K-means 是一种广泛使用的无监督学习聚类算法,其核心目标是将数据集划分为 K 个簇,使得每个簇内的数据点尽可能相似,而不同簇之间的差异尽可能大。该算法通过迭代优化簇的中心(质心),最小化数据点与其所属簇质心之间的距离平方和,从而实现紧凑且分离度高的聚类效果。
Java代码示例:
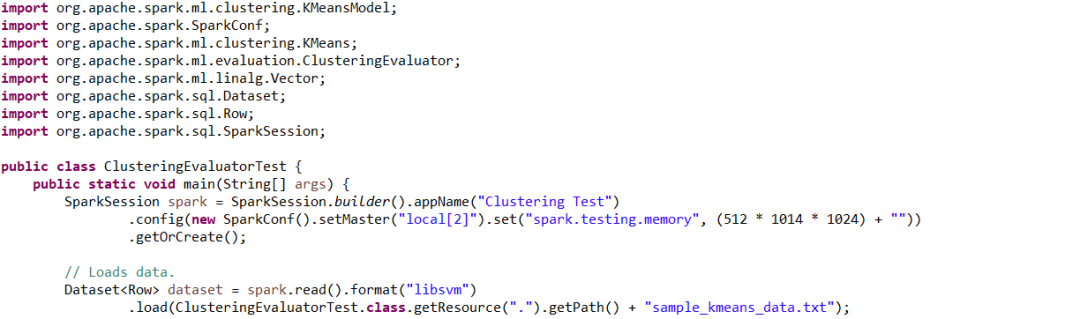
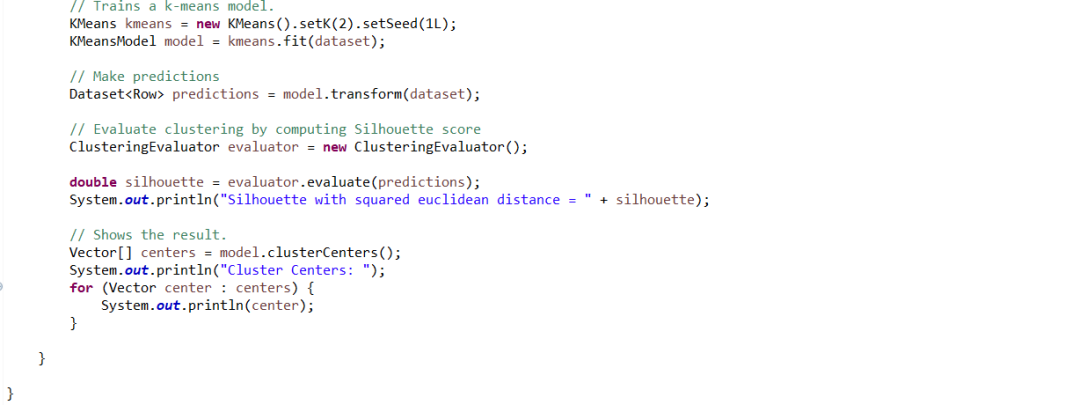
标准测试数据集合sample_kmeans_data的数据样本,其中,第一列是记录序号,其他列是特征数据(特征值对应的索引号:特征值):

运行Java代码:

K-means 是一种广泛使用的无监督学习聚类算法,其核心目标是将数据集划分为 K 个簇,使得每个簇内的数据点尽可能相似,而不同簇之间的差异尽可能大。该算法通过迭代优化簇的中心(质心),最小化数据点与其所属簇质心之间的距离平方和,从而实现紧凑且分离度高的聚类效果。
Java代码示例:
标准测试数据集合sample_kmeans_data的数据样本,其中,第一列是记录序号,其他列是特征数据(特征值对应的索引号:特征值):
运行Java代码: