MiniMax M2.5深度评测:更快更强更智能,为真实世界生产力而生
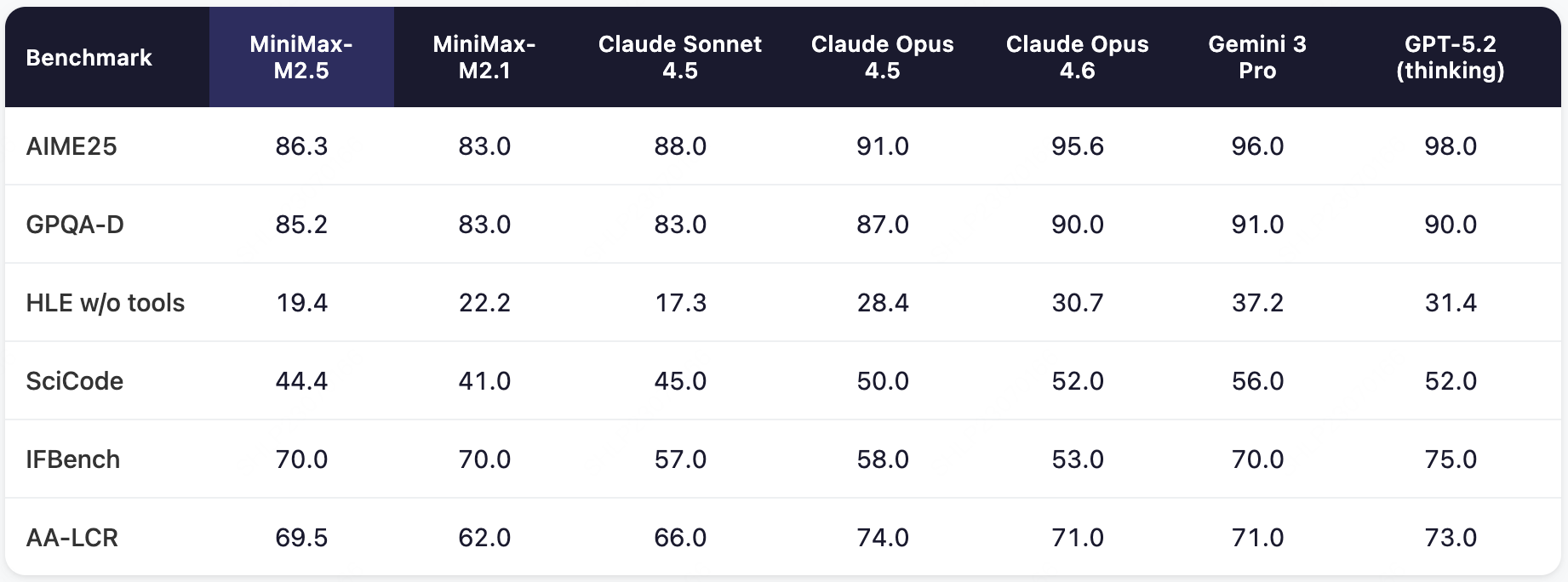
2026年2月12日,MiniMax发布了新一代文本模型------MiniMax-M2.5。经过在数十万个真实复杂环境中的大规模强化学习训练,M2.5 在编程、Agent工具使用和搜索、办公等生产力场景都达到或者刷新了行业的SOTA(State-of-the-Art),在 SWE-Bench Verified 上取得80.2%的成绩、Multi-SWE-Bench 取得51.3%的成绩、BrowseComp 达到76.3%。

MiniMax M2.5 的定位非常明确:为真实世界生产力而生。与上一代模型相比,M2.5 优化了模型对复杂任务的拆解能力和思考过程中 token 的消耗,使其能更快地完成复杂的 Agentic 任务。在 SWE-Bench Verified 的测试中,M2.5 比上一个版本 M2.1 完成任务的速度快了37%。
核心规格
| 项目 | 参数 |
|---|---|
| 定位 | 生产力导向的前沿模型 |
| 发布时间 | 2026年2月12日 |
| 版本 | M2.5 / M2.5-Lightning |
| 训练环境 | 200,000+ 真实世界环境 |
| 多语言支持 | 10+ 种编程语言 |
| 核心能力 | 编程、Agent工具使用、搜索、办公场景 |
技术亮点
Forge RL框架:大规模强化学习
MiniMax M2.5 的核心突破在于 Forge RL 框架。这是一个 Agent-native 的强化学习框架,引入了中间层,完全解耦了底层训练-推理引擎与 Agent,支持集成任意 Agent,并能够优化模型在 Agent scaffolds 和工具上的泛化能力。
通过优化异步调度策略来平衡系统吞吐量和样本 off-policyness,设计了树状结构化的样本合并策略,实现了约 40 倍的训练加速。MiniMax 基于 CISPO 算法确保 MoE 模型在大规模训练期间的稳定性,并引入了过程奖励机制来端到端监控生成质量。
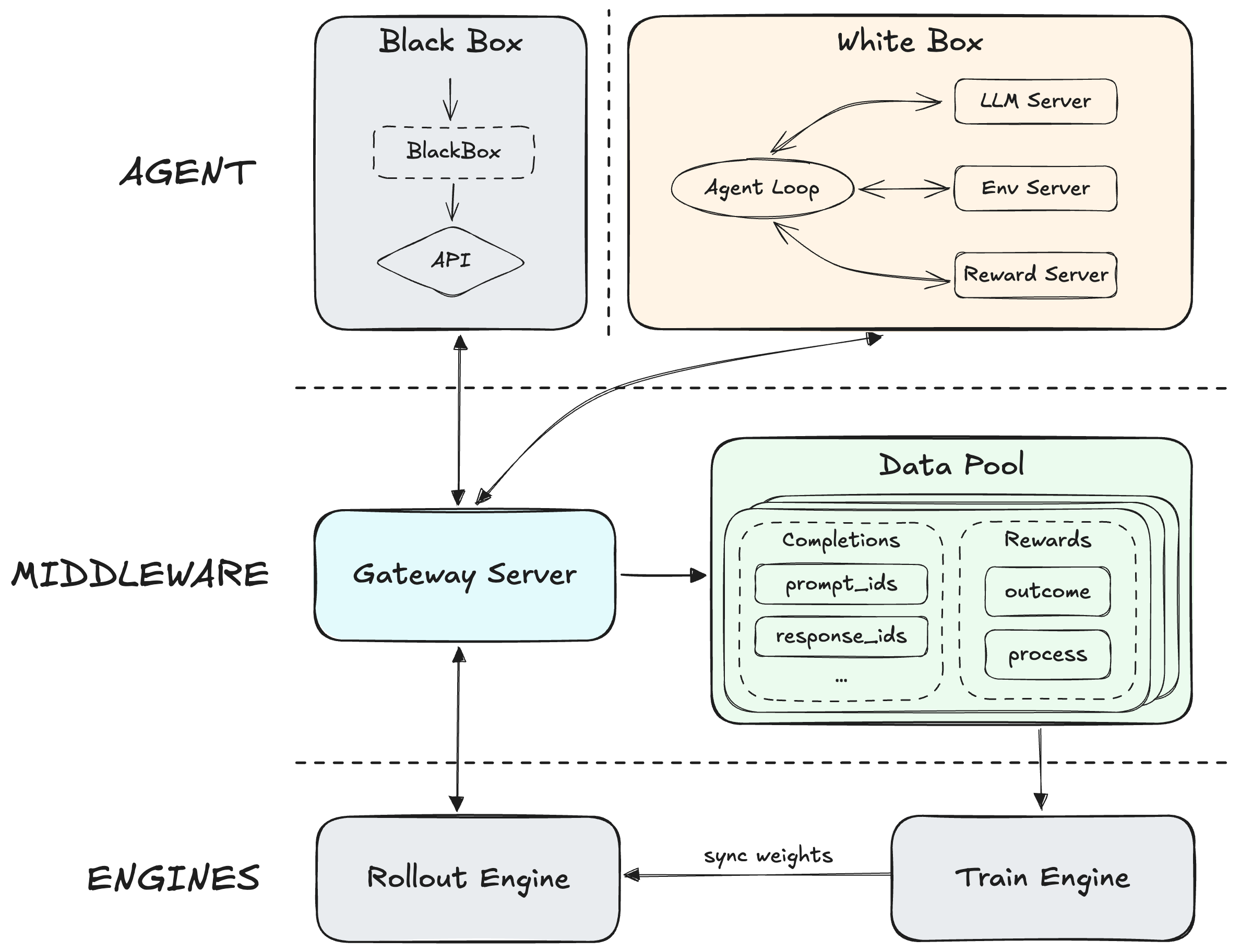
(图片来源:MiniMax官方发布页面)
Spec-writing能力:像架构师一样思考和构建
M2.5 的一个显著改进是其具备了"像架构师一样思考和构建"的能力。模型在训练过程中演化出了原生 Spec 行为:在动手写代码前,M2.5 以架构师的视角主动拆解功能、结构和 UI 设计,实现完整的前期规划。
这种能力超越了传统的 bug-fixing 类场景。M2.5 在从 0-1 系统设计、环境构建,从 1-10 的系统开发,从 10-90 的功能迭代,从 90-100 的完备 code review 与系统测试的整个开发生命周期中,都能可靠地完成复杂系统的开发。它覆盖 Web、Android、iOS、Windows、Mac 等多平台的全栈项目,包含 Server 端 API、业务逻辑、数据库等,而不仅仅是"前端网页 demo"。
多语言支持与全栈开发
M2.5 在超过 10 种语言和数十万个真实环境中进行了训练,包括:Go、C、C++、TypeScript、Rust、Kotlin、Python、Java、JavaScript、PHP、Lua、Dart 和 Ruby。这种多语言训练使其在 Multi-SWE-Bench 等多语言复杂环境中表现优异。
工具调用与搜索优化
有效的工具调用和搜索是模型能够自动处理更复杂任务的前提。在 BrowseComp、Wide Search 等 Agent 任务中,M2.5 以更低的轮次消耗取得了更优的效果,相较于上一代模型表现提升约20%,达到了行业顶尖水平。
MiniMax 构建了 RISE(Realistic Interactive Search Evaluation)来衡量模型在真实世界专业任务上的搜索能力。结果表明 M2.5 在真实世界的专家级搜索任务上表现卓越。在 BrowseComp、Wide Search 和 RISE 多项任务中,M2.5 以更低的轮次取得了更好的结果,相比 M2.1 使用约少 20% 的搜索轮次,表明模型不再仅仅是获得正确答案,而是以更高效的路径推理出结果。
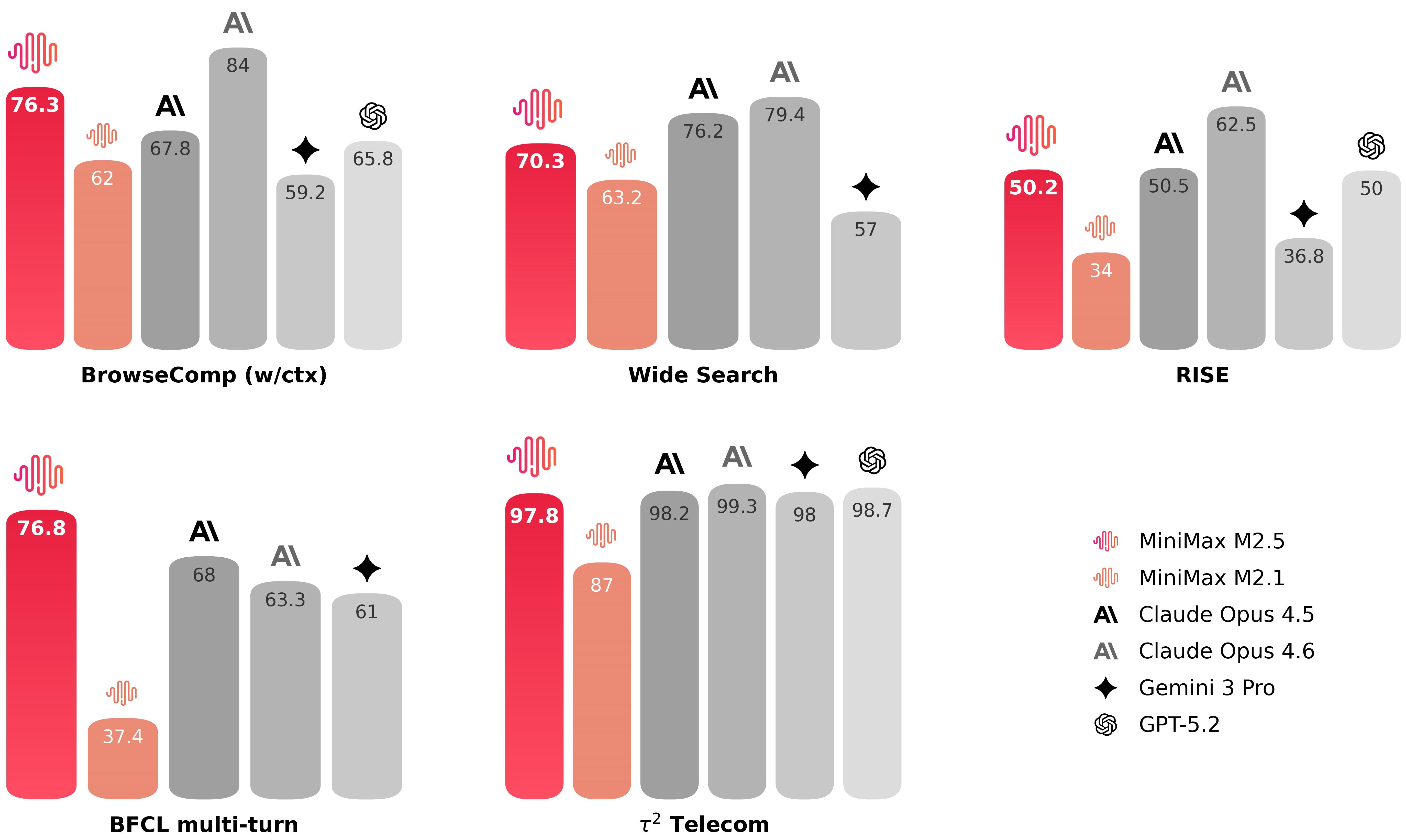
(图片来源:MiniMax官方发布页面)
办公场景应用
M2.5 经过与金融、法律和社会科学等领域的高级专业人士的深入协作,训练以产生真正可交付的办公场景输出。这些专家设计了需求、提供反馈、参与定义标准,并直接贡献于数据构建,将行业的隐性知识带入到模型的训练管道中。
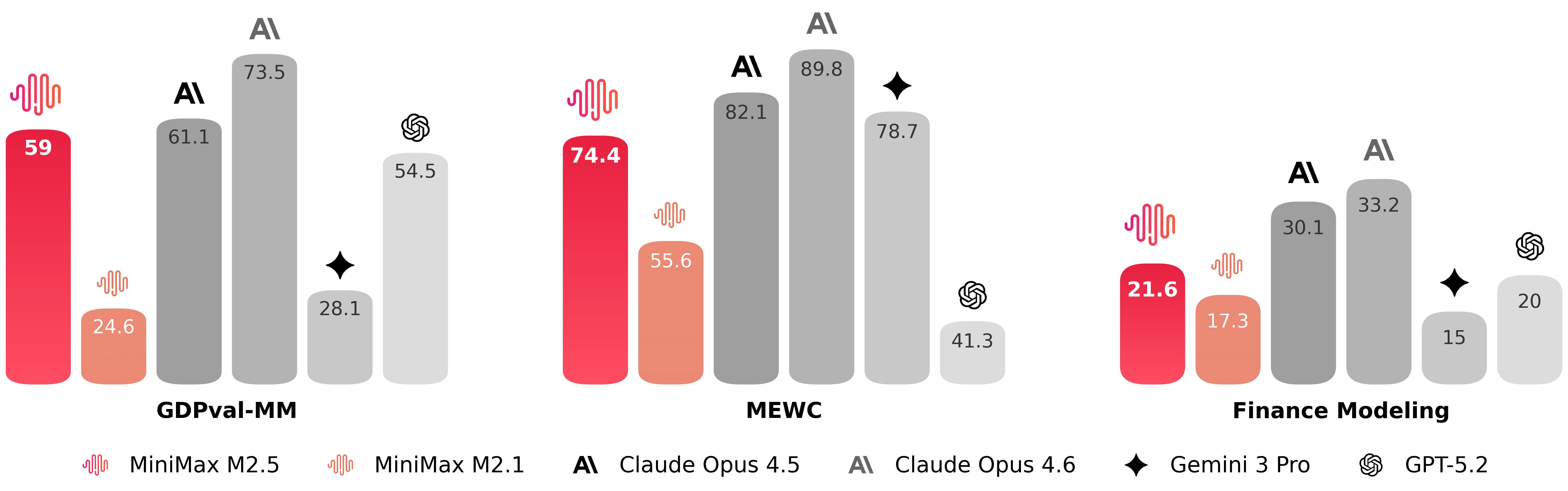
基于此基础,M2.5 在 Word、PowerPoint、Excel 金融建模等高价值 Workspace 场景中实现了显著的能力提升。在与其他主流模型的比较中,它在 GDPval-MM 评测中取得了59.0%的平均胜率。
性能表现
编程能力
在编程的核心测试中,M2.5 相比于前代模型有了显著提升,达到了与 Claude Opus 系列类似的水平。
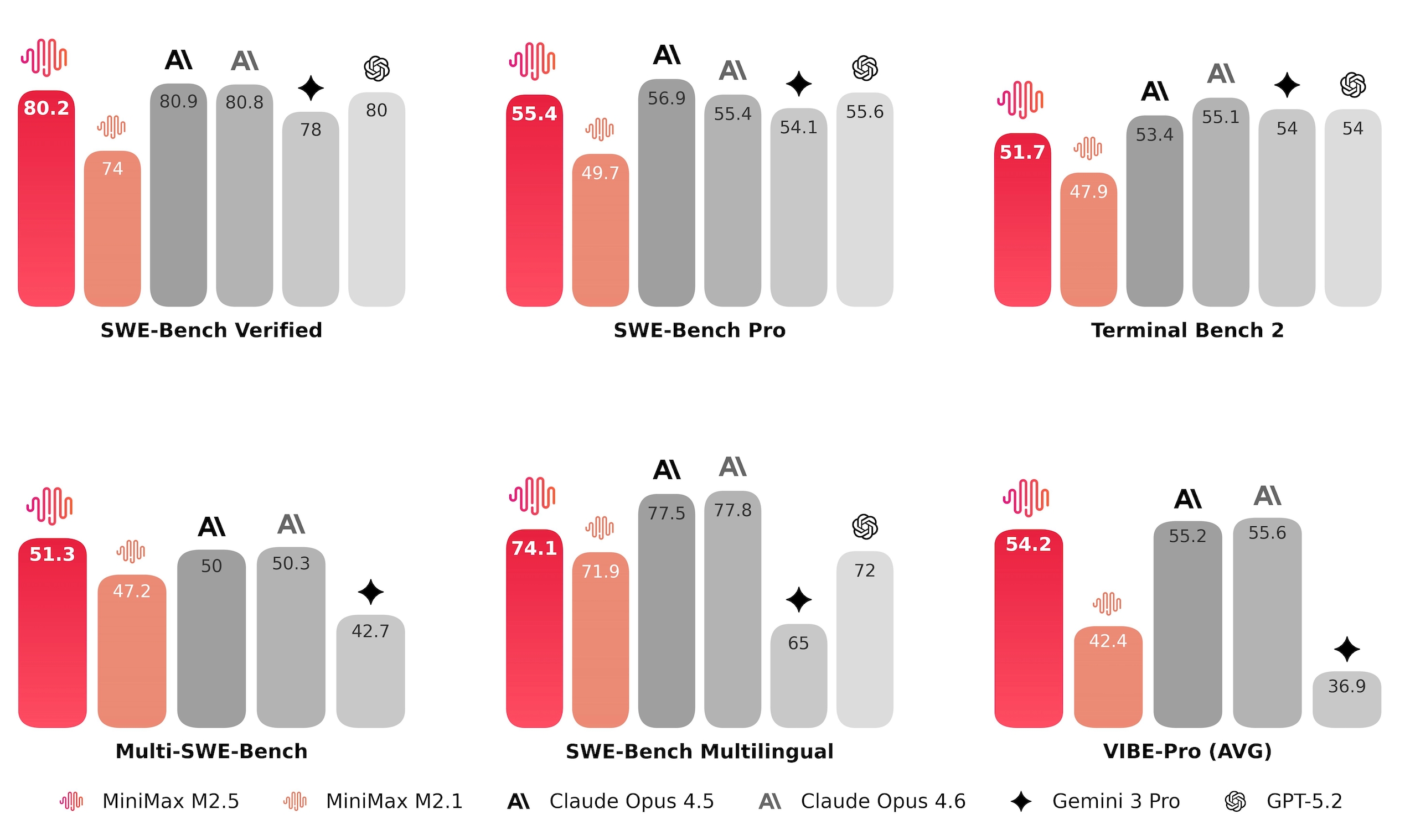
(图片来源:MiniMax官方发布页面)
- SWE-Bench Verified: 80.2%
- Multi-SWE-Bench: 51.3%
在 Multi-SWE-Bench 等多语言设置及更具挑战性的 SWE-Bench-Pro 测试中,M2.5 的表现亮眼。MiniMax 还将 VIBE benchmark 升级为了更复杂、更具挑战性的 Pro 版本,显著提升了任务复杂度、领域覆盖度和评估准确度。综合来看,M2.5 与 Opus 4.5 表现相当。
MiniMax 关注了模型在不同 scaffolding 上的泛化性。在 SWE-Bench Verified 评测集上,使用不同的编码 Agent scaffolding 进行了测试:
- 在 Droid 上:M2.5 为 79.7,超过 M2.1 的71.3分以及 Opus 4.6 的78.9分
- 在 OpenCode 上:M2.5 为76.1,超过 M2.1 的72.0分和 Opus 4.6 的75.9分
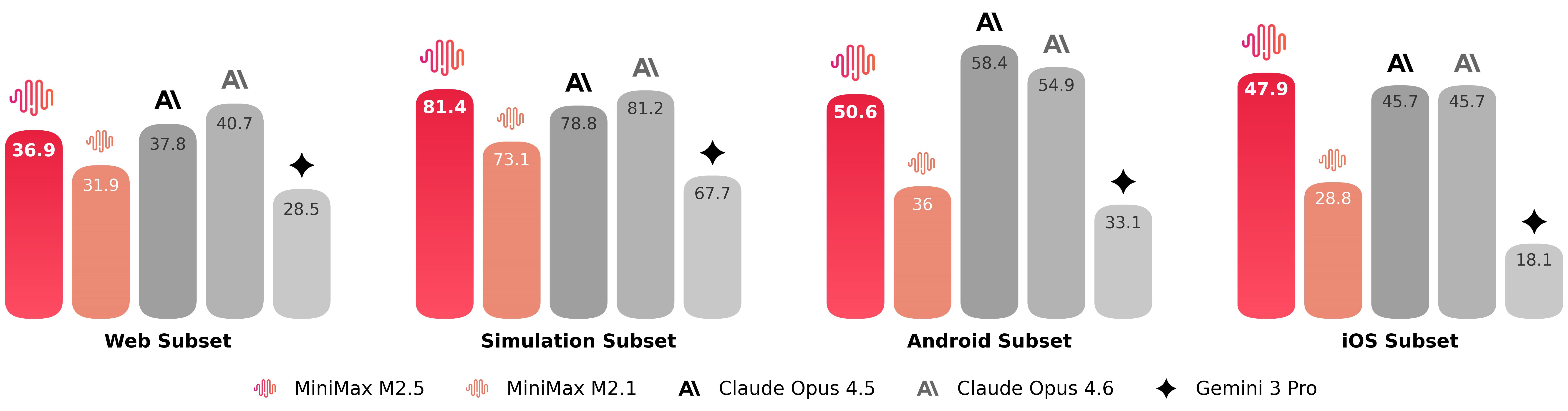
工具调用与搜索能力
(图片来源:MiniMax官方发布页面)
- BrowseComp: 76.3%(带上下文管理)
- RISE: 专家级搜索能力评估结果
速度与效率
由于真实世界充满了截止日期和时间约束,任务完成速度是实际必需的。模型完成任务的时间取决于其任务分解有效性、token 效率和推理速度。M2.5 原生以 100 tokens per second 的速率提供服务,这几乎是其他前沿模型的两倍。此外,MiniMax 的强化学习设置激励模型进行高效推理并最优地拆分任务。
例如,在运行 SWE-Bench Verified 时,M2.5 平均每个任务消耗 352万 tokens。相比之下,M2.1 消耗 372万 tokens。同时,由于并行工具调用等能力的改进,端到端运行时间从平均 31.3 分钟降低到 22.8 分钟,代表了 37% 的速度提升。这个运行时间与 Claude Opus 4.6 的 22.9 分钟相当,而每个任务的总成本仅为 Claude Opus 4.6 的 10%。
(图片来源:MiniMax官方发布页面)
定价和成本效益
MiniMax 设计 M2 系列基础模型的目标是支持复杂的 Agent 而不必担心成本。MiniMax 认为M2.5 接近实现这一目标。
M2.5 发布了两个版本:M2.5 和 M2.5-Lightning,它们在能力上完全相同,但在速度上有所差异。M2.5-Lightning 拥有 100 tokens per second 的稳定吞吐量,是其他前沿模型的两倍,成本为每百万输入 tokens 0.30 美元、每百万输出 tokens 2.40 美元。M2.5 的吞吐量为 50 tokens per second,成本减半。两个模型版本都支持缓存。根据输出价格,M2.5 的成本是 Opus、Gemini 3 Pro 和 GPT-5 的 1/10 到 1/20。
在每秒输出 100 tokens 的情况下,M2.5 连续工作一小时只需花费 1 美金。而在每秒 50 个 token 的情况下,价格降至 0.3 美金。这意味着你可以有四个 M2.5 实例连续工作一整年,成本仅为 10,000 美元。MiniMax 认为 M2.5 为经济中 Agent 的开发和运维提供了几乎无限的可能性。
| 模型 | 输入价格 | 输出价格 | 速度(TPS) | 成本倍数 |
|---|---|---|---|---|
| M2.5-Lightning | $0.30/M | $2.40/M | 100 | 1x |
| M2.5 | $0.15/M | $1.20/M | 50 | 0.5x |
| Claude Opus 4.5 | - | - | - | 10-20x |
内部应用案例
M2.5 已经在 MiniMax Agent 中完全部署,提供了最佳的 Agent 体验。MiniMax 将核心信息处理能力深度集成到标准化的 Office Skills 中,在 MiniMax Agent 内部。在 MAX 模式下,当处理 Word 格式化、PowerPoint 编辑、Excel 计算等任务时,MiniMax Agent 会自动加载相应的 Office Skills,提升任务输出的质量。
此外,用户可以将 Office Skills 与特定行业的专业知识相结合,创建可重用的专家(Experts),为特定的任务场景量身定制。
MiniMax 已经是 M2.5 能力的首批受益者。在整个公司的日常运营中,30% 的任务由 M2.5 自主完成,涵盖研发、产品、销售、HR、财务等功能------渗透率还在持续上升。在编程场景中的表现尤为显著,M2.5 生成的代码占新提交代码的 80%。
总结
MiniMax M2.5 是一个为真实世界生产力而生的前沿模型。它的核心优势在于:
- SOTA 级别的性能:在 SWE-Bench Verified(80.2%)、Multi-SWE-Bench(51.3%)、BrowseComp(76.3%)等关键 benchmark 中达到行业顶尖水平。
- 性价比领先:成本仅为 Opus、Gemini 3 Pro、GPT-5 等模型的 1/10 到 1/20,支持大规模 Agent 应用。
- 极速响应:100 TPS 的输出速度,37% 的任务完成速度提升。
- 真实世界验证:经过 200,000+ 真实环境训练,并在 MiniMax 内部完成 30% 的任务。
- 完整开发生命周期:从 0-1 系统设计到 90-100 code review 的全流程覆盖。
适用人群:M2.5 特别适合需要高频调用 API 的开发者、构建 Agent 应用的团队,以及对成本敏感但需要高性能的用户。
与 Claude Opus 系列相比,M2.5 在编程和 Agent 能力上表现相当,但具有显著的性价比优势;与 GPT-5 和 Gemini 3 Pro 相比,M2.5 在聚焦生产力的场景中提供了更强的竞争力。