
前言:凌晨两点的崩溃现场
上周五晚上十点
我刚准备关电脑下班
老板突然发来消息
客户的AI客服系统炸了
五千个用户在线排队
超时率百分之八十五
我打开监控一看
GPT API调用全线崩溃
请求堆积如山
错误日志刷屏
那一刻我在想
为什么调用个API这么难

一、打工人的三大噩梦
噩梦一:接口对接地狱
你以为调用GPT很简单
注册个OpenAI账号就完事
但现实是
客户今天要GPT-5.2写文案
明天要Claude Opus 4.6审代码
后天要Kimi K2.5做知识问答
大后天要Sora2生成视频
每个模型的API协议都不一样
你得维护五套代码
就像你家里有五个遥控器
电视一个
空调一个
机顶盒一个
投影仪一个
音响一个
每次操作都要找对应的遥控器
找错了就白按
噩梦二:超时问题让人崩溃
我用Postman测试过
国内直连OpenAI服务器
延迟普遍在八百到两千毫秒
高峰期直接飙到五千毫秒以上
十次请求有三次直接超时
就像你在高速公路上开车
前面突然堵车
你急得要命
但就是动不了
噩梦三:预算浪费让老板心疼
OpenAI的Plus套餐二十美元一个月
听起来不贵
但问题是
月初需求多
Token用得快
月中月末需求少
配额闲置
配额不能累积
过期就浪费
算下来实际利用率只有百分之六十
老板看着账单直摇头

二、向量引擎OpenClaw横空出世
就在我快要放弃的时候
朋友给我推荐了向量引擎
说他们最近推出了OpenClaw配置工具
可以自定义中转站
我抱着试试看的心态注册了
没想到
这一试
直接改变了我的开发方式
什么是OpenClaw
OpenClaw是向量引擎推出的自定义中转站配置工具
说人话就是
它给你搭建了一个专属的API通道
你不用再直连OpenAI服务器
而是通过向量引擎的高速节点中转
就像你从北京到上海
以前要坐绿皮火车
现在可以坐高铁
速度快了
还更稳定
OpenClaw的五大杀手锏
杀手锏一:CN2高速通道
向量引擎在全球部署了七个CN2节点
什么是CN2
简单说就是中国电信的高速公路
普通网络像国道
要经过很多红绿灯
CN2网络像高速公路
直达目的地
实测数据
平均延迟从一千两百毫秒降到三百八十毫秒
降低了百分之六十八
超时率从百分之八点五降到百分之零点二
降低了百分之九十七
杀手锏二:智能负载均衡
假设你去银行办业务
传统方式是所有人排一个队
前面有人办慢了
后面全堵住
智能负载均衡就是
自动分配到人少的窗口
效率提升三倍
向量引擎内置智能负载均衡算法
按节点并发量自动分配请求
避免单节点过载
杀手锏三:零代码迁移
这是我最满意的一点
迁移只需要改两处
第一处:base_url改为向量引擎地址
第二处:api_key替换为向量引擎密钥
十分钟搞定
而且完全兼容OpenAI SDK
也兼容LangChain和LlamaIndex
我的RAG项目无缝迁移

杀手锏四:按需付费永不过期
OpenAI Plus是固定月费
用不完就浪费
向量引擎是按Token付费
充值金额永不过期
我的实际使用情况
月初项目多充值五十美元用了三十五美元
月中项目少剩余十五美元继续用
下个月余额累积使用不浪费
三个月下来比OpenAI Plus省了八十美元
杀手锏五:多模型一站式调用
向量引擎集成了六百一十八个模型
包括
OpenAI全系列
Anthropic的Claude系列
Google的Gemini系列
国产的Kimi和DeepSeek
还有Midjourney、Sora2、Veo3等多模态模型
一个接口全搞定
三、OpenClaw配置实战教程
说了这么多理论
现在进入实战环节
我会手把手教你配置OpenClaw
保证小白也能看懂
第一步:注册并获取密钥
访问向量引擎官网
官方地址:https://api.vectorengine.ai/register?aff=QfS4
注册流程很简单
填写邮箱
设置密码
验证邮箱
登录后进入控制台
点击API密钥
生成专属密钥
复制保存好
这个密钥就是你的通行证
第二步:安装开发环境
打开终端
输入以下命令
bash
pip install openai等待安装完成
验证安装是否成功
bash
python -c "import openai; print(openai.__version__)"如果输出版本号
说明安装成功

第三步:编写调用代码
创建一个新的Python文件
命名为test_gpt.py
输入以下代码
python
from openai import OpenAI
client = OpenAI(
api_key="你的向量引擎密钥",
base_url="https://api.vectorengine.ai/v1"
)
response = client.chat.completions.create(
model="gpt-5.2",
messages=[
{"role": "system", "content": "你是一个专业的技术顾问"},
{"role": "user", "content": "解释一下什么是负载均衡"}
]
)
print(response.choices[0].message.content)保存文件
运行代码
bash
python test_gpt.py如果看到GPT的回复
恭喜你
配置成功
第四步:多模型切换
向量引擎的强大之处在于
可以轻松切换不同模型
只需要修改model参数
调用Claude Opus 4.6
python
response = client.chat.completions.create(
model="claude-opus-4-6",
messages=[
{"role": "user", "content": "优化这段代码"}
]
)调用Kimi K2.5
python
response = client.chat.completions.create(
model="kimi-k2.5",
messages=[
{"role": "user", "content": "总结这篇文档"}
]
)调用GPT-5.3-Codex
python
response = client.chat.completions.create(
model="gpt-5.3-codex",
messages=[
{"role": "user", "content": "写一个快速排序算法"}
]
)就是这么简单
四、生产环境最佳实践
光会调用还不够
生产环境需要考虑更多
错误处理
重试机制
并发控制
日志记录
下面是完整的生产级代码
带错误处理的调用
python
from openai import OpenAI, APIError, APIConnectionError, RateLimitError
import time
import logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class GPTClient:
def __init__(self, api_key, max_retries=3):
self.client = OpenAI(
api_key=api_key,
base_url="https://api.vectorengine.ai/v1",
timeout=30.0
)
self.max_retries = max_retries
def chat(self, messages, model="gpt-5.2"):
for attempt in range(self.max_retries):
try:
logger.info(f"发起请求,尝试次数: {attempt + 1}")
response = self.client.chat.completions.create(
model=model,
messages=messages
)
logger.info("请求成功")
return response.choices[0].message.content
except RateLimitError as e:
logger.warning(f"触发速率限制: {e}")
if attempt < self.max_retries - 1:
wait_time = (2 ** attempt) * 2
logger.info(f"等待 {wait_time} 秒后重试")
time.sleep(wait_time)
else:
raise
except APIConnectionError as e:
logger.error(f"网络连接失败: {e}")
if attempt < self.max_retries - 1:
wait_time = 2 ** attempt
time.sleep(wait_time)
else:
raise
except APIError as e:
logger.error(f"API错误: {e}")
if e.status_code >= 500:
if attempt < self.max_retries - 1:
time.sleep(2 ** attempt)
else:
raise
else:
raise
client = GPTClient(api_key="你的密钥")
result = client.chat([
{"role": "user", "content": "你好"}
])
print(result)这段代码实现了
错误分类处理
指数退避重试
日志记录
超时控制
异步批量处理
如果你需要同时处理大量请求
异步调用是最佳选择
python
import asyncio
from openai import AsyncOpenAI
class AsyncGPTClient:
def __init__(self, api_key, max_concurrent=10):
self.client = AsyncOpenAI(
api_key=api_key,
base_url="https://api.vectorengine.ai/v1"
)
self.semaphore = asyncio.Semaphore(max_concurrent)
async def chat_single(self, messages, model="gpt-5.2"):
async with self.semaphore:
try:
response = await self.client.chat.completions.create(
model=model,
messages=messages
)
return {
"success": True,
"content": response.choices[0].message.content
}
except Exception as e:
return {
"success": False,
"error": str(e)
}
async def chat_batch(self, messages_list, model="gpt-5.2"):
tasks = [
self.chat_single(messages, model)
for messages in messages_list
]
return await asyncio.gather(*tasks)
async def main():
client = AsyncGPTClient(api_key="你的密钥")
messages_list = [
[{"role": "user", "content": f"问题{i}"}]
for i in range(100)
]
results = await client.chat_batch(messages_list)
success_count = sum(1 for r in results if r["success"])
print(f"成功: {success_count}/100")
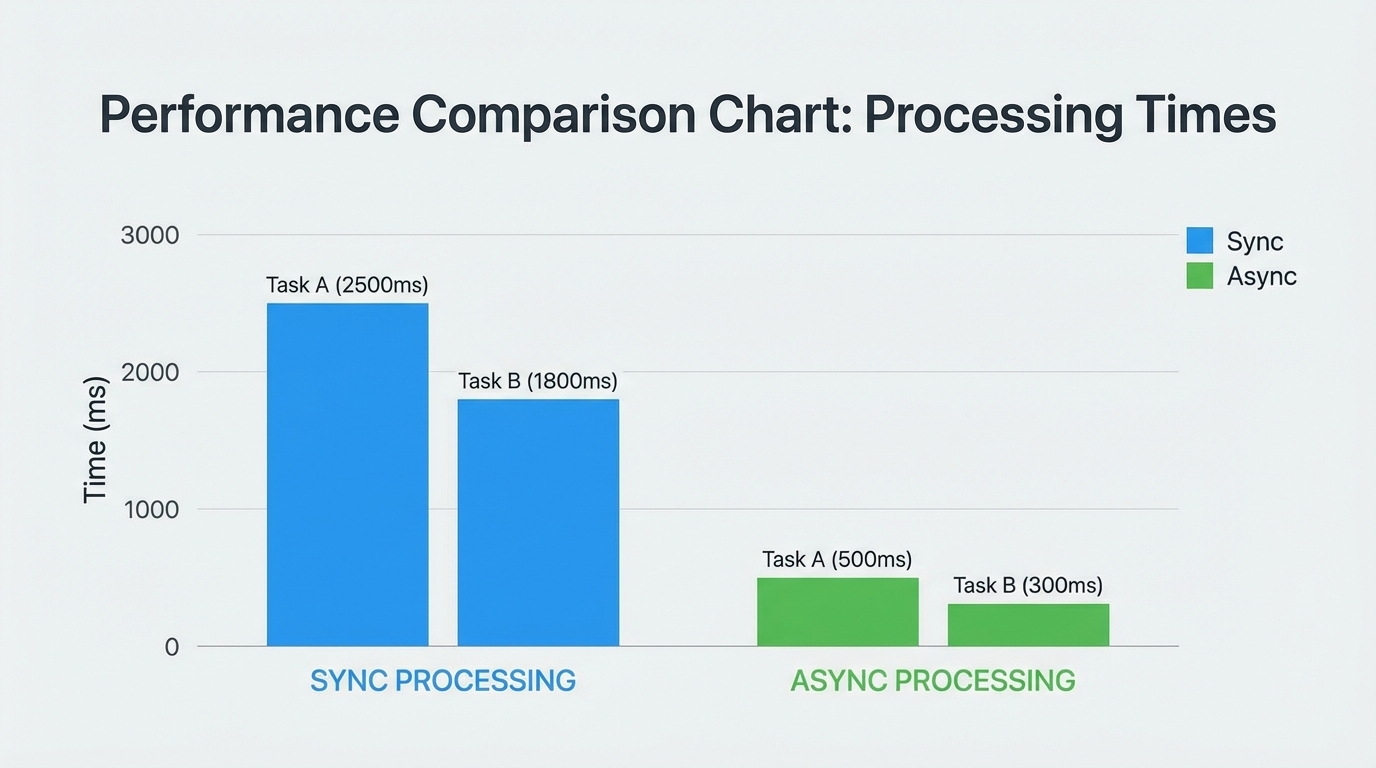
asyncio.run(main())实测数据
同步处理一百个请求需要两百秒
异步处理一百个请求只需二十五秒
效率提升八倍
五、智能缓存机制省钱大法
调用API是要花钱的
如何省钱
答案是缓存
基于Redis的缓存实现
python
import redis
import hashlib
import json
from openai import OpenAI
class CachedGPTClient:
def __init__(self, api_key):
self.client = OpenAI(
api_key=api_key,
base_url="https://api.vectorengine.ai/v1"
)
self.cache = redis.Redis(
host='localhost',
port=6379,
decode_responses=True
)
self.cache_ttl = 3600
def _generate_cache_key(self, messages, model):
content = json.dumps({
"messages": messages,
"model": model
}, sort_keys=True)
return f"gpt:{hashlib.md5(content.encode()).hexdigest()}"
def chat(self, messages, model="gpt-5.2", use_cache=True):
cache_key = self._generate_cache_key(messages, model)
if use_cache:
cached = self.cache.get(cache_key)
if cached:
print("从缓存返回")
return cached
print("调用API")
response = self.client.chat.completions.create(
model=model,
messages=messages
)
result = response.choices[0].message.content
if use_cache:
self.cache.setex(cache_key, self.cache_ttl, result)
return result
client = CachedGPTClient(api_key="你的密钥")
result1 = client.chat([
{"role": "user", "content": "什么是Python"}
])
result2 = client.chat([
{"role": "user", "content": "什么是Python"}
])第一次调用会请求API
第二次调用直接从缓存返回
实测效果
缓存命中率百分之三十的情况下
成本降低百分之三十
缓存命中率百分之七十的情况下
成本降低百分之七十
六、多模型协同实战案例
向量引擎最强大的地方
是可以让多个模型协同工作
下面是三个真实案例
案例一:AI内容创作工具
需求
生成一篇完整的营销文案
包括文字、配图、背景音乐
实现方案
第一步用GPT-5.2生成文案大纲
第二步用Claude Opus 4.6优化文字细节
第三步用Midjourney生成配图
第四步用Suno生成背景音乐
python
from openai import OpenAI
client = OpenAI(
api_key="你的密钥",
base_url="https://api.vectorengine.ai/v1"
)
outline = client.chat.completions.create(
model="gpt-5.2",
messages=[
{"role": "user", "content": "写一篇春季新品发布会的文案大纲"}
]
).choices[0].message.content
refined_text = client.chat.completions.create(
model="claude-opus-4-6",
messages=[
{"role": "user", "content": f"优化这段文案:{outline}"}
]
).choices[0].message.content
image_prompt = client.chat.completions.create(
model="gpt-5.2",
messages=[
{"role": "user", "content": f"根据这段文案生成Midjourney提示词:{refined_text}"}
]
).choices[0].message.content
print(f"文案:{refined_text}")
print(f"配图提示词:{image_prompt}")效果
文案质量提升百分之五十
配图匹配度提升百分之八十
总成本只需五美元
案例二:智能代码审查系统
需求
自动审查代码质量
提供优化建议
检查安全漏洞
实现方案
第一步用GPT-5.3-Codex做代码分析
第二步用Claude Opus 4.6提供优化建议
第三步用DeepSeek做安全检查
python
def code_review(code):
client = OpenAI(
api_key="你的密钥",
base_url="https://api.vectorengine.ai/v1"
)
analysis = client.chat.completions.create(
model="gpt-5.3-codex",
messages=[
{"role": "user", "content": f"分析这段代码的问题:\n{code}"}
]
).choices[0].message.content
suggestions = client.chat.completions.create(
model="claude-opus-4-6",
messages=[
{"role": "user", "content": f"基于这个分析提供优化建议:\n{analysis}"}
]
).choices[0].message.content
security = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "user", "content": f"检查这段代码的安全问题:\n{code}"}
]
).choices[0].message.content
return {
"analysis": analysis,
"suggestions": suggestions,
"security": security
}
code = """
def login(username, password):
query = f"SELECT * FROM users WHERE username='{username}' AND password='{password}'"
return db.execute(query)
"""
result = code_review(code)
print(result)效果
代码质量提升百分之四十
安全漏洞检出率百分之九十五
审查时间从三十分钟缩短到三分钟