LeNet创建了深度学习的火把,而AlexNet点亮了深度学习的火把!!
AlexNet 正是对 LeNet 的直接传承和全面升级,是"更深、更大、更强"的现代版本。可以说,AlexNet 是 LeNet 在 2012 年的"完全体"。
1 核心改进对比

2 具体的"改进链"
2.1 卷积结构继承
LeNet: 2个卷积-池化对
Conv1 -> Pool1 -> Conv2 -> Pool2 -> FC
AlexNet: 5个卷积层(3个带池化)
Conv1 -> Pool1 -> Conv2 -> Pool2 -> Conv3 -> Conv4 -> Conv5 -> Pool3 -> FC
AlexNet 保持了 LeNet 的"卷积-池化-全连接"基本架构,但加宽加深了卷积层。
2.2 激活函数革命
LeNet: Sigmoid (有梯度消失问题)
nn.Sigmoid()
AlexNet: ReLU (无梯度消失)
nn.ReLU(inplace=True)
这是最关键的技术突破。ReLU 让训练深层网络成为可能。
2.3 正则化机制
LeNet: 无正则化 -> 容易过拟合
AlexNet: Dropout (全连接层)
nn.Dropout(p=0.5) # 随机"关闭"50%神经元
Dropout 是解决大型网络过拟合的利器。
2.4 数据增强
LeNet 只有简单的归一化,
AlexNet 引入了:
随机裁剪
水平翻转
颜色扰动。
这些技巧人工扩大了训练数据。
3 pytorch代码简单实现
c
import torch
import torch.nn as nn
class AlexNet(nn.Module):
def __init__(self, num_classes=1000):
"""
AlexNet 网络结构
输入尺寸:3 x 224 x 224
原始论文结构:
- 5个卷积层(包含池化)
- 3个全连接层
"""
super(AlexNet, self).__init__()
# 第一部分:特征提取(卷积+池化)
self.features = nn.Sequential(
# 第1层卷积:输入[3, 224, 224] -> 输出[96, 55, 55]
# 公式:floor((224 - 11 + 2*2) / 4) + 1 = 55
nn.Conv2d(
in_channels=3, # 输入通道:RGB三通道
out_channels=96, # 输出通道:96个卷积核
kernel_size=11, # 卷积核大小:11x11
stride=4, # 步长:4
padding=2 # 填充:2(左右各2,上下各2)
),
nn.ReLU(inplace=True), # 使用ReLU激活,inplace=True节省内存
# 第1层池化:输入[96, 55, 55] -> 输出[96, 27, 27]
# 公式:floor((55 - 3) / 2) + 1 = 27
nn.MaxPool2d(
kernel_size=3, # 池化窗口:3x3
stride=2 # 步长:2(重叠池化)
),
# 第2层卷积:输入[96, 27, 27] -> 输出[256, 27, 27]
# 公式:floor((27 - 5 + 2*2) / 1) + 1 = 27
nn.Conv2d(96, 256, kernel_size=5, padding=2), # 保持27x27尺寸不变
nn.ReLU(inplace=True),
# 第2层池化:输入[256, 27, 27] -> 输出[256, 13, 13]
# 公式:floor((27 - 3) / 2) + 1 = 13
nn.MaxPool2d(kernel_size=3, stride=2),
# 第3层卷积:输入[256, 13, 13] -> 输出[384, 13, 13]
nn.Conv2d(256, 384, kernel_size=3, padding=1), # 保持13x13尺寸不变
nn.ReLU(inplace=True),
# 第4层卷积:输入[384, 13, 13] -> 输出[384, 13, 13]
nn.Conv2d(384, 384, kernel_size=3, padding=1), # 保持13x13尺寸不变
nn.ReLU(inplace=True),
# 第5层卷积:输入[384, 13, 13] -> 输出[256, 13, 13]
nn.Conv2d(384, 256, kernel_size=3, padding=1), # 保持13x13尺寸不变
nn.ReLU(inplace=True),
# 第3层池化:输入[256, 13, 13] -> 输出[256, 6, 6]
# 公式:floor((13 - 3) / 2) + 1 = 6
nn.MaxPool2d(kernel_size=3, stride=2),
)
# 第二部分:分类器(全连接层)
self.classifier = nn.Sequential(
# Dropout层1:训练时随机丢弃50%的神经元
nn.Dropout(p=0.5),
# 全连接层1:输入9216 -> 输出4096
# 输入尺寸:256 * 6 * 6 = 9216
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
# Dropout层2:训练时随机丢弃50%的神经元
nn.Dropout(p=0.5),
# 全连接层2:输入4096 -> 输出4096
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
# 输出层:输入4096 -> 输出num_classes
nn.Linear(4096, num_classes),
# 注意:这里没有Softmax,因为CrossEntropyLoss会自动加Softmax
)
# 可选的权重初始化
self._initialize_weights()
def _initialize_weights(self):
"""权重初始化(可选,但建议使用)"""
for m in self.modules():
if isinstance(m, nn.Conv2d):
# 卷积层使用Kaiming初始化(适配ReLU)
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
# 全连接层使用正态分布初始化
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
def forward(self, x):
"""
前向传播
输入:x [batch_size, 3, 224, 224]
输出:x [batch_size, num_classes]
"""
# 1. 特征提取
x = self.features(x) # -> [batch_size, 256, 6, 6]
# 2. 展平
x = torch.flatten(x, 1) # -> [batch_size, 256*6*6=9216]
# 3. 分类
x = self.classifier(x) # -> [batch_size, num_classes]
return x
# 使用示例
if __name__ == "__main__":
# 创建模型实例
model = AlexNet(num_classes=1000)
# 打印网络结构
print("AlexNet 结构:")
print(model)
# 模拟输入:batch_size=4, 3通道, 224x224
dummy_input = torch.randn(4, 3, 224, 224)
# 前向传播
with torch.no_grad():
output = model(dummy_input)
print(f"\n输入尺寸: {dummy_input.shape}")
print(f"输出尺寸: {output.shape}") # 应为 [4, 1000]
print(f"参数量: {sum(p.numel() for p in model.parameters()) / 1e6:.2f}M")4 为什么 AlexNet 成功而 LeNet 被遗忘?
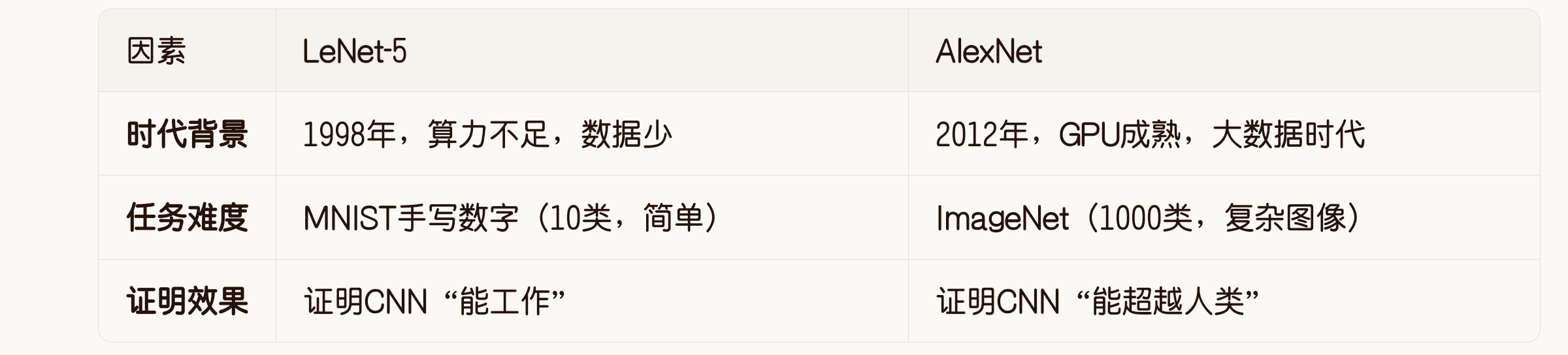
关键点:LeNet 证明了 CNN 的理论可行性,但受限于当时的硬件和数据,只能解决简单问题。AlexNet 在 14 年后,用大数据 + 强算力 + 技术改进,证明了 CNN 在复杂问题上的实用性。
5 技术演进关系
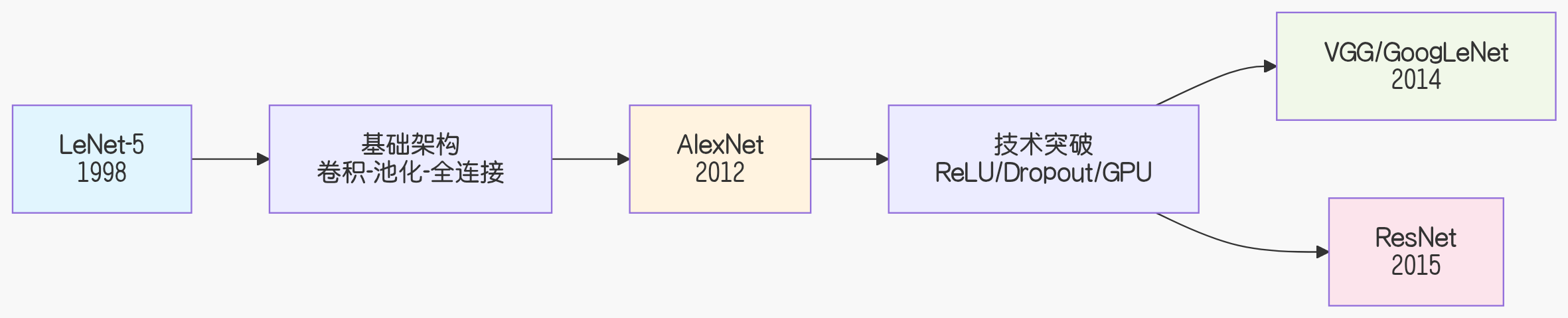 传承关系:
传承关系:
LeNet 创造了 CNN 基础架构
AlexNet 证明了 CNN 实用价值
后续网络在 AlexNet 基础上继续深化
6 一个生动的比喻
LeNet 像是第一架飞机(莱特兄弟):证明了"能飞起来",但只能飞几十米。
AlexNet 像是第一架喷气式客机:用新引擎(ReLU/GPU)、新材料(大数据)、新设计(Dropout),真正实现了"商业飞行"。
后来者(VGG/ResNet)则是现代客机:更快、更大、更安全。
7 影响
AlexNet 在 2012 年 ImageNet 竞赛的横空出世,引发的影响是核弹级别的。它不仅仅是一个模型,更是引爆整个 AI 浪潮的导火索,彻底重塑了人工智能的研究、产业和认知。
7.1 对学术研究:范式革命
核心影响:证明了"大数据 + 大算力 + 深度网络"这条技术路线的绝对优越性。
传统方法集体出局:在 AlexNet 夺冠前,ImageNet 竞赛是 SIFT、HOG 等"手工特征 + 传统分类器"的天下。AlexNet 后,2013 年所有顶尖队伍全部转向 CNN,传统计算机视觉方法几乎在一夜之间被淘汰。
研究方向剧变:
从"特征工程"到"结构工程":研究者不再费心设计特征提取器,转而设计更深的网络结构(VGG, 19层)、更复杂的模块(GoogLeNet, Inception)、更巧妙的训练技巧(ResNet, 残差连接)。
论文井喷:CVPR、ICCV 等顶会中,基于深度学习的论文占比从个位数飙升至超过 90%。
7.2 对工业界:算力军备竞赛与产业重构
核心影响:让AI从实验室玩具变成了可落地的核心技术。
硬件革命:
GPU 登上王座:NVIDIA 的股价在随后十年上涨超过 100 倍。GPU 从"游戏显卡"变为"AI 计算卡",催生了 A100、H100 等专为 AI 设计的芯片。
算力即权力:Google、Facebook、百度等巨头开始疯狂建设 GPU/TPU 集群,算力成为核心战略资源。
人才争夺战:
2013 年,Google 以 4400 万美元 收购了 AlexNet 作者 Hinton 创办的 DNNresearch 公司(实质上是为了获取 Hinton 及其两位学生 Alex Krizhevsky 和 Ilya Sutskever)。
AI 博士的身价暴涨,企业研究院(FAIR, Google Brain, MSR)成为顶尖人才的聚集地。
开启AI商业化浪潮:
计算机视觉:人脸识别、安防、医疗影像分析。
自然语言处理:Word2Vec (2013)、Transformer (2017) 都受其启发。
自动驾驶:感知系统全面转向深度学习。
7.3. 对技术发展:定义了现代深度学习的基础范式
AlexNet 确立的"标准配方"沿用至今:
ReLU 成为标配:解决了深度网络训练的梯度消失问题。
Dropout 成为正则化利器:让大型网络不易过拟合。
GPU 训练成为标准流程:没有GPU,就没有现代深度学习。
大数据驱动:证明了模型性能与数据规模强相关。
开源与复现文化:论文公开代码成为常态,加速了社区进步。
7.4 对社会认知:AI 复兴的标志
媒体与资本:AlexNet 让"深度学习"登上《纽约时报》《经济学人》等主流媒体,吸引了全球资本疯狂涌入 AI 领域。
公众认知:从"AI 是科幻"变为"AI 是未来",直接推动了后续 AlphaGo、ChatGPT 等事件的社会关注。
7.5 一个简明的"影响链"
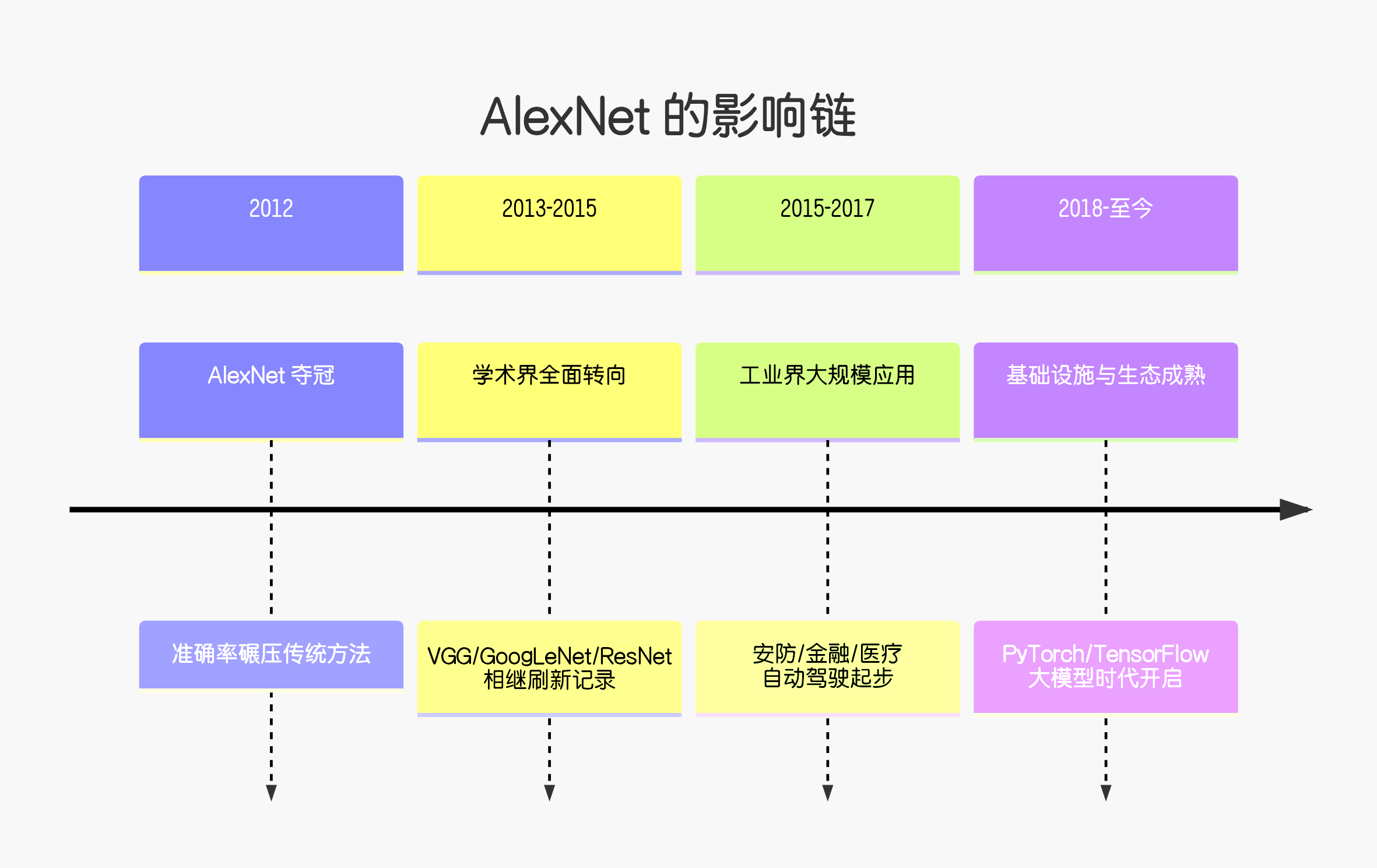
总结来说,AlexNet 的影响是全方位、颠覆性、持久的:
技术上:它终结了一个时代(传统CV),开启了一个新时代(深度学习)。
产业上:它创造了万亿美元的市场,催生了 NVIDIA 这样的巨头。
文化上:它让"端到端学习"、"大力出奇迹"成为AI研究的核心哲学。
没有 AlexNet 的成功,就不会有后来 AlphaGo 战胜李世石,也不会有今天 ChatGPT 的对话能力。它是人工智能从"冷冬"走向"盛夏"的真正转折点。
LeNet创建了深度学习的火把,而AlexNet点亮了深度学习的火把!!