K8S常见的控制器之Jobs和CronJobs
Jobs控制器
概念
所谓的Jobs就是K8S集群用于处理一次性任务的控制器。
编写资源清单
示例:简单打印一个句子
yaml
# 01-jobs-pi.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: jobs-py
spec:
# 定义Pod的模板
template:
spec:
containers:
- name: py
image: harbor250.oldboyedu.com/oldboyedu-casedemo/python:3.9.16-alpine3.16
command:
- python3
- -c
- "print('https://www.oldboyedu.com/')"
restartPolicy: Never
#never不重启
# 如果容器执行失败,则重试的次数,重试会重新创建新的Pod
backoffLimit: 4查看日志
bash
[root@master231 jobs]# kubectl logs -f jobs-py-rj228
https://www.oldboyedu.com/Pod的五个阶段
-
Pending(悬决)
- Pod已被Kubernetes系统接受,但有一个或者多个容器尚未创建亦未运行
- 此阶段包括等待Pod被调度的时间和通过网络下载镜像的时间
-
Running(运行中)
- Pod已经绑定到了某个节点,Pod中所有的容器都已被创建
- 至少有一个容器仍在运行,或者正处于启动或重启状态
-
Succeeded(成功)
- Pod中的所有容器都已成功终止,并且不会再重启
-
Failed(失败)
- Pod中的所有容器都已终止,并且至少有一个容器是因为失败终止
- 也就是说,容器以非0状态退出或者被系统终止,且未被设置为自动重启
-
Unknown(未知)
- 因为某些原因无法取得Pod的状态
- 这种情况通常是因为与Pod所在主机通信失败
K8S常见的控制器之CronJobs
概念
全称为"cronjobs",其并不直接管理Pod,而是底层周期性调用Job控制器。
编写资源清单
yaml
# 01-cj-demo.yaml
apiVersion: batch/v1
kind: CronJob
metadata:
name: hello
spec:
# 指定调度的周期,分别表示: 分,时,日,月,周
schedule: "* * * * *"
# 定义Job控制器的模板
jobTemplate:
spec:
template:
spec:
volumes:
- name: dt
hostPath:
path: /etc/localtime
containers:
- name: hello
image: harbor250.oldboyedu.com/oldboyedu-casedemo/busybox:1.28
volumeMounts:
- name: dt
mountPath: /etc/localtime
command:
- /bin/sh
- -c
- date -R; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure测试验证
bash
[root@master231 cronjobs]# kubectl apply -f 01-cj-demo.yaml
cronjob.batch/hello created
# 测试验证 cronjobs 创建job ,job创建po:会每分钟同步一次时间然后输出一次
[root@master231 cronjobs]# kubectl get cj,job,po
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
cronjob.batch/hello * * * * * False 0 7s 93s
NAME COMPLETIONS DURATION AGE
job.batch/hello-29312735 1/1 2s 67s
job.batch/hello-29312736 1/1 3s 7s
NAME READY STATUS RESTARTS AGE
pod/hello-29312735-qq642 0/1 Completed 0 67s
pod/hello-29312736-gt2lt 0/1 Completed 0 7s
[root@master231 cronjobs]# kubectl logs hello-29312735-qq642
Thu, 25 Sep 2025 09:35:00 +0800
Hello from the Kubernetes cluster
[root@master231 cronjobs]# kubectl logs hello-29312736-gt2lt # 很明显,时间相差1min
Thu, 25 Sep 2025 09:36:00 +0800
Hello from the Kubernetes cluster重点掌握
Pod长期处于Terminating的解决方案:基于etcd删除Pod
1. 部署测试服务
bash
[root@master231 pods]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master231 Ready control-plane,master 5d23h v1.23.17
worker232 Ready <none> 5d23h v1.23.17
worker233 Ready <none> 5d23h v1.23.17
[root@master231 pods]# cat 13-pods-nodeName.yaml
apiVersion: v1
kind: Pod
metadata:
name: xixi
spec:
nodeName: worker233
containers:
- name: c1
image: registry.cn-hangzhou.aliyuncs.com/yinzhengjie-k8s/apps:v2
[root@master231 pods]# kubectl apply -f 13-pods-nodeName.yaml
pod/xixi created
[root@master231 pods]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
xixi 1/1 Running 0 4s 10.100.2.185 worker233 <none> <none>2. 将指定节点关机模拟故障
bash
[root@worker233 ~]# init 03. 再次查看node和pod状态
bash
[root@master231 pods]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master231 Ready control-plane,master 5d23h v1.23.17
worker232 Ready <none> 5d23h v1.23.17
worker233 NotReady <none> 5d23h v1.23.17
[root@master231 pods]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
xixi 1/1 Running 0 93s 10.100.2.185 worker233 <none> <none>
[root@master231 pods]# kubectl describe pod xixi
# 最后一行 Warning NodeNotReady 2m4s node-controller Node is not ready
[root@master231 pods]# curl --connect-timeout 2 10.100.2.185 # 不难发现,此时Pod无法提供正常服务
curl: (28) Connection timeout after 2001 ms
[root@master231 pods]# kubectl delete pod xixi # 我们会发现无法删除该Pod
pod "xixi" deleted一直卡着4. 检查Pod状态
bash
[root@master231 ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
xixi 1/1 Terminating 0 8m26s 10.100.2.185 worker233 <none> <none>
[root@master231 ~]# kubectl describe pod xixi
Name: xixi
Namespace: default
Priority: 0
Node: worker233/10.0.0.233
Start Time: Thu, 25 Sep 2025 10:15:59 +0800
Labels: <none>
Annotations: <none>
Status: Terminating (lasts 2m4s) # 发现Pod处于正在终止状态,已经超过垃圾回收时间30s,已经耗时2m4s
Termination Grace Period: 30s # 30s后强行退出。
IP: 10.100.2.185
...
# 怎么办呢,数据存在etcd所以访问etcd5. 连接etcd数据库删除数据
bash
# 5.1 下载etcd的软件包
wget https://github.com/etcd-io/etcd/releases/download/v3.5.22/etcd-v3.5.22-linux-amd64.tar.gz
# 5.2 解压etcd的二进制程序包到PATH环境变量路径
[root@master231 ~]# tar -xf etcd-v3.5.22-linux-amd64.tar.gz -C /usr/local/bin etcd-v3.5.22-linux-amd64/etcdctl --strip-components=1
[root@master231 ~]# ll /usr/local/bin/etcd*
-rwxr-xr-x 1 yinzhengjie yinzhengjie 19062936 Jul 23 02:20 /usr/local/bin/etcdctl*
[root@master231 ~]# etcdctl version
etcdctl version: 3.5.22
API version: 3.5
# 5.3 检查etcd所在的worker节点
[root@master231 ~]# kubectl get pods -n kube-system -l component=etcd -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
etcd-master231 1/1 Running 9 (81m ago) 5d23h 10.0.0.231 master231 <none> <none>
[root@master231 ~]# ss -ntl | grep 2379
LISTEN 0 4096 127.0.0.1:2379 0.0.0.0:*
LISTEN 0 4096 10.0.0.231:2379 0.0.0.0:*
# 5.4 连接etcd集群:etcd后面指定的是认证文件和节点信息
[root@master231 ~]# etcdctl --endpoints="https://10.0.0.231:2379" --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/server.crt --key=/etc/kubernetes/pki/etcd/server.key endpoint status --write-out=table
+-------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS |
+-------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| https://10.0.0.231:2379 | 3b1681ce69008ae3 | 3.5.6 | 3.9 MB | true | false | 11 | 222010 | 222010 | |
+-------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
[root@master231 ~]# etcdctl --endpoints="https://10.0.0.231:2379" --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/server.crt --key=/etc/kubernetes/pki/etcd/server.key get "" --prefix --keys-only | grep -v "^$" | wc -l
675
# 5.5 删除etcd数据验证pod信息是否丢失
[root@master231 ~]# etcdctl --endpoints="https://10.0.0.231:2379" --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/server.crt --key=/etc/kubernetes/pki/etcd/server.key get "" --prefix --keys-only | grep pods
/registry/pods/default/xixi
/registry/pods/kube-flannel/kube-flannel-ds-7fpf5
/registry/pods/kube-flannel/kube-flannel-ds-kxcgq
/registry/pods/kube-flannel/kube-flannel-ds-vzx4x
/registry/pods/kube-system/coredns-6d8c4cb4d-s85bq
/registry/pods/kube-system/coredns-6d8c4cb4d-tdrnj
/registry/pods/kube-system/etcd-master231
/registry/pods/kube-system/kube-apiserver-master231
/registry/pods/kube-system/kube-controller-manager-master231
/registry/pods/kube-system/kube-proxy-55jhz
/registry/pods/kube-system/kube-proxy-7ffbs
/registry/pods/kube-system/kube-proxy-xgqln
/registry/pods/kube-system/kube-scheduler-master231
/registry/pods/metallb-system/controller-644c958987-9xbtc
/registry/pods/metallb-system/speaker-hfb5k
/registry/pods/metallb-system/speaker-p27z5
/registry/pods/metallb-system/speaker-vtxk8
[root@master231 ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
xixi 1/1 Terminating 0 20m 10.100.2.185 worker233 <none> <none>
# 删除这个报错的节点
[root@master231 ~]# etcdctl --endpoints="https://10.0.0.231:2379" --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/server.crt --key=/etc/kubernetes/pki/etcd/server.key del /registry/pods/default/xixi
1
[root@master231 ~]# kubectl get pods -o wide
No resources found in default namespace.
# 所以可以直接操作etcd,删除pod课堂练习之周期性备份etcd数据库
1. 准备镜像
bash
[root@master231 ~]# cp /usr/local/bin/etcdctl ./
[root@master231 ~]# cat Dockerfile
FROM registry.cn-hangzhou.aliyuncs.com/yinzhengjie-k8s/apps:v1
LABEL school=oldboyedu \
class=linux99 \
auther=JasonYin
COPY etcdctl /usr/local/bin
CMD ["tail","-f","/etc/hosts"]
[root@master231 ~]# docker build -t harbor250.oldboyedu.com/oldboyedu-casedemo/etcdctl:v1 .
[root@master231 ~]# docker push harbor250.oldboyedu.com/oldboyedu-casedemo/etcdctl:v1
# 温馨提示:不要使用官方的镜像,有坑,很多命令都没有,比如tail,sleep,date都没有!!!2. 准备etcd的证书文件
bash
[root@master231 ~]# mkdir -p /yinzhengjie/data/nfs-server/casedemo/etcd/certs
[root@master231 ~]# cp /etc/kubernetes/pki/etcd/{ca.crt,server.crt,server.key} /yinzhengjie/data/nfs-server/casedemo/etcd/certs
[root@master231 ~]# ll /yinzhengjie/data/nfs-server/casedemo/etcd/certs
total 20
drwxr-xr-x 2 root root 4096 Sep 25 10:42 ./
drwxr-xr-x 3 root root 4096 Sep 25 10:41 ../
-rw-r--r-- 1 root root 1086 Sep 25 10:42 ca.crt
-rw-r--r-- 1 root root 1200 Sep 25 10:42 server.crt
-rw------- 1 root root 1675 Sep 25 10:42 server.key3. 准备备份的数据目录
bash
[root@master231 ~]# mkdir /yinzhengjie/data/nfs-server/casedemo/etcd/backup4. 编写资源清单
yaml
# 03-cj-backup-etcd.yaml
apiVersion: batch/v1
kind: CronJob
metadata:
name: cj-backup-etcd
spec:
schedule: "* * * * *"
jobTemplate:
spec:
template:
spec:
# 就是将宿主机里的数据,挂载到容器里面,分别是时间,认证文件,快照数据,共享完直接在容器里面执行快照的命令
volumes:
- name: dt
hostPath:
path: /etc/localtime
- name: certs
nfs:
server: 10.0.0.231
path: /yinzhengjie/data/nfs-server/casedemo/etcd/certs
- name: data
nfs:
server: 10.0.0.231
path: /yinzhengjie/data/nfs-server/casedemo/etcd/backup
containers:
- name: hello
image: harbor250.oldboyedu.com/oldboyedu-casedemo/etcdctl:v1
volumeMounts:
- name: dt
mountPath: /etc/localtime
- name: certs
mountPath: /etc/kubernetes/pki/etcd
- name: data
mountPath: /oldboyedu/data
command:
- /bin/sh
- -c
- "etcdctl --endpoints='https://10.0.0.231:2379' --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/server.crt --key=/etc/kubernetes/pki/etcd/server.key snapshot save /oldboyedu/data/oldboyedu-etcd-$(date +%F_%T).backup"
restartPolicy: OnFailure5. 创建资源
bash
[root@master231 case-demo]# kubectl apply -f 03-cj-backup-etcd.yaml
cronjob.batch/cj-backup-etcd created
[root@master231 case-demo]# kubectl get cj,job,po -o wide
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE CONTAINERS IMAGES SELECTOR
cronjob.batch/cj-backup-etcd * * * * * False 1 2s 22s hello harbor250.oldboyedu.com/oldboyedu-casedemo/etcdctl:v1 <none>
NAME COMPLETIONS DURATION AGE CONTAINERS IMAGES SELECTOR
job.batch/cj-backup-etcd-29312860 0/1 2s 2s hello harbor250.oldboyedu.com/oldboyedu-casedemo/etcdctl:v1 controller-uid=cfcbf2df-9906-4cac-b7a3-a8a7cf94a923
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod/cj-backup-etcd-29312860-nwgvv 0/1 Completed 0 2s 10.100.1.110 worker232 <none> <none>6. 验证数据
bash
[root@master231 ~]# ll /yinzhengjie/data/nfs-server/casedemo/etcd/backup/
total 3820
drwxr-xr-x 2 root root 4096 Sep 25 11:43 ./
drwxr-xr-x 4 root root 4096 Sep 25 11:08 ../
-rw------- 1 root root 3899424 Sep 25 11:43 oldboyedu-etcd-2025-09-25_11:43:00.backup基于备份的数据进行还原K8S集群环境(故障面试题)生产环境一定要备份
1. 模拟故障,删除etcd的所有数据,直接node全没了
bash
[root@master231 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master231 Ready control-plane,master 6d v1.23.17
worker232 Ready <none> 6d v1.23.17
worker233 NotReady <none> 6d v1.23.17
[root@master231 ~]# etcdctl --endpoints="https://10.0.0.231:2379" --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/server.crt --key=/etc/kubernetes/pki/etcd/server.key del "" --prefix # 删除所有的数据
[root@master231 ~]# rm -rf /var/lib/etcd/*
[root@master231 ~]# reboot
[root@master231 ~]# ss -ntl | grep 2379
LISTEN 0 4096 10.0.0.231:2379 0.0.0.0:*
LISTEN 0 4096 127.0.0.1:2379 0.0.0.0:*
[root@master231 ~]# kubectl get nodes -o wide # 很明显数据已经不准确啦!
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
master231 Ready <none> 60s v1.23.17 10.0.0.231 <none> Ubuntu 22.04.4 LTS 5.15.0-153-generic docker://20.10.242. 停止etcd服务
bash
[root@master231 ~]# cd /etc/kubernetes/manifests/ # 这是静态pod的目录
[root@master231 manifests]# ll
total 24
drwxr-xr-x 2 root root 4096 Sep 24 16:21 ./
drwxr-xr-x 4 root root 4096 Sep 19 11:03 ../
-rw------- 1 root root 2280 Sep 19 11:03 etcd.yaml
-rw------- 1 root root 4068 Sep 24 16:20 kube-apiserver.yaml
-rw------- 1 root root 3546 Sep 19 11:03 kube-controller-manager.yaml
-rw------- 1 root root 1465 Sep 19 11:03 kube-scheduler.yaml
[root@master231 manifests]# mv etcd.yaml /opt/ # 将启动的etcd的pod从静态pod目录移出先
[root@master231 manifests]# ss -ntl | grep 2379 # 此时etcd服务停止3. 恢复数据
bash
[root@master231 manifests]# mv /var/lib/etcd/ /opt/ # 之前的数据暂时备份,之前的数据移走
[root@master231 manifests]# ll /var/lib/etcd
ls: cannot access '/var/lib/etcd': No such file or directory
# 还原
[root@master231 manifests]# etcdctl --endpoints="https://10.0.0.231:2379" --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/server.crt --key=/etc/kubernetes/pki/etcd/server.key snapshot restore /yinzhengjie/data/nfs-server/casedemo/etcd/backup/oldboyedu-etcd-2025-09-25_11\:43\:00.backup --data-dir=/var/lib/etcd/
Deprecated: Use `etcdutl snapshot restore` instead.
2025-09-25T12:05:30+08:00 info snapshot/v3_snapshot.go:265 restoring snapshot {"path": "/yinzhengjie/data/nfs-server/casedemo/etcd/backup/oldboyedu-etcd-2025-09-25_11:43:00.backup", "wal-dir": "/var/lib/etcd/member/wal", "data-dir": "/var/lib/etcd/", "snap-dir": "/var/lib/etcd/member/snap", "initial-memory-map-size": 0}
2025-09-25T12:05:31+08:00 info membership/store.go:138 Trimming membership information from the backend...
2025-09-25T12:05:31+08:00 info membership/cluster.go:421 added member {"cluster-id": "cdf818194e3a8c32", "local-member-id": "0", "added-peer-id": "8e9e05c52164694d", "added-peer-peer-urls": ["http://localhost:2380"], "added-peer-is-learner": false}
2025-09-25T12:05:31+08:00 info snapshot/v3_snapshot.go:293 restored snapshot {"path": "/yinzhengjie/data/nfs-server/casedemo/etcd/backup/oldboyedu-etcd-2025-09-25_11:43:00.backup", "wal-dir": "/var/lib/etcd/member/wal", "data-dir": "/var/lib/etcd/", "snap-dir": "/var/lib/etcd/member/snap", "initial-memory-map-size": 0}
[root@master231 manifests]# ll /var/lib/etcd
total 12
drwx------ 3 root root 4096 Sep 25 12:05 ./
drwxr-xr-x 65 root root 4096 Sep 25 12:05 ../
drwx------ 4 root root 4096 Sep 25 12:05 member/
[root@master231 manifests]# ll /var/lib/etcd/member/
total 16
drwx------ 4 root root 4096 Sep 25 12:05 ./
drwx------ 3 root root 4096 Sep 25 12:05 ../
drwx------ 2 root root 4096 Sep 25 12:05 snap/
drwx------ 2 root root 4096 Sep 25 12:05 wal/4. 启动etcd服务:静态pod启动
bash
[root@master231 manifests]# mv /opt/etcd.yaml ./
[root@master231 manifests]# ss -ntl | grep 2379
LISTEN 0 4096 10.0.0.231:2379 0.0.0.0:*
LISTEN 0 4096 127.0.0.1:2379 0.0.0.0:* 5. 验证数据是否恢复
bash
[root@master231 manifests]# kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
master231 Ready control-plane,master 6d1h v1.23.17 10.0.0.231 <none> Ubuntu 22.04.4 LTS 5.15.0-153-generic docker://20.10.24
worker232 Ready <none> 6d1h v1.23.17 10.0.0.232 <none> Ubuntu 22.04.4 LTS 5.15.0-153-generic docker://20.10.24
worker233 NotReady <none> 6d1h v1.23.17 10.0.0.233 <none> Ubuntu 22.04.4 LTS 5.15.0-153-generic docker://20.10.24重点掌握:K8S集群资源之ConfigMap
概念
简称"cm",主要存储的是配置信息,只要是配置相关的信息都可以存储在该资源中。cm资源可以被k8s的pod以环境变量的方式注入,也可以基于存储卷的方式注入。
资源清单
yaml
# 01-cm-conf.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: cm-conf
# 一个是key,一个是value
data:
school: oldboyedu
class: linux99
# my.cnf是key,下面内容是value,写了个配置文件
my.cnf: |
[mysqld]
datadir=/oldboyedu/data/mysql80
basedir=/oldboyedu/softwares/mysql80
socket=/tmp/mysql80
[client]
username=linux99
password=oldboyedu
# 写了个脚本
start.sh: |
#!/bin/sh
mkdir /tmp/yinzhengjie
mount -t tmpfs -o size=90M tmpfs /tmp/yinzhengjie/
dd if=/dev/zero of=/tmp/yinzhengjie/bigfile.log
sleep 30
rm /tmp/yinzhengjie/bigfile.log
umount /tmp/yinzhengjie
rm -rf /tmp/yinzhengjie测试
bash
# 2.2 创建资源
[root@master231 configmaps]# kubectl apply -f 01-cm-conf.yaml
configmap/cm-conf created
# 2.3 查看资源
[root@master231 configmaps]# kubectl get cm
NAME DATA AGE
cm-conf 4 4s
kube-root-ca.crt 1 6d8h
[root@master231 configmaps]# kubectl get cm cm-conf
NAME DATA AGE
cm-conf 4 103s
# 2.4 删除资源
[root@master231 configmaps]# kubectl delete -f 01-cm-conf.yaml
configmap "cm-conf" deletedPod基于环境变量引用cm资源
创建资源
bash
[root@master231 configmaps]# kubectl apply -f 01-cm-conf.yaml
[root@master231 configmaps]# kubectl get cm cm-conf 编写资源清单
yaml
# ./02-pods-env-cm.yaml
apiVersion: v1
kind: Pod
metadata:
name: pods-cm-env
spec:
containers:
- name: c1
image: registry.cn-hangzhou.aliyuncs.com/yinzhengjie-k8s/apps:v2
env:
- name: oldboyedu-SCHOOL
# 表示值从某个地方引用
valueFrom:
# 值从一个cm资源引用
configMapKeyRef:
# 指定的是cm的资源清单的名称
name: cm-conf
# 指定是cm中存在的某个key
key: school
- name: oldboyedu-MySQL
valueFrom:
configMapKeyRef:
name: cm-conf
key: my.cnf测试验证
bash
[root@master231 configmaps]# kubectl apply -f ./02-pods-env-cm.yaml
pod/pods-cm-env created
[root@master231 configmaps]# kubectl get pods pods-cm-env
NAME READY STATUS RESTARTS AGE
pods-cm-env 1/1 Running 0 16s
[root@master231 configmaps]# kubectl exec pods-cm-env -- env
...
oldboyedu-SCHOOL=oldboyedu
oldboyedu-MySQL=[mysqld]
datadir=/oldboyedu/data/mysql80
basedir=/oldboyedu/softwares/mysql80
socket=/tmp/mysql80
[client]
username=linux99
password=oldboyeduPod基于存储卷的方式引用cm资源
编写资源清单
yaml
# 03-pods-volumes-cm.yaml
apiVersion: v1
kind: Pod
metadata:
name: pods-cm-env-volumes
spec:
# 进行存储卷引用
volumes:
- name: data
# 指定configMap为存储卷类型
configMap:
# 指定存储卷的名称
name: cm-conf
# 指引引用的具体key,若不指定,则默认引用所有的key。
items:
# 引用cm的key
- key: my.cnf
# 此处可以理解为将来挂载点的文件名称
path: mysql.txt
- key: start.sh
path: oldboyedu-start.sh
containers:
- name: c1
image: registry.cn-hangzhou.aliyuncs.com/yinzhengjie-k8s/apps:v2
# 进去容器就可以在/oldboyedu下面显示你引用的文件了
volumeMounts:
- name: data
mountPath: /oldboy·edu
# 这个是环境变量:进去容器的env就会显示oldboyedu-SCHOOL=oldboyedu olboyedu-MySQL=那个资源清单
env:
- name: oldboyedu-SCHOOL
valueFrom:
configMapKeyRef:
name: cm-conf
key: school
- name: oldboyedu-MySQL
valueFrom:
configMapKeyRef:
name: cm-conf
key: my.cnf测试验证
bash
[root@master231 configmaps]# kubectl apply -f 03-pods-volumes-cm.yaml
pod/pods-cm-env-volumes created
[root@master231 configmaps]# kubectl get pods -o wide pods-cm-env-volumes
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pods-cm-env-volumes 1/1 Running 0 6s 10.100.1.70 worker232 <none> <none>
[root@master231 configmaps]# kubectl exec -it pods-cm-env-volumes -- sh
/ # ls -l /oldboyedu/
total 0
lrwxrwxrwx 1 root root 16 Sep 25 11:28 mysql.txt -> ..data/mysql.txt
lrwxrwxrwx 1 root root 25 Sep 25 11:28 oldboyedu-start.sh -> ..data/oldboyedu-start.sh
/ # cat /oldboyedu/mysql.txt
[mysqld]
datadir=/oldboyedu/data/mysql80
basedir=/oldboyedu/softwares/mysql80
socket=/tmp/mysql80
[client]
username=linux99
password=oldboyedu
/ # cat /oldboyedu/oldboyedu-start.sh
#!/bin/sh
mkdir /tmp/yinzhengjie
mount -t tmpfs -o size=90M tmpfs /tmp/yinzhengjie/
dd if=/dev/zero of=/tmp/yinzhengjie/bigfile.log
sleep 30
rm /tmp/yinzhengjie/bigfile.log
umount /tmp/yinzhengjie
rm -rf /tmp/yinzhengjie案例:ConfigMap实现配置中心案例
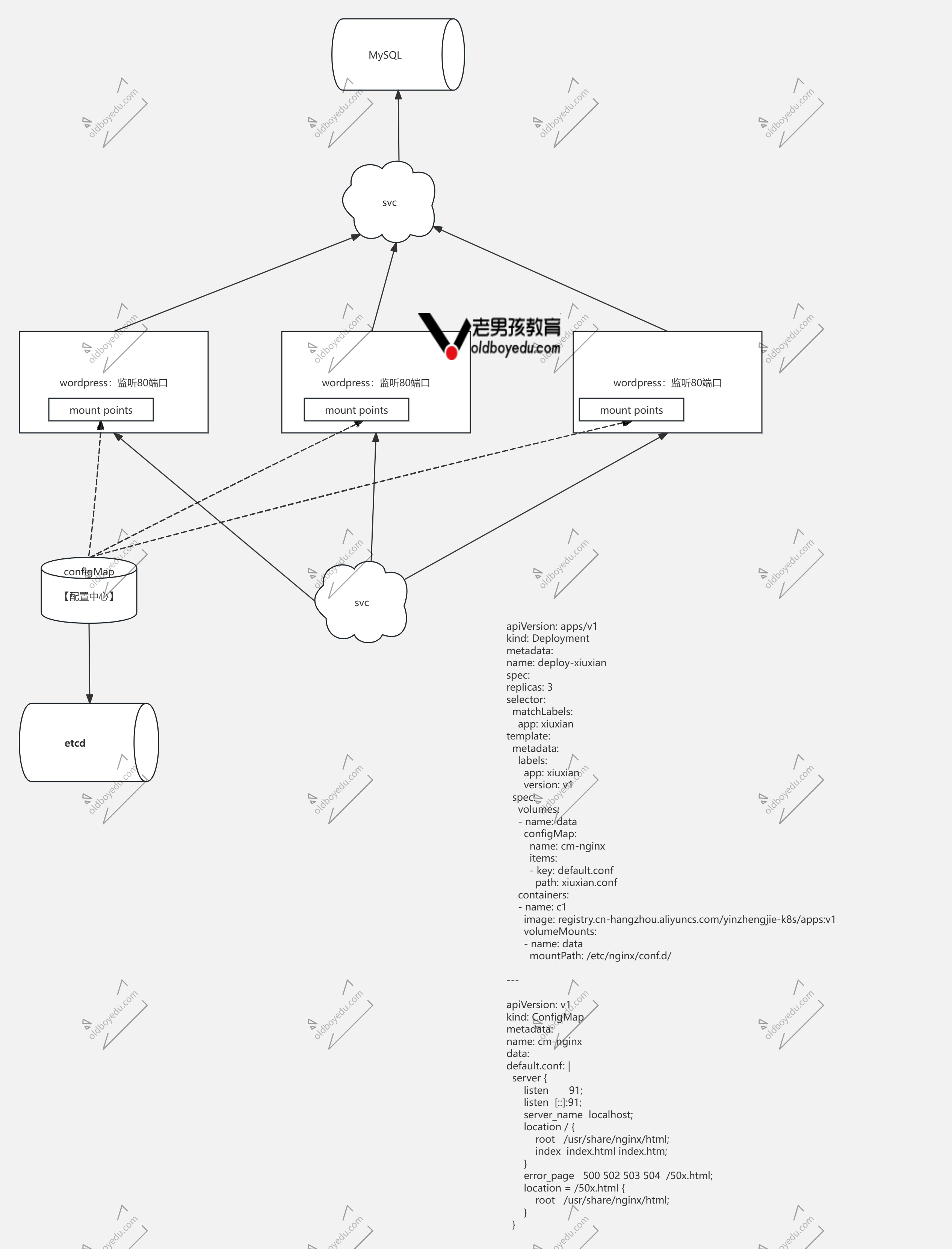
目的:统一切换nginx配置文件的端口
编写资源清单
yaml
# 04-deploy-cm-xiuxian.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: deploy-xiuxian
spec:
replicas: 3
selector:
matchLabels:
app: xiuxian
template:
metadata:
labels:
app: xiuxian
version: v1
spec:
volumes:
- name: data
configMap:
name: cm-nginx # 引用的配置就是下面的cm-nginx
items:
- key: default.conf
path: xiuxian.conf
containers:
- name: c1
image: registry.cn-hangzhou.aliyuncs.com/yinzhengjie-k8s/apps:v1
volumeMounts:
- name: data
mountPath: /etc/nginx/conf.d/ # 所以到时就在/etc/nginx/config.d/xiuxian.conf
---
apiVersion: v1
kind: ConfigMap
metadata:
name: cm-nginx
data:
default.conf: |
server { # 监听端口91
listen 91;
listen [::]:91;
server_name localhost;
location / {
root /usr/share/nginx/html;
index index.html index.htm;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root /usr/share/nginx/html;
}
}测试验证
bash
[root@master231 configmaps]# kubectl apply -f 04-deploy-cm-xiuxian.yaml
deployment.apps/deploy-xiuxian created
configmap/cm-nginx created
[root@master231 configmaps]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
deploy-xiuxian-84885b878c-7wv8k 1/1 Running 0 3s 10.100.2.188 worker233 <none> <none>
deploy-xiuxian-84885b878c-lsz8z 1/1 Running 0 3s 10.100.1.90 worker232 <none> <none>
deploy-xiuxian-84885b878c-tkcvv 1/1 Running 0 3s 10.100.2.189 worker233 <none> <none>
[root@master231 configmaps]# curl 10.100.2.188
curl: (7) Failed to connect to 10.100.2.188 port 80 after 0 ms: Connection refused
[root@master231 configmaps]# curl 10.100.2.188:90
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8"/>
<title>yinzhengjie apps v1</title>
<style>
div img {
width: 900px;
height: 600px;
margin: 0;
}
</style>
</head>
<body>
<h1 style="color: green">凡人修仙传 v1 </h1>
<div>
<img src="1.jpg">
<div>
</body>
</html>
# 注意:如需再次切换,需要删除并重启pod资源清单