大语言模型 SFT 后训练方法全景解析:SFT, DFT, ASFT, ProFit, BFT, RAFT
大语言模型(LLMs)在预训练之后,往往需要通过 Supervised Fine-Tuning (SFT) 进行对齐与能力塑形。然而,近年来研究发现:标准 SFT 并非一个"绝对完美"的优化过程,它在梯度结构、泛化行为和表达学习方面存在缺陷。围绕这些问题,出现了一系列改进方法:
- DFT ------ Dynamic Fine-Tuning:"ON THE GENERALIZATION OF SFT: A REINFORCEMENT LEARNING PERSPECTIVE WITH REWARD RECTIFICATION, ICLR2026"
- ASFT ------ Anchored SFT:"ANCHORED SUPERVISED FINE-TUNING, ICLR2026"
- ProFit ------ Probability-Guided Fine-Tuning:"ProFit: Leveraging High-Value Signals in SFT via Probability-Guided Token Selection"
- BFT ------ Balanced Fine-Tuning:"Aligning LLMs with Biomedical Knowledge using Balanced Fine-Tuning"
- RAFT ------ Reward Ranked Fine-Tuning:"RAFT: Reward rAnked FineTuning for Generative Foundation Model Alignment, Transactions on Machine Learning Research, 2023"
本文将从 优化目标、梯度结构、信息密度、训练稳定性 等角度,系统梳理它们之间的关系。
1️⃣ 标准 SFT:一切的起点
Objective
标准 SFT 的目标是最小化 token-level cross-entropy:LSFT=−∑tlogpθ(yt∣x,y<t)\mathcal{L}{SFT} = -\sum_t \log p\theta(y_t | x, y_{<t})LSFT=−∑tlogpθ(yt∣x,y<t)
关键特征
- 所有 token 等权重
- 低概率 token 自动产生大梯度
- 高概率 token 贡献小梯度
隐含问题主要是泛化能力有限,SFT 是稳定的,但不是最优的。
2️⃣ DFT:动态重加权
SFT 的梯度结构存在隐式 reward 机制。DFT中发现SFT按照策略梯度写法,SFT的token梯度大小与token概率的倒数正相关,所以SFT在低概率token上很容易梯度爆炸从而过拟合,因此,DFT 通过引入 动态 token 权重 (token概率) 改变梯度。修改后的目标函数:LDFT=−∑twtlogpθ(yt)\mathcal{L}{DFT} = -\sum_t w_t \log p\theta(y_t)LDFT=−∑twtlogpθ(yt),其中:wt=sg(pθ(yt))w_t = sg(p_\theta(y_t))wt=sg(pθ(yt))。
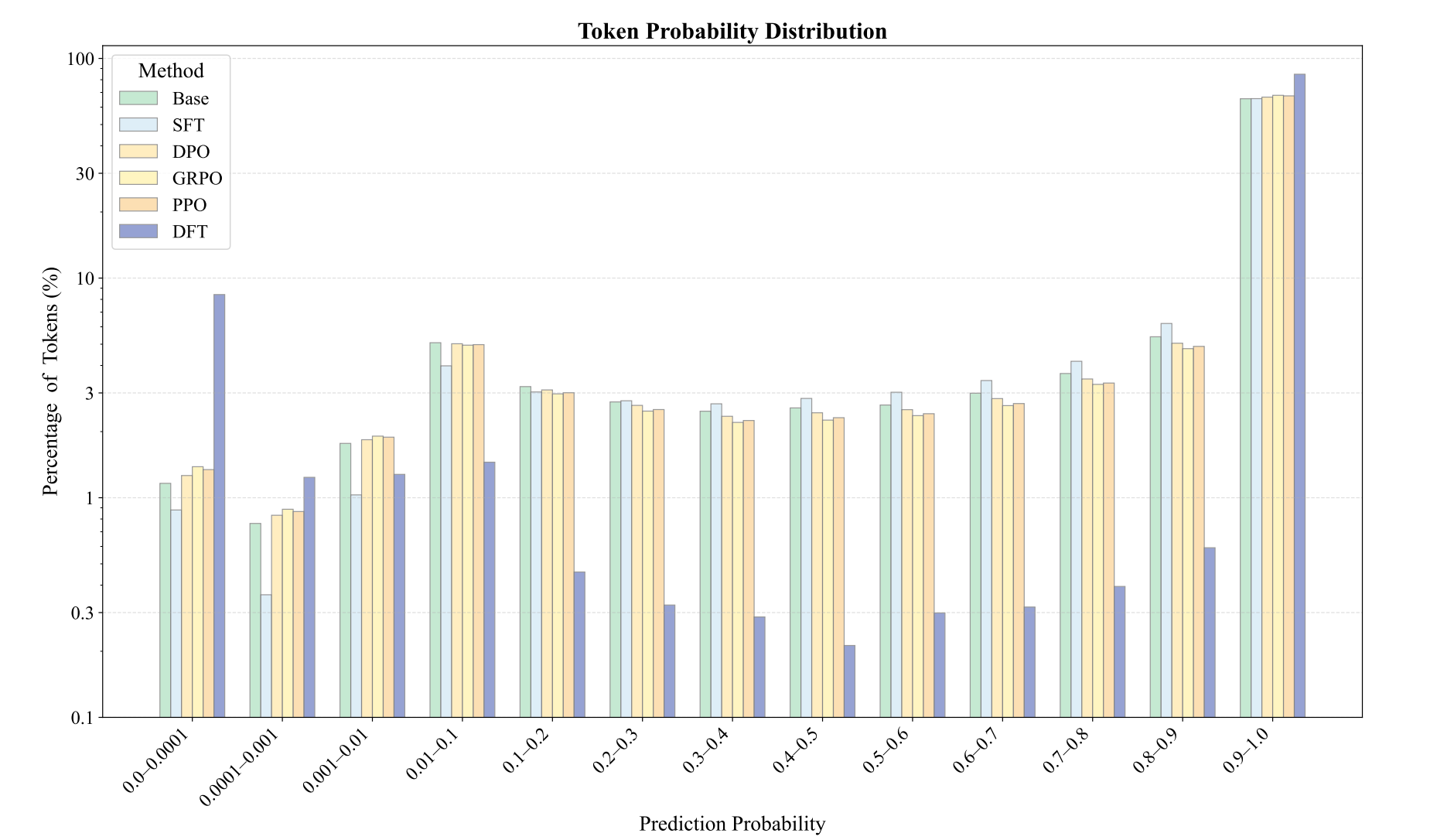
DFT中,分析了训练后的token概率分布。传统的 SFT 均匀地将概率推向训练集,而 DFT 则有选择地增加某些概率,同时减少其他概率。特别是,拟合度较低的token比例上升,表明正则化得到改善,过拟合得到缓解。
为了理解DFT训练的模型与SFT和其他强化学习方法有何不同,我们可以观察上图中模型输出在训练集上的token概率分布。SFT倾向于均匀地提高token概率,使整个分布向更高的置信度移动,但主要针对的是低概率和最低概率的token。最高概率的token部分几乎没有增加。与此形成鲜明对比的是,DFT表现出极化效应:它显著提升了一部分token的概率,同时主动抑制了其他token的概率。这导致了双峰分布,更多的token同时占据了最高概率和最低概率区间。
其他强化学习方法,例如DPO、GPPO和PPO,也表现出与DFT相同的趋势,尽管其幅度要小得多。进一步研究概率最低的词组,发现它们通常是连接词或标点符号,例如"the"、"let"、","、"."等等。这些结果表明,为了实现稳健的学习,模型不应试图以相同的置信度拟合所有token。降低拟合那些服务于语法功能而非承载主要语义内容的token的优先级可能是有益的。这一概念类似于人类的语言学习,在语言学习中,学生被教导专注于实质性概念,而不是完善常用连接词的用法。
3️⃣ ASFT:加入分布锚定
DFT强化的是高概率序列:它通过依赖模型当前分布的序列概率,使训练重点偏向模型已经倾向生成的序列(相当于"强化已知高概率路径"),这也是为什么会出现分布漂移(distribution drift)。
ASFT的改进:ASFT的核心是给DFT加上KL anchoring,用预训练模型作为 reference 分布,形成一个"trust region",防止概率偏低的token被完全忽略或高概率token过度强化,从而稳定训练。
ASFT 引入 KL 正则:LASFT=LDFT+βKL(pθ∣∣pref)\mathcal{L}{ASFT} = \mathcal{L}{DFT} + \beta KL(p_\theta || p_{ref})LASFT=LDFT+βKL(pθ∣∣pref)
4️⃣ RAFT:奖励排序微调
RAFT 不修改 loss,而是修改数据。流程如下:
- 模型生成多个候选
- 奖励模型打分
- 选择高 reward 样本
- 用选中样本做 SFT
本质是用 reward 作为样本筛选器。RAFT中使用现成的Reward model进行打分,筛选高质量样本。
5️⃣ ProFit:基于概率的 token 选择
观察到以下现象:
- 高概率 token ≈ 核心语义:通过统计分析(使用 Gemini-3-Pro 或 Qwen3 模型预测概率),发现核心逻辑 token 的预测概率通常较高。
- 低概率 token → 多为可替换的表面表达。

所以ProFit是一种选择性的SFT,本质是更Hard的一种DFT
| 条件 | 解释 |
|---|---|
| (pt>τ)( p_t > \tau )(pt>τ) | 高价值 token → 保留训练 |
| (pt≤τ)( p_t \le \tau )(pt≤τ) | 非核心 token → mask 掉,避免训练 |
6️⃣ BFT:平衡微调
Balanced Fine-Tuning (BFT) 的核心目标是稳定梯度结构,避免 token 级过拟合,同时提升困难样本的学习。
在生物医学语料上统计了token的概率,发现孤立概率下降的token通常对应可替换的功能词,连续概率下降的token片段通常对应生物医学实体和逻辑内容。因此,BFT在token层面使用DFT,但是在一整个sample层面利用最低组置信度检测样本的难易程度,并在sample层面进行损失函数加强。
ASFT中曾提到DFT容易出现分布漂移,所以借助KL约束更新模型和ref模型之间的距离。BFT是另一种缓解分布漂移的方式:
- 持续低概率span(包含长尾实体或复杂逻辑)不会被完全忽略,模型训练中仍会接触这些低概率但信息量大的序列。因此,BFT通过sample-level加权为低概率、知识密集序列提供持续梯度,使训练分布更均衡,从而缓解DFT的偏移风险。
7️⃣ 方法关系
对比如下:
| 方法 | 修改层级 | 是否改 loss | 是否改数据 | 是否用 KL | 核心目标 |
|---|---|---|---|---|---|
| SFT | token CE | ✗ | ✗ | ✗ | 基础监督 |
| DFT | token weight | ✓ | ✗ | ✗ | 动态重加权 |
| ASFT | token weight + KL | ✓ | ✗ | ✓ | 防止DFT分布漂移 |
| ProFit | token selection | ✓ | ✗ | ✗ | 去除表达性token过拟合 |
| BFT | token weight+sample weight | ✓ | ✗ | ✗ | token稳定与sample难易之间平衡 |
| RAFT | sample selection | ✗ | ✓ | ✗ | 奖励筛选 |