深度学习GPU介绍
- GPU概述
- [Nvidia 的 GPU ------❤️](#Nvidia 的 GPU ——❤️)
-
- 分类
- 架构演进过程
- 三种具体的核心
-
- [CUDA Cores:并行计算的基石](#CUDA Cores:并行计算的基石)
- [Tensor Cores:AI 核心驱动力](#Tensor Cores:AI 核心驱动力)
- [Ray-Tracing Cores:渲染技术的革命者](#Ray-Tracing Cores:渲染技术的革命者)
- 总结
- GTX和RTX有什么区别
- GPU的选择
- 参考文章
GPU概述
CPU 和 GPU 的区别
GPU(Graphic Processing Unit)图形处理器
CPU (Central Processing Unit)中央处理器

显卡算力天梯图
品牌
- 现在主流的显卡品牌有两个:
英伟达NVIDIA和ATI(被AMD收购),所以分别称为N卡和A卡 - 因为英伟达多年来一直运营着显卡驱动cuda,所以深度学习对N卡支持都比较好,一般推荐等购买N卡。这里的型号也以N卡为例。
型号
- 显卡的型号标识着显卡的能力,比如
NVIDIAGeForceRTX3080Ti 12G其中NVIDIA表示这张显卡是英伟达品牌,是N卡GeForce系列表示这是张消费级显卡,此外还有Tesla系列就是专用级显卡RTX表示支持光追(RayTracing),除此外还有GTX 。RTX系列显卡比GTX更晚面试,所以新显卡都是RTX系列,这两个可以理解为升级了。3080是显卡的真正型号,30表示这是30系显卡,这个数字表表示是第几代显卡。在每一代显卡中都有不同级别40/50/60/70/80/903080后面的Ti表示加强版,是在3080基础上增强了性能,扩充了显存12G表示这张显卡内存有12GB大小
- 前面说了我们主要关心的是显卡的算力和内存大小,所以在型号里主要关注3080Ti和12G这两个参数,3080Ti决定了算力,12G决定了内存大小。在选择显卡时主要就是根据型号购买适合的算力和内存即可。
- 不是新一版的显卡算力一定更强,比如2080的算力就比比3060的强 。但是通常来说,同级别的显卡,新一代都比旧一代强,如2080和3080的对比。但是更高的算力通常常需要更大的功率,也更费电,而且电源可能不兼容,比如3060这种甜品级显卡只要400W额定功率的电源,但是3080这种专业级显卡需要额定功率至少500W
AI芯片技术路线之争
FPGA(Field Programmable Gate Array)现场可编程逻辑门阵列
- FPGA作为一种高性能、低功耗的可编程芯片,可以根据客户定制来做针对性的算法设计。所以在处理海量数据的时候,FPGA 相比于CPU 和GPU,优势在于:FPGA计算效率更高,FPGA更接近IO。
- FPGA不采用指令和软件,是软硬件合一的器件。对FPGA进行编程要使用硬件描述语言,硬件描述语言描述的逻辑可以直接被编译为晶体管电路的组合所以FPGA实际上直接用晶体管电路实现用户的算法,没有通过指令系统的翻译
- 可以对硬件编程,实现软件的编程效果
- 灵活,但是功耗大,成本高
ASIC(Application Specific Integrated Circuit)特殊应用集成电路
- ASIC是一种专用芯片,与传统的通用芯片有一定的差异。是为了某种特定的需求而专门定制的芯片
- ASIC芯片的计算能力和计算效率都可以根据算法需要进行定制,所以ASIC与通用芯片相比,具有以下几个方面的优越性:体积小、功耗低、计算性能高、计算效率高、芯片出货量越大成本越低
- 但是缺点也很明显:算法是固定的,一旦算法变化就可能无法使用
- 软硬件固化,针对某种特定应用;
- 功耗低,量产后成本低,但是不灵活
vGPU
vGPU(虚拟GPU)是一种技术,允许将物理GPU的计算资源虚拟化,以便多个虚拟机可以共享这些资源
背景
- 由于加密货币、 AI 等产业的蓬勃发展,加上 GPU 芯片产能不足,以及后来美国针对中国的 GPU 禁运等一系列事件的影响,GPU 卡在市场上非常稀缺,导致其售价非常昂贵,而且供货周期也不稳定
- 对于有 GPU 需求的企业用户,不但需要思考 GPU 卡的选型,同时需要考虑怎样尽可能高效利用 GPU 资源
- 通常情况下,将 GPU 资源虚拟化能有效提高资源利用率,目前大多企业也已经习惯将业务部署在虚拟机之上,GPU 与虚拟机的结合可以说是顺理成章的
技术
- GPU 直通主要是利用 PCIe Pass-through 的技术,将物理主机上的 整块 GPU 显卡直通挂载到虚拟机上使用,相当于虚拟机独占了 GPU 卡
- 通用性好,大部分的 GPU 卡型号都支持直通功能
- vGPU 技术应运而生:将 GPU 卡上的资源进行 切分,切分后的 GPU 资源可分配给多台虚拟机使用
- GPU 拥有多种切分方式和不同切分粒度,使得 vGPU 方案有很多种组合
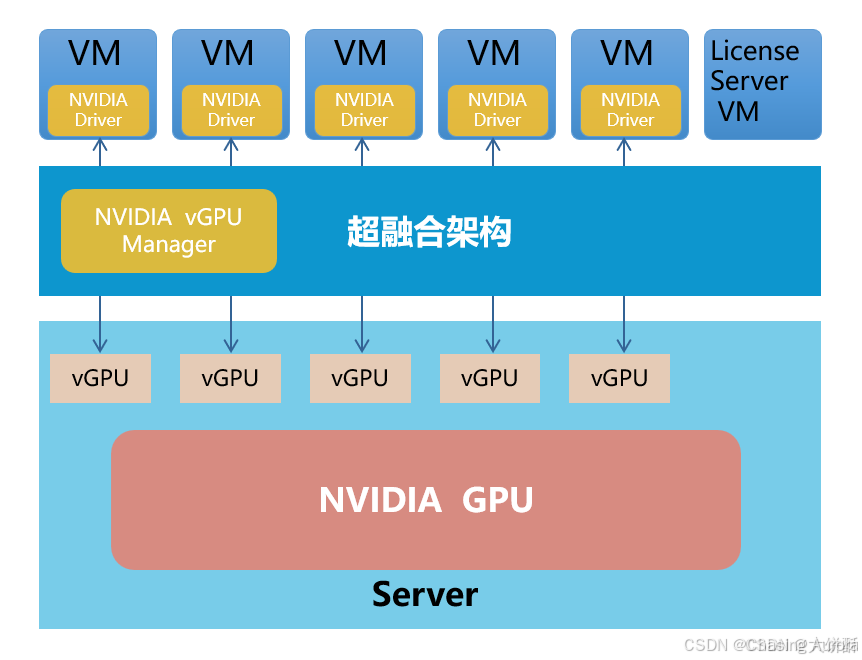
GeForce不支持vGPU方案,只能直通
Nvidia 的 GPU ------❤️
分类
NVIDIA将显示核心分为三大系列。GeForce用于提供家庭娱乐;Quadro用于专业绘图设计;Tesla用于大规模的并联电脑运算
GeForce系列(消费级/游戏与创作)
- 这个系列主要面向游戏玩家、内容创作者及个人计算用户,搭配台式机和笔记本。常见的产品型号如
GeForce RTX5090、4090等 - GeForce系列注重提供高性能的图形处理能力和游戏特性。它们具备实时光线追踪(Ray Tracing)和DLSS(Deep Learning Super Sampling)等先进技术,提供更逼真的游戏画面和流畅的游戏体验
Quadro系列(P系列)

- Quadro系列是英伟达专业级GPU产品线,针对商业和专业应用领域进行了优化。常见的产品型号如
NVIDIA RTX A6000、A5000等 - Quadro GPU具备强大的计算能力、大容量显存和专业特性,如双精度浮点运算和驱动程序的优化。主要用于计算机辅助设计(CAD)、动画制作、科学计算、虚拟现实等需要高精度计算和可靠稳定性的专业领域
- 多数产品的核心实质上与定位于个人领域的GeForce完全相同,但与GeForce相比Quadro强调与行业软件的兼容性、稳定性以及高效率
- 一般来说Quadro的价钱比GeForce贵,所以有部分用户软改GeForce显卡,利用改版的驱动,他们可得到一张便宜而等价的Quadro显卡
Tesla系列(T系列)
英伟达禁止在 数据中心场景 使用GeForce系列显卡
- Tesla系列主要用于高性能计算和机器学习任务,在计算能力和深度学习加速方面有突出表现
- Tesla GPU集成了深度学习加速器(如NVIDIA Tensor Cores),提供快速的矩阵运算和神经网络推理。主要应用于科学计算、数据分析、深度学习等高要求的计算任务
- 这是继GeForce和Quadro之后,第三个显示核心商标。但Nvidia于2020年5月起停用这个品牌,据称是因为可能与特斯拉汽车厂牌造成混淆。其新的 GPU 以"
Nvidia Data Center GPU"作为品牌,例如基于Ampere微架构的 A100 GPU
其他
- 以上这个三个系列是大家比较熟悉的GPU系列
- 除此之外
- 还有面向移动处理器产品线的Tegra系列
- 面向面向边缘计算和人工智能应用的嵌入式开发平台Jetson系列
- 面向面向深度学习和人工智能研究的高性能计算服务器DGX系列等等
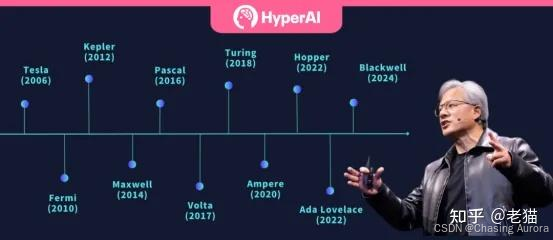
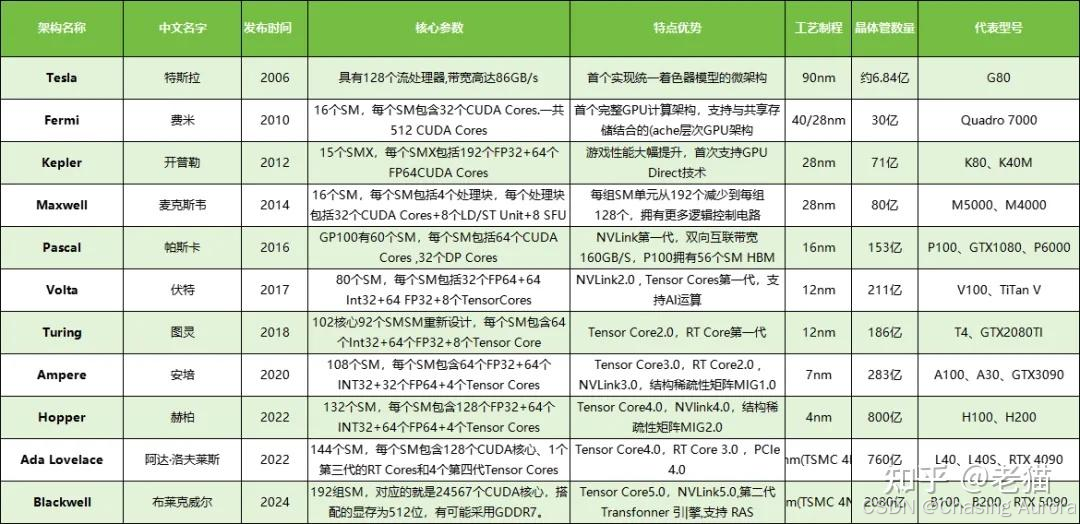
架构演进过程
英伟达每个架构,都会以一个著名科学家的名字命名,截至目前发布,已经有 11 款芯片架构代号取自科学家名字
GPU阉割版芯片
- A800和H800是英伟达专为中国市场推出的受限版GPU,以符合美国的出口管制要求:
- A800:基于A100,限制了NVLink互联带宽,适合AI推理和训练
- H800:基于H100,限制了带宽,但仍然保留了较高的计算能力,适用于大型AI训练
- H20:英伟达为中国市场设计的新一代受限版H100,预计将取代H800。进一步的阉割版
- 这些GPU主要面向中国客户,如阿里云、腾讯云、百度云等云计算厂商,性能稍逊于A100和H100,但仍然具备极高的计算能力。
三种具体的核心
- GPU的核心数量也被称为
CUDA 核心(NVIDIA的术语)或流处理器(AMD的术语) - 核心数量是评估GPU并行处理能力的重要指标。核心数量越多,GPU在执行图形和并行计算任务时通常表现得越好
- 显存带宽:这是一个衡量GPU与其显存之间数据传输速度的指标
CUDA Cores:并行计算的基石
- CUDA cores(Compute Unified Device Architecture cores)是 NVIDIA GPU 中最基础的处理单元,专门用于执行并行计算任务。其主要职责包括处理大规模的浮点运算和整数运算,尤其适合需要高吞吐量的计算场景
- CUDA 是 Compute Unified Device Architecture 的缩写,是GPU并行编程处理和直接访问Nvidia GPU指令集API的总称 ,它适用于流行的编程语言C、C++,方便用户调用
- CUDA使得GPU看起来和别的可编程设备一样
- cuDNN(CUDA Deep Neural Network library)
- NVIDIA打造的针对深度神经网络的加速库,是一个用于深层神经网络的GPU加速库。如果你要用GPU训练模型,cuDNN不是必须的,但是一般会采用这个加速库
Tensor Cores:AI 核心驱动力
- NVIDIA GPU 中的第2大核心,
Tensor cores为深度学习模型训练和推理任务 专门设计的计算单元,首次引入于 Volta 架构(如 Tesla V100) - 其核心特性是能够在 张量运算(Tensor Operations)中表现出色,例如矩阵乘法和累加计算(
Matrix Multiplication and Accumulation, MMA) - 在矩阵计算任务中, Tensor Cores 其性能往往是 CUDA cores 的数倍,尤其是在处理 FP16 或 INT8 类型的高效计算时
Ray-Tracing Cores:渲染技术的革命者
Ray-Tracing cores是 NVIDIA 针对光线追踪渲染技术专门设计的核心单元,首次引入于 Turing 架构(如 RTX 20 系列) 。其主要任务是加速光线追踪计算,即模拟光线在 3D 场景中的传播和交互,以实现逼真的光影效果
总结
- Tensor cores 提供高效的矩阵MMA计算,用于深度神经网络训练和推理
- CUDA cores 处理预处理、数据加载和其他非矩阵计算任务,负责通用的数值计算和模拟任务,为 Tensor cores 减轻负
- 在某些生成式模型(如 GAN 和 Stable Diffusion)中,Ray-Tracing cores 可用于生成更真实的图像效果
GTX和RTX有什么区别
- "RT"就代表着光线追踪(ray tracing的缩写),RTX系显卡所支持的光追和DLSS,表现出了可靠的画面呈现力
- GTX系的显卡没有光追DLSS,但是GTX系的显卡其他性能也是很强的,价格也比以前降低,性价比变的很高
- 至于两者怎么选择,还是看你对光线追踪有没有要求,想玩就RTX,不想玩就GTX,同价位性能大概没有多少差距。如果想要体验光线追踪技术,那么购买的显卡最好还是RTX30起步

GPU的选择
常见型号简介
推荐显卡------❤️
- 20系显卡推荐
2080及以上 - 30系显卡推荐
3060及以上,其中306012G如果你有训练需求,预算又不够高,是个不错选择 - 40系显卡推荐
4060及以上
查看GPU信息
参考文章
GPU介绍及选型
一文彻底读懂:英伟达GPU分类、架构演进和参数解析
NVIDIA Quadro
NVIDIA Tesla
一文读懂 NVIDIA GPU Core
全面解析GPU CUDA Core, 为什么Tensor Core可以加速深度学习
一文搞懂最新NVIDIA GPU满血版和阉割版芯片:A100、H100、A800、H800、H20的差异
显卡GTX与RTX的区别
显卡选择