深度学习网络从入门到入土 含并行连结的网络GoogLeNet
个人导航
知乎:https://www.zhihu.com/people/byzh_rc
CSDN:https://blog.csdn.net/qq_54636039
注:本文仅对所述内容做了框架性引导,具体细节可查询其余相关资料or源码
参考文章:各方资料
文章目录
- [深度学习网络从入门到入土 含并行连结的网络GoogLeNet](#[深度学习网络从入门到入土] 含并行连结的网络GoogLeNet)
- 个人导航
- 参考资料
- 背景
- 架构(公式)
-
-
-
- [1. ==Inception v1模块==(并行卷积结构)](#1. ==Inception v1模块==(并行卷积结构))
- [2. ==1×1 卷积==的作用](#2. ==1×1 卷积==的作用)
- [3. 辅助分类器](#3. 辅助分类器)
-
-
- 创新点
-
-
-
- [1. 并行结构(Multi-branch)](#1. 并行结构(Multi-branch))
- [2. 1×1 卷积大规模使用](#2. 1×1 卷积大规模使用)
- [3. ==Global Average Pooling==](#3. ==Global Average Pooling==)
- [4. 22层深度 + 极低参数量](#4. 22层深度 + 极低参数量)
-
-
- 代码实现
- 项目实例
参考资料
Going Deeper with Convolutions.
背景
在 2014--2015 年,CNN 已经进入"越深越强"的阶段
当时面临的核心问题:网络越深 → 参数暴涨 → 计算量爆炸 → 过拟合风险增大
VGG 19 层参数达到 1.4 亿
GoogLeNet 在 22 层深度下参数量 ≈ 500万
架构(公式)
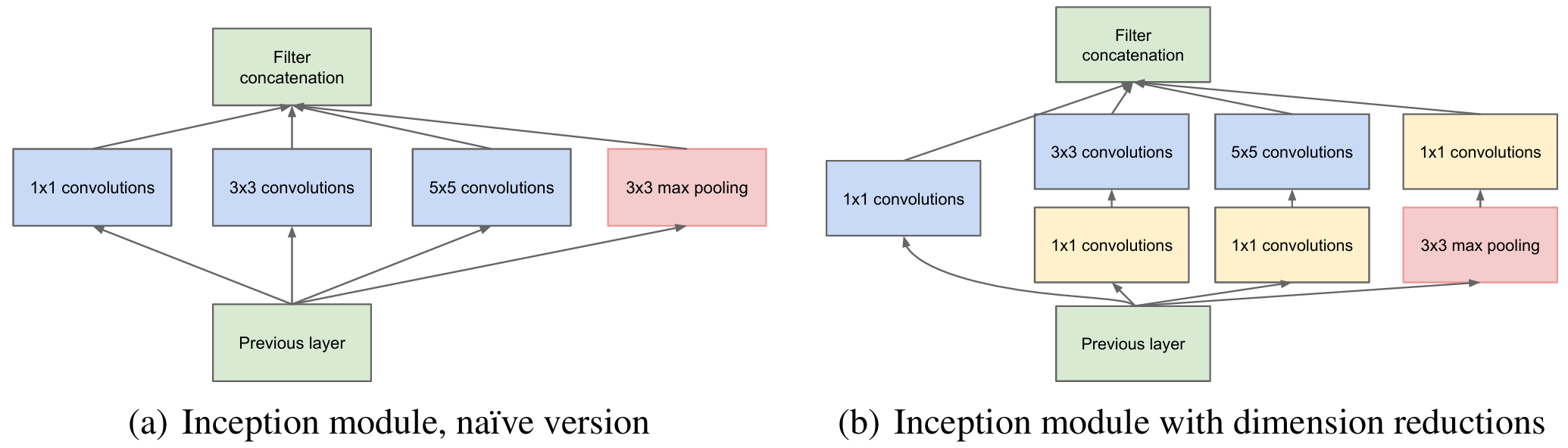
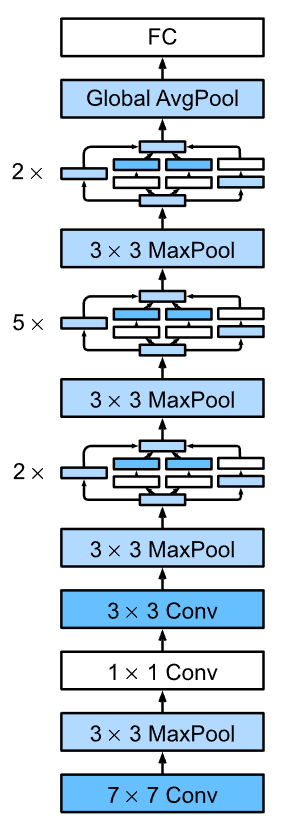
1. Inception v1模块(并行卷积结构)
由GoogLeNet提出, 为v1版本, 后续还有v2版本和v3版本和v4版本
整体网络由多个 Inception block 堆叠而成
Conv → MaxPool
→ Inception × 9
→ Global Average Pooling
→ Linear
→ Softmax一个 Inception 包含 4 条并行路径:
4条并行路径:
1×1 Conv
1×1 Conv → 3×3 Conv
1×1 Conv → 5×5 Conv
3×3 MaxPool → 1×1 Conv
最后(沿通道维拼接):
Concat2. 1×1 卷积的作用
1×1 卷积: Y = W X Y = W X Y=WX
本质:
- 通道间线性组合
- 降维
- 减少计算量
3. 辅助分类器
GoogLeNet 在中间层加入两个辅助输出
训练时: L o s s = L m a i n + 0.3 L a u x 1 + 0.3 L a u x 2 Loss = L_{main} + 0.3L_{aux1} + 0.3L_{aux2} Loss=Lmain+0.3Laux1+0.3Laux2, 测试时丢弃
作用:
- 防止梯度消失
- 起到正则化作用
创新点
1. 并行结构(Multi-branch)
第一次系统性引入==同层多尺度特征提取==
之前 CNN 是串行结构
2. 1×1 卷积大规模使用
降低维度 + 提升非线性表达能力
3. Global Average Pooling
代替全连接层: F C → G A P FC → GAP FC→GAP
优点:
- 参数更少
- 不易过拟合
4. 22层深度 + 极低参数量
| 模型 | 参数量 |
|---|---|
| AlexNet | 6200万 |
| VGG16 | 1.38亿 |
| GoogLeNet | 700万 |
代码实现
py
import torch
import torch.nn as nn
import torch.nn.functional as F
from byzh.ai.Butils import b_get_params
# -------------------------
# Basic Conv Block: Conv -> ReLU
# (Inception v1 原论文没有 BN,这里也不加 BN,保持论文风格)
# -------------------------
class BasicConv2d(nn.Module):
def __init__(self, in_ch, out_ch, kernel_size, stride=1, padding=0):
super().__init__()
self.conv = nn.Conv2d(
in_ch, out_ch,
kernel_size=kernel_size,stride=stride, padding=padding, bias=True
)
def forward(self, x):
x = self.conv(x)
x = F.relu(x)
return x
# -------------------------
# Inception Module (v1)
# branch1: 1x1
# branch2: 1x1 -> 3x3
# branch3: 1x1 -> 5x5
# branch4: 3x3 maxpool -> 1x1
# -------------------------
class Inception(nn.Module):
def __init__(self, in_ch, c1, c3r, c3, c5r, c5, pool_proj):
super().__init__()
self.branch1 = BasicConv2d(in_ch, c1, kernel_size=1)
self.branch2 = nn.Sequential(
BasicConv2d(in_ch, c3r, kernel_size=1),
BasicConv2d(c3r, c3, kernel_size=3, padding=1),
)
self.branch3 = nn.Sequential(
BasicConv2d(in_ch, c5r, kernel_size=1),
BasicConv2d(c5r, c5, kernel_size=5, padding=2),
)
self.branch4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=1, padding=1),
BasicConv2d(in_ch, pool_proj, kernel_size=1),
)
def forward(self, x):
y1 = self.branch1(x)
y2 = self.branch2(x)
y3 = self.branch3(x)
y4 = self.branch4(x)
output = torch.cat([y1, y2, y3, y4], dim=1)
return output
# -------------------------
# Auxiliary Classifier (Inception v1)
# 原论文:AvgPool(5x5, s=3) -> 1x1 conv(128) -> FC(1024) -> Dropout(0.7) -> FC(num_classes)
# 论文里 FC 前通常 flatten 后接线性层(输入维度依赖输入分辨率)
# 对 224 输入,经过该 AvgPool 通常得到 4x4 特征图
# -------------------------
class InceptionAux(nn.Module):
def __init__(self, in_ch, num_classes):
super().__init__()
self.avgpool = nn.AvgPool2d(kernel_size=5, stride=3)
self.conv = BasicConv2d(in_ch, 128, kernel_size=1)
# 224 输入时:这里一般是 128 x 4 x 4 = 2048
self.fc1 = nn.Linear(128 * 4 * 4, 1024)
self.dropout = nn.Dropout(p=0.7)
self.fc2 = nn.Linear(1024, num_classes)
def forward(self, x):
x = self.avgpool(x)
x = self.conv(x)
x = torch.flatten(x, 1)
x = F.relu(self.fc1(x), inplace=True)
x = self.dropout(x)
x = self.fc2(x)
return x
# -------------------------
# GoogLeNet / Inception v1 (2014)
# stage naming aligns with论文:3a,3b,4a,4b,4c,4d,4e,5a,5b
# -------------------------
class B_GoogLeNet_Paper(nn.Module):
def __init__(self, num_classes=1000, aux_logits=False):
"""
:param num_classes: 分类数
:param aux_logits: 控制 GoogLeNet 论文里的两个"辅助分类器(auxiliary classifiers)" 要不要启用
"""
super().__init__()
self.aux_logits = aux_logits
# --- Stem (论文结构) ---
self.conv1 = BasicConv2d(3, 64, kernel_size=7, stride=2, padding=3)
self.maxpool1 = nn.MaxPool2d(3, stride=2, padding=1)
self.conv2 = BasicConv2d(64, 64, kernel_size=1)
self.conv3 = BasicConv2d(64, 192, kernel_size=3, padding=1)
self.maxpool2 = nn.MaxPool2d(3, stride=2, padding=1)
# --- Inception 3 ---
self.inception3a = Inception(192, 64, 96, 128, 16, 32, 32) # out 256
self.inception3b = Inception(256, 128, 128, 192, 32, 96, 64) # out 480
self.maxpool3 = nn.MaxPool2d(3, stride=2, padding=1)
# --- Inception 4 ---
self.inception4a = Inception(480, 192, 96, 208, 16, 48, 64) # out 512
self.inception4b = Inception(512, 160, 112, 224, 24, 64, 64) # out 512
self.inception4c = Inception(512, 128, 128, 256, 24, 64, 64) # out 512
self.inception4d = Inception(512, 112, 144, 288, 32, 64, 64) # out 528
self.inception4e = Inception(528, 256, 160, 320, 32, 128, 128) # out 832
self.maxpool4 = nn.MaxPool2d(3, stride=2, padding=1)
# --- Inception 5 ---
self.inception5a = Inception(832, 256, 160, 320, 32, 128, 128) # out 832
self.inception5b = Inception(832, 384, 192, 384, 48, 128, 128) # out 1024
# --- Aux classifiers ---
if aux_logits:
self.aux1 = InceptionAux(512, num_classes) # from inception4a output
self.aux2 = InceptionAux(528, num_classes) # from inception4d output
else:
self.aux1 = None
self.aux2 = None
# --- Head ---
self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) # GAP
self.dropout = nn.Dropout(p=0.4) # 论文主分支常用 dropout
self.fc = nn.Linear(1024, num_classes)
def forward(self, x):
# Stem
x = self.conv1(x)
x = self.maxpool1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.maxpool2(x)
# Inception 3
x = self.inception3a(x)
x = self.inception3b(x)
x = self.maxpool3(x)
# Inception 4
x = self.inception4a(x)
aux1 = self.aux1(x) if (self.training and self.aux_logits) else None
x = self.inception4b(x)
x = self.inception4c(x)
x = self.inception4d(x)
aux2 = self.aux2(x) if (self.training and self.aux_logits) else None
x = self.inception4e(x)
x = self.maxpool4(x)
# Inception 5
x = self.inception5a(x)
x = self.inception5b(x)
# Head
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.dropout(x)
out = self.fc(x)
if self.training and self.aux_logits:
return out, aux1, aux2
return out
if __name__ == '__main__':
# 测试不带辅助分类器的 GoogLeNet 模型
net = B_GoogLeNet_Paper(num_classes=1000)
a = torch.randn(50, 3, 224, 224)
result = net(a)
print(result.shape)
print(f"参数量: {b_get_params(net)}") # 6_998_552
# 测试带辅助分类器的 GoogLeNet 模型
net = B_GoogLeNet_Paper(num_classes=1000, aux_logits=True)
a = torch.randn(50, 3, 224, 224)
result = net(a)[0]
print(result.shape)
print(f"参数量: {b_get_params(net)}") # 13_378_280项目实例
库环境:
numpy==1.26.4
torch==2.2.2cu121
byzh-core==0.0.9.21
byzh-ai==0.0.9.53
byzh-extra==0.0.9.12
...GoogLeNet训练MNIST数据集:
py
# copy all the codes from here to run
import torch
import torch.nn.functional as F
from uploadToPypi_ai.byzh.ai.Bdata import b_stratified_indices
from byzh.ai.Btrainer import B_Classification_Trainer
from byzh.ai.Bdata import B_Download_MNIST, b_get_dataloader_from_tensor
# from uploadToPypi_ai.byzh.ai.Bmodel.study_cnn import B_GoogLeNet_Paper
from byzh.ai.Bmodel.study_cnn import B_GoogLeNet_Paper
from byzh.ai.Butils import b_get_device
##### hyper params #####
epochs = 10
lr = 1e-3
batch_size = 32
device = b_get_device(use_idle_gpu=True)
##### data #####
downloader = B_Download_MNIST(save_dir='D:/study_cnn/datasets/MNIST')
data_dict = downloader.get_data()
X_train = data_dict['X_train_standard']
y_train = data_dict['y_train']
X_test = data_dict['X_test_standard']
y_test = data_dict['y_test']
num_classes = data_dict['num_classes']
num_samples = data_dict['num_samples']
indices = b_stratified_indices(y_train, num_samples//5)
X_train = X_train[indices]
X_train = F.interpolate(X_train, size=(224, 224), mode='bilinear')
X_train = X_train.repeat(1, 3, 1, 1)
y_train = y_train[indices]
indices = b_stratified_indices(y_test, num_samples//5)
X_test = X_test[indices]
X_test = F.interpolate(X_test, size=(224, 224), mode='bilinear')
X_test = X_test.repeat(1, 3, 1, 1)
y_test = y_test[indices]
train_dataloader, val_dataloader = b_get_dataloader_from_tensor(
X_train, y_train, X_test, y_test,
batch_size=batch_size
)
##### model #####
model = B_GoogLeNet_Paper(num_classes=num_classes)
##### else #####
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
criterion = torch.nn.CrossEntropyLoss()
##### trainer #####
trainer = B_Classification_Trainer(
model=model,
optimizer=optimizer,
criterion=criterion,
train_loader=train_dataloader,
val_loader=val_dataloader,
device=device
)
trainer.set_writer1('./runs/googlenet/log.txt')
##### run #####
trainer.train_eval_s(epochs=epochs)
##### calculate #####
trainer.draw_loss_acc('./runs/googlenet/loss_acc.png', y_lim=False)
trainer.save_best_checkpoint('./runs/googlenet/best_checkpoint.pth')
trainer.calculate_model()