第三章 RNN及其变体
1 认识RNN模型
【根据RNN内部结构,可以分为哪几类】
- 定义
properties
循环神经网络:一般接受的一序列进行输入,输出也是一个序列- 作用和应用场景
properties
RNN擅长处理连续语言文本,机器翻译、文本生成、文本分类、摘要生成-
RNN模型的分类
- 根据输入与输出结构
propertiesN Vs N : 输入和输出等长,应用场景:对联生成;词性标注;NER N Vs 1 : 输入N,输出为单值,应用场景:文本分类 1 Vs N : 输入是一个,输出为N,应用场景:图片文本生成 N Vs M : 输入和输出不等长,应用场景:文本翻译、摘要总结- 根据RNN内部结构
properties传统RNN LSTM BI-LSTM GRU BI-GRU
2 传统RNN模型
【传统RNN的工作原理是什么】
【激活函数tanh的作用是什么】
【nn.RNN初始化主要参数有哪几个】
【RNN的输入input、h0每一维度表示什么意义】
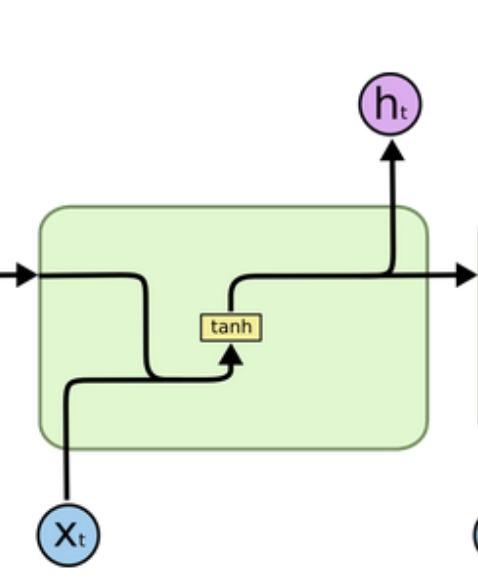
2.1 内部结构
- 输入:当前时间步xt和上一时间步输出的ht-1
- 输出:ht和ot (一个时间步内:ht=ot)
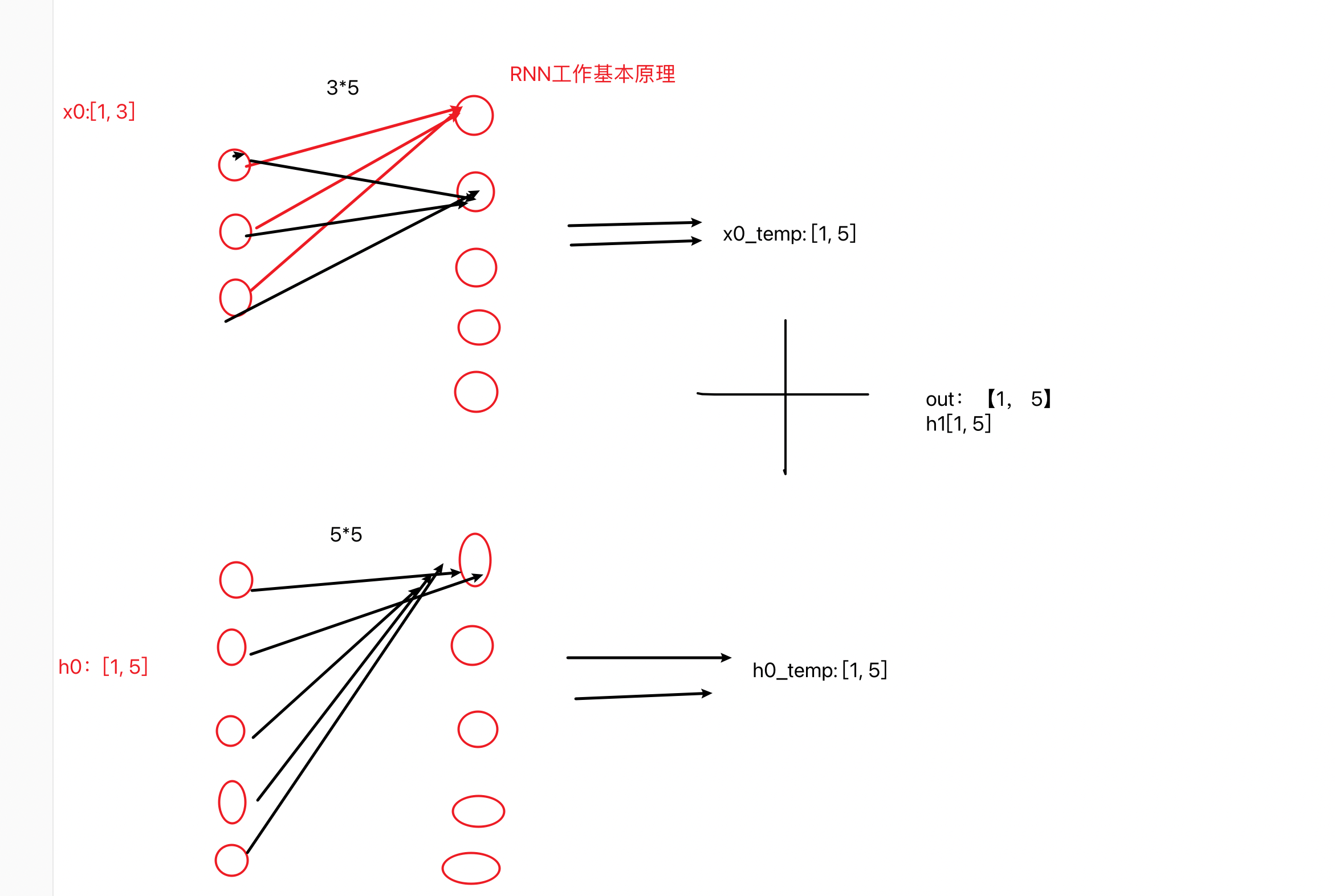
-
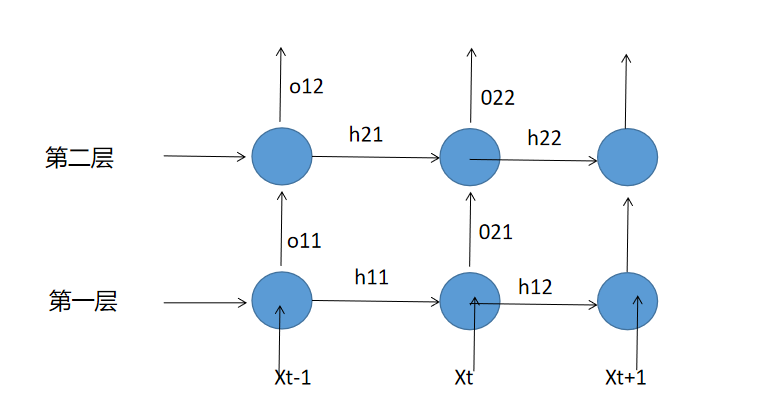
多层RNN的解析
-
RNN模型实现
python# 输入数据长度发生变化 def dm_rnn_for_sequencelen(): ''' 第一个参数:input_size(输入张量x的维度) 第二个参数:hidden_size(隐藏层的维度, 隐藏层的神经元个数) 第三个参数:num_layer(隐藏层的数量) ''' rnn = nn.RNN(5, 6, 1) #A ''' 第一个参数:sequence_length(输入序列的长度) 第二个参数:batch_size(批次的样本数量) 第三个参数:input_size(输入张量的维度) ''' input = torch.randn(20, 3, 5) #B ''' 第一个参数:num_layer * num_directions(层数*网络方向) 第二个参数:batch_size(批次的样本数) 第三个参数:hidden_size(隐藏层的维度, 隐藏层神经元的个数) ''' h0 = torch.randn(1, 3, 6) # C # [20,3,5],[1,3,6] --->[20,3,6],[1,3,6] output, hn = rnn(input, h0) print('output--->', output.shape) print('hn--->', hn.shape) print('rnn模型--->', rnn) # 程序运行效果如下: output---> torch.Size([20, 3, 6]) hn---> torch.Size([1, 3, 6]) rnn模型---> RNN(5, 6)
3 LSTM模型
【介绍一下LSTM的结构】
【什么是BiLSTM】
【LSTM的优缺点是什么】
【如何调用双向LSTM】
3.1 内部结构
- 遗忘门
- 输入门
- 细胞状态
- 输出门
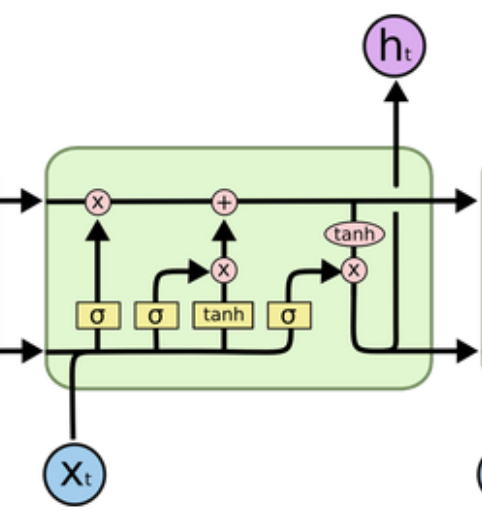
-
LSTM模型代码实现
pythonimport torch import torch.nn as nn def dm02_lstm_for_direction(): ''' 第一个参数:input_size(输入张量x的维度) 第二个参数:hidden_size(隐藏层的维度, 隐藏层的神经元个数) 第三个参数:num_layer(隐藏层的数量) bidirectional = True # ''' lstm = nn.LSTM(5, 6, 1, batch_first = True) ''' input 第一个参数:batch_size(批次的样本数量) 第二个参数:sequence_length(输入序列的长度) 第三个参数:input_size(输入张量的维度) ''' input = torch.randn(4, 10, 5) ''' hn和cn 第一个参数:num_layer * num_directions(层数*网络方向) 第二个参数:batch_size(批次的样本数) 第三个参数:hidden_size(隐藏层的维度, 隐藏层神经元的个数) ''' h0 = torch.zeros(1, 4, 6) c0 = torch.zeros(1, 4, 6) # 数据送入模型 output, (hn, cn) = lstm(input, (h0, c0)) print(f'output-->{output.shape}') print(f'hn-->{hn.shape}') print(f'cn-->{cn.shape}') -
BI-LSTM
properties
定义: 不改变原始的LSTM模型内部结构,只是将文本从左到右计算一遍,再从右到左计算一遍,把最终的输出结果拼接得到模型的完整输出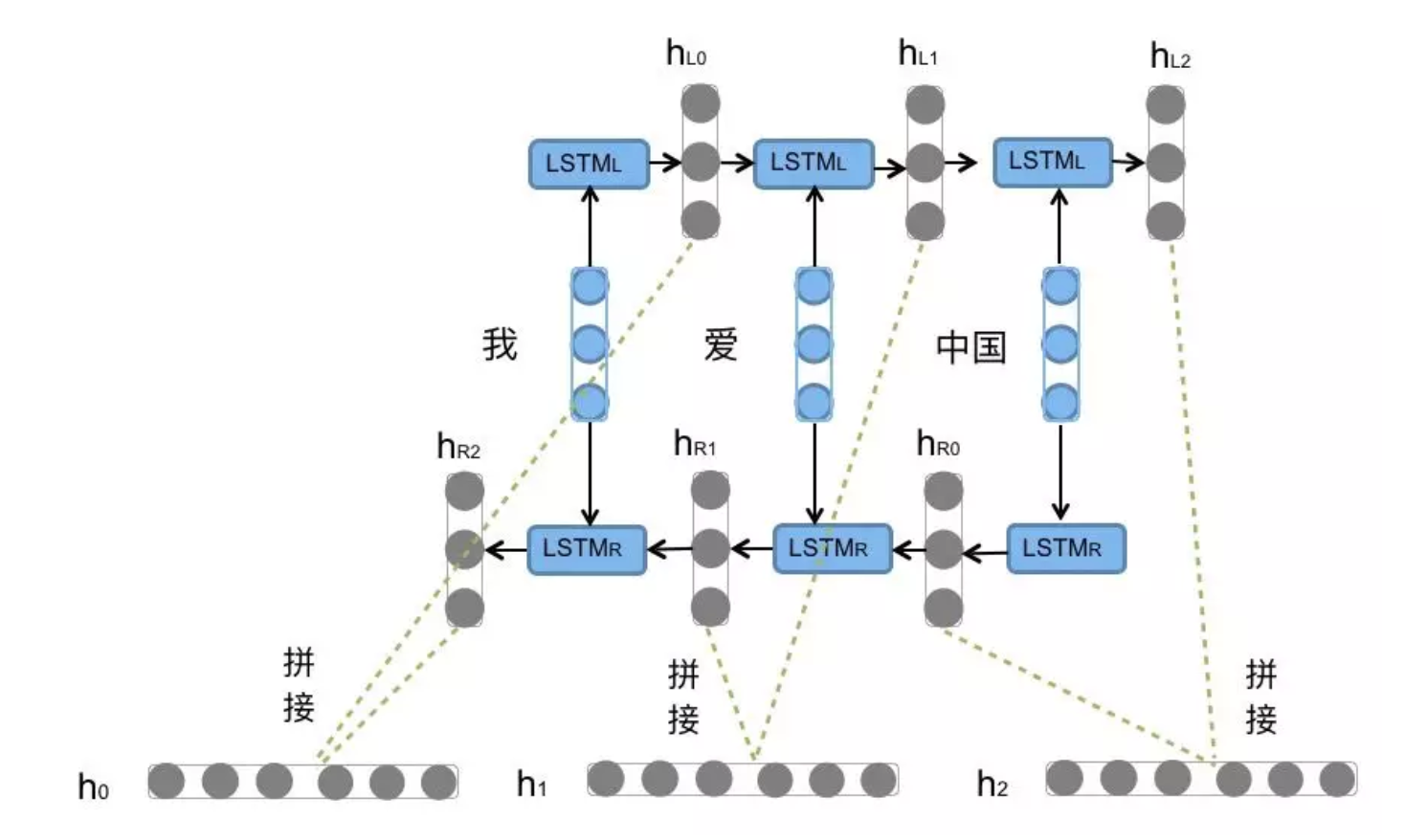
4 GRU模型
【介绍一下GRU结构】
【GRU有什么优势】
【如何调用GRU】
4.1 内部结构
- 更新门
- 重制门
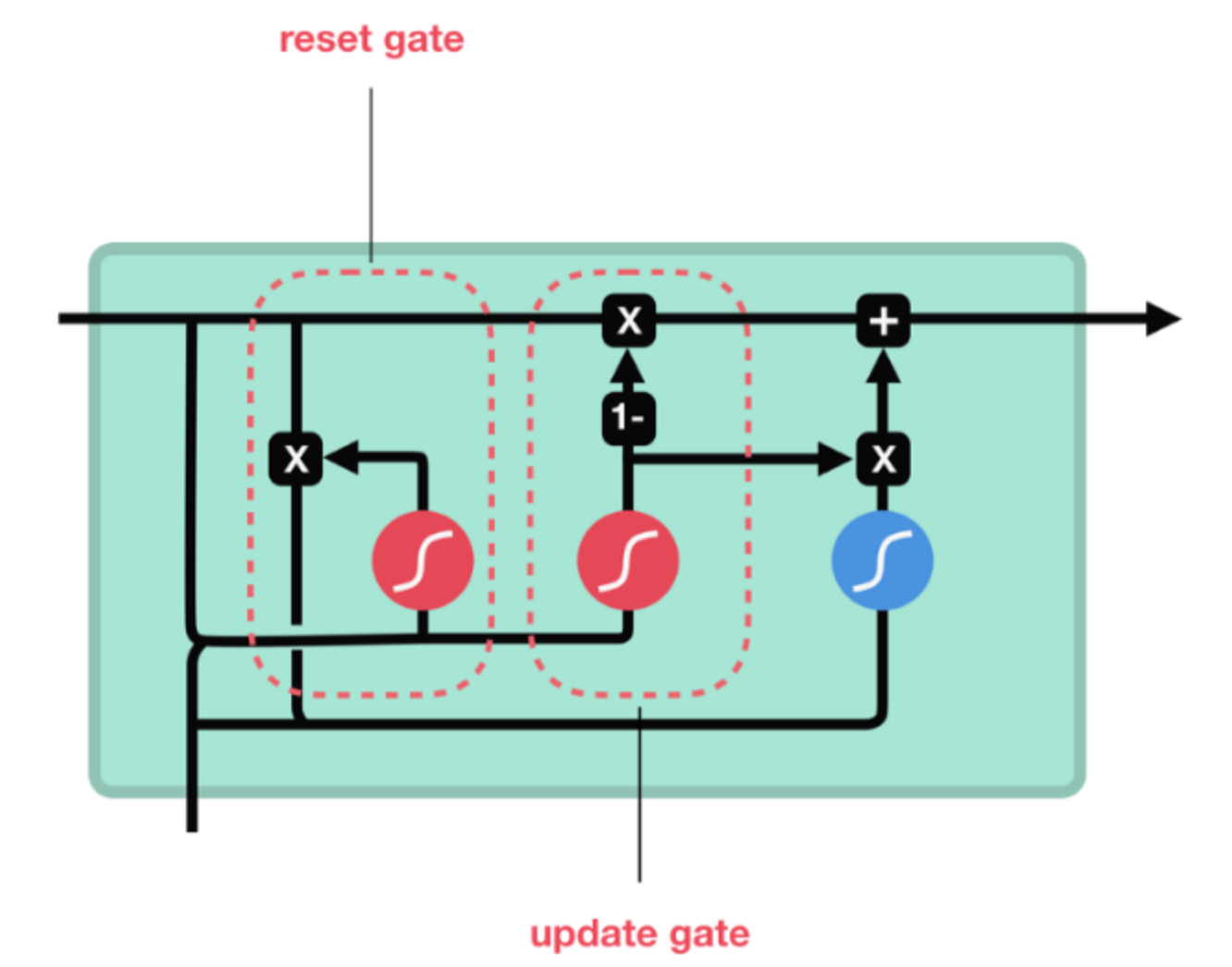
-
GRU模型代码实现
python# coding:utf-8 import torch import torch.nn as nn # 模型参数发生变化对其他输入参数的影响 def dm01_gru_(): ''' 第一个参数:input_size(输入张量x的维度) 第二个参数:hidden_size(隐藏层的维度, 隐藏层的神经元个数) 第三个参数:num_layer(隐藏层的数量) # batch_first = True,代表batch_size 放在第一位 ''' gru = nn.GRU(5, 6, 1, batch_first=True) print(gru.all_weights) print(gru.all_weights[0][0].shape) print(gru.all_weights[0][1].shape) ''' 第一个参数:batch_size(批次的样本数量) 第二个参数:sequence_length(输入序列的长度) 第三个参数:input_size(输入张量的维度) ''' input = torch.randn(4, 3, 5) ''' 第一个参数:num_layer * num_directions(层数*网络方向) 第二个参数:batch_size(批次的样本数) 第三个参数:hidden_size(隐藏层的维度, 隐藏层神经元的个数) ''' h0 = torch.randn(1, 4, 6) # 将数据送入模型得到结果 output, hn = gru(input, h0) print(f'output--》{output}') print(f'hn--》{hn}') if __name__ == '__main__': dm01_gru_() -
Bi-GRU
properties
定义: 不改变原始的GRU模型内部结构,只是将文本从左到右计算一遍,再从右到左计算一遍,把最终的输出结果拼接得到模型的完整输出- 优缺点
- 优点:相比LSTM,结构较为简单,能够和lstm一样缓解梯度消失问题
- 缺点:RNN系列模型不能实现并行运算,数据量大的话,效率比较低
5 RNN案例 人名分类器
5.1 案例介绍
- 任务目的
properties
目的: 给定一个人名,来判定这个人名属于哪个国家
典型的文本分类任务: 18分类---多分类任务-
数据格式
-
注意:两列数据,第一列是人名,第二列是国家类别,中间用制表符号"\t"隔开
properties
Ang Chinese
AuYong Chinese
Yuasa Japanese
Yuhara Japanese
Yunokawa Japanese5.2 案例步骤
properties
1. 获取数据:案例中是直接给定的
2. 数据预处理: 脏数据清洗、数据格式转换、数据源Dataset的构造、数据迭代器Dataloader的构造
3. 模型搭建: RNN、LSTM、GRU一系列模型
4. 模型评估(测试)
5. 模型上线--API接口(1)数据预处理
- 读取txt文档数据
目的
properties
将文档里面的数据读取到内存中,实际上我们做了一个操作: 将人名存放到一个列表中,国家类别存放到一个类别中代码实现
python
def read_data(filename):
# 1. 初始化两个空列表
my_list_x, my_list_y = [], []
# 2. 读取文件内容
with open(filename,'r', encoding='utf-8') as fr:
for line in fr.readlines():
if len(line) <= 5:
continue
# strip()方法默认将字符串首尾两端的空白去掉
x, y = line.strip().split('\t')
my_list_x.append(x)
my_list_y.append(y)
return my_list_x, my_list_y- 构建DataSet
目的
properties
使用Pytorch框架,一般遵从一个规矩:使用DataSet方法构造数据源,来让模型进行使用
构造数据源的过程中:必须继承torch.utils.data.Dataset类,必须构造两个魔法方法:__len__(), __getitem__()
__len__(): 一般返回的是样本的总个数,我们可以直接len(dataset对象)直接就可以获得结果
__getitem__(): 可以根据某个索引取出样本值,我们可以直接用dataset对象[index]来直接获得结果代码实现
python
class NameClassDataset(Dataset):
def __init__(self, mylist_x, mylist_y):
self.mylist_x = mylist_x
self.mylist_y = mylist_y
self.sample_len = len(mylist_x)
# 定义魔法方法len
def __len__(self):
return self.sample_len
# 定义魔法方法getitem
def __getitem__(self, index):
# 1.index异常值处理
index = min(max(index, 0), self.sample_len - 1)
# 2. 根据index取出人名和国家名
x = self.mylist_x[index]
# print(f'x--->{x}')
y = self.mylist_y[index]
# print(f'y--->{y}')
# 3.需要对人名进行one-hot编码表示:这里的思路是:针对每个人名组成的单词进行one-hot,然后再拼接
tensor_x = torch.zeros(len(x), n_letter)
# print(f'tensor_x-->{tensor_x}')
for li, letter in enumerate(x):
tensor_x[li][all_letters.find(letter)] = 1
# 4.获取标签
# print(f'dataset内部的tensor_x--》{tensor_x.shape}')
tensor_y = torch.tensor(categorys.index(y), dtype=torch.long)
# print(f'dataset内部的tensor_y-->{tensor_y}')
return tensor_x, tensor_y- 构建Dataloader
目的
properties
为了将Dataset我们上一步构建的数据源,进行再次封装,变成一个迭代器,可以进行for循环,而且,可以自动为我们dataset里面的数据进行增维(bath_size),也可以随机打乱我们的取值顺序代码实现
python
filename = './data/name_classfication.txt'
my_list_x, my_list_y = read_data(filename)
mydataset = NameClassDataset(mylist_x=my_list_x, mylist_y=my_list_y)
my_dataloader = DataLoader(dataset=mydataset, batch_size=1, shuffle=True)(2)模型搭建
搭建RNN模型
- 注意事项
properties
RNN模型在实例化的时候,默认batch_first=False,因此,需要小心输入数据的形状
因为: dataloader返回的结果x---》shape--〉[batch_size, seq_len, input_size], 所以课堂上代码和讲义稍微有点不同,讲义是默认的batch_first=False,而我们的代码是batch_first=True,这样做的目的,可以直接承接x的输入。- 代码实现
python
class MyRNN(nn.Module):
def __init__(self, input_size, hidden_size, ouput_size, num_layers=1):
super().__init__()
# input_size 代表词嵌入维度;
self.input_size = input_size
# hidden_size代表RNN隐藏层维度
self.hidden_size = hidden_size
# output_size代表:国家种类个数
self.ouput_size = ouput_size
self.num_layers = num_layers
# 定义RNN网络层
# 和讲义不一样,我设定了batch_first=True,意味着rnn接受的input第一个参数是batch_size
self.rnn = nn.RNN(self.input_size, self.hidden_size,
num_layers=self.num_layers, batch_first=True)
# 定义输出网络层
self.linear = nn.Linear(self.hidden_size, self.ouput_size)
# 定义softmax层
self.softmax = nn.LogSoftmax(dim=-1)
def forward(self, input, hidden):
# input的shape---》[batch_size, seq_len, input_size] [1, 9, 57]
# hidden的shape---》[num_layers, batch_size, hidden_size] [1,1,128]
# 将input和hidden送入RNN模型得到结果rnn_output【1,9,128】,rnn_hn[1,1,128]
rnn_output, rnn_hn = self.rnn(input, hidden)
# print(f'rnn_output--》{rnn_output.shape}')
# temp:[1, 128]
tmep = rnn_output[0][-1].unsqueeze(0)
# print(f'tmep--》{tmep.shape}')
# 将临时tmep:代表当前样本最后一词的隐藏层输出结果[1, 18]
output = self.linear(tmep)
# print(f'output--》{output.shape}')
# 经过softmax
return self.softmax(output), rnn_hn
def inithidden(self):
return torch.zeros(self.num_layers, 1, self.hidden_size)- RNN模型测试
python
def test_RNN():
# 1.得到数据
my_dataloader = get_dataloader()
# 2.实例化模型
input_size = n_letter # 57
hidden_size = 128 # 自定设定RNN模型输出结果维度
output_size = len(categorys) # 18
my_rnn = MyRNN(input_size, hidden_size, output_size)
h0 = my_rnn.inithidden()
# 3.将数据送入模型
for i, (x, y) in enumerate(my_dataloader):
print(f'x--->{x.shape}')
output, hn = my_rnn(input=x, hidden=h0)
print(f'output模型输出结果-->{output.shape}')
print(f'hn-->{hn.shape}')
break搭建LSTM模型
- 注意事项
properties
LSTM模型在实例化的时候,默认batch_first=False,因此,需要小心输入数据的形状
因为: dataloader返回的结果x---》shape--〉[batch_size, seq_len, input_size], 所以课堂上代码和讲义稍微有点不同,讲义是默认的batch_first=False,而我们的代码是batch_first=True,这样做的目的,可以直接承接x的输入。- 代码实现
python
class MyLSTM(nn.Module):
def __init__(self, input_size, hidden_size, ouput_size, num_layers=1):
super().__init__()
# input_size 代表词嵌入维度;
self.input_size = input_size
# hidden_size代表RNN隐藏层维度
self.hidden_size = hidden_size
# output_size代表:国家种类个数
self.ouput_size = ouput_size
self.num_layers = num_layers
# 定义LSTM网络层
# 和讲义不一样,我设定了batch_first=True,意味着rnn接受的input第一个参数是batch_size
self.lstm = nn.LSTM(self.input_size, self.hidden_size,
num_layers=self.num_layers, batch_first=True)
# 定义输出网络层
self.linear = nn.Linear(self.hidden_size, self.ouput_size)
# 定义softmax层
self.softmax = nn.LogSoftmax(dim=-1)
def forward(self, input, hidden, c0):
# input的shape---》[batch_size, seq_len, input_size] [1, 9, 57]
# hidden的shape---》[num_layers, batch_size, hidden_size] [1,1,128]
# 将input和hidden送入RNN模型得到结果rnn_output【1,9,128】,rnn_hn[1,1,128]
lstm_output, (lstm_hn, lstm_cn) = self.lstm(input, (hidden, c0))
# print(f'rnn_output--》{rnn_output.shape}')
# temp:[1, 128]
tmep = lstm_output[0][-1].unsqueeze(0)
# print(f'tmep--》{tmep.shape}')
# 将临时tmep:代表当前样本最后一词的隐藏层输出结果[1, 18]
output = self.linear(tmep)
# print(f'output--》{output.shape}')
# 经过softmax
return self.softmax(output), lstm_hn, lstm_cn
def inithidden(self):
h0 = torch.zeros(self.num_layers, 1, self.hidden_size)
c0 = torch.zeros(self.num_layers, 1, self.hidden_size)
return h0, c0- LSTM测试
python
def test_LSTM():
# 1.得到数据
my_dataloader = get_dataloader()
# 2.实例化模型
input_size = n_letter # 57
hidden_size = 128 # 自定设定LSTM模型输出结果维度
output_size = len(categorys) # 18
my_lstm = MyLSTM(input_size, hidden_size, output_size)
h0, c0 = my_lstm.inithidden()
# 3.将数据送入模型
for i, (x, y) in enumerate(my_dataloader):
print(f'x--->{x.shape}')
output, hn, cn = my_lstm(input=x, hidden=h0, c0=c0)
print(f'output模型输出结果-->{output.shape}')
print(f'hn-->{hn.shape}')
print(f'cn-->{cn.shape}')
break搭建GRU模型
- 注意事项
properties
GRU模型在实例化的时候,默认batch_first=False,因此,需要小心输入数据的形状
因为: dataloader返回的结果x---》shape--〉[batch_size, seq_len, input_size], 所以课堂上代码和讲义稍微有点不同,讲义是默认的batch_first=False,而我们的代码是batch_first=True,这样做的目的,可以直接承接x的输入。- 代码实现
python
class MyGRU(nn.Module):
def __init__(self, input_size, hidden_size, ouput_size, num_layers=1):
super().__init__()
# input_size 代表词嵌入维度;
self.input_size = input_size
# hidden_size代表RNN隐藏层维度
self.hidden_size = hidden_size
# output_size代表:国家种类个数
self.ouput_size = ouput_size
self.num_layers = num_layers
# 定义GRU网络层
# 和讲义不一样,我设定了batch_first=True,意味着rnn接受的input第一个参数是batch_size
self.gru = nn.GRU(self.input_size, self.hidden_size,
num_layers=self.num_layers, batch_first=True)
# 定义输出网络层
self.linear = nn.Linear(self.hidden_size, self.ouput_size)
# 定义softmax层
self.softmax = nn.LogSoftmax(dim=-1)
def forward(self, input, hidden):
# input的shape---》[batch_size, seq_len, input_size] [1, 9, 57]
# hidden的shape---》[num_layers, batch_size, hidden_size] [1,1,128]
# 将input和hidden送入RNN模型得到结果rnn_output【1,9,128】,rnn_hn[1,1,128]
gru_output, gru_hn = self.gru(input, hidden)
# print(f'rnn_output--》{rnn_output.shape}')
# temp:[1, 128]
tmep = gru_output[0][-1].unsqueeze(0)
# print(f'tmep--》{tmep.shape}')
# 将临时tmep:代表当前样本最后一词的隐藏层输出结果[1, 18]
output = self.linear(tmep)
# print(f'output--》{output.shape}')
# 经过softmax
return self.softmax(output), gru_hn
def inithidden(self):
return torch.zeros(self.num_layers, 1, self.hidden_size)- GRU测试
python
def test_GRU():
# 1.得到数据
my_dataloader = get_dataloader()
# 2.实例化模型
input_size = n_letter # 57
hidden_size = 128 # 自定设定RNN模型输出结果维度
output_size = len(categorys) # 18
my_gru = MyGRU(input_size, hidden_size, output_size)
# 2.1 初始化参数
h0 = my_gru.inithidden()
# 3.将数据送入模型
for i, (x, y) in enumerate(my_dataloader):
print(f'x--->{x.shape}')
output, hn = my_gru(input=x, hidden=h0)
print(f'output模型输出结果-->{output.shape}')
print(f'hn-->{hn.shape}')
break5.3 模型训练
- 基本过程
properties
1.获取数据
2.构建数据源Dataset
3.构建数据迭代器Dataloader
4.加载自定义的模型
5.实例化损失函数对象
6.实例化优化器对象
7.定义打印日志参数
8.开始训练
8.1 实现外层大循环epoch
(可以在这构建数据迭代器Dataloader)
8.2 内部遍历数据迭代球dataloader
8.3 将数据送入模型得到输出结果
8.4 计算损失
8.5 梯度清零: optimizer.zero_grad()
8.6 反向传播: loss.backward()
8.7 参数更新(梯度更新): optimizer.step()
8.8 打印训练日志
9. 保存模型: torch.save(model.state_dict(), "model_path")- 代码实现
python
# 思路分析
# a 从文件获取数据、实例化数据源对象nameclassdataset 数据迭代器对象mydataloader
# b 实例化模型对象my_rnn 损失函数对象mycrossentropyloss=nn.NLLLoss() 优化器对象myadam
# c 定义模型训练的参数
# starttime total_iter_num total_loss total_loss_list total_acc_num total_acc_list
# d 外层for循环 控制轮数 for epoch_idx in range(epochs)
# e 内层for循环 控制迭代次数 for i, (x, y) in enumerate(mydataloader)
# 给模型喂数据 # 计算损失 # 梯度清零 # 反向传播 # 梯度更新
# 计算辅助信息 # 累加总损失和准确数 每100次训练计算一个总体平均损失 总体平均准确率 每2000次训练 打印日志
# 其他 # 预测对错 i_predit_tag = (1 if torch.argmax(output).item() == y.item() else 0)
# f 模型保存
# torch.save(my_rnn.state_dict(), './my_rnn_model_%d.bin' % (epoch_idx + 1))
# g 返回平均损失列表total_loss_list, 时间total_time, 平均准确total_acc_list
# 定义全局变量
epochs = 1
my_lr = 1e-3
# 9.RNN模型训练函数
def train_my_rnn():
# 1. 读取数据
my_list_x, my_list_y = read_data(filename='./data/name_classfication.txt')
# 2. 实例化自己定义的Dataset
myDataset = NameClassDataset(mylist_x=my_list_x, mylist_y=my_list_y)
# 3. 实例化自己的Dataloader
my_dataloader = DataLoader(dataset=myDataset, batch_size=1, shuffle=True)
# 4. 实例化自己定义的RNN模型
# 4.1 定义参数
input_size = 57 # n_letters
hidden_size = 128
output_size = 18 # 国家类别
my_rnn = MyRNN(input_size, hidden_size, output_size)
# 5. 实例化损失函数对象
my_crossentropy = nn.NLLLoss()
# 6. 实例化优化器
my_optimizer = optim.Adam(my_rnn.parameters(), lr=my_lr)
# 7. 设置训练的打印日志参数
start_time = time.time() # 开始的时间
total_iter_num = 0 # 已经训练好的样本数
total_loss = 0 # 已经训练的总损失
total_loss_list = [] # 每隔100步存储一下平均损失
total_acc_num = 0 # 已经训练的样本数预测正确的样本
total_acc_list = [] # 每隔100步存储一下平均准确率
# 8.开始训练
# 8.1 外层for训练(epochs迭代多少轮)
for epoch_idx in range(epochs):
# 8.2 内部数据开始迭代(一个epoch)
for i, (x, y) in enumerate(tqdm(my_dataloader)):
# 8.3 将x送入模型(自己定义的模型)
# 初始化一个h0
h0 = my_rnn.inithidden()
output, hn = my_rnn(input=x, hidden=h0)
# print(f'output--》模型的输出结果:{output}')
# print(f'y--》真实的样本结果:{y}')
# 8.4 将output模型预测结果和真实的y做损失计算
my_loss = my_crossentropy(output, y)
# print(f'模型的损失--》{my_loss}')
# 8.5 梯度清零
my_optimizer.zero_grad()
# 8.6 反向传播
my_loss.backward()
# 8.7 梯度更新
my_optimizer.step()
# 打印日志的参数
total_iter_num += 1 # 计数
total_loss += my_loss.item() # 累计损失值
item1 = 1 if torch.argmax(output, dim=-1).item() == y.item() else 0
total_acc_num += item1 # 累计正确样本的个数
# 每隔100步存储一下平均损失和准确率
if total_iter_num % 100 == 0:
# 保存平均损失
loss_avg = total_loss / total_iter_num
total_loss_list.append(loss_avg)
# 保存平均准确率
acc_avg = total_acc_num / total_iter_num
total_acc_list.append(acc_avg)
if total_iter_num % 2000 == 0:
loss_avg = total_loss / total_iter_num
acc_avg = total_acc_num / total_iter_num
end_time = time.time()
use_time = end_time - start_time
print("当前训练的批次: %d,平均损失: %.5f, 训练时间: %.3f, 准确率: %.2f" % (
epoch_idx + 1,
loss_avg,
use_time,
acc_avg
))
# 9. 保存模型
torch.save(my_rnn.state_dict(), "model/my_rnn.bin")
# 结束
all_time = time.time() - start_time
return total_loss_list, all_time, total_acc_list
# 10.将模型结果保存,方便下次读取
def save_rnn_results():
# 1.训练模型得到需要的结果
total_loss_list, all_time, total_acc_list = train_my_rnn()
# total_loss_list, all_time, total_acc_list = train_my_lstm()
# total_loss_list, all_time, total_acc_list = train_my_gru()
# 2. 定义一个字典
dict1 = {"loss": total_loss_list,
"time": all_time,
"acc": total_acc_list}
# 3. 保存到一个json格式的文件
with open("./data/rnn_result.json", "w") as fw:
fw.write(json.dumps(dict1))
# 11.读取json文件内容
def read_json(json_path):
with open(json_path, "r") as fr:
results = json.load(fr)
return results
# 12.LSTM模型训练函数
def train_my_lstm():
# 1. 读取数据
my_list_x, my_list_y = read_data(filename='./data/name_classfication.txt')
# 2. 实例化自己定义的Dataset
myDataset = NameClassDataset(mylist_x=my_list_x, mylist_y=my_list_y)
# 3. 实例化自己的Dataloader
my_dataloader = DataLoader(dataset=myDataset, batch_size=1, shuffle=True)
# 4. 实例化自己定义的RNN模型
# 4.1 定义参数
input_size = 57 # n_letters
hidden_size = 128
ouput_size = 18 # 国家类别
my_lstm = MyLSTM(input_size, hidden_size, ouput_size)
# 5. 实例化损失函数对象
my_crossentropy = nn.NLLLoss()
# 6. 实例化优化器
my_optimizer = optim.Adam(my_lstm.parameters(), lr=my_lr)
# 7. 设置训练的打印日志参数
start_time = time.time() # 开始的时间
total_iter_num = 0 # 已经训练好的样本数
total_loss = 0 # 已经训练的总损失
total_loss_list = [] # 每隔100步存储一下平均损失
total_acc_num = 0 # 已经训练的样本数预测正确的样本
total_acc_list = [] # 每隔100步存储一下平均准确率
# 8.开始训练
# 8.1 外层for训练(epochs迭代多少轮)
for epoch_idx in range(epochs):
# 8.2 内部数据开始迭代(一个epoch)
for i, (x, y) in enumerate(tqdm(my_dataloader)):
# 8.3 将x送入模型(自己定义的模型)
# 初始化一个h0, c0
h0, c0 = my_lstm.inithidden()
output, hn, cn = my_lstm(input=x, hidden=h0, c0=c0)
# print(f'output--》模型的输出结果:{output}')
# print(f'y--》真实的样本结果:{y}')
# 8.4 将output模型预测结果和真实的y做损失计算
my_loss = my_crossentropy(output, y)
# print(f'模型的损失--》{my_loss}')
# 8.5 梯度清零
my_optimizer.zero_grad()
# 8.6 反向传播
my_loss.backward()
# 8.7 梯度更新
my_optimizer.step()
# 打印日志的参数
total_iter_num += 1 # 计数
total_loss += my_loss.item() # 累计损失值
item1 = 1 if torch.argmax(output, dim=-1).item() == y.item() else 0
total_acc_num += item1 # 累计正确样本的个数
# 每隔100步存储一下平均损失和准确率
if total_iter_num % 100 == 0:
# 保存平均损失
loss_avg = total_loss / total_iter_num
total_loss_list.append(loss_avg)
# 保存平均准确率
acc_avg = total_acc_num / total_iter_num
total_acc_list.append(acc_avg)
if total_iter_num % 2000 == 0:
loss_avg = total_loss / total_iter_num
acc_avg = total_acc_num / total_iter_num
end_time = time.time()
use_time = end_time - start_time
print("当前训练的批次: %d,平均损失: %.5f, 训练时间: %.3f, 准确率: %.2f" % (
epoch_idx + 1,
loss_avg,
use_time,
acc_avg
))
# 9. 保存模型
torch.save(my_lstm.state_dict(), "model/my_lstm.bin")
# 结束
all_time = time.time() - start_time
return total_loss_list, all_time, total_acc_list
# 13.GRU模型训练函数
def train_my_gru():
# 1. 读取数据
my_list_x, my_list_y = read_data(filename='./data/name_classfication.txt')
# 2. 实例化自己定义的Dataset
myDataset = NameClassDataset(mylist_x=my_list_x, mylist_y=my_list_y)
# 3. 实例化自己的Dataloader
my_dataloader = DataLoader(dataset=myDataset, batch_size=1, shuffle=True)
# 4. 实例化自己定义的RNN模型
# 4.1 定义参数
input_size = 57 # n_letters
hidden_size = 128
ouput_size = 18 # 国家类别
my_gru = MyGRU(input_size, hidden_size, ouput_size)
# 5. 实例化损失函数对象
my_crossentropy = nn.NLLLoss()
# 6. 实例化优化器
my_optimizer = optim.Adam(my_gru.parameters(), lr=my_lr)
# 7. 设置训练的打印日志参数
start_time = time.time() # 开始的时间
total_iter_num = 0 # 已经训练好的样本数
total_loss = 0 # 已经训练的总损失
total_loss_list = [] # 每隔100步存储一下平均损失
total_acc_num = 0 # 已经训练的样本数预测正确的样本
total_acc_list = [] # 每隔100步存储一下平均准确率
# 8.开始训练
# 8.1 外层for训练(epochs迭代多少轮)
for epoch_idx in range(epochs):
# 8.2 内部数据开始迭代(一个epoch)
for i, (x, y) in enumerate(tqdm(my_dataloader)):
# 8.3 将x送入模型(自己定义的模型)
# 初始化一个h0
h0 = my_gru.inithidden()
output, hn = my_gru(input=x, hidden=h0)
# print(f'output--》模型的输出结果:{output}')
# print(f'y--》真实的样本结果:{y}')
# 8.4 将output模型预测结果和真实的y做损失计算
my_loss = my_crossentropy(output, y)
# print(f'模型的损失--》{my_loss}')
# 8.5 梯度清零
my_optimizer.zero_grad()
# 8.6 反向传播
my_loss.backward()
# 8.7 梯度更新
my_optimizer.step()
# 打印日志的参数
total_iter_num += 1 # 计数
total_loss += my_loss.item() # 累计损失值
item1 = 1 if torch.argmax(output, dim=-1).item() == y.item() else 0
total_acc_num += item1 # 累计正确样本的个数
# 每隔100步存储一下平均损失和准确率
if total_iter_num % 100 == 0:
# 保存平均损失
loss_avg = total_loss / total_iter_num
total_loss_list.append(loss_avg)
# 保存平均准确率
acc_avg = total_acc_num / total_iter_num
total_acc_list.append(acc_avg)
if total_iter_num % 2000 == 0:
loss_avg = total_loss / total_iter_num
acc_avg = total_acc_num / total_iter_num
end_time = time.time()
use_time = end_time - start_time
print("当前训练的批次: %d,平均损失: %.5f, 训练时间: %.3f, 准确率: %.2f" % (
epoch_idx + 1,
loss_avg,
use_time,
acc_avg
))
# 9. 保存模型
torch.save(my_gru.state_dict(), "model/my_gru_%s.bin" % (epoch_idx + 1))
# 结束
all_time = time.time() - start_time
return total_loss_list, all_time, total_acc_list
# 14.画图
def plt_RNN():
# 获取rnn模型的输出结果
rnn_results = read_json(json_path="./data/rnn_result-epoch3.json")
total_loss_list_rnn, all_time_rnn, total_acc_list_rnn = rnn_results["loss"], rnn_results["time"], rnn_results["acc"]
lstm_results = read_json(json_path="./data/lstm_result-epoch3.json")
total_loss_list_lstm, all_time_lstm, total_acc_list_lstm = lstm_results["loss"], lstm_results["time"], lstm_results[
"acc"]
gru_results = read_json(json_path="./data/gru_result-epoch3.json")
total_loss_list_gru, all_time_gru, total_acc_list_gru = gru_results["loss"], gru_results["time"], gru_results["acc"]
# 画出损失对比曲线图
plt.figure(0)
plt.plot(total_loss_list_rnn, label="RNN")
plt.plot(total_loss_list_lstm, color="red", label="LSTM")
plt.plot(total_loss_list_gru, color="orange", label="GRU")
plt.legend(loc="upper left")
plt.savefig('./picture/loss.png')
plt.show()
# 画出时间对比图
plt.figure(1)
x_data = ["RNN", "LSTM", "GRU"]
y_data = [all_time_rnn, all_time_lstm, all_time_gru]
plt.bar(range(len(x_data)), y_data, tick_label=x_data)
plt.savefig("./picture/use_time.png")
plt.show()
# 画出准确率对比曲线图
plt.figure(0)
plt.plot(total_acc_list_rnn, label="RNN")
plt.plot(total_acc_list_lstm, color="red", label="LSTM")
plt.plot(total_acc_list_gru, color="orange", label="GRU")
plt.legend(loc="upper left")
plt.savefig('./picture/acc.png')
plt.show()
# 15. 定义sequence2tensor():
def line2tensor(x):
'''
x :相当于输入的人名"zhang" 需要对它进行one-hot
'''
# 1.初始化一个全零的张量 n_letter=57
tensor_x = torch.zeros(len(x), n_letter)
# 2.进行one-hot张量的表示
for li, letter in enumerate(x):
tensor_x[li][all_letters.find(letter)] = 1
return tensor_x5.4 模型预测
- 基本过程
properties
1.获取数据
2.数据预处理:将数据转化one-hot编码
3.实例化模型
4.加载模型训练好的参数: model.load_state_dict(torch.load("model_path"))
5.with torch.no_grad():
6.将数据送入模型进行预测(注意:张量的形状变换)- 代码实现
python
# 16.实现rnn模型的预测函数
def rnn_predict(x):
'''
x :相当于输入的人名"zhang"
'''
# 1.对x进行one-hot编码
tensor_x = line2tensor(x)
# 2.实例化模型
my_rnn = MyRNN(input_size=57, hidden_size=128, ouput_size=18)
my_rnn.load_state_dict(torch.load("./model/my_rnn.bin"))
# 3.开始预测
with torch.no_grad():
# 将数据送入模型:需要将tensor_x升成3维
input0 = tensor_x.unsqueeze(0)
h0 = my_rnn.inithidden()
# output-->[1, 18]
output, hn = my_rnn(input0, h0)
# print(f'output-->{output}')
# 取出output的最大概率的前三个值
topv, topi = output.topk(3, 1, True)
# print(f'topv-->{topv}')
# print(f'topi-->{topi}')
print("%s这个人名rnn模型的预测结果" % (x))
for i in range(3):
value = topv[0][i]
index = topi[0][i]
category = categorys[index]
print('RNN模型预测的结果:%.2f, 国家类别是%s' % (value, category))
# 17.实现lstm模型的预测函数
def lstm_predict(x):
'''
x :相当于输入的人名"zhang"
'''
# 1.对x进行one-hot编码
tensor_x = line2tensor(x)
# 2. 实例化模型
my_lstm = MyLSTM(input_size=57, hidden_size=128, ouput_size=18)
my_lstm.load_state_dict(torch.load("./model/my_lstm.bin"))
# 3.开始预测
with torch.no_grad():
# 将数据送入模型:需要将tensor_x升成3维
input0 = tensor_x.unsqueeze(0)
h0, c0 = my_lstm.inithidden()
# output-->[1, 18]
output, hn, cn = my_lstm(input0, h0, c0)
# print(f'output-->{output}')
# 取出output的最大概率的前三个值
topv, topi = output.topk(3, 1, True)
# print(f'topv-->{topv}')
# print(f'topi-->{topi}')
print("%s这个人名lstm模型的预测结果" % (x))
for i in range(3):
value = topv[0][i]
index = topi[0][i]
category = categorys[index]
print('LSTM模型预测的结果:%.2f, 国家类别是%s' % (value, category))
# 18.实现rnn模型的预测函数
def gru_predict(x):
'''
x :相当于输入的人名"zhang"
'''
# 1.对x进行one-hot编码
tensor_x = line2tensor(x)
# 2. 实例化模型
my_gru = MyGRU(input_size=57, hidden_size=128, ouput_size=18)
my_gru.load_state_dict(torch.load("./model/my_gru.bin"))
# 3.开始预测
with torch.no_grad():
# 将数据送入模型:需要将tensor_x升成3维
input0 = tensor_x.unsqueeze(0)
h0 = my_gru.inithidden()
# output-->[1, 18]
output, hn = my_gru(input0, h0)
# print(f'output-->{output}')
# 取出output的最大概率的前三个值
'''
output.topk(3, 1, True):这是PyTorch中的一个方法,用于找出给定张量中指定维度上最大的k个元素及其索引。
第一个参数3:这表示我们想要找到每个时间步(或序列的每个元素)上概率最高的3个值。
第二个参数1:这指定了我们要在哪个维度上查找最大的值。在这个上下文中,它通常意味着在输出特征的维度上查找
(即,如果output的形状是(batch_size, num_classes),则1表示在每个batch_size的num_classes中查找最大的3个值)
第三个参数True:这表示我们想要得到最大值的索引,而不仅仅是值本身。
topv:这是包含每个时间步上最大概率的3个值的张量。
topi:这是包含这些最大值对应索引的张量,即每个时间步上概率最高的3个类别的索引。
'''
topv, topi = output.topk(3, 1, True)
print(f'topv-->{topv}')
print(f'topi-->{topi}')
print("%s这个人名gru模型的预测结果" % (x))
for i in range(3):
value = topv[0][i]
index = topi[0][i]
category = categorys[index]
print('GRU模型预测的结果:%.2f, 国家类别是%s' % (value, category))6 注意力机制
【注意力机制分为几类,每类有什么特点】
6.1 注意力机制的由来
properties
引入Attention的原因1: 1、在 Attention 机制引入之前,有一个问题大家一直很苦恼:长距离的信息会被弱化,就好像记忆能力弱的人,记不住过去的事情是一样的。
引入Attention的原因2: 参数少、速度快、效果好
最初场景问题: 文本翻译问题
问题1: 如果翻译的句子很长很复杂,比如直接一篇文章输进去,模型的计算量很大,并且模型的准确率下降严重
问题2: 没有考虑词与词之间的相关性,导致翻译效果比较差6.2 什么是注意力机制
6.3 实例解释Attention
properties
通俗理解注意力机制原理与本质:Q(query)、K(key)、V(value)
- 第一步【查询】:打开京东网站,我们输入查询(query,Q),比如"笔记本"
- 第二步【计算相似性】:京东后台拿到这个查询Q,会用这个查询Q去和后台的所有商品的关键字(或者title)(key, K)一一来对比,找到物品和我们查询的相似性(或者说物品对应的相似性的权重),相似性越高,越可能推送给我们
- 第三步【得到价值】:这个时候我们还需要考虑物品的价值(value, V),这个V不是指物品值几块钱,而是这个物品在算法中的价值。如果商家给了京东广告费,或者商品物美价廉,评论好,点赞高等,那么算法就越有可能把物品排在前面推送给我们
- 第四步【计算带权重的价值】:我们拿刚刚得到的相似性,乘以物品在算法中的价值V,计算结果就是每件物品的最后带有相似性权重的价值,京东最后的算法就是返回这个带权重的价值,也就是把排序好的商品推送给我们
- **【总结】**:这是个典型的注意力过程,它推送在最前面给我们展示的商品,肯定是它最希望获得我们注意力的商品。当然,京东内部的算法肯定不是这样的,但是他们本质原理一样,都是基于注意力,并且我们看到的现象也是一样的。 6.4 Attention概念
properties
"注意力机制"实际上就是想将人的感知方式、注意力的行为应用在机器上,让机器学会去感知数据中的重要和不重要的部分。6.5 注意力机制分类
properties
1、软注意力: 注意力权重值分布在0-1之间,关注所有的词汇,但是不同词汇根据权重大小关注的程度不一样。
2、硬注意力: 注意力权重值是0或者1,只关注哪些重要的部分,忽略次要的部分
3、自注意力: 通过输入项内部的"表决"来决定应该关注哪些输入项.6.6 注意力计算步骤(常见三步走战略)
Attention计算构成元素
properties
query(Q)、key(K)、value(V)(计算规则的普遍性表达)
properties
第一步: query和key进行相似度计算,得到attention_score
第二步: 对attention_score进行softmax归一化得到权重值,压缩数值到0-1之间
第三步: 对上一步的权重值和value进行融合,得到具有权重信息的新value
properties
基本步骤
第一步: 根据注意力计算规则, 对Q,K,V进行相应的计算.
第二步: 根据第一步采用的计算方法, 如果是拼接方法,则需要将Q与第一步的计算结果再进行拼接, 如果是转置点积, 一般是自注意力, Q与V相同, 则不需要进行与Q的拼接.
第三步: 最后为了使整个attention机制按照指定尺寸输出, 使用线性层作用在第二步的结果上做一个线性变换, 得到最终对Q的注意力表示.6.7 注意力计算规则
计算规则前提
properties
必须有指定的数据: Q、K、V;当输入的Q=K=V时(或者Q\K\V来自于同一个X), 称作自注意力计算规则;当Q、K、V不相等时称为一般注意力计算规则三种规则方法
properties
第一种方法: 将Q和K进行纵轴拼接,然后经过线性变换,再经过Softmax进行处理得到权重,最后和V进行相乘
properties
第二种方法: 将Q和K进行纵轴拼接,接着经过一次线性变化,然后进过tanh激活函数处理,再进行sum求和,再经过softmax进行处理得到权重,最后和V进行张量的乘法
properties
第三种方法: 将Q和K的转置进行点乘,然后除以一个缩放系数,再经过softmax进行处理得到权重,最后和V进行张量的乘法6.8 注意力机制的作用
概念
properties
在解码器端的注意力机制: 能够根据模型目标有效的聚焦编码器的输出结果, 当其作为解码器的输入时提升效果. 改善以往编码器输出是单一定长张量, 无法存储过多信息的情况.
在编码器端的注意力机制: 主要解决表征问题, 相当于特征提取过程, 得到输入的注意力表示. 一般使用自注意力(self-attention).6.9 注意力机制实现步骤(深度学习中)
properties
第一步: 按照注意力规则,对Q、K、V进行注意力的计算
第二步: 如果第一步是拼接操作,需要将Q和第一步计算的结果进行再次拼接,如果是点乘运算,Q和K、V相等,一般属于自注意力,不需要拼接
第三步: 我们需要将第二步的结果,进行线性变化,按照指定输出维度进行结果的表示代码实现
properties
class MyAtt(nn.Module):
# 32 32 32 64 32
def __init__(self, query_size, key_size, value_size1, value_size2, output_size):
super(MyAtt, self).__init__()
self.query_size = query_size
self.key_size = key_size
self.value_size1 = value_size1
self.value_size2 = value_size2
self.output_size = output_size
# 线性层1 注意力权重分布
self.attn = nn.Linear(self.query_size + self.key_size, self.value_size1)
# 线性层2 注意力结果表示按照指定维度输出层 self.attn_combine
self.attn_combine = nn.Linear(self.query_size+self.value_size2, output_size)
def forward(self, Q, K, V):
# 1 求查询张量q的注意力权重分布, attn_weights[1,32]
# [1,1,32],[1,1,32]--> [1,32],[1,32]->[1,64]
# [1,64] --> [1,32]
# tmp1 = torch.cat( (Q[0], K[0]), dim=1)
# tmp2 = self.attn(tmp1)
# tmp3 = F.softmax(tmp2, dim=1)
attn_weights = F.softmax( self.attn(torch.cat( (Q[0], K[0]), dim=-1)), dim=-1)
# 2 求查询张量q的结果表示 bmm运算, attn_applied[1,1,64]
# [1,1,32] * [1,32,64] ---> [1,1,64]
attn_applied = torch.bmm(attn_weights.unsqueeze(0), V)
# 3 q 与 attn_applied 融合,再按照指定维度输出 output[1,1,64]
# 3-1 q与结果表示拼接 [1,32],[1,64] ---> [1,96]
output = torch.cat((Q[0], attn_applied[0]), dim=-1)
# 3-2 shape [1,96] ---> [1,32]
output = self.attn_combine(output).unsqueeze(0)
# 4 返回注意力结果表示output:[1,1,32], 注意力权重分布attn_weights:[1,32]
return output, attn_weights8 SeqSeq英译法案例
8.1 任务目的
properties
目的: 给定一段英文,翻译为法文
典型的文本分类任务: 每个时间步去预测应该属于哪个法文单词8.2 数据格式
- 注意:两列数据,第一列是英文文本,第二列是法文文本,中间用制表符号"\t"隔开
properties
i am from brazil . je viens du bresil .
i am from france . je viens de france .
i am from russia . je viens de russie .
i am frying fish . je fais frire du poisson .
i am not kidding . je ne blague pas .8.3 实现流程
properties
1. 获取数据:案例中是直接给定的
2. 数据预处理: 脏数据清洗、数据格式转换、数据源Dataset的构造、数据迭代器Dataloader的构造
3. 模型搭建: 编码器和解码器等一系列模型
4. 模型评估(测试)
5. 模型上线---API接口8.4 数据预处理
4.1 定义样本清洗函数和构建字典
- 目的
properties
样本清洗函数: 将脏数据进行清洗,以免影响模型训练
构建字典:一方面是为了将文本进行数字表示,还有一方面进行解码的时候将预测索引数字映射为真实的文本- 样本清洗函数代码实现
python
# 文本清洗工具函数
def normalizeString(s):
"""字符串规范化函数, 参数s代表传入的字符串"""
s = s.lower().strip()
# 在.!?前加一个空格 这里的\1表示第一个分组 正则中的\num
s = re.sub(r"([.!?])", r" \1", s)
# s = re.sub(r"([.!?])", r" ", s)
# 使用正则表达式将字符串中 不是 大小写字母和正常标点的都替换成空格
s = re.sub(r"[^a-zA-Z.!?]+", r" ", s)
return s- 构建字典代码实现
python
def my_getdata():
# 1.读取数据
with open(data_path, 'r' , encoding='utf-8') as fr:
sentens_str = fr.read()
sentences = sentens_str.strip().split('\n')
# 2.构建数据源pair
my_pairs = [[normalizeString(s) for s in l.split('\t')] for l in sentences]
# 3.1 初始化两个字典
english_word2index = {"SOS": 0, "EOS": 1}
english_word_n = 2
french_word2index = {"SOS": 0, "EOS": 1}
french_word_n = 2
# 3.2遍历my_pairs
for pair in my_pairs:
for word in pair[0].split(' '):
if word not in english_word2index:
english_word2index[word] = english_word_n
english_word_n += 1
# english_word2index[word] = len(english_word2index)
for word in pair[1].split(' '):
if word not in french_word2index:
french_word2index[word] = french_word_n
french_word_n += 1
english_index2word = {v: k for k, v in english_word2index.items()}
french_index2word = {v: k for k, v in french_word2index.items()}
return english_word2index, english_index2word, english_word_n, french_word2index, french_index2word, french_word_n, my_pairs4.2 构建DataSet
- 目的
properties
使用Pytorch框架,一般遵从一个规矩:使用DataSet方法构造数据源,来让模型进行使用
构造数据源的过程中:必须继承torch.utils.data.Dataset类,必须构造两个魔法方法:__len__(), __getitem__()
__len__(): 一般返回的是样本的总个数,我们可以直接len(dataset对象)直接就可以获得结果
__getitem__(): 可以根据某个索引取出样本值,我们可以直接用dataset对象[index]来直接获得结果- 代码实现
python
# 3.构建数据源Dataset
class Seq2SeqDaset(Dataset):
def __init__(self, my_pairs):
self.my_pairs = my_pairs
self.sample_len = len(my_pairs)
def __len__(self):
return self.sample_len
def __getitem__(self, index):
# 1.index异常值处理[0, self.sample_len-1]
index = min(max(index, 0), self.sample_len-1)
# 2. 根据index取出样本数据
x = self.my_pairs[index][0]
y = self.my_pairs[index][1]
# 3.进行文本数据数字化的转换
x1 = [english_word2index[word] for word in x.split(' ')]
tensor_x = torch.tensor(x1, dtype=torch.long, device=device)
y1 = [french_word2index[word] for word in y.split(' ')]
y1.append(EOS_token)
tensor_y = torch.tensor(y1, dtype=torch.long, device=device)
return tensor_x, tensor_y4.3 构建Dataloader
- 目的
properties
为了将Dataset我们上一步构建的数据源,进行再次封装,变成一个迭代器,可以进行for循环,而且,可以自动为我们dataset里面的数据进行增维(bath_size),也可以随机打乱我们的取值顺序- 代码实现
python
# 4.构建数据迭代器dataloader
def get_dataloader():
# 1.实例化dataset
my_dataset = Seq2SeqDaset(my_pairs)
# 2.实例化dataloader
my_dataloader = DataLoader(dataset=my_dataset, batch_size=1, shuffle=True)
return my_dataloader8.5 模型搭建
5.1 搭建编码器GRU模型
- 注意事项
properties
GRU模型在实例化的时候,默认batch_first=False,因此,需要小心输入数据的形状
因为: dataloader返回的结果x---》shape--〉[batch_size, seq_len, input_size], 所以课堂上代码和讲义稍微有点不同,讲义是默认的batch_first=False,而我们的代码是batch_first=True,这样做的目的,可以直接承接x的输入。- 代码实现
python
# 5. 构建GRU编码器模型
class EncoderGRU(nn.Module):
def __init__(self, vocab_size, hidden_size):
super().__init__()
# 1.vocab_size代表英文单词的总个数(去重)
self.vocab_size = vocab_size
# 2. hidden_size词嵌入维度/隐藏层输出维度(我们让他相等)
self.hidden_size = hidden_size
# 3.定义Embedding层,目的:将每个词汇进行向量表示
self.embed = nn.Embedding(self.vocab_size, self.hidden_size)
# 4.定义GRU层第一个self.hidden_size实际上是embedding的输出结果词嵌入维度
# 4.定义GRU层第二个self.hidden_size实是我们指定的GRU模型的输出维度,只不过这里GRU输入和输出一样
self.gru = nn.GRU(self.hidden_size, self.hidden_size, batch_first=True)
def forward(self, input, hidden):
# 1.input-->[1, 6]需要经过embedding--》[1,6, 256]
input_x = self.embed(input)
# 2.将input_x和hidden送入GRU模型
output, hidden = self.gru(input_x, hidden)
return output, hidden
def inithidden(self):
return torch.zeros(1, 1, self.hidden_size, device=device)- 编码器模型测试
python
# 测试编码器模型
def test_EncoderGRU():
# 获取数据
my_dataloader = get_dataloader()
# 实例化模型
my_encoder = EncoderGRU(vocab_size=english_word_n, hidden_size=256)
my_encoder.to(device)
# 初始化h0
h0 = my_encoder.inithidden()
for i, (x, y) in enumerate(my_dataloader):
print(f'x---》{x.shape}')
output, hn = my_encoder(x, h0)
print(f'output--》{output.shape}')
print(f'hn--》{hn.shape}')
break5.2 搭建解码器无Attention模型
- 代码实现
python
#6. 构建没有attention的GRU解码器
class DecoderGRU(nn.Module):
def __init__(self, vocab_size, hidden_size):
super().__init__()
# vocab_size代表解码器中法语单词的词汇总量(去重)
self.vocab_size = vocab_size
# hidden_size词嵌入维度
self.hidden_size = hidden_size
# Embedding层
self.embed = nn.Embedding(self.vocab_size, self.hidden_size)
# GRU层:这里定义GRU模型的输入和输出形状一样
self.gru = nn.GRU(self.hidden_size, self.hidden_size, batch_first=True)
# 定义输出层:判断法语单词属于self.vocab_size里面的哪一个
self.out = nn.Linear(self.hidden_size, self.vocab_size)
# 定义softmax层
self.softmax = nn.LogSoftmax(dim=-1)
def forward(self, input, hidden):
# input输入一般是一个字,解码的时候,是一个字符一个字符解码的
# 1. input-->[1, 1]-->embeding之后--》[1, 1, hidden_size]-->[1, 1, 256]
input_x = self.embed(input)
# 2. relu激活函数使用
input_x = F.relu(input_x)
# 3. 将数据送入GRU模型:input_x-->[1,1,256],hidden:[1, 1, 256]
# output-->[1, 1, 256]
output, hidden = self.gru(input_x, hidden)
# 4. 将output结果取最后一个词隐藏层输出送入linear层
# output-->[1, vocab_size]-->[1, 4345]
output = self.out(output[0])
return self.softmax(output), hidden
def inithidden(self):
return torch.zeros(1, 1, self.hidden_size, device=device)- 代码测试
python
# 测试没有attention的解码器
def test_DecoderGRU():
# 1.实例化dataset
mydataset = Seq2SeqDaset(my_pairs)
# 2.实例化dataloader
my_dataloader = DataLoader(dataset=mydataset, batch_size=1, shuffle=True)
# 3.实例化编码器模型
my_encoder = EncoderGRU(vocab_size=english_word_n, hidden_size=256)
# my_encoder = EncoderGRU(vocab_size=english_word_n, hidden_size=256).to(device)
my_encoder.to(device)
# 4. 实例化解码器模型
my_decoder = DecoderGRU(vocab_size=french_word_n, hidden_size=256)
my_decoder.to(device)
# 5.将数据送入模型
for x, y in my_dataloader:
print(x)
print(f'x--->{x.shape}')
print(f'y--->{y.shape}')
print(f'y--->{y}')
# 5.1将x英文原始输入送入编码器模型得到编码结果;hidden就是C
output, hidden = my_encoder(input=x, hidden=my_encoder.inithidden())
# 5.2基于C开始一个字符一个字符的去解码
for i in range(y.shape[1]):
# print(f'y[0]-->{y[0]}')
# print(f'y[0][i]-->{y[0][i]}')
temp = y[0][i].view(1, -1)
output, hidden = my_decoder(input=temp, hidden=hidden)
print(f'output--》{output.shape}')
break5.3 搭建解码器带Attention模型
- 注意事项
properties
带Attention:需要有三个参数:Q、K、V,在本次案例中Q上一时间步预测的真实结果;K:上一时间步隐藏层输出的结果;V代表编码器的输出结果- 代码实现
python
# 7.带attention的解码器
class AttentionDecoderGRU(nn.Module):
def __init__(self, vocab_size, hidden_size, dropout_p=0.1, max_length=MAX_LENGTH):
super().__init__()
# vocab_size:属于解码器端,代表法语的总的单词个数
self.vocab_size = vocab_size
# hidden_size:代表词嵌入的维度
self.hidden_size = hidden_size
# 随机失活概率
self.dropout_p = dropout_p
# 最大句子长度:因为训练语料里面不管英文还是法文最大句子长度都不超过10,我们这里限定最大长度,目的是方便计算注意力
self.max_length = max_length
# 定义Embedding层
self.embed = nn.Embedding(self.vocab_size, self.hidden_size)
# 计算注意力的第一个全连接层:得到权重分数
self.attn = nn.Linear(self.hidden_size*2, self.max_length)
# 随机失活层
self.droupout = nn.Dropout(p=self.dropout_p)
# 计算注意力的第二个全连接层:让注意力按照指定维度输出
self.attn_combin = nn.Linear(self.hidden_size*2, self.hidden_size)
# 定义GRU层
self.gru = nn.GRU(self.hidden_size, self.hidden_size, batch_first=True)
# 定义输出层
self.out = nn.Linear(self.hidden_size, self.vocab_size)
# 定义softmax层
self.softmax = nn.LogSoftmax(dim=-1)
def forward(self, input, hidden, encoder_output):
# input-->query--》解码器输入某个词[1, 1]
# hidden-->key--》上一时间步隐藏层输出[1, 1, 256]
# encoder_output--->value-->编码器的输出结果[10, 256]--[max_length, 256]
# 1. 将input送入embedding-->input_x-->[1,1,256]--query(真正)
input_x = self.embed(input)
# 1.1对input_x进行dropout
input_x = self.droupout(input_x)
# 2. 计算注意力权重分数self.attn_weight-->[1, 10]-->[1, max_length]
attn_weight = F.softmax(self.attn(torch.cat((input_x[0], hidden[0]), dim=-1)), dim=-1)
# 3. 将注意力权重和Value相乘:[1, 1,10]*[1,10,256]-->self.attn_applied-->[1, 1,256]
attn_applied = torch.bmm(attn_weight.unsqueeze(0), encoder_output.unsqueeze(0))
# 4.将query和self.attn_applied结果拼接之后,再经过线性的变换self.output1-->[1, 1, 256]
output1 = self.attn_combin(torch.cat((input_x[0], attn_applied[0]), dim=-1)).unsqueeze(0)
# 5. 经过relu激活函数
relu_output = F.relu(output1)
# 6. 将self.relu_output,以及hidden送入GRU模型中-->gru_output-->[1, 1,256]
gru_output, hidden = self.gru(relu_output , hidden)
# 7.将gru的结果送入输出层,得到最后的预测结果output-->[1, 4345]
output = self.out(gru_output[0])
return self.softmax(output), hidden, attn_weight
def inithidden(self):
return torch.zeros(1, 1, self.hidden_size, device=device)- 模型测试
python
# 测试带attention的解码器
def test_AttenDecoder():
# 1.实例化dataset
mydataset = Seq2SeqDaset(my_pairs)
# 2.实例化dataloader
my_dataloader = DataLoader(dataset=mydataset, batch_size=1, shuffle=True)
# 3.实例化编码器模型
my_encoder = EncoderGRU(vocab_size=english_word_n, hidden_size=256)
# my_encoder = EncoderGRU(vocab_size=english_word_n, hidden_size=256).to(device)
my_encoder.to(device)
# 4.实例化解码器模型
my_attenDecoder = AttentionDecoderGRU(vocab_size=french_word_n, hidden_size=256)
my_attenDecoder.to(device)
#5.循环数据送入模型
for x, y in my_dataloader:
print(f'x--》{x.shape}')
print(f'y--》{y.shape}')
# 1.将x送入编码器模型得到结果
h0 = my_encoder.inithidden()
encoder_output, hidden = my_encoder(input=x, hidden=h0)
# print(f'encoder_output--》{encoder_output.shape}')
# 2.将编码的结果进行处理,统一长度,方便计算注意力
encoder_output_c = torch.zeros(MAX_LENGTH, my_encoder.hidden_size, device=device)
# print(f'encoder_output_c--》{encoder_output_c.shape}')
# 2.1将真实的编码的输出 结果赋值到encoder_output_c中,多余的都是用0来表示
for i in range(encoder_output.shape[1]):
# print(f'encoder_output[0][i]-->{encoder_output[0][i].shape}')
# print(f'encoder_output[0, i]-->{encoder_output[0, i].shape}')
encoder_output_c[i] = encoder_output[0][i]
# 3.测试:进行解码应用
for j in range(y.shape[1]):
temp = y[0][j].view(1, -1)
output, hidden, attn_weight = my_attenDecoder(temp, hidden, encoder_output_c)
print(f'output--》{output.shape}')
print(f'hidden--》{hidden.shape}')
print(f'attn_weight--》{attn_weight.shape}')
print("*"*80)
break8.6 模型训练
- 基本过程
properties
1.获取数据
2.构建数据源Dataset
3.构建数据迭代器Dataloader
4.实例化自定义的模型: 编码器模型和解码器模型
5.实例化损失函数对象
6.实例化优化器对象: 编码器优化器和解码器优化器
7.定义打印日志参数
8.开始训练
8.1 实现外层大循环epoch
(可以在这构建数据迭代器Dataloader)
8.2 内部遍历数据迭代球dataloader
8.3 将数据送入模型得到输出结果
8.4 计算损失
8.5 梯度清零: optimizer.zero_grad()
8.6 反向传播: loss.backward()
8.7 参数更新(梯度更新): optimizer.step()
8.8 打印训练日志
9. 保存模型: torch.save(model.state_dict(), "model_path")- 代码实现
python
# 8.构建模型的训练函数
def train_seq2seq():
# 1.实例化dataset
mydataset = Seq2SeqDaset(my_pairs)
# 2.实例化dataloader
my_dataloader = DataLoader(dataset=mydataset, batch_size=1, shuffle=True)
# 3.实例化编码器模型
my_encoder = EncoderGRU(vocab_size=english_word_n, hidden_size=256)
# my_encoder = EncoderGRU(vocab_size=english_word_n, hidden_size=256).to(device)
my_encoder.to(device)
# 4.实例化解码器模型
my_attenDecoder = AttentionDecoderGRU(vocab_size=french_word_n, hidden_size=256)
my_attenDecoder.to(device)
# 5.实例化优化器
encoder_optimizer = optim.Adam(my_encoder.parameters(), lr=mylr)
decoder_optimizer = optim.Adam(my_attenDecoder.parameters(), lr=mylr)
# 6.实例化损失对象
crossentropy = nn.NLLLoss()
# 7.定义一个空列表list--》存储损失值,画图
plot_loss_list = []
# 8. 进入外层循环
for epoch_idx in range(epochs):
# 初始化损失值为0
print_loss_total, plot_loss_total = 0.0, 0.0
start_time = time.time()
# 进入内部循环
for i, (x, y) in enumerate(tqdm(my_dataloader), start=1):
myloss = Train_Iters(x, y, my_encoder,
my_attenDecoder,encoder_optimizer,
decoder_optimizer,crossentropy)
# print(f'主训练了函数的myloss--》{myloss}')
print_loss_total += myloss
plot_loss_total += myloss
# 打印日志
# 每隔1000步打印损失
if i % 10 == 0:
print_loss_avg = print_loss_total / 1000
print_loss_total = 0
use_time = time.time() - start_time
print(f'当前的轮次%d,平均损失%.4f,时间%.2f'%(epoch_idx+1, print_loss_avg.item()*100, use_time))
# 每隔100步保留损失,画图
if i % 10 == 0:
plot_loss_avg = plot_loss_total / 100
# 如果画图报错:放到CPU--》plot_loss_avg.cpu().detach().numpy()
plot_loss_list.append(plot_loss_avg.cpu().detach().numpy())
plot_loss_total = 0
# 保存模型
torch.save(my_encoder.state_dict(), './ai19_model/my_encoder_%s.pth'%(epoch_idx+1))
torch.save(my_attenDecoder.state_dict(), './ai19_model/my_decoder_%s.pth'%(epoch_idx+1))
# 画图
plt.figure()
plt.plot(plot_loss_list)
plt.savefig("./ai19_seq2se1_loss.png")
plt.show()
return plot_loss_list- 模型训练内部迭代函数代码实现
python
# 定义内部迭代函数
def Train_Iters(x, y, my_encoder, my_attenDecoder, encoder_optimizer, decoder_optimizer, crossentropy):
# 1.将x送入编码器得到编码的结果
# print(f'x-->{x.shape}')
# print(f'y-->{y.shape}')
h0 = my_encoder.inithidden()
encoder_output, encoder_hidden = my_encoder(x, h0)
# print(f'encoder_output--》{encoder_output.shape}')
# print(f'encoder_hidden--》{encoder_hidden.shape}')
# 2. 定义解码器的参数
# 2.1 中间语意张量C:value
encoder_output_c = torch.zeros(MAX_LENGTH, my_encoder.hidden_size, device=device)
for i in range(x.shape[1]):
encoder_output_c[i] = encoder_output[0][i]
# 2.2 解码器的初始化的hidden, key
decoder_hidden = encoder_hidden
# 2.3 解码器的初始化输出:query
input_y = torch.tensor([[SOS_token]], dtype=torch.long, device=device)
# 3.定义一个初始化的损失
my_loss = 0.0
# 4.选择性的使用teacher_forcing策略
teacher_forcing = True if random.random() < teacher_forcing_ratio else False
# 5.开始计算损失
if teacher_forcing:
for i in range(y.shape[1]):
# output_y--》[1, 4345]
output_y, decoder_hidden, attn_weight =my_attenDecoder(input_y, decoder_hidden, encoder_output_c)
# 根据预测结果计算损失
target_y = y[0][i].view(1)
# print(f'target_y--》{target_y}')
my_loss = my_loss + crossentropy(output_y, target_y)
# print(f'my_loss--》{my_loss}')
# 将真实的下一个单词当作input_y
input_y = y[0][i].view(1, -1)
# print(f'input_y--》{input_y}')
else:
for i in range(y.shape[1]):
# output_y--》[1, 4345]
output_y, decoder_hidden, attn_weight = my_attenDecoder(input_y, decoder_hidden, encoder_output_c)
# 根据预测结果计算损失
target_y = y[0][i].view(1)
my_loss = my_loss + crossentropy(output_y, target_y)
topv, topi = output_y.topk(1)
# 如果output_y预测的最大值对应的索引刚好等EOS,直接终止
if topi.squeeze().item() == EOS_token:
break
# 将预测结果的当作下一个input_y
input_y = topi.detach()
# 6. 梯度清零
encoder_optimizer.zero_grad()
decoder_optimizer.zero_grad()
# 7. 反向传播
my_loss.backward()
# 8.梯度更新
encoder_optimizer.step()
decoder_optimizer.step()
return my_loss / y.shape[1]8.7 模型预测
- 基本过程
properties
1.获取数据
2.数据预处理
3.实例化模型: 编码器和解码器
4.加载模型训练好的参数: model.load_state_dict(torch.load("model_path"))
5.with torch.no_grad():
6.将数据送入模型进行预测(注意:张量的形状变换)- 代码实现
python
# 9.定义模型评估/预测函数
def test_Seq2Seq_Evaluate():
# 1.加载训练好的编码器模型
my_encoder = EncoderGRU(vocab_size=english_word_n, hidden_size=256).to(device)
my_encoder.load_state_dict(torch.load("./ai19_model/my_encoder_1.pth"))
# my_encoder.to(device)
print(my_encoder)
# 2.加载训练好的解码器模型
my_decoder = AttentionDecoderGRU(vocab_size=french_word_n, hidden_size=256).to(device)
my_decoder.load_state_dict(torch.load("./ai19_model/my_decoder_1.pth"))
# my_decoder.load_state_dict(torch.load("./ai19_model/my_decoder_1.pth", map_location="cpu"), strict=False)
print(my_decoder)
print('*'*80)
# 3.准备样本
my_samplepairs =[['i m impressed with your french .', 'je suis impressionne par votre francais .'],
['i m more than a friend .', 'je suis plus qu une amie .'],
['she is beautiful like her mother .', 'elle est belle comme sa mere .']]
print('my_samplepairs--->', len(my_samplepairs))
# 4. 将样本输入模型得到结果
for index, pair in enumerate(my_samplepairs[2:]):
x = pair[0]
y = pair[1]
# 需要对x英文文本进行处理
x_word2id = [english_word2index[word] for word in x.split(' ')]
# print(f'x_word2id--》{x_word2id}')
tensor_x = torch.tensor([x_word2id], dtype=torch.long, device=device)
# print(f'tensor_x-->{tensor_x}')
decoder_words, attention_weights = evaluate_seq2seq(tensor_x, my_encoder, my_decoder)
decoder_french = ' '.join(decoder_words)
print("*"*80)
print(f'原始的英文输入文本是---》{x}')
print(f'原始的法文标签文本是---》{y}')
print(f'模型预测的法文---》{decoder_french}')- 内部评估代码实现
python
def evaluate_seq2seq(x, encoder, decoder):
# x代表当前需要翻译的英文文本
# encoder代表编码器模型
# decoder代表解码器模型
# 1. 将x送入编码器得到编码结果
# print(f'x---》{x.shape}')
h0 = encoder.inithidden()
encoder_outputs, encoder_hidden = encoder(x, h0)
# 2. 准备解码的参数
# 2.1 编码器结果--Value
encoder_outputs_c = torch.zeros(MAX_LENGTH, encoder.hidden_size, device=device)
for index in range(x.shape[1]):
encoder_outputs_c[index] = encoder_outputs[0][index]
# 2.2 解码器的key
decode_hidden = encoder_hidden
# 2.3 解码器的原始输入
input_y = torch.tensor([[SOS_token]], dtype=torch.long, device=device)
# 3.准备变量
# 3.1 存储模型的预测结果
decoder_words = []
# 3.2 初始化一个全0的权重矩阵:存储每一步解码出来的注意力权重
attention_weights = torch.zeros(MAX_LENGTH, MAX_LENGTH, device=device)
# 4.进行模型的预测
index = 0
for i in range(MAX_LENGTH):
output_y, decode_hidden, atten = decoder(input_y, decode_hidden, encoder_outputs_c)
# 获取output_y预测的最大概率值对应索引
topv, topi = output_y.topk(1)
# print(f'topi--》{topi}')
# print(f'atten-->{atten}')
# 将真实的注意力权重赋值给attention_weights
# print(f' attention_weights[i]-->{ attention_weights[i]}')
attention_weights[i] = atten
if topi.item() == EOS_token:
decoder_words.append("<EOS>")
break
else:
decoder_words.append(french_index2word[topi.item()])
input_y = topi.detach()
index = i
print(f'attention_weights--》{attention_weights}')
return decoder_words, attention_weights[:index+1]
- 注意力图
python
# 10.注意力图展示
def test_attention_plot():
# 1.加载训练好的编码器模型
my_encoder = EncoderGRU(vocab_size=english_word_n, hidden_size=256).to(device)
my_encoder.load_state_dict(torch.load("./ai19_model/my_encoder_1.pth"))
# my_encoder.to(device)
print(my_encoder)
# 2.加载训练好的解码器模型
my_decoder = AttentionDecoderGRU(vocab_size=french_word_n, hidden_size=256).to(device)
my_decoder.load_state_dict(torch.load("./ai19_model/my_decoder_1.pth"))
# my_decoder.load_state_dict(torch.load("./ai19_model/my_decoder_1.pth", map_location="cpu"), strict=False)
print(my_decoder)
print('*' * 80)
sentence = "we re both teachers ."
# 需要对x英文文本进行处理
x_word2id = [english_word2index[word] for word in sentence.split(' ')]
# print(f'x_word2id--》{x_word2id}')
tensor_x = torch.tensor([x_word2id], dtype=torch.long, device=device)
# print(f'tensor_x-->{tensor_x}')
decoder_words, attention_weights = evaluate_seq2seq(tensor_x, my_encoder, my_decoder)
plt.matshow(attention_weights.cpu().detach().numpy())
plt.savefig('./ai19_attention.png')
plt.show()