"你说'几乎实时',ES 当真了 ------ 结果断电后它只记得'几乎'。"
------ 这不是直男,是异步写入的代价
💥 现象:重启后发现最近 5 分钟数据没了
- 写入成功(返回
201 Created) - 服务正常运行
- 突然断电 / kill -9 / 宕机
- 重启后:最近 5 分钟数据消失
- 日志无报错,但
_count明显少于预期
❌ 这不是 bug,是 index.translog.durability: async 的明确行为。
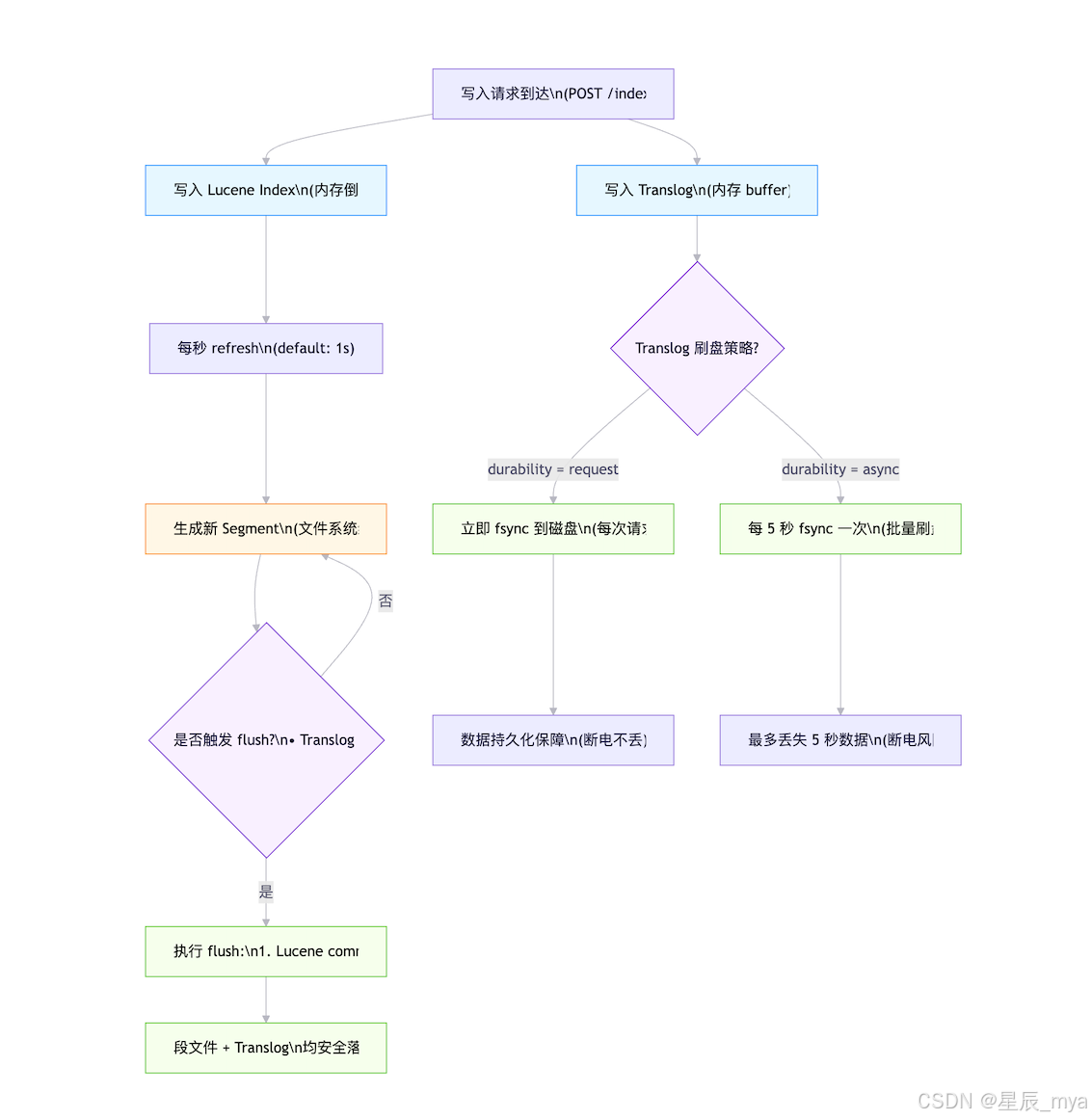
🕵️ 根因:Lucene + Translog 的双缓冲机制
ES 写入流程(简化):
- 写入请求到达 → 写入 Translog(内存 buffer)
- 同时写入 Lucene Index(内存,不可搜索)
- 每秒 refresh → Lucene 变成 可搜索段(segment)
- 定期 fsync Translog 到磁盘(持久化)
- 定期 flush → Lucene 段落盘 + 清空 Translog
| 模式 | 行为 | 数据安全性 | 性能 |
|---|---|---|---|
request(默认) |
每个写入请求都 fsync Translog | ✅ 最高(断电不丢) | ⚠️ 较低(每次 I/O) |
async |
Translog 每 5 秒 fsync 一次 | ❌ 最多丢 5 秒数据 | ✅ 高(批量 I/O) |
💡 默认就是 request! 所以如果你没改过配置,不应该丢数据 。只有显式设为 async 才会丢!
| 阶段 | 存储位置 | 是否持久化 | 是否可搜索 | 安全性 |
|---|---|---|---|---|
| Translog (内存) | 内存 | ❌ 否 | --- | 断电丢失 |
| Lucene (内存) | 内存 | ❌ 否 | ❌ 否 | 断电丢失 |
| Refresh → Segment | 文件系统缓存 | ❌ 否 | ✅ 是 | 重启可能丢失 |
| fsync Translog | 磁盘 | ✅ 是 | --- | 断电不丢(request 模式) |
| Flush | 磁盘 | ✅ 是 | ✅ 是 | 完全持久化 |
之前也有过一个图片~ 各有千秋吧
为什么有人用 async?
- 写入吞吐要求极高(如日志场景)
- 能容忍少量丢失("近实时"即可)
- 但绝不能用于订单、支付、用户注册等关键业务!
| 配置 | 最大丢失窗口 | 实测吞吐(SSD) |
|---|---|---|
durability: request |
0(请求级持久化) | ~8k writes/sec |
durability: async |
≤ 5 秒(默认 translog.sync_interval: 5s) |
~25k writes/sec |
📊 压测结论(ES 8.10, i3.2xlarge):
async吞吐提升 2--3 倍- 但 断电必丢最近 1--5 秒数据
🛠️ 正确解决方案:分层防护
第一层:关键索引强制 request(默认已满足!)
# 创建索引时显式声明(虽默认已是 request,但显式更安全)
PUT /orders-2026
{
"settings": {
"index.translog.durability": "request", // ← 默认值,可不写
"index.translog.sync_interval": "5s" // async 模式才生效
}
}GET /_settings?flat_settings=true&include_defaults=false # 查看 index.translog.durability
第二层:避免手动 flush
- 不要频繁调用
POST /_flush!- flush 会触发 Lucene commit + 清空 Translog
- 如果刚 flush 完就断电,之后所有写入全丢(因为 Translog 已清)
- 让 ES 自动 flush(默认条件:Translog > 512MB 或 30 分钟)
第三层:硬件 + OS 层加固
| 措施 | 作用 |
|---|---|
| 使用 带电容保护的 RAID 卡 | 防止 write cache 丢失 |
挂载磁盘加 data=ordered(ext4) |
保证 metadata 与 data 顺序写 |
禁用磁盘 write cache(hdparm -W0 /dev/sda) |
强制物理落盘(性能下降,慎用) |
💡 云环境注意 :AWS EBS / 阿里云云盘 默认提供 crash-consistent 保证 ,但 仍依赖 fsync!
数据丢失后能否恢复?
❌ **不能!Translog 一旦丢失,数据永久消失。**丢了就是丢了,要学会为自己的行为买单单
为什么无法恢复?
- Lucene 段文件只包含 已 refresh 的数据
- Translog 是 唯一记录未 flush 写入的地方
- 断电后内存中 Translog buffer 清零 → 无任何痕迹
唯一出路:从上游重放
- 订单系统:从 MQ 重放消息
- 日志系统:从 Filebeat 重新发送(需开启
persistent_queue) - 用户操作:前端提示"请重试"
🛡️ 预防 > 补救!防不胜防咱也没办法,但是这是小小概率事件了
"你把 durability 设成 async,就像让朋友帮你记账却说'大概记得就行',结果他喝断片了---你的钱还在,只是 ES 不记得了。"
附1:如何安全地"提升吞吐"而不丢数据?
如果写入性能不够,不要改 durability,而是:
- 增加分片数(提高并行度)
- 用 bulk 批量写入(减少请求开销)
- 调整 refresh_interval (如
"30s",降低 refresh 频率) - 升级 SSD / 增加内存(提升 I/O)
✅ 性能与安全可以兼得,前提是别碰 durability: async;万万不可
附件 1:Kibana Dashboard JSON ------ Translog 健康监控
监控这学问可大着嘞
| 指标 | 用途 |
|---|---|
indices.translog.size_in_bytes |
Translog 文件大小(突增可能预示 flush 延迟) |
indices.translog.uncommitted_operations |
未提交操作数(越高,断电丢失风险越大) |
indices.refresh.total_time_in_millis |
refresh 耗时(影响写入吞吐) |
thread_pool.write.rejected |
写入线程拒绝(可能因 Translog I/O 阻塞) |
导入方式(Kibana)
-
进入 Stack Management → Saved Objects → Import
-
上传下方 JSON 文件
{"attributes":{"description":"Monitor Translog health to prevent data loss","kibanaSavedObjectMeta":{"searchSourceJSON":"{"query":{"language":"kuery","query":""},"filter":[]}"},"title":"ES Translog Health","version":1},"id":"es-translog-health","migrationVersion":{"dashboard":"8.0.0"},"references":[],"type":"dashboard"}
{"attributes":{"columns":["indices.translog.size_in_bytes","indices.translog.uncommitted_operations"],"filters":[],"hideChart":false,"hideTotal":false,"indexPatternRefName":"pattern_0","isCompact":false,"minimumVisibleRows":5,"query":{"language":"kuery","query":""},"rowHeight":30,"sampleSize":1000,"sort":[{"columnId":"indices.translog.size_in_bytes","direction":"desc"}],"title":"Top Indices by Translog Size","viewMode":"list"},"id":"translog-size-table","migrationVersion":{"lens":"8.0.0"},"references":[{"id":"","name":"pattern_0","type":"index-pattern"}],"type":"lens"}
{"attributes":{"aggregation":"avg","axisPosition":"left","axisType":"value","breakdownBy":"index","chartType":"line","colorMapping":{},"customLabel":"","dataLayer":"indices","fieldName":"translog.uncommitted_operations","filter":"","groupBy":"terms","legendDisplay":"show","legendPosition":"right","metric":"avg","operationType":"average","palette":"default","panelTitle":"Uncommitted Operations (Risk of Data Loss)","reportDefinitions":{},"selectedMetricField":"translog.uncommitted_operations","seriesType":"normal","showGridlines":true,"showLegend":true,"timeInterval":"auto","title":"Uncommitted Operations Over Time","valueAxisScale":"linear","valueLabels":"none","visualizationType":"timeseries","xAxisScale":"time","yAxisExtents":[0,null]},"id":"uncommitted-ops-timeseries","migrationVersion":{"metrics":"8.0.0"},"references":[],"type":"metrics"}
💡 使用前提:叮咚咚
- 已启用 Elastic Stack Monitoring(或 Metricbeat 收集 ES 指标)
- 索引模式包含
.monitoring-es-*或metricbeat-*
🔔 告警规则建议(基于此 Dashboard)
- 条件 :
indices.translog.uncommitted_operations > 100000持续 5 分钟 - 动作:通知 SRE ------ "高风险:断电可能导致大量数据丢失!"