swanlab: Tracking run with swanlab version 0.7.8
swanlab: Run data will be saved locally in
/root/workspace/SFT/swanlog/run-20260214_194247-3pbhrarpfcqr95z67fwxq
swanlab: 🚀 View run at
0%| | 0/1084 00:00\`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`.
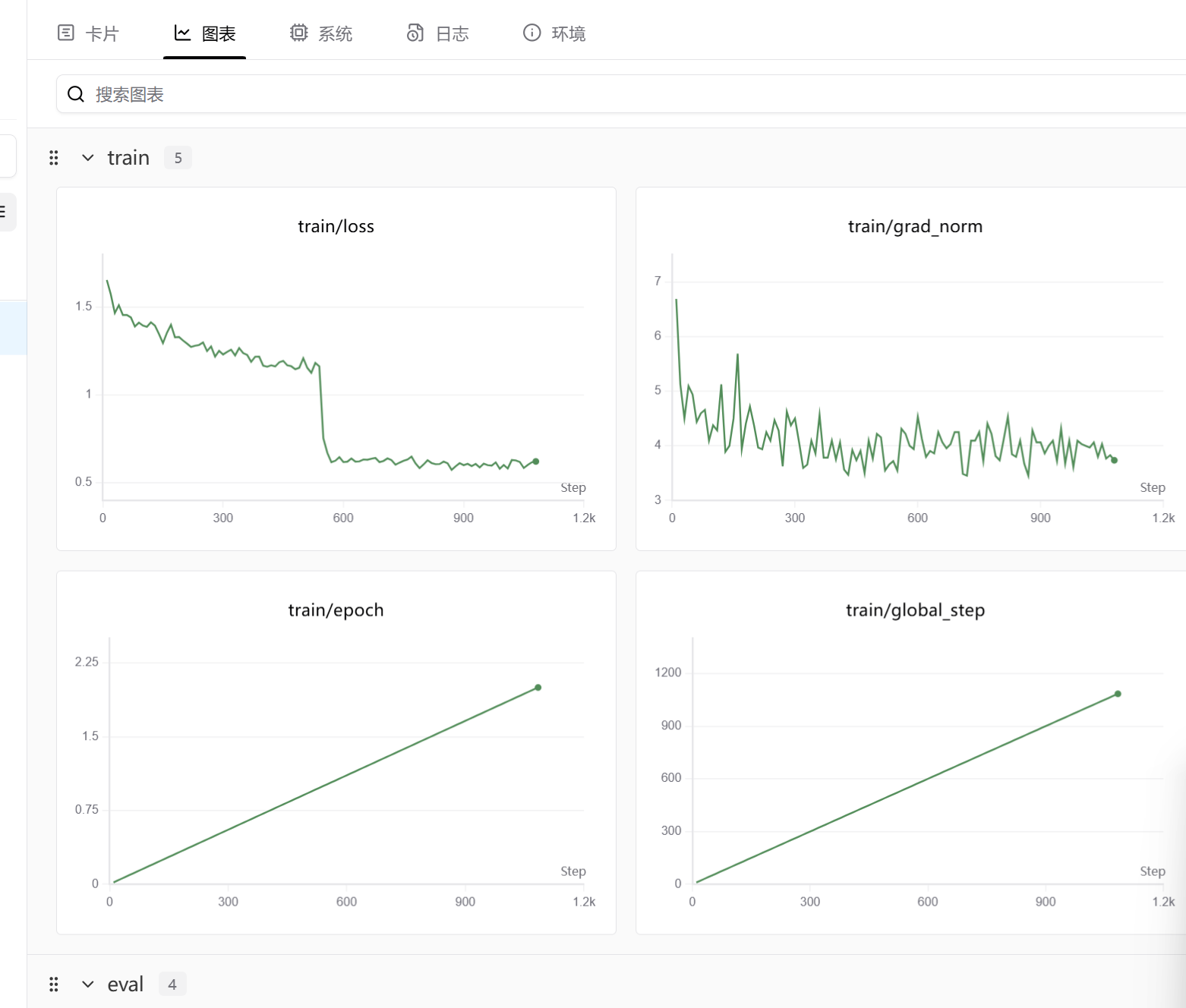
{'loss': 1.6551, 'grad_norm': 6.6875, 'learning_rate': 9.916974169741697e-05, 'epoch': 0.02}
{'loss': 1.5727, 'grad_norm': 5.125, 'learning_rate': 9.824723247232473e-05, 'epoch': 0.04}
{'loss': 1.4665, 'grad_norm': 4.5, 'learning_rate': 9.732472324723247e-05, 'epoch': 0.06}
{'loss': 1.5116, 'grad_norm': 5.09375, 'learning_rate': 9.640221402214022e-05, 'epoch': 0.07}
{'loss': 1.4561, 'grad_norm': 4.9375, 'learning_rate': 9.547970479704798e-05, 'epoch': 0.09}
{'loss': 1.4563, 'grad_norm': 4.4375, 'learning_rate': 9.455719557195572e-05, 'epoch': 0.11}
{'loss': 1.4422, 'grad_norm': 4.59375, 'learning_rate': 9.363468634686348e-05, 'epoch': 0.13}
{'loss': 1.3903, 'grad_norm': 4.65625, 'learning_rate': 9.271217712177123e-05, 'epoch': 0.15}
{'loss': 1.4125, 'grad_norm': 4.09375, 'learning_rate': 9.178966789667896e-05, 'epoch': 0.17}
{'loss': 1.3957, 'grad_norm': 4.375, 'learning_rate': 9.086715867158672e-05, 'epoch': 0.18}
9%|███▋ | 100/1084 01:04\<10:41, 1.53it/s
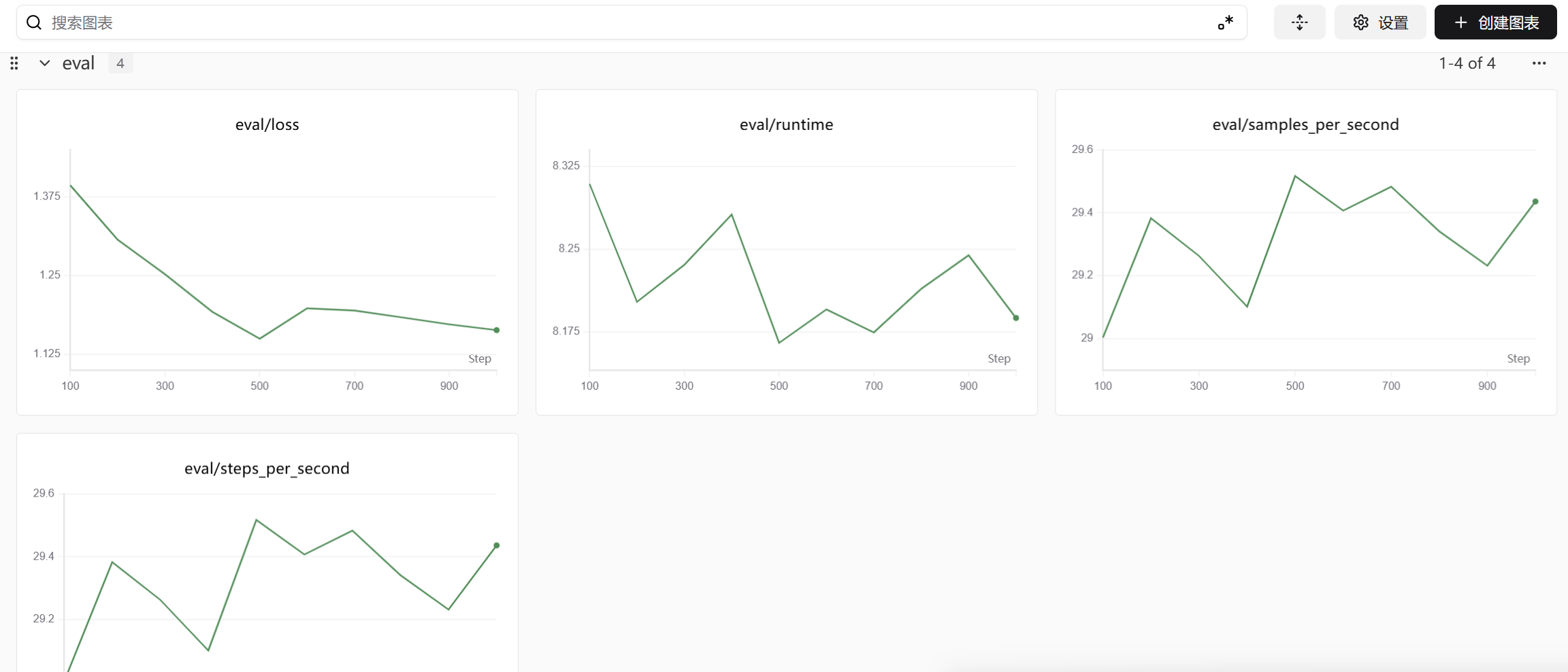
{'eval_loss': 1.3938418626785278, 'eval_runtime': 8.3091, 'eval_samples_per_second': 29.004, 'eval_steps_per_second': 29.004, 'epoch': 0.18}
9%|███▋ | 100/1084 01:13\<10:41, 1.53it/s
{'loss': 1.3884, 'grad_norm': 4.28125, 'learning_rate': 8.994464944649447e-05, 'epoch': 0.2}
{'loss': 1.4145, 'grad_norm': 5.125, 'learning_rate': 8.902214022140221e-05, 'epoch': 0.22}
{'loss': 1.3954, 'grad_norm': 3.890625, 'learning_rate': 8.809963099630997e-05, 'epoch': 0.24}
{'loss': 1.3476, 'grad_norm': 4.0, 'learning_rate': 8.717712177121771e-05, 'epoch': 0.26}
{'loss': 1.2956, 'grad_norm': 4.5, 'learning_rate': 8.625461254612547e-05, 'epoch': 0.28}
{'loss': 1.3551, 'grad_norm': 5.6875, 'learning_rate': 8.533210332103322e-05, 'epoch': 0.3}
{'loss': 1.4003, 'grad_norm': 3.9375, 'learning_rate': 8.440959409594096e-05, 'epoch': 0.31}
{'loss': 1.3292, 'grad_norm': 4.40625, 'learning_rate': 8.348708487084871e-05, 'epoch': 0.33}
{'loss': 1.3307, 'grad_norm': 4.71875, 'learning_rate': 8.256457564575646e-05, 'epoch': 0.35}
{'loss': 1.3106, 'grad_norm': 4.375, 'learning_rate': 8.16420664206642e-05, 'epoch': 0.37}
18%|███████▍ | 200/1084 02:16\<09:35, 1.54it/s
{'eval_loss': 1.3073816299438477, 'eval_runtime': 8.2021, 'eval_samples_per_second': 29.383, 'eval_steps_per_second': 29.383, 'epoch': 0.37}
18%|███████▍ | 200/1084 02:24\<09:35, 1.54it/s
{'loss': 1.293, 'grad_norm': 3.96875, 'learning_rate': 8.071955719557196e-05, 'epoch': 0.39}
{'loss': 1.274, 'grad_norm': 3.9375, 'learning_rate': 7.979704797047972e-05, 'epoch': 0.41}
{'loss': 1.281, 'grad_norm': 4.25, 'learning_rate': 7.887453874538746e-05, 'epoch': 0.42}
{'loss': 1.285, 'grad_norm': 4.09375, 'learning_rate': 7.795202952029521e-05, 'epoch': 0.44}
{'loss': 1.2994, 'grad_norm': 4.46875, 'learning_rate': 7.702952029520296e-05, 'epoch': 0.46}
{'loss': 1.2504, 'grad_norm': 4.28125, 'learning_rate': 7.61070110701107e-05, 'epoch': 0.48}
{'loss': 1.2771, 'grad_norm': 3.625, 'learning_rate': 7.518450184501845e-05, 'epoch': 0.5}
{'loss': 1.2186, 'grad_norm': 4.625, 'learning_rate': 7.42619926199262e-05, 'epoch': 0.52}
{'loss': 1.2517, 'grad_norm': 4.375, 'learning_rate': 7.333948339483395e-05, 'epoch': 0.54}
{'loss': 1.2311, 'grad_norm': 4.5, 'learning_rate': 7.24169741697417e-05, 'epoch': 0.55}
28%|███████████ | 300/1084 03:27\<08:20, 1.57it/s
{'eval_loss': 1.252408742904663, 'eval_runtime': 8.2357, 'eval_samples_per_second': 29.263, 'eval_steps_per_second': 29.263, 'epoch': 0.55}
28%|███████████ | 300/1084 03:36\<08:20, 1.57it/s
{'loss': 1.2456, 'grad_norm': 4.0625, 'learning_rate': 7.149446494464945e-05, 'epoch': 0.57}
{'loss': 1.2583, 'grad_norm': 3.59375, 'learning_rate': 7.05719557195572e-05, 'epoch': 0.59}
{'loss': 1.2255, 'grad_norm': 3.65625, 'learning_rate': 6.964944649446495e-05, 'epoch': 0.61}
{'loss': 1.2678, 'grad_norm': 4.09375, 'learning_rate': 6.872693726937269e-05, 'epoch': 0.63}
{'loss': 1.2388, 'grad_norm': 3.859375, 'learning_rate': 6.780442804428044e-05, 'epoch': 0.65}
{'loss': 1.2292, 'grad_norm': 4.5625, 'learning_rate': 6.68819188191882e-05, 'epoch': 0.66}
{'loss': 1.1889, 'grad_norm': 3.78125, 'learning_rate': 6.595940959409594e-05, 'epoch': 0.68}
{'loss': 1.2184, 'grad_norm': 3.78125, 'learning_rate': 6.50369003690037e-05, 'epoch': 0.7}
{'loss': 1.2191, 'grad_norm': 4.09375, 'learning_rate': 6.411439114391144e-05, 'epoch': 0.72}
{'loss': 1.1671, 'grad_norm': 3.75, 'learning_rate': 6.31918819188192e-05, 'epoch': 0.74}
37%|██████████████▊ | 400/1084 04:39\<07:06, 1.60it/s
{'eval_loss': 1.192654013633728, 'eval_runtime': 8.2813, 'eval_samples_per_second': 29.102, 'eval_steps_per_second': 29.102, 'epoch': 0.74}
37%|██████████████▊ | 400/1084 04:47\<07:06, 1.60it/s
{'loss': 1.1614, 'grad_norm': 4.0625, 'learning_rate': 6.226937269372694e-05, 'epoch': 0.76}
{'loss': 1.1696, 'grad_norm': 3.5625, 'learning_rate': 6.134686346863468e-05, 'epoch': 0.78}
{'loss': 1.1628, 'grad_norm': 3.46875, 'learning_rate': 6.0424354243542434e-05, 'epoch': 0.79}
{'loss': 1.1866, 'grad_norm': 3.921875, 'learning_rate': 5.950184501845018e-05, 'epoch': 0.81}
{'loss': 1.1949, 'grad_norm': 3.734375, 'learning_rate': 5.857933579335794e-05, 'epoch': 0.83}
{'loss': 1.1692, 'grad_norm': 3.90625, 'learning_rate': 5.765682656826569e-05, 'epoch': 0.85}
{'loss': 1.1641, 'grad_norm': 3.5, 'learning_rate': 5.6734317343173437e-05, 'epoch': 0.87}
{'loss': 1.1471, 'grad_norm': 4.09375, 'learning_rate': 5.5811808118081185e-05, 'epoch': 0.89}
{'loss': 1.1554, 'grad_norm': 3.765625, 'learning_rate': 5.488929889298893e-05, 'epoch': 0.9}
{'loss': 1.21, 'grad_norm': 4.21875, 'learning_rate': 5.3966789667896676e-05, 'epoch': 0.92}
46%|██████████████████▍ | 500/1084 06:04\<06:06, 1.59it/s
{'eval_loss': 1.1499255895614624, 'eval_runtime': 8.1648, 'eval_samples_per_second': 29.517, 'eval_steps_per_second': 29.517, 'epoch': 0.92}
46%|██████████████████▍ | 500/1084 06:13\<06:06, 1.59it/s
{'loss': 1.1546, 'grad_norm': 4.15625, 'learning_rate': 5.3044280442804425e-05, 'epoch': 0.94}
{'loss': 1.1268, 'grad_norm': 3.546875, 'learning_rate': 5.212177121771218e-05, 'epoch': 0.96}
{'loss': 1.183, 'grad_norm': 3.65625, 'learning_rate': 5.119926199261993e-05, 'epoch': 0.98}
{'loss': 1.1638, 'grad_norm': 3.71875, 'learning_rate': 5.027675276752768e-05, 'epoch': 1.0}
{'loss': 0.7539, 'grad_norm': 3.546875, 'learning_rate': 4.935424354243543e-05, 'epoch': 1.01}
{'loss': 0.6707, 'grad_norm': 4.3125, 'learning_rate': 4.8431734317343176e-05, 'epoch': 1.03}
{'loss': 0.6179, 'grad_norm': 4.21875, 'learning_rate': 4.7509225092250925e-05, 'epoch': 1.05}
{'loss': 0.6259, 'grad_norm': 4.0, 'learning_rate': 4.6586715867158674e-05, 'epoch': 1.07}
{'loss': 0.6462, 'grad_norm': 3.9375, 'learning_rate': 4.566420664206642e-05, 'epoch': 1.09}
{'loss': 0.6182, 'grad_norm': 4.53125, 'learning_rate': 4.474169741697417e-05, 'epoch': 1.11}
55%|██████████████████████▏ | 600/1084 07:16\<04:38, 1.74it/s
{'eval_loss': 1.1983122825622559, 'eval_runtime': 8.1952, 'eval_samples_per_second': 29.407, 'eval_steps_per_second': 29.407, 'epoch': 1.11}
55%|██████████████████████▏ | 600/1084 07:24\<04:38, 1.74it/s
{'loss': 0.6207, 'grad_norm': 4.125, 'learning_rate': 4.381918819188192e-05, 'epoch': 1.13}
{'loss': 0.6387, 'grad_norm': 3.796875, 'learning_rate': 4.289667896678967e-05, 'epoch': 1.14}
{'loss': 0.6205, 'grad_norm': 3.90625, 'learning_rate': 4.197416974169742e-05, 'epoch': 1.16}
{'loss': 0.6223, 'grad_norm': 3.859375, 'learning_rate': 4.105166051660517e-05, 'epoch': 1.18}
{'loss': 0.633, 'grad_norm': 4.25, 'learning_rate': 4.0129151291512916e-05, 'epoch': 1.2}
{'loss': 0.6316, 'grad_norm': 4.0625, 'learning_rate': 3.920664206642067e-05, 'epoch': 1.22}
{'loss': 0.6376, 'grad_norm': 3.953125, 'learning_rate': 3.828413284132841e-05, 'epoch': 1.24}
{'loss': 0.6419, 'grad_norm': 4.03125, 'learning_rate': 3.736162361623616e-05, 'epoch': 1.25}
{'loss': 0.6178, 'grad_norm': 4.25, 'learning_rate': 3.643911439114391e-05, 'epoch': 1.27}
{'loss': 0.6246, 'grad_norm': 4.25, 'learning_rate': 3.5516605166051667e-05, 'epoch': 1.29}
65%|█████████████████████████▊ | 700/1084 08:28\<04:02, 1.58it/s
{'eval_loss': 1.1947330236434937, 'eval_runtime': 8.1743, 'eval_samples_per_second': 29.483, 'eval_steps_per_second': 29.483, 'epoch': 1.29}
65%|█████████████████████████▊ | 700/1084 08:36\<04:02, 1.58it/s
{'loss': 0.6395, 'grad_norm': 3.484375, 'learning_rate': 3.459409594095941e-05, 'epoch': 1.31}
{'loss': 0.6292, 'grad_norm': 3.453125, 'learning_rate': 3.367158671586716e-05, 'epoch': 1.33}
{'loss': 0.6034, 'grad_norm': 4.09375, 'learning_rate': 3.274907749077491e-05, 'epoch': 1.35}
{'loss': 0.6151, 'grad_norm': 4.09375, 'learning_rate': 3.182656826568266e-05, 'epoch': 1.37}
{'loss': 0.6252, 'grad_norm': 4.25, 'learning_rate': 3.0904059040590404e-05, 'epoch': 1.38}
{'loss': 0.6329, 'grad_norm': 3.71875, 'learning_rate': 2.9981549815498156e-05, 'epoch': 1.4}
{'loss': 0.6493, 'grad_norm': 4.40625, 'learning_rate': 2.9059040590405905e-05, 'epoch': 1.42}
{'loss': 0.6106, 'grad_norm': 4.21875, 'learning_rate': 2.8136531365313657e-05, 'epoch': 1.44}
{'loss': 0.5835, 'grad_norm': 3.8125, 'learning_rate': 2.7214022140221403e-05, 'epoch': 1.46}
{'loss': 0.6047, 'grad_norm': 3.734375, 'learning_rate': 2.629151291512915e-05, 'epoch': 1.48}
74%|█████████████████████████████▌ | 800/1084 09:40\<03:07, 1.51it/s
{'eval_loss': 1.1839239597320557, 'eval_runtime': 8.2139, 'eval_samples_per_second': 29.341, 'eval_steps_per_second': 29.341, 'epoch': 1.48}
74%|█████████████████████████████▌ | 800/1084 09:48\<03:07, 1.51it/s
{'loss': 0.6289, 'grad_norm': 4.125, 'learning_rate': 2.5369003690036904e-05, 'epoch': 1.49}
{'loss': 0.613, 'grad_norm': 4.53125, 'learning_rate': 2.444649446494465e-05, 'epoch': 1.51}
{'loss': 0.6062, 'grad_norm': 3.84375, 'learning_rate': 2.35239852398524e-05, 'epoch': 1.53}
{'loss': 0.6071, 'grad_norm': 3.796875, 'learning_rate': 2.2601476014760147e-05, 'epoch': 1.55}
{'loss': 0.6209, 'grad_norm': 4.09375, 'learning_rate': 2.16789667896679e-05, 'epoch': 1.57}
{'loss': 0.6112, 'grad_norm': 3.671875, 'learning_rate': 2.0756457564575644e-05, 'epoch': 1.59}
{'loss': 0.5737, 'grad_norm': 3.453125, 'learning_rate': 1.9833948339483397e-05, 'epoch': 1.61}
{'loss': 0.5943, 'grad_norm': 4.28125, 'learning_rate': 1.8911439114391146e-05, 'epoch': 1.62}
{'loss': 0.6121, 'grad_norm': 4.0625, 'learning_rate': 1.7988929889298894e-05, 'epoch': 1.64}
{'loss': 0.6008, 'grad_norm': 4.0625, 'learning_rate': 1.7066420664206643e-05, 'epoch': 1.66}
83%|█████████████████████████████████▏ | 900/1084 11:05\<01:56, 1.58it/s
{'eval_loss': 1.1728265285491943, 'eval_runtime': 8.2444, 'eval_samples_per_second': 29.232, 'eval_steps_per_second': 29.232, 'epoch': 1.66}
83%|█████████████████████████████████▏ | 900/1084 11:13\<01:56, 1.58it/s
{'loss': 0.6081, 'grad_norm': 3.859375, 'learning_rate': 1.6143911439114392e-05, 'epoch': 1.68}
{'loss': 0.5955, 'grad_norm': 4.0, 'learning_rate': 1.5221402214022141e-05, 'epoch': 1.7}
{'loss': 0.6075, 'grad_norm': 4.09375, 'learning_rate': 1.4298892988929891e-05, 'epoch': 1.72}
{'loss': 0.5878, 'grad_norm': 3.71875, 'learning_rate': 1.3376383763837639e-05, 'epoch': 1.73}
{'loss': 0.6091, 'grad_norm': 4.3125, 'learning_rate': 1.2453874538745389e-05, 'epoch': 1.75}
{'loss': 0.6008, 'grad_norm': 3.671875, 'learning_rate': 1.1531365313653138e-05, 'epoch': 1.77}
{'loss': 0.5985, 'grad_norm': 4.09375, 'learning_rate': 1.0608856088560887e-05, 'epoch': 1.79}
{'loss': 0.6167, 'grad_norm': 3.609375, 'learning_rate': 9.686346863468636e-06, 'epoch': 1.81}
{'loss': 0.5806, 'grad_norm': 4.09375, 'learning_rate': 8.763837638376384e-06, 'epoch': 1.83}
{'loss': 0.6019, 'grad_norm': 4.03125, 'learning_rate': 7.841328413284133e-06, 'epoch': 1.85}
92%|███████████████████████████████████▉ | 1000/1084 12:16\<00:54, 1.54it/s
{'eval_loss': 1.1636466979980469, 'eval_runtime': 8.1874, 'eval_samples_per_second': 29.436, 'eval_steps_per_second': 29.436, 'epoch': 1.85}
92%|███████████████████████████████████▉ | 1000/1084 12:24\<00:54, 1.54it/s
{'loss': 0.5817, 'grad_norm': 4.0, 'learning_rate': 6.918819188191883e-06, 'epoch': 1.86}
{'loss': 0.6298, 'grad_norm': 3.96875, 'learning_rate': 5.996309963099631e-06, 'epoch': 1.88}
{'loss': 0.6278, 'grad_norm': 4.0625, 'learning_rate': 5.0738007380073806e-06, 'epoch': 1.9}
{'loss': 0.619, 'grad_norm': 3.796875, 'learning_rate': 4.151291512915129e-06, 'epoch': 1.92}
{'loss': 0.5847, 'grad_norm': 4.03125, 'learning_rate': 3.2287822878228782e-06, 'epoch': 1.94}
{'loss': 0.602, 'grad_norm': 3.765625, 'learning_rate': 2.3062730627306275e-06, 'epoch': 1.96}
{'loss': 0.617, 'grad_norm': 3.828125, 'learning_rate': 1.3837638376383765e-06, 'epoch': 1.98}
{'loss': 0.6218, 'grad_norm': 3.734375, 'learning_rate': 4.612546125461255e-07, 'epoch': 1.99}
{'train_runtime': 2727.1485, 'train_samples_per_second': 1.588, 'train_steps_per_second': 0.397, 'train_loss': 0.952085128569515, 'epoch': 2.0}
100%|███████████████████████████████████████| 1084/1084 13:30\<00:00, 1.34it/s
The attention mask is not set and cannot be inferred from input because pad token is same as eos token. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.
Caching is incompatible with gradient checkpointing in Qwen3DecoderLayer. Setting `past_key_values=None`.
/opt/miniconda3/envs/torch29/lib/python3.11/site-packages/torch/utils/checkpoint.py:85: UserWarning: None of the inputs have requires_grad=True. Gradients will be None
warnings.warn(
Question: 1895年德国物理学教授伦琴的发现对医学影像学的发展有何具体影响?请从技术进步、学科建立和临床应用三个方面进行分析。
LLM:<think>:::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::
Question: 医生,我最近胃部不适,听说有几种抗溃疡药物可以治疗,您能详细介绍一下这些药物的分类、作用机制以及它们是如何影响胃黏膜的保护与损伤平衡的吗?
LLM:<think>:::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::
Question: 我最近被诊断出患有淋巴瘤,医生提到这可能导致发热。请问这是由于淋巴瘤组织的坏死和细胞破坏引起的吗?如果是,具体机制是什么?
LLM:<think>ine::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::
全参数调试结果: