(文献+程序)深度强化学习滑膜无人船艇轨迹跟踪 Python DDPG 1.ddpg+mpc 2.ddqn 3.ddqg RBF神经网络 无人车 无人机编队车辆控制 跟踪 轨迹规划 滑膜控制动态面, 跟踪sin正弦轨迹和圆轨迹 出图包括舵角变换 轨迹图MATLAB simulink仿真
最近在研究深度强化学习在无人船艇轨迹跟踪中的应用,感觉收获满满,来和大家分享一下😃。
(文献+程序)深度强化学习滑膜无人船艇轨迹跟踪 Python DDPG 1.ddpg+mpc 2.ddqn 3.ddqg RBF神经网络 无人车 无人机编队车辆控制 跟踪 轨迹规划 滑膜控制动态面, 跟踪sin正弦轨迹和圆轨迹 出图包括舵角变换 轨迹图MATLAB simulink仿真
咱这次主要聚焦在基于Python的DDPG算法上,也就是深度确定性策略梯度算法。这算法在无人船艇的控制里可算是大放异彩🧐。
一、DDPG + MPC
DDPG结合模型预测控制(MPC),那效果真的是杠杠的👍。MPC可以根据无人船艇当前的状态和未来的预测,提前规划出最优的控制策略。就好比下棋,能提前想好几步之后的走法。
python
# 简单示意DDPG + MPC的部分代码结构
class DDPG_MPC_Agent:
def __init__(self):
self.actor = Actor()
self.critic = Critic()
self.mpc = MPC()
def train(self):
state = get_current_state()
action = self.actor(state)
next_state, reward, done = step(action)
target_q = self.critic(next_state, self.actor(next_state))
q_loss = F.mse_loss(self.critic(state, action), target_q)
actor_loss = -self.critic(state, self.actor(state)).mean()
self.optimizer_q.step(q_loss)
self.optimizer_actor.step(actor_loss)
self.mpc.update(action)这里面,Actor网络负责输出控制动作,Critic网络评估当前状态和动作的价值,MPC则根据预测来调整控制策略。每次训练的时候,先获取当前状态,通过Actor得到动作,执行动作后获取新状态、奖励和是否结束。然后用Critic来计算目标Q值,通过均方误差损失来更新网络参数,同时MPC也会根据动作进行更新。
二、DDQN
双深度Q网络(DDQN)也是个有趣的玩意儿😜。它通过引入两个Q网络,一个用于选择动作,一个用于评估动作,有效解决了Q值估计的偏差问题。
python
# DDQN代码简单示例
class DDQN_Agent:
def __init__(self):
self.online_q = QNetwork()
self.target_q = QNetwork()
def train(self):
state = get_current_state()
action = self.online_q.act(state)
next_state, reward, done = step(action)
target_q = self.target_q(next_state, self.online_q(next_state).detach().max(1)[1].unsqueeze(1))
q_loss = F.mse_loss(self.online_q(state, action), target_q)
self.optimizer_q.step(q_loss)这里,onlineq**网络用于实时选择动作,target q网络用于稳定地评估动作价值。训练时,先从当前状态选择动作,执行后获取新状态等信息。然后用targetq**网络结合online q网络选出的动作索引来计算目标Q值,再通过均方误差损失更新online_q网络。
三、DDQG
深度确定性Q图网络(DDQG),它结合了深度Q网络和确定性策略梯度的优点,在处理连续动作空间时表现出色👏。
python
# DDQG代码简单示意
class DDQG_Agent:
def __init__(self):
self.actor = Actor()
self.critic = Critic()
self.target_actor = Actor()
self.target_critic = Critic()
def train(self):
state = get_current_state()
action = self.actor(state)
next_state, reward, done = step(action)
target_action = self.target_actor(next_state)
target_q = self.target_critic(next_state, target_action)
q_loss = F.mse_loss(self.critic(state, action), target_q)
actor_loss = -self.critic(state, self.actor(state)).mean()
self.optimizer_q.step(q_loss)
self.optimizer_actor.step(actor_loss)这里有两个Actor网络和两个Critic网络,分别用于当前和目标网络。训练过程和DDPG类似,通过计算Q值损失和策略损失来更新网络参数。
四、RBF神经网络
径向基函数(RBF)神经网络在无人船艇轨迹跟踪里也发挥了重要作用。它可以很好地逼近复杂的非线性函数,比如无人船艇的动力学模型。
python
# RBF神经网络简单示例
import numpy as np
from sklearn.neural_network import MLPRegressor
class RBF_Network:
def __init__(self):
self.model = MLPRegressor(hidden_layer_sizes=(100,), activation='tanh')
def train(self, X, y):
self.model.fit(X, y)
def predict(self, X):
return self.model.predict(X)这里用sklearn里的MLPRegressor来构建RBF神经网络。通过训练输入数据X和输出数据y,网络就能学习到它们之间的关系,之后就可以对新的输入数据进行预测啦。
五、无人船艇轨迹跟踪实战
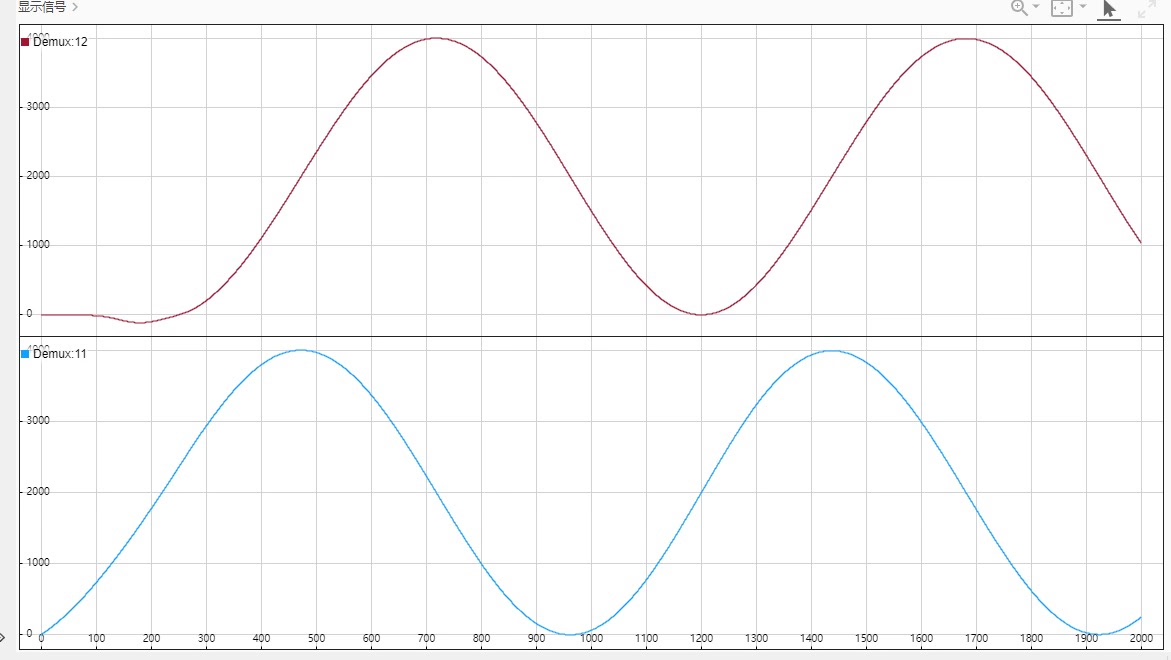
咱的无人船艇要跟踪sin正弦轨迹和圆轨迹,可有意思了😃。
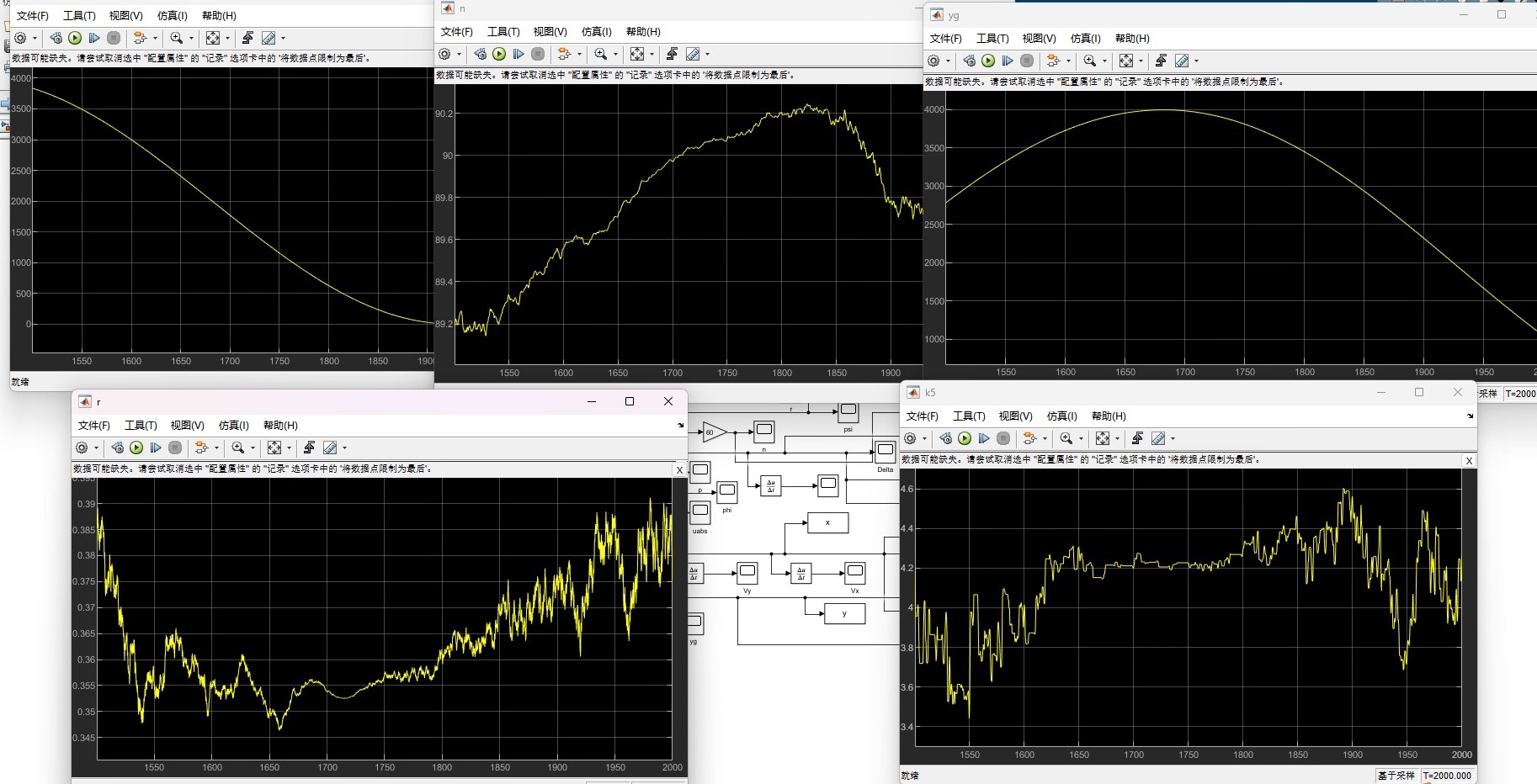
舵角变换
舵角的变换直接影响着无人船艇的转向,从而实现轨迹跟踪。通过不断调整舵角,让无人船艇尽可能地沿着目标轨迹行驶。
轨迹图
MATLAB simulink仿真帮我们直观地展示了无人船艇的轨迹跟踪过程。看着无人船艇一点点地沿着正弦轨迹或圆轨迹行驶,真的超有成就感🤩。
matlab
% MATLAB simulink仿真代码片段示例
sim('unmanned_boat_tracking');
figure;
plot(tout, yout(:,1), 'b', 'LineWidth', 2);
hold on;
plot(target_x, target_y, 'r--', 'LineWidth', 2);
xlabel('X Position (m)');
ylabel('Y Position (m)');
title('Unmanned Boat Trajectory Tracking');
legend('Actual Trajectory', 'Target Trajectory');
grid on;这段代码通过sim函数运行仿真,然后用plot函数画出实际轨迹和目标轨迹,最后设置图表的标签、标题和图例等。
通过这些方法,深度强化学习在滑膜无人船艇轨迹跟踪中展现出了强大的能力,为无人船艇的自主控制提供了有效的解决方案。希望这篇分享能让大家对相关内容有更清楚的了解😁。