作者:来自 Elastic Margaret Gu 及 Eyo Eshetu
学习如何通过其 Elasticsearch 集成在 LangChain 中使用混合搜索,并提供完整的 Python 和 JavaScript 示例。
Elasticsearch 充满了新功能,帮助你为你的用例构建最佳搜索解决方案。学习如何在我们的动手网络研讨会中将它们付诸实践,构建现代 Search AI 体验。你也可以现在开始免费的云试用,或在你的本地机器上试用 Elastic。
Elasticsearch 混合搜索 已通过我们的 Python 和 JavaScript 集成在 LangChain 中可用。这里我们将讨论什么是混合搜索、它在什么时候有用,并通过一些简单示例来开始。
我们也计划很快在社区驱动的 Java 集成中支持 混合搜索。
什么是混合搜索?
混合搜索是一种信息检索方法,它将基于关键词的全文搜索(词法匹配)与 语义搜索(向量相似度)结合在一起。实际来说,这意味着一个查询之所以能匹配到文档,既可能是因为文档包含了正确的词语,也可能是因为文档表达了正确的含义(即使用词不同)。
用简单的话来说,你可以这样理解:
- 词法检索:这些文档是否包含我输入的词(或相关词)?
- 语义检索:这些文档的含义是否与我输入的内容相似?
这两种检索方式产生的分数位于不同的尺度上,因此 混合搜索 系统通常会使用一种融合策略,将它们合并成一个统一的排序结果,例如使用 倒数排序融合( RRF )。
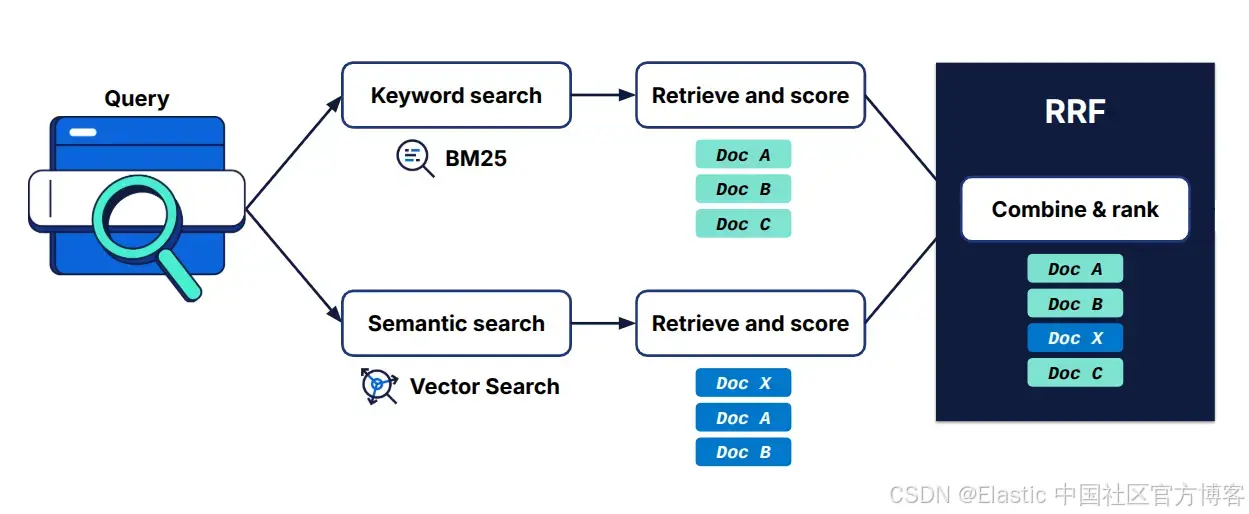
在上图中,我们展示了一个示例:BM25(关键词搜索)返回了 文档 A、文档 B 和 文档 C,而 语义搜索 返回了 文档 X、文档 A 和 文档 B。随后,RRF 算法 将这两个结果列表合并成最终排序:文档 A、文档 B、文档 X 和 文档 C。通过 混合搜索,由于 BM25 的存在,文档 C 也被包含在结果中。
为什么混合搜索很重要
如果你已经在生产环境中构建过搜索或 检索增强生成( RAG )功能,你可能一再看到相同的失败模式:
- 关键词搜索可能过于字面化。如果用户没有使用与你文档中完全相同的词语,相关内容就会被埋没或遗漏。
- 语义搜索可能过于模糊。它在理解含义方面很强,但也可能返回看起来相关却缺少关键约束的结果,比如产品名称、错误代码,或用户实际输入的特定短语。
混合搜索之所以存在,是因为生产环境中的真实用户查询通常同时需要这两者。
接下来,我们将深入介绍如何在 LangChain 的 Python 和 JavaScript 集成中开始使用混合搜索。如果你想了解更多关于混合搜索的内容,可以查看 什么是混合搜索? 和 混合搜索真正发挥优势的时候。
本地搭建 Elasticsearch 实例
在运行示例之前,你需要在本地运行 Elasticsearch。最简单的方法是使用 start-local 脚本:
curl -fsSL https://elastic.co/start-local | sh启动后,你将拥有:
- Elasticsearch 地址:http://localhost:9200
- Kibana 地址:http://localhost:5601
你的 API key 存储在 .env 文件中(位于 elastic-start-local 文件夹下),名称为 ES_LOCAL_API_KEY。
注意 :此脚本仅用于本地测试。请勿在生产环境中使用。有关生产环境安装,请参考 Elasticsearch 官方文档。
在 LangChain 中开始使用混合搜索(Python 和 JavaScript)
数据集是一个包含 1,000 部科幻电影信息的 CSV,取自 Kaggle 上的 IMDb 数据集。本演示使用经过清理的数据子集。你可以从我们的 GitHub gist 下载本文使用的数据集,以及本演示的完整代码。
步骤 1:安装所需工具
首先,你需要安装 LangChain 的 Elasticsearch 集成和 Ollama 用于 embeddings。(如果你愿意,也可以使用其他 embedding 模型。)
在 Python 中:
pip install langchain-elasticsearch langchain-ollama在 JavaScript 中:
npm install @langchain/community @langchain/ollama @elastic/elasticsearch csv-parse步骤 2:配置连接和数据集路径
在 Python 中:
在脚本开头,我们设置了:
-
Elasticsearch 所在位置(ES_LOCAL_URL)
-
如何进行身份验证(ES_LOCAL_API_KEY)
-
使用的演示索引名称(INDEX_NAME)
-
我们将导入的 CSV 文件(scifi_1000.csv)
ES_URL = os.getenv("ES_LOCAL_URL", "http://localhost:9200")
ES_API_KEY = os.getenv("ES_LOCAL_API_KEY")
INDEX_NAME = "scifi-movies-hybrid-demo"
CSV_PATH = Path(file).with_name("scifi_1000.csv")
在 JavaScript 中:
JavaScript 注意事项**:**
-
JavaScript 使用 process.env 而不是 os.getenv
-
路径解析需要使用 fileURLToPath 和 dirname 来处理 Elasticsearch 模块
-
类名为 ElasticVectorSearch(Python 中为 ElasticsearchStore)
import { Client } from "@elastic/elasticsearch";
import { OllamaEmbeddings } from "@langchain/ollama";
import {
ElasticVectorSearch,
HybridRetrievalStrategy,
} from "@langchain/community/vectorstores/elasticsearch";
import { parse } from "csv-parse/sync";
import { readFileSync } from "fs";
import { dirname, join } from "path";
import { fileURLToPath } from "url";const __dirname = dirname(fileURLToPath(import.meta.url));
const ES_URL = process.env.ES_LOCAL_URL || "http://localhost:9200";
const ES_API_KEY = process.env.ES_LOCAL_API_KEY;
const INDEX_NAME = "scifi-movies-hybrid-demo";
const CSV_PATH = join(__dirname, "scifi_1000.csv");
现在我们也可以创建客户端。
在 Python 中:
es = Elasticsearch(ES_URL, api_key=ES_LOCAL_API_KEY)在 JavaScript 中:
const client = new Client({
node: ES_URL,
auth: ES_API_KEY ? { apiKey: ES_LOCAL_API_KEY } : undefined,
});步骤 3:导入数据集,然后比较仅向量搜索与 混合搜索
步骤 3a:读取 CSV 并构建索引内容
我们构建三个列表:
- texts:将被嵌入并搜索的实际文本
- metadata:与文档一起存储的结构化字段
- ids:稳定 ID(以便 Elasticsearch 在需要时去重)
在 Python 中:
# --- Ingest dataset ---
texts: list[str] = []
metadatas: list[dict] = []
ids: list[str] = []
with CSV_PATH.open(newline="", encoding="utf-8") as f:
for row in csv.DictReader(f):
movie_id = (row.get("movie_id") or "").strip()
movie_name = (row.get("movie_name") or "").strip()
year = (row.get("year") or "").strip()
genre = (row.get("genre") or "").strip()
description = (row.get("description") or "").strip()
director = (row.get("director") or "").strip()
# This text is both:
# - embedded (vector search)
# - keyword-matched (BM25 in hybrid mode)
text = "\n".join(
[
f"{movie_name} ({year})" if year else movie_name,
f"Director: {director}" if director else "Director: (unknown)",
f"Genres: {genre}" if genre else "Genres: (unknown)",
f"Description: {description}" if description else "Description: (missing)",
]
)
texts.append(text)
metadatas.append(
{
"movie_id": movie_id or None,
"movie_name": movie_name or None,
"year": year or None,
"genre": genre or None,
"director": director or None,
}
)
ids.append(movie_id or movie_name)在 JavaScript 中:
async function main() {
// --- Ingest dataset ---
const texts = [];
const metadatas = [];
const ids = [];
const csvContent = readFileSync(CSV_PATH, "utf-8");
const records = parse(csvContent, {
columns: true,
skip_empty_lines: true,
});
for (const row of records) {
const movieId = (row.movie_id || "").trim();
const movieName = (row.movie_name || "").trim();
const year = (row.year || "").trim();
const genre = (row.genre || "").trim();
const description = (row.description || "").trim();
const director = (row.director || "").trim();
// This text is both:
// - embedded (vector search)
// - keyword-matched (BM25 in hybrid mode)
const text = [
year ? `${movieName} (${year})` : movieName,
director ? `Director: ${director}` : "Director: (unknown)",
genre ? `Genres: ${genre}` : "Genres: (unknown)",
description ? `Description: ${description}` : "Description: (missing)",
].join("\n");
texts.push(text);
metadatas.push({
movie_id: movieId || null,
movie_name: movieName || null,
year: year || null,
genre: genre || null,
director: director || null,
});
ids.push(movieId || movieName);
}这里的重要点:
- 我们不仅嵌入 description,还嵌入了一个组合文本块(title/year + director + genre + description)。这样结果更容易展示,有时还能提升检索效果。
- 同样的文本也是词法部分使用的文本(在 混合搜索 模式下),因为它被索引为可搜索文本。
步骤 3b:使用 LangChain 将文本添加到 Elasticsearch
这是索引步骤。我们在这里嵌入文本并写入 Elasticsearch。
对于异步应用,请使用 AsyncElasticsearchStore,API 相同。
你可以找到 ElasticsearchStore 的同步和异步版本参考文档,以及用于高级 RRF 微调的更多参数。
在 Python 中:
print(f"Ingesting {len(texts)} movies into '{INDEX_NAME}' from '{CSV_PATH.name}'...")
vector_store = ElasticsearchStore(
index_name=INDEX_NAME,
embedding=OllamaEmbeddings(model="llama3"),
es_url=ES_LOCAL_URL,
es_api_key=ES_LOCAL_API_KEY,
strategy=ElasticsearchStore.ApproxRetrievalStrategy(hybrid=False),
)
#This is the indexing step. We embed the texts and add them to Elasticsearch
vectore_store.add_texts(texts=texts, metadatas=metadatas, ids=ids)在 JavaScript 中:
console.log(
`Ingesting ${texts.length} movies into '${INDEX_NAME}' from 'scifi_1000.csv'...`
);
const embeddings = new OllamaEmbeddings({ model: "llama3" });
// Vector-only store (no hybrid)
const vectorStore = new ElasticVectorSearch(embeddings, {
client,
indexName: INDEX_NAME,
});
// This is the indexing step. We embed the texts and add them to Elasticsearch
await vectorStore.addDocuments(
texts.map((text, i) => ({
pageContent: text,
metadata: metadatas[i],
})),
{ ids }
);步骤 3c:为 混合搜索 创建另一个 store
我们创建另一个 ElasticsearchStore 对象,指向相同索引,但具有不同的检索行为:
hybrid=False表示仅向量搜索hybrid=True表示 混合搜索(BM25 + kNN,通过 RRF 融合)
在 Python 中:
# Since we are using the same INDEX_NAME we can avoid adding texts again
# This ElasticsearchStore will be used for hybrid search
hybrid_store = ElasticsearchStore(
index_name=INDEX_NAME,
embedding=OllamaEmbeddings(model="llama3"),
es_url=ES_LOCAL_URL,
es_api_key=ES_LOCAL_API_KEY,
strategy=ElasticsearchStore.ApproxRetrievalStrategy(hybrid=True),
)在 JavaScript 中:
// Since we are using the same INDEX_NAME we can avoid adding texts again
// This ElasticVectorSearch will be used for hybrid search
const hybridStore = new ElasticVectorSearch(embeddings, {
client,
indexName: INDEX_NAME,
strategy: new HybridRetrievalStrategy(),
});
// With custom RRF parameters
const hybridStoreCustom = new ElasticVectorSearch(embeddings, {
client,
indexName: INDEX_NAME,
strategy: new HybridRetrievalStrategy({
rankWindowSize: 100, // default: 100
rankConstant: 60, // default: 60
textField: "text", // default: "text"
}),
});步骤 3d:以两种方式运行相同查询,并打印结果
例如,让我们运行查询:"Find movies where the main character is stuck in a time loop and reliving the same day." 并比较 混合搜索 和 仅向量搜索 的结果。
在 Python 中:
query = "Find movies where the main character is stuck in a time loop and reliving the same day."
k = 5
print(f"\n=== Query: {query} ===")
vec_docs = vector_store.similarity_search(query, k=k)
hyb_docs = hybrid_store.similarity_search(query, k=k)
print("\nVector search (kNN) top results:")
for i, doc in enumerate(vec_docs, start=1):
print(f"{i}. {(doc.page_content or '').splitlines()[0]}")
print("\nHybrid search (BM25 + kNN + RRF) top results:")
for i, doc in enumerate(hyb_docs, start=1):
print(f"{i}. {(doc.page_content or '').splitlines()[0]}")在 JavaScript 中:
const query =
"Find movies where the main character is stuck in a time loop and reliving the same day.";
const k = 5;
console.log(`\n=== Query: ${query} ===`);
const vecDocs = await vectorStore.similaritySearch(query, k);
const hybDocs = await hybridStore.similaritySearch(query, k);
console.log("\nVector search (kNN) top results:");
vecDocs.forEach((doc, i) => {
console.log(`${i + 1}. ${(doc.pageContent || "").split("\n")[0]}`);
});
console.log("\nHybrid search (BM25 + kNN + RRF) top results:");
hybDocs.forEach((doc, i) => {
console.log(`${i + 1}. ${(doc.pageContent || "").split("\n")[0]}`);
});
}
main().catch(console.error);示例输出:
Ingesting 1000 movies into 'scifi-movies-hybrid-demo' from 'scifi_1000.csv'...
=== Query: Find movies where main character is stuck in a time loop and reliving the same day. ===
Vector search (kNN) top results:
1. The Witch: Part 1 - The Subversion (20 18)
2. Divinity (2023)
3. The Maze Runner (2014)
4. Spider-Man (2002)
5. Spider-Man: Into the Spider-Verse (2018)
Hybrid search (BM25 + kNN + RRF) top results:
1. Edge of Tomorrow (2014)
2. The Witch: Part 1 - The Subversion (2018)
3. Boss Level (2020)
4. Divinity (2023)
5. The Maze Runner (2014)为什么会得到这些结果?
这个查询("time loop / reliving the same day")是 混合搜索 特别擅长的一个案例,因为数据集中包含 BM25 可以匹配的字面短语,同时向量仍能捕捉含义。
-
仅向量搜索(kNN):将查询嵌入并尝试找到语义相似的剧情。在广泛的科幻数据集中,这可能会偏离到 "trapped / altered reality / memory loss / high-stakes sci‑fi",即使没有 time-loop 的概念。这就是为什么像《The Witch: Part 1 -- The Subversion》(失忆)和《The Maze Runner》(困住/逃脱)这样的结果可能出现。
-
混合搜索(BM25 + kNN + RRF):奖励同时匹配关键词和语义的文档。描述中明确提到 "time loop" 或 "relive the same day" 的电影会得到强烈的词法提升,因此像《Edge of Tomorrow》(一天一天不断重复)和《Boss Level》(困在不断重复的时间循环中)这样的标题会排在前面。
混合搜索 并不保证每个结果都是完美的。它平衡了词法信号和语义信号,因此你仍可能在前 k 条结果的尾部看到一些非 time-loop 的科幻电影。
主要结论是,当数据集包含关键词时,混合搜索帮助用精确文本证据锚定语义检索。
完整代码示例
你可以在 GitHub gist 上找到我们的完整演示代码(Python 和 JavaScript),以及使用的数据集。
结论
混合搜索通过将传统 BM25 关键词搜索与现代向量相似度结合为单一统一排序,提供了一种务实且强大的检索策略。你无需在词法精度和语义理解之间选择,而是两者兼得,同时不会给应用增加显著复杂性。
在真实世界的数据集中,这种方法通常产生更直观正确的结果。精确词匹配帮助将结果锚定到用户的明确意图,而 embeddings 确保对同义词、改写或不完整查询的鲁棒性。这种平衡对于嘈杂、多样化或用户生成的内容尤其有价值,因为仅依赖单一检索方法往往不够。
在本文中,我们展示了如何通过 LangChain 的 Elasticsearch 集成使用 混合搜索,并提供了 Python 和 JavaScript 的完整示例。我们还在贡献其他开源项目,例如 LangChain4j,以扩展对 Elasticsearch 混合搜索的支持。
我们相信 混合搜索 将成为生成式 AI(GenAI)和 agentic AI 应用的关键能力,并计划继续与生态系统中的库、框架和编程语言合作,使高质量检索更加可访问和稳健。
原文:https://www.elastic.co/search-labs/blog/langchain-elasticsearch-hybrid-search