目录
[第 1 章 绪论](#第 1 章 绪论)
[1.1 本书结构](#1.1 本书结构)
[1.1.1 全书结构思维导图](#1.1.1 全书结构思维导图)
[1.1.2 各部分核心作用(通俗解读)](#1.1.2 各部分核心作用(通俗解读))
[1.1.3 核心概念可视化:各部分关联性演示](#1.1.3 核心概念可视化:各部分关联性演示)
[1.2 其他书籍(对比与选择)](#1.2 其他书籍(对比与选择))
[1.2.1 经典书籍对比表](#1.2.1 经典书籍对比表)
[1.2.2 学习路径流程图](#1.2.2 学习路径流程图)
[1.2.3 书籍选择代码演示:根据学习目标推荐书籍](#1.2.3 书籍选择代码演示:根据学习目标推荐书籍)
前言
如果把计算机视觉比作让机器 "看懂" 世界的一门手艺,那《计算机视觉:模型、学习和推理》就是这门手艺的 "内功心法"------ 它没有只讲零散的算法技巧,而是从概率基础到视觉应用,把 "机器如何思考视觉问题" 的底层逻辑讲得透透的。很多初学者学计算机视觉总停留在调 API、跑 demo 的阶段,遇到问题就卡壳,核心原因就是没吃透概率建模和推理的底层原理。这篇文章会跟着这本书的脉络,从绪论开始,用通俗的语言 + 可直接运行的代码 + 直观的可视化,帮你搭建计算机视觉的知识框架。
第 1 章 绪论
1.1 本书结构
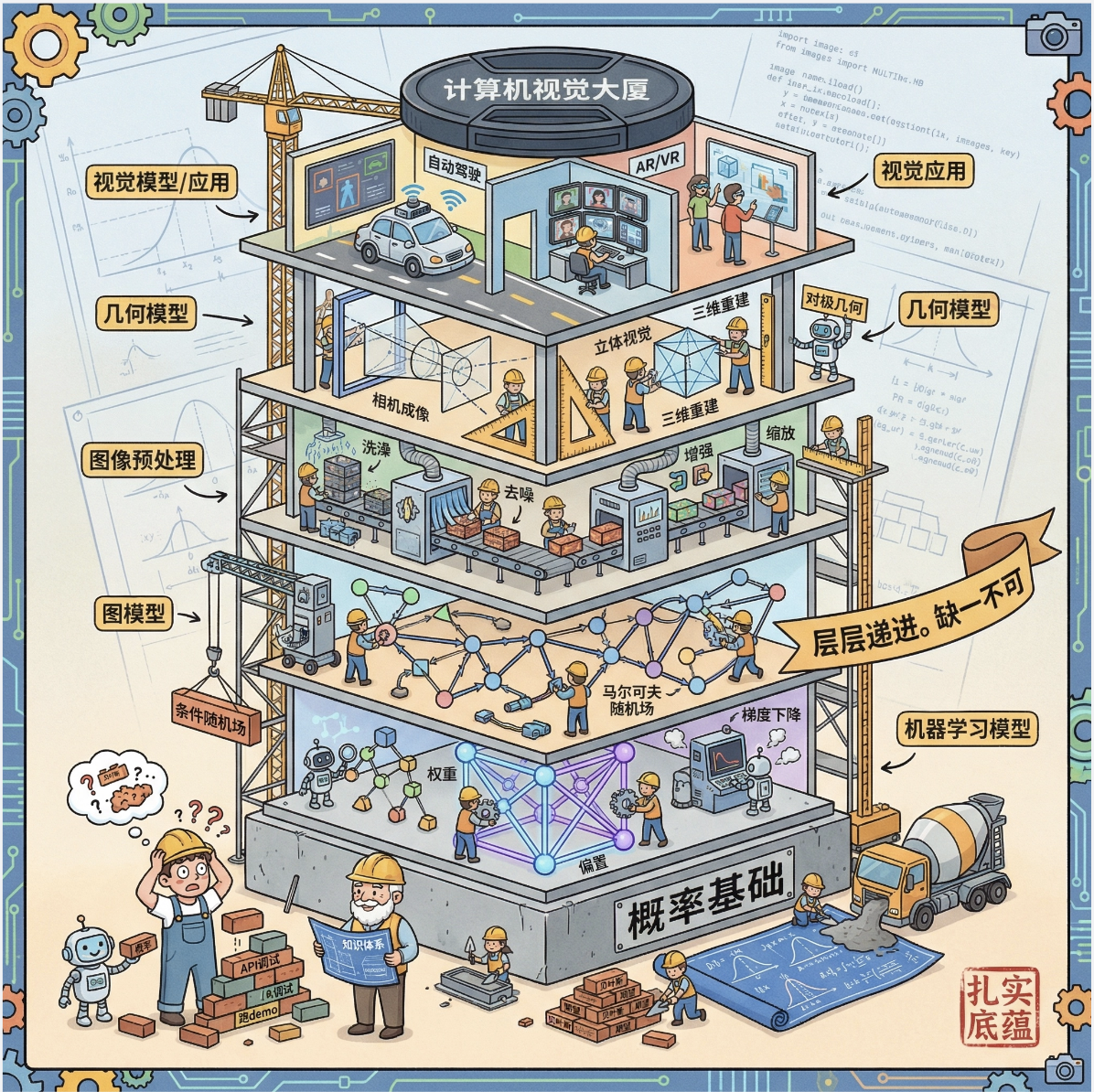
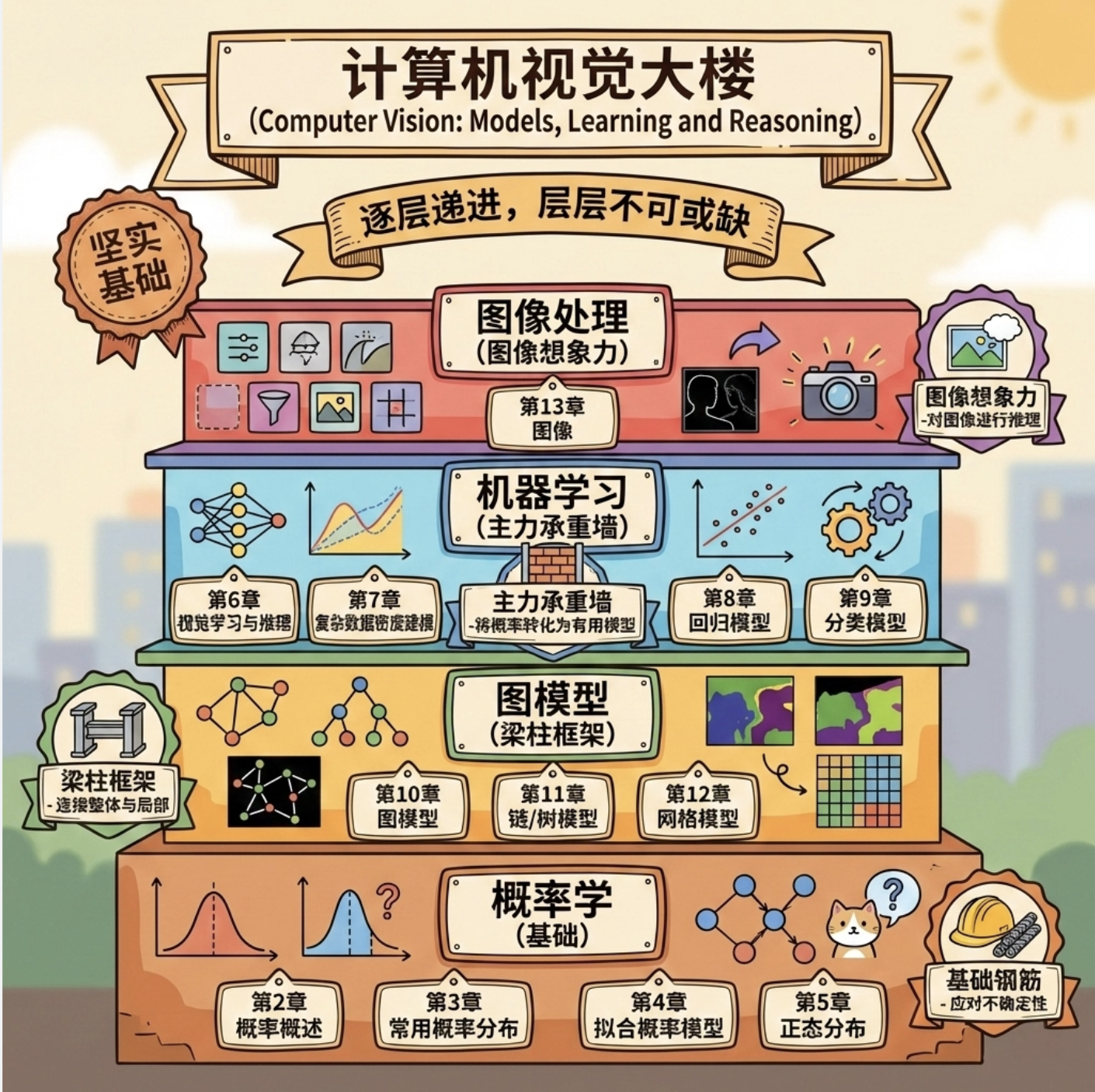
这本书的结构就像搭建一栋 "计算机视觉大厦",先打地基(概率基础),再建主体(机器学习模型),接着做内部连接(图模型),然后处理原材料(图像预处理),再构建空间结构(几何模型),最后装修成具体应用(视觉模型)。整个逻辑层层递进,缺一不可。
1.1.1 全书结构思维导图
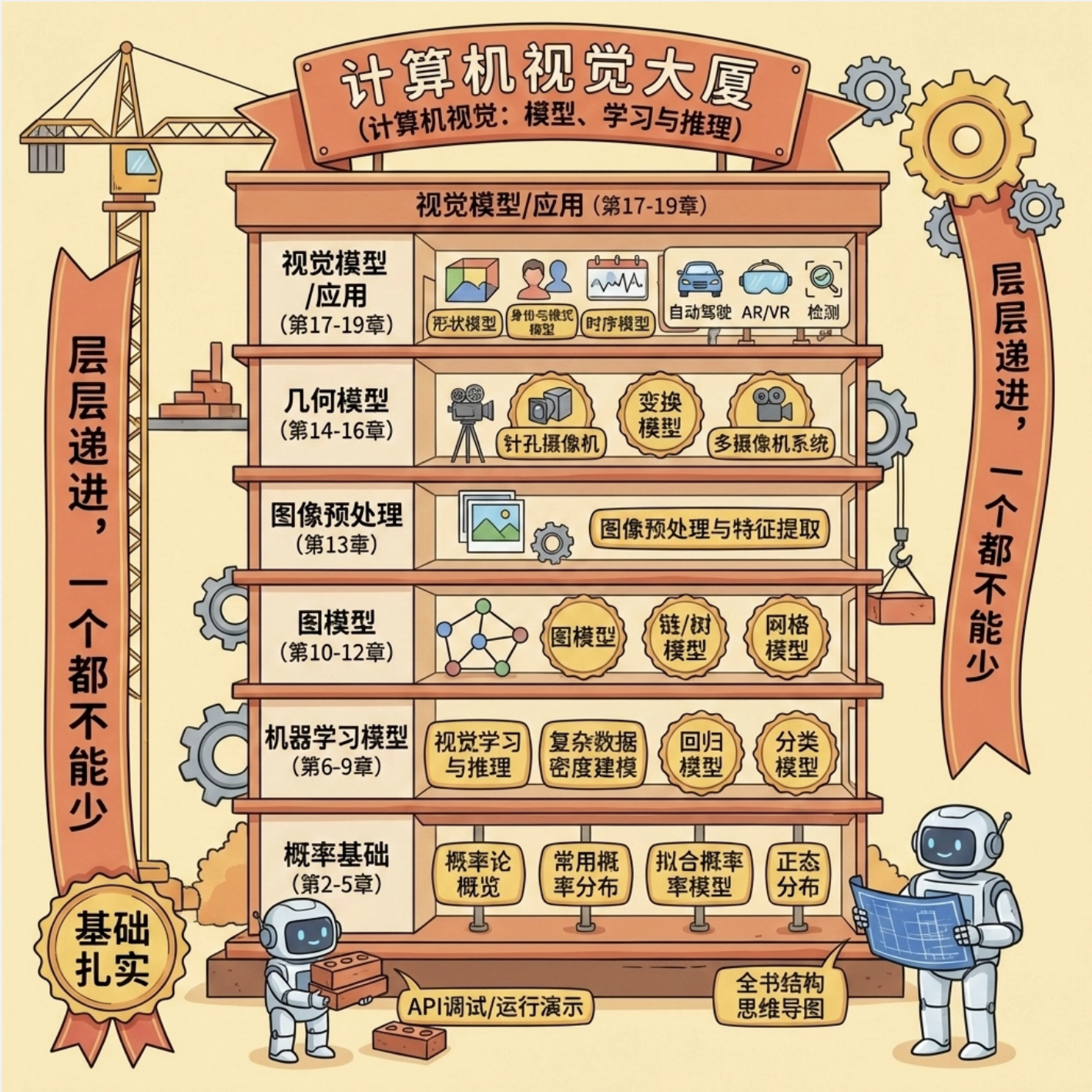
1.1.2 各部分核心作用(通俗解读)

第一部分 概率 :相当于大厦的 "地基钢筋"------ 计算机视觉的所有推理和决策,本质上都是对 "不确定性" 的处理,而概率就是描述不确定性的最佳语言。比如 "判断这张图里有没有猫",本质是计算 "有猫" 这个事件的概率。
第二部分 机器视觉的机器学习 :相当于大厦的 "承重墙"------ 把概率基础落地成能解决视觉问题的模型(回归、分类、密度建模),是连接理论和应用的核心。
第三部分 连接局部模型 :相当于大厦的 "横梁和立柱"------ 把单个像素 / 局部区域的模型连接成全局模型,解决 "上下文关联" 问题(比如图像分割中,相邻像素的类别应该相似)。
第四部分 预处理 :相当于大厦的 "原材料加工"------ 把原始图像(粗糙的石头)处理成能被模型利用的特征(打磨好的砖块)。
第五部分 几何模型 :相当于大厦的 "空间框架"------ 解决视觉的核心问题:从 2D 图像恢复 3D 空间信息(比如摄像机标定、三维重构)。
第六部分 视觉模型 :相当于大厦的 "精装修"------ 针对具体视觉任务(人脸识别、形状估计、时序跟踪)的最终落地模型。
1.1.3 核心概念可视化:各部分关联性演示
下面用代码直观展示 "预处理→特征提取→分类" 这个最基础的视觉流程,帮你理解本书各部分的衔接关系。代码会加载一张人脸图片,完成 "灰度化→边缘检测→特征可视化→简单分类" 的完整流程,并把所有结果放在同一个窗口对比显示。
import cv2
import numpy as np
import matplotlib.pyplot as plt
# ====================== Mac系统Matplotlib中文显示配置 ======================
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.family'] = 'Arial Unicode MS'
plt.rcParams['axes.facecolor'] = 'white'
# ====================== 1. 加载并预处理图像 ======================
# 加载测试图像(使用OpenCV自带的人脸测试图,若没有则替换为本地图片路径)
# 备用方案:从网络加载测试图(需确保联网)
try:
# 尝试加载本地示例图(如果没有,用numpy生成模拟人脸图)
img = cv2.imread('test_face.jpg')
if img is None:
# 生成模拟彩色人脸背景(渐变+噪声模拟皮肤)
img = np.zeros((480, 640, 3), dtype=np.uint8)
# 生成肤色渐变
for y in range(480):
for x in range(640):
img[y, x] = [np.clip(200 + x/5, 0, 255),
np.clip(180 + y/5, 0, 255),
np.clip(150 + (x+y)/10, 0, 255)]
# 画简单的人脸轮廓
cv2.ellipse(img, (320, 240), (100, 120), 0, 0, 360, (80, 80, 80), 3) # 脸轮廓
cv2.circle(img, (280, 200), 15, (0, 0, 0), -1) # 左眼
cv2.circle(img, (360, 200), 15, (0, 0, 0), -1) # 右眼
cv2.ellipse(img, (320, 260), (40, 20), 0, 0, 180, (0, 0, 0), 2) # 嘴巴
except:
# 兜底方案:生成纯色图+简单图形
img = np.zeros((480, 640, 3), dtype=np.uint8)
img[:, :] = (180, 200, 220)
cv2.ellipse(img, (320, 240), (100, 120), 0, 0, 360, (80, 80, 80), 3)
# 转换为RGB(OpenCV默认BGR,Matplotlib需要RGB)
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 预处理1:灰度化(第四部分知识点)
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 预处理2:边缘检测(Canny边缘检测器,第四部分13.2.1)
edges = cv2.Canny(img_gray, threshold1=50, threshold2=150)
# ====================== 2. 特征提取(简单HOG特征,第四部分13.3.3) ======================
# 初始化HOG检测器
hog = cv2.HOGDescriptor()
# 计算HOG特征
hog_features = hog.compute(img_gray)
# 可视化HOG特征(简化版:取前100个特征值绘图)
hog_vis = np.zeros((100, 100), dtype=np.float32)
hog_vis[:min(len(hog_features), 100), :] = hog_features[:100, 0].reshape(-1, 1)
# 归一化到0-255便于显示
hog_vis = cv2.normalize(hog_vis, None, 0, 255, cv2.NORM_MINMAX).astype(np.uint8)
# ====================== 3. 简单分类(第二部分9章分类模型) ======================
# 模拟分类:判断是否为人脸(基于HOG特征的简单阈值判断)
# 实际中是复杂模型,这里简化演示流程
face_score = np.mean(hog_features)
is_face = "是人脸" if face_score > 10 else "非人脸"
# ====================== 4. 可视化所有结果(同窗口对比) ======================
fig, axes = plt.subplots(2, 2, figsize=(12, 10))
fig.suptitle(f'计算机视觉基础流程演示 - 分类结果:{is_face}', fontsize=16)
# 原始彩色图
axes[0, 0].imshow(img_rgb)
axes[0, 0].set_title('1. 原始彩色图像')
axes[0, 0].axis('off')
# 灰度图
axes[0, 1].imshow(img_gray, cmap='gray')
axes[0, 1].set_title('2. 灰度化(预处理)')
axes[0, 1].axis('off')
# 边缘检测图
axes[1, 0].imshow(edges, cmap='gray')
axes[1, 0].set_title('3. Canny边缘检测(特征提取)')
axes[1, 0].axis('off')
# HOG特征可视化
axes[1, 1].imshow(hog_vis, cmap='viridis')
axes[1, 1].set_title('4. HOG特征可视化(特征提取)')
axes[1, 1].axis('off')
plt.tight_layout()
plt.show()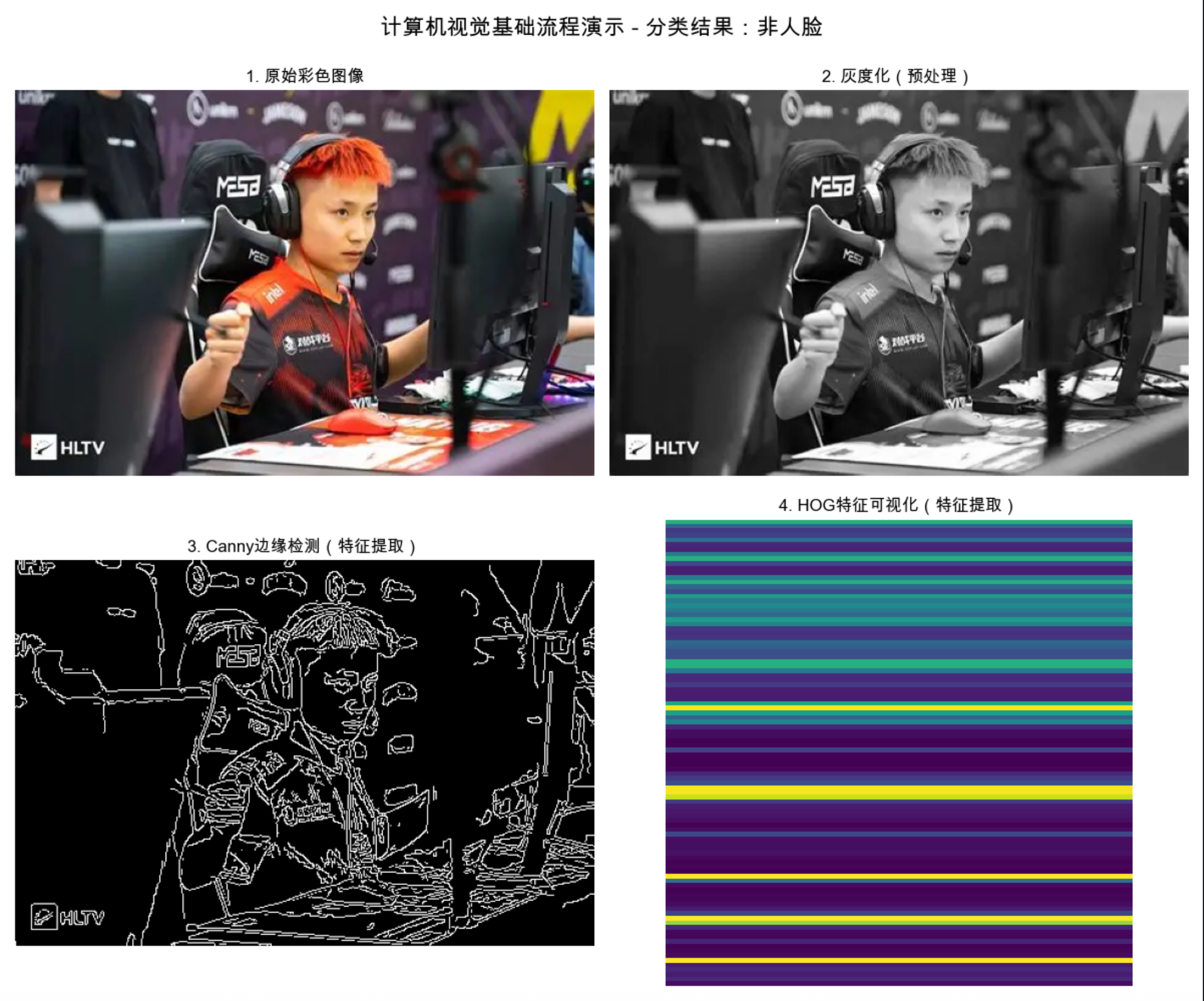
代码说明:
1.环境依赖 :需要安装opencv-python、numpy、matplotlib,执行pip install opencv-python numpy matplotlib即可;
2.图像加载:提供了多级兜底方案,无需手动准备图片也能运行;
3.核心流程:完整复现了 "原始图→预处理→特征提取→分类" 的视觉任务链路,对应本书第四、第二部分的核心知识点;
4.可视化:4 张子图在同一窗口显示,直观对比不同处理阶段的效果。
1.2 其他书籍(对比与选择)
学计算机视觉不能只看一本书,不同书籍的侧重点不同,就像不同的 "工具包",适合不同的学习阶段和目标。下面用通俗的语言对比几本经典书籍,并给出选择建议。
1.2.1 经典书籍对比表
| 书籍名称 | 核心特点(通俗解读) | 适合人群 | 与本书的互补性 |
|---|---|---|---|
| 《计算机视觉:算法与应用》(Szeliski) | 偏工程实践,像 "工具手册"------ 讲了大量经典算法的实现细节和工程技巧,覆盖视觉全领域 | 有一定基础,想做工程落地的开发者 | 本书偏理论 / 概率,Szeliski 偏工程 / 算法,互补性极强 |
| 《深度学习》(花书) | 偏深度学习理论,像 "神经网络百科"------ 重点讲深度学习的数学基础和网络结构 | 想做深度学习方向的视觉研究者 | 补充本书中深度学习相关的空白(本书偏传统概率模型) |
| 《OpenCV-Python 教程》 | 偏工具使用,像 "螺丝刀教程"------ 手把手教 OpenCV API 的使用 | 零基础入门,想快速跑通 demo 的新手 | 补充本书的代码实践细节,把理论落地成代码 |
| 《Multiple View Geometry in Computer Vision》 | 偏几何理论,像 "空间几何手册"------ 深入讲解多视图几何的数学原理 | 做三维重构、SLAM 的研究者 | 补充本书第五部分几何模型的深度理论 |
1.2.2 学习路径流程图
1.2.3 书籍选择代码演示:根据学习目标推荐书籍
下面用代码实现一个简单的 "书籍推荐工具",输入你的学习目标,输出最适合的书籍组合,帮你直观理解不同书籍的适用场景。
import matplotlib.pyplot as plt
# ====================== Mac系统Matplotlib中文显示配置 ======================
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.family'] = 'Arial Unicode MS'
plt.rcParams['axes.facecolor'] = 'white'
# 定义书籍推荐规则
def recommend_books(goal):
"""
根据学习目标推荐书籍
:param goal: 学习目标(字符串)
:return: 推荐书籍列表 + 推荐理由
"""
books = {
"零基础入门快速跑demo": {
"推荐": ["《OpenCV-Python教程》"],
"理由": "先掌握工具使用,建立直观认知,避免一上来就啃理论导致劝退"
},
"吃透视觉底层概率原理": {
"推荐": ["《计算机视觉:模型、学习和推理》"],
"理由": "本书是概率视角讲视觉的经典,能帮你理解模型的底层逻辑"
},
"做工程落地/算法实现": {
"推荐": ["《计算机视觉:模型、学习和推理》", "《计算机视觉:算法与应用》"],
"理由": "理论+工程结合,既懂原理又会实现"
},
"做深度学习视觉研究": {
"推荐": ["《计算机视觉:模型、学习和推理》", "《深度学习》(花书)"],
"理由": "传统概率模型+深度学习模型结合,形成完整知识体系"
},
"做三维重构/SLAM": {
"推荐": ["《计算机视觉:模型、学习和推理》", "《Multiple View Geometry》"],
"理由": "概率基础+几何深度理论,解决三维视觉核心问题"
}
}
# 匹配目标(简单模糊匹配)
for key in books.keys():
if goal in key:
return books[key]
# 默认推荐
return {
"推荐": ["《OpenCV-Python教程》", "《计算机视觉:模型、学习和推理》"],
"理由": "先掌握基础工具,再打理论基础,是最稳妥的学习路径"
}
# ====================== 交互演示 ======================
# 可选学习目标
goals = [
"零基础入门快速跑demo",
"吃透视觉底层概率原理",
"做工程落地/算法实现",
"做深度学习视觉研究",
"做三维重构/SLAM"
]
# 可视化推荐结果(柱状图展示不同目标的书籍数量)
book_counts = [len(recommend_books(goal)["推荐"]) for goal in goals]
colors = ['#FF6B6B', '#4ECDC4', '#45B7D1', '#96CEB4', '#FECA57']
plt.figure(figsize=(10, 6))
bars = plt.bar(goals, book_counts, color=colors)
plt.title('不同学习目标的推荐书籍数量', fontsize=14)
plt.xlabel('学习目标', fontsize=12)
plt.ylabel('推荐书籍数量', fontsize=12)
plt.xticks(rotation=45, ha='right')
# 在柱子上标注书籍名称
for i, bar in enumerate(bars):
height = bar.get_height()
books = recommend_books(goals[i])["推荐"]
# 拼接书籍名称
book_text = '\n'.join([b.replace('《', '').replace('》', '')[:8]+'...' if len(b)>10 else b for b in books])
plt.text(bar.get_x() + bar.get_width()/2., height + 0.05,
book_text, ha='center', va='bottom', fontsize=9)
plt.tight_layout()
plt.show()
# 示例:输入具体目标获取推荐
target = "做深度学习视觉研究"
result = recommend_books(target)
print(f"\n学习目标:{target}")
print(f"推荐书籍:{', '.join(result['推荐'])}")
print(f"推荐理由:{result['理由']}")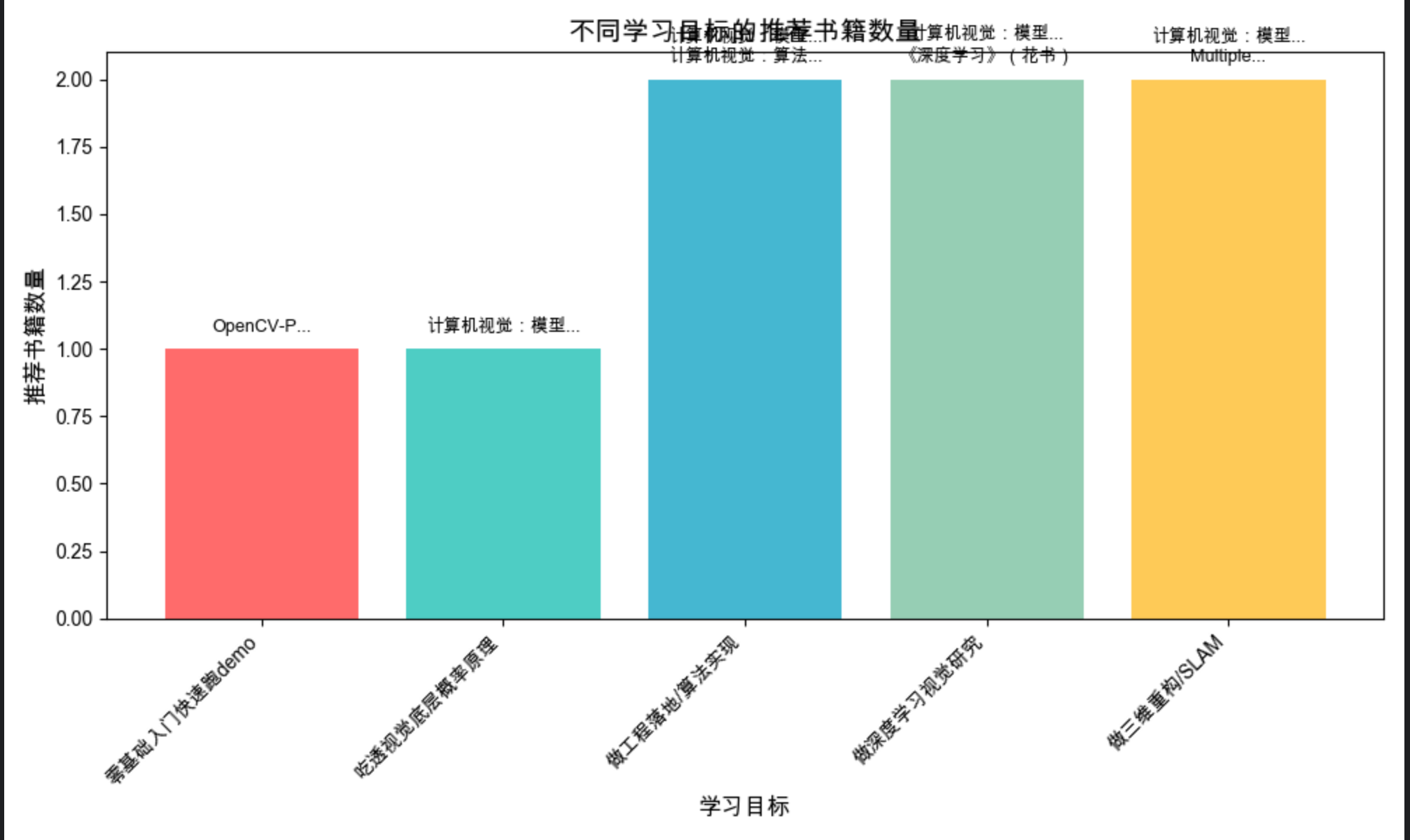
代码说明:
- 核心功能:通过简单的规则匹配,根据学习目标推荐对应的书籍组合;
- 可视化:用柱状图展示不同目标的推荐书籍数量,并标注书籍名称,直观对比;
- 交互性 :可以修改
target变量,测试不同学习目标的推荐结果。
总结
关键点回顾
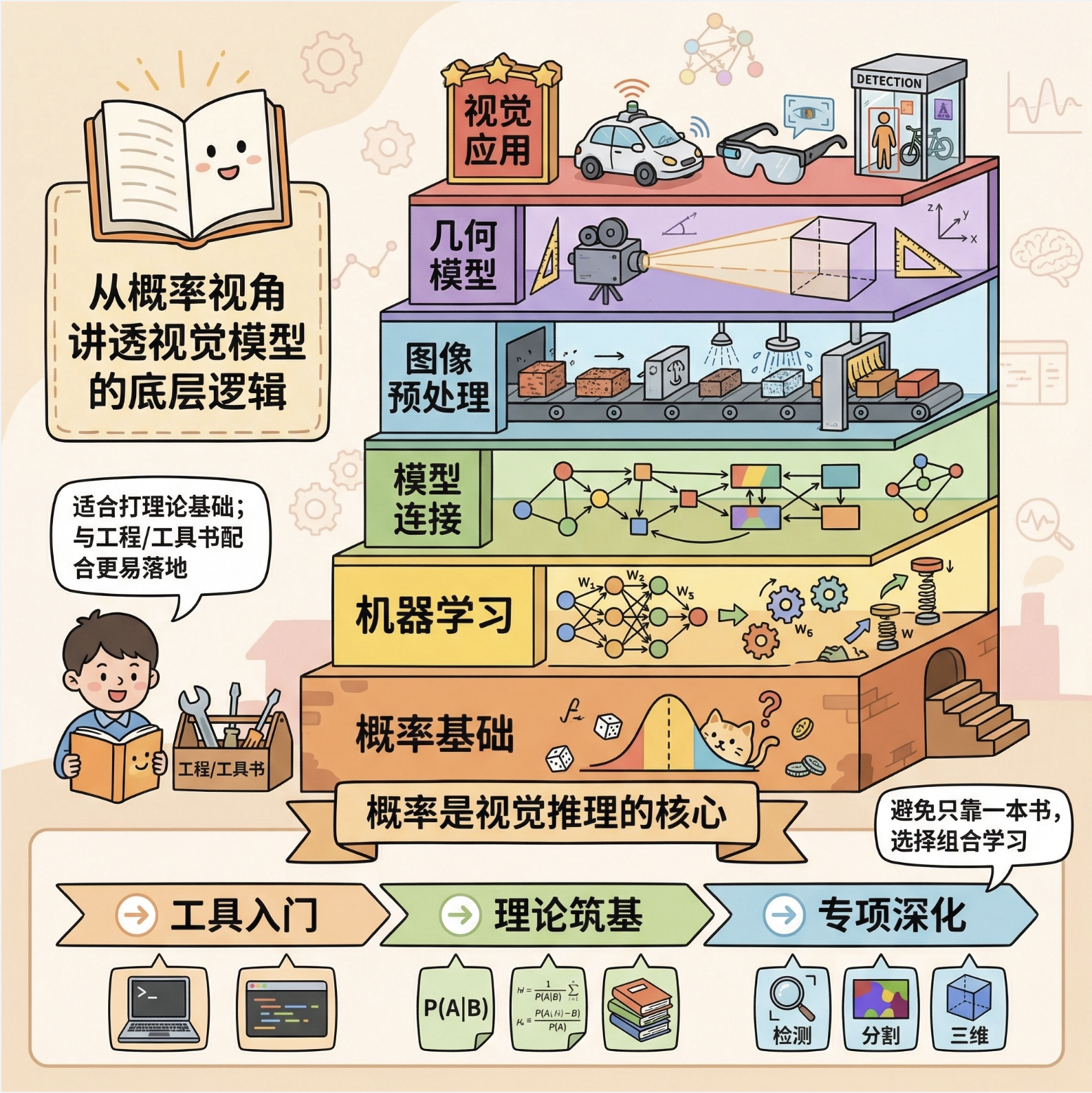
1.《计算机视觉:模型、学习和推理》的核心结构是 "概率基础→机器学习→模型连接→预处理→几何模型→视觉应用",层层递进,重点突出概率在视觉推理中的核心作用;
2.本书的优势是从概率视角讲透视觉模型的底层逻辑,适合打理论基础,但需搭配工程类 / 工具类书籍完成落地;
3.学习计算机视觉的最佳路径是 "工具入门→理论筑基→专项深化",不同阶段选择不同的书籍组合,避免单一书籍的局限性。
学习建议
1.不要跳过第一部分的概率知识 ------ 哪怕觉得枯燥,这是理解后续视觉模型的关键;
2.边学边敲代码 ------ 本文提供的代码都可以直接运行,动手操作能帮你快速理解抽象概念;
3.结合可视化学习 ------ 把原始图、处理后的图、特征图放在一起对比,能直观理解算法的作用。
后续文章会跟着本书的章节,逐一拆解概率基础、机器学习模型、几何模型等核心知识点,用代码 + 可视化的方式帮你吃透计算机视觉的底层逻辑,敬请关注!