京东商品评论数据采集权威指南:API 与爬虫实战
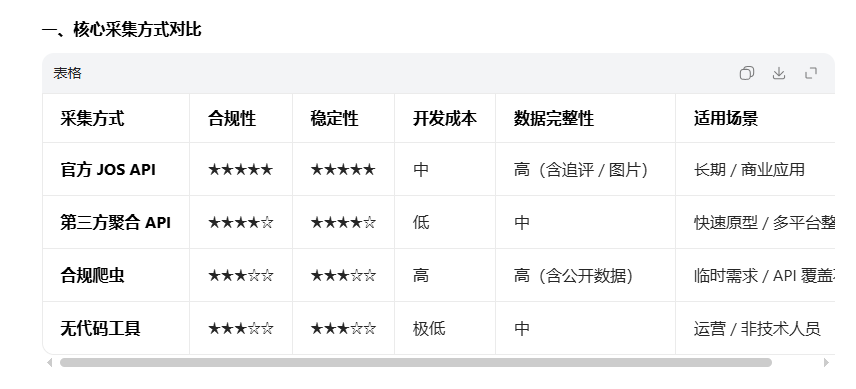
速览:京东评论采集首选官方 JOS API (合规稳定),其次第三方聚合 API (快速接入),必要时用合规爬虫 (解决 API 覆盖不足);核心接口为jingdong.ware.comment.get与productPageComments.action;必须重视反爬与合规,控制请求频率、使用代理 IP 并遵守平台规则。
二、官方 JOS API 采集方案(推荐)
1. 接口与权限申请
核心接口:
jingdong.ware.comment.get- 商品评价查询(基础评论数据)jd.union.open.comment.query- 联盟评论接口(推广场景)jingdong.comments.list- 评论详情接口(含追评 / 图片)
申请流程:
- 注册京东开放平台 (JOS) 账号并完成企业认证
- 创建应用,选择 "数据服务" 类目提交审核
- 获取
AppKey与AppSecret(用于签名认证) - 在控制台申请评论相关 API 权限(部分接口需额外审核)
- 阅读接口文档,了解参数与返回格式
2. API 调用示例(Python)
python
运行
import requests
import hashlib
import time
import json
# 配置信息
APP_KEY = "your_app_key"
APP_SECRET = "your_app_secret"
API_URL = "https://api.jd.com/routerjson"
SKU_ID = "100012345678" # 目标商品ID
def generate_sign(params):
"""生成京东API签名"""
sorted_params = sorted(params.items(), key=lambda x: x[0])
sign_str = APP_SECRET + ''.join([f"{k}{v}" for k, v in sorted_params]) + APP_SECRET
return hashlib.md5(sign_str.encode()).hexdigest().upper()
def get_jd_comments(sku_id, page=1, page_size=20):
"""调用京东商品评论API"""
params = {
"app_key": APP_KEY,
"method": "jingdong.ware.comment.get",
"timestamp": time.strftime("%Y-%m-%d %H:%M:%S"),
"v": "2.0",
"360buy_param_json": json.dumps({
"skuId": sku_id,
"page": page,
"pageSize": page_size,
"score": 0 # 0=全部,1=差评,2=中评,3=好评,4=晒单,5=追评
})
}
params["sign"] = generate_sign(params)
response = requests.post(API_URL, data=params)
return response.json()
# 使用示例
if __name__ == "__main__":
result = get_jd_comments(SKU_ID, page=1, page_size=20)
if "wareCommentResult" in result:
comments = result["wareCommentResult"]["comments"]
for comment in comments:
print(f"用户: {comment['nickname']}")
print(f"评分: {comment['score']}星")
print(f"时间: {comment['creationTime']}")
print(f"内容: {comment['content']}")
print(f"追评: {comment.get('afterContent', '无')}")
print("-" * 50)
else:
print(f"API调用失败: {result.get('error_response', {}).get('msg', '未知错误')}")3. 数据字段解析
表格
| 字段名 | 说明 | 示例值 |
|---|---|---|
content |
评论内容 | "音质清晰,续航持久" |
score |
评分(1-5 星) | 5 |
creationTime |
评论时间 | "2026-02-10 15:30:00" |
afterContent |
追评内容 | "使用一周后依然稳定" |
images |
评论图片 URL 列表 | "[https://img10.jd.com/](https://img10.jd.com/ "https://img10.jd.com/")..." |
productColor |
购买颜色 | "黑色" |
productSize |
购买规格 | "128GB" |
usefulVoteCount |
有用数 | 12 |
三、第三方聚合 API 方案(快速接入)
1. 主流服务商与接口
表格
| 服务商 | 接口名称 | 特点 | 价格 |
|---|---|---|---|
| 万邦开放平台 | jd.item_review |
多平台整合,含追评 | 按量计费 |
| 数据宝 | 京东评论接口 |
高并发支持,数据清洗 | 套餐制 |
| 聚美数仓 | jd_comment_get |
实时同步,简单易用 | 免费 + 付费 |
2. 调用示例(万邦 API)
python
运行
import requests
API_KEY = "your_api_key"
API_URL = "https://api.wanbangdata.com/jd/item_review"
SKU_ID = "100012345678"
params = {
"key": API_KEY,
"sku_id": SKU_ID,
"page": 1,
"page_size": 20,
"score": 0 # 0=全部,1=差评,2=中评,3=好评,5=追评
}
response = requests.get(API_URL, params=params)
result = response.json()
if result["code"] == 200:
for comment in result["data"]["comments"]:
print(f"用户: {comment['user_nick']}")
print(f"内容: {comment['content']}")
print(f"时间: {comment['create_time']}")
else:
print(f"API调用失败: {result['msg']}")四、合规爬虫采集方案(API 覆盖不足时)
1. 京东评论接口分析
核心接口(PC 端):
plaintext
https://club.jd.com/comment/productPageComments.action核心参数:
表格
| 参数 | 说明 | 示例 |
|---|---|---|
productId |
商品 ID | 100012345678 |
score |
评分筛选 | 0 = 全部,1 = 差评,2 = 中评,3 = 好评,4 = 晒单,5 = 追评 |
page |
页码 | 0(从 0 开始) |
pageSize |
每页数量 | 10(最大 10) |
sortType |
排序方式 | 5 = 时间排序,6 = 推荐排序 |
isShadowSku |
是否包含影子商品 | 0 = 否,1 = 是 |
反爬机制:
- IP 频率限制(单 IP 建议≤10 次 / 分钟)
- User-Agent 检测
- 动态参数(如
callback、_时间戳) - 部分接口需要登录态
2. 爬虫实现(Playwright 版,推荐)
python
运行
from playwright.sync_api import sync_playwright
import json
import time
import random
def crawl_jd_comments(product_id, page_count=5):
comments = []
user_agents = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 14_2) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/17.2 Safari/605.1.15"
]
with sync_playwright() as p:
browser = p.chromium.launch(headless=False) # 调试时设为False
context = browser.new_context(user_agent=random.choice(user_agents))
page = context.new_page()
for page_num in range(page_count):
# 构造请求URL
url = f"https://club.jd.com/comment/productPageComments.action?productId={product_id}&score=0&sortType=5&page={page_num}&pageSize=10&isShadowSku=0"
# 访问页面
page.goto(url)
page.wait_for_timeout(random.randint(2000, 5000)) # 随机延迟
# 提取JSON数据
content = page.text_content("pre")
try:
data = json.loads(content)
comments.extend(data.get("comments", []))
print(f"第{page_num+1}页采集成功,获取{len(data.get('comments', []))}条评论")
except:
print(f"第{page_num+1}页解析失败")
# 随机休息,模拟人工浏览
time.sleep(random.randint(3, 8))
browser.close()
return comments
# 使用示例
if __name__ == "__main__":
product_id = "100012345678"
all_comments = crawl_jd_comments(product_id, page_count=3)
print(f"共采集{len(all_comments)}条评论")
# 保存到JSON文件
with open("jd_comments.json", "w", encoding="utf-8") as f:
json.dump(all_comments, f, ensure_ascii=False, indent=2)3. 反爬应对策略
表格
| 反爬手段 | 应对方法 | 实施要点 |
|---|---|---|
| IP 封禁 | 代理 IP 池 | 使用高匿代理,每请求轮换 IP,控制单 IP≤5 次 / 分钟 |
| UA 检测 | 随机 UA 池 | 收集主流浏览器 UA,每次请求随机切换 |
| 请求频率 | 动态延迟 | 随机间隔 3-8 秒,避免固定间隔 |
| 动态参数 | 实时抓包 | 分析callback等参数生成规则,或使用浏览器自动化 |
| 登录限制 | 模拟登录 / 无头浏览器 | Playwright 自动处理登录态与 Cookie |
| 数据加密 | 解析 JSON 响应 | 直接提取 pre 标签中的 JSON 数据,无需解密 |
五、数据处理与合规指南
1. 数据清洗流程
- 去重:基于评论 ID 或内容去重
- 过滤:移除空评论、测试评论与广告内容
- 标准化:统一日期格式、评分格式
- 结构化:提取评论内容、评分、时间、用户信息、商品规格等字段
- 存储:MySQL(结构化数据)+ MongoDB(非结构化数据)+ Redis(缓存)
2. 合规与法律要求
核心合规原则:
- 遵守京东
robots.txt协议,不爬取禁止区域 - 仅采集公开评论数据,不获取用户隐私信息
- 不伪装成官方客户端,使用真实爬虫标识
- 数据仅用于合法用途,不用于商业竞争或非法活动
- 建立数据使用日志,记录采集时间、来源、用途
法律依据:
- 《网络安全法》《数据安全法》《个人信息保护法》
- 刑法第 285 条(非法获取计算机信息系统数据罪)
- 京东开放平台用户协议与开发者协议
六、最佳实践建议
-
货源平台应用方案
- 核心商品评论:通过官方 JOS API 获取(合规稳定)
- 竞品分析:结合第三方 API 与合规爬虫,扩大覆盖范围
- 评论分析:使用情感分析(如 SnowNLP)提取用户需求与痛点
- 数据更新:API 实时获取,爬虫定时补充(每日≤1 次)
-
性能优化策略
- 批量请求:API 调用时使用最大 pageSize,减少请求次数
- 增量采集:仅采集新增评论,避免重复采集
- 缓存机制:热门商品评论缓存 30 分钟,降低 API / 爬虫压力
- 分布式部署:大规模采集时使用多节点分布式爬虫
-
风险防控措施
- 监控 API 调用失败率,设置告警阈值
- 建立备用采集方案,API 失败时自动切换到爬虫
- 定期进行合规审计,及时调整采集策略
- 遇到法律问题,及时咨询专业律师
七、常见问题与解决方案
表格
| 问题 | 解决方案 |
|---|---|
| API 调用返回 "权限不足" | 检查权限申请状态,重新提交接口权限申请 |
| 爬虫频繁被封禁 | 增加代理 IP 池规模,延长请求间隔,使用浏览器自动化 |
| 评论数据不全 | 结合多个接口,官方 API 获取基础数据,爬虫补充追评与图片 |
| 数据更新不及时 | 调整 API 调用频率,爬虫定时增量采集 |