目录
[使用 dig 工具分析 DNS 过程](#使用 dig 工具分析 DNS 过程)
什么是DNS?
TCP/IP提供了通过IP地址来连接到设备的功能,但对用户来讲,记住某台设备的IP地址是相当困难的,因此专门设计了一种字符串形式的主机命名机制,这些主机名与IP地址相对应。在IP地址与主机名之间需要有一种转换和查询机制,提供这种机制的系统就是域名系统DNS(Domain Name System)。
为什么要有DNS
互联网中,一台计算机与其他计算机通信时,通过IP地址唯一的标志自己。此时的IP地址就类似于我们日常生活中的电话号码。但是,这种纯数字的标识是比较难记忆的,而且数量也比较庞大。例如,每个IPv4地址是一个32位长的二进制数字,或者采用点分十进制展示成192.168.1.1这种格式,有接近43亿个的IPv4地址。DNS的作用就是将人类可读的名称转换为机器识别的IP地址,供计算机相互连接。DNS的工作原理和电话簿相似,都是管理名称和数字之间的映射关系。就像我们日常打电话,一般使用人名查找,很少直接输入电话号码一样。当我们上网打开某个网页、视频时,也很少直接使用IP地址,而是在浏览器里输入的URL地址,例如:https://www.huawei.com,这其实使用的就是计算机的名字,一般称为域名。
DNS的背景
在早期,因其IP地址不方便记忆,人们发明了一种叫主机名的东西,是一个字符串,并且使用hosts文件来描述主机名和IP地址的关系
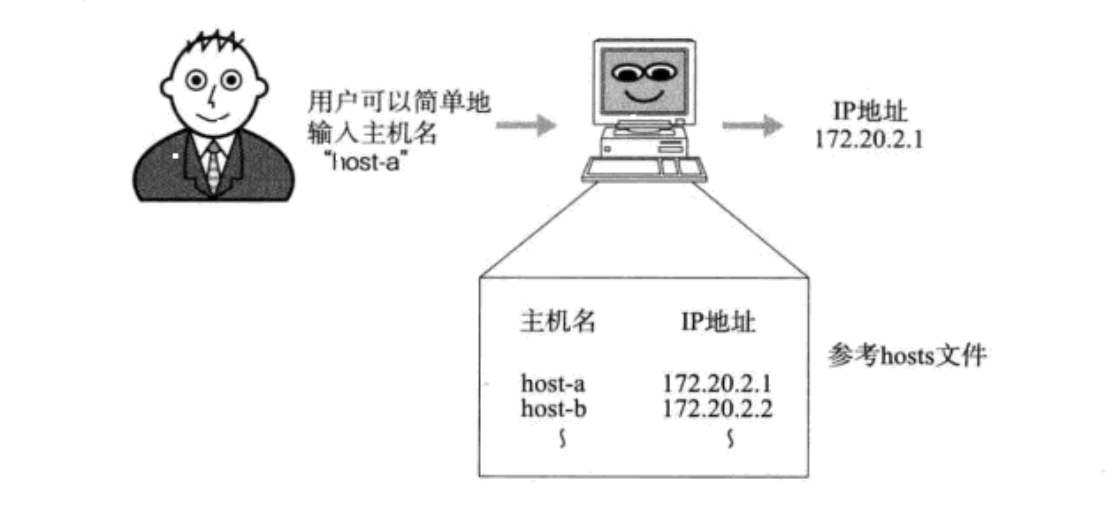
最初,通过互连网信息中心(SRI-NIC)来管理这个hosts文件的。
- 如果一个新计算机要接入网络,或者某个计算机IP变更,都需要到信息中心申请变更hosts文件。
- 其他计算机也需要定期下载更新新版本的hosts文件才能正确上网。
但其这样太麻烦了。于是便产生了DNS系统。
- 一个组织的系统管理机构,维护系统内的每个主机的IP和主机名的对应关系。
- 如果新计算机接入网络,将这个信息注册到数据库中。
- 用户输入域名的时候,会自动查询DNS服务器,由DNS服务器检索数据库,得到对应的IP地址。
至今,我们的计算机上仍然保留了hosts文件。在域名解析的过程中仍然会优先查找hosts文件的内容。
对于此,可以使用以下命令查看
cat /etc/hosts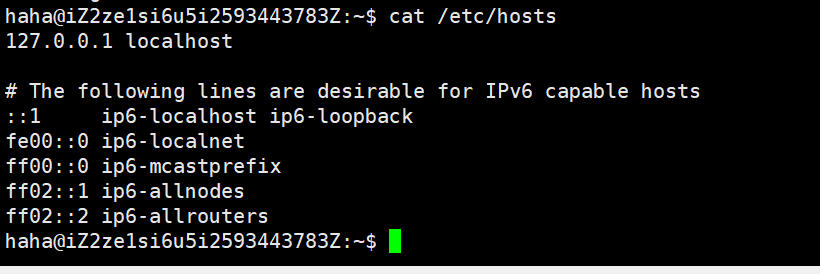
域名简介
最初设备的域名由字符序列组成、所有设备的域名组成一个未分级的域名结构。未分级的域名结构存在命名冲突、管理维护复杂的缺点。因此,TCP/IP把DNS的域名设计成了分级的树状结构。每个申请加入Internet的国家都要向NIC注册一个顶级域名,顶级域采用组织模式和地理模式的划分模式,如cn代表中国、us代表美国等。常见的顶级域名如下表所示。

NIC将顶级域的管理权分派给由其指定的管理机构,由这些管理机构再对被授权管理的域继续进行划分,从而形成了二级域。负责划分二级域的管理机构可以授权其下属的管理结构,由它们继续划分域。由此下去,便形成了层次型的Internet域名体系结构。
从语法上来讲,每一个域名都是有标号序列组成,而各标号之间用小数点隔开。以 www.baidu.com 为例,从右到左依次是:
- com:一级域名 (也可叫顶级域名) 。表示这是一个企业域名。同级的还有 "net"(网络提供商), "org"(非盈利组织) 等。
- baidu:二级域名,归属于某个公司自己的域名。
- www:只是一种习惯用法。之前人们在使用域名时,往往命名成类似于ftp.xxx.xxx/www.xxx.xxx这样的格式,来表示主机支持的协议或某个公司提供的是什么服务。
DNS域名解析过程(了解)
通过域名获取对应IP地址的过程称为域名解析。DNS域名解析分为以下两种方式:
- 静态域名解析
- 动态域名解析
在实际设计中,为提高查询速度,在解析域名时,首先采用静态域名解析的方法,如果静态解析不成功,再采用动态域名解析的方法。
具体可以看以下文章
一张图看懂DNS域名解析全过程 - 知乎![]() https://zhuanlan.zhihu.com/p/698510659
https://zhuanlan.zhihu.com/p/698510659
DNS域名详细解析过程(最全面,看这一篇就够)_dns解析-CSDN博客![]() https://blog.csdn.net/bangshao1989/article/details/121913780
https://blog.csdn.net/bangshao1989/article/details/121913780
使用 dig 工具分析 DNS 过程
安装 dig 工具,命令如下(Ubuntu版本):
sudo apt install dnsutils之后就可以使用 dig 指令查看域名解析过程了
dig www.baidu.com可以看到结果如下:
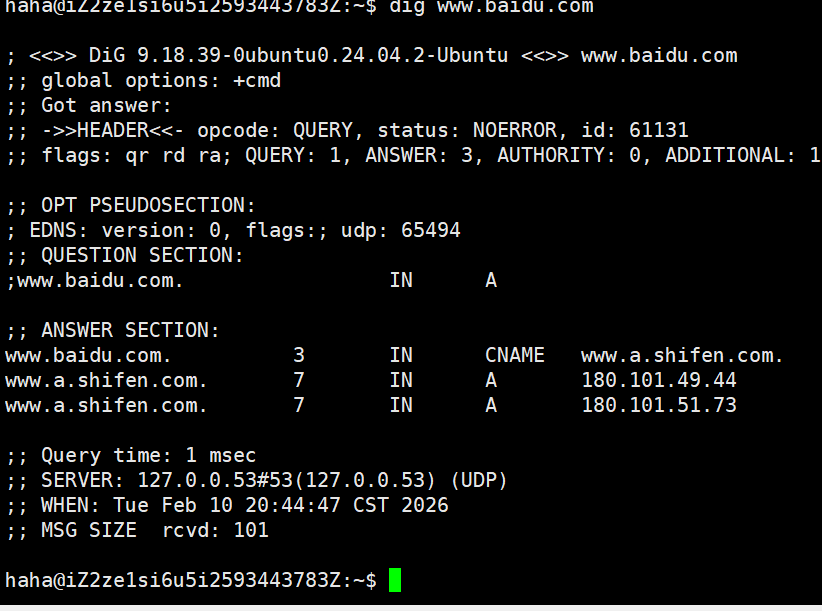
结果解释
-
开头显示的是
dig指令的版本号。 -
第二部分为服务器返回的详细信息,其中最重要的
status参数若为NOERROR,则表示查询成功。 -
QUESTION SECTION 展示了本次查询的域名。
-
ANSWER SECTION 为查询结果:系统先将
www.baidu.com解析为www.a.shifen.com,随后进一步将www.a.shifen.com解析为两个 IP 地址。 -
最下方为查询结果统计信息,包括本次查询所用时间及所使用的 DNS 服务器地址等。
更多 dig 的使用方法, 参见
linux dig 命令使用方法_慕课手记![]() https://www.imooc.com/article/26971?block_id=tuijian_wz
https://www.imooc.com/article/26971?block_id=tuijian_wz
浏览器中输入url后,发生的事情
根据我们前面所学的网络内容,这里我们要考虑的不仅仅是输入后就看看到浏览器相对应的界面,而是要分析其底层。
第一步:在浏览器中输入url
如www.baidu.com,输入后,可以看到对应百度首页。但这是底层并不是第一步。
第二步:浏览器使用DNS查找域名的IP地址
浏览器的第一步便是,根据DNS域名解析,得到对应的IP地址。
第三步:建立TCP连接(三次握手)
在发送 HTTP 请求之前,必须先建立可靠的传输通道
第四步:浏览器跨网络向web服务器发送一个HTTP请求
在这个过程中,不仅包括客户端中,用户在客户端触发操作,应用层生成对应数据请求;随后,数据经过 TCP/IP 协议栈自上而下逐层封装,形成可通过物理网络传输的数据帧。接着,该帧经由一系列路由器转发,通过"一跳接一跳"的方式跨越多个网络,最终抵达目标 Web 服务器。
第五步:服务器处理请求并返回响应
服务器接收到请求后,进行业务处理并生成响应数据。该响应沿相反方向(自下而上解封装后,再自上而下重新封装)经由网络返回客户端,确保客户端收到完整、可靠的数据。
-
直接返回 200 OK + HTML
-
或返回 301/302 重定向 (如
www.baidu.com→www.baidu.com或 HTTP → HTTPS)。
第六步 :浏览器处理响应
-
若是重定向(301/302) :浏览器读取
Location头部,自动跳转至新 URL,并重复第2-5步(但可能复用 TCP 连接)。 -
若是正常响应(200) :浏览器根据
Content-Type(如text/html)决定如何处理内容。
第七步:客户端开始显示HTML页面
在浏览器没有完整接受全部HTML文档时,它就已经开始显示这个页面了,其会首先加载相对小的数据。
-
在解析HTML/CSS过程中,遇到外部资源(如图片
<img>、样式表<link>、脚本<script>、字体@font-face),浏览器会立即并行发起新的HTTP请求去获取这些资源(受浏览器同域并发数限制)。 -
对于
<script>标签(没有async/defer属性),HTML解析会暂停,直到脚本下载并执行完毕,因为JS可能会修改DOM。这是性能优化的关键点之一。