🔥 本文专栏:Linux网络
🌸作者主页:努力努力再努力wz


💪 今日博客励志语录 :
平庸的选择是为了避开失败,而勇敢的选择是为了定义自我。失败从不是勇气的终点,它只是命运在试探你:你是打算就此收笔,还是准备翻开更精彩的一页?
引入
那么在此前的学习中,我们已经学习了应用层协议,包括如何自定义一个应用层协议、序列化与反序列化的实现方式,以及经典应用层协议 HTTP。本篇文章将进入对传输层协议 的学习。传输层协议主要分为两种:第一种是UDP协议 ,第二种是TCP协议 。因此,文章开篇我们将首先回顾 UDP 协议。
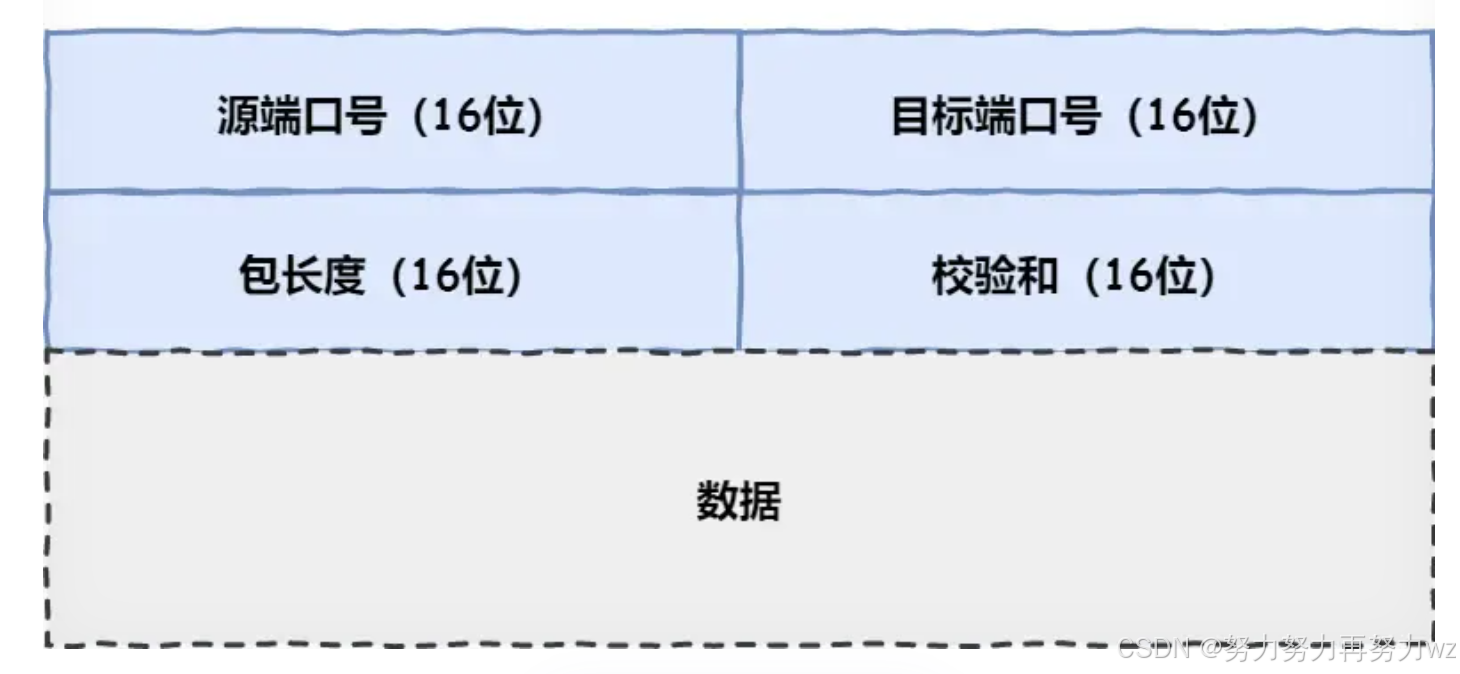
何能够收发数据的网络设备都可以用 TCP/IP 模型来描述,其中最上层是应用层。应用层在添加应用层协议头之后,数据会进入传输层,并附加传输层协议头。UDP 协议头仅占 8 字节,且字段非常简单;相比之下,TCP 协议头不仅字段更多,长度也在 20 至 60 字节之间可变。这决定了 TCP 的传输策略远比 UDP 复杂。TCP 头部字段之所以丰富,是因为 TCP 需要确保可靠传输,相关字段的具体作用我们将在后文详细展开。
UDP 头部长度固定,IP 头部也是定长的,这意味着我们可以快速定位到应用层数据。而对于 TCP,由于其头部是变长的,我们必须先通过头部中的数据偏移字段获取当前 TCP 头的长度,才能准确找到应用层数据的起始位置。
尽管 UDP 头部结构简单,但也付出了相应的代价:UDP 不提供可靠性保证。UDP 头部的前两个字段------源端口号和目的端口号------我们已经很熟悉。"包长度"字段标识整个 UDP 数据包的总长度(包含 UDP 头部),而"校验和"用于检测数据在传输过程中是否出错。如果数据包在传输中出现差错,到达目标主机后经传输层处理会被直接丢弃,既不会通知应用层,也不会触发发送方重传。这也是 UDP 不具备可靠性的原因之一。
此外,UDP 协议是面向数据报(面向报文)的。发送方可以连续向接收方发送多个 UDP 数据报,接收方在收到这些数据报后,会将它们依次放入接收缓冲区。但需要注意的是,UDP 数据报并不保证按发送顺序到达 目标主机。由于网络状态(例如网络拥塞)的影响,先调用 sendto 发送的数据报,反而可能晚于后发送的数据报到达接收方。
如果接收方接收到的数据报之间存在逻辑关联(即必须按照发送顺序进行解析),UDP 协议本身并不会提供任何顺序保障。由于 UDP 报头字段非常简单,它并不关心数据报是有序到达还是乱序到达,只是按照到达顺序将数据报依次存入接收缓冲区。
因此,当应用层调用 recvfrom 接口读取数据时,读取顺序取决于数据报到达的先后顺序 ,并且每一次读取到的,都是一个完整的 UDP 应用层数据报 。这一点反而成为 UDP 的一个优势:对方发送了多少次 UDP 数据报,接收方只需对应调用相同次数的 recvfrom 即可完成接收,应用层不需要自行处理"拆包"和"粘包"问题。
然而,由于 UDP 缺乏可靠性保障,其对丢包和有序性 均不作任何承诺。如果在某些场景下需要基于 UDP 实现可靠传输,那么就只能在应用层自行实现相关机制。事实上,这些机制的设计思路基本就是对 TCP 的"复刻"------因为 TCP 已经是一个在可靠性方面非常成熟且高效的范例。在应用层为 UDP 实现可靠性,本质上就是借鉴并实现 TCP 的相关策略。
当然,UDP 虽然不保证可靠性,但这并不意味着它毫无价值。不同的应用场景对传输特性的要求不同:有些场景必须保证可靠性,而有些场景则更看重实时性。例如直播场景,通常是一对多的通信模式,发送方需要将数据以 UDP 数据报的形式同时发送给多个接收方。
TCP 连接是一对一的,即一个 TCP 连接只能固定在两个主机进程的两个套接字之间进行通信;而 UDP 则可以实现:一个设备上的同一个套接字,向多个不同设备上的进程同时发送数据。不过,这并不是直播场景选择 UDP 的最核心原因。
关键在于 TCP 为了保证可靠性,引入了超时重传机制。假设直播过程中,第 5 秒画面对应的数据报丢失,那么即使接收方已经收到了第 6 秒、第 7 秒的数据,由于 TCP 需要保证字节流的有序和完整性,它不会将后续数据交付给应用层,同时也不会立即向发送方确认。发送方在超时后未收到确认报文,就会重传第 5 秒的数据。
在这种情况下,综合超时等待和网络传输延迟,观众看到的效果就是:画面长时间停留在第 4 秒,无法继续播放。对于直播这种对实时性要求极高的场景而言,这是完全不可接受的。
而对于 UDP,即使出现丢包或乱序到达的情况,偶尔丢失一两个数据报对整体观看体验影响并不大,最多只是出现短暂的掉帧或卡顿。由于 UDP 的传输层不会处理乱序问题,而是将数据报直接交付给应用层,因此在实际的直播系统中,应用层通常会引入类似 TCP 序列号的机制,对数据进行重组和排序,以避免出现先显示第 6 秒画面、再回退到第 5 秒画面的情况。
至此,UDP 协议的核心内容基本介绍完毕。从 UDP 报头极其简洁的结构也可以看出,UDP 的设计目标就是简单、高效、低延迟,而非复杂的可靠性保障。
虽然 UDP 足够简单高效,但当我们面对"绝不允许丢失一个字节"的网页数据或转账记录时,UDP 的这种"无责任传输"就会成为致命缺陷。那么,TCP 究竟是如何在充满不确定性的网络环境中,依靠那些复杂的报头字段,构建起一套可靠传输机制的?接下来,我们将正式进入 TCP 的"可靠性森林"。
TCP协议
对于TCP协议,要深入理解它,我们仍需从其协议报头的结构开始:
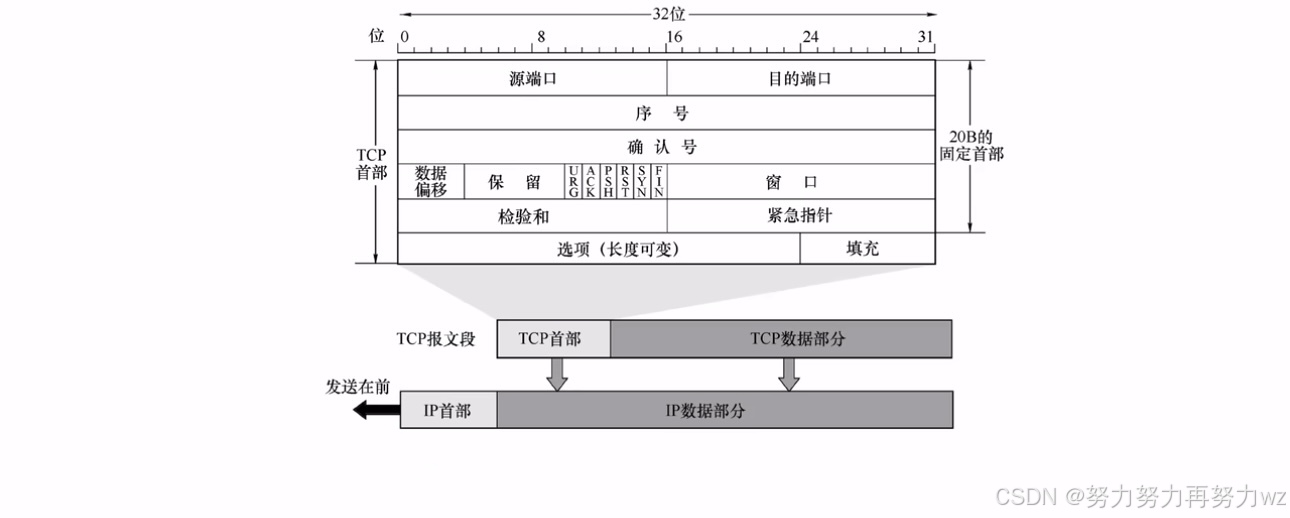
观察TCP协议报头,其结构相较于UDP协议报头要复杂得多。TCP报头之所以包含如此多的字段,核心原因在于TCP协议需要保障可靠性。其中,前两个字段------源端口号与目的端口号------我们已很熟悉。这里要介绍的第一个字段是 数据偏移 字段,它用来标识TCP报头的总长度。如前所述,TCP报头是变长的,长度在20到60字节之间。数据偏移字段占4位,其值范围为0到15(十进制),并且其单位是4字节。因此,该字段能表示的总字节数范围是0到60字节。由于TCP有一个固定的20字节头部,故数据偏移的实际取值是5到15。
介绍了数据偏移字段后,读者可能预期我会继续按此模式逐一讲解其他字段。然而,要理解其余字段,我们必须结合整个通信过程,而非将它们孤立出来讲解。因此,我们先从通信的起点开始。
在网络中进行通信的实体并非设备本身,而是设备上运行的进程。参与网络通信的进程通常扮演两种角色:客户端或服务端。客户端主动向服务端发起请求,服务端接收来自不同客户端的请求,处理后再将响应报文返回给客户端,这便是通信的基本流程。
这个流程的起点是:无论是客户端还是服务端进程,都会先创建一个套接字,即调用socket 接口。socket
底层的行为是创建一个套接字,具体来说是一个struct socket结构体。套接字可以理解为"容器+描述符"。它具备容器的功能,可以暂存来自其他设备的数据报;同时也作为描述符,记录了传输层和网络协议栈的相关属性。不过,这个struct socket 结构体本身并非核心,它有一个关联字段sk ,指向一个struct sock
结构体,sock 结构体才是真正的核心。
cpp
struct socket {
// 1. 套接字状态
socket_state state; // SS_FREE, SS_UNCONNECTED, SS_CONNECTING, SS_CONNECTED
// 2. 协议族信息
struct proto_ops *ops; // 协议操作函数表
unsigned short type; // 套接字类型
unsigned int flags; // 套接字标志
// 3. 文件系统关联
struct file *file; // 关联的文件结构
struct sock *sk; // 网络层套接字结构
//.....
};struct socket 与struct sock 的关系,可以类比为汽车外壳与发动机引擎。socket 是外壳,而sock 才是核心的引擎。
sock 结构体记录了与网络层和传输层 相关的关键信息,内核正是通过管理 sock 结构体来完成网络层与传输层协议栈的处理,并以此维护通信状态。因此,后续分析将主要聚焦于 sock 结构体。
首先需明确,sock 结构体作为描述符,需要同时描述传输层和网络层。传输层有TCP、UDP等协议,网络层也有IPv4、IPv6等多种协议。不同协议的报头结构各异,描述它们的结构体字段自然也不同。sock 需要有能力描述所有这些协议,而非仅限于某一种。
当我们调用socket 接口时,可以通过参数指定创建UDP或TCP类型的套接字。在底层,该接口会创建一个统一的struct socket 结构体,并通过其sk 字段关联到不同类型的sock 结构体。由于Linux内核使用C语言实现,它采用了类似C++中面向对象继承的方式来设计sock 结构体系列。无论UDP还是TCP套接字,其最顶层的"基类"都是同一个struct sock 结构体,但下层的"派生类"则不同。
对于UDP协议,其继承关系是:基类sock -> 描述网络层的inet_sock -> UDP特有的udp_sock 。这里的"继承"是通过将sock 结构体作为inet_sock 的第一个成员,再将inet_sock 作为udp_sock 的第一个成员来实现的。
cpp
sock → inet_sock → udp_sock
---------------------------------------
struct udp_sock { // UDP层
struct inet_sock { // IP层
struct sock { // 传输层基类
// 通用套接字信息
};
__be32 inet_daddr; // 目标IP
__be32 inet_saddr; // 源IP
__be16 inet_dport; // 目标端口
__be16 inet_sport; // 源端口
};
// UDP特有字段
int corkflag; // 是否启用corking
int pending; // 待处理数据
// ... 没有端口号相关字段
};
对于TCP协议,其继承层次更深。由于TCP是面向连接的可靠协议,它在网络层(inet_sock )之上,还需要一个管理层来维护连接状态。因此其关系为:基类sock ->inet_sock -> 管理连接的inet_connection_sock -> TCP特有的tcp_sock 。
cpp
sock
↓
inet_sock
↓
inet_connection_sock
↓
tcp_sock重新审视这个设计:最顶层是统一的基类sock ,其下层是描述网络层的inet_sock 结构体。不同的网络层协议可以让其对应的结构体继承自sock 。同理,不同的传输层协议(如TCP、UDP)可以让其特有的结构体继承自上层结构。这种分层继承的设计,使得每一层都对应一个结构体,上层无需关心下层的具体实现,下层也无需了解上层细节,实现了良好的解耦。顶层socket 结构体的sk 指针需要能关联到udp_sock 或tcp_sock 等不同类型的结构体。由于这些结构体最开始的第一个成员(基类sock )是相同的,因此sk 指针可以先指向这个公共起始地址,后续再通过判断具体类型进行强制类型转换,这本质上是一种多态的思想。
接下来,让我们认识一下作为基类的sock 结构体。作为"容器+描述符",基类sock 主要承担"容器"的角色,其最核心的字段是输入缓冲区和输出缓冲区。
cpp
struct sock {
// 1. 队列(管理数据包)
struct sk_buff_head sk_receive_queue; // 接收队列(输入缓冲区)
struct sk_buff_head sk_write_queue; // 发送队列(输出缓冲区)
// 2. 内存分配(管理字节数)
unsigned int sk_rmem_alloc; // 接收缓冲区已分配字节数
unsigned int sk_wmem_alloc; // 发送缓冲区已分配字节数
// 3. 容量限制
int sk_rcvbuf; // 接收缓冲区最大容量
int sk_sndbuf; // 发送缓冲区最大容量
// ...
};这里的输入/输出缓冲区本质上是一个双向链表,链表的每个节点是一个sk_buff 结构体。在使用TCP协议通信时,发送方调用write 或send 接口发送应用层数据。需要注意的是,这些接口仅负责将数据从用户空间提交到内核,并不意味着数据会立即被发送出去。TCP作为传输控制协议,其核心在于"控制",对数据的发送有自己的一套策略。应用层数据会被拷贝到发送缓冲区,即这个双向链表队尾节点的sk_buff 的数据区中。
此时需要纠正一个常见的理解误区。
如果仅按照 TCP/IP 协议栈模型进行抽象,读者可能会认为内核在处理数据时会经历如下过程:
- 为 TCP 头 + 应用层数据申请一块内存;
- 拷贝应用层数据并初始化 TCP 头;
- 再为 IP 头 + TCP 头 + 应用层数据申请一块内存;
- 再次拷贝并初始化 IP 头;
- 最终将数据发送到网络。
但这种方式涉及频繁的内存申请、拷贝与释放,效率极低,实际内核并不会采用这种实现。
内核在实际实现中采用了更为高效的处理方式:它会预先分配一块足够大的内存区域,该内存区域不仅用于存放应用层数据,同时还预留了 TCP 头部和 IP 头部的空间 。在这一抽象层面上,我们可以将协议头与应用层数据理解为一个连续的线性内存区域的逻辑模型,即它们位于同一块连续的内存中。
在 Linux 内核中,sk_buff 结构体正是通过一组指针来描述和管理这块内存区域的,其核心指针包括:
head:指向该内存块的起始位置。end:指向该内存块的末尾位置。data:指向当前有效数据的起始位置。tail:指向当前有效数据的末尾位置。
当数据需要发送时,内核并不会重新拷贝应用层数据,而是通过调整 data 指针的位置(例如,将其向前移动到预留的 TCP 头部起始处),随后在对应区域内填充协议头即可。通过这种方式,内核能够在绝大多数情况下避免不必要的数据拷贝,从而显著提升发送路径的整体效率。
需要注意的是,上述描述仍然是一种偏向逻辑抽象的模型,它并不能完全反映内核中真实的物理内存布局和数据组织方式。后文中我们将逐步过渡到更贴近实际的物理模型,并在此基础上重新、更加精确地阐述这四个指针在真实实现中的含义、作用以及它们所指向的具体对象,这里先作为一个铺垫。
另外需要强调的是TCP面向字节流的特性。这意味着TCP不像UDP那样有明确的报文边界。有读者可能认为,发送缓冲区链表的每个节点就对应一个完整的、待发送的TCP报文。但事实并非总是如此。
假设应用层连续调用两次write ,分别写入100字节和200字节的数据。由于这两个报文较短,一般情况下,sk_buff 所分配的内存块大小通常为 4KB 。虽然单个 IP 数据包的最大长度可以达到 65535 字节(约 64KB) ,但如果每创建一个 sk_buff 就直接分配 64KB 的内存,那么整体的内存开销将非常大。
此外,实际场景中应用层写入的数据并不一定都是完整的数据包,很多时候可能仅写入几个字节或几十字节 的数据。如果仍然为此分配 64KB 的缓冲区,显然会造成严重的内存浪费。因此,内核通常选择为 sk_buff 预分配较小的内存块(如 4KB),以提高内存利用率。
另一方面,在 Linux 系统中,内存页(page)的大小通常为 4KB 。如果需要一次性分配 64KB 的连续内存,就意味着需要申请 连续的 16 个内存页。在系统内存碎片较为严重的情况下,内核未必能够顺利找到如此大块的连续空闲内存,从而增加分配失败的风险。
基于上述原因,内核在设计上更倾向于以页大小为单位分配 sk_buff 的缓冲区,而不是直接为每个数据包分配其理论最大长度。所以这两个报文很可能会被存放在同一个sk_buff 节点的缓冲区中。
cpp
struct sk_buff {
// 1. 链表管理
struct sk_buff *next; // 指向下一个sk_buff
struct sk_buff *prev; // 指向上一个sk_buff
// 2. 缓冲区指针
unsigned char *head; // 缓冲区起始地址
unsigned char *data; // 当前数据开始地址
unsigned char *tail; // 当前数据结束地址
unsigned char *end; // 缓冲区结束地址
// 3. 协议头偏移量(关键!)
unsigned int mac_header; // 以太网头偏移
unsigned int network_header; // IP头偏移
unsigned int transport_header; // TCP/UDP头偏移
// 4. 元数据
unsigned int len; // 数据长度
__u16 protocol; // 协议类型
// ... 其他字段
};因此,这里需要分情况讨论。
如果双向链表中前面的 sk_buff 节点的缓冲区已经被填满 ,那么只能新申请一个 sk_buff 节点以及对应的内存块 。在新创建的 sk_buff 中,data 与 tail 在初始状态下是重合的,随后应用层数据会按字节拷贝到 tail 所指向的位置,同时 tail 不断向后移动。拷贝完成后,tail 即指向当前数据的末尾。
而如果双向链表末尾的 sk_buff 节点仍然存在足够的剩余空间 ,则无需新建节点,而是直接在该节点的缓冲区末尾进行追加写入 。具体过程与前述逻辑一致,即将数据按字节依次拷贝到 tail 所指向的位置,并同步更新 tail 的位置。
了解如何将应用层数据拷贝到 sk_buff 的缓冲区后,接下来讨论数据的发送过程。如前文所述,TCP 协议是面向字节流的,不区分数据边界,因此在输出缓冲区(即双向链表)中的一个 sk_buff 节点可能包含多个完整的数据报。但需注意,sk_buff 所指向的缓冲区(即预分配的内存块)虽然能集中存放应用层数据,它们却共享同一份预留的 TCP 和 IP 头部。然而,每个发送的数据报中 TCP 头部和 IP 头部的各字段并非完全相同,例如 TCP 头部的序列号。
假设当前输出缓冲区中待发送的 sk_buff 节点的缓冲区存储了 5000 字节的应用层数据。实际发送时并不会将该节点缓冲区中的所有应用层数据一次性全部发出,而是会按照 MSS 进行分段。MSS 基于 MTU 计算,以太网中 MTU 为 1500 字节,该长度为包括 IP 头和 TCP 头的完整数据包长度。因此,MSS 对应的是应用层数据部分,其大小为 MTU 减去 IP 头和 TCP 头的长度,即 1460 字节。
规定每个发送的数据包长度不超过 1500 字节,是因为底层数据链路层(即网卡)负责将数字信号(二进制序列)转换为物理信号。带宽反映了网卡的数据发送与接收能力,即单位时间内能将多少二进制序列转换为物理信号。带宽越高,单位时间内网卡发送到网络的数据量越大。若对数据包大小不加限制,过大的数据包会占用更长的转换时间,导致其他待发送数据包在缓冲区中排队等待并且交换机和路由器的缓冲区有限,小包更易缓存。
若传输层不进行分段,直接发送 5000 字节,则数据在传输层处理后,还需经过网络层处理。此时网络层会强制进行分片:若待发送数据包总长度超过 MTU,会将其拆分为多个分片,每个分片都包含 IP 头部,但只有第一个分片包含 TCP 头部。每个分片携带 IP 头部的原因是,路由器以分片为单位进行转发,若无 IP 头部,则无法查询转发表以将其送达目标主机。IP 头部的标识字段用于标识属于同一完整报文的所有分片。网络层将这些分片按标识符存储在缓冲区中(通常以链表组织),每个分片的 IP 头部还包含 MF 标志位和片偏移字段。MF 标志位占 1 比特,0 表示后续无数据,1 表示后续还有分片;片偏移表示该分片在完整报文中的起始位置。目标主机的网络层可根据 MF 标志位和片偏移判断当前数据包是分片还是完整报文。若 MF 为 1,或 MF 为 0 但片偏移不为 0,则判定为分片,内核将其暂存于缓冲区(结构可为链表或红黑树),待收齐所有分片后,再按片偏移重新组合为完整 IP 报文。
需要注意的是,路由器作为工作在网络层、数据链路层和物理层的网络设备,能对 IP 分片进行路由和转发,但不会对其进行重组。如果路由器执行重组,在未能收齐所有分片时,这些分片会一直占用缓冲区。而路由器每时每刻需处理大量数据包,若执行此类逻辑,缓冲区将迅速耗尽。因此,IP 分片的重组仅在目标主机进行。若某个分片在网络中丢失,目标主机因无法收齐全部分片而不进行重组,也就不会将重组后的 IP 报文递交至传输层。传输层未收到数据,自然不会向发送方发送确认报文,最终发送方会触发超时重传,重传整个 IP 数据包而非单个分片。因此,传输层主动进行分段,正是为了尽量避免网络层的分片。因为分段丢失时,发送方可针对性地重传该分段;而分片丢失则需要重传整个 IP 数据包。
理解了这一点之后,再回到正题。当应用层调用write或者send接口写了5000 字节的数据,若输出缓冲区的双向链表中最后一个 sk_buff 节点的缓冲区有足够剩余容量,数据会追加到其末尾。这意味着,一个 sk_buff 节点可能包含应用层多次写入的数据。由于 TCP 是面向字节流的,不关心也不区分该缓冲区中哪些数据对应一次完整的应用层写入,即不识别数据边界。此时,sk_buff 缓冲区中的数据虽然共享同一份 TCP 和 IP 头部,但实际发送时,为避免网络层分片,必然需要根据 MSS 将缓冲区数据截取为多个分段发送。然而,每个分段对应的协议头字段实际上并不相同,因此各分段无法共享完全相同的协议头,每个分段必须拥有自己独立的协议头。
因此,内核在发送数据时,会构建一个新的 sk_buff 结构体。该结构与 sock 中双向链表内的 sk_buff 节点在形式上相同,但作用与内容不同:其缓冲区中存储的是包含一个 TCP 分段的应用层数据。内核通常不会从输出缓冲区的 sk_buff 节点中拷贝某一数据区间到新节点,而是直接让新构建的 sk_buff 共享原始 sk_buff 所使用的物理内存页,并通过增加该内存页的引用计数来保证其生命周期,从而避免数据拷贝,而协议头部分是各自独立分配的。接着,内核会初始化并填充各自的 TCP 头和 IP 头,这意味着协议头与应用层数据在物理上并不连续存储。
cpp
发送一个TCP段时的完整结构:
skb0:
┌──────────────────────────────┐
│ sk_buff 结构体 (192字节) │
│ - head, data, tail, end │
│ - frags[] 数组 │
└──────────────────────────────┘
│
├─────(head指针)──────→ ┌────────────────┐
│ │ 线性缓冲区 │
│ │ 预留空间 │
│ ├────────────────┤
│ │ IP头 (20字节) │
│ ├────────────────┤
│ │ TCP头(20字节) │← data指针
│ └────────────────┘
│
└─────(frags[0])────────→ ┌────────────────┐
│ 共享数据页 │
│ [0..1459] │← 应用数据
│ 1460字节 │
└────────────────┘
引用计数++
skb1:
┌──────────────────────────────┐
│ sk_buff 结构体 │
└──────────────────────────────┘
│
├─────(head指针)──────→ ┌────────────────┐
│ │ 线性缓冲区 │
│ │ IP头 (不同!) │← 私有的
│ │ TCP头(不同!) │← 私有的
│ └────────────────┘
│
└─────(frags[0])────────→ ┌────────────────┐
│ 同一个数据页 │
│ [1460..2919] │← offset不同
│ 1460字节 │
└────────────────┘
引用计数++这里当应用层调用 write 或 send 接口写入数据时,若发送缓冲区(即写队列中双向链表的最后一个 sk_buff 节点)所指向的数据区仍有足够的剩余空间,那么内核会将新写入的数据直接追加到该缓冲区的末尾 。
而如果该缓冲区已经没有剩余空间,那么内核会新分配一个 4KB 的内存页,并将剩余的数据写入这个新的内存页中。
至此,就需要引入更贴近真实实现的物理模型 ,以解答前文埋下的伏笔。此前我们为了便于理解,曾将协议头与应用层数据简单地视为位于一块线性连续的内存中;但在实际发送阶段,数据会根据 MSS 进行分段,每一个 TCP 报文段都会对应一个 sk_buff。为了避免数据拷贝,内核并不会为每个报文段重新复制数据,而是会构造多个新的 sk_buff,并让它们共享同一组物理内存页,只是各自指向该内存页中不同的 MSS 区间。
事实上,这里所谓的"四元组"仅指向 线性区(Linear Area) ,而这个"线性"仅限于协议头部分。原因在于:每一个新构建的 sk_buff 都对应一个独立的 TCP 报文段,而不同报文段的 TCP/IP 头部字段(如序列号、校验和等)必然不同,因此协议头必须是私有的 。
而真正的应用层数据则被多个 sk_buff 所共享,这就导致协议头与数据区在物理上是分离的,而非连续的。
不过需要强调的是:每一个 sk_buff 的协议头部分自身始终是连续的 。因此,在构建新的 sk_buff 时,内核会为其分配一小块线性内存,用于存放该报文段私有的协议头。
此时:
- 四元组指向的正是这段协议头所在的线性区;
head指向线性区的起始位置;end指向线性区的结束位置;data与tail在初始状态下是重合的,且位于线性区中部(为后续向前"压栈"协议头预留空间)。
当数据真正进入发送阶段时,内核会依次构建各层协议头:
首先向前移动 data 指针至 TCP 头起始位置并填充 TCP 头字段;随后继续向前移动到 IP 头起始位置并填充 IP 头;最后再移动到链路层帧头起始位置并填充帧头。
完成上述步骤后,data 指向整个协议头的起始位置,tail 则指向协议头的末尾。
既然已经明确:四元组仅指向协议头所在的线性区,那么应用层数据又是通过什么机制与 sk_buff 关联的呢?
答案正是"三元组",也就是分片数组(Fragment Array)。
sk_buff 内部还维护了一个分片数组,其核心是一个 struct skb_shared_info * 指针,用于指向分片数组所在的共享信息结构体。该结构体中维护的是一组描述非线性数据区的条目,每个条目由三部分组成:物理内存页地址、页内偏移量以及该分片的长度。
cpp
struct sk_buff {
/* 线性缓冲区指针 (Linear Area): 存储协议首部 */
unsigned char *head;
unsigned char *data;
sk_buff_data_t tail;
sk_buff_data_t end;
/* 长度度量 */
unsigned int len;
unsigned int data_len;
/* 共享信息 */
struct skb_shared_info *shinfo;
/* 发送队列双向链表 */
struct sk_buff *next;
struct sk_buff *prev;
};
struct skb_shared_info {
unsigned char nr_frags;
atomic_t dataref;
skb_frag_t frags[MAX_SKB_FRAGS];
};
struct skb_frag_struct {
struct {
struct page *p;
} page;
__u32 page_offset;
__u32 size;
};当应用层调用 write 或 send 写入数据,而数据尚未进入发送阶段时,这些数据会不断被追加到当前 4KB 内存页的末尾;若该页被写满,则会分配新的内存页,并继续追加。
在这一阶段,sk_buff 的角色更接近于一个**"字节仓库"**,用于缓存应用层持续写入的数据流。
在初始状态下,每一个 sk_buff 的分片数组通常只维护一个内存页,因此 nr_frags = 1。该分片的页内偏移量为 0,表示整个内存页专用于存放应用层数据;size 则随着写入操作不断增长。
为了保证内核设计上的一致性以及 sk_buff 数据结构语义的统一:sk_buff 的协议头与应用层数据在所有阶段始终是逻辑分离的 ,并不存在"原始 sk_buff 为连续内存,而新构建的 sk_buff 才采用分离存储"的差异化实现。
4KB 内存页始终仅用于存储应用层数据,而协议头始终位于独立的线性区(linear area)。
每当应用层继续调用 write 或 send,内核就会不断更新当前分片的 size;当该页写满后,会分配新的内存页,并在分片数组中新增一个条目,其页内偏移量同样为 0,随后重复上述过程。
由于分片数组最多包含 16 个条目,这意味着单个 sk_buff 最多可容纳约 64KB 的应用层数据 。若应用层一次性写入的数据超过该上限,则内核会构建新的 sk_buff 结构体来承载后续数据。
进入发送阶段后,每一个 sk_buff 只能对应一个 TCP 报文段 。此时内核会构建新的 sk_buff,为其分配独立的线性区以存放私有协议头,同时共享原始 sk_buff 的数据区 。
具体而言,新构建的 sk_buff 并不会重新分配数据页,而是通过分片数组指向原始数据页中的某一个区间,此时其页内偏移量不再为 0。由此实现了完整的数据区共享,也即零拷贝。
需要注意的是,某些 TCP 报文段的数据可能跨越多个内存页,此时该 sk_buff 的分片数组条目数量将大于 1。
真相大白:SKB 并非内存的搬运工,而是资源调度员
到了这里,之前埋下的那个伏笔终于可以揭晓了:sk_buff 根本不是一整块死板的内存,它其实是一套极其优雅的"分权治理"架构。
为了实现极致的性能,内核把一个包拆成了两个部分来管理:
- 四元组(线性区)------ 专属的"定制包装盒" : 每个新构建的
sk_buff都有自己独立的一个小空间(线性区)。这就像是每个外卖订单都有一个独立的包装盒。包装盒上要写上这个包特有的"配送信息":这单的单号是多少(TCP 序列号)、要送到哪层楼(目的 IP)、有没有加急标志。这个盒子是私有的,因为每个人的单号肯定不一样。 - 三元组(分片数组)------ 共享的"中央大厨房" : 真正的货物(应用层数据)全都老老实实地躺在那些 4KB 的物理页里。这就像是一个巨大的中央厨房。厨房里备好了几大桶已经做好的"米饭"(原始数据流)。
真正的硬核逻辑在于: 当外卖准备出发(发送)时,内核压根不会从大桶里把米饭"盛"出来装进每个包装盒。这样太慢了,还费体力(CPU 拷贝开销)。
相反,它只是在每个包装盒里塞了一张**"提货指令单"**(也就是修改分片数组里的 offset 和 size):
"盒子 A:去 1 号厨房,从第 0 粒米开始取,取 1460 粒。" "盒子 B:去 1 号厨房,从第 1460 粒米开始取,取 1460 粒。"
网卡硬件(DMA 引擎)就像一个手脚利索的配送员。它直接扫描每一个包装盒:先读盒子上的配送信息(协议头),然后根据指令单,直接冲进大厨房对应的位置,把米饭抓出来装进车里直接发走。
这就是 Linux 内核实现极致零拷贝的物理真相:包装是包装,货物是货物。逻辑上是一份完整的外卖,但在物理内存里,包装盒跟大厨房是完全分开的。
cpp
write_queue 链表 (存储阶段,假设应用层调用write一次写了5000字节):
HEAD → [skb0 仓库节点] → TAIL
(总计 5000 字节)
↑
尚未分段,只是一个大载体
--------------------------------------------------------
skb0 控制结构 (Linear Area):
┌──────────────────────────────────────┐
│ data/tail 重合在中间 (预留给未来的头) │
└──────────────────────────────────────┘
skb0 共享信息 (Shared Info - 分片数组):
┌──────────────────────────────────────┐
│ nr_frags = 2 │
│ [frags 0]: page_ptr -> Page_A │
│ offset -> 0 │
│ size -> 4096 (持续增长) │
└──────────────────────────────────────┘
┌──────────────────────────────────────┐
│ nr_frags = 2 │
│ [frags 0]: page_ptr -> Page_B │
│ offset -> 0 │
│ size -> 904 (持续增长) │
└──────────────────────────────────────┘
--------------------------------------------------
第一次分段:tcp_fragment(skb0, 1460)
目的:从仓库中剥离出第一个 MSS。
操作 1:修正原本的 skb0 (使其成为第一个报文段)
内核缩减 skb0 的载荷范围,使其正好等于一个 MSS。
线性区操作:执行 skb_push,data 指针向前偏移,填充该报文段私有的 TCP/IP 协议头。
分片区操作:
frags[0].size: 由 4096 修正为 1460。
nr_frags: 修正为 1(因为它不再持有 Page_A 后半部分和 Page_B 的数据)。
操作 2:创建新节点 skb0_1 (承接剩余数据)
分配新的 sk_buff 结构及其独立的线性区,将原 skb0 吐出来的"剩余遗产"全部收入囊中。
线性区操作:预留空间,准备在发送时填充自己的协议头(Seq = 原 Seq + 1460)。
分片区操作 (分身继承逻辑):
nr_frags = 2 (因为它继承了 Page_A 的剩余部分和完整的 Page_B)
[frags 0]: Page_A, offset = 1460, size = 2636 (4096 - 1460)
[frags 1]: Page_B, offset = 0, size = 904
结果: skb0_1 此时逻辑长度为 3540 字节。
操作 3:内存引用管理
Page 引用计数: Page_A 的引用计数从 1 变为 2(被 skb0 和 skb0_1 共同持有);Page_B 引用计数仍为 1(仅被 skb0_1 持有)。
物理真相: 物理内存页中的 5000 字节稳如泰山,完全没有拷贝。内核仅通过调整两个 sk_buff 内部 frags 数组的 offset 和 size,就实现了逻辑上的切分。
操作 4:发送判定与递归切分 (The Loop)
在操作3 完成内存引用增加后,内核紧接着会进入一个高效的判定循环:
分段即发送: 第一个分段 skb0 (1460 字节) 之所以被切出来,是因为它在进入 tcp_fragment 之前,就已经通过了拥塞窗口(cwnd)和接收窗口(rwnd)的"海关检查"。所以它一旦重塑完成,会直接投递到底层驱动。
残余段重评估:现在注意力回到了 skb0_1(那个承接了剩余 3540 字节的"遗产包")身上。判定条件:内核会问:"我的发送窗口还有剩余吗?这 3540 字节是否又攒够了一个 MSS?"
递归操作:如果条件依然满足(比如此时窗口还够发),内核会立刻对 skb0_1 重复之前的步骤。
链表演进:skb0_1 被原地裁剪为 1460 字节(第二个 TCP 报文段)。再次分裂出一个新的 skb0_2,继承剩下的 3540 - 1460 = 2080$字节。Page_A 的引用计数从 2 变为 3(被 skb0、skb1、skb2 共同瓜分)。
所以这里在对上文所讲的TCP数据流转的内容进行一个总结以及收尾:
1. 存储阶段:作为"字节仓库"的 skb
当应用层调用 write 写入数据时,内核的首要目标是极致的载荷堆积。
- 物理页追加 :此时的
skb本质上是一个分配在内核中的内存页容器 。新写入的数据会持续追加到sk_buff指向的物理页中,直到达到页边界或数据写完。 - 仓库载体 :在这个阶段,
skb并不关心 MSS,也不关心协议封装。它就是一个字节仓库 ,通过分片数组(frags)将零散的物理页串联起来。此时缓冲区中的数据是完全不分边界的连续流,单个skb节点持有的载荷长度可能远超 MSS,直到填满 16 个分片条目或达到发送上限。
2. 发送阶段:基于 MSS 的"递归收割"
只有在触发发送动作时,这个"仓库"才会被推向协议栈的手术台。内核必须按照 MSS 标尺对这团"生肉"进行精准切分:
- 就绪即切分 :内核在发送循环中,看准窗口空间,对
skb仓库执行tcp_fragment。 - 原地分裂(Splitting) :这是一个"细胞分裂"过程。原始
skb被缩减为第一个标准 MSS 长度,而剩余的"仓库资产"被瞬间过继给一个新创建的skb_next节点。 - 私有头封装 :分裂出的两个
skb拥有各自独立的线性区(Linear Area) 。内核通过skb_push在各自的私有空间内填充 TCP/IP 头部。尽管载荷依然共享同一块物理页,但每个段都拥有了独立的序列号和校验和。
3. 动态循环:残余段的持续收割
这并非一次性的切分,而是一个**"切一刀、走一个、剩一坨"**的动态收割过程。
- 残余评估 :第一个 MSS 报文段发走后,内核立即对那个承接了剩余数据的
skb_next进行评估。 - 循环推进:只要发送窗口仍有余量且满足发送算法,内核会针对残余段重复执行切分逻辑。直到数据被完全拆解为标准的报文段,或窗口耗尽。
4. 重传保障:协议栈的物理镜像
这种动态切分产生的 skb 链表,构成了网络中数据包的真实物理镜像。
- 边界锁定 :每一个
skb节点都通过offset和size锁定了一段特定的物理内存区间。 - 高效重传 :当发生丢包时,内核无需重新访问"字节仓库"进行二次切分,直接将发送队列(
write_queue)中这些已经定义好边界的skb重新投递即可。这种设计将"分段"的复杂性留在发送那一刻,而让"重传"变得极度简单高效。
与 TCP 的字节流合并机制不同,UDP 是面向报文的协议。虽然 UDP 套接字在内核中同样使用 sock 结构作为基类,但在数据封装上有着本质区别:
- 报文不合并 :在 UDP 的发送过程中,内核不会对多次写入的数据进行合并。应用层每调用一次发送接口(如
sendto),内核就会创建一个独立的sk_buff。这意味着每一个sk_buff从诞生起就对应一个完整、独立的应用层数据报。 - 私有头部的连续性 :由于 UDP 不存在动态分段的需求,每个
sk_buff在初始化时就会分配好包含协议头和数据区的连续且完整内存块。每一个节点都拥有自己私有的 UDP 头部和 IP 头部,不会像TCP那样,数据区和协议头部是分离的 - 直接投递 :在发送时,UDP 不需要像 TCP 那样经历"在缓冲区攒数据"和"后期动态切分"的过程。输出缓冲区(双向链表)中的每一个节点本身就是一个准备就绪的物理镜像,内核直接依次将这些
sk_buff节点提交给网络层发送即可。
这种设计保证了 UDP 的边界对齐:应用层发的是什么,网络上跑的就是什么。
序列号以及确认号
那么根据上文,我们已经认识了 sock 结构体中的输入缓冲区和输出缓冲区。其本质都是一个双向链表,并且链表中的每一个节点都是一个 sk_buff。
每一个 sk_buff 内部都会维护一组数据指针,用于指向一块预先分配的内存区域,该内存区域中既包含数据区,也预留了用于协议头的空间,其大小通常以一个内存页为单位,一般为 4KB。
而我们知道,TCP 协议的一个核心特性是保证数据传输的可靠性。应用层要发送的完整数据,在经过传输层时会被拆分为多个 TCP 报文段,然后再发送到网络当中。在实际网络环境中,可能由于网络拥塞或路径差异,导致某些后发送的报文段反而先于之前发送的报文段到达接收方。
因此,接收方在收到这些报文段时,首先需要具备识别报文段是否乱序到达的能力,其次还需要能够将这些乱序到达的报文段重新组合为正确的字节流。而要实现这两点,就必须依赖 TCP 中的序列号机制。
所谓序列号,本质上是用于描述数据的有序性。在 TCP 连接建立完成后,通信双方会各自为即将发送的数据字节流中的每一个字节 分配一个序号。
我们知道,发送方会将应用层写入的数据暂存到发送缓冲区中,而发送缓冲区本身是一个由 sk_buff 组成的双向链表。链表中的每一个 sk_buff 节点都对应一段待发送的数据。
虽然从物理内存布局上看,这些 sk_buff 中的数据并不一定是连续存放的,但在逻辑上,我们可以将整个发送缓冲区中的数据抽象为一个一维的、连续的字节流(可以类比为一个 char 类型的线性数组)。
在这个逻辑字节流中,发送方会为第一个字节随机选择一个初始序列号,例如记为 x,而后续的每一个字节,其序列号都在前一个字节的基础上依次加一。
因此,TCP 的序列号实际上描述的是:某一个字节在整个有效数据字节流中的逻辑位置。
在理解了序列号的含义之后,接下来可以结合一个具体的发送场景来说明其实际应用过程。
我们知道,应用层在一次系统调用中可能会写入大量数据,例如通过 write 接口一次写入 5000 字节的数据。当内核接收到这 5000 字节的数据后,首先会检查发送缓冲区,也就是双向链表中最后一个 sk_buff 节点的剩余空间是否足以容纳这些数据。
如果当前 sk_buff 的剩余容量足够,那么内核会直接将这 5000 字节追加到该 sk_buff 数据区的末尾;
如果剩余容量不足以完整容纳这 5000 字节,那么内核会创建一个新的 sk_buff 节点,将剩余的数据拷贝到新节点的数据区中,并将该节点挂载到发送缓冲区的双向链表末尾。
需要注意的是,内核并不会将这 5000 字节的数据原样直接发送到网络中。由于该数据量已经超过了 MSS(Maximum Segment Size),因此在真正发送之前,TCP 层会对数据进行分段。
在这个例子中,5000 字节的数据大致会被拆分为 4 个 TCP 报文段,每一个报文段对应一个 sk_buff,并依次发送到网络中。在发送之前,内核会为每一个报文段初始化 TCP 报头和 IP 报头。
在初始化 TCP 报头时,其中一个非常重要的字段就是序列号字段。根据前文的分析,我们已经知道序列号是按字节递增的,而内核会为发送方发送的有效数据的第一个字节随机生成一个初始序列号。
需要强调的是,TCP 报头中的序列号字段,并不是记录该报文段中所有字节的序列号,而是记录该报文段中第一个字节的序列号 。
这是因为序列号是按照字节顺序线性递增的,只要已知某个报文段的起始序列号以及该报文段的数据长度,就可以推导出该报文段中所有字节的序列号。
而报文段的数据长度,可以通过 IP 报头中的总长度字段,以及 TCP 报头中的数据偏移字段计算得到。因此,一旦确定了报文段的起始序列号和长度,就可以唯一确定该报文段所覆盖的字节序列号范围。
由此可知,内核只需要随机生成发送方有效数据的第一个字节的序列号,而后续每一个报文段的起始序列号,都可以通过"前一个报文段的起始序列号 + 前一个报文段的数据长度"计算得到。在发送到网络之前,内核会据此完成 TCP 报头中序列号字段的初始化。
假设在发送过程中,网络出现了拥堵,第一个报文段由于网络状况较差,反而比后续的三个报文段更晚到达目标主机。
由于 TCP 是以字节为单位进行编号的,接收端的套接字(对应 tcp_sock 结构体)会维护两个关键的数据结构:有序队列和乱序队列。
在 Linux 内核中,tcp_sock 是通过类似 C++ 面向对象的"结构体嵌套"方式实现的。其最上层的 sock 结构体中维护了一个双向链表,该链表用于表示已经按序到达的数据,即有序队列,其中每一个节点都是一个 sk_buff。
而乱序队列并不位于 sock 结构体中,这是因为无论是 udp_sock 还是 tcp_sock,其最上层的 sock 结构体布局是统一的。为了保证结构的一致性,TCP 特有的乱序队列被放置在 tcp_sock 结构体中。乱序队列同样是一个由 sk_buff 组成的双向链表。
除了乱序队列之外,tcp_sock 还会维护一个变量,用于记录期望接收到的下一个字节的序列号 。
当接收端收到一个 TCP 报文段时,会从 TCP 报头中取出序列号字段,该序列号表示该报文段中第一个字节的序列号。
接收端会将该序列号与当前期望接收的下一个字节序列号进行比较:
- 如果两者相等,说明该报文段正是当前期望接收的下一个报文段,那么其数据会被拷贝到有序队列中。如果有序队列尾部的
sk_buff剩余空间不足,则会新建一个sk_buff,并将数据拷贝到新的节点中,再插入到队尾。 - 如果该序列号大于期望接收的下一个字节序列号,说明该报文段属于后续到达的乱序数据,此时不会丢弃,而是插入到乱序队列中等待后续重组。
- 如果该序列号小于期望接收的下一个字节序列号,则说明该报文段是已经接收过的重复报文(后文会解释),内核会直接将其丢弃。
而这里还需要注意的是:当内核收到了一个按序到达 的 TCP 报文段时,根据上文的描述,该报文段会被放置到有序队列 中,同时内核会更新期望接收的下一个字节序列号 。这个"下一个期望序列号"的计算方式为:当前收到的报文段中第一个字节的序列号,加上该报文段所携带的数据长度。
随后,内核还会继续遍历乱序队列 。在现代 Linux 内核中,乱序队列通常并不是采用双向链表实现,而是使用红黑树 ,其目的在于更高效地按照序列号进行查找与遍历。内核会检查乱序队列中是否存在序列号正好与当前期望值匹配的报文段;如果存在,则将该报文段从乱序队列中移除,并插入到有序队列中。该过程会持续进行,直到不存在可匹配的序列号,或者乱序队列为空为止。
在理解了序列号之后,接下来就需要引入确认号(ACK Number)*的概念。确认号在数值层面上与序列号并无本质区别,但其*语义与作用完全不同。TCP 的可靠传输机制,正是依赖于序列号与确认号的配合**来实现的。
我们知道,发送方将数据包发送到网络之后,在网络转发过程中可能会发生丢包。而 TCP 可靠性的重要体现之一,就是发送方必须能够确认自己发送的数据是否被接收方成功接收 。那么,发送方是如何得知这一点的呢?答案是:接收方在成功接收到数据后,会向发送方返回一个确认报文。
该确认报文的含义可以概括为:"我已经成功接收到了你发送的数据。"
但需要注意的是,这里不仅仅是一个"收到"的语义,还必须明确指出:成功接收的是哪一个序列号范围内的数据。当发送方收到确认报文之后,便能够确认其发送的某一个 TCP 分段已经被对方成功接收。
在此基础上,发送方就可以对输出缓冲区 进行回收操作,释放对应的 sk_buff 节点。根据前文的描述,一个完整的应用层数据通常存储在一个内存页中,而多个 sk_buff 会指向该内存页中的不同区间,从而共享同一块数据区。因此,这里的"释放"并不会立刻回收存储应用层数据的内存页,而只是释放 sk_buff 结构体本身,并递减其对数据页的引用计数。只有当引用计数减为 0 时,才会真正释放用于存放应用层数据的内存页。
当接收方向发送方发送确认报文时,需要通过 TCP 报头中的 ACK 标志位 来明确该报文的类型。具体而言,TCP 报头中的 ACK 标志位被设置为 1,表示这是一个确认报文 ;如果该标志位为 0,则确认号字段不具备有效语义。发送方在接收到 TCP 报文后,会首先检查 ACK 标志位;若其值为 1,则进一步读取并解析确认号字段,并执行前文所述的确认与释放逻辑。当然,在后续引入滑动窗口机制之后,这一流程还会进一步扩展和完善。
关于确认号的语义,还需要进一步补充说明。确认号的作用不仅在于通知发送方"数据已被接收",还明确表示:从某个序列号之前的所有字节,接收方均已成功接收。因此,确认号的计算方式尤为关键。
假设接收方成功收到了一个起始序列号为 x 的 TCP 报文段,在接收完成之后,接收方并不会直接"确认 x",而是告知发送方:下一个期望接收的字节序列号是什么 。也就是说,确认号的值等于 x 加上该报文段的数据长度,得到下一个分段的起始序列号,假设为 y。当发送方收到该确认报文并识别到 ACK 标志位为 1 后,读取确认号 y,即可得知:序列号小于 y 的所有字节,均已被对方成功接收。
到这里我们可以明确:发送方发送了一个携带有效数据的 TCP 报文段,接收方在成功接收之后,必然会向发送方返回一个确认报文。而 TCP 是全双工通信协议,数据传输是双向的,这意味着通信双方既可以作为发送方,也可以作为接收方。因此,同理可知,当对方发送携带有效数据的报文段时,本端在接收后也需要向其发送确认报文,告知其"此前序列号范围内的所有字节均已成功接收"。
在 TCP 协议的早期设计中,采用的是停止等待协议(Stop-and-Wait) 。其基本工作方式是:一方发送一个携带有效数据的 TCP 报文段之后,必须等待对方返回一个纯 ACK 报文段 (即不携带任何有效数据的 TCP 报文段),在收到确认之前,不再继续发送新的数据。纯 ACK 报文段的作用,仅用于确认序列号为 x 之前的所有字节已被成功接收。
这种通信方式在双方是对称的:一端发送携带有效数据的报文后会进入等待状态,直到收到确认;另一端亦是如此。然而显而易见,这种方式的通信效率是非常低的。
如果我们重新审视这种交互模式,会发现它更像是两个人对话时的"你一句、我一句确认"的形式。例如,一个人说:"你吃了吗?",另一个人回复:"收到。"------但在现实场景中,更高效的交流方式往往是:"你吃了吗?"------"收到,我吃了。",即在回复中捎带确认信息。
正因如此,现代 TCP 协议已经不再采用停止等待协议,而是引入了更高效的捎带应答(Piggybacking)机制。舍弃停止等待协议的根本原因在于:一旦发送方发送了一个携带有效数据的 TCP 报文段,便立刻进入等待状态,无法继续发送后续数据,这会极大地浪费链路带宽。
如果进一步分析这一过程,还可以计算出下一次能够发送数据的时间。首先,TCP 报文段需要经过网卡设备,将二进制数据转换为物理信号并发送到链路上,这一过程与网卡带宽密切相关。带宽表示单位时间内网卡能够处理并发送的比特数量,例如常见的 1000 Mbps 网卡。
| 单位 | 全称 | 换算关系 (以 bit 为基准) | 常见应用场景 |
|---|---|---|---|
| bps | bit per second | 1 | 极慢的传感器数据 |
| Kbps | Kilobit per second | 10^3 (1,000) bps | 早期的拨号上网 |
| Mbps | Megabit per second | 10^6 (1,000,000) bps | 现代家用宽带 (如 300M, 1000M) |
| Gbps | Gigabit per second | 10^9 bps | 万兆网卡、数据中心骨干网 |
| Tbps | Terabit per second | 10^12 bps | 核心交换机集群、海底光缆总带宽 |
在现代网络环境中,发送时间本身通常是极其短暂的,真正占据主要时间的是数据在网络中的传播延迟。数据经过中间路由器节点转发后,最终到达目标主机。随后,目标主机的网卡会将接收到的物理信号转换为二进制序列,并存储到网卡自身的缓冲区中。
接下来,网卡会首先完成数据链路层的处理工作,包括校验数据帧的帧头和帧尾,并在校验完成后剥离帧头和帧尾。之后,需要将剥离后的、仍然包含网络层及以上协议头和应用层数据的报文段,拷贝到主机内存中。
需要注意的是,此时网卡已经得到了一个完整的 TCP/IP 报文段,并需要将其存放到一块连续的内存区域 中。现代主机通常采用多核 CPU 架构,每一个 CPU 核心都可以独立地执行网络协议栈的处理流程。因此,在系统启动时,内核会为每一个 CPU 核心预先分配一个接收用的环形缓冲区。
该环形缓冲区本质上是一个描述符数组 ,也可以简单理解为一个指针数组。数组中的每一个元素都是一个结构体,其中最核心的字段是一个指针,指向一块预分配的内存区域。由于发送方在发送数据时会按照 MSS 对数据进行分段,因此单个数据报的大小是有上限的。内核通常预分配大小为 4KB 的内存块,以确保能够容纳一个完整的数据报。预分配的方式本身也是一种以空间换时间的优化手段,可以避免在数据到达时临时进行内存分配。
此外,该缓冲区之所以被称为"环形",是因为其大小是固定的,描述符数组中维护着读指针和写指针:读指针由内核维护,写指针则由 DMA 设备维护。在这里,有必要引入 DMA 的概念。
DMA(Direct Memory Access,直接内存访问)是一种用于减轻 CPU 负担的硬件机制。计算机系统中,CPU 与各类 I/O 设备共享总线,而总线可划分为数据总线、地址总线和控制总线。如果没有 DMA,I/O 设备之间无法直接与内存交互,所有数据拷贝操作都必须由 CPU 参与完成。
以网卡接收数据为例:若无 DMA,网卡需要先触发硬件中断,CPU 在响应中断后切换到内核态,读取网卡缓冲区的数据到 CPU 缓存中,然后再由 CPU 将数据写入内存。这一过程不仅涉及多次上下文切换,还会频繁占用总线资源。在高并发服务器场景下,这种方式会导致 CPU 大量时间用于处理中断和数据拷贝,从而严重影响正常任务的执行。
DMA 的引入极大地缓解了这一问题。DMA 控制器可以在无需 CPU 参与的情况下,直接将数据从网卡缓冲区拷贝到内存中的接收缓冲区。结合前文所述的多核架构,每个 CPU 核心都有独立的环形缓冲区,且每个描述符都指向一块已经预分配好的内存区域。
在数据到达后,网卡完成数据链路层的处理,并剥离以太网帧头和帧尾,随后从报文中提取五元组信息,即源 IP、目的 IP、源端口、目的端口以及协议类型。接着,网卡以该五元组作为输入,计算 RSS(Receive Side Scaling)哈希值。
在得到哈希值之后,网卡会查询间接表(Indirection Table) 。需要说明的是,间接表由多个基本条目组成,每一个基本条目本质上是一个二元组 ,包含一个索引 以及该索引所映射的接收队列号。由于在多队列网卡中,不同 CPU 核心通常对应各自独立的接收环形缓冲区,因此,这里的队列号实际上用于标识不同 CPU 核心所对应的接收队列。
通常情况下,间接表包含 128 个条目 。而 RSS 计算得到的哈希值往往是一个较大的数值,为了保证该哈希值能够映射到间接表的有效索引范围(0~127),会对哈希值进行一次取模运算,从而得到最终的索引值。通过该索引查表,即可得到对应的接收队列号。借助这种机制,可以保证同一个 TCP 连接上的所有报文段始终被分发到同一个 CPU 核心进行处理。
cpp
间接表(Indirection Table):
┌─────┬─────────┐
│索引 │ 队列号 │
├─────┼─────────┤
│ 0 │ 0 │
│ 1 │ 1 │
│ 2 │ 2 │
│ ... │ ... │
│ 52 │ 3 │← 查到了!
│ ... │ ... │
│ 127 │ 7 │
└─────┴─────────┘
使用方式:
1. 计算哈希值:hash = RSS_hash(五元组) = 0xABCD1234
2. 计算索引: index = hash % 128 = 52
3. 查表: queue = indirection_table[52] = 3那么这里读者可能会产生疑问:为什么必须保证同一个 TCP 连接上的所有报文段映射到同一个 CPU 核心,也就是说交由同一个 CPU 核心来处理? 如果同一个 TCP 连接的报文段不通过哈希算法固定映射到同一个核心的接收缓冲区,又会带来什么后果?
如果不存在这种基于哈希的映射机制,实际上就意味着多个 CPU 核心需要并发地访问同一个接收环形缓冲区。在这种情况下,不同 CPU 核心会从同一个环形缓冲区中取出指向 TCP 报文段的内存块,并继续执行后续的网络协议栈处理流程。
具体来说,CPU 会根据读指针指向的位置,从环形缓冲区中获取对应的内存块。需要注意的是,读指针本质上是一个位于内存中的地址值。CPU 首先会将该地址加载到寄存器中,然后再根据该地址从内存中读取完整的 TCP 报文段,并将其加载到该 CPU 核心的高速缓存中。随后,CPU 需要将读指针向后移动一个位置,以指向下一个待处理的缓冲区元素。
然而,这一过程实际上包含了多个步骤:从内存中读取读指针的值、根据该值访问数据、再更新读指针。在没有额外同步机制的前提下,这一系列操作并不具备原子性。
如果某个 CPU 核心在读取读指针并将对应数据加载到缓存之后,时间片到期发生上下文切换,而在读指针尚未完成更新之前,另一个 CPU 核心也开始读取同一个读指针,那么就可能导致多个核心处理同一份数据,或者跳过部分数据,从而引发数据不一致问题。
因此,一种更加直接且高效的做法是:为每一个 CPU 核心分配独立的接收环形缓冲区,从根本上避免多个核心对同一缓冲区的并发访问。同时,由于 RSS 哈希函数具有确定性,相同的五元组输入必然得到相同的哈希结果,从而保证同一 TCP 连接上的所有报文始终被分发到同一个接收队列和同一个 CPU 核心。这不仅减少了对共享数据结构的访问冲突,也避免了引入复杂且代价较高的加锁操作。
cpp
网卡寄存器空间布局:
─────────────────────────────────┐
│ 队列0寄存器组(0x1000-0x10FF) │← 一组寄存器
│ ├─ +0x00: RX描述符基地址低32位 │← 单个寄存器
│ ├─ +0x04: RX描述符基地址高32位 │← 单个寄存器
│ ├─ +0x08: RX描述符环长度 │← 单个寄存器
│ ├─ +0x0C: RX head指针 │← 单个寄存器
│ ├─ +0x10: RX tail指针 │← 单个寄存器
│ ├─ +0x14: RX中断控制 │← 单个寄存器
│ └─ ... │
├─────────────────────────────────┤
│ 队列1寄存器组(0x1100-0x11FF) │
│ ├─ +0x00: RX描述符基地址低32位 │
│ ├─ +0x04: RX描述符基地址高32位 │
│ └─ ... │
├─────────────────────────────────┤
│ 队列2寄存器组(0x1200-0x12FF) │
│ ... │
└─────────────────────────────────┘DMA 通常集成在网卡芯片内部。实际上,DMA 会根据对应的队列号(queue)读取相应的寄存器组 ,从中获取接收缓冲区的基地址 以及当前的写指针 ,并据此计算出需要拷贝的数据在内存中的起始位置。随后,DMA 会将数据从网卡的接收缓冲区直接拷贝到主存中。
当拷贝完成后,DMA 会向 CPU 发送一个硬件中断 ,用于通知 CPU 此时已经接收到 TCP 报文段,需要进入后续处理流程。CPU 在响应中断后会切换到内核态,并继续执行随后的网络协议栈处理逻辑。
cpp
struct rx_ring {
struct rx_descriptor *descriptors; // 描述符数组
unsigned int size; // 数组大小(如512、1024)
unsigned int head; // 硬件写入位置
unsigned int tail; // 软件读取位置
};
// 每个描述符
struct rx_descriptor {
u64 buffer_addr; // 指向内存块的物理地址
u16 length; // 数据长度
u16 packet_type; // 数据包类型
u32 rss_hash; // RSS哈希值
u16 vlan_tag; // VLAN标签
// ... 其他字段
};而这里需要注意的是:我们知道内存页的大小通常是 4KB ,而发送方在发送数据时会依据 MSS 进行分段,因此单个 TCP 报文段的应用层数据长度不会超过 MSS。由此可以推断,一个 4KB 的内存页在容量上完全可以容纳一个数据帧对应的应用层数据。
但如果一个内存页仅用于存储一个完整的数据帧,而一个典型以太网数据帧的有效负载长度大约为 1500 字节,那么这将导致大量内存空间被浪费。需要明确的是,操作系统在设计上不会采用这种低效且缺乏意义的方式;因此,一个成熟的 Linux 内核不可能选择"一个内存页只存储一个数据帧"的策略,因为这种方式的内存利用率过低。
基于这一考虑,内核通常会对一个内存页进行进一步划分,例如将一个 4KB 的内存页划分为两个 2KB 的分片。这样,一个内存页即可用于存储两个数据帧。考虑到一个数据帧的有效负载长度约为 1500 字节,而 2KB(2048 字节)能够容纳该数据规模并保留一定余量,这种方式能够显著提升内存利用率。
因此,这里就需要对之前的环形缓冲区模型进一步完善。此时,环形缓冲区中的每一个条目并不再对应一个完整的 4KB 内存页,而是仅对应其中的一个分片。也就是说,环形缓冲区中每一个槽位------也即描述符中保存的指针------实际指向的是一个 2KB 分片的起始地址。
在此基础上,我们可以进一步完善数据接收的整体流程:
网卡接收到数据包后,首先将物理信号转换为二进制序列,并存储到网卡自身的接收缓冲区中;随后提取数据包的五元组信息,计算哈希值,并查询间接表以确定目标队列号。接着,DMA 读取对应队列的寄存器组,获取环形缓冲区的基地址以及当前写指针位置,计算得到目标分片的内存起始地址,并将数据帧(不包括前导码以及帧尾的校验和)拷贝到该分片中,随后交由内核网络协议栈进行后续处理。
读到这里,读者可能会产生一个疑问:网卡与内核(或者说 CPU)之间实际上构成了一个生产者---消费者模型。网卡作为生产者,通过 DMA 向缓冲区写入数据,而内核作为消费者,通过读指针从缓冲区中取出数据帧。那么,当生产速度大于消费速度时,如何避免缓冲区被覆盖?
显然,DMA 不可能在不加控制的情况下持续写入并盲目推进写指针。这意味着 DMA 必须能够感知消费者的进度,也即读指针的位置。为此,在寄存器组中专门提供了一个 tail 寄存器,用于表示由内核维护的读指针位置。
同时,每一个 CPU 核心通常对应一个独立的环形缓冲区,因此内核需要对不同核心的环形缓冲区进行统一管理。其管理方式遵循"先描述、再组织"的原则:内核会为每一个环形缓冲区定义一个控制结构体,用于记录该缓冲区的相关属性,其中就包括读指针的位置。
内核通过读取该控制块获取读指针后,定位到对应的分片,并据此构建一个 sk_buff 结构体:初始化其分片数组,使其指向分片中对应的应用层数据区域;同时申请一个较小的线性内存块,将协议头拷贝到该线性区中,并使 sk_buff 的四元组信息指向该线性区。
此外,内核在处理读指针指向的数据帧时,并不局限于单个分片,而是会在写指针之前的有效范围内,向后扫描 读指针之后的分片,并提取其中的四元组信息(源 IP、目的 IP、源端口、目的端口)。若这些四元组与当前分片一致,则说明这些数据属于同一个 TCP 流。此时,内核会进一步检查序列号:如果这些数据报在序列空间上是连续的(即紧接在读指针所指向的数据之后),内核通常会在一定范围内进行扫描,例如最多扫描读指针在内的 64 个槽位 。这一上限并非随意设定,而是出于性能上的折中考虑:
若扫描范围过小,则在高吞吐场景下,内核需要频繁响应中断并反复进入软中断上下文,难以及时合并数据,反而增加调度与中断开销;
而若扫描范围过大,则内核可能在单次软中断处理中停留过久,占用 CPU 时间片,从而延迟其他进程的调度执行。
因此,诸如 64 这样的扫描上限,通常被视为在中断响应开销 与软中断处理时长 之间取得平衡的一种经验性取值。内核在一次处理过程中会顺序扫描这 64 个槽位 。由于每个槽位可能对应不同的流,内核的处理方式是:
先扫描一个槽位,并据此构建一个 sk_buff 结构体,然后继续向后扫描后续槽位。
如果后续槽位中提取出的 四元组 与当前读指针所对应的是同一个流 ,且其 TCP 序列号是连续的 ,则内核会执行合并操作。这里所谓的"合并",并不是重新构建新的 sk_buff,而是将后续属于同一流、且序列号连续的分片的应用层数据,直接挂载到当前的 sk_buff 上 ,从而减少 sk_buff 的创建与管理开销。
如果后续槽位对应的并非同一个流,则内核会新建一个 sk_buff ,并将后序属于该流且序列号连续的分片的应用层数据挂载到该 sk_buff 上;而当序列号不连续时,也只能独立构建一个新的 sk_buff,并将对应的数据挂载其中
由此可见,内核在一次扫描过程中可以并行地处理多个不同的流 ,并最终构建出多个 sk_buff,分别对应各自的流及其连续的数据段。
需要注意的是,有读者可能会认为:不同的 TCP 报文段具有不同的协议头,那么在将多个分片的应用层数据挂载到同一个 sk_buff 时,协议头应当如何处理?
这里涉及到一个精妙的逻辑:虽然每个 TCP 原始报文段的协议头在内容上有所不同,但其核心字段具有逻辑上的单调性与可累积性。例如,尽管各分段的序列号(Sequence Number)各异,但在合并过程中,内核只需保留第一个报文的协议头作为母本,并随数据挂载不断更新载荷长度与确认号。这种'逻辑归一化'的处理,使得多个分片能够共享同一个线性区中的协议头,极大地减少了冗余首部的解析开销。
对于标志位而言,如果被合并的报文中任意一个携带了 PSH 标志,则会在最终 sk_buff 的线性区中将 PSH 标志置位;但如果报文携带了 SYN、RST 或 FIN 等具有控制语义的标志,则该报文不能被合并。同样地,携带 URG 标志的报文也不参与合并(后文会详细讲解这些标志位)。每当一个分片被挂载到 sk_buff 的分片数组中时,内核都会相应地增加该内存页的引用计数。
当合并过程结束后,内核会从构建完成的 sk_buff 中提取四元组信息,并查询已连接套接字的哈希表,从而定位到对应的 sock 结构体。随后,内核根据序列号判断该数据应当进入有序队列还是乱序队列,并等待应用层调用 read 或 recv 接口读取数据。
当某个分片中的应用层数据被完全读取后,内核将释放对该分片的独占权,使其可以被回收复用。与此同时,内核会更新读指针的位置,使其向后移动一个槽位,并将新的读指针值写入对应的 tail 寄存器。
而在网卡侧,每一次 DMA 写入之前,都会检查缓冲区是否已满:即读取 tail 寄存器的值,并判断
( h e a d + 1 ) m o d s i z e = = t a i l (head + 1) \bmod size == tail (head+1)modsize==tail
若条件成立,则说明环形缓冲区已满,此时 DMA 将无法继续进行拷贝操作。
那么在了解了目标主机接收并处理一个 TCP 数据包的完整流程之后,接下来再补充说明一下路由器接收并处理 TCP 数据包的流程。总体来看,路由器与目标主机在数据包接收阶段的处理流程大致相似。
具体而言,路由器的网卡首先将接收到的物理信号转换为二进制比特流,并暂存到网卡的接收缓冲区中。随后,网卡对数据帧的帧头和帧尾进行校验,确认无误后,提取用于分发的关键信息(如五元组或用于 RSS 的字段),并计算哈希值。根据哈希结果查询间接表,得到对应的接收队列号。接着,DMA 控制器根据该队列号定位到对应的寄存器组,读取队列的基地址和读指针,计算出需要写入的内存起始地址,并将数据帧从网卡缓冲区拷贝到主机内存中。
当数据帧被拷贝到内存之后,CPU 会从内存中获取该数据帧,继续进行后续的网络协议栈处理,即网络层的处理逻辑。需要注意的是,路由器与目标主机在网络层的职责有所不同:路由器的网络层主要负责转发与路由决策,而目标主机的网络层还需要承担 IP 分片重组等工作。
在路由器中,网络层会首先提取出数据包中的目标 IP 地址,并据此查询转发表。路由器通常维护一棵前缀树(如 Trie),用于存储各个目标网络前缀。此时,路由器会使用目标 IP 地址在前缀树中进行最长前缀匹配,匹配到的叶子节点通常对应一个索引值。随后,路由器利用该索引去查询数组或哈希表,而数组或哈希表中的每一个元素通常是一个路由项结构体,其中包含下一跳设备的 IP 地址以及对应的出接口信息。
在确定下一跳之后,路由器需要获取下一跳设备的 MAC 地址。此时会先查询 ARP 表,如果未命中,则发送 ARP 请求报文以获取对应的 MAC 地址。最后,路由器将原始数据包重新封装为新的以太网帧,并通过选定的接口将该数据帧发送出去。
所以根据上文,我们可以知道,数据包首先会经由网卡被转换为物理信号,随后通过传输介质在网络中传播,依次经过中间的各个路由器节点。路由器在对数据包进行必要的处理后,将其转发至下一跳,最终到达目标主机。数据包在目标主机处经过完整的网络协议栈处理后,目标主机会向发送方返回一个确认报文(ACK)。
因此,整个过程的总耗时主要包括:发送时延、在物理介质上的传输时延,以及中间路由器节点和目标主机的处理时延。确认报文返回的路径在宏观上是对称的,而在整个过程中,发送时延相对于其他时延而言通常可以忽略不计。
如果通信双方采用的是停止---等待协议,那么发送方在发送一个数据报文后就必须停止发送,等待对方返回一个确认报文。在从发送数据到接收到确认报文的这段时间窗口内,发送方的网卡和链路资源只能处于空闲状态,从而导致带宽利用率极低,造成明显的资源浪费。
因此,在实际的 TCP 传输过程中,发送方并不会在发送一个 TCP 报文段后就立即停止发送,而是会连续发送多个 TCP 报文段。当然,这种连续发送并不是无限制的,发送方并不能随意发送任意数量的报文段,其发送上限受到多种因素的约束,这一点将在后文关于滑动窗口机制中进行说明。与此同时,对于接收方而言,在收到对方发送的 TCP 报文段之后,也并非总是发送一个仅用于确认的纯 ACK 报文,而是更倾向于采用捎带确认(Piggybacking)的方式,即在发送的报文中同时携带确认信息和有效数据,从而避免单独发送一个仅包含协议头的确认报文,提高传输效率。接收方同样可以连续发送一系列报文,其中包含对已接收数据的确认信息。
当发送方收到接收方返回的确认报文后,就可以确定某个确认序列号之前的字节已经被接收方成功接收,从而释放对应的 sk_buff 节点,回收相关的发送缓冲区资源。
我们知道,正是这种基于序列号与确认应答相结合的机制,保证了 TCP 的可靠性。只要发送方成功收到了接收方发送的确认报文,就意味着在发送方向接收方这一传输方向上,发送方可以确认:在该确认报文所确认的序列号之前,所有已发送的 TCP 数据都已经被接收方正确接收。
然而,这里存在一个潜在的问题:发送方能够确认其发送的数据已经被接收方全部接收的前提,是发送方最终能够成功收到对应的确认报文。如果确认报文在传输过程中丢失,那么接收方本身是无法感知其发送的确认报文是否已经被对方成功接收的。在这种情况下,对于发送方而言,是否会因此而一直陷入等待状态呢?
答案显然是否定的,而这正是 TCP 超时重传机制所要解决的问题
超时重传
根据上文,我们知道发送的确认报文(ACK)本身也可能存在丢失的情况。因此,发送方并不会在发送数据后一直被动等待对方的确认报文。具体来说,发送方在发送数据报文之后,会为该报文设置一个重传定时器(RTO)。如果在定时器到期之前收到了对方的确认报文,则不会触发超时重传机制;反之,如果定时器到期后仍未收到对应的确认报文,发送方就会认为该数据报文可能已经在传输过程中丢失,从而对尚未被确认的数据报文进行重传,并重新设置定时器。
如果定时器再次到期仍然没有收到确认报文,则会再次触发重传。若在连续重传达到一定次数后仍然无法收到对方的确认,这通常意味着对端可能已经异常退出或连接已不可达。在这种情况下,TCP 不会无限制地尝试重传,而是会在超过重传上限后主动终止该 TCP 连接。
因此,这里并不需要过度担心 ACK 报文丢失的问题,因为 TCP 的超时重传机制本身就是用于兜底处理此类情况的。需要注意的是,每当发送方发送了新的、尚未被确认的数据报文后,都会为这些报文设置相应的重传定时器。而这个定时器的超时时间并不是随意设定的,而是需要非常谨慎:如果定时器的时间窗口设置得过小,可能会导致 ACK 实际上尚在网络中传输,但发送方却误判为丢失,从而触发大量不必要的重传;而如果定时器设置得过大,则在真实丢包发生时,通信双方又会陷入较长时间的"沉默期",显著降低传输效率。
因此,RTO 的取值是动态调整的。这里需要注意的是,发送方在发送 TCP 数据报文时,会将当前的发送时间戳记录到 TCP 头部的时间戳选项字段(Timestamp Option)中。接收方在收到该 TCP 报文后,会在返回的确认报文中,将该时间戳回填到 TCP 头部的时间戳回显字段中。同时,接收方在发送 ACK 报文时,也会将其自身发送该 ACK 的时间戳写入 TCP 头部的时间戳选项字段。
cpp
发送方发送数据:
┌────────────────────────────────┐
│ TCP Header │
├────────────────────────────────┤
│ Options: │
│ Timestamp: │
│ TSval = 12345678 ← 发送时间│
│ TSecr = 87654321 ← 回显 │
└────────────────────────────────┘
接收方发送ACK:
┌────────────────────────────────┐
│ TCP Header │
├────────────────────────────────┤
│ Options: │
│ Timestamp: │
│ TSval = 12346000 ← 接收方时间│
│ TSecr = 12345678 ← 回显发送时间!│
└────────────────────────────────┘
发送方收到ACK后:
当前时间 = 12345878
发送时间 = TSecr = 12345678(从ACK中获取)
RTT样本 = 12345878 - 12345678 = 200ms最终,发送方在收到确认报文后,结合原始发送时间戳 、对方回显的时间戳 以及当前收到确认报文的时间点,即可计算出一次完整的 RTT(Round-Trip Time,往返时延)。随后,内核会使用特定的平滑与加权算法对 RTT 进行处理,并引入一定的抖动量,最终计算得到重传超时时间 RTO。
滑动窗口
那么在认识了超时重传机制 之后,接下来就需要引入滑动窗口机制。
我们发现 TCP 报头中包含一个字段,即窗口(Window)字段。根据上文的分析可以知道,对于发送方而言,不可能不加限制地发送发送缓冲区中的所有数据。原因在于接收方的处理能力是有限的。
对于接收方来说,当其收到对方发送的数据包后,首先由网卡将物理信号转换为二进制数据并存储到网卡自身的缓冲区中,随后通过 DMA 将数据从网卡缓冲区拷贝到内存中的某个环形缓冲区 。本质上,网卡与内核之间构成了一个生产者--消费者模型:网卡负责生产数据,内核负责消费数据。
如果发送方无限制地发送数据,将会导致网卡持续不断地把数据搬运到内存的环形缓冲区中,并不断推进写指针。而内核则通过读指针读取当前读指针所指向位置的分片数据,构建 sk_buff,并将该分片挂载到 sk_buff 的分片数组中。这里采用的是零拷贝策略。
一旦某个分片被挂载到 sk_buff 上,该分片就会被内核独占,不再归网卡所有,这意味着网卡不能再覆盖该分片中的数据。并且根据上文可知,内核不仅会读取当前分片,还会从当前位置向后扫描后续分片:如果后续分片属于同一个流(四元组相同),且 TCP 序列号是连续的,也会一并挂载到同一个 sk_buff 中。
然而,如果应用层始终不调用 read 或 recv 接口来读取数据,那么这些分片会一直被内核占用,无法被回收,最终导致环形缓冲区被填满。一旦缓冲区耗尽,后续到达的数据将只能被丢弃。
因此,滑动窗口机制的本质,就是在通信双方之间进行流量控制的协商。如果不对发送方的发送速率和发送量加以限制,就会出现生产速度大于消费速度的情况,最终导致接收方丢包。丢包的直接后果是:接收方无法对这些数据发送确认报文,发送方只能依赖超时重传机制进行重传。
虽然 TCP 通过超时重传机制保证了可靠性,但需要注意的是,TCP 不仅关注"可靠",同样关注"效率"。如果接收方始终无法腾出足够的缓冲区空间,那么即使发送方发生超时重传,重传的数据仍然可能再次被接收方丢弃,从而反复触发超时重传。而超时重传采用的是指数退避(Exponential Backoff)策略,比如间隔 1s, 2s, 4s, 8s, 16s... ,即每次重传的等待时间都会成倍增长,这将显著降低传输效率。
正因为如此,通信双方在发送 TCP 报文时,都会携带完整的 TCP 报头,其中就包括窗口字段。该字段用于向对方通告:当前我方接收缓冲区中仍然可用的空间大小。发送方在发送数据时,必须保证其"在途数据"的总字节数不超过该窗口值。
在发送端,发送缓冲区会维护三个关键的指针(严格来说是三个与序列号相关的边界),这些值存储在 TCP 专有的控制结构体 tcp_sock 中,用于精确描述当前发送窗口的状态:
- 已发送但尚未收到确认的最小序列号
- 下一次即将发送的数据的起始序列号
- 当前窗口所允许发送的最大序列号边界
cpp
struct tcp_sock {
u32 snd_una; // 已发送但未确认的最小序列号
u32 snd_nxt; // 下一次发送的序列号
u32 snd_wnd; // 发送窗口大小(由对方通告)
// ...
};由此,滑动窗口实际上就是维护这样一个动态变化的区间:左边界为 snd_una,表示"已发送但尚未确认"的最小序列号;右边界由 snd_una + snd_wnd 决定,表示当前允许发送的最大序列号范围。这样,整个发送缓冲区可以被逻辑地划分为三部分:
- 已发送且已确认的数据
- 已发送但尚未确认的数据
- 尚未发送、但允许发送的数据
在引入滑动窗口之后,接下来就需要进一步分析发送方的实际发送逻辑 ,而在这一过程中,就不可避免地要引入 Nagle 算法
Nagle算法
根据上文,我们已经认识了滑动窗口机制 。发送方在任意时刻能够发送的数据量是有上限的,其发送范围只能位于当前发送窗口之内,也就是不超过窗口右边界之前的数据。但这种机制会自然引出一个问题。
我们知道,在 Linux 内核中,tcp_sock 结构体会维护若干关键的序列号状态,其中包括:下一次要发送的序列号 ,以及发送窗口大小 。需要澄清的一点是:tcp_sock 并不会直接维护"允许发送的最大序列号"这个值 ,而是维护发送窗口大小(snd_wnd)。
因此,所谓"允许发送的最大序列号",实际上是通过计算得到的:
已发送但尚未确认的最小序列号(窗口左边界) + 当前窗口大小 = 窗口右边界。
如果此时下一次发送的序列号小于窗口右边界,那么按照滑动窗口的基本逻辑,只要该序列号尚未与右边界重合,就允许继续发送数据。
但问题也正是从这里开始的。
假设应用层每次调用 write 或 send 时,只写入几个字节的数据 。那么此时,下一次发送的序列号与窗口右边界之间的可用空间可能只有几个字节。按照最朴素的滑动窗口逻辑,只要不超过右边界,这几个字节依然会被立刻封装成 TCP 报文并发送出去。
这就会直接导致一个结果:网络中会出现大量的小包(tiny packet)。
需要注意的是,一旦系统普遍采用这种行为,网络中并不只是某一台主机在发送小包,而是成千上万台 TCP 主机同时向网络注入小包。如果每一台主机的 TCP 实现都遵循这种"只要窗口允许就立即发送"的策略,那么整个网络将充斥着大量的极小 TCP 报文。
而结合上文我们对路由器数据包处理流程 的分析,可以知道:
无论数据包是大是小,路由器在处理时,都需要消耗环形缓冲区中的一个硬件描述符 。对于网卡而言,小包在接收时,往往会被 DMA 拷贝到对应的接收缓冲区分片中,而每一个分片只能对应一个数据帧。
其直接后果就是:
环形缓冲区会因为描述符被快速耗尽 而迅速写满,进而导致新到达的数据包被丢弃,最终触发大量的超时重传 。因此,从网络整体角度来看,小包传输是极其忌讳的行为。
很多初学者会认为:TCP 是字节流协议,因此发送 1 个字节和发送 1460 个字节在语义上没有区别。
但如果从路由器环形缓冲区的角度来看,这两者的破坏力完全不同。
每一个到达路由器的 TCP 帧,无论其有效载荷多小,都会通过 DMA 占用一个宝贵的硬件描述符。如果全世界的 TCP 主机都频繁发送小包,路由器的 CPU 将陷入无穷无尽的协议头解析、转发表查找和中断处理之中,而其环形缓冲区也会因为"槽位耗尽"而在极短时间内陷入瘫痪。
正因为如此,TCP 在保证可靠性的同时,也必须兼顾整体效率 。协议设计者显然意识到这样一个问题:
应用层可能一次只写入几个字节,而 TCP 又是面向字节流的协议,它并不像 UDP 那样,每次发送的数据报都天然对应一次应用层写操作。
因此,TCP 并不会在应用层每写入几个字节时就立即发送,而是引入了一种**攒包(packet coalescing)**的思想:
先等待应用层继续写入数据,尽量凑够一个 MSS 大小的数据段,再一次性发送,而不是分多次发送小包。
这样做的好处是显而易见的:
对于接收方而言,可以一次性处理更多有效数据;
对于网络而言,可以显著减少包的数量;
而这正是 Nagle 算法 的核心思想。
接下来,我们聚焦 Nagle 算法在滑动窗口机制下的发送逻辑。
对于发送方而言,如果当前没有在途数据------也就是不存在"已发送但尚未确认的报文"------内核会检查发送缓冲区。如果发送缓冲区不为空,且当前窗口大小大于 0,那么内核会允许立即发送数据。
即使此时窗口中只剩下几个字节,这些数据仍然会被立刻发送出去,形成一个小包。需要注意的是,虽然前文强调了小包对网络的不利影响,但 Nagle 算法为了避免发送延迟,只允许在这种"无在途数据"的情况下发送一个小包,作为启动阶段的代价。
而如果当前存在在途数据,也就是已经有报文发送出去但尚未收到确认,那么内核的行为就会发生变化。
此时,内核会检查发送缓冲区是否仍然存在待发送的数据,并进一步检查窗口情况。
如果下一次发送序列号到窗口右边界之间的可用数据量已经达到或超过 MSS,那么内核会直接按照 MSS 对数据进行分段并发送,同时更新下一次发送的序列号。
但如果当前待发送的数据量小于 MSS ,那么内核就会进入典型的攒包逻辑 :
继续等待应用层写入数据,直到累计的数据量达到 MSS,然后再一次性发送出去。
还有一种特殊但非常关键的情况需要注意:
如果此时窗口本身的可用空间小于 MSS ,也就是下一次发送的序列号与窗口右边界之间的距离不足 MSS,那么即使应用层继续写入数据,使得发送缓冲区中的待发送数据量超过 MSS,窗口限制的优先级依然高于 Nagle 算法。
在这种情况下,只要窗口仍未向前推进,这部分小于 MSS 的窗口空间内的数据是无法被发送的。
唯一的例外是:当发送方收到了所有在途数据的确认报文,使得当前不再存在在途数据时,内核会立即将窗口内剩余的数据全部发送出去------即使这些数据只有几个字节。
这是因为此时接收方已经处理完之前发送的所有数据,发送方不能让接收方因为等待数据而陷入空转,因此必须立即发出剩余的数据。
那么认识了 Nagle 算法之后,根据上文可知,滑动窗口的约束优先于 Nagle 算法的发送策略。也就是说,即使发送缓冲区中的待发送数据已经超过 MSS,只要当前通告窗口(rwnd)小于 MSS,即右边界与下一个待发送字节序列号之间的可用窗口空间小于 MSS,在仍存在未确认数据的前提下,发送方通常不会继续发送新的报文段;除非当前不存在在途数据(即满足 Nagle 算法"无未确认数据"的条件),否则依然受窗口大小的限制。
那么这里发送方收到接收方返回的数据报文时,这些报文都会携带完整的 TCP 首部,其中包含窗口字段。发送方会根据该字段更新对端通告的窗口大小。此时需要特别注意窗口边界的移动规则:左边界(已确认序列号)只能向右移动,而右边界(L + W)则可能向右移动,也可能向左移动,这取决于确认号的推进幅度以及窗口大小的变化。
根据上文分析,发送方发送连续报文后,接收方若连续收到这些报文,首先由网卡将物理信号转换为二进制数据流并存储到硬件缓冲区;随后 DMA 将数据帧从网卡缓存区拷贝到内存中的环形缓冲区(对应某个描述符所指向的分片);接着触发硬件中断,CPU 进入内核态处理。内核读取当前读指针及其后的连续分片,构建 sk_buff 结构体,将属于同一连接(通过四元组定位)且序列号连续的分片的应用层那个数据挂载到 sk_buff的分片数组 中。随后根据序列号判断是放入有序队列还是乱序队列。处理完成后,接收方向发送方发送确认报文。
需要注意的是,如果应用层迟迟不调用 read 或 recv 接口读取数据,或者每次仅读取少量字节,那么问题就会出现。由于 sk_buff 在接收路径上通常采用零拷贝或引用分片数据的方式(即引用页片段而非立即复制数据),只要应用层未将分片中的应用层数据全部读取并释放,该分片就会一直被内核占用,无法归还给网卡驱动进行复用。
此时,如果接收方又收到新一批数据报文,而之前的数据仍未被应用层读取,对应分片尚未释放,那么新的数据帧只能占用新的分片,从而导致环形缓冲区的可用空间减少。因此,接收方在后续确认报文中通告的窗口大小就会小于上一次通告的值------这体现为接收窗口的收缩。
当发送方收到接收方返回的确认报文时,尤其是在收到冗余 ACK(duplicate ACK)时,情况会更加复杂。所谓冗余 ACK,简单来说,是指接收方收到了乱序到达的报文段,这些报文只能暂存于乱序队列。由于 TCP 语义要求应用层只能读取按序重组后的字节流,因此应用层只能读取有序队列中的数据,无法读取乱序队列中的数据。
一旦某些分片被挂载到乱序队列中,不仅这些分片无法被网卡回收复用,而且应用层也无法立即读取这些数据。此时接收方发送的冗余 ACK 其确认号与之前相同,即确认号未推进,也就意味着左边界(L)保持不变。
在这种场景下,如果窗口大小还在减小,那么右边界就可能向左移动。
假设数据按序到达,但最后一个或多个报文段丢失。接收方正常接收到了前面按序到达的报文,并将其放入有序队列,但应用层始终不读取数据。接收方仍然会发送确认报文,确认号正常前进,但由于缓冲区未释放,窗口持续缩小。发送方收到确认报文后,左边界向右移动;但由于仍然存在在途数据,左边界不会立即与右边界重合。
在某些情况下,如果窗口缩小的幅度超过确认号前进的幅度,那么右边界确实可能向左移动,甚至小于"下一个待发送字节的序列号"。这就是窗口收缩(window shrinking)现象。
设:
L为左边界
W为通告的窗口大小
R=L+W
按照上文刚才讲的场景:
收到部分确认 : 左边界推进 Δ L ( Δ L > 0 。 ) 。 收到部分确认:左边界推进 \Delta L(\Delta L > 0。) 。 收到部分确认:左边界推进ΔL(ΔL>0。)。
窗口缩减:由于应用层不读,缓冲区剩余空间变小, W n e w < W o l d ,即 Δ W < 0 。 窗口缩减:由于应用层不读,缓冲区剩余空间变小,W_{new} < W_{old},即 \Delta W < 0。 窗口缩减:由于应用层不读,缓冲区剩余空间变小,Wnew<Wold,即ΔW<0。
右边界是否向向右移,取决于: Δ L + Δ W 是否大于 0 。 右边界是否向向右移,取决于:\Delta L + \Delta W 是否大于0。 右边界是否向向右移,取决于:ΔL+ΔW是否大于0。
因为 L + Δ L + W n e w > L + W o l d 因为L+\Delta L + W_{new} >L+W_{old} 因为L+ΔL+Wnew>L+Wold
Δ L + W n e w > W o l d \Delta L + W_{new} >W_{old} ΔL+Wnew>Wold
Δ L + W n e w − W o l d > 0 \Delta L + W_{new} -W_{old}>0 ΔL+Wnew−Wold>0
Δ L + Δ W > 0 \Delta L +\Delta W >0 ΔL+ΔW>0
如果 ∣ Δ W ∣ > ∣ Δ L ∣ (即窗口缩小的程度超过了确认号前进的幅度),那么: R n e w < R o l d 如果 |\Delta W| > |\Delta L|(即窗口缩小的程度超过了确认号前进的幅度),那么:R_{new} < R_{old} 如果∣ΔW∣>∣ΔL∣(即窗口缩小的程度超过了确认号前进的幅度),那么:Rnew<Rold
这种情况在理论上是可能发生的,但在实际系统中相对较少见。通常应用层不会长期不读取数据;同时,操作系统内核也会进行调节。例如,当可用接收缓冲区接近耗尽时,内核可能直接通告零窗口(Zero Window),通过显式流控机制迫使发送方暂停发送,从而缓解接收缓冲区压力。
零窗口
接下来便要来认识零窗口。所谓零窗口,是指发送窗口的左边界与右边界重合,此时发送窗口大小为 0。这里的关键在于理解零窗口是如何被触发的。
那么,当发送方已经发送完当前发送窗口内的所有待发送数据,并且成功收到了对方的确认报文,使得窗口内的所有数据都被确认;同时,接收方在该确认报文中将通告窗口(rwnd)更新为 0。此时,发送窗口的左边界会向右滑动,与右边界重合。即便发送方的发送缓冲区中仍然存在尚未发送的数据,由于接收方通告窗口为 0,发送方也无法再发送任何字节的数据,此时即进入零窗口状态。
如果情况再特殊一些:对方发送的并非纯 ACK 报文,而是捎带确认(即在携带应用层数据的同时对已接收数据进行确认)。发送方收到该捎带确认后,不仅确认了窗口内的全部数据,同时也将发送窗口更新为 0,导致左边界与右边界重合。这一点与前述情况一致。
但特殊之处在于:由于该报文携带了应用层数据,发送方在接收数据后必须向对方回复 ACK。然而,此时发送窗口为 0,发送方无法再捎带数据进行确认,因此只能等待延迟确认定时器到期(后文会讲到),随后发送一个纯 ACK 报文。
此时,如果接收方收到该纯 ACK 报文后,其发送的数据也恰好被全部确认,并且在 ACK 中同样将窗口大小更新为 0,那么接收方的发送窗口左、右边界也会重合。结果是双方的发送窗口都为 0,双方都无法再发送数据。此时,双方都在等待对方发送报文以更新窗口大小,从逻辑上看便陷入了一种"死锁"状态。
虽然这种"死锁"的触发条件较为苛刻,属于小概率事件,但并不意味着不会发生。TCP 的设计并不会忽略这种情况,而是提供了专门的机制进行处理,即窗口探测(Zero Window Probe)。
当一方进入零窗口状态后,会周期性地主动发送窗口探测报文。该报文通常携带 1 字节的有效载荷,其目的并非真正传输数据,而是强制对方返回 ACK。对方在 ACK 报文的 TCP 首部中会重新通告当前的窗口大小,发送方据此更新自己的发送窗口。
如果发送窗口探测报文后对方未响应,发送方会设置重传定时器,定期再次发送窗口探测报文。该过程类似于超时重传机制,并采用指数退避策略。探测报文通常存在最大重试次数(实现相关,常见为约 15 次)。如果在多次探测后仍未收到任何响应,通常可以认为对端异常或连接已经失效,发送方将主动关闭连接。
延迟确认
根据上文,在认识了Nagle 算法以及滑动窗口机制之后,接下来我们将视角转向接收方。接收方在收到对端发送的数据报文段后,必然需要回复确认报文。如果每接收一个报文段就立即发送一个纯ACK 报文,而发送方又基于滑动窗口机制连续发送多个数据报文段,那么按照这种逻辑,网络中将出现大量仅携带 ACK 的小报文。
根据前文分析,网络对"小包"是较为敏感的。这是因为无论报文大小如何,每个报文在路由器中都会占用缓存资源,并经历完整的协议栈处理流程(包括查表转发等固定开销)。极端情况下甚至可能导致路由器缓冲区耗尽,从而加剧网络拥塞。因此,从效率角度出发,接收方更倾向于采用"捎带确认"(piggybacking)的方式。
所谓捎带确认,是指在发送应用层数据时,将ACK 信息附加在数据报文中一并发送。这样既能向对端提供确认信息,又能承载应用层数据,提高链路利用率。需要注意的是,既然发送的是应用层数据,那么该发送行为仍然必须受到滑动窗口以及Nagle 算法的约束,确认报文的"捎带"并不意味着可以绕开这些发送规则。
当接收方收到对端发送的数据报文段时,第一步通常是检查自身发送缓冲区是否存在待发送的应用层数据。如果发送缓冲区不为空,则需要遵守滑动窗口和 Nagle 算法的发送约定:
- 如果当前不存在在途数据,或者窗口中的待发送数据量大于等于
MSS,则可以直接发送数据报文,并在其中捎带 ACK; - 如果存在在途数据,且窗口中的待发送数据量小于
MSS,则根据 Nagle 算法,需要暂缓发送,等待数据累计到 MSS 或收到对端 ACK 后再发送。
接收方虽然倾向于捎带确认,但并不意味着一定要发送捎带 ACK。如果此时发送缓冲区为空(即没有应用层数据),或者窗口中的待发送数据量小于 MSS,则通常会启动一个延迟确认定时器 (Delayed ACK Timer),其等待时间一般为200ms 左右。接收方会在该时间窗口内等待应用层调用 write 或 send 接口写入数据,以便进行捎带确认。
在延迟期间:
- 如果有
在途数据,且窗口中的待发送数据累积到 MSS,则立即发送携带数据的报文,并捎带 ACK; - 如果
发送缓冲区为空,且在超时之前应用层写入了数据,即使不足 MSS,也可能根据实现策略立即发送数据并捎带 ACK; - 如果在定时期间又收到了发送方发送的第二个数据报文段(即连续两个报文段),即便其中包含重复报文,也通常会立即发送一个纯 ACK 报文,而不再继续延迟。
这里需要特别说明,接收方之所以不能无限期等待应用层写入数据,是因为确认报文的延迟会直接影响发送方的行为。如果接收方迟迟不发送 ACK,发送方可能会误判为丢包,从而触发超时重传。此外,根据前文分析,发送方发送的数据在未收到确认之前,其对应的内存缓冲区资源(例如sk_buff 及其关联的数据页)无法释放,也无法被网卡复用。如果发送方的应用层持续写入数据,而确认迟迟不到达,发送缓冲区可能被逐步填满,进而限制发送能力。因此,延迟确认必须设置上限定时器,以避免协议层面的资源阻塞。
此外,在延迟确认期间,如果接收方收到了连续两个数据报文段就立即发送纯 ACK,是为了避免潜在的"窗口停滞"现象。因为发送方每发送一个数据报文段,其下一个待发送字节的序列号都会向右移动,逐渐逼近发送窗口的右边界。一旦达到右边界,在未收到新的 ACK 之前,发送方将无法继续发送数据。如果此时接收方仍在延迟确认(例如发送缓冲区为空或待发送数据不足 MSS),双方可能会进入一个最长约 200ms 的"沉默期"。为降低这种风险,协议通常规定:当接收方收到两个连续的数据报文段时,应立即发送 ACK。
不过,这种"停滞"现象并不能被完全避免。例如,当发送方的发送窗口剩余空间恰好等于一个 MSS,发送完该报文段后,其下一个待发送字节的序列号立即与右边界重合,此时发送方必须等待 ACK 才能继续发送。如果此刻接收方也在执行延迟确认策略(例如发送缓冲区为空或待发送数据不足 MSS),且应用层未及时写入数据,那么仍可能出现短暂的停顿。
这种停顿不会无限持续,因为延迟确认定时器最终会触发 ACK 的发送,但在这段时间内,链路带宽得不到充分利用,整体吞吐率会受到一定影响。从协议设计角度看,这是在"减少小包开销"与"降低交互时延"之间做出的折中。
快速重传
那么根据上文,我们已经认识了滑动窗口以及Nagle 算法,接下来便是快速重传机制。我们知道,主机按照发送顺序发出的数据报,并不一定按照顺序到达目标主机,可能会出现乱序到达的情况,即后发送的数据报先到达目标主机。
对于接收方而言,当其收到乱序到达的数据报时,会将其放置到乱序队列(out-of-order queue)中进行缓存。接收方在收到乱序数据报之后,会立即发送一个 ACK 报文。这个 ACK 报文属于"冗余ACK冗余 (Duplicate ACK)"。之所以称之为冗余,是因为该 ACK 报文中的确认号与之前发送的确认报文的确认号相同,即确认号没有更新,无法推动发送窗口的左边界向右移动。
此外,在支持 SACK(Selective Acknowledgment)的情况下,也就是通信双方在 TCP 连接建立时协商并启用了 SACK(Selective Acknowledgment,选择性确认)选项, 冗余ACK 的 TCP 头部选项字段中会携带 SACK 信息,用于标明已成功接收的乱序数据块的序列号范围。通过该字段,接收方可以明确告知发送方:哪些数据段已经成功接收,哪些数据段仍然缺失。
发送方第一次收到这样的 ACK 时,会发现确认号没有前移,从而识别出这是一个冗余 ACK。但此时发送方不会立即根据 SACK 选项中携带的信息计算出缺失的序列号范围并立刻重传。原因在于:网络中可能只是发生了乱序,后发送的数据报提前到达,而中间的数据报仍在传输路径上尚未到达。因此,发送方会继续等待后续的反馈,而不会仅凭一次 冗余ACK 就判断发生了 丢包 。
如果接收方连续收到多个乱序到达的报文,并持续将其放入 乱序队列 ,那么每收到一个新的乱序报文,都会立即发送一个 冗余ACK 。最新发送的 冗余ACK 仍然携带当前期望收到的下一个连续字节的序列号作为确认号,同时在 SACK选项中更新已接收的乱序数据块范围。
需要注意的是,冗余 ACK 本身在网络中也可能出现乱序到达发送方的情况。但发送方在识别到冗余 ACK 后,会统计具有相同确认号的冗余 ACK 数量。与此同时,若启用了 SACK ,发送方还会记录 SACK 选项中反馈的已接收数据块信息。此时,发送窗口左边界(即已发送但尚未被累计确认的最小序列号)与接收方反馈的最小乱序数据块起始序列号之间的区间,通常就是可能丢失的数据范围。
当发送方连续收到三个具有相同确认号的 冗余ACK 时,便会触发 快速重传 (Fast Retransmit)机制。此时发送方可以较为确信:某个序列号范围内的数据段已经丢失,于是立即重传对应的数据段,而无需等待重传定时器超时。
那么,读者可能会产生几个疑问。
第一个疑问:为什么是"三个"冗余 ACK 才触发快速重传,而不是两个?
原因在于,两个冗余 ACK 并不足以让发送方确认一定发生了丢包。数据报在网络中乱序是较为常见的现象,可能只是因为路径上的排队或转发延迟不同导致到达顺序发生变化。如果仅凭两个冗余 ACK 就触发重传,很容易导致大量不必要的重传,从而进一步加剧网络拥塞。而当连续收到三个冗余 ACK 时,从统计意义上看,发生丢包的概率显著增加。即便最终并未真正丢包,最多也只是发送了一个重复的数据段,接收方会根据序列号将其丢弃,对系统影响相对可控。
第二个疑问:为什么需要快速重传?直接依赖超时重传不可以吗?
这正是快速重传机制存在的意义。若完全依赖超时重传,发送方必须等待重传定时器到期后才能重传丢失的数据段,这将显著增加恢复延迟。而在支持 SACK 的情况下,发送方可以根据冗余 ACK 中携带的 SACK 信息,精确定位已经收到的数据块范围,仅针对缺失的序列号区间进行重传。相比之下,超时重传往往只能基于累计确认进行判断,可能导致对已经成功接收的数据进行重复重传,效率较低。
第三个疑问:如果冗余 ACK 本身丢失了怎么办?例如发送方需要收到三个冗余 ACK 才能触发快速重传,但其中一个 ACK 在网络中丢失了。
在这种情况下,确实可能无法及时触发快速重传,因为冗余 ACK 的计数不足以达到阈值。不过,TCP 仍然有超时重传机制作为兜底。一旦重传定时器到期,发送方仍会重传未被确认的数据段。因此,快速重传是一种优化机制,用于在大多数情况下更快地恢复丢包;而超时重传则作为最终保障机制,确保可靠性。代价是,在未能触发快速重传的场景下,恢复延迟会增加,且可能产生一定数量的重复报文。
PSH以及URG标志位
接下来的内容讨论 TCP 报头中的相关标志位。首先介绍的是 PSH 标志位。
我们知道,发送方会在滑动窗口允许的范围内连续发送多个数据报文段给接收方。接收方的网卡收到数据后,首先将物理信号转换为二进制比特流并暂存于网卡缓冲区,随后通过 DMA 将数据拷贝到内存中。之后触发硬中断,CPU 切换至内核态,读取接收队列的读指针,将对应的数据片段挂载到 sk_buff 结构体,并根据报文中的四元组在哈希表中定位对应的 sock 结构体。接着依据 TCP 序列号判断该报文段应插入到接收端的有序队列(已按序到达)还是乱序队列(失序到达)。
对于接收方而言,只要接收缓冲区不为空------哪怕仅有少量字节------内核理论上就可以唤醒因调用 read 或 recv 而阻塞的进程。但需要注意的是,频繁唤醒进程会带来明显的上下文切换开销。例如,内核需要将进程状态设置为就绪态,插入就绪队列;当调度器选择该进程运行时,还需恢复其内核栈中保存的寄存器上下文,将相关寄存器值重新加载到 CPU 中。若每次仅为极少量数据就触发唤醒,将显著增加系统开销。
为减少这种因"小包"导致的频繁调度,套接字可以通过 setsockopt 设置接收低水位线(SO_RCVLOWAT),示例如下:
cpp
int lowat = 1024; // 设置水位线为 1024 字节
setsockopt(sockfd, SOL_SOCKET, SO_RCVLOWAT, &lowat, sizeof(lowat));当接收缓冲区中的数据量低于该水位线时,内核不会唤醒阻塞在 read 或 recv 上的进程,而是继续积累数据,待数据量达到或超过水位线后再统一唤醒进程,由应用层一次性处理,从而减少上下文切换次数。这种机制本质上是一种"攒包"策略,用于在实时性与系统开销之间取得平衡。
然而,这里存在一个潜在问题:假设发送方发送完当前发送缓冲区中的最后一个报文段,此时发送缓冲区为空,且应用层暂时不再调用 write 或 send 写入新的数据。接收方收到该最后一个报文段后,将其放入有序队列,但接收缓冲区中的数据总量仍低于水位线。在这种情况下,如果没有额外机制介入,内核不会唤醒应用进程,而发送方也不会再发送数据,那么接收进程可能会长期阻塞在 read 上,造成"尾部数据滞留"的问题。
此时,PSH 标志位便发挥作用。
PSH 标志位通常由 TCP 协议栈根据发送缓冲区的状态自动设置,无需应用程序手动干预。当发送方发送当前发送缓冲区中的最后一个报文段时,TCP 可能会在该报文段的首部中将 PSH 位置为 1。接收方在将带有 PSH 标志位的报文段按序插入有序队列后,一旦内核检测到有序队列中存在带 PSH 标志的数据,便会绕过接收低水位线的限制,将数据及时递交给应用层,而不再等待缓冲区达到水位线。
需要强调的是,PSH 的语义并不是"必须立即交付",而是提示接收端"发送方希望尽快将数据推送给应用层"。具体实现上,内核通常会在保证数据按序可读的前提下,加快交付节奏。
PSH 的影响是针对当前这批数据的交付行为 。当带有 PSH 标志位的报文段按序进入接收队列时,内核会在满足顺序性的前提下尽快将这部分数据标记为可读,从而唤醒阻塞的应用进程,即使当前接收缓冲区的数据量尚未达到 SO_RCVLOWAT 所设定的水位线。
一旦应用层通过 read 或 recv 将包含 PSH 标志位的这部分数据读取完毕,如果此时接收缓冲区中剩余的数据量再次低于水位线,并且没有新的 PSH 标志报文到达,那么套接字后续的可读性判断将重新回到常规的水位线机制。
之所以在"当前发送缓冲区的最后一个报文段"上设置 PSH,是因为发送方无法准确预知应用层是否还会继续调用 write 或 send 写入新的数据。因此,当发送缓冲区暂时被清空时,将该报文段标记为 PSH,可以避免上述"尾部数据滞留"问题。即便之后应用层再次写入数据,也仅需在新的最后一个报文段上再次设置 PSH 即可,并不会产生副作用。
进一步考虑一种较为极端的情况:发送方未禁用 Nagle 算法,而接收方又设置了较高的接收低水位线。在这种场景下:
- 发送方因 Nagle 算法的限制(存在未确认的在途数据,且待发送数据小于 MSS)而延迟发送,进行"攒包";
- 接收方即便收到数据,也因未达到低水位线而不唤醒应用进程。
这两种机制叠加,可能显著增加数据从发送到被应用层处理的时延。可以理解为多种延迟策略的"叠加效应"。
在这种情况下,PSH 标志位相当于一种兜底机制:当发送方阶段性地发送完当前缓冲区数据时,通过设置 PSH,提示接收端尽快交付数据,从而避免数据长期滞留于内核缓冲区,缓解由 Nagle 算法与接收低水位线共同作用带来的延迟问题。
综上,PSH 标志位的核心作用并非改变 TCP 的可靠性或顺序性语义,而是在特定场景下优化数据从内核到应用层的交付时机,避免尾部数据被长期滞留,提高交互类应用的响应性。
接下来便是 URG 标志位 。当 TCP 报头设置了 URG 标志位时,表示该报文段中包含紧急数据(urgent data)。需要注意的是,这里的"紧急数据"通常被视为一字节的带外数据(Out-Of-Band Data)。这一字节在语义上独立于正常的应用层字节流,也就是说,它不属于常规应用层数据流的一部分。
因此,当接收方收到携带 URG 标志位的报文段时,内核会将该紧急数据与普通数据区分处理,应用层在常规 read/recv 调用中默认不会读取这一字节的数据。
那么首先的问题是:这一字节的紧急数据是如何发送的?
既然其是"紧急"的,就意味着接收方应尽快感知它的存在。然而 TCP 本质上是一个严格有序的字节流协议 ,每一个字节都拥有确定的序列号,因此紧急数据不可能"插队"------也就是说,它不能被随意插入到发送缓冲区(例如双向链表的第一个 sk_buff 节点所挂载的分片数据)中。
由于字节流的顺序在逻辑上已经确定,如果应用层发送一个紧急数据,而内核直接将其插入到当前待发送分片的前部,那么就会破坏序列号的连续性。
例如,假设当前第一个分片的序列号范围为 1000~2000(包含 1000,不包含 2000)。若强行插入 1 字节紧急数据,则该分片的有效载荷长度将增加 1 字节,其序列号范围将变为 1000~2001。但此时,后续分片的起始序列号已经确定,内核不可能整体调整后续所有分片的序列号,否则会破坏 TCP 已建立的发送序列结构。
再看确认过程:
当该分片发送出去后,接收方若按序收到,会将其放入有序队列,并返回确认报文。确认号等于"当前期望收到的下一个字节序列号"。假设当前期望序列号为 1000,若收到长度为 1001 字节的数据,则确认号应为 2001。
但若插入了 1 字节并导致长度变为 1002,则确认号变为 2002。意味着返回的确认号就是 2002。此时发送方收到该确认报文后,会检查发送缓冲区,并认为 2002 之前的所有字节均已被成功确认。
然而,按照原本的发送序列设计,理论上只应确认到 2001。如果确认号异常推进到 2002,就会导致发送方误认为序列号为 2001 的那个字节已经被对端正确接收,从而将其从发送缓冲区移除。这样一来,原本应当发送或尚未真正被正确确认的字节可能被错误丢弃。
更严重的是,这还可能导致发送窗口的右边界异常前移,甚至超过当前实际应发送的下一个字节序列号,从而破坏发送端的窗口一致性与字节流语义。
正因为 TCP 必须严格维护字节流的顺序与确认号的单调一致性,所以紧急数据绝不能以"插入"的方式改变既有字节序列结构。
通过上述例子可以看出:即使是紧急数据,也必须严格遵守 TCP 字节流的顺序语义。
因此,在实现上,紧急数据并不会真正"插队"。它仍然位于正常字节流中,只不过发送方在对应报文段中设置:
URG标志位紧急指针(Urgent Pointer)
紧急指针表示:从当前报文段序列号开始,偏移多少字节处是紧急数据的结束位置。
通常实现中,紧急数据会追加在当前发送缓冲区的尾部,即最后一个 sk_buff 所挂载分片的末尾。应用层随后调用 write 或 send 写入的数据,会继续顺序追加在其之后。也就是说,紧急数据在物理上仍然属于普通字节流的一部分。
当携带紧急数据的报文段发送时,内核会:
- 设置
URG标志位为 1 - 填充紧急指针字段
在发送策略上,紧急数据通常具有一定"优先权"。例如,在某些实现中,即便当前存在未确认数据,且未达到 MSS,内核也可能优先发送该报文段,而不再等待攒包逻辑(例如 Nagle 算法),以降低紧急通知的延迟。
接收方处理流程如下:
- 收到报文段后检查 URG 标志位;
- 若 URG=1,则根据紧急指针定位紧急数据;
- 内核将该字节从正常数据流逻辑中分离;
- 通过信号机制通知应用进程(通常为
SIGURG); - 应用进程通过
recv(..., MSG_OOB)主动读取该字节。
由于紧急数据在语义上不属于普通数据流的一部分,因此应用层在常规 read/recv 调用中读取数据时,会跳过该字节。这也是其被称为"带外数据(Out-Of-Band Data)"的原因。
读者可能会问:如何在应用层发送紧急数据?
这需要在 send 接口中使用 MSG_OOB 选项:
cpp
const char *urgent_data = "!";
// 关键点:MSG_OOB 告诉内核,这 1 字节需要触发 URG 标志位和紧急指针
send(sockfd, urgent_data, 1, MSG_OOB);而在接收方,为了能够接收到紧急通知,需要:
- 设置 socket 所属进程(用于接收 SIGURG 信号)
- 注册信号处理函数
- 在信号处理函数中使用
MSG_OOB读取数据
cpp
// 告诉内核,如果这个 socket 有紧急数据,把信号发给当前进程(PID)
fcntl(sockfd, F_SETOWN, getpid());
void urgent_handler(int sig) {
char oob_byte;
// 使用 MSG_OOB 标志读取那 1 字节紧急数据
int n = recv(sockfd, &oob_byte, 1, MSG_OOB);
if (n > 0) {
printf("捕获到紧急数据: %c\n", oob_byte);
}
}
// 注册信号
signal(SIGURG, urgent_handler);需要注意的是,在现代系统中,带外数据的使用已经非常罕见。,大多数应用协议更倾向于在应用层自行设计控制消息,而非依赖 TCP 的 URG 机制。因此,在实际工程中,URG/带外数据机制基本属于了解性内容。
TCP三次握手
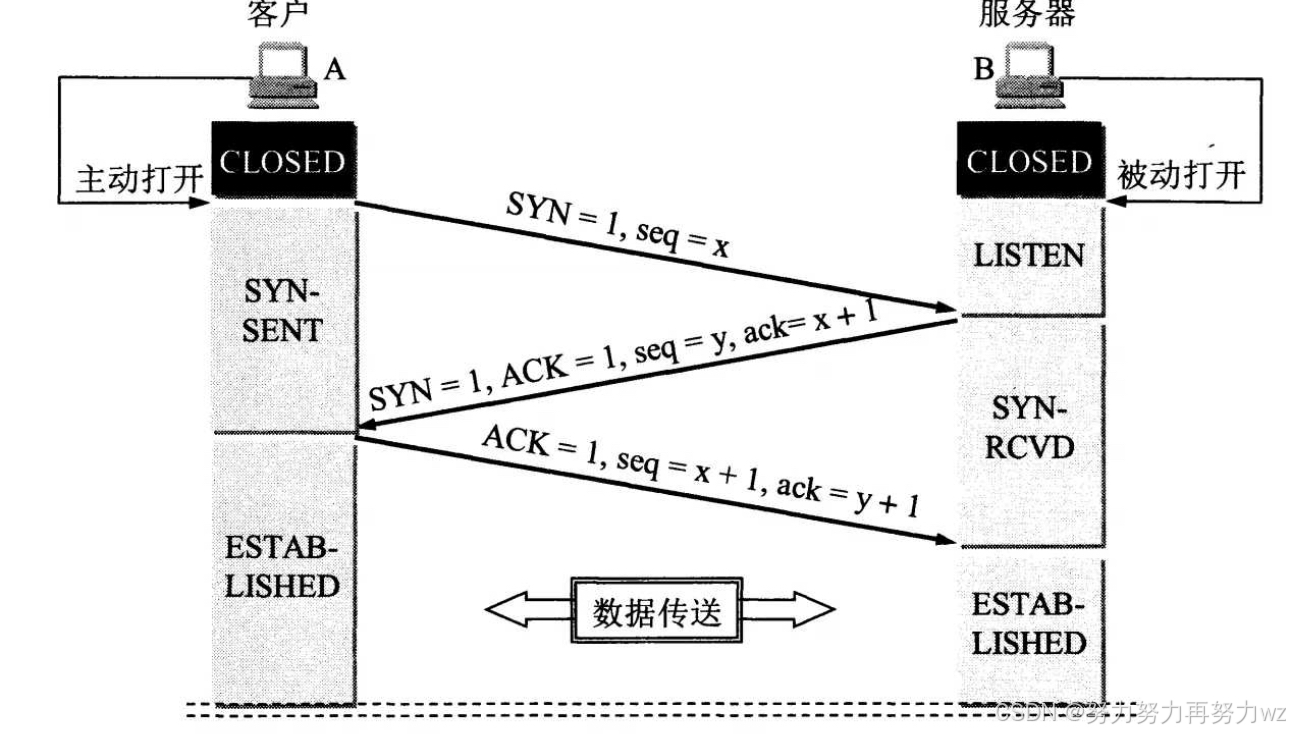
那么接下来讨论 TCP 的三次握手。TCP 协议与 UDP 协议的核心区别在于:TCP 在正式通信之前需要建立连接,即完成三次握手。三次握手的目的在于验证通信双方的收发能力,并协商 TCP 的相关参数(如初始序列号、窗口缩放、SACK等选项)。
在建立 TCP 连接时,通信双方分别扮演客户端与服务端的角色。通常由客户端主动向服务端发起连接请求。客户端首先向服务端发送一个 SYN 报文段,其中 TCP 首部的 SYN 标志位被置为 1。该报文不携带应用层数据,因为此阶段尚未进入正式通信阶段。需要注意的是,SYN 报文本身会消耗一个序列号,因此其序列号会被计入序列空间,这就是第一次握手。
当服务端收到客户端发送的 SYN 报文后,会回复一个 SYN-ACK 报文,即 TCP 首部中的 SYN 与 ACK 标志位均被置为 1。该报文的含义是:我已收到你的 SYN 报文,并同意建立连接,同时告知我的初始序列号。这是第二次握手。
客户端收到服务端的 SYN-ACK 报文后,会再发送一个 ACK 报文作为确认,此时第三次握手完成。
根据上述过程可知,三次握手的第一个目的在于验证双方的收发能力。具体而言:
- 客户端发送 SYN 报文,说明客户端的发送能力正常;
- 服务端收到 SYN 并返回 SYN-ACK,说明服务端的接收能力和发送能力正常;
- 客户端收到 SYN-ACK 后再发送 ACK,若该 ACK 被服务端成功接收,则服务端能够确认客户端的接收能力正常。
因此,必须通过三次握手而非两次握手,才能确保双方的收发能力均被完整验证。这是三次握手存在的第一个原因。
三次握手之所以是三次而不是两次,还有更深层的原因。要理解这一点,需要从内核实现层面分析其底层机制。
通信双方在通信之前都需要调用 socket 接口创建套接字。对于服务端而言,其调用 socket 接口创建的是普通套接字,随后通过 bind 和 listen 使其成为监听套接字。
在 TCP 设计中,建立连接与正式通信是两个不同阶段,因此服务端不会使用同一个套接字同时完成"连接建立"和"数据通信"两个职责。原因在于 TCP 连接是点对点、一对一的。一旦连接建立成功,该连接对应的套接字只能与唯一的对端进行通信。如果由同一个套接字既负责接收多个客户端的连接请求,又负责与某个客户端进行一对一通信,则在语义上将变成"一对多",这显然不符合 TCP 点对点通信的设计。
因此,在三次握手完成后,内核会创建一个新的"已连接套接字"(connected socket),专门用于与该客户端进行一对一通信;而原来的监听套接字只负责接收来自多个客户端的连接请求,即"建立连接阶段"是一对多,而"通信阶段"是一对一。
在内核实现中,监听套接字与已连接套接字在结构上具有相同的继承体系。其自上而下大致包括:
sock(基类)inet_sock(与网络层相关)inet_connection_sock(管理传输层连接状态)tcp_sock(TCP 特有结构)
虽然监听套接字和已连接套接字都具有这四层结构,但由于职责不同,它们使用的功能侧重点不同。
以监听套接字为例:
最上层的 sock 结构体本质上是一个通用容器,内部包含发送缓冲区和接收缓冲区,这些缓冲区本质上是以 sk_buff 为节点的链表,用于暂存应用层数据。然而在连接建立阶段(SYN、SYN-ACK、ACK),并不会承载应用层数据,因此监听套接字通常不会使用这些发送/接收缓冲区。
监听套接字主要使用的是 inet_connection_sock 中的半连接队列(SYN 队列)和全连接队列(accept 队列)。
当主机收到客户端发送的 SYN 报文时,处理流程大致如下:
- 网卡将物理信号转换为二进制数据帧,写入网卡接收缓冲区;
- 通过 DMA 将数据拷贝至内存;
- 触发硬件中断,CPU 切换至内核态;
- 内核构建
sk_buff结构体; - 提取 TCP 四元组(源 IP、源端口、目的 IP、目的端口)。
内核首先在已连接套接字哈希表中查找四元组,若未命中,则提取目的 IP 与目的端口(二元组),在监听套接字哈希表中查找对应的监听套接字,并检查其状态是否为 LISTEN。
若状态正确,则内核构建一个 request_sock 结构体,用于表示一个处于半连接状态的请求,其中记录:
- 对端初始序列号;
- 本端初始序列号;
- 期望接收的下一个序列号;
- 将要发送的 SYN-ACK 的序列号;
- 协商的 TCP 选项等。
cpp
struct request_sock {
// 链表指针
struct request_sock *dl_next; // 下一个节点
struct request_sock *dl_prev; // 上一个节点
// 指向已连接的sock(当三次握手完成后)
struct sock *sk;
// 引用计数
atomic_t rsk_refcnt;
// TCP特定字段
struct tcp_request_sock {
u32 snt_isn; // 发送初始序列号
u32 rcv_isn; // 接收初始序列号
u32 snt_synack; // 发送的SYN-ACK序列号
u32 rcv_nxt; // 期望接收的下一个序列号
// TCP选项
struct tcp_options_received tcp_opt;
// 时间戳
u32 snt_synack_stamp; // SYN-ACK发送时间
u32 rcv_tsecr; // 接收到的TSecr
};
// INET特定字段
struct inet_request_sock {
__be32 ir_rmt_addr; // 远程IP地址
__be32 ir_loc_addr; // 本地IP地址
__be16 ir_rmt_port; // 远程端口
__be16 ir_loc_port; // 本地端口
// TCP选项
u8 tstamp_ok; // 时间戳选项是否可用
u8 wscale_ok; // 窗口缩放选项是否可用
u8 sack_ok; // SACK选项是否可用
u8 ecn_ok; // ECN选项是否可用
u8 rcv_wscale; // 接收窗口缩放因子
u8 snd_wscale; // 发送窗口缩放因子
u32 ir_mark; // 标记值
u32 snd_wscale:4, // 发送窗口缩放因子
rcv_wscale:4; // 接收窗口缩放因子
};
};那么构建完成的 request_sock 结构体会被插入到半连接队列(SYN 队列)中。内核通常使用哈希表来组织半连接队列。
具体而言,内核会首先提取四元组,即源 IP、目的 IP、源端口和目的端口。该四元组唯一标识一条 TCP 连接。随后通常会结合一个随机扰动因子(例如基于随机种子的混合运算),减少哈希冲突的概率。接着将处理后的结果输入哈希函数,得到一个哈希值。
这里的哈希表本质上是一个指针数组(桶数组)。数组中的每一个元素都是一个指针,指向一个链表(或其他冲突解决结构)。由于哈希函数生成的哈希值通常是一个较大的整数,需要将其映射到数组下标范围内,因此会通过取模运算将哈希值映射到 [0, table_size - 1] 的区间,从而得到桶索引。
随后,内核会将新构建的 request_sock 结构体插入到对应桶的链表中,通常采用头插法以获得 O(1) 的插入复杂度。
在 request_sock 成功加入半连接队列之后,内核会自动构造并发送一个 SYN-ACK 报文给客户端,进入三次握手的第二阶段。
这里需要强调的是:虽然客户端与服务端都会调用 socket 接口,并且传入的参数可能完全相同,但此时创建出来的套接字本质上只是一个处于 CLOSE 状态的通用套接字结构,并未被赋予明确的语义,其职责尚未划分。
套接字"角色"的确定,是在后续调用不同接口之后完成的。
当客户端调用 connect 接口时,内核会主动发起三次握手流程,并将套接字状态从 CLOSE 修改为 SYN_SENT;在收到对端的 SYN-ACK 并完成第三次握手后,再将状态修改为 ESTABLISHED。此时该套接字成为一个已连接套接字,用于一对一的数据通信。
而当服务端调用 listen 接口时,内核会将套接字状态从 CLOSE 修改为 LISTEN,并初始化半连接队列与全连接队列。此时该套接字成为监听套接字,用于接收来自多个客户端的连接请求。
因此,内核并不是通过"创建方式"来区分套接字类型,而是通过 sock 结构体中的 sk_state 状态字段来区分。不同的状态决定了内核在协议栈中对该套接字采用不同的处理路径和访问逻辑。
换言之,socket 只是创建了一个通用的通信端点,而真正赋予其"监听"或"已连接"语义的是后续的 listen 或 connect 调用。内核正是通过状态机机制来完成套接字类型的区分与管理,从而能够正确地调度和访问对应的套接字。
而对于客户端而言,其创建的套接字只会主动与某一个服务端建立连接,并在连接建立成功后,与服务端对应的已连接套接字进行一对一通信。
客户端不存在"一对多"的连接建立场景。与之相对,服务端的监听套接字需要同时接收并处理来自多个客户端的连接请求,因此其在"建立连接阶段"是典型的一对多模型;而一旦三次握手完成,内核会为每一个客户端创建独立的已连接套接字,从而进入一对一通信阶段。
正因为客户端在整个生命周期内始终只面向单一对端(无论是连接建立阶段还是数据通信阶段,均为一对一关系),因此客户端可以复用同一个套接字来完成连接建立与后续通信。而服务端由于连接建立阶段是一对多的语义,必须通过监听套接字与已连接套接字的分离来实现职责划分。
客户端调用 connect 时,内核发送 SYN 报文,并将套接字状态从 CLOSE 修改为 SYN_SENT。当收到 SYN-ACK 后,内核将状态修改为 ESTABLISHED,并唤醒因 connect 阻塞的进程,进入正式通信阶段。
这里读者可能还会产生一个疑问:我们知道监听套接字与已连接套接字分别维护各自的哈希表。监听套接字的哈希表通常以目的 IP 地址和目的端口(二元组)为键;而已连接套接字的哈希表则以源 IP、源端口、目的 IP、目的端口(四元组)为键。
当客户端收到 SYN-ACK 报文后,会唤醒因调用 connect 而阻塞的进程,并进入通信阶段。同时客户端还需要发送第三次握手的 ACK 报文,以确认收到了对方的 SYN-ACK。这个 ACK 报文通常可能是纯 ACK,也可能是"捎带确认"(即 ACK + 应用层数据)。
那么,当服务端收到这个第三次握手报文时,该如何处理?
需要注意的是,第三次握手报文中通常不再携带 SYN 标志位。监听套接字此前已经为该客户端创建了对应的 request_sock,并将其插入半连接队列。因此,监听套接字必须在收到第三次握手报文后,才能确认连接建立完成。
内核的处理流程是固定的,并不会因为是否携带 SYN 标志位而改变整体查找逻辑:
- 首先提取四元组;
- 优先查找已连接套接字哈希表。
这样设计的原因在于,绝大多数网络流量来自已建立连接的正常通信报文,而非连接建立阶段。因此优先查找已连接套接字可以提高匹配效率。
- 若在已连接套接字哈希表中命中,则该报文被视为正常通信报文,直接交由对应的
tcp_sock处理。 - 若未命中,则内核会继续处理。
此时内核会提取目的 IP 与目的端口(二元组),查找监听套接字哈希表,并确认其状态为 LISTEN。若命中,则进一步使用四元组在半连接队列中查找对应的 request_sock。
如果在半连接队列中找到匹配的 request_sock,则说明这是合法的第三次握手报文,三次握手完成。此时内核会:
- 销毁对应的
request_sock; - 创建新的
tcp_sock(已连接套接字); - 将其插入已连接套接字哈希表(以四元组为键);
- 将其加入监听套接字的全连接队列尾部(该队列通常采用链表结构实现);
- 将其状态修改为
ESTABLISHED。
需要强调的是,第三次握手报文不一定是纯 ACK,也可能携带应用层数据。但这并不会影响内核的处理流程。因为无论报文类型如何(SYN、ACK、RST 等),内核都会先构建 sk_buff 结构体:将协议头拷贝到线性区,并将数据部分挂载到分片数组中。
当新的 tcp_sock 创建完成后,如果该 ACK 报文中携带了应用层数据,这些数据会被挂载到该已连接套接字的接收缓冲区中,等待后续由用户态通过 accept 返回的文件描述符进行读取。
关于四元组的继承关系:
全连接队列中的已连接套接字,其四元组中的:
- 目的 IP 与目的端口 ------ 继承自监听套接字绑定的本地地址与端口;
- 源 IP 与源端口 ------ 来自客户端。
虽然所有已连接套接字都继承相同的本地 IP 与端口,但由于客户端的源 IP 和源端口不同,因此四元组依然保持唯一性。这也是 TCP 能够在同一监听端口上同时服务多个客户端的根本原因。
当服务端进程调用 accept 接口时,内核会执行以下操作:
- 访问监听套接字的全连接队列;
- 取出队首的已连接套接字;
- 为该已连接套接字创建新的
socket结构体; - 在当前进程的文件描述符表中分配一个新的文件描述符;
- 创建对应的
file结构体,并将file->private_data关联到该socket; - 将文件操作表指向对应的 socket 操作函数表;
- 返回新的文件描述符给用户态。
cpp
客户端发送SYN
↓
服务端接收SYN
↓
创建request_sock
↓
放入半连接队列(哈希表)
↓
发送SYN-ACK
↓
等待客户端ACK
↓
收到ACK
↓
从半连接队列移除
↓
创建已连接套接字(完整4层结构)
↓
放入全连接队列(双向链表)
↓
应用层调用accept()从全连接队列获取连接至此,服务端获得了一个专门用于与该客户端进行一对一通信的已连接套接字,三次握手流程在内核层面也彻底完成。
而这里就能进一步说明为什么必须是"三次握手",而不是"两次握手"的更深层次原因。
如果连接建立仅通过两次握手完成,也就是不需要客户端再发送第三次确认报文,那么只要服务端回复 SYN 并确认,连接就被认为建立成功。此时,内核就必须为该连接创建一个 tcp_sock 结构体。我们知道,有些客户端可能是恶意客户端,其目的并非正常通信,而是大量与服务端建立连接却不进行后续数据交互。
如果采用两次握手机制,那么一旦第二次握手完成,内核就需要创建 tcp_sock 结构体。而 tcp_sock 的内存开销远大于 request_sock,并且其生命周期也远长于 request_sock。request_sock 仅存在于半连接阶段,生命周期通常较短;而 tcp_sock 一旦创建,就代表一个已建立连接,资源占用显著增加。
此外,半连接队列通常可以容纳数千个 request_sock,而全连接队列(已完成三次握手的连接)是有明确上限的。如果大量恶意客户端通过两次握手直接建立连接,迅速创建大量 tcp_sock,那么全连接队列很快会被占满,导致正常客户端无法建立连接。
因此,三次握手的意义不仅在于验证双方的收发能力是否正常,更在于:如果对方迟迟不完成第三次握手,服务端所付出的代价仅仅是维护一个轻量级、生命周期较短的 request_sock,而不会立即分配完整的 tcp_sock 资源。这本质上是一种资源保护机制。
TCP保活机制以及重复ACK
那么这里还需要补充一点:即使有恶意客户端成功完成了三次握手,服务端为其创建了已连接套接字,如果客户端之后既不发送数据,也不调用 close() 关闭连接,会发生什么?
这种情况可以理解为客户端"占用连接但不进行通信"。如果服务端什么都不做,确实会导致已连接套接字长期占用资源。但实际上并不会无限期等待。
每当服务端收到客户端的数据时,会重新设置一次保活定时器(Keepalive Timer)。在默认配置下,这个时间通常为 2 小时。如果在该时间内没有收到客户端的任何数据,服务端会发送一个保活探测报文,用于确认对端是否仍然存活。
这个保活探测报文具有如下特点:
- 通常不携带实际有效数据(实现上可能构造为 1 字节探测)
- 其序列号为"当前已发送但未确认的最小序列号减一",也就是发送窗口左边界的前一个字节
当接收方收到这个探测报文时,如果其仍然存活,那么由于该序列号小于其当前期望接收的序列号(即小于接收窗口左边界),因此会将其视为重复报文,并立即发送一个重复 ACK。
该重复 ACK 的确认号仍然填写"期望收到的下一个字节的序列号"。发送方如果收到了这个 ACK,就可以确认客户端仍然存活,于是重置保活定时器,继续维持连接。
如果发送方没有收到 ACK,则不会立即断开连接,而是间隔一定时间后重传保活探测报文,因为探测报文本身也可能在网络中丢失。当连续多次探测均未收到响应时,才会判定对端异常,主动关闭连接并释放资源。
需要注意的是,默认 2 小时的保活时间对于高并发服务器来说过长,实际生产环境中通常会调整为 60 秒左右,探测间隔例如 30 秒等,以便更快释放异常连接资源。
如果客户端进程突然崩溃、断电或者网线被拔掉,这些都属于非正常退出场景。在这种情况下,客户端进程无法执行清理逻辑,自然也无法主动发送 FIN 报文。
而如果进程是正常退出或者收到终止信号退出,则会进行资源清理流程,包括:
- 遍历文件描述符表
- 访问对应的
file结构体 - 将引用计数减一
- 若引用计数为 0,则释放该对象
- 调用操作函数表中的
close()方法
如果该文件描述符关联的是套接字,那么会调用套接字的关闭函数。如果套接字当前状态不是 CLOSE,说明仍与对端存在连接,此时会主动发送 FIN 报文,与对端进行四次挥手断开连接,然后释放套接字资源。
因此,即使客户端异常崩溃,TCP 的保活机制也会作为最终的兜底保障机制,避免连接资源被永久占用。
而根据上文,我们知道 TCP 在内核中的保活定时器默认值通常为 2 小时。这个时间在多数通用场景下是合理的,但在高并发或对故障检测要求较高的系统中往往过长。因此,可以通过 setsockopt() 接口修改套接字的保活相关参数,包括是否开启保活机制、空闲触发时间、探测间隔以及最大重试次数。
cpp
int sockfd = socket(...);
// 启用保活
int optval = 1; // 1. 设置为 1 表示开启(0 表示关闭)
// 2. SOL_SOCKET 表示这是"通用套接字"级别的选项
// 3. SO_KEEPALIVE 是保活机制的总开关
setsockopt(sockfd, SOL_SOCKET, SO_KEEPALIVE, &optval, sizeof(optval));
/*
* 【内核解读】:
* 这一行代码会在内核对应的 tcp_sock 结构体中勾选一个标志位(flag)。
* 只有该标志位为"真"时,内核的保活定时器(Keepalive Timer)才会真正挂载到内核时间轮上。
* 如果不执行这一步,即便系统全局配置了保活,该特定连接也会永远保持"沉默等待",直到应用层主动关闭。换句话说没有这行代码,内核是不会默认开辟保活机制的
*/
-------------------------------------------------------------
// 单独为此连接配置参数
int keepidle = 60; // 1. 设置"静默期"时长:60秒
// 2. 调用 setsockopt 调整 TCP 协议层(IPPROTO_TCP)的具体参数
setsockopt(sockfd, IPPROTO_TCP, TCP_KEEPIDLE,
&keepidle, sizeof(keepidle));
/* * 【内核解读】:
* 这一行是在设置"保活定时器"的初始触发阈值。
* 只要连接上产生一次数据收发(ACK也算),内核就会将该连接的 idle 计时器重置为 0。
* 只有当连接完全"死寂"满 60 秒时,内核才会停止等待,发起第一轮保活探测(Keepalive Probe)。
*/
-----------------------------------
int keepintvl = 10; // 1. 设置"探测间隔":10秒
// 2. IPPROTO_TCP 层选项,控制保活探测包(Probe)的重发频率
setsockopt(sockfd, IPPROTO_TCP, TCP_KEEPINTVL,
&keepintvl, sizeof(keepintvl));
/*
* 【内核解读】:
* 当第一枚保活探测报文(SEQ = SND.UNA - 1)发出后,内核会启动一个定时器。
* 如果在 10 秒内没有收到对应的重复 ACK(即对方没有"纠正"我的序列号),
* 内核就会认为这一枚探测包可能在网络中丢失了,或者是对方暂时没反应过来。
* 于是,内核会按照这个 10 秒的频率,持续发起后续的探测。
*/
--------------------------------------
int keepcnt = 6; // 1. 设置"最大重试次数":6次
// 2. IPPROTO_TCP 层选项,设置保活探测包的"容忍上限"
setsockopt(sockfd, IPPROTO_TCP, TCP_KEEPCNT,
&keepcnt, sizeof(keepcnt));
/*
* 【内核解读】:
* 这是一个计数器。
* 内核每发送一枚探测包(SEQ = SND.UNA - 1),如果没收到回音,计数器就减 1。
* 如果连续 6 枚探测包都如泥牛入海,内核就会判定:对方已经彻底不在了。
* 此时,内核会直接销毁该 tcp_sock,并向应用层 read/write 抛出 ETIMEDOUT 错误。
*/其次,根据上文我们知道,接收方在收到乱序报文时会立即发送冗余 ACK;在收到重复报文时也会发送重复 ACK。
这个重复ACK的机制的意义在于保证确认报文丢失时,连接仍然能够恢复到一致状态。
例如:接收方按序收到了报文,更新了期望接收的下一个字节序列号,并发送了确认报文。如果这个确认报文在网络中丢失,发送方未收到 ACK,就会认为数据可能丢失,从而在超时后进行重传。
当发送方重传该报文后,接收方会发现该报文序列号小于当前期望序列号,判断为重复报文,将其丢弃,并发送一个重复 ACK。这样,发送方就可以通过收到重复 ACK 确认数据实际上已经被成功接收。
如果没有这个机制,在确认报文丢失的场景下,发送方可能持续触发超时重传,造成不必要的网络开销。
cpp
request_sock:
- 大小:约128字节
- 生命周期:几秒到几十秒
- 容量:半连接队列可容纳数千个
- 超时:自动清理
tcp_sock:
- 大小:约2KB(包含完整的四层结构)
- 生命周期:通常随连接存在而存在
- 容量:全连接队列通常只有128-1024个
- 清理:需要应用层close()或内核超时机制
--------------------------
两次握手(假设):
10万个SYN → 10万个tcp_sock
内存占用:10万 × 2KB = 200MB
全连接队列:立即满(假设上限1024)
→ 正常客户端无法连接
→ 服务瘫痪!
三次握手(实际):
10万个SYN → 10万个request_sock
内存占用:10万 × 128字节 = 12.8MB
半连接队列:可以容纳(假设上限8192)
→ 第三次握手收不到
→ request_sock超时自动清理
→ 服务仍可用认识了关于TCP协议 为什么不是二次握手而是`三次握手的深层原因之后,那么读者可能会进一步思考,TCP 协议为什么不是四次握手呢?
从理论上讲,TCP 确实可以设计为四次握手。也就是说,服务端在收到客户端发送的SYN 报文之后,先回复一个ACK 报文,表示已收到对方的连接建立请求;随后再单独发送一个 SYN 报文,表示同意与客户端建立连接。
然而我们知道,在正式通信之前,需要先完成连接建立这一阶段。该阶段的核心任务,是双方确认彼此的收发能力,并完成 TCP 相关参数(如初始序列号、窗口大小、选项字段等)的协商,并不涉及任何应用层数据的传输。因此,对于服务端而言,"确认收到对方的 SYN "与"发送自己的SYN "这两个动作在语义上是紧密相关、可以同时完成的,并不存在必须分离的必要性。
换言之,服务端在发送自己 SYN 报文的同时,完全可以将对客户端 SYN 的确认信息一并携带,这就是所谓的"捎带确认"机制,即将 ACK 与 SYN 合并为一个 SYN+ACK 报文。这样做可以减少一个报文的往返过程 ,从而降低连接建立阶段的时延。
如果采用四次握手的方式,将 ACK 与 SYN 分开发送,那么客户端在收到纯 ACK 之后,仍需等待服务端的 SYN 才能完成连接建立。这样将额外引入一次不必要的报文往返开销,整体连接建立时间理论上会增加约一个 RTT 。
因此,在保证可靠性与状态确认完整性的前提下,三次握手通过合并报文减少了一次无效的往返延迟,在效率与语义完整性之间取得了更优的平衡。这正是 TCP 选择三次握手而不是四次握手的根本原因。
而根据上文,我们知道三次握手不仅用于确认双方的收发能力是否正常,其还承担着 TCP 协议参数协商 的重要职责。其中最核心的参数之一便是序列号(Sequence Number)。也就是说,在连接建立之初,双方就需要对各自字节流的起始序列号达成一致。
这里客户端发送的第一个 SYN 建立连接请求报文,虽然不携带任何应用层数据,但在发送 SYN 之前,内核会随机选择一个初始序列号(Initial Sequence Number, ISN),作为之后发送的所有应用层数据字节流的起始序号。同时,该 SYN 报文本身会占用并消耗这一个初始序列号,从而使对方可以通过确认号(ACK = ISN + 1)来确认该 SYN 是否被成功接收。
当服务端收到该 SYN 报文后,便可以明确客户端后续发送的字节流将从该初始序列号开始进行编号。与此同时,服务端在发送 SYN-ACK 报文之前,内核同样会随机生成一个自己的初始序列号,作为服务端后续应用层数据字节流的起始序号。同时,该 SYN-ACK 报文中的 SYN 也会占用服务端的这个初始序列号,并在报文中告知客户端。客户端随后通过发送 ACK 报文进行确认。至此,双方各自的初始序列号均完成交换与确认。
这样,在正式通信阶段,双方就能够依据序列号与确认号判断数据报是否按序到达、是否存在乱序或丢失,从而保证可靠传输。
除了协商并交换初始序列号之外,在连接建立阶段,双方还会通告自身当前的接收窗口大小,即接收缓冲区的可用空间,以便对后续正式通信阶段的数据发送速率进行初步的流量控制。此外,双方还会协商是否启用选择确认(SACK)选项、最大报文段长度(MSS)等关键参数,这些选项都会影响后续数据传输的效率与可靠性。
TCP握手状态变化
那么在明确了上述背景之后,接下来讨论 TCP 协议三次握手过程中的状态变化。
首先,将视角聚焦于服务端。服务端是被动接收来自客户端的连接建立请求的一方。对于服务端进程而言,首先需要调用 socket 接口创建一个普通套接字。ocket 调用返回的套接字,本质上是在内核中创建了一个包含传输层、网络层等协议控制块的分层结构(例如包含 sock、inet_sock、tcp_sock 等结构的组织关系)。不过,此时该套接字仅完成了协议类型的确定,还未被赋予"监听"或"已连接"等具体语义。
因此,接下来通常需要调用 listen 接口,将该普通套接字转换为监听套接字。在调用 listen 之前,该 TCP 套接字的初始状态为 CLOSE;调用 listen 之后,其状态转换为 LISTEN。只有当套接字处于 LISTEN 状态时,内核才会将其视为监听套接字,才能接收客户端发送的连接建立请求报文(即 SYN 报文)。
此时读者可能会产生疑问:在服务端调用 listen 之前,通常会先调用 bind 接口,将套接字绑定到特定的 IP 地址和端口号(二元组)。而 bind 在内核层面所做的核心工作之一,就是将该套接字按照键值插入到相应的哈希表中,以便后续快速查找。
然而,TCP 与 UDP 在这一点上存在本质区别。TCP 协议中,监听套接字与已连接套接字分别维护各自独立的哈希表;而在调用 listen 之前,该套接字尚未被赋予"监听"或"已连接"的具体语义。那么此时执行 bind 操作,究竟应将该套接字插入到哪个哈希表中?
这里需要注意:对于 TCP 而言,内核通常维护三类哈希结构------监听套接字哈希表、已连接套接字哈希表,以及一张全局(或称为无状态)哈希表。由于 bind 发生在 listen 或 connect 之前,此时套接字尚未确定未来角色,因此内核无法直接将其插入监听或已连接套接字对应的哈希表中。
因此,对于已调用 bind 的 TCP 套接字,内核会先将其按照二元组(IP + 端口)插入到全局哈希表中。待之后调用 listen 或 connect 时,再根据具体语义将其从全局哈希表中移除,更新状态,并插入到对应的监听或已连接套接字哈希表中。
而对于 UDP 而言,其套接字本身不具备 TCP 那样的连接状态语义,不存在监听态与已连接态的区分。因此 UDP 仅维护一张以二元组(IP + 端口)为键的哈希表。对于 UDP 类型的套接字,bind 调用后即可直接插入该哈希表,无需后续状态迁移。
在理解了上述机制之后,继续回到 TCP 服务端流程:调用 bind 接口后,再调用 listen 接口。此时监听套接字的状态从 CLOSE 转换为 LISTEN,同时内核会为该监听套接字初始化半连接队列(SYN 队列)与全连接队列(accept 队列)。随后,将其在全局哈希表中的条目移除,并插入到监听套接字哈希表中。至此,服务端便可以接收来自不同客户端的连接建立请求报文。
根据前文分析,当服务端收到客户端发送的 SYN 报文时,内核会创建一个 request_sock 结构体,用于暂存半连接阶段的相关信息,其中包括 TCP 协议控制参数、初始序列号、窗口信息以及四元组等。随后,内核提取出四元组信息,在半连接队列中进行查找,并将该 request_sock 插入其中。
对于监听套接字本身而言,其状态实际上只有两种:CLOSE 与 LISTEN。然而在教材中,我们常常会看到一个额外的状态------SYN-RECV(或 SYN-RECEIVED)。需要澄清的是,该状态并不属于监听套接字,而是用于描述半连接阶段对应的 request_sock 的逻辑状态。
不过,从实现角度来看,request_sock 的状态变化是非常单一的。它在创建后即处于 SYN-RECV 状态,不会经历类似监听套接字或已连接套接字那样的多阶段状态转换。
具体而言:
- 若服务端在发送 SYN+ACK 后,长时间未收到客户端的第三次握手 ACK 报文,则会触发重传机制。若重传次数达到上限,内核会直接销毁对应的
request_sock,而不会将其转入某种"关闭"状态。 - 若成功收到客户端发送的第三次握手 ACK 报文,内核同样会销毁该
request_sock,随后创建新的tcp_sock结构体,将其状态设置为ESTABLISHED,并插入到已连接套接字对应的哈希表,同时放入全连接队列中,等待用户进程调用accept取出。
因此,对于 request_sock 而言,其生命周期可以理解为:从 SYN-RECV 状态开始,最终要么因超时被销毁,要么在握手成功后被替换为真正的 tcp_sock。它不会经历更多状态迁移。
从严格的状态机建模角度看,SYN-RECV 这一状态的存在主要是为了完整表达 TCP 协议三次握手过程中的逻辑阶段,而并非用于描述一个长期存在的、可反复迁移的内核对象状态。因此,可以认为该状态更多是协议层语义上的标识,而非复杂的实现层状态流转。
而对于客户端进程而言,其同样需要调用 socket 接口创建一个普通套接字,然后调用 connect 接口将其转化为已连接套接字。调用 socket 接口创建的套接字初始状态为 CLOSE。由于客户端的端口号通常由内核自动分配,因此一般不会显式调用 bind 进行绑定。
如果显式调用 bind 接口进行绑定,那么此时 bind 会将该套接字插入到全局哈希表中,并初始化 sock 结构体中 inet_sock 子结构体的源 IP 地址以及源端口字段。接着调用 connect 接口时,内核会检查 sock 结构体中 inet_sock 的源 IP 和源端口字段是否为 0。
- 如果不为 0,则说明该套接字已经被显式绑定。此时内核会先从全局哈希表中移除对应条目,然后基于已经绑定好的本地 IP 地址和端口号,与目标 IP 和目标端口共同组成四元组,再将其插入到已连接套接字哈希表中。
- 如果为 0,则表示尚未进行显式绑定,本地 IP 地址与端口号的分配将由内核完成。内核会根据路由选择合适的本地 IP 地址,并分配一个当前未被占用的临时端口(ephemeral port)。确定本地二元组后,与目标端组成四元组,并将其插入到已连接套接字哈希表中。
完成上述步骤后,内核会将套接字状态设置为 SYN-SENT,同时发送一个 SYN 报文至服务端,请求建立连接。
当内核收到服务端返回的 SYN-ACK 报文时,会根据报文中的四元组信息查询已连接套接字哈希表,从而定位到对应的 tcp_sock 结构体。随后将套接字状态修改为 ESTABLISHED,并唤醒因调用 connect 而陷入阻塞的进程,至此三次握手完成,连接正式建立,进入后续的数据通信阶段。
RST标记位
认识了三次握手之后,接下来介绍 RST 标志位。根据上文,我们知道客户端会主动向服务端发送一个建立连接的 SYN 报文。服务端收到 SYN 报文后,内核会创建一个 request_sock 结构体,并将其插入到对应监听套接字的半连接队列(SYN 队列)中,然后回复一个 SYN-ACK 报文。
需要注意的是,如果客户端向服务端发送 SYN 报文(即调用 connect 接口发起连接),调用 connect 时必须提供服务端的 IP 地址以及端口号。假设服务端在该端口上并未创建监听套接字,意味着监听套接字对应的哈希表中不存在相关条目。此时内核收到 SYN 报文后,会提取报文中的四元组信息,首先查询已连接套接字对应的哈希表;若未命中,则继续查询监听套接字对应的哈希表;如果仍未命中,说明该端口上不存在监听套接字。
在这种情况下,内核会向客户端发送一个设置了 RST 标志位的报文。RST 报文本身不具备重传和确认机制,它用于立即终止当前连接尝试。
一旦客户端成功收到 RST 报文,其含义是服务端拒绝建立连接(例如端口未监听)。在上述场景中,由于服务端收到了客户端发送的 SYN 报文,因此回复的 RST 报文通常会同时设置 ACK 标志位,并携带相应的确认号,表示该 SYN 已被确认,但连接被拒绝。客户端检测到 RST(以及 ACK)标志位后,即可明确连接失败的原因,无需再发送 ACK 或重新发送 SYN。此时客户端会将套接字状态从 SYN-SENT 转换为 CLOSE,同时设置 sk_err 字段,唤醒因调用 connect 而阻塞的进程,并向用户空间返回相应的错误码(例如 ECONNREFUSED)。
还有一种场景是:客户端已经与服务端完成三次握手并进入通信阶段,随后服务端发生异常,例如服务端重启。在该情况下,由于系统重启,原有的监听套接字和已连接套接字相关哈希表条目均被清空(断电后内存数据丢失)。当服务端内核再次收到客户端发送的数据报文时,会提取四元组并查询已连接套接字和监听套接字对应的哈希表。如果均未命中,则说明不存在匹配的连接状态,此时内核会直接回复一个 RST 报文。
客户端收到该 RST 报文后,会将套接字状态设置为 CLOSE,设置 sk_err 字段,并唤醒因调用 read 或 recv 接口而阻塞的进程,随后返回错误码,表明连接已被对端重置(Connection reset)。
这里还需要特别注意一个细节。根据上文,当客户端发送 SYN 报文后,服务端收到该报文,会构建 request_sock 结构体并插入到监听套接字的半连接队列中,然后发送 SYN-ACK 报文。如果随后服务端收到了客户端发送的第三次握手报文(ACK),此时并不会立刻销毁 request_sock,而是会检查全连接队列(accept 队列)是否已满。
如果全连接队列已满,则不会销毁 request_sock,也不会创建真正的 tcp_sock 并将其加入全连接队列,而是直接丢弃该第三次握手的 ACK 报文。
之所以这样设计,是因为内核不希望立即放弃这个潜在连接。若应用层稍后调用 accept,腾出了全连接队列的空间,该连接仍有机会建立成功。
但对于客户端而言,它已经认为三次握手完成,connect 返回成功,随后开始发送应用层数据。这些数据到达服务端后,内核提取四元组,查询已连接套接字哈希表未命中;随后根据二元组查询监听套接字哈希表,命中;再查询半连接队列,发现存在对应的 request_sock。
此时内核意识到双方状态并不一致:客户端认为连接已建立,而服务端尚未将其转入全连接队列。在这种情况下,内核不会发送 RST,而是继续丢弃这些数据报文。同时,由于 request_sock 仍然存在于半连接队列中,服务端会基于超时机制重传 SYN-ACK 报文。
客户端再次收到 SYN-ACK 报文后,会查询已连接套接字哈希表,发现命中对应套接字,但检测到该报文中 SYN 标志位为 1,而当前套接字状态已经是 ESTABLISHED,因此可以判断双方状态存在不一致,即服务端尚未确认连接建立成功。此时客户端会再次回复 ACK。
如果此时服务端的全连接队列已有空闲位置,内核便可以创建 tcp_sock,将其插入全连接队列,等待应用层通过 accept 取走。此前被丢弃的数据,由于客户端存在超时重传机制,在连接真正建立完成后会重新发送,从而正常进入数据接收路径。
另外,也无需担心这样一种情况:客户端认为连接建立成功,但迟迟未收到服务端对数据的响应,最终因重传次数达到上限而主动关闭连接。需要注意的是,在半连接阶段,服务端针对 SYN-ACK 的重传次数通常为 5 次,而在正常通信阶段,数据报文的重传次数通常为 15 次(具体取决于内核参数配置)。
如果服务端已对 SYN-ACK 重传 5 次仍未完成握手,且全连接队列始终无空闲位置,则会销毁对应的 request_sock,正式放弃该连接。一旦 request_sock 被销毁,后续到达的、承载应用层数据的报文将不再只是简单丢弃。
此时内核查询已连接套接字哈希表未命中,查询监听套接字哈希表命中,但在半连接队列中已找不到对应的 request_sock。在这种情况下,内核不仅会丢弃报文,还会发送 RST 报文,明确通知对方:服务端已放弃该连接。客户端此时若仍希望通信,只能重新发起连接,而不是继续发送数据报文。
TCP四次挥手
根据上文,我们认识了 TCP 的三次握手,接下来介绍 TCP 的四次挥手。TCP 四次挥手用于断开连接。需要注意的是,TCP 四次挥手与三次握手不同:三次握手通常由客户端主动发起(在典型的 C/S 模型中由客户端调用 connect 触发),而 TCP 四次挥手则可以由通信双方中的任意一方主动发起。
那么其中一方主动发起四次挥手,也就是调用 close 接口。close 接口会接收文件描述符,然后在当前进程的文件描述符表中定位对应的 file 结构体,接着减少 file 结构体的引用计数;如果引用计数为 0,则释放 file 结构体,并调用其操作函数表中的 close 函数。对于套接字而言,该函数最终会调用 socket 结构体对应的 close 操作。
其底层行为通常包括:首先检查发送缓冲区是否为空;如果不为空,则先将发送缓冲区中的数据依然按照滑动窗口和nagle算法的发送逻辑发送出去,其中发送的最后一个报文,会捎带 FIN 标志为。该 FIN 报文的本质是将 FIN 标志位设置为 1。这个 FIN 报文即为第一次挥手,同时将套接字状态置为 FIN_WAIT_1,而如果对方接收窗口(Window Size)为 0,你的 FIN 是发不出去的。
- 即使你调了
close,只要对方没腾出地方,你的最后一个带 FIN 的报文就会一直卡在发送缓冲区。 - 这时候主动关闭方的套接字会卡在
FIN_WAIT_1(或者在发送前卡在CLOSE调用上),直到对方读取数据腾出窗口。这再次证明了 TCP 是一个"完全受控"的协议,即便要分手,也得看对方的脸色。
对方收到该 FIN 报文(即第一次挥手报文)后,内核会修改对应已连接套接字的状态为 CLOSE_WAIT,并向对方发送一个 ACK 报文,表示已经收到该 FIN 报文。
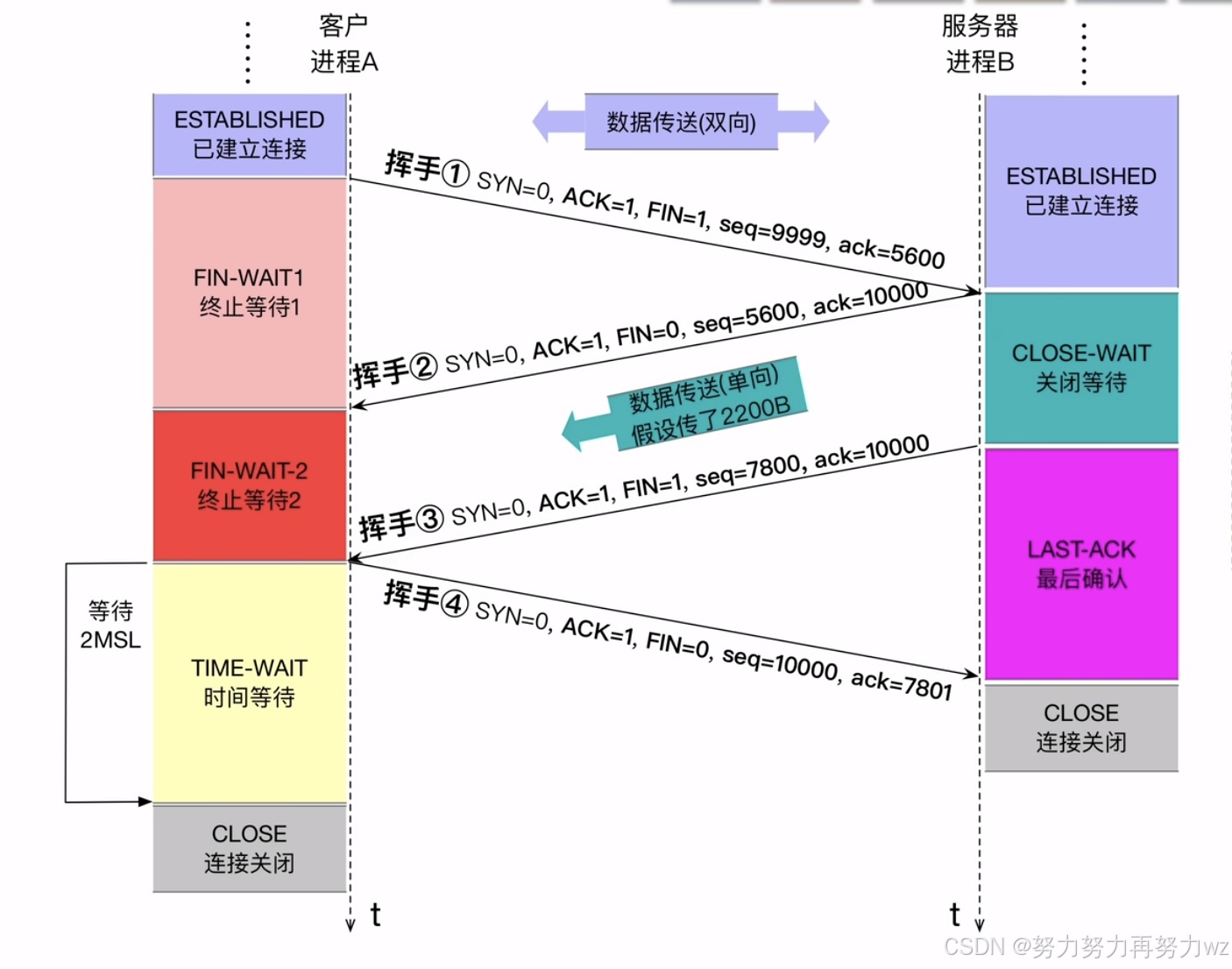
至此前两次挥手完成。但需要注意,这两次挥手仅关闭了一个方向的数据传输。也就是说,主动发起关闭的一方不能再向对方发送数据,但仍然可以接收对方发送的数据;而被动关闭的一方仍然可以继续发送数据给主动关闭的一方。
此时,主动关闭的一方只能读取套接字接收缓冲区中的数据,并且在成功接收数据后仍然会向对方发送纯 ACK 确认报文。纯 ACK 报文本身不携带数据,因此不会消耗序列号(但其确认号字段会发生变化)。
当对方也调用 close 接口时,意味着其也关闭了另一个方向的通信。此时对方会发送一个 FIN 报文。主动关闭连接的一方在收到该 FIN 之前通常已进入 FIN_WAIT_2 状态;当收到该 FIN 后,会发送一个 ACK 确认报文,发送完成后进入持续 2MSL 的 TIME_WAIT 状态。
由于这里发送的是纯 ACK,对方无需再进行确认应答。但如果该 ACK 报文在网络中丢失,对方未收到确认,就会触发超时重传 FIN。因此,主动关闭方不会立即进入 CLOSED 状态,而是进入 TIME_WAIT 并等待 2MSL 时间。MSL(Maximum Segment Lifetime)表示报文在网络中的最大生存时间,通常为 30 秒左右,因此 2MSL 一般约为 60 秒(不同系统实现可能不同)。
这里需要注意,根据前文可知,如果对方在调用 close 时其发送缓冲区中仍然存在数据,那么内核会按照滑动窗口机制以及 Nagle 算法的发送逻辑,将发送缓冲区中的数据依次发送出去。通常情况下,最后一个报文段会"捎带"一个 FIN 标志位(即在该数据报文段中同时携带 FIN),从而完成本方向数据发送的终止。
需要进一步说明的是:FIN 本身也占用一个序列号。因此,它在序列空间中具有明确的位置。
如果第三次挥手中的 FIN 报文提前到达目标主机(即发生乱序到达),内核会根据其序列号进行校验。若发现该 FIN 对应的序列号超出了当前期望接收的下一个序列号(即中间仍存在"空洞"),则不会立即处理该 FIN,而是将其放入乱序队列(out-of-order queue)中缓存。
此时连接状态不会立即进入 TIME_WAIT。因为 TCP 的状态推进依赖于按序交付 的语义:只有当之前缺失的数据报文全部到达、空洞被填补,序列号连续之后,该 FIN 才会从乱序队列移动到有序队列,成为"当前可按序处理的报文"。在这一时刻,内核才会真正处理该 FIN,发送对应的 ACK,并将连接状态切换为 TIME_WAIT。
换句话说:
- 乱序到达的 FIN 只会被缓存,不会立即触发状态迁移;
- 只有当所有前序数据都被成功接收并完成按序重组后,FIN 才会生效;
- 状态机的推进必须建立在序列号连续的基础之上。
这一机制保证了 TCP 的可靠性和有序性,不会因为 FIN 的乱序到达而提前结束连接。
并且对于发送方而言,一旦其调用了 close 接口(在被动关闭一侧,即处于 CLOSE_WAIT 状态时调用 close),内核会先按照发送逻辑将发送缓冲区中的数据发送完毕,然后发送一个 FIN 报文段。
需要强调两点:
- FIN 本身也占用一个序列号;
- 发送 FIN 之后,套接字状态会进入
LAST_ACK,而不是立即进入CLOSED。
在 LAST_ACK 状态下,发送方必须等待对端对该 FIN 的确认(即收到对 FIN 的 ACK 报文)。只有当该 ACK 报文成功到达,并且确认号覆盖了 FIN 所占用的序列号时,内核才会认为连接已经完全终止,随后将状态从 LAST_ACK 切换为 CLOSED,并最终释放相关资源。
如果该 ACK 报文丢失,对端会因未收到确认而重传 FIN;发送方在 LAST_ACK 状态下仍然能够响应重传的 FIN(通常会重新发送 ACK),直到成功收到确认并完成状态迁移
TCP 四次挥手的意义不仅在于断开连接,还在于确保历史报文不会影响后续新的连接。
例如,某些之前发送的数据报文可能由于网络拥塞等原因发生严重延迟。更极端的情况是,该报文在网络中的某个路由器处发生环路,在网络中"滞留"了较长时间。此时发送方因为未收到确认而触发超时重传,重传报文正常到达接收方,填补了之前的序列号空洞,随后接收方会将乱序队列中的报文依次移交到有序队列,其中也包括最后一个 FIN 报文。至此,连接完成四次挥手,主动关闭方进入 2MSL 的 TIME_WAIT 状态,并发送一个 ACK 报文,该 ACK 的确认号覆盖了最后一个 FIN 所占用的序列号。
如果此时那个在网络中"绕路"的旧报文在 2MSL 等待期间才到达主机,内核会对其进行序列号校验。由于当前连接仍处于 TIME_WAIT 状态,内核仍然保留该连接的控制块信息,因此可以识别出该报文属于旧连接的重复数据,从而将其直接丢弃,不会对系统造成影响。
然而,如果没有 TIME_WAIT 机制,在连接关闭后立即释放资源,并且使用相同的四元组(源 IP、源端口、目的 IP、目的端口)建立了新的连接,那么这个迟到的旧报文一旦到达,就可能被误认为是新连接的数据。若其序列号恰好落入新连接的序列号空间范围内,就可能被当作合法数据接收,从而造成数据错乱或协议状态异常。
因此,在 2MSL 的 TIME_WAIT 阶段内,这些旧报文要么在内核仍能识别旧连接时被正确处理(通常是根据序列号判断为重复报文并直接丢弃),从而避免与后续使用同一四元组建立的新连接产生混淆。
这正是 TIME_WAIT 存在的核心工程意义:
它不是"浪费时间",而是用时间换取协议状态的确定性与安全性,保证 TCP 连接在时序混乱的网络环境下依然能够保持可靠与一致。
这里还需要注意一点:在服务端进程通常是长期运行的场景下,如果通过 Ctrl + C 发送信号强制终止服务端进程,进程在退出时会进行资源清理,包括关闭已打开的文件。具体来说,会遍历文件描述符表,依次关闭文件;关闭文件的过程同样是减少对应 file 结构体的引用计数,若引用计数为 0,则释放该结构体,并调用其 close 操作,也就是间接调用套接字的 close,从而发送 FIN 报文。
此时,对方收到 FIN 报文后会发送 ACK,并唤醒因调用 read 或 recv 而阻塞的客户端进程。客户端进程检测到返回值为 0(表示对端已正常关闭连接),或根据错误码判断连接已断开,从而决定是否退出,进而完成后续的挥手流程。
因此,即使服务端进程已经退出,其对应的套接字在内核中也不会立即释放,而是可能进入 TIME_WAIT 状态。当我们立即重启服务端时,可能会出现 bind error,这是因为原先的 IP 地址和端口号仍处于占用状态(准确来说,是处于 TIME_WAIT 相关限制之下)。
为了解决该问题,可以在创建套接字后,通过 setsockopt 设置端口复用选项 SO_REUSEADDR,以允许在一定条件下复用处于 TIME_WAIT 状态的地址和端口:
cpp
int sockfd = socket(AF_INET, SOCK_STREAM, 0);
// 设置 SO_REUSEADDR 选项
int reuse = 1;
setsockopt(sockfd, SOL_SOCKET, SO_REUSEADDR, &reuse, sizeof(reuse));最后关于 TCP 挥手为什么是四次,而不是三次,其根本原因在于:TCP 是全双工协议,两个方向的通信通道是相互独立的,因此必须分别关闭。
与建立连接阶段不同,在三次握手过程中,双方尚未进入正式的数据通信阶段,因此不存在"未发送完的数据"的问题,SYN 与 ACK 可以在一定程度上合并处理。而在连接终止阶段,双方可能仍然存在尚未发送完的应用层数据,因此两个方向的关闭在时序上并不一定是连续发生的。
具体来说:
- TCP 前两次挥手对应的是一个方向的关闭;
- 后两次挥手对应的是另一个方向的关闭;
- 这两个方向的关闭在时间上可能相隔较长。
当一方完成前两次挥手后(发送 FIN,收到 ACK),只是表示该方向的数据流被关闭,但另一方向仍然可以继续发送数据。因此,被动关闭的一方(即收到 FIN 的一方)在发送 ACK 时,通常不会立即将 ACK 与自己的 FIN 捎带发送。因为它可能仍有数据需要发送,尚未准备关闭。
只有在一种特殊情况下------被动关闭方在收到 FIN 时恰好也没有数据需要发送,并且也决定立即关闭连接------才可能将 ACK 与 FIN 合并发送,从而在报文层面上看起来像"三次挥手"。但 TCP 规范不能假设所有连接都会满足这种理想情况。
换句话说,TCP 不能依赖"双方都会同时关闭"这一前提。由于:
- 连接可能由任意一方主动关闭;
- 被动关闭方可能仍有数据需要继续发送;
- 应用层关闭时机无法由协议强制同步;
因此协议设计上必须允许两个方向独立终止,这就决定了标准情况下需要四次挥手。
所以,TCP 之所以采用四次挥手,并不是出于形式上的对称,而是因为:
每个方向的关闭都需要一次 FIN 和一次 ACK,而两个方向的关闭在时序上是独立的。
这保证了 TCP 在全双工通信模型下的正确性与完整性,也能够覆盖所有可能的应用场景。这就是 TCP 终止连接通常需要四次挥手的根本原因。
拥塞窗口
那么关于 TCP 协议的最后一个话题,就是拥塞窗口(cwnd)。我们知道,数据包从主机发出之后会进入网络,而网络中充斥着来自各个主机的数据报文。如果发送方只关注对方主机的接收能力(即接收窗口 rwnd),而不考虑当前网络的状态,直接按照窗口范围持续向网络注入数据,那么极易造成网络拥塞,进而导致数据报丢失。
因此,对于发送方而言,其不仅需要关注对方接收缓冲区的容量,还必须关注当前网络的拥塞状况。如果网络处于拥堵状态,发送方就应主动控制发送速率,这正是 TCP 拥塞控制机制存在的意义。
那么,发送方如何获取网络的状态呢?发送方显然不可能直接与沿途的路由器进行通信。一方面,网络中存在大量路由器,路径是动态选择的;发送方只负责将数据从网卡发出,至于数据包具体经过哪些路由器,发送方并不知情。这个过程类似于在上游放出一个漂流瓶,它会随着水流向下游漂去,但具体流向哪个分支路径,发送者无法掌控。
另一方面,路由器的职责是进行转发和路由决策,如果还需要与所有主机进行状态交互,将极大增加其负载和缓冲区压力,这在工程上是不可行的。因此,TCP 的拥塞控制是一种端到端的推断机制。
既然发送方无法直接获知网络状态,那么只能通过间接信号来推断,例如:
- 是否发生丢包(超时重传)
- 是否收到多个冗余 ACK(触发快速重传)
在完成连接建立之后,进入数据传输阶段,发送方首先进入慢启动(Slow Start)阶段。
所谓慢启动,并不是"慢速启动",而是指发送窗口从一个较小的初始值开始,逐步扩大。其核心思想是:先以较小的数据量进行试探,以感知当前网络的承载能力。
在慢启动阶段,每收到一个 ACK,拥塞窗口 cwnd 就增加一个 MSS。因此,在一个 RTT 内,若当前发送了 cwnd 个报文段并全部被确认,则 cwnd 会翻倍,呈现指数级增长。之所以采用指数增长,是因为如果采用线性增长,达到可用带宽上限的过程将过于缓慢,不利于带宽的快速利用。
但指数增长不可能无限持续。随着时间推移,指数函数增长速度极快,若不加限制,将迅速超过网络的实际承载能力。因此 TCP 设置了一个门限值:慢启动门限(ssthresh, slow start threshold)。
当 cwnd 小于 ssthresh 时,采用指数增长;当 cwnd 达到或超过 ssthresh 时,进入拥塞避免阶段(Congestion Avoidance),改为线性增长。
如果当前不存在历史连接记录,那么 ssthresh 通常会被设置为一个足够大的值(逻辑上可以理解为极大值),这意味着发送方会在慢启动阶段持续进行指数增长,直到真正检测到拥塞事件。只有在首次发生拥塞之后,才会根据当时的 cwnd 计算出一个具有实际网络意义的门限值:
s s t h r e s h = c w n d 2 ssthresh = \frac{cwnd}{2} ssthresh=2cwnd
因此,第一次拥塞发生时得到的 ssthresh,才是与当前网络路径实际容量相关的有效门限值。
而如果之前存在到同一目的主机的历史连接记录,那么内核可能会缓存这些拥塞控制相关参数。这些信息通常以目的 IP 为键存储在内核的 TCP metrics 缓存结构中(实现上通常基于哈希表)。
在 Linux 系统中,可以通过以下命令查看这些缓存信息:
bash
ip tcp_metrics其中可能展示如下指标:
- ssthresh:上一次连接检测到拥塞时记录的门限值
- rtt / rttvar:往返时间估计值及其波动
- cwnd:上一次连接结束时的拥塞窗口大小
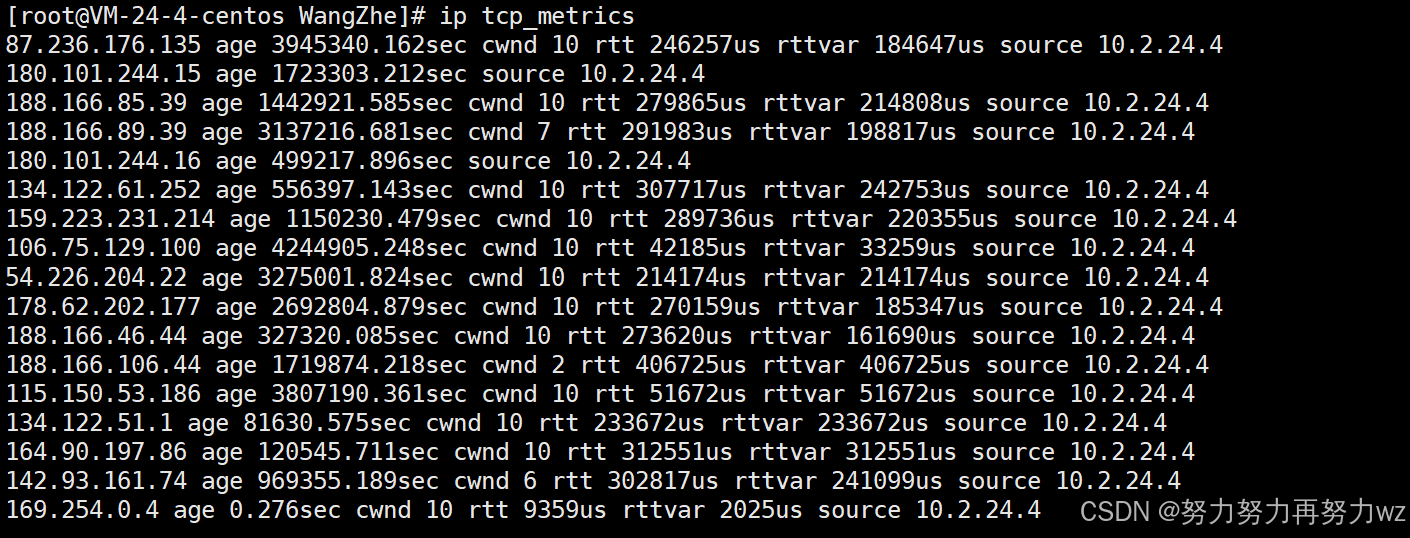
当再次向同一目的地址建立连接时,内核可能会参考这些历史记录来初始化当前连接的拥塞控制参数,例如将之前记录的 ssthresh 作为当前连接的初始门限参考值,从而避免每次都从完全未知状态开始探测网络容量。
需要强调的是,这种基于历史路径信息的参数复用属于具体内核实现层面的优化机制,而非 TCP 协议层面的强制规定。
当发送方检测到严重拥塞(通常表现为超时重传),TCP 会执行如下操作:
- 将 ssthresh 设置为当前拥塞窗口的一半(ssthresh = cwnd / 2);
- 将 cwnd 重置为初始值(传统实现为 1 MSS,现代实现通常为 10 MSS 左右);
- 重新进入慢启动阶段。
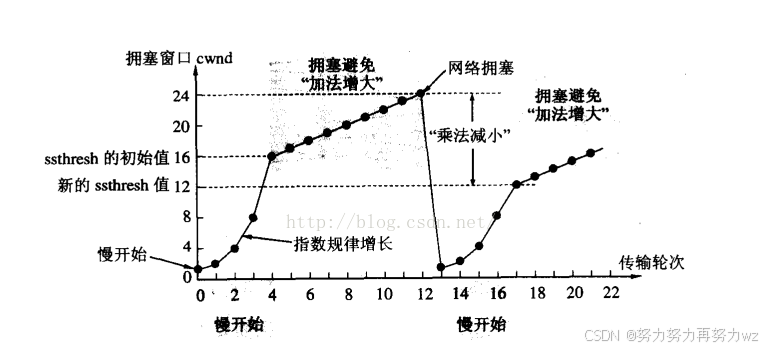
之所以要大幅降低发送速率,是因为发生超时重传通常意味着网络已经出现较为严重的拥塞。并且,超时检测本身具有延迟性------当发送方检测到超时时,网络可能早已进入拥塞状态一段时间。因此必须采取较为激进的退让策略,以帮助网络尽快恢复。
将 ssthresh 设置为当前窗口的一半,本质上是一种经验性的折中策略。拥塞的形成是一个逐渐累积的过程,并非瞬时发生,因此将窗口减半通常能够回退到一个较为安全的发送速率区间。
需要进一步说明的是,流量控制与拥塞控制是两个不同维度的机制:
- 流量控制:由接收窗口 rwnd 决定,防止接收方缓冲区溢出;
- 拥塞控制:由拥塞窗口 cwnd 决定,防止网络过载。
最终发送窗口大小由两者共同决定:
实际发送窗口 = min ( c w n d , r w n d ) 实际发送窗口 = \min(cwnd, rwnd) 实际发送窗口=min(cwnd,rwnd)
关于慢启动初始值(Initial cwnd),现代操作系统通常将其设置为约 10 个 MSS,这是基于对实际网络环境和 Web 传输特征的工程优化结果,而不是固定的协议常数。
在慢启动阶段,窗口增长规律可以表示为(以 RTT 为单位):
1 → 2 → 4 → 8 → ... 1 \to 2 \to 4 \to 8 \to \dots 1→2→4→8→...
即每经过一个 RTT,窗口大小近似翻倍,呈现出指数增长的趋势。其数学形式可以表示为:
c w n d = 2 k cwnd = 2^k cwnd=2k
其中 k 表示经历的 RTT 轮数。
至此,可以看到 TCP 通过 cwnd 与 rwnd 的协同控制,在保证接收方能力边界的同时,也动态适应网络的实际承载能力,从而在效率与稳定性之间取得平衡。
结语
那么这就是本篇文章的全部内容,带你全面认识以及掌握TCP协议,至此我们掌握了传输层协议的有关内容,那么下一期博客我会更新IP协议,我会持续更新,希望你能够多多关注,如果本文有帮助到你的话,还请三连加关注,你的支持就是我创作的最大动力!
