清理规则模板:
makefile
# 伪目标:clean,清理所有编译产物
.PHONY: clean
clean:
rm -rf test *.o libcalc.a libcalc.so # 删除可执行文件、所有.o、库文件执行清理:
bash
make clean # 一键删除所有编译产物,恢复项目初始状态4.3实例介绍(含推导)
c
#include <stdio.h>
int main()
{
printf("hello Makefile!\n");
return 0;
}
Makefile
myproc:myproc.c
gcc -o myproc myproc.c
.PHONY:clean
clean:
rm -f myproc依赖关系---上⾯的⽂件myproc,它依赖myproc.c.
依赖⽅法---gcc -o myproc myproc.c,就是与之对应的依赖关系.
项⽬清理---⼯程是需要被清理的.
像clean这种,没有被第⼀个⽬标⽂件直接或间接关联,那么它后⾯所定义的命令将不会被⾃动执⾏,不过,我们可以显⽰要make执⾏.即命令⸺"make clean",以此来清除所有的⽬标⽂件,以便重编译.
但是⼀般我们这种clean的⽬标⽂件,我们将它设置为伪⽬标,⽤ .PHONY 修饰,伪⽬标的特性
是,总是被执⾏的.可以将我们的 hello ⽬标⽂件声明成伪⽬标,测试⼀下.
什么叫做总是被执⾏?
bash
$ stat XXX
File: 'XXX'
Size: 987 Blocks: 8 IO Block: 4096 regular file
Device: fd01h/64769d Inode: 1321125 Links: 1
Access: (0664/-rw-rw-r--) Uid: ( 1000/ whb) Gid: ( 1000/ whb)
Access: 2026-2-6 18:05:30.430619002 +0800
Modify: 2026-2-6 18:05:25.940595116 +0800
Change: 2026-2-6 18:05:25.940595116 +0800
⽂件 = 内容 + 属性
Modify: 内容变更,时间更新
Change:属性变更,时间更新
Access:常指的是⽂件最近⼀次被访问的时间.在Linux的早期版本中,每当⽂件被访问时,其atime都会更新.但这种机制会导致⼤量的IO操作.具体更新原则,不做过多解释.
#结论:.PHONY:让make忽略源⽂件和可执⾏⽬标⽂件的M时间对⽐
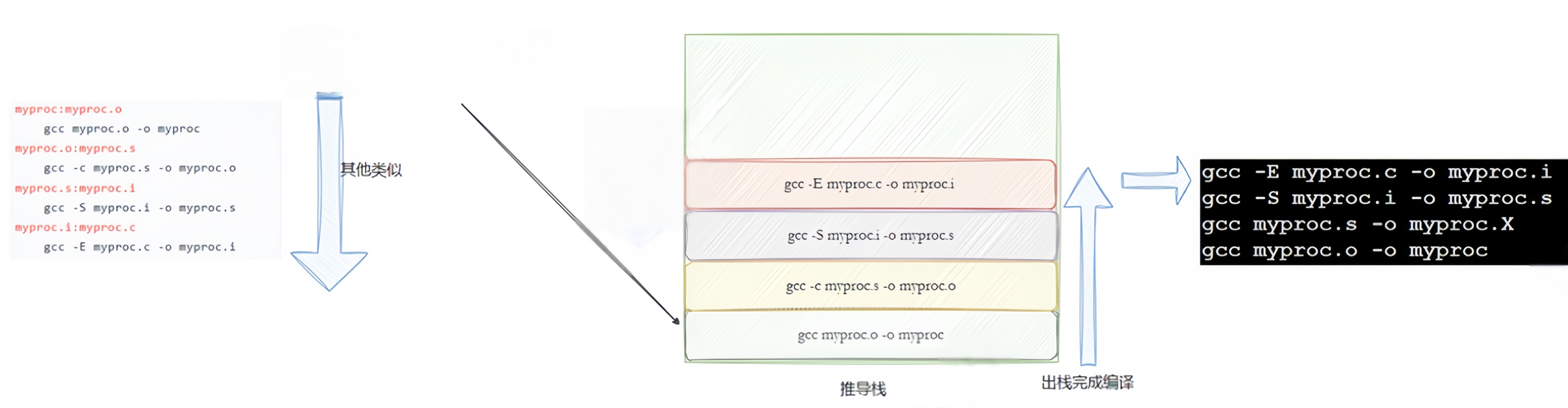
bash
myproc:myproc.o
gcc myproc.o -o myproc
myproc.o:myproc.s
gcc -c myproc.s -o myproc.o
myproc.s:myproc.i
gcc -S myproc.i -o myproc.s
myproc.i:myproc.c
gcc -E myproc.c -o myproc.i
.PHONY:clean
clean:
rm -f *.i *.s *.o myproc
#编译
$ make
gcc -E myproc.c -o myproc.i
gcc -S myproc.i -o myproc.s
gcc -c myproc.s -o myproc.o
gcc myproc.o -o myproc
make是如何⼯作的,在默认的⽅式下,也就是我们只输⼊make命令.那么:
1️⃣make会在当前⽬录下找名字叫"Makefile"或"makefile"的⽂件.
2️⃣如果找到,它会找⽂件中的第⼀个⽬标⽂件(target),在上⾯的例⼦中,他会找到 myproc 这个⽂件,并把这个⽂件作为最终的⽬标⽂件.
3️⃣如果 myproc ⽂件不存在,或是myproc 所依赖的后⾯的 myproc.o ⽂件的⽂件修改时间要⽐myproc 这个⽂件新(可以⽤ touch 测试),那么,他就会执⾏后⾯所定义的命令来⽣成myproc 这个⽂件.
4️⃣如果 myproc 所依赖的 myproc.o ⽂件不存在,那么 make 会在当前⽂件中找⽬标为myproc.o ⽂件的依赖性,如果找到则再根据那⼀个规则⽣成 myproc.o ⽂件.(这有点像⼀个堆栈的过程)
5️⃣当然,你的C⽂件和H⽂件是存在的,于是 make 会⽣成 myproc.o ⽂件,然后再⽤myproc.o ⽂件声明 make 的终极任务,也就是执⾏⽂件 hello 了.
6️⃣这就是整个make的依赖性,make会⼀层⼜⼀层地去找⽂件的依赖关系,直到最终编译出第⼀个
⽬标⽂件.
7️⃣在找寻的过程中,如果出现错误,⽐如最后被依赖的⽂件找不到,那么make就会直接退出,并报错,⽽对于所定义的命令的错误,或是编译不成功,make根本不理.
8️⃣make只管⽂件的依赖性,即,如果在我找了依赖关系之后,冒号后⾯的⽂件还是不在,那么对不起,我就不⼯作.
bash
BIN=test.exe
#SRC=$(shell ls *.c)
SRC=$(wildcard *.c) # wildcard函数,获取当前目录下的所有的原文件
OBJ=$(SRC:.c=.o)
CC=gcc
Echo=echo
Rm=rm -rf
$(BIN):$(OBJ)
@$(CC) -o $@ $^
@$(Echo) "linking $^ to $@ ... done"
%.o:%.c
@$(CC) -c $<
@$(Echo) "compling $< to $@ ... done"
.PHONY:clean
clean:
$(Rm) $(OBJ) $(BIN)
.PHONY:test
test:
@echo "Debug-------"
@echo $(SRC);
@echo "Debug-------"
@echo $(OBJ);
@echo "Debug-------"
#BIN=test.exe
#SRC=test.c
#
#$(BIN):$(SRC)
# @echo "开始编译代码"
# gcc -o $@ $^
# @echo "编译完成"
#.PHONY:clean
#clean:
# @echo "清理 工程..."
# rm -f $(BIN)
# @echo "清理完毕..."
#test.exe:test.o
#gcc test.o -o test.exe
#test.o:test.s
#gcc -c test.s -o test.o
#test.s:test.i
#gcc -S test.i -o test.s
#test.i:test.c
#gcc -E test.c -o test.i4.4适度扩展语法
bash
BIN=proc.exe # 定义变量
CC=gcc
#SRC=$(shell ls *.c) # 采⽤shell命令⾏⽅式,获取当前所有.c⽂件名
SRC=$(wildcard *.c) # 或者使⽤ wildcard 函数,获取当前所有.c⽂件名
OBJ=$(SRC:.c=.o) # 将SRC的所有同名.c 替换 成为.o 形成⽬标⽂件列表
LFLAGS=-o # 链接选项
FLAGS=-c # 编译选项
RM=rm -f # 引⼊命令
$(BIN):$(OBJ)
@$(CC) $(LFLAGS) $@ $^ # $@:代表⽬标⽂件名。 $^: 代表依赖⽂件列表
@echo "linking ... $^ to $@"
%.o:%.c # %.c 展开当前⽬录下所有的.c。 %.o: 同时展开同
名.o
@$(CC) $(FLAGS) $< # %<: 对展开的依赖.c⽂件,⼀个⼀个的交给gcc。
@echo "compling ... $< to $@" # @:不回显命令
.PHONY:clean
clean:
$(RM) $(OBJ) $(BIN) # $(RM): 替换,⽤变量内容替换它
.PHONY:test
test:
@echo $(SRC)
@echo $(OBJ)敬请期待下一篇文章内容-->Linux系统的进度条实现、版本控制器git和调试器gdb介绍!
