引言:时序数据处理的双核心武器
Apache IoTDB 作为专为时间序列数据设计的开源数据库,凭借其高性能的写入与查询能力,已成为处理海量传感器数据的首选方案。IoTDB其分布式架构支持千万级时间序列的摄取和查询,性能指标领先。然而,要充分发挥IoTDB的潜力,必须掌握其核心的查询优化技术结果集排序(ORDER BY子句)和查询对齐模式(ALIGN BY DEVICE子句)。

Apache IoTDB 时序数据库【系列篇章】:
本文将深入讲解这两个子句的语法细节、性能优化策略与实际应用场景。从基础语法到高级优化,从单节点部署到分布式集群,我们将全方位展示如何利用ORDER BY和ALIGN BY DEVICE提升查询效率,降低系统负载,最终实现高质量数据分析。
一、结果集排序(ORDER BY子句)控制数据呈现顺序
1.1 时间对齐模式下的排序
IoTDB的查询结果集默认按照时间对齐,可以使用ORDER BY TIME的子句指定时间戳的排列顺序。示例代码如下:
sql
select * from root.ln.** where time <= 2017-11-01T00:01:00 order by time desc;结果:
text
+-----------------------------+--------------------------+------------------------+-----------------------------+------------------------+
| Time|root.ln.wf02.wt02.hardware|root.ln.wf02.wt02.status|root.ln.wf01.wt01.temperature|root.ln.wf01.wt01.status|
+-----------------------------+--------------------------+------------------------+-----------------------------+------------------------+
|2017-11-01T00:01:00.000+08:00| v2| true| 24.36| true|
|2017-11-01T00:00:00.000+08:00| v2| true| 25.96| true|
|1970-01-01T08:00:00.002+08:00| v2| false| null| null|
|1970-01-01T08:00:00.001+08:00| v1| true| null| null|
+-----------------------------+--------------------------+------------------------+-----------------------------+------------------------+2.2 设备对齐模式下的排序
在设备对齐模式下支持4种排序模式的子句,其中包括两种排序键,DEVICE和TIME,靠前的排序键为主排序键,每种排序键都支持ASC和DESC两种排列顺序。
ORDER BY DEVICE: 按照设备名的字典序进行排序,排序方式为字典序排序,在这种情况下,相同名的设备会以组的形式进行展示。
ORDER BY TIME: 按照时间戳进行排序,此时不同的设备对应的数据点会按照时间戳的优先级被打乱排序。
ORDER BY DEVICE,TIME: 按照设备名的字典序进行排序,设备名相同的数据点会通过时间戳进行排序。
ORDER BY TIME,DEVICE: 按照时间戳进行排序,时间戳相同的数据点会通过设备名的字典序进行排序。
为了保证结果的可观性,当不使用ORDER BY子句,仅使用ALIGN BY DEVICE时,会为设备视图提供默认的排序方式。其中默认的排序视图为ORDER BY DEVCE,TIME,默认的排序顺序为ASC,
即结果集默认先按照设备名升序排列,在相同设备名内再按照时间戳升序排序。
当主排序键为DEVICE时,结果集的格式与默认情况类似:先按照设备名对结果进行排列,在相同的设备名下内按照时间戳进行排序。
sql
select * from root.ln.** where time <= 2017-11-01T00:01:00 order by device desc,time asc align by device;结果:
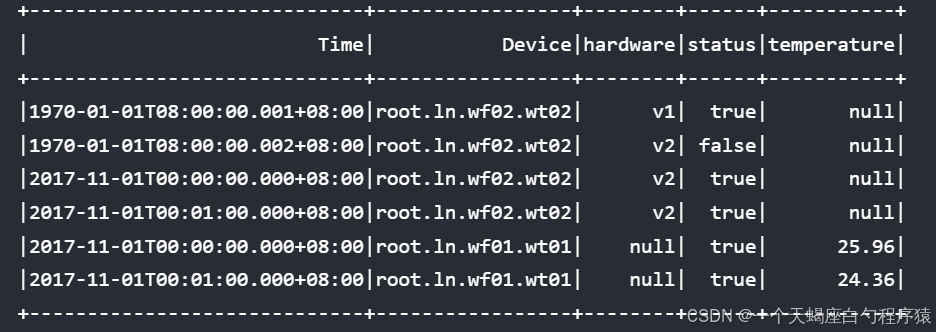
主排序键为Time时,结果集会先按照时间戳进行排序,在时间戳相等时按照设备名排序。
sql
select * from root.ln.** where time <= 2017-11-01T00:01:00 order by time asc,device desc align by device;结果:
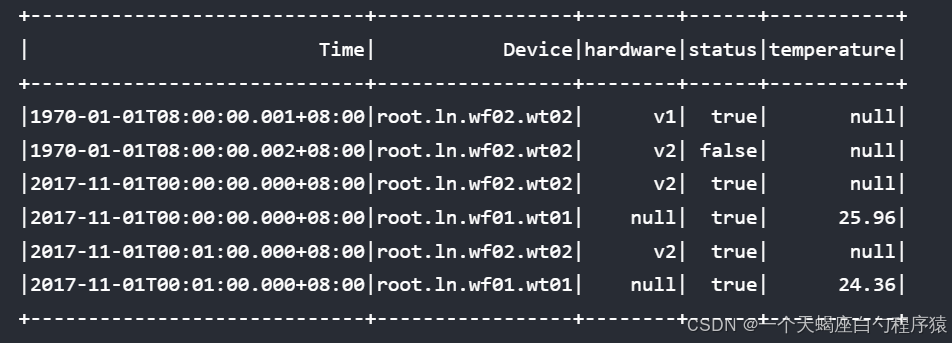
当没有显式指定时,主排序键默认为Device,排序顺序默认为ASC
sql
select * from root.ln.** where time <= 2017-11-01T00:01:00 align by device;结果如图所示,可以看出,ORDER BY DEVICE ASC,TIME ASC就是默认情况下的排序方式,由于ASC是默认排序顺序,此处可以省略。
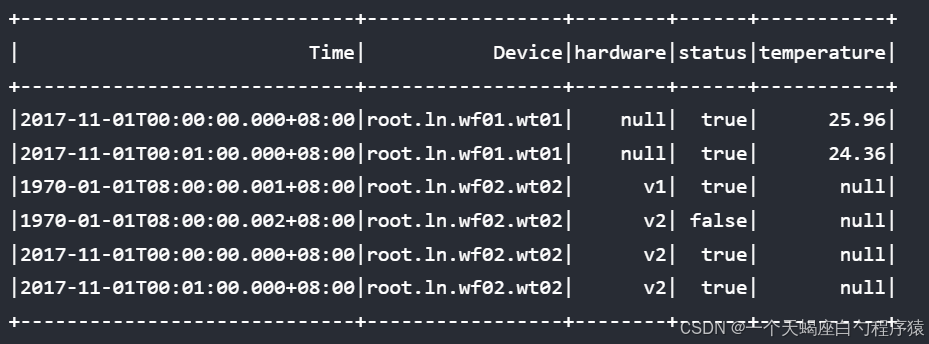
同样,可以在聚合查询中使用ALIGN BY DEVICE和ORDER BY子句,对聚合后的结果进行排序
sql
select count(*) from root.ln.** group by ((2017-11-01T00:00:00.000+08:00,2017-11-01T00:03:00.000+08:00],1m) order by device asc,time asc align by device结果:
text
+-----------------------------+-----------------+---------------+-------------+------------------+
| Time| Device|count(hardware)|count(status)|count(temperature)|
+-----------------------------+-----------------+---------------+-------------+------------------+
|2017-11-01T00:01:00.000+08:00|root.ln.wf01.wt01| null| 1| 1|
|2017-11-01T00:02:00.000+08:00|root.ln.wf01.wt01| null| 0| 0|
|2017-11-01T00:03:00.000+08:00|root.ln.wf01.wt01| null| 0| 0|
|2017-11-01T00:01:00.000+08:00|root.ln.wf02.wt02| 1| 1| null|
|2017-11-01T00:02:00.000+08:00|root.ln.wf02.wt02| 0| 0| null|
|2017-11-01T00:03:00.000+08:00|root.ln.wf02.wt02| 0| 0| null|
+-----------------------------+-----------------+---------------+-------------+------------------+1.3 任意表达式排序
除了IoTDB中规定的Time,Device关键字外,还可以通过ORDER BY子句对指定时间序列中任意列的表达式进行排序。
排序在通过ASC,DESC指定排序顺序的同时,可以通过NULLS语法来指定NULL值在排序中的优先级,NULLS FIRST默认NULL值在结果集的最上方,NULLS LAST则保证NULL值在结果集的最后。如果没有在子句中指定,则默认顺序为ASC,NULLS LAST。
对于如下的数据,将给出几个任意表达式的查询示参考:
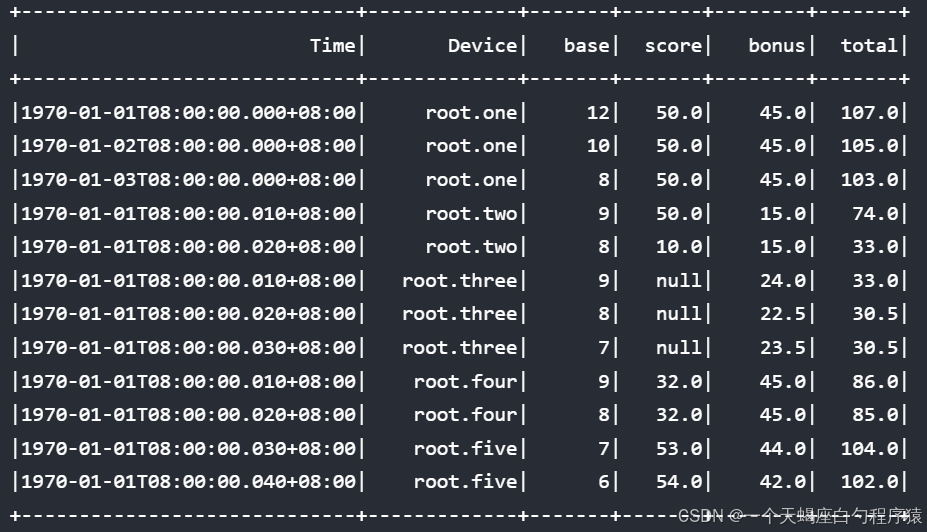
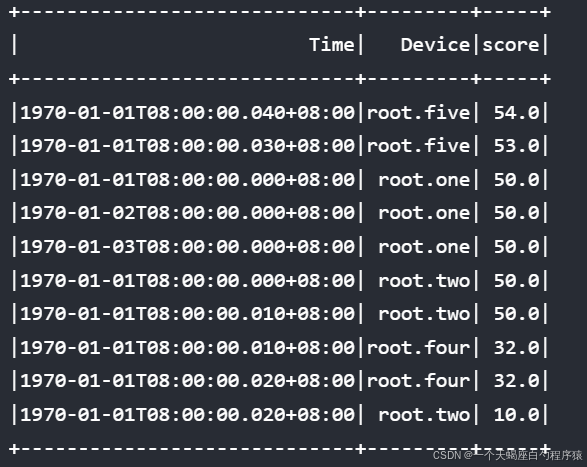
当需要根据基础分数score对结果进行排序时,可以直接使用
sql
select score from root.** order by score desc align by device结果:
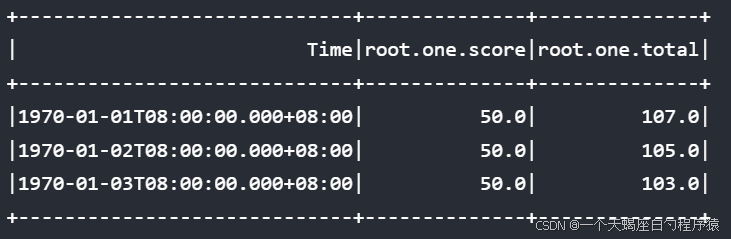
当想要根据总分对结果进行排序,可以在order by子句中使用表达式进行计算
sql
select score,total from root.one order by base+score+bonus desc该sql等价于
sql
select score,total from root.one order by total desc结果:
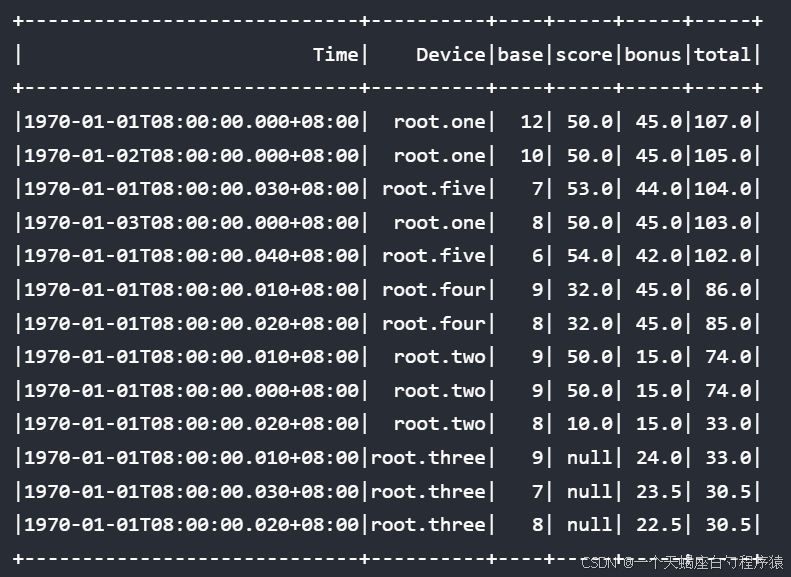
而如果要对总分进行排序,且分数相同时依次根据score, base, bonus和提交时间进行排序时,可以通过多个表达式来指定多层排序
sql
select base, score, bonus, total from root.** order by total desc NULLS Last,
score desc NULLS Last,
bonus desc NULLS Last,
time desc align by device结果:
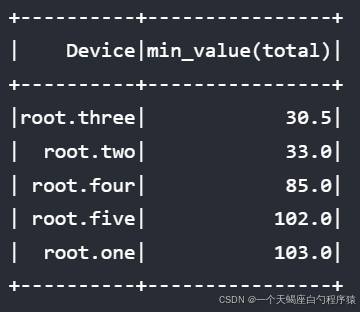
在order by中同样可以使用聚合查询表达式
sql
select min_value(total) from root.** order by min_value(total) asc align by device结果:
当在查询中指定多列,未被排序的列会随着行和排序列一起改变顺序,当排序列相同时行的顺序和具体实现有关(没有固定顺序)
sql
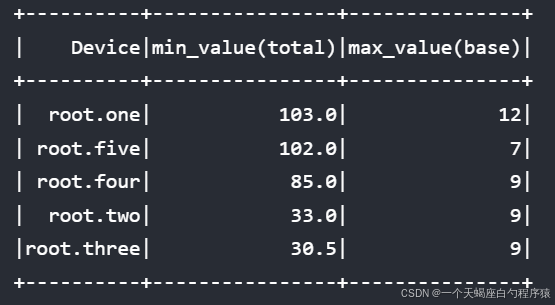
select min_value(total),max_value(base) from root.** order by max_value(total) desc align by device结果:
Order by device, time可以和order by expression共同使用
sql
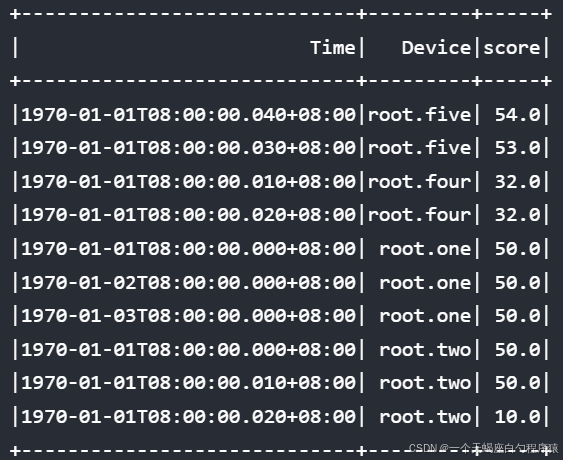
select score from root.** order by device asc, score desc, time asc align by device结果:
1.4 异常处理
在IoTDB的ORDER BY使用中,有常见的三大错误要注意
- 字段名混淆
错误示例:
sql
SELECT * FROM root.sg.d1 ORDER BY timestamp;正确写法:
sql
SELECT * FROM root.sg.d1 ORDER BY time;在IoTDB中,时间戳字段统一命名为time,使用timestamp将导致"column not found"错误。
- NULL值处理缺失
传感器数据可能因通信故障产生大量NULL值。未指定NULL处理策略时,默认行为因数据库而异。IoTDB默认采用NULLS LAST策略,但显式声明可提升代码可读性:
sql
ORDER BY value ASC NULLS FIRST;- 索引失效场景
当排序字段包含函数计算结果时,索引将无法使用:
sql
SELECT time, sin(value) as sin_value
FROM root.sg.d1
ORDER BY sin_value;优化:通过物化视图或预计算优化。
二、查询对齐模式(ALIGN BY DEVICE子句)
在 IoTDB 中,查询结果集默认按照时间对齐,包含一列时间列和若干个值列,每一行数据各列的时间戳相同。
除按照时间对齐外,还支持以下对齐模式:
按设备对齐 ALIGN BY DEVICE
2.1 按设备对齐
在按设备对齐模式下,设备名会单独作为一列出现,查询结果集包含一列时间列、一列设备列和若干个值列。如果 SELECT 子句中选择了 N 列,则结果集包含 N + 2 列(时间列和设备名字列)。
在默认情况下,结果集按照 Device 进行排列,在每个 Device 内按照 Time 列升序排序。
当查询多个设备时,要求设备之间同名的列数据类型相同。
为便于理解,可以按照关系模型进行对应。设备可以视为关系模型中的表,选择的列可以视为表中的列,Time + Device 看做其主键。
例:
sql
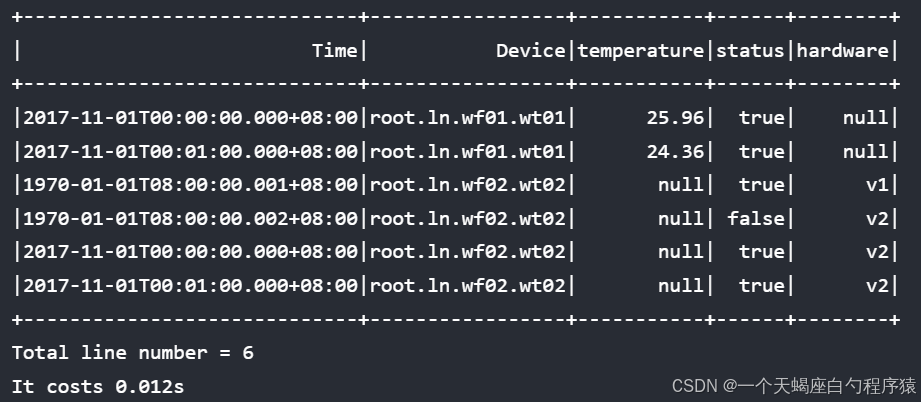
select * from root.ln.** where time <= 2017-11-01T00:01:00 align by device;结果如下:
2.2 设备对齐模式下的排序
在设备对齐模式下,默认按照设备名的字典序升序排列,每个设备内部按照时间戳大小升序排列,可以通过 ORDER BY 子句调整设备列和时间列的排序优先级。
三、双模式融合从查询到决策
3.1 模式融合场景
在复杂业务场景中,ORDER BY与ALIGN BY DEVICE常需协同使用。以下三大场景展示了双模式融合的强大能力:
- 设备异常排名
在设备健康管理场景中,常需对设备异常进行排名:
sql
SELECT device, count(*) as anomaly_count
FROM root.sg.**
WHERE value > threshold
ALIGN BY DEVICE
GROUP BY device
ORDER BY anomaly_count DESC
LIMIT 10;该查询首先通过ALIGN BY DEVICE获取设备级数据,然后按设备分组统计异常次数,最后按次数降序排列,取前10名。
- 多指标趋势分析
在多指标联合分析场景中,需同时考虑时间顺序和设备差异:
sql
SELECT device, time, temperature, pressure
FROM root.ln.wf01.*
WHERE time >= '2026-01-01'
ALIGN BY DEVICE
ORDER BY device ASC, time ASC;该查询首先按设备对齐数据,然后按设备和时间双重排序,形成清晰的多设备多指标趋势图。
- 设备性能基准测试
在设备性能评估场景中,需比较不同设备在相同条件下的表现:
sql
SELECT device, avg(temperature) as avg_temp, max(pressure) as max_pressure
FROM root.sg.**
WHERE time >= '2026-01-01' AND time < '2026-01-02'
ALIGN BY DEVICE
GROUP BY device
ORDER BY avg_temp DESC, max_pressure DESC;该查询通过设备对齐和双重排序,可清晰展示各设备的性能差异。
3.2 分布式集群中的双模式优化
在分布式集群环境下,ORDER BY与ALIGN BY DEVICE的协同使用需考虑数据分布与负载均衡。可提升集群性能的方案如下
- 数据分区与查询
在IoTDB集群中,数据按时间槽和序列哈希分区。合理设置分区策略可确保查询负载均衡:
sql
SET 'data_region_count'='8';
SET 'sequence_hash_range'='65536';通过增加数据区域数量,可将查询负载分散到更多节点,避免单点瓶颈。
- 并行查询优化
在IoTDB支持并行查询算子。启用并行查询可显著提升复杂查询性能:
sql
SET 'enable_parallel_query'='true';
SET 'parallel_query_thread_count'='8';通过并行执行,可将大型查询分解为多个子任务,充分利用多核CPU资源。
- 负载均衡
在集群运行过程中,需持续监控节点负载,避免热点问题:
sql
SHOW REGIONS;
BALANCE REGIONS;通过定期检查数据分布,并执行均衡操作,可确保各节点负载均衡,提升系统稳定性。
四、实践总结
本文的学习后,总结出以下十大方案,希望可以帮助到友友们。
- 始终使用
time作为时间戳字段,避免timestamp混淆 - 在排序字段上建立索引,提升查询效率
- 合理使用分页查询,避免全表扫描
- 在设备对齐模式下,充分利用设备拓扑信息
- 在分布式集群中,合理设置分区策略
- 启用并行查询,提升复杂查询性能
- 定期监控集群负载,执行均衡操作
- 在边缘计算场景中,采用轻量级部署
- 在多模态数据处理中,合理设计数据模型
- 持续关注IoTDB版本更新,采用新特性优化系统
通过这些总结,可充分发挥IoTDB的强大能力,实现高效、稳定的时序数据处理,支撑各类工业互联网应用场景。
结语
Apache IoTDB通过ORDER BY与ALIGN BY DEVICE两大核心子句,构建了时序数据处理的完整解决方案。从基础语法到高级优化,从单节点部署到分布式集群,IoTDB提供了全面的工具集与最佳实践。通过本文的学习,友友们可全面掌握这两个子句的使用方法与优化策略,实现高质量数据分析。