《娜璋带你读论文》系列主要是督促自己阅读优秀论文及听取学术讲座,并分享给大家,希望您喜欢。由于作者的英文水平和学术能力不高,需要不断提升,所以还请大家批评指正,非常欢迎大家给我留言评论,学术路上期待与您前行,加油。
前一篇博客介绍了一种LLM上下文驱动的Android恶意软件检测框架。本文将介绍APILI,一种面向恶意软件行为分析的深度学习方法,用于在动态执行轨迹中定位与恶意攻击技术(MITRE ATT&CK Techniques)相对应的底层 API 调用。实验结果表明 APILI 在技术发现与 API 定位两方面均优于传统方法与现有机器学习模型,显著降低分析负担。注意,由于我们团队还在不断成长和学习中,写得不好的地方还请海涵,希望这篇文章对您有所帮助,这些大佬真值得我们学习。fighting!
- 欢迎关注作者新建的『网络攻防和AI安全之家』知识星球(文章末尾)
文章目录

原文作者 :Guo-Wei Wong , Yi-Ting Huang , Ying-Ren Guo , Yeali Sun, and Meng Chang Chen
原文标题 :Attention-Based API Locating for Malware Techniques
原文链接 :https://ieeexplore.ieee.org/document/10309174
发表期刊 :IEEE TIFS 2024
其它开源代码 :https://github.com/Irish-kw/Attention-Based-API-Locating-for-Malware-Techniques
笔记作者:贵州大学 李琳
一.摘要
传统恶意软件分析难以将底层API调用与高层恶意技术直接关联,导致分析效率低下。本文提出 APILI(API LocatIng System),一种面向行为型恶意软件分析的深度学习框架,用于在动态执行轨迹中定位与已发现恶意技术相对应的 API 调用。
- APILI 在 API 调用、系统资源以及攻击技术三者之间构建多重注意力机制,并将 MITRE ATT&CK 框架中的战术、技术及过程知识嵌入神经网络结构中。
- 方法采用微调 BERT 进行参数/资源语义嵌入,利用奇异值分解(SVD)构建技术表示空间,并设计层级结构与噪声增强机制以提升 API 定位能力。
据作者所述,这是首个能够将高层恶意技术语义与低层 API 调用行为证据进行自动对齐的深度学习方法。实验表明,APILI 在技术识别与 API 定位两项任务中均优于传统规则系统及其他机器学习方法,显著降低了分析人员的工作负担。
二.研究动机与贡献
论文首先指出网络威胁情报知识库(如 MITRE ATT&CK)虽提供标准化的攻击技术描述,但这些描述停留在语义层级,并不包含对应的具体系统执行证据,如 API 调用或审计日志事件。相反,恶意行为的真实体现存在于动态执行轨迹中的 API 调用序列及其参数资源。这种"高层技术语义"与"低层系统行为证据"之间的抽象差异构成了严重的语义鸿沟,使得安全分析仍依赖人工规则或专家经验建立映射,既难扩展又易误报。论文将这一问题界定为API Locating Problem,即从高层 ATT&CK 技术反向定位其底层实现 API。
作者强调,ATT&CK 技术具有精确定义的攻击语义,可作为恶意行为分析的中间语义层。传统系统(如 Holmes、RapSheet)通过手工规则实现跨层映射,但规则构建成本高且难以适应攻击变种。论文动机在于设计一种无需专家知识、通过表示学习自动建模"技术-资源-API"因果依赖的深度学习框架。该框架不仅能够发现恶意技术,还能直接定位关键 API 调用,从而建立跨层行为解释链。
本文的核心贡献在于提出了一个跨层注意力传播模型,实现 API 行为、资源对象与攻击技术三层语义之间的自动对齐。首先,设计资源注意力机制以捕捉 API 调用与系统对象之间的语义依赖;其次,引入技术注意力机制并结合技术嵌入空间实现资源到 ATT&CK 技术的映射;最后,在大规模真实数据集上验证模型在技术识别与 API 定位两项任务中的显著性能优势。
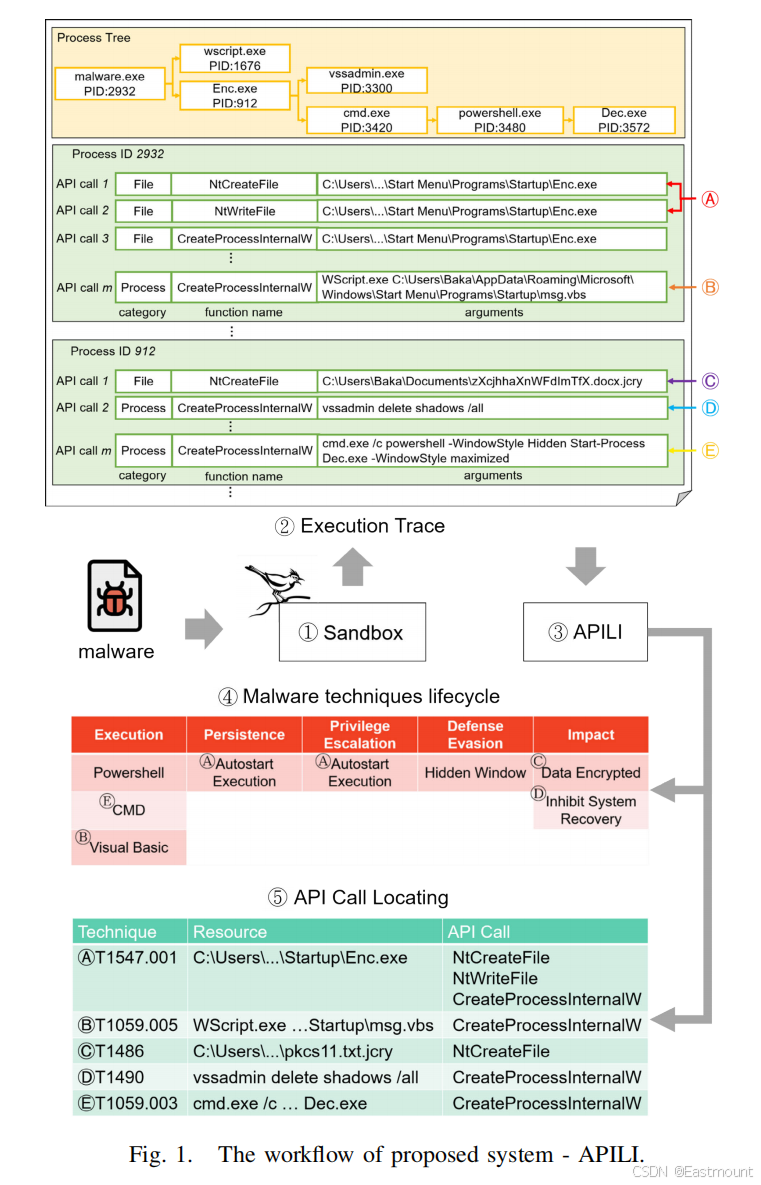
三.背景和挑战
1.Cuckoo Sandbox
Cuckoo Sandbox 是常用的动态分析平台,通过虚拟环境执行恶意软件并生成 API 调用轨迹,再利用签名规则识别恶意行为。然而该系统依赖专家编写签名,维护成本高,且难以覆盖 API 与 ATT&CK 技术之间复杂的多对多关系。本文仅将 Cuckoo 作为轨迹采集工具,而将语义建模任务交由深度模型完成。
2.Dynamic Malware Analysis
动态分析产生的执行轨迹具有层级结构,包括进程树、API 调用序列及其参数。API 调用在本文被视为最小行为单元,由类别、函数名和参数组成,其中参数对应被操作的系统资源(文件、注册表、进程等)。论文指出恶意行为与 API 调用存在强相关性,参数语义尤为关键,因此需要对参数进行语义嵌入以保留行为含义。
- execution trace
- process tree
- Process
- API call
3.MITRE ATT&CK Framework
ATT&CK 提供战术、技术与过程的结构化攻击知识体系。技术在本文中作为恶意行为的语义标签,每种技术可能由一个或多个 API 调用实现,且可能分散在不同时间或进程中,呈现明显的多对多映射。这种复杂关系使规则匹配难以奏效,成为模型设计核心挑战。
- tactic
- technique/sub-technique
- procedure
4.Deep Learning
论文借鉴自然语言处理中的嵌入与注意力机制,将 API 调用视为"句子",将参数视为"词语"。BERT 用于生成参数上下文语义表示,而注意力机制用于识别与特定技术最相关的资源与 API,从而在序列中选择关键行为证据。
5.Motivation and Key Challenges
核心挑战包括进程与 API 数量可变、技术相关实体识别困难,以及合法行为与恶意行为的混淆问题。尤其是 API 与技术之间的多对多关系,使单次规则匹配不可行。APILI 通过多层注意力传播建模资源因果流,降低误报并实现跨层语义对齐。
- Variable numbers of processes and API calls
- Identification of technique relevant entities
- Resource correlation for false positive reduction
四.模型设计
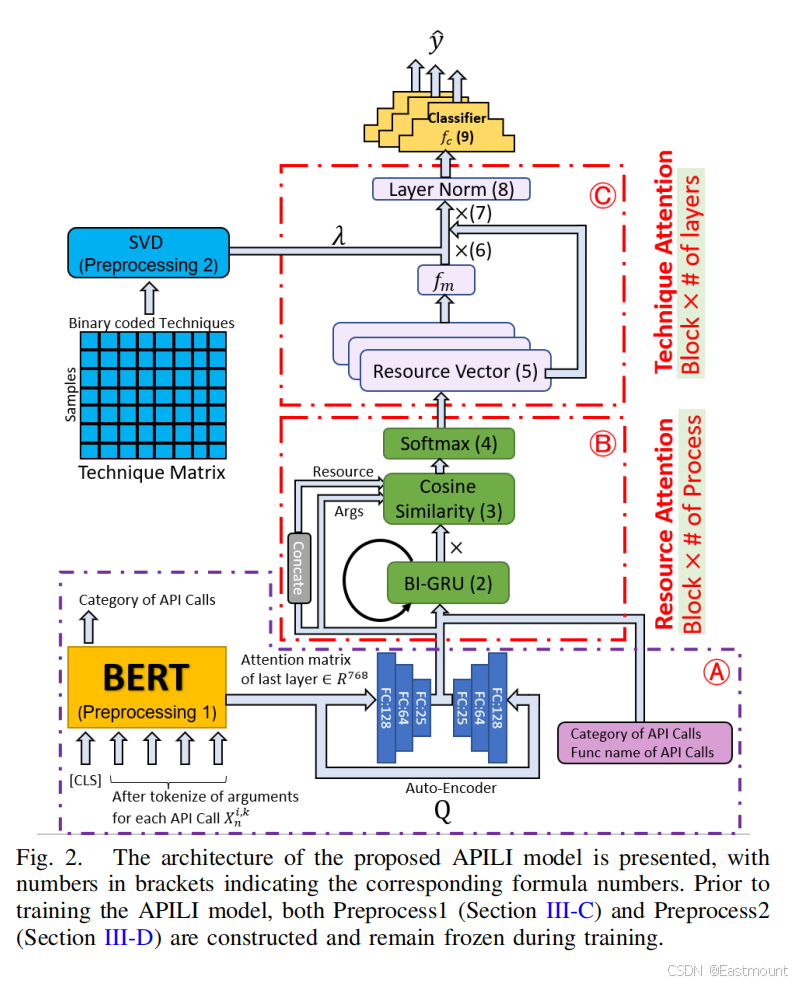
本节对 APILI 系统、神经网络模型以及 API 调用定位方法进行总体概述。在模型训练之前,首先进行两个预处理步骤:API 调用嵌入表示和攻击技术表示学习。APILI 模型的高层结构如图 2 所示。该模型以恶意软件样本的动态行为作为输入,这些行为由 Cuckoo 沙箱记录。为支持攻击技术发现与 API 调用定位,APILI 引入了两种注意力机制:资源注意力(resource attention)和技术注意力(technique attention)。
- 左支路:API调用语义分支
- 右支路:API调用行为分支
- 中间融合:注意力机制定位技术
1.技术发现机制
该部分将恶意技术识别形式化为多标签分类问题。论文假设一个恶意样本可产生多个进程,而每个进程可能对应不同 ATT&CK 技术集合,因此以进程为基本分析单元进行建模。这种设计避免了跨进程语义干扰,使技术识别更加精细化。模型使用二元相关(Binary Relevance, BR)策略,将多标签任务拆解为多个独立二分类子任务,每个技术对应一个分类器,从而实现对技术存在性的概率建模。
技术预测基于公式(1)完成。模型先对每个进程计算技术概率,再进行样本级聚合,只要任一进程满足阈值条件即判定该技术存在。这一设计反映了恶意行为的"局部触发即可整体成立"的特征,符合攻击技术在实际执行中的分布式实现模式。该阶段的输出不仅用于技术发现,还为后续 API 定位提供监督信号,是 APILI 整体推理链条的起点。
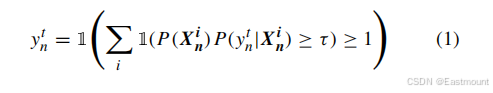
2.系统总体结构
图2展示了 APILI 的核心结构,该模型由两类注意力机制构成:资源注意力(Resource Attention)与技术注意力(Technique Attention),分别用于刻画"API→资源"与"资源→技术"的双层语义映射。这种层级式注意力设计体现了因果链式建模思想,即先建立底层操作与系统资源之间的关联,再推理资源与高层攻击技术之间的联系。
系统前置两个冻结预处理模块:
- API 嵌入模块
- 技术表示模块
这种"预训练 + 端到端训练"的混合架构在保证语义表达能力的同时降低了训练复杂度。整个模型从输入动态执行轨迹到输出技术概率与 API 定位结果形成闭环,实现从行为表征到因果定位的自动化推理流程,是本研究的核心创新框架。
3.API Call表示学习
API 调用被视为"类自然语言句子",其语义由类别、函数名及参数共同构成。论文采用微调 BERT对字符串参数进行语义编码,这一选择优于传统 Doc2vec 的原因在于:BERT 能捕捉上下文语义依赖,并通过 WordPiece 机制有效表示 CLSID 等稀有符号,从而提升对恶意行为关键参数的表达能力。
编码流程中,参数向量经 AutoEncoder 压缩为低维表示,再与类别和函数名嵌入拼接形成 API 向量。这种结构保持了 API 语义完整性,同时避免高维噪声干扰。该嵌入是整个模型后续注意力计算的基础,其质量直接影响技术发现与资源定位的准确性。此设计体现了"语义保真优先于结构简化"的建模原则。
本研究将改用微调后的BERT把API调用的字符串实参映射成768维向量。BERT是动态嵌入,同一词在不同上下文里向量不同,Doc2vec是静态的,一词一向量。实参里常出现罕见词(如 COM 类 CLSID),Doc2vec 直接当 OOV 扔掉;BERT 的 30 k WordPiece 子词表能把罕见词拆成子词,依旧生成可用向量。
4.技术语义表示
ATT&CK 技术之间存在共现与组合关系,论文构建技术共现矩阵并通过 SVD/PCA降维得到技术表示 λ。该表示反映技术之间的语义相关性,使模型具备对"技术协同出现模式"的理解能力,而不仅依赖单点标签监督。
这一模块等价于构建攻击技术的"潜在语义空间"。技术注意力后续利用该表示计算资源---技术相关性,从而实现从底层资源行为到高层攻击策略的映射。该方法避免了人工规则维护,是 APILI 脱离专家规则的重要步骤。
攻击模式是多技术组合,ATT&CK技术与API调用之间存在强相关性,用"技术"比直接用原始API更能表达"攻击意图",于是建了一张样本-技术共现矩阵(行 = 恶意软件样本,列 = 技术,值 = 是否出现),矩阵巨大且稀疏,需要降维同时保留语义。选用SVD或PCA是将大矩阵拆成"低维特征向量",每行样本得到一条紧凑向量,后续可直接喂给分类器或注意力模块。
5.资源注意力机制
该机制首先通过 Bi-GRU 建模 API 调用序列的时序依赖,获得隐藏状态 hn。随后提取所有唯一参数作为资源集合 rn,并计算 API 参数向量与资源向量的余弦相似度,形成资源注意力权重矩阵 rw。这一矩阵刻画"哪些 API 操作与哪些系统资源高度相关"。
资源向量 rv=hn×rw 是后续技术推理的关键中间表示。资源注意力不仅用于 API 定位,也为技术发现提供资源上下文。其本质是一个因果线索提取层,强调资源在攻击行为中的核心地位。该设计显著降低了误报,因为它引入资源间信息流依赖,而非孤立行为判断。
6.技术注意力机制
技术注意力以资源向量为输入,与技术表示 λ 进行线性映射后加入噪声并经 softmax 归一化,得到技术注意力 dw。噪声注入用于打破相同注意力值导致的分区问题,提高模型泛化性与排序区分能力。
随后通过递归层归一化(LayerNorm)迭代更新资源向量,实现多层语义传播。这一多层注意力传播机制使模型能够捕捉跨资源、跨技术的复杂依赖关系,等价于在技术空间进行图传播。该部分体现了 APILI 从单跳相关推理扩展到多跳因果推理的能力,是性能提升的关键因素。
7.损失函数设计
模型目标由两部分组成:
- 一是 Binary Cross Entropy 用于技术分类;
- 二是 Resource Distance Loss 用于最大化真实资源的注意力权重。
资源距离损失迫使模型在技术预测前优先校准资源注意力,使技术预测依赖于正确的因果资源,而非噪声信号。最终联合损失函数形成端到端优化目标。这种"先因果对齐、再语义分类"的设计使模型同时具备高技术识别率和高 API 定位精度。
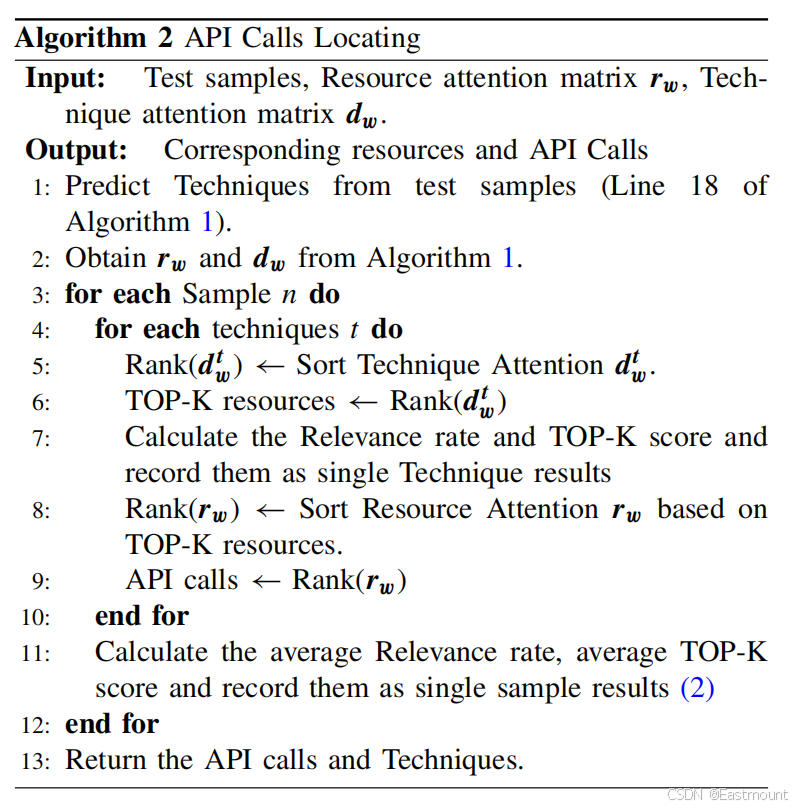
8.API 调用定位机制
模型训练完成后,技术注意力排序得到 TOP-K 关键资源,再利用资源注意力矩阵定位对应参数及 API 调用。由于资源与 API 参数在查找表中存在映射关系,整个定位过程可自动完成,无需人工规则。API定位的意义在于不需要人工去一条条看API调用,而是直接告诉哪些API可能和某个恶意行为有关。
评价指标包括 Relevance、TOP-K、MAP-K、MRR,体现资源排序质量。该阶段证明 APILI 能从高层技术反向推理到底层 API,实现"技术→资源→API"的可解释因果链路,这是该论文区别于传统恶意检测工作的核心突破。
APILI模型通过两个注意力机制来完成API定位:
- 技术注意力:判断某个技术与哪些系统资源最相关,输出的是一个注意力向量,表示每个资源对该技术的重要性。
- 资源注意力:判断某个资源是哪些API调用操作的,输出的是另一个注意力向量,表示每个API对该资源的操作强度。
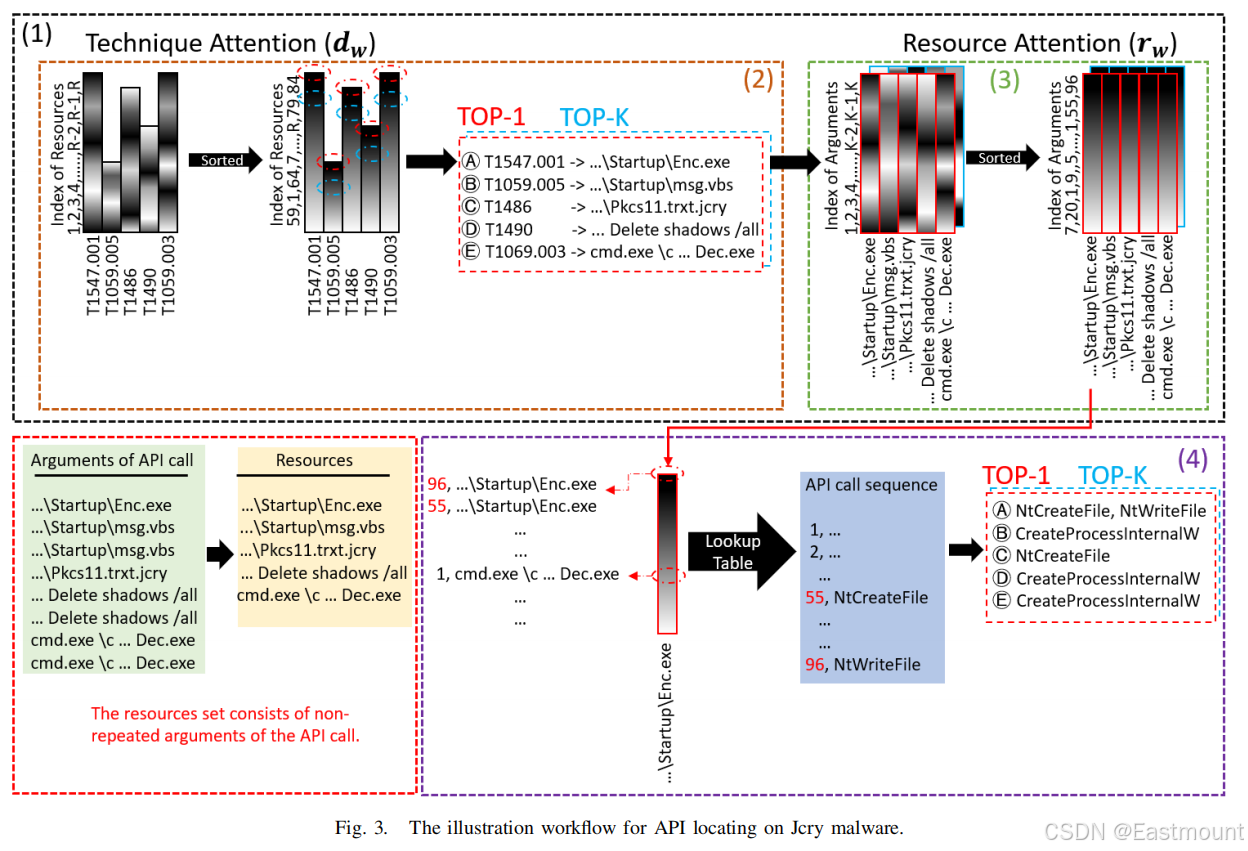
API定位的流程:
- 预测技术:用训练好的模型预测出该样本中存在的所有技术
- 提取注意力矩阵:从模型中提取技术注意力矩阵和资源注意力矩阵
- 排序资源:对每个技术,按技术注意力值从高到低排序,选出TOP-K个最相关的资源
- 排序API:从选中的资源中,按资源注意力值排序,找出操作这些资源的API调用
- 查找API调用:通过查找表将资源映射回原始的API调用,完成定位

五.实证研究
1.实验设置
实验部分首先明确了评估环境与数据来源。所有实验均基于 Cuckoo Sandbox 动态分析日志构建 API 调用序列,样本涵盖多种恶意软件家族,保证行为技术覆盖面。为确保评估客观性,作者采用训练集、验证集、测试集分离策略,并对不同攻击技术类别保持分布平衡。数据预处理阶段包含 API 标准化、去噪、序列截断与填充操作,使模型输入维度统一,同时保留关键行为顺序信息。
从实验结构上看,APILI 的评估分为"技术发现能力"和"API 定位能力"两个核心任务,分别对应 技术级别识别性能 与 行为级别定位精度。这种双层评估框架体现了论文研究目标------不仅识别恶意技术类别,还需定位其在行为序列中的具体 API 来源,从而提升安全可解释性。
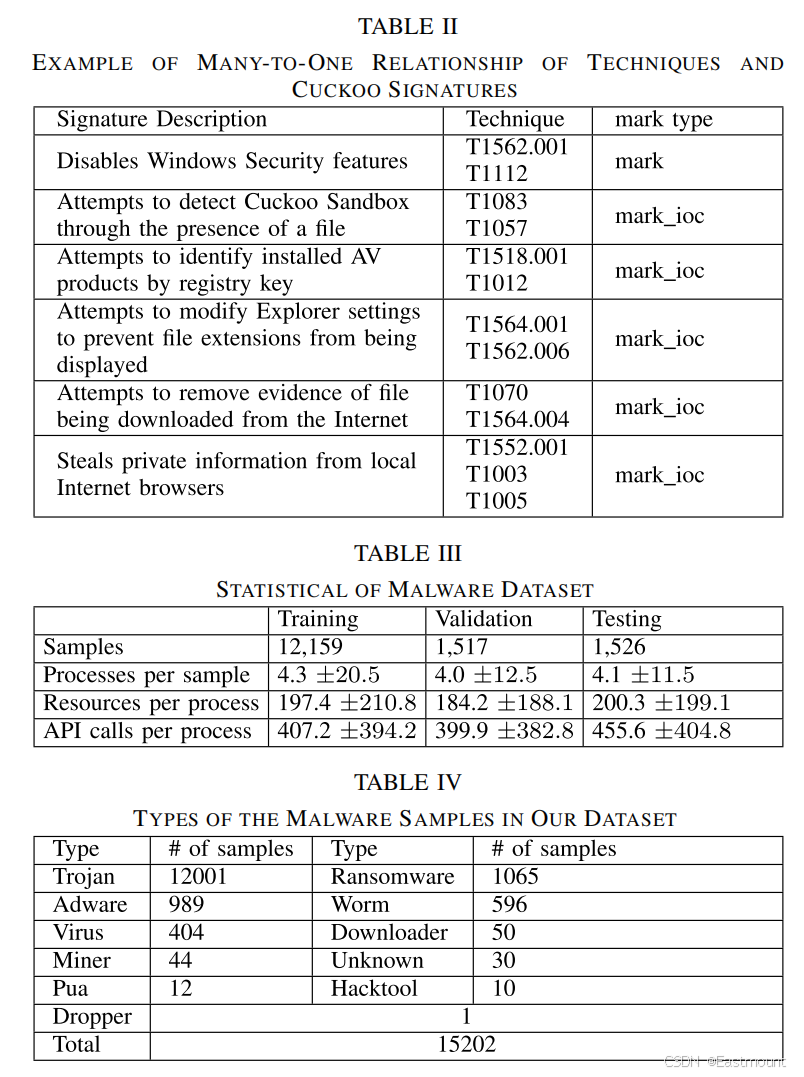
论文采用多维度指标体系以全面反映模型性能。技术发现任务主要使用 Precision、Recall、F1-score;API 定位任务额外引入 Localization Accuracy。其中,F1-score 用于衡量模型在类别识别中的综合能力,而定位准确率衡量模型是否正确识别技术对应的关键 API 调用点。实验分析包含15202个样本的数据集,对APILI进行了全面评估。
- 将APILI与其他七种机器学习方法以及两种深度学习模型进行了性能比较
- 使用TOP-K评分,MAP-K评分和MRR来衡量API定位性能对API调用预测的准确性
- 为深入了解APILI中每个单独成分的贡献,进行了消融研究
- 提高了一个详细案例研究,证明APILI的实用性,案例研究真是了APILI如何在真实场景中有效找到系统资源和相应的API调用。
2.实现细节
模型实现基于 PyTorch 框架,采用 Adam 优化器与交叉熵损失函数。训练过程中引入 dropout 与早停策略以防止过拟合。嵌入层采用 API 调用语义嵌入与技术标签嵌入的联合表示。训练批次大小与学习率经过网格搜索优化,以达到最佳收敛状态。
从效率结果图可以观察到,APILI 在增加双注意力机制后训练时间增长有限,而推理阶段延迟仍维持在可接受范围。这说明模型在复杂语义建模与运行效率之间取得了良好平衡。
3.实验评估
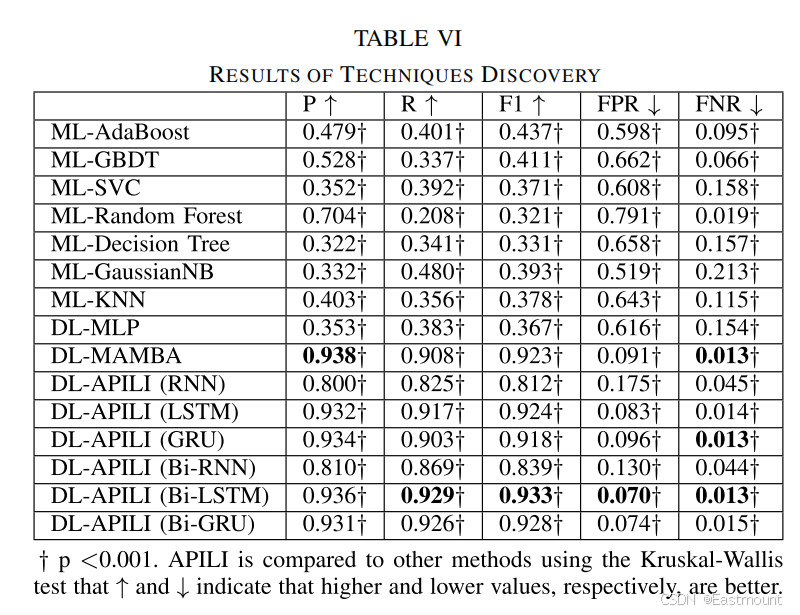
Technique Discovery
技术发现任务的实验结果如表 6 所示。APILI 在所有技术类别上的 F1-score 均高于对比模型,尤其在复杂技术(如多阶段攻击链)上的 Recall 提升明显。该结果表明,模型能够捕捉长距离依赖,避免传统模型因序列过长导致语义稀释的问题。
API Locating
API 定位实验结果(表 7)显示,APILI 在定位准确率方面大幅领先基线模型。特别是在长序列样本中,其性能下降幅度最小。这说明资源注意力机制有效解决了"多进程多资源依赖"的复杂行为链问题。
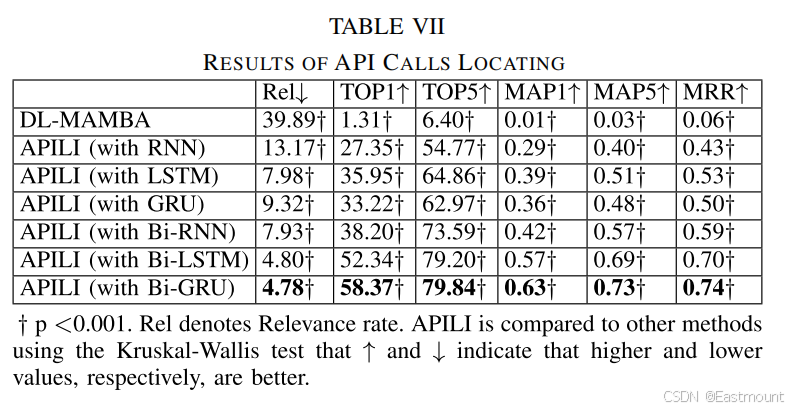
图 4 展示了模型在一个真实样本中的 API 定位热力图。可以观察到模型对攻击关键 API 调用分配了显著更高权重,而对无关调用权重较低。这种可解释性增强了模型在安全取证场景中的应用价值。

Ablation Study
消融实验(表 8)验证了模型组件的重要性。去除资源注意力后,误报率显著上升;去除技术注意力后,Recall 明显下降。这说明两种注意力机制分别承担"行为因果建模"与"技术语义对齐"的关键角色。
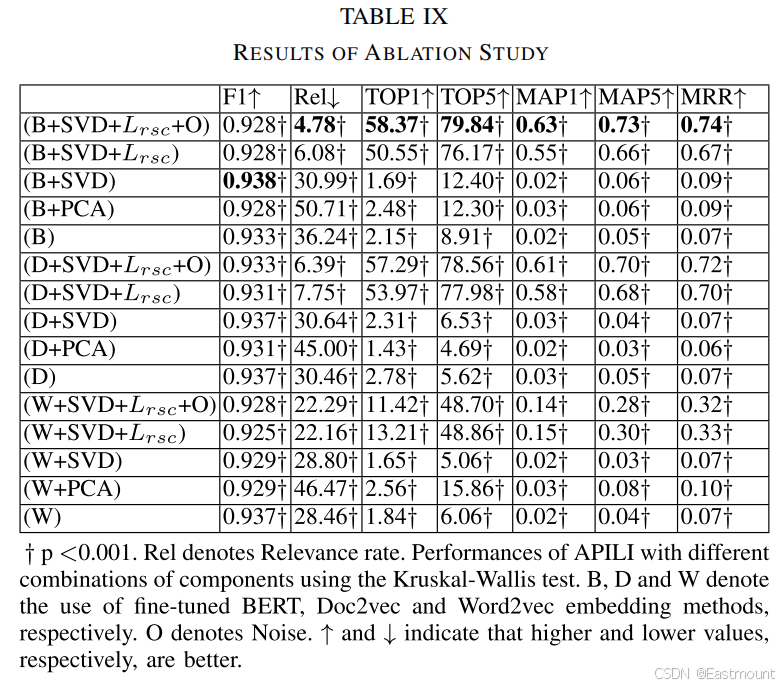
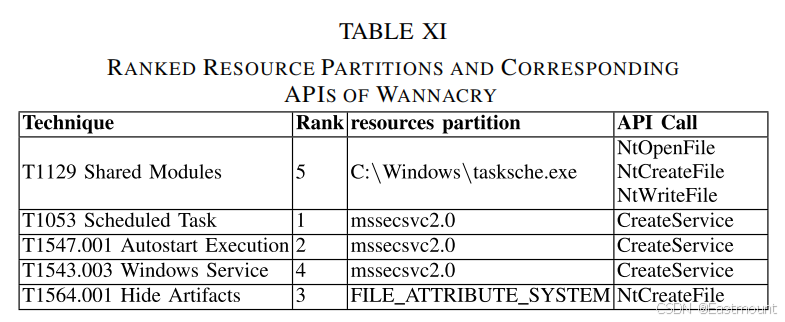
表11和案例分析图(图4)展示了 APILI 在真实恶意样本中的技术识别与 API 定位结果。模型成功识别出多个相关 API 并将其映射至对应攻击技术。该结果证明模型不仅能输出分类标签,还能提供攻击链级别的解释。
六.讨论与结论
本文提出了一种基于注意力的恶意软件行为分析机制APILI,用于自动识别MITRE ATT和CK技术及其对应的API调用。
- 第一阶段:训练一个具有资源注意力输出的BiGRU,以发现API调用和被操纵的系统资源之间的关系。
- 第二阶段:使用所提出的技术注意来探索资源和技术之间的关系。
传统的动态恶意软件分析工具需要大量的人力来构建知识并分析恶意软件样本的恶意行为。我们的系统减少了分析人员发现恶意行为和对可疑系统资源进行排序的工作量。我们使用了Cuckoo Sandbox,用于恶意软件分析以记录API跟踪,使用API调用嵌入和技术表示来构造领域知识和进行威胁推 理,对APILI的实验评估表明,能够准确识别恶意行为及其对应的API调用,包括技术和API调用之间的一对多和多对多映射。
结论:APILI的优势在于减少了专家手动定位基于签名的系统无法推断的API调用的需要,这是第一次尝试使用深度学习方法来定位与发现高质量的数据
未来展望:将考虑将该技术应用于审计日志,与API定位类似,将一项技术与审计日志的一个或多个事件相关联,极大帮助识别隐形攻击。
2024年4月28日是Eastmount的安全星球------『网络攻防和AI安全之家』正式创建和运营的日子,该星球目前主营业务为 安全零基础答疑、安全技术分享、AI安全技术分享、AI安全论文交流、威胁情报每日推送、网络攻防技术总结、系统安全技术实战、面试求职、安全考研考博、简历修改及润色、学术交流及答疑、人脉触达、认知提升等。下面是星球的新人券,欢迎新老博友和朋友加入,一起分享更多安全知识,比较良心的星球,非常适合初学者和换安全专业的读者学习。
目前收到了很多博友、朋友和老师的支持和点赞,尤其是一些看了我文章多年的老粉,购买来感谢,真的很感动,类目。未来,我将分享更多高质量文章,更多安全干货,真心帮助到大家。虽然起步晚,但贵在坚持,像十多年如一日的博客分享那样,脚踏实地,只争朝夕。继续加油,再次感谢!
(By:Eastmount 2026-02-09 周一夜于贵阳 http://blog.csdn.net/eastmount/ )
前文赏析:
- 论文阅读 (01)拿什么来拯救我的拖延症?初学者如何提升编程兴趣及LATEX入门详解
- 论文阅读 (02)SP2019-Neural Cleanse: Identifying and Mitigating Backdoor Attacks in DNN
- 论文阅读 (03)清华张超老师 - GreyOne: Discover Vulnerabilities with Data Flow Sensitive Fuzzing
- 论文阅读 (04)人工智能真的安全吗?浙大团队外滩大会分享AI对抗样本技术
- 论文阅读 (05)NLP知识总结及NLP论文撰写之道------Pvop老师
- 论文阅读 (06)万字详解什么是生成对抗网络GAN?经典论文及案例普及
- 论文阅读 (07)RAID2020 Cyber Threat Intelligence Modeling Based on Heterogeneous GCN
- 论文阅读 (08)NDSS2020 UNICORN: Runtime Provenance-Based Detector for Advanced Persistent Threats
- 论文阅读 (09)S&P2019 HOLMES Real-time APT Detection through Correlation of Suspicious Information Flow
- 论文阅读 (10)基于溯源图的APT攻击检测安全顶会总结
- 论文阅读 (11)ACE算法和暗通道先验图像去雾算法(Rizzi | 何恺明老师)
- 论文阅读 (12)英文论文引言introduction如何撰写及精句摘抄------以入侵检测系统(IDS)为例
- 论文阅读 (13)英文论文模型设计(Model Design)如何撰写及精句摘抄------以入侵检测系统(IDS)为例
- 论文阅读 (14)英文论文实验评估(Evaluation)如何撰写及精句摘抄(上)------以入侵检测系统(IDS)为例
- 论文阅读 (15)英文SCI论文审稿意见及应对策略学习笔记总结
- 论文阅读 (16)Powershell恶意代码检测论文总结及抽象语法树(AST)提取
- 论文阅读 (17)CCS2019 针对PowerShell脚本的轻量级去混淆和语义感知攻击检测
- 论文阅读 (18)英文论文Model Design和Overview如何撰写及精句摘抄------以系统AI安全顶会为例
- 论文阅读 (19)英文论文Evaluation(实验数据集、指标和环境)如何描述及精句摘抄------以系统AI安全顶会为例
- 论文阅读 (20)USENIXSec21 DeepReflect:通过二进制重构发现恶意功能(恶意代码ROI分析经典)
- 论文阅读 (21)S&P21 Survivalism: Systematic Analysis of Windows Malware Living-Off-The-Land (经典离地攻击)
- 论文阅读 (22)图神经网络及认知推理总结和普及-清华唐杰老师
- 论文阅读 (23)恶意代码作者溯源(去匿名化)经典论文阅读:二进制和源代码对比
- 论文阅读 (24)向量表征:从Word2vec和Doc2vec到Deepwalk和Graph2vec,再到Asm2vec和Log2vec(一)
- 论文阅读 (25)向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)
- 论文阅读 (26)基于Excel可视化分析的论文实验图表绘制总结------以电影市场为例
- 论文阅读 (27)AAAI20 Order Matters: 二进制代码相似性检测(腾讯科恩实验室)
- 论文阅读 (28)李沐老师视频学习------1.研究的艺术·跟读者建立联系
- 论文阅读 (29)李沐老师视频学习------2.研究的艺术·明白问题的重要性
- 论文阅读 (30)李沐老师视频学习------3.研究的艺术·讲好故事和论点
- 论文阅读 (31)李沐老师视频学习------4.研究的艺术·理由、论据和担保
- 论文阅读 (32)南洋理工大学刘杨教授------网络空间安全和AIGC整合之道学习笔记及强推(InForSec)
- 论文阅读 (33)NDSS2024 Summer系统安全和恶意代码分析方向相关论文汇总
- 论文阅读 (34)EWAS2024 基于SGDC的轻量级入侵检测系统
- 论文阅读 (35)TIFS24 MEGR-APT:基于攻击表示学习的高效内存APT猎杀系统
- 论文阅读 (36)C&S22 MPSAutodetect:基于自编码器的恶意Powershell脚本检测模型
- 论文阅读 (37)CCS21 DeepAID:基于深度学习的异常检测(解释)
- 论文阅读 (38)基于大模型的威胁情报分析与知识图谱构建论文总结(读书笔记)
- 论文阅读 (39)EuroS&P25 CTINEXUS:基于大模型的威胁情报知识图谱自动构建
- 论文阅读 (40)CCS24 PowerPeeler:一种通用的PowerShell脚本动态去混淆方法
- 论文阅读 (41)JISA24 物联网环境下基于少样本学习的攻击流量分类
- 论文阅读 (42)ASC25 基于大语言模型的未知Web攻击威胁检测
- 论文阅读 (43)ESWA25 评估大模型在真实攻击活动的恶意代码解混淆能力
- 论文阅读 (44)一种基于LLM少样本多标签的Android恶意软件检测方法
- 论文阅读 (45)C&S24 AISL: 基于攻击意图驱动与序列学习方法的APT攻击检测
- 论文阅读 (46)IDS-Agent: 一种用于物联网可解释入侵检测的大模型Agent
- 论文阅读 (47)LAMD: 基于大模型上下文驱动的Android恶意软件检测与分类
- 论文阅读 (48)TIFS24 基于注意力的恶意软件API定位技术