0 前言
最近在尝试使用腾讯云来给自己的大模型小程序加语音识别功能,但是论坛上对于这方面的文章似乎很少,所以只能硬看官网的介绍以及参考大佬提供的部分代码磕磕绊绊实现了这一功能。
1 腾讯云实时语音识别介绍

最开始我尝试使用腾讯云的一句话语音识别,这个实现起来就比实时语音识别简单,只需要像普通传递音频文件到后端再发送给腾讯云服务器解析返回就行,但是这种耗时会很长,音频长一点可能得等待好几秒钟才能收到返回结果,这个对于发送消息给大模型的场景是不可接受的,所以必须使用实时语音识别。而实时语音识别的官方文档不像一句话语音识别有代码示例,它只有图文解释,但是实际原理并不复杂。
2 腾讯云实时语音识别流程
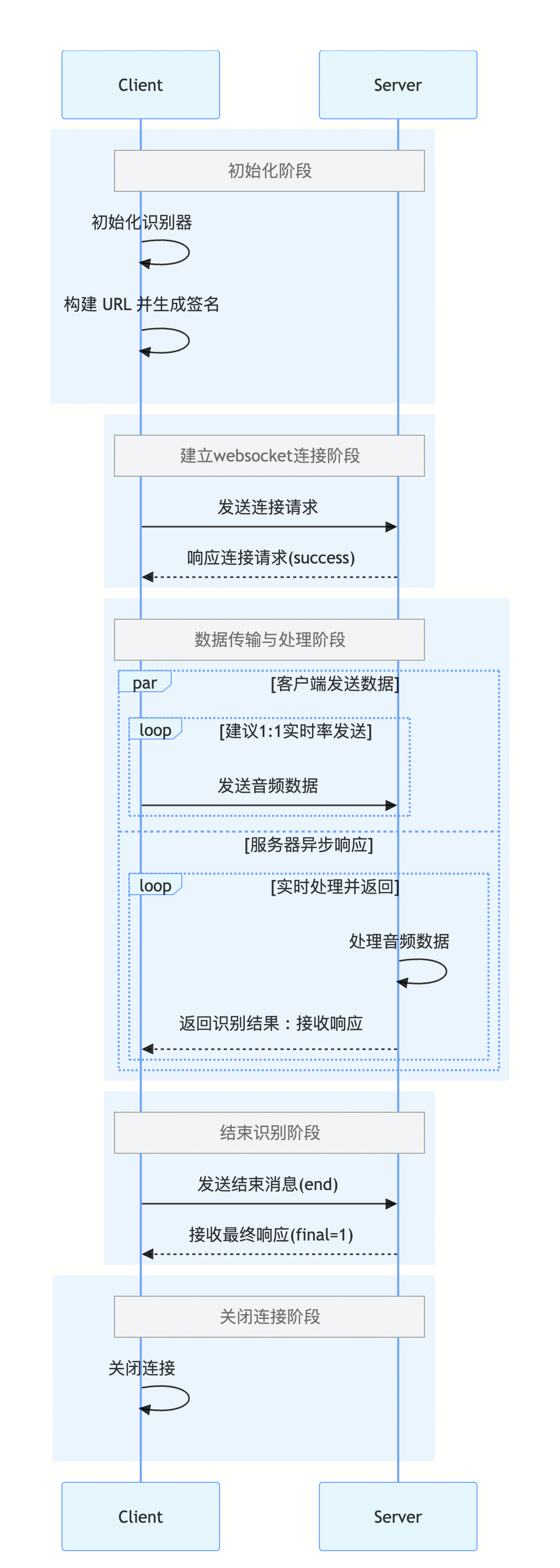
根据官方文档说明,接口调用流程一共分为两个阶段,握手阶段 和识别阶段,所谓握手阶段实际就是websocket的连接过程,其中复杂的地方就是websocket url的生成,它需要包含各项参数并进行签名等操作。而识别阶段就是前端发送切片音频数据到腾讯云服务器被识别处理后返回给前端的过程。
2.1 握手阶段
请求格式
握手阶段,客户端主动发起 WebSocket 连接请求,请求 URL 格式为:
shell
wss://asr.cloud.tencent.com/asr/v2/<appid>?{请求参数}其中 需替换为腾讯云注册账号的 appid,可通过 API 密钥管理页面 获取,{请求参数}格式为:
shell
key1=value2&key2=value2...部分参数如下,具体可去官网查看,即握手阶段主要任务就是生成这个websocket url,但是还有个前置重要任务是生成signature ,这个也是该url 前置参数的一部分
2.1.1 signature 签名生成
步骤一 :
对除 signature 之外的所有参数按字典序进行排序,拼接请求 URL (不包含协议部分:wss://)作为 签名原文,这里以 appid=125922***,secretid=Qq1zhZMN8dv0* 为例拼接签名原文,则拼接的签名原文为:
python
asr.cloud.tencent.com/asr/v2/125922***?engine_model_type=16k_zh&expired=1673494772&needvad=1&nonce=1673408372&secretid=*****Qq1zhZMN8dv0******×tamp=1673408372&voice_format=1&voice_id=c64385ee-3e5c-4fc5-bbfd-7c71addb35b0python代码如下,对params 即对参数字典的每一项的key进行排序,为什么必须排序?因为签名的生成对参数顺序敏感,如果前端 / 后端排序不一致,生成的签名就会不同
python
# 1.对除 signature 之外的所有参数按字典序进行排序,拼接请求 URL (不包含协议部分:wss://)作为签名原文
sorted_params = sorted(params.items(), key=lambda x: x[0])
# 2. 拼接为 key1=value1&key2=value2格式
query_str = "&".join([f"{k}={v}" for k, v in sorted_params])
# 3. 签名原文(query_str拼接上前缀)
signature_str = f"{ASR_PRE}/{APPID}?{query_str}"步骤二 :
对签名原文使用 SecretKey 进行 HMAC-SHA1 加密,之后再进行 base64 编码。例如对上一步的签名原文, secretkey=SkqpeHgqmSz,使用 HMAC-SHA1 算法进行加密并做 base64 编码处理:
powershell
Base64Encode(HmacSha1("asr.cloud.tencent.com/asr/v2/125922***?engine_model_type=16k_zh&expired=1673494772&needvad=1&nonce=1673408372&secretid=*****Qq1zhZMN8dv0******×tamp=1673408372&voice_format=1&voice_id=c64385ee-3e5c-4fc5-bbfd-7c71addb35b0", "*****SkqpeHgqmSz*****"))python代码如下,这个使用 HMAC-SHA1加密再编码的过程可以问问ai怎么做,都是固定的写法
python
# 1. 将 字符串密钥 和 字符串原始数据 转换为 字节类型(必须步骤)
secret_key_bytes = SECRET_KEY.encode('utf-8')
raw_data_bytes = signature_str.encode('utf-8')
# 2. 初始化 HMAC-SHA1 实例,传入密钥和哈希算法
hmac_obj = hmac.new(
key=secret_key_bytes, # 密钥字节
msg=raw_data_bytes, # 待签名数据字节
digestmod=hashlib.sha1 # 指定哈希算法为 SHA1
)
# 3. 计算 HMAC-SHA1 二进制摘要(返回 bytes 类型)
hmac_sha1_bytes = hmac_obj.digest()
# 4 转换为 Base64 编码字符串(接口签名最常用)
signature_base64 = base64.b64encode(hmac_sha1_bytes).decode('utf-8')步骤三 :
将 signature 值进行 urlencode(必须进行 URL 编码,编码函数必须要支持对+、=等特殊字符的编码,否则将导致鉴权失败偶发)后拼接得到最终请求 URL 为:
powershell
wss://asr.cloud.tencent.com/asr/v2/125922****?engine_model_type=16k_zh&expired=1592380492&filter_dirty=1&filter_modal=1&filter_punc=1&needvad=1&nonce=1592294092123&secretid=A*********************************0r×tamp=1592294092&voice_format=1&voice_id=c64385ee-3e5c-4fc5-bbfd-7c71addb35b0&signature=G8jDQBRg1JfeBi%2FYnTjyjekxfDA%3D代码如下,将上面得到的 signature_base64 进行urlencode,即处理掉一些特殊字符,对其进行编码
python
# 将 signature 值进行 urlencode(必须进行 URL 编码,编码函数必须要支持对+、=等特殊字符的编码,否则将导致鉴权失败偶发
return urllib.parse.quote(signature_base64)此时得到了 signature
2.1.2 合成最终的url
上一步骤已经生成了signature,接着就可以把signature放入url中的signature参数中,生成url的函数如下
python
async def get_asr_ws_url(openid:str=Depends(decode_jwt)):
# 定义握手所需参数
timestamp = int(time.time())
params = {
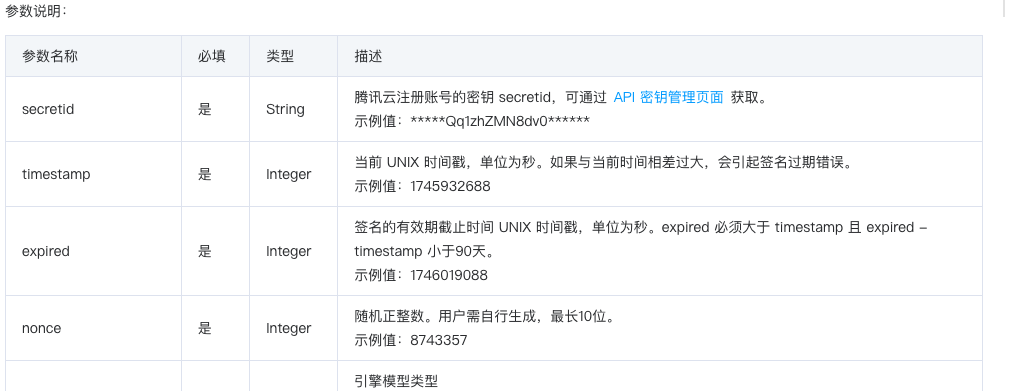
"secretid": SECRET_ID, # 腾讯云注册账号的密钥 secretid,可通过 API 密钥管理页面 获取。
"timestamp": timestamp, # 当前 UNIX 时间戳,单位为秒。如果与当前时间相差过大,会引起签名过期错误。
"expired": timestamp + 60, # 签名的有效期截止时间 UNIX 时间戳,单位为秒。expired 必须大于 timestamp 且 expired - timestamp 小于90天。
"nonce": int(time.time() * 1000), # 随机正整数。用户需自行生成,最长10位。示例值:8743357
"engine_model_type": "16k_zh", # 引擎模型类型
"voice_id": str(uuid.uuid4()), # 音频流全局唯一标识,一个 WebSocket 连接对应一个,用户自己生成(推荐使用 UUID),最长128位。
"voice_format": 1, # 语音编码方式,可选,默认值为4。1:pcm;
"needvad": 1 # 0:关闭 vad,1:开启 vad,默认为0。如果语音分片长度超过60秒,会强制在60s断一次,建议客户音频超过60s时,开启 vad(人声检测切分功能),提升切分效果。
}
# 生成 signature
signature = generate_signature(params)
# 拼接最终 URL
params["signature"] = signature
query = "&".join([f"{k}={v}" for k, v in params.items()])
ws_url = f"wss://{ASR_PRE}/{APPID}?{query}"
return response(ws_url)此时,调用接口,后端可返回完整的可连接的websocket url
2.2 识别阶段
步骤一 :
该阶段主要是在前端进行编码,此时距离握手成功实际还差一步,客户端发起连接请求后,后台建立连接并进行签名校验,校验成功则返回 code 值为0的确认消息表示握手成功;如果校验失败,后台返回 code 为非0值的消息并断开连接。
代码片段如下
python
// 监听收到消息
this.socketTask.onMessage((res: any) => {
const objRes: TencentASRRealTimeResponse = JSON.parse(res.data)
// 握手成功
if (objRes.code === 0) {
.......步骤二 :
在识别过程中,客户端持续上传 binary message 到后台,内容为音频流二进制数据。建议每 200ms 发送 200ms 时长(即1:1实时率)的数据包,对应 PCM 大小为:8k 采样率3200字节,16k 采样率6400字节。音频发送速率过快超过1:1实时率或者音频数据包之间发送间隔超过6秒,可能导致引擎出错,后台将返回错误并主动断开连接。
js
// 小程序端
// 已录制完指定帧大小的文件,会回调录音分片结果数据。如果设置了 frameSize ,则会回调此事件
recorderManager.onFrameRecorded((res) => {
// 将ArrayBuffer 转成可方便切片操作的 8位数组
const buffer = new Uint8Array(res.frameBuffer)
// 16k 采样率1280字节,即每一块都需要尽量为1280字节,可以在最后一块小于1280字节
const CHUNK_SIZE = 1280
//将buffer切块
let offset = 0
while (offset < buffer.length) {
const slice = buffer.slice(offset, offset + CHUNK_SIZE)
offset += CHUNK_SIZE
appStore.socketTask.send({
data: slice.buffer,
});
}
})音频流上传完成之后,客户端需发送以下内容的 text message,通知后台结束识别。
python
{"type": "end"}步骤三 :
接收消息
客户端上传数据的过程中,需要同步接收后台返回的实时识别结果,结果示例:
后台识别完所有上传的语音数据之后,最终返回 final 值为1的消息并断开连接。

识别过程中如果出现错误,后台返回 code 为非0值的消息并断开连接。

其中sliceType
识别结果类型:
0:一段话开始识别。
1:一段话识别中,voice_text_str 为非稳态结果(该段识别结果还可能变化)。
2:一段话识别结束,voice_text_str 为稳态结果(该段识别结果不再变化)。 根据发送的音频情况,识别过程中可能返回的
slice_type 序列有:
0-1-2:一段话开始识别、识别中(可能有多次1返回)、识别结束。
0-2:一段话开始识别、识别结束。
2:直接返回一段话完整的识别结果。
对于 index
当前一段话结果在整个音频流中的序号,从0开始逐句递增。
所以识别阶段开始时首先需要判断sliceType,当其为0时说明语音识别正常开始,然后可以创建个字符串数组来保存每一段解析的文本,每一段的索引就是返回消息的index字段,代码可以如下编写
js
// 监听收到消息
this.socketTask.onMessage((res: any) => {
const objRes: TencentASRRealTimeResponse = JSON.parse(res.data)
// 握手成功
if (objRes.code === 0) {
// 语音返回结果
if (objRes.result && objRes.result.voice_text_str) {
const index: number = objRes.result.index
const text: string = objRes.result.voice_text_str
const sliceType: number = objRes.result.slice_type
// 初始化该index段
if (!asrSegment[index]) {
asrSegment[index] = ""
}
// 段话开始识别。
if (sliceType === 0) {
asrSegment[index] = text
}
// 一段话识别中,voice_text_str 为非稳态结果(该段识别结果还可能变化)
if (sliceType === 1) {
asrSegment[index] = text;
}
// 一段话识别结束,voice_text_str 为稳态结果(该段识别结果不再变化)
if (sliceType === 2) {
asrSegment[index] = text
}
// 拼接完整语音
this.voiceResText = asrSegment.filter(Boolean).join("")
console.log('voiceResText', this.voiceResText)
}
} else if (objRes.code === 4008) {
uni.showToast({
icon: "none",
title: "没有听到你说话",
});
} else {
uni.showToast({
icon: "none",
title: "连接失败",
});
}
})当用户停止语音识别后,在合适的时机发送end消息通知腾讯云停止语音识别,并断开连接
js
// 通知腾讯云识别结束
appStore.socketTask.send({
data: JSON.stringify({ type: "end" }),
});此时整个语音识别流程结束,此时已经可以获取到完整的语音识别文本
3 效果图
上述完整代码以及该项目完整代码仓库如下,如果该项目对你有帮助,麻烦送颗香喷喷的⭐️,感谢感谢
仓库地址
