🚀 架构实战:用线程池 + SKIP LOCKED 构建高可用分布式调度引擎
从零到一打造支持水平扩展、故障自愈的分布式任务调度框架
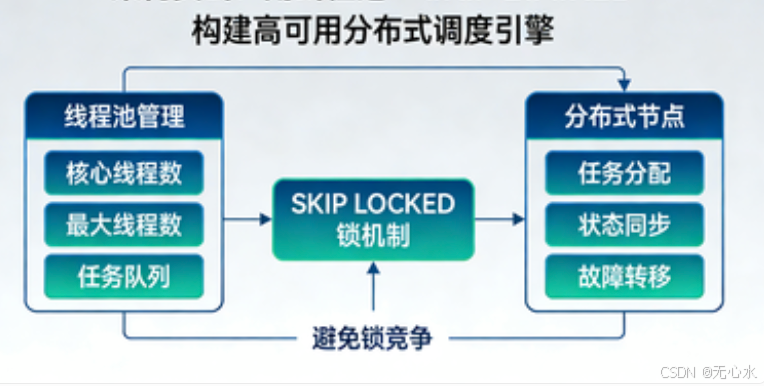
在前三篇文章中,我们深入探讨了 SELECT FOR UPDATE SKIP LOCKED 的原理、数据库差异以及锁机制。理论终需落地,今天我们将进入实战环节:如何基于线程池和 SKIP LOCKED 构建一个生产可用的分布式调度引擎。
本文会涵盖整体架构设计、核心调度器实现、任务执行器扩展、故障恢复机制等关键模块。所有代码均以 Java + Spring Boot 为例,并提供完整的 mermaid 流程图,帮助你轻松理解整个系统的运作方式。
一、整体架构设计
1.1 系统架构图
一个高可用的分布式调度系统通常由多个无状态的调度节点组成,它们共享同一个数据库,通过 SKIP LOCKED 竞争任务。每个节点内部包含调度线程池、任务执行线程池以及监控模块。
节点内部
调度集群
调度节点1
调度节点2
调度节点N
数据库
轮询线程
定时拉取
动态线程池
任务执行器1
任务执行器2
任务执行器3
心跳线程
监控线程
死任务检测
(独立模块或定时任务)
1.2 数据库任务表设计
任务表是整个系统的核心,设计的好坏直接影响调度效率和可靠性。以下是一个经过实战检验的表结构(以 MySQL 为例):
sql
CREATE TABLE `task` (
`id` BIGINT UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '主键',
`task_type` VARCHAR(64) NOT NULL COMMENT '任务类型,用于路由到具体的执行器',
`payload` JSON DEFAULT NULL COMMENT '任务参数,JSON格式,灵活扩展',
`status` TINYINT NOT NULL DEFAULT '0' COMMENT '状态:0-待执行 1-执行中 2-成功 3-失败 4-待重试',
`priority` TINYINT NOT NULL DEFAULT '5' COMMENT '优先级 1-10,数值越大优先级越高',
`execute_time` DATETIME NOT NULL COMMENT '计划执行时间(或下次重试时间)',
`retry_times` TINYINT NOT NULL DEFAULT '0' COMMENT '已重试次数',
`max_retries` TINYINT NOT NULL DEFAULT '3' COMMENT '最大重试次数',
`node_id` VARCHAR(64) DEFAULT NULL COMMENT '当前执行节点ID,用于故障恢复',
`version` INT NOT NULL DEFAULT '0' COMMENT '乐观锁版本(可选,用于防止并发更新)',
`create_time` DATETIME DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` DATETIME DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`),
KEY `idx_status_exec_time` (`status`, `execute_time`),
KEY `idx_node_id` (`node_id`),
KEY `idx_task_type` (`task_type`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='任务表';关键字段说明:
task_type:用于区分不同的业务任务,如EMAIL、REPORT、CLEANUP等。payload:JSON 格式,存储任务所需的参数,灵活且无需改表。status:状态机流转如下:
创建任务
节点领取
执行完成
失败且未达最大重试次数
重试时间到,再次领取
失败且已达最大重试次数
待执行
执行中
成功
待重试
失败
priority:支持优先级调度,结合ORDER BY使用。node_id:记录当前执行任务的节点,用于检测死任务(节点宕机后,其他节点可接管)。
索引优化 :最核心的查询是 WHERE status IN (0,4) AND execute_time <= NOW() ORDER BY priority DESC, execute_time ASC LIMIT ?,因此需要建立 (status, execute_time) 复合索引。如果还涉及 priority 排序,可以尝试 (status, priority, execute_time),但要注意索引大小和更新成本。
二、核心调度器实现
2.1 定时拉取 + SKIP LOCKED
每个调度节点都有一个后台轮询线程,定期执行以下操作:
- 计算当前可用的执行线程槽位数(动态负载控制)。
- 使用
SELECT FOR UPDATE SKIP LOCKED从数据库拉取待执行任务。 - 将拉取到的任务提交给线程池执行。
下面是核心代码(基于 Spring Boot + JdbcTemplate):
java
@Component
@Slf4j
public class DistributedTaskScheduler implements InitializingBean, DisposableBean {
@Autowired
private JdbcTemplate jdbcTemplate;
@Autowired
private TaskExecutorFactory executorFactory;
@Value("${scheduler.node-id}")
private String nodeId;
@Value("${scheduler.poll-interval:1000}")
private long pollIntervalMs;
@Value("${scheduler.batch-size:20}")
private int batchSize;
@Value("${scheduler.thread-pool.core-size:10}")
private int corePoolSize;
@Value("${scheduler.thread-pool.max-size:50}")
private int maxPoolSize;
private ScheduledExecutorService pollExecutor;
private ThreadPoolExecutor taskExecutor;
private final Set<Long> processingIds = ConcurrentHashMap.newKeySet();
private final Map<Long, Future<?>> runningTasks = new ConcurrentHashMap<>();
private volatile boolean running = false;
@Override
public void afterPropertiesSet() {
initialize();
}
private void initialize() {
// 创建动态线程池
this.taskExecutor = new ThreadPoolExecutor(
corePoolSize,
maxPoolSize,
60L, TimeUnit.SECONDS,
new LinkedBlockingQueue<>(1000),
new ThreadFactoryBuilder().setNameFormat("task-worker-%d").build(),
new ThreadPoolExecutor.CallerRunsPolicy() // 当队列满时,由调用线程执行
);
this.pollExecutor = Executors.newSingleThreadScheduledExecutor(
new ThreadFactoryBuilder().setNameFormat("poll-thread").build()
);
this.running = true;
// 启动轮询任务
pollExecutor.scheduleWithFixedDelay(this::pollLoop, 0, pollIntervalMs, TimeUnit.MILLISECONDS);
// 启动监控
startMonitor();
log.info("Task scheduler started on node: {}", nodeId);
}
/**
* 核心轮询逻辑
*/
private void pollLoop() {
if (!running) return;
try {
// 计算当前可用的线程槽位
int availableSlots = maxPoolSize - taskExecutor.getActiveCount() - processingIds.size();
if (availableSlots <= 0) {
log.debug("No available slots, skip polling");
return;
}
int fetchSize = Math.min(availableSlots, batchSize);
List<Task> tasks = fetchTasksWithSkipLocked(fetchSize);
if (!tasks.isEmpty()) {
log.info("Fetched {} tasks, submitting to thread pool", tasks.size());
tasks.forEach(this::submitTask);
}
} catch (Exception e) {
log.error("Error in poll loop", e);
}
}
/**
* 使用 SKIP LOCKED 拉取任务
*/
@Transactional
public List<Task> fetchTasksWithSkipLocked(int limit) {
String sql = """
SELECT id, task_type, payload, status, execute_time, retry_times, max_retries, priority
FROM task
WHERE status IN (0, 4)
AND execute_time <= NOW()
ORDER BY priority DESC, execute_time ASC
LIMIT ?
FOR UPDATE SKIP LOCKED
""";
List<Task> tasks = jdbcTemplate.query(sql, (rs, rowNum) -> {
Task task = new Task();
task.setId(rs.getLong("id"));
task.setTaskType(rs.getString("task_type"));
task.setPayload(rs.getString("payload"));
task.setStatus(rs.getInt("status"));
task.setExecuteTime(rs.getTimestamp("execute_time").toLocalDateTime());
task.setRetryTimes(rs.getInt("retry_times"));
task.setMaxRetries(rs.getInt("max_retries"));
task.setPriority(rs.getInt("priority"));
return task;
}, limit);
if (tasks.isEmpty()) {
return Collections.emptyList();
}
// 更新任务状态为"执行中",并记录 node_id
List<Long> ids = tasks.stream().map(Task::getId).collect(Collectors.toList());
claimTasks(ids, nodeId);
return tasks;
}
/**
* 批量认领任务(更新状态和 node_id)
*/
private void claimTasks(List<Long> ids, String nodeId) {
String inClause = ids.stream().map(String::valueOf).collect(Collectors.joining(","));
String sql = String.format("""
UPDATE task
SET status = 1, node_id = '%s', update_time = NOW()
WHERE id IN (%s) AND status IN (0,4)
""", nodeId, inClause);
jdbcTemplate.update(sql);
}
/**
* 提交任务到线程池执行
*/
private void submitTask(Task task) {
// 本地去重:防止因并发导致重复提交
if (!processingIds.add(task.getId())) {
log.warn("Task {} already in processing, skip", task.getId());
return;
}
Future<?> future = taskExecutor.submit(() -> executeTask(task));
runningTasks.put(task.getId(), future);
}
}2.2 动态线程池管理
上面的代码中,线程池使用了 ThreadPoolExecutor,并通过 availableSlots 动态计算可拉取的任务数量,避免任务堆积在线程池队列中。当线程池活跃线程数接近最大值时,轮询线程会减少拉取量,实现**背压(backpressure)**机制。
线程池配置要点:
- corePoolSize:核心线程数,根据系统平均负载设置。
- maxPoolSize:最大线程数,应对突发流量。
- queue:有界队列,防止内存溢出。
- 拒绝策略 :这里使用
CallerRunsPolicy,当队列满时由轮询线程执行任务,相当于降级。
2.3 本地去重与任务追踪
为什么需要 processingIds 和 runningTasks?
- processingIds:一个线程安全的 Set,用于记录当前正在处理的任务 ID,防止同一任务被多次提交(例如,轮询线程在一次循环中不小心重复拉取到相同任务,虽然 SKIP LOCKED 保证了不同节点不会重复,但同一节点内由于异步提交可能导致重复)。
- runningTasks:记录每个任务的 Future,用于后续可能的取消操作(如优雅关闭时)。
三、任务执行器工厂模式
3.1 插件化设计
为了支持多种任务类型(如邮件、报表、清理等),我们采用工厂模式 + 策略模式。每个任务类型对应一个 TaskExecutor 实现类,通过 task_type 路由到正确的执行器。
java
public interface TaskExecutor {
/**
* 返回执行器支持的任务类型
*/
String getType();
/**
* 执行任务
* @param payload 任务参数(JSON 格式)
* @return 执行结果(可选)
* @throws Exception 执行失败时抛出异常
*/
Object execute(String payload) throws Exception;
}工厂类负责管理所有执行器:
java
@Component
public class TaskExecutorFactory {
private final Map<String, TaskExecutor> executorMap = new ConcurrentHashMap<>();
@Autowired
public TaskExecutorFactory(List<TaskExecutor> executors) {
executors.forEach(e -> executorMap.put(e.getType(), e));
}
public TaskExecutor getExecutor(String type) {
TaskExecutor executor = executorMap.get(type);
if (executor == null) {
throw new IllegalArgumentException("No executor found for type: " + type);
}
return executor;
}
// 允许动态注册(如热加载)
public void register(TaskExecutor executor) {
executorMap.put(executor.getType(), executor);
}
}3.2 示例:邮件任务执行器
java
@Component
public class EmailTaskExecutor implements TaskExecutor {
@Autowired
private EmailService emailService;
@Override
public String getType() {
return "EMAIL";
}
@Override
public Object execute(String payload) throws Exception {
// 解析 JSON 参数
JsonNode params = JsonUtils.parse(payload);
String to = params.get("to").asText();
String subject = params.get("subject").asText();
String content = params.get("content").asText();
emailService.send(to, subject, content);
return Map.of("sent", true, "to", to);
}
}3.3 执行任务的核心方法
在 executeTask 方法中,我们调用工厂获取执行器,并处理成功/失败逻辑:
java
private void executeTask(Task task) {
long taskId = task.getId();
String taskType = task.getTaskType();
int retryTimes = task.getRetryTimes();
int maxRetries = task.getMaxRetries();
try {
TaskExecutor executor = executorFactory.getExecutor(taskType);
Object result = executor.execute(task.getPayload());
// 执行成功,更新任务状态
markSuccess(taskId);
log.info("Task {} executed successfully", taskId);
} catch (Exception e) {
log.error("Task {} execution failed: {}", taskId, e.getMessage(), e);
// 判断是否需要重试
if (retryTimes < maxRetries) {
// 下次重试时间 = 当前时间 + 指数退避
LocalDateTime nextRetry = calculateNextRetryTime(retryTimes + 1);
markForRetry(taskId, retryTimes + 1, nextRetry, e.getMessage());
} else {
markFailed(taskId, e.getMessage());
}
} finally {
// 清理本地追踪
processingIds.remove(taskId);
runningTasks.remove(taskId);
}
}
private void markSuccess(Long taskId) {
jdbcTemplate.update("UPDATE task SET status = 2, node_id = NULL WHERE id = ?", taskId);
}
private void markForRetry(Long taskId, int retryTimes, LocalDateTime nextRetry, String errorMsg) {
jdbcTemplate.update("""
UPDATE task
SET status = 4, retry_times = ?, execute_time = ?, node_id = NULL,
update_time = NOW()
WHERE id = ?
""", retryTimes, nextRetry, taskId);
// 可选:记录错误日志到 task_log 表
}
private void markFailed(Long taskId, String errorMsg) {
jdbcTemplate.update("UPDATE task SET status = 3, node_id = NULL WHERE id = ?", taskId);
}
/**
* 指数退避计算下次重试时间:2^n 秒后,加上随机抖动(0~2^n 秒)
*/
private LocalDateTime calculateNextRetryTime(int retryTimes) {
long baseDelay = (long) Math.pow(2, retryTimes) * 1000; // 毫秒
long jitter = ThreadLocalRandom.current().nextLong(baseDelay);
return LocalDateTime.now().plusNanos(TimeUnit.MILLISECONDS.toNanos(baseDelay + jitter));
}四、故障恢复机制
分布式系统中,节点随时可能宕机。我们必须确保:
- 正在执行的任务不会丢失:如果节点在执行任务过程中宕机,该任务应被其他节点重新执行。
- 任务不会无限期卡在"执行中"状态:需要死任务检测机制。
4.1 死任务检测
每个节点可以启动一个定时任务,扫描那些处于"执行中"状态但长时间未更新的任务(即节点可能已宕机)。扫描条件通常是:
status = 1(执行中)update_time超过阈值(例如timeout_seconds+ 缓冲时间)
java
@Component
public class DeadTaskDetector {
@Autowired
private JdbcTemplate jdbcTemplate;
@Value("${scheduler.dead-task-timeout:300}") // 默认5分钟
private int timeoutSeconds;
@Scheduled(fixedDelay = 60000) // 每分钟执行一次
public void detectAndRecover() {
int recovered = jdbcTemplate.update("""
UPDATE task
SET status = 0,
node_id = NULL,
update_time = NOW()
WHERE status = 1
AND update_time < DATE_SUB(NOW(), INTERVAL ? SECOND)
""", timeoutSeconds);
if (recovered > 0) {
log.warn("Recovered {} dead tasks", recovered);
}
}
}注意:
- 超时时间应大于任务的最大执行时间,避免误判。
- 如果任务执行时间很长(如数小时),可以设计心跳机制:节点定期更新
update_time,表明自己还活着。这样死任务检测模块就不会误杀正在执行的长任务。
4.2 节点心跳与自动释放
为了防止长任务被误判为死任务,我们可以在每个节点启动一个心跳线程,定期更新自己领取的所有"执行中"任务的 update_time。
java
@Component
public class HeartbeatManager {
@Autowired
private JdbcTemplate jdbcTemplate;
@Value("${scheduler.node-id}")
private String nodeId;
@Scheduled(fixedDelay = 30000) // 每30秒心跳一次
public void heartbeat() {
int updated = jdbcTemplate.update("""
UPDATE task
SET update_time = NOW()
WHERE node_id = ? AND status = 1
""", nodeId);
if (updated > 0) {
log.debug("Heartbeat updated {} tasks", updated);
}
}
}当节点正常关闭时,我们应该主动释放自己领取的任务,以便其他节点立即接手。
java
@Override
public void destroy() {
running = false;
// 停止轮询
pollExecutor.shutdown();
// 取消正在执行的任务(可选,根据业务决定)
runningTasks.forEach((id, future) -> future.cancel(true));
// 释放所有由本节点领取的任务
int released = jdbcTemplate.update("""
UPDATE task
SET status = 0, node_id = NULL
WHERE node_id = ? AND status = 1
""", nodeId);
log.info("Released {} tasks on shutdown", released);
// 关闭线程池
taskExecutor.shutdown();
try {
if (!taskExecutor.awaitTermination(60, TimeUnit.SECONDS)) {
taskExecutor.shutdownNow();
}
} catch (InterruptedException e) {
taskExecutor.shutdownNow();
}
}4.3 整体故障恢复流程
死任务检测器 数据库 节点B 节点A 死任务检测器 数据库 节点B 节点A 心跳停止 loop 每30秒 领取任务T1,更新状态为执行中 节点A突然宕机 扫描执行中超时的任务 发现T1超时(update_time过旧) 更新T1状态为待执行,node_id=NULL 轮询任务,使用SKIP LOCKED 返回T1(因为已被释放) 领取T1,状态置为执行中 执行T1
通过这种方式,系统实现了自动故障转移,保证了任务最终会被执行。
五、总结与扩展
本文详细介绍了如何使用线程池和 SKIP LOCKED 构建一个高可用的分布式调度引擎。我们涉及了:
- 架构设计:多节点无状态 + 共享数据库
- 任务表设计:关键字段和索引优化
- 核心调度器:轮询、SKIP LOCKED、动态线程池
- 任务执行器:工厂模式支持多种任务类型
- 故障恢复:死任务检测 + 心跳机制
这个架构已经在多家公司的生产环境中得到验证,能够支撑每日千万级的任务调度。如果你正在设计类似的系统,完全可以基于本文的代码进行改造。
当然,还有很多可以优化的地方:
- 分库分表:当任务量极大时,可以对任务表进行水平拆分。
- 优先级队列:可以使用多个队列(如高、中、低优先级)分别拉取。
- 任务依赖:可以引入 DAG 工作流支持。
- 监控告警:对接 Prometheus + Grafana,实时监控任务堆积、失败率等。
在下一篇文章中,我们将探讨如何兼容多种数据库(如 SQL Server、Oracle)以及如何进行性能调优,敬请期待!
如果你觉得这篇文章对你有帮助,欢迎点赞、收藏、分享,也欢迎在评论区留言交流你的实战经验!