目录
[公式中 ϕ(ℓ) 函数的具体实现方式和设计考虑是什么,它如何影响模型对视觉信息的利用?](#公式中 ϕ(ℓ) 函数的具体实现方式和设计考虑是什么,它如何影响模型对视觉信息的利用?)
a) 语言模型内部的自注意力机制 (Self-Attention in the Frozen Language Model) 语言模型内部的自注意力机制 (Self-Attention in the Frozen Language Model))
b) 提示工程 (Prompt Engineering) 提示工程 (Prompt Engineering))
[1.Vision Encoder:从像素到特征](#1.Vision Encoder:从像素到特征)
[Perceiver Resampler将视觉特征重新采样为固定数量的64个视觉token,这个数量是如何确定的?改变这个数量会对模型性能产生什么影响?](#Perceiver Resampler将视觉特征重新采样为固定数量的64个视觉token,这个数量是如何确定的?改变这个数量会对模型性能产生什么影响?)
[2.Preceiver Resampler:从不同大小的大型特征图到少量视觉token](#2.Preceiver Resampler:从不同大小的大型特征图到少量视觉token)
Flamingo最核心的创新点之一:如何在不破坏强大预训练语言模型(LM)原有知识的基础上,有效地融入视觉信息?
2.设计动机一:防止灾难性遗忘 (Catastrophic Forgetting)
3.设计动机二:高效且有策略地引入视觉条件 (Efficient and Strategic Visual Conditioning)
[4.设计动机三:Perceiver Resampler 的作用](#4.设计动机三:Perceiver Resampler 的作用)
[为什么选用 tanh(α) 作为门控机制?](#为什么选用 tanh(α) 作为门控机制?)
考虑:是否可以作为tanh(α)函数的替代函数,起到门控注意力的作用?
[为什么 tanh(x) 仍然是首选(或最常见)](#为什么 tanh(x) 仍然是首选(或最常见))
[七、Training on a mixture of vision and language datasets](#七、Training on a mixture of vision and language datasets)
一、前言
今天我们要精读的论文来自2022年DeepMind提出的少样本多模态大模型,该模型Flamingo支持跨模态推理,虽然这篇论文年代有些久远,但对于多模态大模型领域的初学者,或者想要了解多模态大模型的发展历程的同学来说,也是非常值得一读的,里面有一些思想也是可以借鉴的!
咱们闲言少叙,论文原文在Flamingo: a Visual Language Model for Few-Shot Learning,大家可以利用我这篇博客与原文结合起来看,效果更加!
二、创新点总结&模型优越性
1.关键的架构创新
-
桥接强大的预训练的纯视觉和纯语言模型
-
处理任意交错的视觉和文本数据序列
-
无缝地摄取图像或视频作为输入
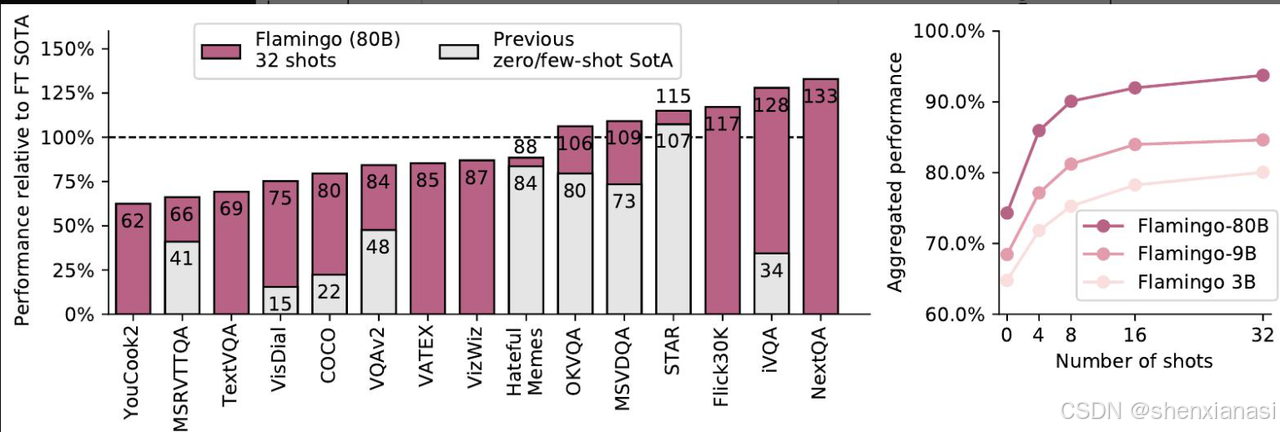
2.Flamingo-80B的性能优越
Flamingo,一种视觉语言模型(VLM),它通过简单地提示几个输入/输出示例,在各种开放式视觉和语言任务上实现了最先进的少样本学习效果

Flamingo-80B获得的输入和输出的精选示例。Flamingo可以通过少量样本提示快速适应各种图像/视频理解任务(顶部)。开箱即用,Flamingo还能够进行多图像视觉对话(底部)
三、Introduction
Flamingo模型利用了两个互补的预训练和冻结模型:一个可以"感知"视觉场景的视觉模型和一个执行基本推理形式的大型语言模型。在这两个模型之间添加了新的架构组件,以一种能够保留它们在计算密集型预训练期间积累的知识的方式将它们连接起来。由于基于Perceiver的架构,Flamingo模型还能够摄取高分辨率图像或视频,该架构对于每个图像/视频可以产生少量固定数量的视觉标记,给定大量且可变的视觉输入特征。
四、方法与架构设计
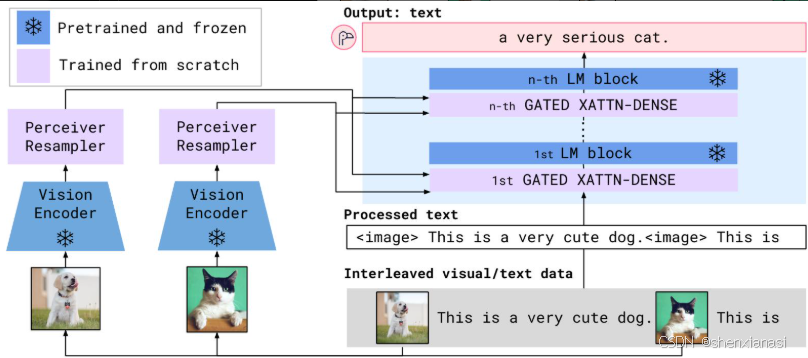
Flamingo架构概述
Flamingo接受文本与图像/视频交错的输入,并输出自由形式的文本
首先,感知器重采样器接收来自视觉编码器的时空特征(从图像或视频获得),并输出固定数量的视觉标记。其次,这些视觉标记用于使用新初始化的交叉注意力层来调节冻结的LM,这些交叉注意力层交错在预训练的LM层之间。这些新层为LM提供了一种富有表现力的方式来整合视觉信息,以用于下一个token的预测任务。
Flamingo将文本𝑦在交错的图像和视频𝑥条件下的可能性建模如下:
【公式含义】
描述了模型如何以自回归的方式预测下一个文本 token,同时考虑之前的文本 token 和相应的视觉信息
【符号解释】
-
p (y ∣x): 表示在给定视觉序列 x 的条件下,文本序列 y 的联合概率(似然性)。
-
y: 表示一个由 L 个语言 token 组成的文本序列,即 y=(
)。
-
x: 表示一个交错的图像和视频序列。
-
L: 表示文本序列 y 中的总 token 数量。
-
ℓ: 表示文本序列中的当前位置索引,从 ℓ 到 L。
-
-
p(yℓ∣y<ℓ,x≤ℓ): 表示在给定所有先前的文本 token y<ℓ (即
-
y<ℓ: 表示在文本序列中位于当前 token
-
x≤ℓ: 表示在交错序列中,在当前 token
【公式拆解】
该公式是自回归 语言模型 的一个标准形式,但其关键创新在于将视觉信息作为条件引入。
-
自回归 分解 : 任何联合概率分布都可以使用链式法则分解为条件概率的乘积。对于文本序列y=(
-
视觉信息条件化 : Flamingo模型将上述自回归分解扩展到多模态领域,即在预测每个文本 token
-
视觉上下文管理 : 论文中提到 "The model attends to the visual tokens of the image that appeared just before it in the interleaved sequence, rather than to all previous images"。这意味着在预测 yℓ 时,模型并非关注所有先前的图像/视频,而是仅关注在当前文本 token yℓ之前 最近出现****的图像/视频 。这通过论文中定义的函数 ϕ(ℓ) 实现,即 x≤ℓ={xi∣i≤ϕ(ℓ)},其中 ϕ(ℓ)给出的是在文本位置 ℓ 之前出现的最后一个图像/视频的索引。这种机制有助于模型处理任意交错的视觉和文本数据序列,并能在推理时无缝地泛化到任意数量的视觉输入。
通过这种方式,Flamingo模型能够将图像和视频作为输入,并生成自由形式的文本输出,从而执行各种多模态任务,如图像/视频描述、视觉问答或视觉对话。该公式是Flamingo模型进行上下文少样本学习 (in-context few-shot learning) 的数学基础,使其能够像GPT-3在纯文本领域那样,通过提供少量输入/输出示例作为提示来适应新任务。
公式中 ϕ(ℓ) 函数的具体实现方式和设计考虑是什么,它如何影响模型对视觉信息的利用?
1.具体实现方式:
ϕ (ℓ) 的核心思想是注意力掩码 (attention masking),用于控制语言模型中的交叉注意力(cross-attention)机制。
-
图像-因果建模 (Image-causal modelling) :模型在处理交错的视觉和文本数据时,采用了一种"图像-因果"的建模方式。这意味着对于任何一个文本 token yℓ,模型在进行交叉注意力计算时,只被允许关注在当前文本 token 之前最近出现的那一个图像或视频的视觉 token。
-
掩码操作 (Masking) :为了实现这种限制,通过掩码 (masking) 操作来控制注意力矩阵。当模型计算一个文本 token yℓ 对视觉 token 的注意力时,所有不符合"最近前一个图像/视频"条件的视觉 token 都会被掩盖(即它们的注意力权重被设置为一个非常小的值,使其在计算中不起作用)。
-
函数定义 (Formalization) :论文形式化地定义了一个函数 ϕ:1,L→0,N,它将每个文本位置 ℓ 映射到在当前位置之前出现的最后一个图像/视频的索引(如果在这之前没有图像/视频,则为0)。因此,x≤ℓ 实际上指的是由 ϕ(ℓ) 所指向的那个单一图像/视频的视觉特征。
2.设计考虑
这种设计并非是随意选择的,而是基于以下几个关键考虑:
-
泛化性 (Generalizability) :这种"单图像交叉注意力"方案(即 yℓ 只关注最近的前一个图像)使得模型能够无缝地泛化到任意数量的视觉输入,无论在训练时使用了多少个图像。在训练时,模型通常只用最多5个图像的序列进行训练,但在评估时,它却能受益于多达32个图像/视频对的序列。这种灵活性对于处理来自网页等实际场景中图像数量不定的多模态数据至关重要。
-
计算效率 ( Computational Efficiency ) :如果模型被允许对所有之前的图像进行交叉注意力,计算复杂度将显著增加,尤其是在处理长序列或大量图像时。限制注意力范围可以有效降低视觉-文本交叉注意力的计算负担。
-
避免混淆 (Avoiding Ambiguity) :论文在 Table 10 的 row (ii) 的消融实验中指出,允许模型关注所有 之前的图像会导致性能显著下降(总体分数降低7.2%)。作者推测,一个潜在的解释是,当关注所有之前的图像时,交叉注意力输入中没有明确的方法来区分不同的图像,这可能导致模型混淆。
-
通过自注意力传递信息 (Information Propagation via Self-Attention) :尽管模型不能明确地 交叉关注所有先前的图像,但语言模型本身的自注意力机制能够将所有先前图像的特征通过先前的文本 token 进行传播。这意味着,虽然当前文本 token 只直接看到最近的图像,但由于语言模型捕获了文本的长期依赖关系,之前图像的信息仍然可以通过文本表示间接影响当前文本 token 的生成。
ϕ(ℓ) 如何影响模型对视觉信息的利用
-
局部视觉上下文的强调 (Emphasis on Local Visual Context) :ϕ(ℓ) 强制模型在生成文本时,优先考虑最近的、直接相关的视觉信息。这对于描述图像内容、回答直接与图像相关的问题等任务非常有效,因为它促使模型聚焦于当前最相关的视觉输入。
-
避免"视觉过载" (Avoiding "Visual Overload"):在多图像/视频序列中,如果模型需要同时处理所有历史视觉信息,可能会面临信息过载和注意力分散的问题。ϕ(ℓ) 通过限制视觉输入的范围,让模型能够更有效地处理复杂的交错数据流。
-
隐式长程视觉依赖 (Implicit Long-Range Visual Dependencies) :尽管直接交叉注意力是局部的,但由于语言模型自身的强大建模能力 ,尤其是其自注意力机制,先前图像的信息仍然可以通过它们所关联的文本 token 传递到后续的文本生成中。例如,如果一个文本描述提到了一个图像,然后后续的文本又引用了该描述中的某个概念,那么即使后续的文本生成时没有直接看到该图像,其信息也可以通过文本上下文传递。
-
提升泛化能力 (Improved Generalization):这种设计使得模型在训练时对图像数量不敏感,从而在推理时能够更好地适应不同长度的视觉序列。这对于实际应用中视觉输入多样性的场景非常关键。
函数的设计是否会限制模型捕捉非相邻图像之间的关联性?
ϕ(ℓ)函数的设计在某种程度上会限制模型直接捕捉非相邻图像之间的关联性,但这种限制是经过深思熟虑的,并且通过其他机制进行了一定程度的弥补。
1. ϕ (ℓ) 函数设计的直接限制
ϕ (ℓ) 函数的核心功能是让模型在生成第 ℓ 个文本 token yℓ 时,只交叉注意力(cross-attend)到其前最近的一个图像或视频 。这意味着:
-
局部聚焦: 模型在处理文本时,其直接的视觉关注点是高度局部的,只集中在文本前面紧邻的那个图像。
-
缺乏直接多图像联合推理: 如果一个文本 token 的生成需要同时理解两个非相邻图像的内容,例如"左边的猫和右边的狗都在看相机",那么根据 ϕ(ℓ) 的定义,当生成"看相机"这个文本时,模型只能直接看到"右边的狗"的图像(假设它是最近的),而无法直接看到"左边的猫"的图像。它不能像人类一样,同时扫描并整合这两个图像的信息来生成描述。
论文在 Section 2.3 和 Appendix A.1.3 中也明确提到了这一点,并进行了解释:
"Though the model only directly attends to a single image at a time..." (Page 6) "In practice, this selective cross-attention is achieved through masking -- illustrated here with the dark blue entries (unmasked/visible) and light blue entries (masked)." (Page 24) "We can see that the single image case leads to significantly better results (7.2% better in the overall score). One potential explanation is that when attending to all previous images, there is no explicit way of disambiguating between different images in the cross-attention inputs." (Page 35)
这些表述都强调了模型在交叉注意力层面的这种局部性。
2.弥补这种限制的机制
尽管存在这种直接限制,Flamingo 模型并非完全无法利用非相邻图像的信息。论文提到了两种主要的弥补机制:
a) 语言模型内部的自注意力机制 (Self-Attention in the Frozen Language Model)
这是最主要的弥补方式。论文在 Section 2.3 中指出:
"...the dependency on all previous images remains via self-attention in the LM." (Page 6) "Note that while the model cannot explicitly attend to all previous images due to this masking strategy, it can still implicitly attend to them from the language-only self-attention that propagates all previous images' features via the previous text tokens." (Page 36)
其工作原理如下:
-
文本上下文积累: 语言模型(LM)在处理文本序列时,其内部的自注意力机制允许每个文本 token 关注序列中所有先前的文本 token。
-
视觉信息编码到文本中: 当一个图像被处理后,其视觉特征会通过交叉注意力影响紧随其后的文本 token 的表示 。例如,如果图像 A 后面跟着文本描述
-
通过文本上下文传递视觉信息: 当模型遇到图像 B 及其文本描述
因此,虽然模型不能同时直接 将交叉注意力投射到多个图像上,但它可以通过文本作为中介,间接地"记住"并利用之前图像的信息。
b) 提示工程 (Prompt Engineering)
在实践中,用户可以通过精心设计的提示来引导模型利用多个图像的信息。例如,在对话场景中(如 Figure 11 的多图像对话),用户可以先提问关于一个图像,得到回答后,再提问关于另一个图像,然后提出一个需要整合前两个图像信息的综合性问题。模型通过对话历史(即之前的文本和图像的交错序列)来维持上下文。
五、视觉处理与Preceiver重采样器
1.Vision Encoder:从像素到特征
视觉编码器是一个预训练且冻结的无归一化层残差网络(NFNet)------ 使用F6模型
本文使用Radford等人提出的双项对比损失,在图像和文本对数据集上,使用对比目标预训练视觉编码器。
使用最后阶段的输出,这是一个二维空间特征网格,它被展平为一个一维序列。对于视频输入,帧以1 FPS的速率采样,并独立编码以获得一个三维时空特征网格,并向其中添加学习到的时间嵌入。特征随后被展平为一维,然后被馈送到Perceiver Resampler。
为什么最后阶段的输出是一个二维空间特征网格?
核心原因: 这与 Flamingo 模型所使用的 Vision Encoder (视觉 编码器 ) 的设计有关。论文明确指出:
"Our vision encoder is a pretrained and frozen Normalizer-Free ResNet (NFNet) 10 -- we use the F6 model. We pretrain the vision encoder using a contrastive objective on our datasets of image and text pairs, using the two-term contrastive loss from Radford et al. 85. We use the output of the final stage, a 2D spatial grid of features that is flattened to a 1D sequence." (Section 2.1, Page 5)
这表明:
-
使用了预训练的 CNN 模型: Flamingo 使用了一个预训练且冻结的 Normalizer-Free ResNet (NFNet) 作为其视觉编码器,具体是 F6 模型。ResNet 系列模型是经典的卷积神经网络(CNN),它们在图像分类任务中表现出色。
-
CNN 的特征提取机制: 经典的 CNN 架构(如 ResNet)通过一系列卷积层、池化层和非线性激活函数来处理图像。随着层数的加深,网络会逐渐提取出图像中越来越抽象和高层次的特征。在网络的"最后阶段"(通常是最后一个卷积块或池化层之后),输出的特征图通常是一个三维 张量 ,其维度可以表示为
(C, H, W),其中C是特征通道数,H和W是空间维度(高度和宽度)。这个(H, W)就是我们所说的二维空间特征网格,它保留了图像中不同区域(空间位置)的特征信息。 -
保持空间信息的重要性: 这种二维网格形式的输出,保留了原始图像的空间结构信息,这对于理解图像中的物体位置、布局和相互关系至关重要。例如,在视觉问答任务中,回答"猫在桌子上面吗?"这类问题就需要模型理解"猫"和"桌子"的各自位置。
因此,最后阶段的输出是一个二维空间特征网格,是其底层 CNN 视觉编码器在提取图像特征时的自然结果,旨在保留图像的空间信息。
二维空间特征网络是如何被展平为一个一维序列的?
展平为一维序列是为了将其输入到后续的 Perceiver Resampler 模块。这个过程的具体操作如下:
-
对于图像输入:
-
原始输出: 如上所述,CNN 视觉编码器输出一个
(C, H, W)的二维空间特征网格。 -
展平操作: "展平"通常意味着将
(H, W)的空间维度合并成一个单一的维度。例如,可以将H × W个空间位置上的特征向量按行或按列顺序连接起来。这样,一个(C, H, W)的张量就会变成一个(H × W, C)或(C, H × W)的二维张量,其中H × W代表了序列的长度,C依然是特征维度。论文中提到是"展平为一个一维序列",更准确的理解是将其空间维度展开,形成一个序列,每个元素是该空间位置的特征向量。
-
-
对于视频输入:
-
帧采样与独立编码: 视频首先以 1 FPS 的速率采样,得到一系列图像帧。
-
独立编码: 每个图像帧都通过视觉编码器独立编码,生成各自的二维空间特征网格
(C, H, W)。 -
时间嵌入: 关键的一步是"添加学习到的时间嵌入"。这意味着对于视频中的每个帧,都会有一个学习到的时间位置编码被加入到其视觉特征中。这使得模型能够区分不同时间点的帧,并理解时间序列。
-
三维时空特征网格: 将所有帧的二维空间特征网格堆叠起来,并结合时间嵌入,就形成了一个三维时空特征网格 。其维度可能类似于
(T, C, H, W),其中T是时间维度(帧数)。 -
展平操作: 类似于图像,这个三维时空特征网格需要被展平为一维序列。这通常是将
(T, H, W)的时空维度合并成一个单一的序列维度。例如,将所有帧的所有空间位置上的特征向量按时间顺序再按空间顺序连接起来,形成一个(T × H × W, C)的序列。
-
展平的目的:
-
统一接口: Perceiver Resampler 旨在处理来自不同模态(图像或视频)的可变数量的输入特征。通过将所有视觉输入统一展平为一维序列,Perceiver Resampler 可以用一个通用的机制来处理它们。
-
适应 Transformer 架构: Perceiver Resampler 内部使用了 Transformer 架构(具体来说是交叉注意力机制)。Transformer 的输入通常是序列,因此将视觉特征展平为一维序列是与 Transformer 架构兼容的必要步骤。
-
降低复杂度(通过 Perceiver Resampler): 尽管展平后的序列可能非常长(尤其是对于视频),但 Perceiver Resampler 的关键作用是将其重新采样为固定数量的少量视觉 token (64个),从而大大降低了后续视觉-文本交叉注意力的计算复杂度。
总之,最后阶段的输出是二维空间特征网格,是因为使用了 CNN 视觉编码器来保留空间信息。而将其展平为一维序列,是为了将其作为序列输入到 Perceiver Resampler 中,从而实现视觉模态的统一处理和与 Transformer 架构的兼容性。
Perceiver Resampler将视觉特征重新采样为固定数量的64个视觉token,这个数量是如何确定的?改变这个数量会对模型性能产生什么影响?
1.Perceiver Resampler 中 64 个视觉 Token 的数量是如何确定的?
论文中提到 Perceiver Resampler 输出固定数量的 64 个视觉 token,但并未直接说明"64"这个具体数字是如何通过理论推导或某项特定分析严格确定的。然而,根据对类似模型(如原始 Perceiver 和 DETR )以及模型设计原则的理解,我们可以推断出其确定方式和背后的考量:
-
受 Perceiver 模型启发: Perceiver Resampler 的设计灵感来源于 Perceiver 模型 。Perceiver 的核心思想是使用一组学习到的低维潜在查询 (learned latent queries) 来对高维、变长的输入(如图像像素、视频帧等)进行交叉注意力,从而输出固定数量的低维表示。这个"固定数量"就是由潜在查询的数量决定的。
-
Perceiver 的查询设计: 在 Perceiver 模型中,这些潜在查询是模型学习到的,它们不直接对应输入数据的任何特定部分,而是作为一种"瓶颈"机制,从海量输入中提取出最相关的、浓缩的信息。
-
Flamingo 的实现: Flamingo 的 Perceiver Resampler 也是通过学习预定义数量的潜在输入查询 (predefined number of latent input queries) 来实现这一点的。这些查询会与视觉编码器输出的展平视觉特征进行交叉注意力。因此,输出的视觉 token 数量就等于这些学习到的潜在查询的数量。
-
-
经验性与工程性权衡 (Empirical and Engineering Trade-offs):
-
计算效率: Perceiver Resampler 的主要目标之一是降低视觉-文本交叉注意力的计算复杂度。如果直接将高分辨率图像或长视频的原始像素/特征序列输入到语言模型中,序列长度会非常大,导致 Transformer 的计算复杂度(通常是序列长度的平方)过高。通过将大量视觉特征压缩到 64 个 token,可以显著减少后续交叉注意力的计算量。
-
信息保留: 64 个 token 需要足够多,以便能够捕获原始视觉输入中的足够丰富的语义信息,足以支持各种下游任务(如图像问答、图像描述)。如果 token 数量太少,可能会丢失关键细节。
-
模型容量与训练稳定性: 这个数字很可能是在实验过程中,通过对不同数量的潜在查询进行** ablation study(消融研究)**,在保持良好性能、计算效率和训练稳定性之间找到的一个经验性平衡点。论文在 Section B.3.1 (Ablation study experimental setup) 中提到他们"进一步调查了 Resampler 的架构设计 (row (i) of Table 10)",并发现"中等大小的 Resampler 实现了最佳性能",这暗示了他们对 Perceiver Resampler 内部参数(包括潜在查询数量)进行过探索和优化。
-
因此,"64"这个数字很可能是在遵循 Perceiver 架构设计原则的基础上,通过大量的实验和调优,在保证信息压缩效率和维持下游任务性能之间找到的最佳实践。
2.改变这个数量会对模型性能产生什么影响?
改变 Perceiver Resampler 输出的视觉 token 数量(即学习到的潜在查询数量)会直接影响模型处理视觉信息的能力,从而对性能产生以下影响:
-
减少视觉 Token 数量 (< 64):
-
信息丢失风险: 如果视觉 token 数量过少,Perceiver Resampler 可能会被迫丢弃原始视觉特征中的重要细节和上下文信息。这可能导致模型在需要精细视觉理解的任务(如识别小物体、理解复杂场景细节)上表现不佳。
-
性能下降: 这种信息瓶颈会限制语言模型从视觉输入中获取完整信息的能力,从而导致在各种视觉-语言任务(如视觉问答、图像描述)上的性能下降。
-
计算效率提升(但可能不明显): 虽然减少 token 数量会进一步降低后续交叉注意力的计算量,但如果性能损失过大,这种效率提升就没有意义。
-
-
增加视觉 Token 数量 (> 64):
-
潜在的信息保留: 增加视觉 token 数量可能会允许 Perceiver Resampler 保留更多来自原始视觉输入的细节和更丰富的上下文信息。这对于需要高度感知细节的任务可能是有益的。
-
计算成本增加: Perceiver Resampler 输出的 token 数量直接决定了后续语言模型中交叉注意力层的计算复杂度。由于 Transformer 的注意力机制通常是序列长度的平方,增加 token 数量会显著增加模型的计算负担(训练和推理时间),并可能导致更高的内存消耗。
-
训练稳定性挑战: 更多的可学习参数(潜在查询)和更复杂的注意力交互可能使模型训练更不稳定,需要更精细的超参数调整。
-
边际效益 递减: 就像许多深度学习模型的容量一样,性能提升往往会经历边际效益递减。达到某个点后,即使继续增加 token 数量,性能提升也会变得微不足道,甚至可能因为过拟合或训练难度增加而略有下降。
-
论文中的暗示和支持:
-
在 Section B.3.1 (Resampler size) 的消融研究中,论文明确指出:"我们调查了 Resampler 的大小,有三种选择:小、中(所有 Flamingo 模型的默认值)和大。我们发现中等大小的 Resampler 实现了最佳性能。"
-
虽然这里用"大小"来描述,但 Perceiver Resampler 的"大小"很可能包括了其输出 token 的数量。这个结果间接支持了"64"是一个在性能和效率之间经过优化的选择。
-
论文还提到:"此外,当与冻结的语言模型一起扩展时,我们观察到增加 Perceiver Resampler 的大小会导致训练不稳定。因此,我们保守地选择所有 Flamingo 模型都使用相同的中等 Resampler 大小。" 这进一步印证了更大的 Perceiver Resampler(可能意味着更多的 token)会带来训练稳定性问题。
-
总结:
64 个视觉 token 的数量很可能是在 DeepMind 内部经过大量实验和权衡后确定的一个经验性最佳值。它在保证模型能够从视觉输入中提取足够语义信息的同时,又控制了计算成本和训练稳定性。
-
减少这个数量 会面临信息丢失导致性能下降的风险。
-
增加这个数量 虽然可能捕获更多细节,但会显著增加计算资源需求,可能导致训练不稳定,并且性能提升可能会遇到边际效益递减。
Flamingo 的设计哲学是"深度优先于简洁",但这种深度是在可接受的计算成本和训练稳定性下实现的。64 个视觉 token 数量就是这种哲学在具体组件设计上的体现。
2.Preceiver Resampler:从不同大小的大型特征图到少量视觉token
该模块将视觉编码器连接到冻结的语言模型。它以来自视觉编码器的可变数量的图像或视频特征作为输入,并产生固定数量的视觉输出(64),从而降低了视觉-文本交叉注意的计算复杂度,经消融实验得知使用这种视觉-语言重采样器模块优于普通的Transformer和MLP
六、基于视觉表征调节冻结语言模型
文本生成由 Transformer 解码器执行,该解码器以 Perceiver Resampler 生成的视觉表征为条件。将预训练且冻结的纯文本 LM 块与从头开始训练的块交错排列,后者交叉注意来自 Perceiver Resampler 的视觉输出。
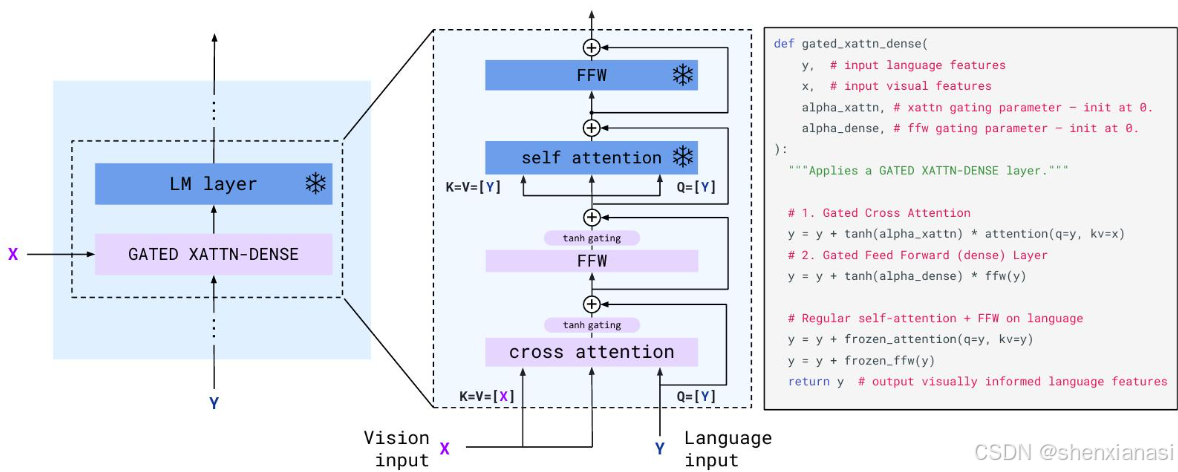
在冻结的预训练语言模型中交错新的门控交叉注意力稠密层。冻结预训练的语言模型块,并在原始层之间插入从头开始训练的门控交叉注意力稠密块(图4)。
Flamingo最核心的创新点之一:如何在不破坏强大预训练语言模型( LM )原有知识的基础上,有效地融入视觉信息?
论文中提到"在冻结的预训练语言模型中交错新的门控交叉注意力稠密层",并"冻结预训练的语言模型块,并在原始层之间插入从头开始训练的门控交叉注意力稠密块"。
这样做主要有以下几个核心目的和设计动机:
1.核心目的:将视觉信息融入语言模型,实现多模态理解
这是最直接的目的。传统的语言模型只能处理文本,而 Flamingo 旨在处理图像和文本交错的序列。为了让语言模型理解和生成与视觉内容相关的文本,必须提供一种机制,使它能够"看到"并"理解"图像或视频。插入交叉注意力层就是这种机制。
2.设计动机一:防止灾难性遗忘 (Catastrophic Forgetting)
-
问题: 如果直接对一个已经在海量文本数据上预训练好的大型语言模型进行微调,以适应多模态任务,很可能会导致灾难性遗忘。这意味着模型会"忘记"它在纯文本预训练阶段学到的丰富语言知识和推理能力,因为它正在尝试适应一个新的数据分布和任务目标。
-
解决方案: 冻结预训练的语言模型块 是防止灾难性遗忘的关键策略。通过保持 LM 块的权重不变,模型能够:
-
保留强大的语言先验知识: LM 已经学习了语法、语义、世界知识和复杂的推理模式。冻结这些权重可以确保这些宝贵的知识不会在多模态训练过程中被破坏。
-
提高训练稳定性: 大型语言模型训练本身就非常复杂。如果所有参数都从头开始训练或同时微调,训练过程会非常不稳定。冻结大部分参数可以显著简化训练,使其更稳定。论文在 Section D.1 中明确指出"Freezing LM components prevents catastrophic forgetting",并在 Section B.3.3 (row (viii)) 的消融研究中验证了这一点:如果从头开始训练 LM,性能会大幅下降 12.9%;即使微调预训练的 LM 也会导致 8.0% 的性能下降。
-
3.设计动机二:高效且有策略地引入视觉条件 (Efficient and Strategic Visual Conditioning)
-
插入位置: 新的交叉注意力层被"交错 "地插入到现有的 LM 块之间 ,而不是简单地在模型开头或结尾添加一个大型视觉模块。这种交错的设计使得视觉信息能够在语言模型处理文本的每个阶段都被整合和利用。这允许视觉信息以更细粒度的方式影响文本生成,而不是仅仅在输入或输出层进行一次粗略的融合。
-
门控机制 (Gating Mechanism): 论文特别强调了"门控交叉注意力稠密层 (GATED XATTN-DENSE layers) "。图 4 详细展示了这种机制,它使用
tanh(alpha_xattn)和tanh(alpha_dense)来门控交叉注意力输出和前馈网络 (FFW) 输出。-
初始化时的完整性: 门控参数
alpha_xattn和alpha_dense在初始化时被设置为 0。这意味着在训练开始时,tanh(0)等于 0,所以新添加的交叉注意力层和稠密层的输出在添加到残差连接之前会被"归零"。 -
保护初始状态: 这确保了在初始化时,整个条件模型(带有视觉输入)的行为与原始的、未条件化的语言模型完全相同。 这种"不干扰"初始状态的特性对于维持预训练 LM 的知识至关重要,并提供了更好的训练稳定性。随着训练的进行,
alpha值会学习增长,从而允许视觉信息逐渐地、有控制地影响语言模型。论文在 Section B.3.3 (row (iii)) 的消融研究中显示,如果没有 0 初始化的 tanh 门控,整体得分会下降 4.2%,并且训练不稳定。
-
-
轻量级且可训练: 这些新添加的交叉注意力层和随后的稠密层是从头开始训练的,而不是微调预训练的 LM 权重。这使得它们能够专门学习如何将视觉信息映射并整合到语言模型的表示中,而不会干扰 LM 自身的核心功能。由于只训练这些新增的层,参数效率更高。
4.设计动机三:Perceiver Resampler 的作用
-
处理变长视觉输入: 视觉编码器(如 NFNet)可以输出高分辨率图像或视频帧的大量特征。视频输入尤其具有可变的长度。Perceiver Resampler 的作用是将这些变长、高维的视觉特征转换为固定数量的低维视觉 token (64个)。
-
降低计算复杂度: 这样做的好处是,后续的语言模型在进行视觉-文本交叉注意力时,只需要关注这 64 个视觉 token,而不是原始的数千甚至数万个像素或帧特征。这极大地降低了计算复杂度,使得模型能够高效地处理视觉输入。
总结流程:
-
预训练: 拥有一个强大的冻结的语言模型 (已学习丰富的文本知识)和一个强大的冻结的视觉 编码器(已学习视觉特征提取)。
-
视觉特征处理: 使用 Perceiver Resampler 将视觉编码器的输出(高维、变长)转换为固定数量的低维视觉 token(例如 64 个),以降低计算复杂度和处理变长输入。
-
多模态融合: 在冻结的 LM 块之间交错插入新的、从头开始训练的门控交叉注意力稠密层。
- 门控机制 确保在训练初期不干扰 LM 的原始行为,保持训练稳定性。
- 交叉注意力 层允许语言模型在处理文本时,动态地根据视觉 token 来调整其内部状态和下一个词的预测。
- 冻结 LM 块 防止灾难性遗忘,保留其强大的语言能力。
通过这种精巧的设计,Flamingo 能够在保留预训练语言模型强大能力的同时,无缝且高效地融入视觉信息,从而实现卓越的 Few-Shot 多模态学习能力。
为了确保在初始化时,条件模型产生与原始语言模型相同的结果,我们使用tanh门控机制。这会将新添加层的输出乘以tanh(α),然后再将其添加到来自残差连接的输入表示中,其中𝛼是一个特定于层的可学习标量,初始化为0
为什么选用 tanh(α) 作为门控机制?
这里 tanh(α) 的作用是门控 (Gating) ,它的核心动机是实现平滑的、从零开始的条件化 (Smooth, Zero-initialized Conditioning)。
解释与设计动机:
-
初始化为零 (Zero-initialization):
α被初始化为 0。当α=0时,tanh(0) = 0。 -
隔离新层: 在训练开始时,新添加的门控交叉注意力层 和随后的稠密层 的输出会被
tanh(0) = 0乘以,这意味着它们的贡献在初始化时被完全"关闭"或"隔离"。 -
保持原始 LM 行为: 由于新层的输出在初始化时是零,通过残差连接(
y = y + tanh(alpha) * attention(...)),模型的语言路径在训练开始时完全等同于原始的、未修改的冻结语言模型 。这确保了在训练初期,模型不会因为新加入的、尚未学习有效视觉-文本对齐的层而产生不稳定的行为或性能下降。 -
平滑学习: 随着训练的进行,
α作为一个可学习参数,会逐渐从 0 开始增长。tanh(α)的值会从 0 逐渐增大(接近 1)。这允许新层对语言模型的影响从无到有,平滑地、渐进地增加。这种渐进式学习有助于提高训练的稳定性和最终性能,避免了模型在训练初期因"冲击"而崩溃。 -
防止灾难性遗忘 (Reinforcement): 这种门控机制进一步强化了防止灾难性遗忘的策略。它不仅冻结了 LM 的大部分权重,还在引入新信息时提供了一个"软启动"机制,确保原有知识不受干扰。
总结: 选用 tanh(α) 作为门控是为了在训练开始时将新加入的视觉条件层"关闭",使模型行为与原始预训练 LM 一致,并在训练过程中通过学习 α 参数,平滑地引入视觉信息,从而提高训练稳定性和最终性能。
设定函数 具有以下性质:
1)为奇函数;
2)值域在-1,1
3)函数变化较为缓慢
考虑: 是否可以作为 tanh(α) 函数的替代函数,起到门控注意力的作用?
门控机制的核心目标:在维持模型稳定性的前提下,实现对视觉信息的平滑、可控的整合。
门控函数的核心需求回顾
-
初始化为 0: 这是最关键的,确保新加入的视觉条件层在训练开始时对冻结语言模型没有干扰,即
output_new_layer * gate_value = 0。 -
平滑变化: 门控值应该能够从 0 平滑地过渡到非零值,允许模型渐进地学习如何利用视觉信息。
-
值域: 门控值的范围决定了新层对原始语言模型表示的"最大影响强度"。
[-1, 1]的范围允许门控值不仅能增强(接近1),也能稍微抑制甚至反向调节(接近-1,尽管在大多数情况下我们期望的是增强)。
满足您条件的函数类型
函数\\phi(),确实是 tanh(x) 的良好替代品。这类函数通常具有以下特点:
-
奇函数 ( Odd Function):
f(-x) = -f(x)。对于门控机制而言,这意味着正向的输入(比如α的正值)会产生正向的门控(增强),负向输入则产生负向门控(抑制)。这在某些情况下可能提供额外的灵活性,但对于简单的"激活"或"增强"门控,其核心价值在于f(0)=0,这在数学上是所有奇函数的性质。 -
值域在
[-1, 1]: 确保门控值不会无限增大,从而避免新层对语言模型产生过大的、不稳定的扰动。[-1, 1]的范围允许在不破坏原始语言模型信息的前提下进行增强或(轻微的)抑制。 -
变化较为缓慢: 这通常指的是函数在
x=0附近斜率较小,或者在整个定义域内没有剧烈的跳变。这有助于训练的稳定性,因为门控值不会对微小的α变化产生过于敏感的响应。
具体的替代函数示例
除了 tanh(x) 之外,确实存在一些满足这些条件的函数,但它们可能需要更复杂的参数化或调整:
-
arctan(x)的 归一化 版本:-
arctan(x)的值域是(-π/2, π/2),是奇函数,且arctan(0) = 0。 -
为了将其值域缩放到
[-1, 1],可以将其除以π/2:g(x) = (2/π) * arctan(x)。 -
变化缓慢特性:
arctan(x)在原点附近的变化相对tanh(x)来说可能稍慢,尤其是在x较大时,它会更早地饱和。
-
-
平滑化的阶跃函数(S-形曲线)或多项式函数:
- 虽然不如
tanh和arctan常见,但可以构造一些高阶奇多项式,使其在[-1, 1]之间,并在原点附近有平缓的斜率。例如,f(x) = x - x^3/3在一定范围内近似tanh。但这通常需要额外的裁剪或归一化以确保值域严格在[-1, 1],并且可能不如tanh等解析函数在优化上表现良好。
- 虽然不如
-
erf(x)的 归一化 版本:-
误差函数
erf(x)也是奇函数,值域在(-1, 1),且erf(0) = 0。 -
变化缓慢特性:
erf(x)在原点附近的变化也比较平滑,与tanh(x)有些相似。
-
为什么 tanh(x) 仍然是首选(或最常见)
尽管存在其他替代品,tanh(x) 在这种门控场景中之所以被广泛使用,主要有以下几个原因:
-
简洁性与数学性质:
tanh(x)是一个非常简洁且导数形式简单的函数,这对于梯度计算和优化非常有利。它自然地满足f(0)=0、奇函数特性和[-1, 1]值域。 -
饱和特性:
tanh(x)在输入值较大时会快速趋近于 1 或 -1(饱和),这可以有效地限制门控的强度,防止数值爆炸,并使得模型能够"决定"是否完全激活或关闭视觉信息。 -
广泛应用与经验:
tanh在神经网络中作为激活函数和门控机制(如 LSTM 和 GRU)有深厚的应用历史,其行为特性和训练稳定性已被广泛验证。
tanh(x) 通常是最佳选择 ,因为它在数学性质、优化友好性、饱和特性以及在神经网络中的良好经验表现之间取得了很好的平衡,尤其是在需要 f(0)=0 来确保初始化稳定性的场景中。如果您选择其他函数,可能需要额外的工程和实验来验证其在训练稳定性、收敛速度和最终性能方面的表现是否优于 tanh(x)。
七、Training on a mixture of vision and language datasets
通过最小化每个数据集的文本期望负对数似然的加权和来训练模型,给定视觉输入:
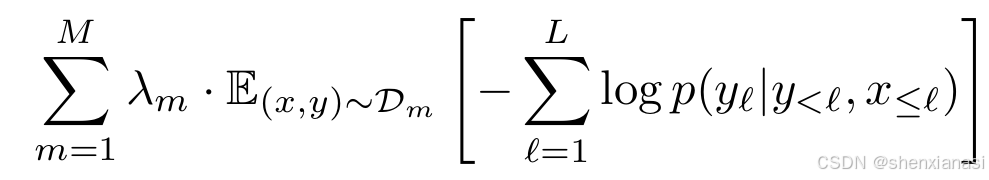
【符号解释】:
-
M: 训练所使用的不同数据集的总数量。
-
-
-
L: 文本序列 y 的总长度,即文本中语言 token 的数量。
-
ℓ: 文本序列中的当前语言 token 索引,从 1 到 L。
-
-
yℓ: 输入文本序列中的第 ℓ 个语言 token。
-
y<ℓ: 在文本序列中,所有位于 yℓ 之前的语言 token 的集合。
-
x≤ℓ: 在交错序列中,所有位于 yℓ 之前的图像/视频输入 x 的集合。根据论文,模型只关注紧邻当前文本 token 之前的最后一个图像/视频。
-
-
【公式应用场景及解释】:
该公式描述了Flamingo模型在多模态、多数据集环境下的训练目标。它通过以下方式实现:
-
逐数据集损失计算:
-
对于每一个数据集 m(从 1 到 M),模型会从该数据集中采样一对视觉输入和文本序列 (x,y)。
-
对于每个 (x,y) 样本,模型计算其负对数似然损失。这个损失是自回归的,即模型尝试在给定所有先前文本 token (y<ℓ) 和先前视觉信息 (x≤ℓ) 的情况下,预测当前文本 token (yℓ)。
-
根据论文描述,
-
-
损失加权求和:
-
每个数据集 m 的期望负对数似然损失(
-
所有数据集的加权损失被求和 (
-
论文明确指出,"调整每个数据集的权重 λm 对性能至关重要",这意味着这些权重是超参数,需要精心选择以平衡不同数据集的贡献,从而达到最佳的整体性能。
-
-
梯度累积优化:
- 论文提到他们"在所有数据集上累积梯度,这比'轮循'方法表现更好"。这意味着在每个训练步骤中,模型会计算所有数据集的加权损失总和的梯度,然后使用这个总梯度来更新模型参数,而不是轮流在一个数据集上训练一个 epoch。这种方法有助于模型同时从所有数据源中学习,并可能提供更稳定的训练。
八、局限性
(1)模型建立在预训练的语言模型(LM)之上,因此会直接继承它们的弱点。例如,语言模型的先验知识通常是有帮助的,但可能在偶尔的幻觉和无根据的猜测中发挥作用。此外,语言模型对长于训练序列的序列泛化能力较差。它们在训练期间也存在样本效率低下的问题
(2)Flamingo的分类性能落后于最先进的对比模型
(3)in-context learning(不是姚顺宇提出的那个CL)相对于基于梯度的少样本学习方法具有显著优势,但也存在一些缺点,具体取决于手头应用的特性。本文证明了当只能访问少量(几十个)示例时,上下文学习的有效性。上下文学习还实现了简单的部署,只需要推理,通常不需要超参数调整。然而,众所周知,上下文学习对演示的各个方面高度敏感,并且其推理计算成本和绝对性能会随着超出此低数据范围的样本数量而急剧下降。可能存在将少样本学习方法结合起来以利用其互补优势的机会
九、说明
本文仅仅是本人在读这篇Paper时的一点理解以及对我的一些疑惑解答后的整理总结,希望能够帮助大家真正深刻的理解Florence,帮助大家找到好的idea。如果大家觉得有所帮助的话,欢迎大家一键三连;如果觉得哪里有什么问题,欢迎评论区交流一下!