论文题目:GST-Net: Global Spatio-Temporal Detection Network for Infrared Small Objects in Complex Ground Scenarios
中文题目 :GST-Net:复杂地面场景下红外小目标的全局时空检测框架
应用任务:红外小目标检测 (IRSTD)、视频目标检测、特征增强
论文原文 (Paper) :https://ieeexplore.ieee.org/abstract/document/11098927
官方代码 (Code) :https://github.com/elvintanhust/GST-Det
摘要 :
本文结合 红外小目标检测 (IRSTD) 领域的经典论文《GST-Net》中的设计思想,针对复杂地面背景下目标微弱、易被噪声淹没 的痛点,提供了一个通用的即插即用模块------Res_CBAM_block 。该模块将经典的 CBAM (Convolutional Block Attention Module) 嵌入到残差结构中,通过**通道注意力(关注"什么")和空间注意力(关注"哪里")**的串联,有效抑制背景杂波,增强小目标的特征响应,是构建高性能红外检测 Backbone 的基础组件。
目录
-
- 第一部分:模块原理与实战分析
-
- [1. 论文背景与解决的痛点](#1. 论文背景与解决的痛点)
- [2. 核心模块原理揭秘](#2. 核心模块原理揭秘)
- [3. 架构图解](#3. 架构图解)
- [4. 适用场景与魔改建议](#4. 适用场景与魔改建议)
- 第二部分:核心完整代码
- 第三部分:结果验证与总结
第一部分:模块原理与实战分析
1. 论文背景与解决的痛点
在红外小目标检测(尤其是涉及视频序列的 GST-Net 任务)中,我们面临着极其恶劣的成像环境:
- 低信噪比 (Low SCR):目标通常只有几个像素大,且亮度可能比背景还低。
- 复杂背景干扰:地面场景中包含树木、道路、建筑物等高频纹理,这些纹理在卷积神经网络眼中很容易被误判为目标。
- 特征淹没:随着网络层数加深,微小的目标特征很容易在下采样过程中丢失。
痛点总结 :我们需要一种机制,能够在特征提取的每一个阶段,都显式地告诉网络"哪里是目标,哪里是背景",防止目标信息流失。
2. 核心模块原理揭秘
虽然 GST-Net 论文中提出了复杂的 RMPE 和 GSTDEM 模块,但其底层特征提取往往依赖于强大的注意力机制。这里提供的 Res_CBAM_block 是实现特征增强的"万金油"模块,其核心逻辑如下:
-
双重注意力机制 (Dual Attention):
-
通道注意力 (Channel Attention) :利用全局平均池化和最大池化,压缩空间维度,学习每个通道的权重。它负责判断哪些特征通道包含目标信息(例如,抑制包含大面积背景噪声的通道)。
-
空间注意力 (Spatial Attention) :在通道维度进行压缩,学习空间上的权重图。它负责定位图像的哪个位置是目标(高亮小目标区域)。
-
残差连接 (Residual Connection):
-
直接将注意力增强后的特征与原始输入相加。这保证了梯度能够顺畅传播,防止因为多层注意力导致的网络退化,同时实现了"特征细化"的效果。
-
fea_add_module (特征融合):
-
一个简单但有效的逐元素加法模块,通常用于融合不同层级或不同分支(如时空双流)的特征。
3. 架构图解
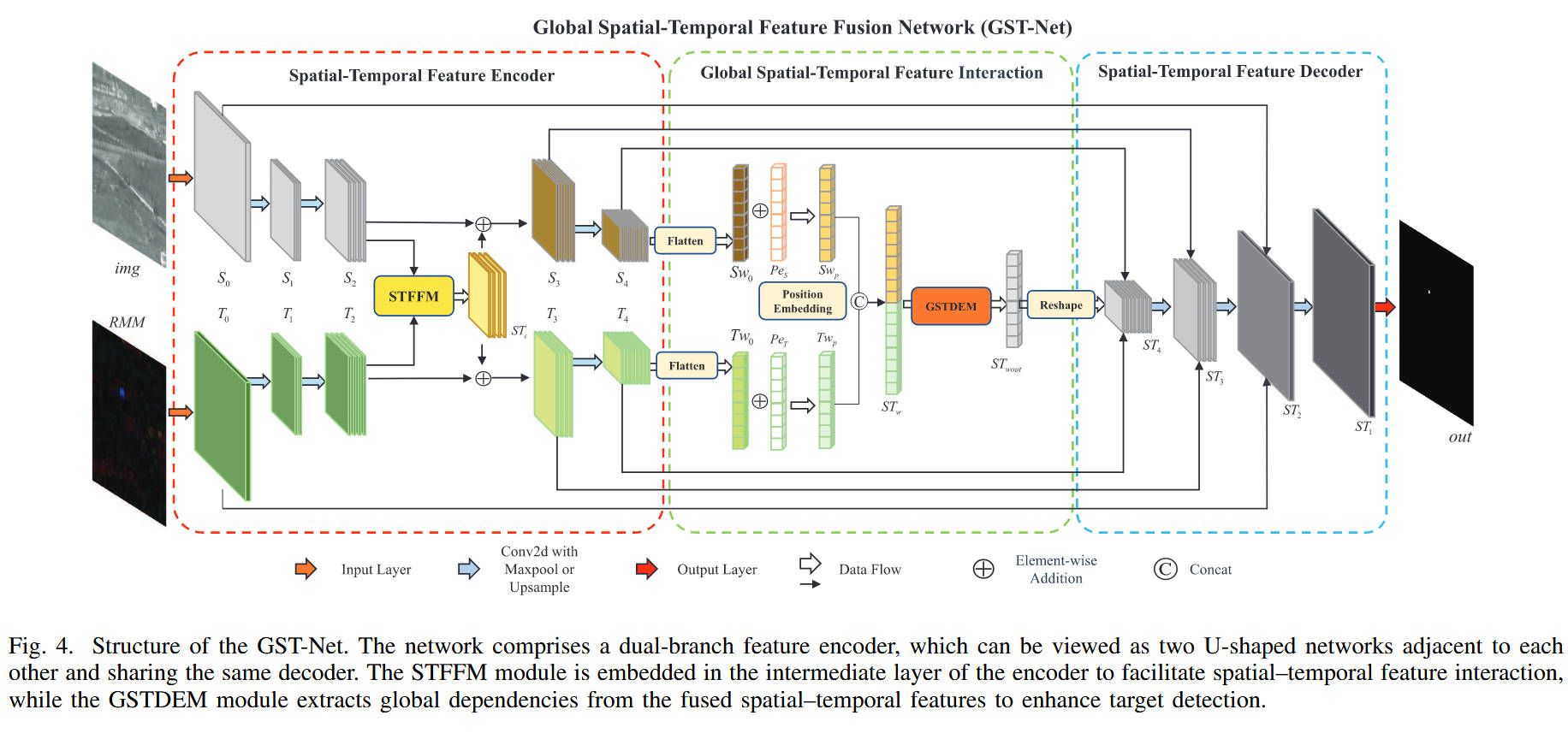
4. 适用场景与魔改建议
这套代码非常适合用于以下场景的改进:
- 红外/遥感小目标检测:替换 ResNet 中的 BasicBlock,显著降低虚警率。
- U-Net 编码器增强:在 U-Net 的下采样路径中加入 Res_CBAM,保护小目标特征不被丢失。
- 特征融合阶段:在 FPN(特征金字塔)的横向连接处使用,增强多尺度特征的表达能力。
第二部分:核心完整代码
python
import torch
import torch.nn as nn
class ChannelAttention(nn.Module):
"""Channel Attention Module from CBAM"""
def __init__(self, in_planes, ratio=16):
super().__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)
self.relu1 = nn.ReLU()
self.fc2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))
out = avg_out + max_out
return self.sigmoid(out)
class SpatialAttention(nn.Module):
"""Spatial Attention Module from CBAM"""
def __init__(self, kernel_size=7):
super().__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv1(x)
return self.sigmoid(x)
class Res_CBAM_block(nn.Module):
"""Residual Block with CBAM (Convolutional Block Attention Module)"""
def __init__(self, in_channels, out_channels, stride=1):
super().__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1)
self.bn1 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1)
self.bn2 = nn.BatchNorm2d(out_channels)
if stride != 1 or out_channels != in_channels:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride),
nn.BatchNorm2d(out_channels))
else:
self.shortcut = None
self.ca = ChannelAttention(out_channels)
self.sa = SpatialAttention()
def forward(self, x):
residual = x
if self.shortcut is not None:
residual = self.shortcut(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.ca(out) * out
out = self.sa(out) * out
out += residual
out = self.relu(out)
return out
class fea_add_module(nn.Module):
"""Feature Addition Module with Dual-stream Attention Fusion"""
def __init__(self, channels):
super().__init__()
self.ca1 = ChannelAttention(channels * 2)
self.ca2 = ChannelAttention(channels)
self.sa = SpatialAttention()
self.relu = nn.ReLU(inplace=True)
self.shortcut1 = nn.Sequential(
nn.Conv2d(channels * 2, channels * 2, kernel_size=1, stride=1),
nn.BatchNorm2d(channels * 2))
self.shortcut2 = nn.Sequential(
nn.Conv2d(channels, channels, kernel_size=1, stride=1),
nn.BatchNorm2d(channels))
self.center_layer = nn.Sequential(
nn.Conv2d(2 * channels, channels, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(channels),
nn.ReLU(inplace=True),
nn.Conv2d(channels, channels, kernel_size=3, padding=1),
nn.BatchNorm2d(channels)
)
def forward(self, S, T):
ST = torch.cat((S, T), dim=1)
out1 = self.ca1(ST) * self.sa(ST) * ST
res1 = self.shortcut1(ST)
out1 += res1
out2 = self.center_layer(out1)
res2 = self.shortcut2(out2)
out = self.ca2(out2) * self.sa(out2) * out2
out += res2
out = self.relu(out)
return out
if __name__ == "__main__":
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("=" * 60)
print("Testing SPSA Modules")
print("=" * 60)
# Test ChannelAttention
print("\n1. Testing ChannelAttention")
x = torch.randn(1, 32, 256, 256).to(device)
ca = ChannelAttention(in_planes=32).to(device)
print(f" Module: {ca.__class__.__name__}")
output = ca(x)
print(f" 输入张量形状: {x.shape}")
print(f" 输出张量形状: {output.shape}")
assert output.shape == (1, 32, 1, 1), "ChannelAttention output shape mismatch!"
print(" ✓ ChannelAttention test passed!")
# Test SpatialAttention
print("\n2. Testing SpatialAttention")
x = torch.randn(1, 32, 256, 256).to(device)
sa = SpatialAttention(kernel_size=7).to(device)
print(f" Module: {sa.__class__.__name__}")
output = sa(x)
print(f" 输入张量形状: {x.shape}")
print(f" 输出张量形状: {output.shape}")
assert output.shape == (1, 1, 256, 256), "SpatialAttention output shape mismatch!"
print(" ✓ SpatialAttention test passed!")
# Test Res_CBAM_block
print("\n3. Testing Res_CBAM_block")
x = torch.randn(1, 32, 256, 256).to(device)
res_cbam = Res_CBAM_block(in_channels=32, out_channels=64, stride=2).to(device)
print(f" Module: {res_cbam.__class__.__name__}")
output = res_cbam(x)
print(f" 输入张量形状: {x.shape}")
print(f" 输出张量形状: {output.shape}")
assert output.shape == (1, 64, 128, 128), "Res_CBAM_block output shape mismatch!"
print(" ✓ Res_CBAM_block test passed!")
# Test Res_CBAM_block with same channels
print("\n4. Testing Res_CBAM_block (same channels)")
x = torch.randn(1, 32, 256, 256).to(device)
res_cbam = Res_CBAM_block(in_channels=32, out_channels=32, stride=1).to(device)
print(f" Module: {res_cbam.__class__.__name__}")
output = res_cbam(x)
print(f" 输入张量形状: {x.shape}")
print(f" 输出张量形状: {output.shape}")
assert output.shape == (1, 32, 256, 256), "Res_CBAM_block output shape mismatch!"
print(" ✓ Res_CBAM_block test passed!")
# Test fea_add_module
print("\n5. Testing fea_add_module")
s = torch.randn(1, 32, 256, 256).to(device)
t = torch.randn(1, 32, 256, 256).to(device)
fea_add = fea_add_module(channels=32).to(device)
print(f" Module: {fea_add.__class__.__name__}")
output = fea_add(s, t)
print(f" 输入张量S形状: {s.shape}")
print(f" 输入张量T形状: {t.shape}")
print(f" 输出张量形状: {output.shape}")
assert output.shape == (1, 32, 256, 256), "fea_add_module output shape mismatch!"
print(" ✓ fea_add_module test passed!")
print("\n" + "=" * 60)
print("All tests passed successfully! ✓")
print("=" * 60)第三部分:结果验证与总结
总结 :
在 GST-Net 等高性能红外检测框架中,注意力机制 是提升性能的基石。Res_CBAM_block 虽然结构简单,但它通过模拟人类视觉的"聚焦"过程,有效地解决了小目标特征微弱的难题。无论你是做视频检测还是单帧检测,加上这个模块,大概率能看到 Loss 下降和 Recall 提升!
喜欢这篇硬核复现的话,欢迎点赞收藏,订阅专栏获取更多 CV/红外目标检测 顶会论文的即插即用代码!