Git版本控制与GDB调试:从入门到实践

🎬 Doro在努力 :个人主页
🔥 个人专栏 : 《MySQL数据库基础语法》《数据结构》
⛺️严于律己,宽以待人
文章目录
- Git版本控制与GDB调试:从入门到实践
-
- 一、为什么我们需要版本控制
- 二、Git的核心概念:仓库与工作区
-
- [2.1 什么是仓库](#2.1 什么是仓库)
- [2.2 工作区、暂存区与本地仓库](#2.2 工作区、暂存区与本地仓库)
- [2.3 远程仓库与本地仓库的同步](#2.3 远程仓库与本地仓库的同步)
- 三、Git的基本操作:三板斧
-
- [3.1 git add:将修改添加到暂存区](#3.1 git add:将修改添加到暂存区)
- [3.2 git commit:将暂存区内容提交到本地仓库](#3.2 git commit:将暂存区内容提交到本地仓库)
- [3.3 git push:将本地仓库同步到远程仓库](#3.3 git push:将本地仓库同步到远程仓库)
- 四、Git多人协作与冲突解决
-
- [4.1 多人协作的基本流程](#4.1 多人协作的基本流程)
- [4.2 什么是冲突,如何解决](#4.2 什么是冲突,如何解决)
- 五、.gitignore:忽略不需要管理的文件
- 六、GDB调试器:找到问题的本质
-
- [6.1 调试的本质是什么](#6.1 调试的本质是什么)
- [6.2 Debug版本与Release版本](#6.2 Debug版本与Release版本)
- [6.3 GDB常用命令](#6.3 GDB常用命令)
- [6.4 CGDB:更友好的调试体验](#6.4 CGDB:更友好的调试体验)
- 七、断点的本质:区域化执行
- 八、总结
作为一名程序员,掌握版本控制和代码调试是必备的基本功。本文将从实际教学的角度出发,深入浅出地讲解Git版本控制器的核心原理与常用操作,以及GDB调试器的使用技巧。无论你是刚接触Linux开发的新手,还是希望系统梳理Git知识的同学,相信这篇文章都能给你带来收获。
一、为什么我们需要版本控制
在学习Git之前,我想先问大家一个问题:你在写实验报告或者课程设计的时候,有没有遇到过这样的情况?为了防止文档丢失或者更改失误,你不得不复制出一个又一个的副本------"报告-v1"、"报告-v2"、"报告-最终版"、"报告-究极最终版"......每个版本都有各自的内容,文件越来越多,到最后你自己都记不清哪个版本修改了什么内容。
文档如此,我们写的项目代码更是如此。想象一下,一个几千行甚至几万行的项目,如果没有版本管理工具,当你发现某个功能出现问题想要回退到之前的版本时,那种绝望感简直让人崩溃。正是在这样的背景下,版本控制器应运而生。
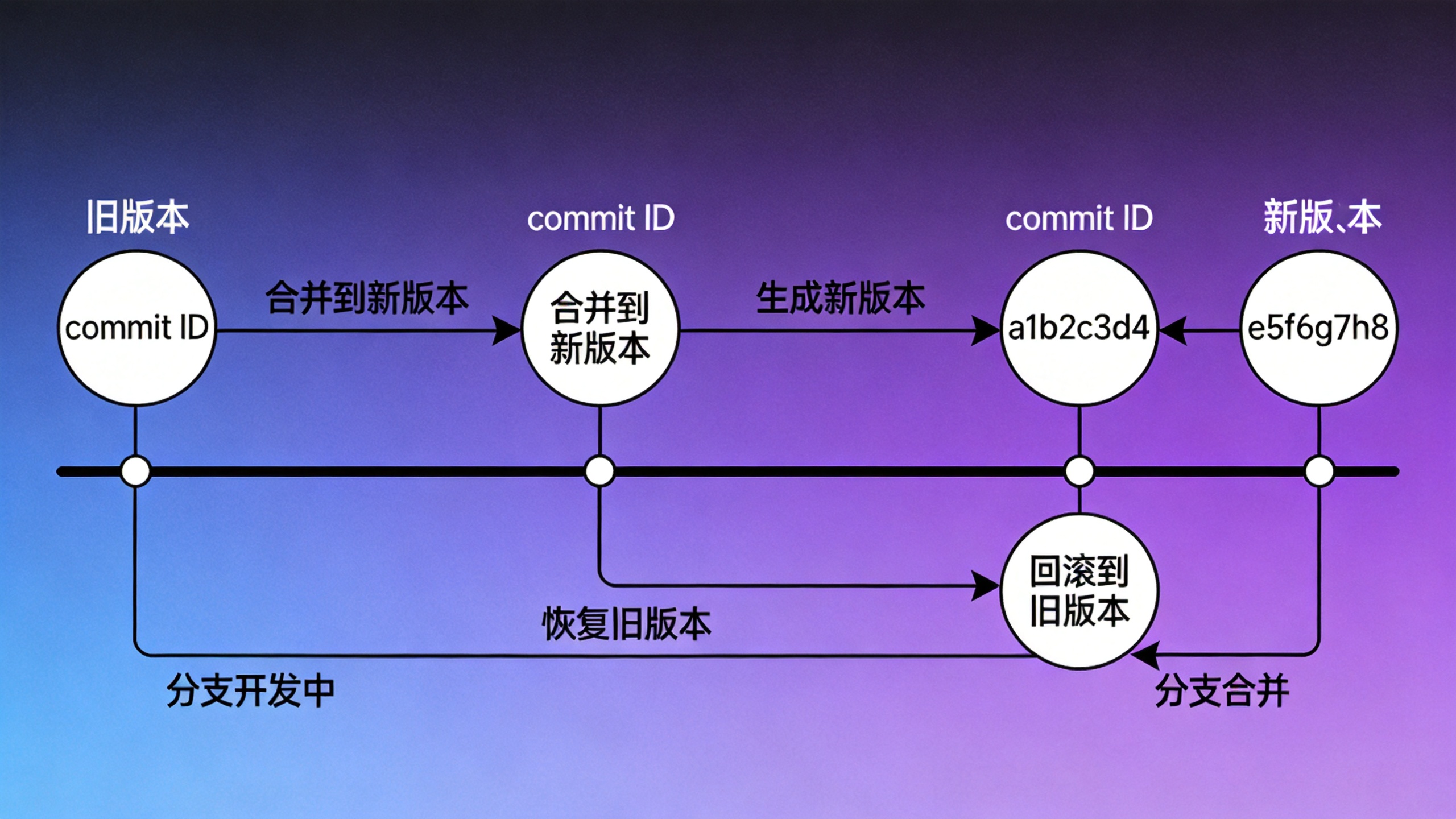
版本控制器 是一个能够记录工程每一次改动和版本迭代的管理系统,同时也方便多人协同作业。目前最主流的版本控制器就是Git,它由Linux内核的缔造者Linus Torvalds于2005年开发,最初是为了解决Linux内核开发过程中的版本管理问题。Git的设计目标非常明确:速度要快、设计要简单、支持非线性开发模式(允许成千上万个并行分支)、完全分布式、能够高效管理超大规模项目。
二、Git的核心概念:仓库与工作区
2.1 什么是仓库
要理解Git,首先要理解"仓库"这个概念。我们可以把仓库想象成一个专门用来存放项目文件及其历史版本的"文件夹"。但严格来说,仓库不仅仅是你看到的那些源代码文件,它还包括一个隐藏的.git目录,这个目录才是Git仓库的核心所在。
当我们在本地初始化一个Git仓库或者从远程克隆一个仓库时,Git会在项目根目录下创建一个.git文件夹。这个文件夹中存储了所有的版本历史、分支信息、配置信息等。换句话说,.git目录才是真正的仓库,而你看到的那些源代码文件只是工作区中的内容。
2.2 工作区、暂存区与本地仓库
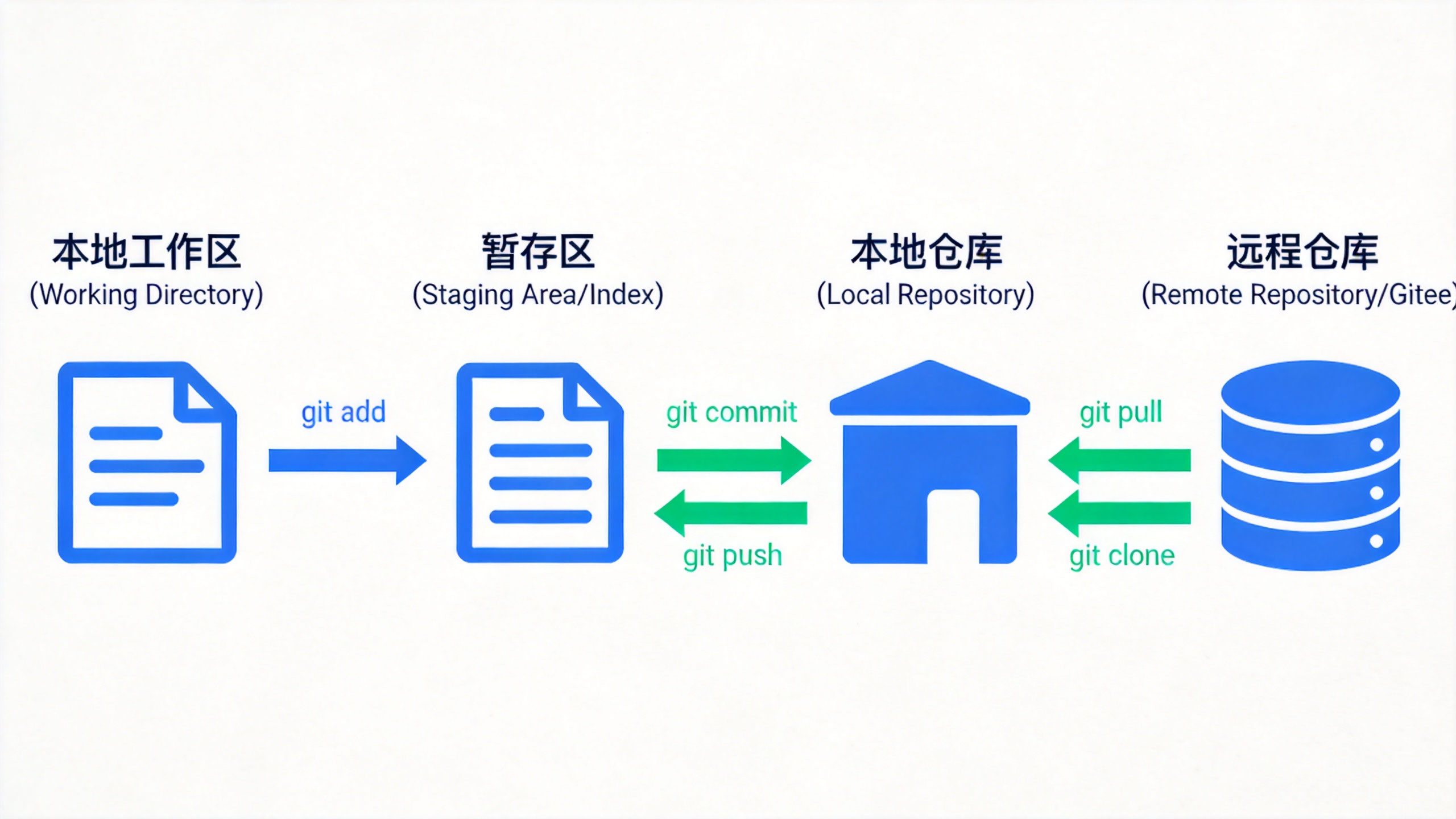
Git的工作流程涉及三个核心区域,理解这三者的关系对于掌握Git至关重要:
工作区(Working Directory):就是你当前正在编辑代码的目录。在这里,你可以自由地修改文件、添加新文件、删除文件,这些操作都不会影响仓库中的历史版本。
暂存区(Staging Area/Index) :这是一个临时区域,用于存放你准备提交的修改。当你执行git add命令时,Git会把工作区中的修改添加到暂存区。为什么要设计暂存区呢?这其实是Git的一个贴心设计------它给了你一个"后悔"的机会。如果你不小心添加了一些不该提交的内容,可以在暂存区中撤销,而不会影响到已经提交的历史版本。
本地仓库(Local Repository) :当你执行git commit命令时,暂存区中的内容会被永久保存到本地仓库中,形成一个新的版本记录。这个版本记录包含了修改的内容、作者信息、提交时间以及提交日志等信息。
2.3 远程仓库与本地仓库的同步
除了本地仓库,Git还支持远程仓库(Remote Repository),比如GitHub、Gitee等平台。远程仓库的作用主要有两个:一是作为本地仓库的备份,防止本地数据丢失;二是方便多人协作开发,团队成员可以通过远程仓库共享代码。
Git提供了git push命令将本地仓库的内容推送到远程仓库,也提供了git pull命令将远程仓库的最新内容拉取到本地。这种设计使得Git成为一个去中心化的分布式版本控制系统------每个开发者的本地仓库都是完整的,可以独立进行版本管理,同时又可以通过远程仓库进行协作。
三、Git的基本操作:三板斧
Git的命令有很多,但对于日常开发来说,最核心的操作可以归纳为"三板斧":git add 、git commit 、git push。
3.1 git add:将修改添加到暂存区
当你在项目中新增或修改了文件后,首先需要使用git add命令将这些变更添加到暂存区。这个命令的用法很灵活:
bash
# 添加单个文件到暂存区
git add filename.c
# 添加当前目录下所有变更的文件
git add .
# 添加所有.c文件
git add *.c这里需要特别强调的是,git add并不是把文件直接提交到仓库,而是提交到暂存区。暂存区的设计给了我们一个缓冲地带,让我们可以在正式提交前检查一遍要提交的内容,确保不会把不该提交的文件(比如临时文件、测试文件等)混入版本库。
3.2 git commit:将暂存区内容提交到本地仓库
当你确认暂存区中的内容没有问题后,就可以使用git commit命令将其提交到本地仓库了:
bash
# 提交并添加提交日志
git commit -m "本次提交的说明信息"关于提交日志,这里有一个非常重要的建议:千万不要随便写! 提交日志是你与未来的自己(或者其他开发者)沟通的重要方式。一个好的提交日志应该清晰地说明本次提交做了什么修改,比如"修复了在某某情况下程序异常退出的问题"、"优化了数据库查询性能"等。千万不要写什么"AAAA"、"BBBB"、"你猜我改了啥"之类的内容------相信我,未来的你一定会骂现在的自己。
另外,Git会记录每一次提交的作者信息(用户名和邮箱)以及提交时间。这些信息可以通过git log命令查看,也是代码审查时的重要依据。所以,配置正确的用户名和邮箱非常重要:
bash
git config --global user.name "你的用户名"
git config --global user.email "你的邮箱"3.3 git push:将本地仓库同步到远程仓库
当你的代码在本地仓库中提交完成后,如果希望与团队成员共享或者备份到云端,就需要使用git push命令将本地仓库推送到远程仓库:
bash
# 推送到默认的远程仓库
git push
# 推送到指定的远程仓库和分支
git push origin mastergit push的本质是将本地.git目录中的内容(包括版本历史和源代码)同步到远程仓库,保持两者的完全一致。需要注意的是,在执行git push之前,最好先执行git pull确保本地仓库是最新的,否则可能会出现冲突。
四、Git多人协作与冲突解决
4.1 多人协作的基本流程
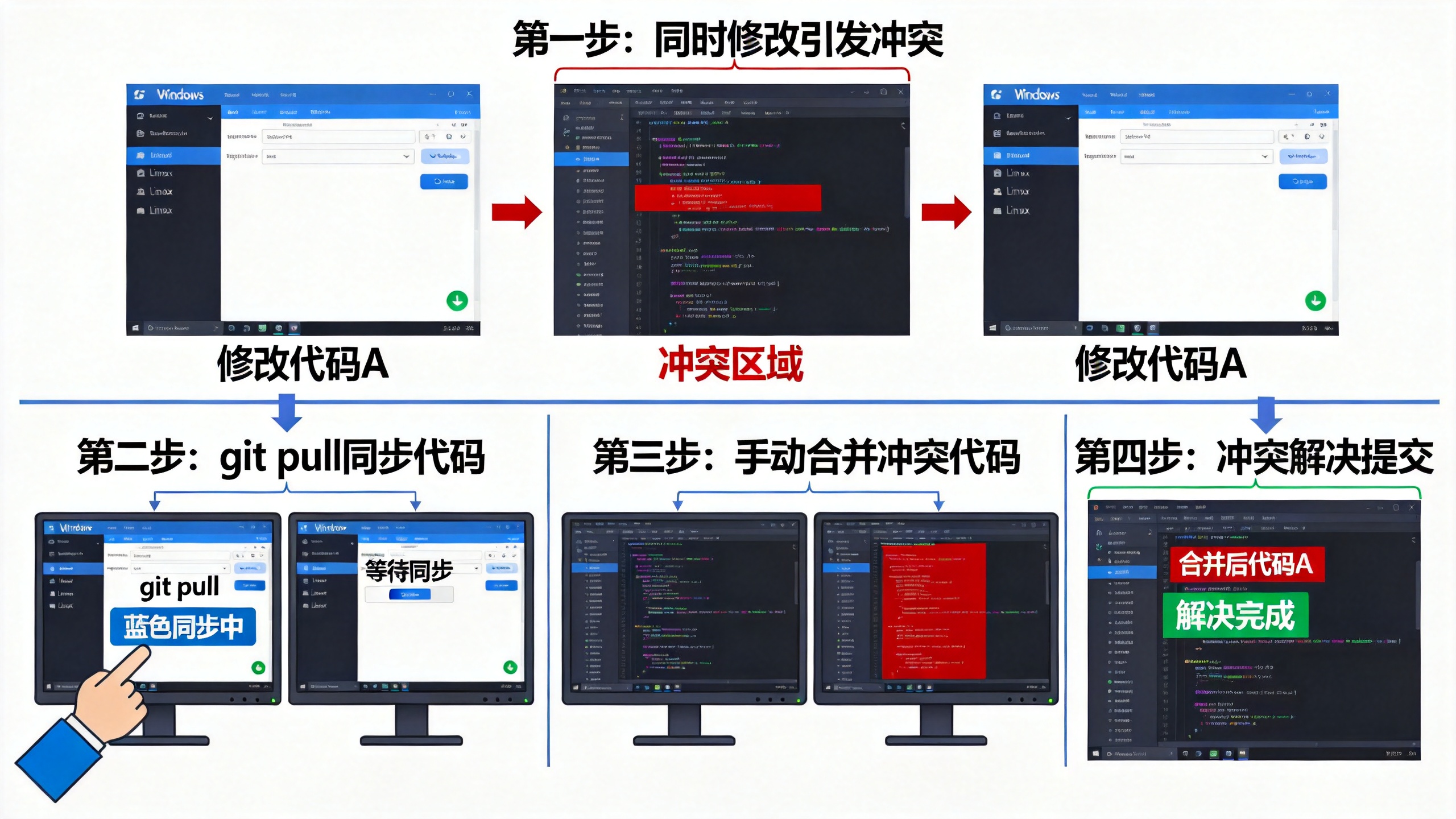
在实际的团队开发中,多人协作是常态。假设你和你的同事分别在Windows和Linux环境下开发同一个项目,基本的协作流程是这样的:
- 你们都从远程仓库克隆代码到本地
- 各自在本地进行开发,修改代码
- 当你完成修改并提交到本地仓库后,执行
git push推送到远程仓库 - 你的同事在推送之前,需要先执行
git pull将远程仓库的最新内容拉取到本地 - 如果没有冲突,直接推送即可;如果有冲突,需要先解决冲突
4.2 什么是冲突,如何解决
冲突(Conflict)发生在当两个人同时修改了同一个文件的同一部分,并且都尝试推送到远程仓库时。Git无法自动判断应该保留哪个版本,因此需要人工介入解决。
冲突解决的基本步骤如下:
- 当你执行
git push时,如果远程仓库已经有了新的提交,Git会提示你先执行git pull - 执行
git pull后,Git会尝试自动合并(auto-merge)两边的修改 - 如果自动合并失败,Git会在冲突的文件中标记出冲突的部分,格式如下:
c
<<<<<<< HEAD
// 这是你的修改
printf("Hello from Linux!\n");
=======
// 这是对方的修改
printf("Hello from Windows!\n");
>>>>>>> branch-name- 你需要手动编辑文件,决定保留哪部分代码,或者将两部分合并
- 解决冲突后,再次执行
git add、git commit、git push
需要注意的是,冲突解决是需要开发人员自己商量着来的。Git只是帮你标记出了冲突的位置,但具体怎么合并,需要你们根据业务逻辑来决定。这也是为什么在实际工作中,良好的项目管理和任务分配非常重要------尽量避免两个人同时修改同一个文件,可以大大减少冲突的发生。
五、.gitignore:忽略不需要管理的文件
在实际开发中,我们的项目目录下经常会有一些不需要纳入版本控制的文件,比如编译生成的目标文件(.o、.obj)、可执行文件(.exe)、日志文件、IDE的配置文件等。如果把这些文件都提交到仓库,不仅会占用不必要的空间,还会让仓库变得杂乱无章。
Git提供了.gitignore文件来解决这个问题。.gitignore是一个文本文件,里面列出了Git应该忽略的文件模式。例如:
gitignore
# 忽略所有.o文件
*.o
# 忽略所有.exe文件
*.exe
# 忽略IDE配置文件
.vscode/
.idea/
# 忽略日志文件
*.log.gitignore文件本身是需要提交到仓库的,这样团队成员都能共享相同的忽略规则。在创建项目时,建议一开始就配置好.gitignore,避免后续不必要的麻烦。
六、GDB调试器:找到问题的本质
6.1 调试的本质是什么
讲完了Git,我们再来聊聊调试。很多同学在使用调试器的时候,往往只是机械地打断点、单步执行、查看变量,但对于"为什么要调试"、"调试的本质是什么"缺乏深入的思考。
调试的本质是帮助我们找到问题,而不是解决问题。 这是一个非常重要的区分。调试器提供了一系列工具(断点、单步执行、查看变量等),帮助我们分析代码的执行流程,定位问题发生的具体位置。但找到问题之后,如何修改代码、如何解决问题,这是需要程序员自己来思考的。
一个完整的调试周期包括以下几个阶段:
- 发现问题:程序崩溃、输出错误、性能不达标等
- 分析问题:通过调试器查看代码执行流程,确定问题发生的范围
- 找到问题:精确定位到导致问题的具体代码行
- 提出解决方案:根据问题原因,设计修复方案
- 解决问题:修改代码,验证修复效果

6.2 Debug版本与Release版本
在使用GDB之前,有一个非常重要的概念需要理解:Debug版本和Release版本的区别。
程序在编译时可以选择不同的发布模式:
- Debug模式:编译器会在生成的可执行文件中包含调试信息(如变量名、函数名、行号等),这些信息会被GDB等调试器使用。Debug版本的程序体积较大,运行速度较慢,但方便调试。
- Release模式:编译器会进行各种优化,去除调试信息,生成的可执行文件体积更小、运行速度更快。Release版本是给最终用户使用的。
在Linux下使用GCC编译时,默认生成的是Release版本。如果要生成Debug版本,需要添加-g选项:
bash
# 生成Release版本(默认)
gcc hello.c -o hello
# 生成Debug版本
gcc -g hello.c -o hello_debug如果你尝试用GDB调试一个没有-g选项编译的程序,GDB会提示"No debugging symbols found"(没有找到调试符号),这意味着你无法查看源代码、无法设置断点、无法查看变量名,调试工作几乎无法进行。
6.3 GDB常用命令
GDB是Linux下最常用的调试器,它提供了丰富的命令来帮助我们调试程序。以下是一些最常用的命令:
启动和退出:
bash
# 启动GDB并加载可执行文件
gdb ./myprogram
# 退出GDB
(gdb) quit查看代码:
bash
# 显示源代码(简写为l)
(gdb) list
(gdb) list 20 # 从第20行开始显示断点相关:
bash
# 在第20行设置断点(简写为b)
(gdb) break 20
(gdb) b 20
# 查看所有断点(简写为info b)
(gdb) info breakpoints
# 删除断点(简写为d)
(gdb) delete 2 # 删除编号为2的断点
# 禁用/启用断点
(gdb) disable 2
(gdb) enable 2运行和单步:
bash
# 运行程序(简写为r)
(gdb) run
# 继续运行到下一个断点(简写为c)
(gdb) continue
# 单步执行,不进入函数内部(简写为n)
(gdb) next
# 单步执行,进入函数内部(简写为s)
(gdb) step查看变量:
bash
# 打印变量值(简写为p)
(gdb) print result
# 长显示变量(每次单步后自动显示)
(gdb) display result6.4 CGDB:更友好的调试体验
如果你觉得GDB的命令行界面不够友好,可以尝试使用CGDB。CGDB是GDB的一个前端,它提供了一个分屏界面:上方显示源代码,下方显示GDB命令行。这样你可以在调试的同时直观地看到代码执行到了哪一行,变量值是多少。
安装CGDB非常简单:
bash
# CentOS
sudo yum install cgdb -y
# Ubuntu
sudo apt install cgdb -y使用CGDB的方式与GDB基本相同:
bash
cgdb ./myprogram七、断点的本质:区域化执行
在结束之前,我想再深入聊聊断点的本质。很多同学在使用断点时,只是简单地把它当作"让程序停下来"的工具,但实际上,断点的价值远不止于此。
断点的本质是对代码进行区域化执行。 在没有断点的情况下,程序会从头到尾一次性执行完毕。而有了断点,我们可以把代码分割成若干个区域,逐个区域地执行和检查。
这种区域化执行的思想在查找问题时非常有用。假设你的程序有1000行代码,出现了bug但不知道在哪。你可以先在第500行设置一个断点,运行程序。如果程序在第500行之前崩溃了,说明问题在前半部分;如果没有崩溃,说明问题在后半部分。然后你可以在第250行或第750行再设置断点,逐步缩小问题范围。这种"二分查找"的思路可以快速地定位问题所在。
另外,断点还有一个重要的属性叫做"使能"(Enable/Disable)。当你暂时不需要某个断点,但又不想删除它时,可以将其禁用。禁用后的断点不会生效,但仍然保留在断点列表中,方便你后续重新启用。这比反复删除和重建断点要高效得多。
八、总结
本文从实际教学的角度,系统地介绍了Git版本控制器和GDB调试器的核心概念与使用方法。让我们回顾一下重点内容:
Git部分:
- Git是一个去中心化的分布式版本控制系统,每个开发者的本地仓库都是完整的
- Git的工作流程涉及工作区、暂存区、本地仓库和远程仓库四个区域
- 核心操作是"三板斧":
git add、git commit、git push - 多人协作时要注意先
git pull同步再git push推送 .gitignore文件用于忽略不需要版本控制的文件
GDB部分:
- 调试的本质是帮助我们找到问题,而不是解决问题
- 调试必须使用Debug版本(编译时加
-g选项) - 断点的本质是对代码进行区域化执行,帮助我们缩小问题范围
- CGDB提供了更友好的可视化调试界面
掌握这些工具和方法,不仅能提高你的开发效率,更能让你在面对复杂问题时保持清晰的思路。记住,工具只是手段,理解原理、培养解决问题的思维方式才是关键。